Nov 08, 2025·8 min
How Small Teams with AI Ship Faster Than Big Engineering Orgs
Learn why small teams using AI can ship faster than large engineering orgs: less overhead, tighter feedback loops, smarter automation, and clearer ownership.
Learn why small teams using AI can ship faster than large engineering orgs: less overhead, tighter feedback loops, smarter automation, and clearer ownership.
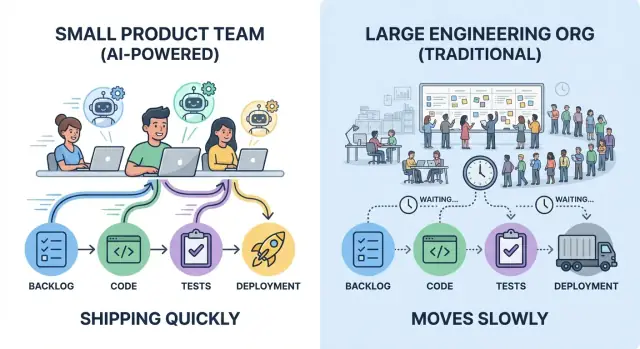
“Shipping faster” isn’t just typing code quickly. Real delivery speed is the time between an idea becoming a reliable improvement users can feel—and the team learning whether it worked.
Teams argue about speed because they’re measuring different things. A practical view is a small set of delivery metrics:
A small team that deploys five small changes per week often learns faster than a larger org that deploys one big release per month—even if the monthly release contains more code.
In practice, “AI for engineering” usually looks like a set of assistants embedded into existing work:
AI helps most with throughput per person and reducing rework—but it doesn’t replace good product judgment, clear requirements, or ownership.
Speed is mostly constrained by two forces: coordination overhead (handoffs, approvals, waiting) and iteration loops (build → release → observe → adjust). AI amplifies teams that already keep work small, decisions clear, and feedback tight.
Without habits and guardrails—tests, code review, and release discipline—AI can also accelerate the wrong work just as efficiently.
Big engineering orgs don’t just add people—they add connections. Each new team boundary introduces coordination work that doesn’t ship features: syncing priorities, aligning designs, negotiating ownership, and routing changes through the “right” channels.
Coordination overhead shows up in familiar places:
None of these are inherently bad. The problem is that they compound—and they grow faster than headcount.
In a large org, a simple change often crosses several dependency lines: one team owns the UI, another owns the API, a platform team owns deployment, and an infosec group owns approval. Even if each group is efficient, the queue time dominates.
Common slowdowns look like:
Lead time isn’t just coding time; it’s elapsed time from idea to production. Every extra handshake adds latency: you wait for the next meeting, the next reviewer, the next sprint, the next slot in someone else’s queue.
Small teams often win because they can keep ownership tight and decisions local. That doesn’t eliminate reviews—it reduces the number of hops between “ready” and “shipped,” which is where large orgs quietly lose days and weeks.
Speed isn’t just about typing faster—it’s about making fewer people wait. Small teams tend to ship quickly when work has single-threaded ownership: one clearly responsible person (or pair) who drives a feature from idea to production, with a named decision maker who can resolve tradeoffs.
When one owner is accountable for outcomes, decisions don’t bounce between product, design, engineering, and “the platform team” in a loop. The owner gathers input, makes the call, and moves forward.
This doesn’t mean working alone. It means everyone knows who is steering, who approves, and what “done” means.
Every handoff adds two types of cost:
Small teams avoid this by keeping the problem inside a tight loop: the same owner participates in requirements, implementation, rollout, and follow-up. The result is fewer “wait, that’s not what I meant” moments.
AI doesn’t replace ownership—it extends it. A single owner can stay effective across more tasks by using AI to:
The owner still validates and decides, but the time spent getting from blank page to workable draft drops sharply.
If you’re using a vibe-coding workflow (for example, Koder.ai), this “one owner covers the whole slice” model gets even easier: you can draft a plan, generate a React UI plus a Go/PostgreSQL backend skeleton, and iterate through small changes in the same chat-driven loop—then export source code when you want tighter control.
Look for these operational signs:
When these signals are present, a small team can move with confidence—and AI makes that momentum easier to sustain.
Big plans feel efficient because they reduce the number of “decision moments.” But they often push learning to the end—after weeks of building—when changes are most expensive. Small teams move faster by shrinking the distance between an idea and real-world feedback.
A short feedback loop is simple: build the smallest thing that can teach you something, put it in front of users, and decide what to do next.
When feedback arrives in days (not quarters), you stop polishing the wrong solution. You also avoid over-engineering “just in case” requirements that never materialize.
Small teams can run lightweight cycles that still produce strong signals:
The key is to treat each cycle as an experiment, not a mini-project.
AI’s biggest leverage here isn’t writing more code—it’s compressing the time from “we heard something” to “we know what to try next.” For example, you can use AI to:
That means less time in synthesis meetings and more time running the next test.
Teams often celebrate shipping velocity—how many features went out. But real speed is learning velocity: how quickly you can reduce uncertainty and make better decisions.
A large org can ship a lot and still be slow if it learns late. A small team can ship less “volume” but move faster by learning earlier, correcting sooner, and letting evidence—not opinions—shape the roadmap.
AI doesn’t make a small team “bigger.” It makes the team’s existing judgment and ownership travel further. The win isn’t that AI writes code; it’s that it removes drag from the parts of delivery that steal time without improving the product.
Small teams get outsized gains when they aim AI at work that’s necessary but rarely differentiating:
The pattern is consistent: AI accelerates the first 80% so humans can spend more time on the final 20%—the part that requires product sense.
AI shines on routine tasks, “known problems,” and anything that starts from an existing codebase pattern. It’s also great for exploring options quickly: propose two implementations, list tradeoffs, or surface edge cases you may have missed.
It helps least when requirements are unclear, when the architecture decision has long-term consequences, or when the problem is highly domain-specific with little written context. If the team can’t explain what “done” means, AI can only generate plausible-looking output faster.
Treat AI as a junior collaborator: useful, fast, and sometimes wrong. Humans still own the outcome.
That means every AI-assisted change should still have review, tests, and basic sanity checks. The practical rule: use AI to draft and transform; use humans to decide and verify. This is how small teams ship faster without turning velocity into future cleanup.
Context switching is one of the quiet killers of speed on small teams. It’s not just “being interrupted”—it’s the mental reboot every time you bounce between code, tickets, docs, Slack threads, and unfamiliar parts of the system. AI helps most when it turns those reboots into quick pit stops.
Instead of spending 20 minutes hunting for an answer, you can ask for a fast summary, a pointer to likely files, or a plain-English explanation of what you’re looking at. Used well, AI becomes a “first draft” generator for understanding: it can summarize a long PR, turn a vague bug report into hypotheses, or translate a scary stack trace into likely causes.
The win isn’t that AI is always right—it’s that it gets you oriented faster so you can make real decisions.
A few prompt patterns consistently reduce thrash:
These prompts shift you from wandering to executing.
Speed compounds when prompts become templates the whole team uses. Keep a small internal “prompt kit” for common jobs: PR reviews, incident notes, migration plans, QA checklists, and release runbooks. Consistency matters: include the goal, constraints (time, scope, risk), and the expected output format.
Don’t paste secrets, customer data, or anything you wouldn’t put in a ticket. Treat outputs as suggestions: verify critical claims, run tests, and double-check generated code—especially around auth, payments, and data deletion. AI reduces context switching; it shouldn’t replace engineering judgment.
Shipping faster isn’t about heroic sprints; it’s about reducing the size of each change until delivery becomes routine. Small teams already have an advantage here: fewer dependencies make it easier to keep work sliced thin. AI amplifies that advantage by shrinking the time between “idea” and “safe, releasable change.”
A simple pipeline beats an elaborate one:
AI helps by drafting release notes, suggesting smaller commits, and flagging files that are likely to be touched together—nudging you toward cleaner, tighter PRs.
Tests are often where “ship often” breaks down. AI can reduce that friction by:
Treat AI-generated tests as a first draft: review for correctness, then keep the ones that meaningfully protect behavior.
Frequent deploys require fast detection and fast recovery. Set up:
If your delivery fundamentals need a refresher, link this into your team’s shared reading: /blog/continuous-delivery-basics.
With these practices, AI doesn’t “make you faster” by magic—it removes the small delays that otherwise accumulate into week-long cycles.
Big engineering organizations rarely move slowly because people are lazy. They move slowly because decisions queue up. Architectural councils meet monthly. Security and privacy reviews sit behind ticket backlogs. A “simple” change can require a tech lead review, then a staff engineer review, then a platform sign-off, then a release manager approval. Each hop adds wait time, not just work time.
Small teams can’t afford that kind of decision latency, so they should aim for a different model: fewer approvals, stronger guardrails.
Approval chains are a risk-management tool. They reduce the chance of bad changes, but they also centralize decision-making. When the same small group must bless every meaningful change, throughput collapses and engineers start optimizing for “getting approval” rather than improving the product.
Guardrails shift quality checks from meetings to defaults:
Instead of “Who approved this?”, the question becomes “Did this pass the agreed gates?”
AI can standardize quality without adding more humans to the loop:
This improves consistency and makes reviews faster, because reviewers start from a structured brief rather than a blank screen.
Compliance doesn’t need a committee. Keep it repeatable:
Approvals become the exception for high-risk work; guardrails handle the rest. That’s how small teams stay fast without being reckless.
Big teams often “design the whole system” before anyone ships. Small teams can move faster by designing thin slices: the smallest end-to-end unit of value that can go from idea → code → production and be used (even by a small cohort).
A thin slice is vertical ownership, not a horizontal phase. It includes whatever is needed across design, backend, frontend, and ops to make one outcome real.
Instead of “redesign onboarding,” a thin slice might be “collect one extra signup field, validate it, store it, show it in the profile, and track completion.” It’s small enough to finish quickly, but complete enough to learn from.
AI is useful here as a structured thinking partner:
The goal isn’t more tasks—it’s a clear, shippable boundary.
Momentum dies when “almost done” drags on. For every slice, write explicit Definition of Done items:
POST /checkout/quote returning price + taxesThin slices keep design honest: you’re designing what you can ship now, learning quickly, and letting the next slice earn its complexity.
AI can help a small team move quickly, but it also changes the failure modes. The goal isn’t to “slow down to be safe”—it’s to add lightweight guardrails so you can keep shipping without accumulating invisible debt.
Moving faster increases the chance that rough edges slip into production. With AI assistance, a few risks show up repeatedly:
Keep rules explicit and easy to follow. A few practices pay off quickly:
AI can draft code; humans must own outcomes.
Treat prompts like public text: don’t paste secrets, tokens, or customer data. Ask the model to explain assumptions, then verify with primary sources (docs) and tests. When something feels “too convenient,” it usually needs a closer look.
If you use an AI-driven build environment like Koder.ai, apply the same rules: keep sensitive data out of prompts, insist on tests and review, and rely on snapshots/rollback-style workflows so “fast” also means “recoverable.”
Speed only matters if you can see it, explain it, and recreate it. The goal isn’t “use more AI”—it’s a simple system where AI-assisted practices reliably reduce time-to-value without raising risk.
Pick a small set you can track weekly:
Add one qualitative signal: “What slowed us down most this week?” It helps you spot bottlenecks metrics won’t.
Keep it consistent, and keep it small-team friendly:
Week 1: Baseline. Measure the metrics above for 5–10 working days. No changes yet.
Weeks 2–3: Pick 2–3 AI workflows. Examples: PR description + risk checklist generation, test-writing assistance, release notes + changelog drafting.
Week 4: Compare before/after and lock in habits. If PR size drops and review time improves without more incidents, keep it. If incidents rise, add guardrails (smaller rollouts, better tests, clearer ownership).
Delivery speed is the elapsed time from an idea becoming a decision to a reliable change being live for users and generating feedback you can trust. It’s less about “coding fast” and more about minimizing waiting (queues, approvals, handoffs) and tightening build → release → observe → adjust loops.
They capture different bottlenecks:
Using all four prevents optimizing one number while the real delay hides elsewhere.
Coordination overhead grows with team boundaries and dependencies. More handoffs mean more:
A small team with clear ownership can often keep decisions local and ship in smaller increments.
It means one clearly accountable owner drives a slice from idea to production, gathers input, and makes calls when tradeoffs appear. Practically:
This reduces back-and-forth and keeps work moving.
AI works best as an accelerator for drafts and transformations, such as:
It increases throughput per person and reduces rework—but it doesn’t replace product judgment or verification.
AI can make it easier to ship the wrong thing faster if you don’t keep learning tight. Good practice is to pair AI-assisted building with AI-assisted learning:
Optimize for learning velocity, not feature volume.
Treat AI output like a fast junior collaborator: helpful, but sometimes wrong. Keep guardrails lightweight and automatic:
Rule of thumb: AI drafts; humans decide and verify.
Use guardrails to make “safe by default” the normal path:
Reserve human approvals for truly high-risk changes rather than routing everything through a committee.
A thin slice is a small, end-to-end unit of value (design + backend + frontend + ops as needed) that can ship and teach you something. Examples:
Thin slices keep momentum because you reach production and feedback faster.
Start with a baseline and focus on a few weekly signals:
Run a short weekly check: “What slowed us down most?” If your delivery fundamentals need alignment, standardize on a shared reference like /blog/continuous-delivery-basics.