Nov 14, 2025·8 min
Why Read Replicas Exist and When They Actually Help
Learn why read replicas exist, what problems they solve, and when they help (or hurt). Includes common use cases, limits, and practical decision tips.
Learn why read replicas exist, what problems they solve, and when they help (or hurt). Includes common use cases, limits, and practical decision tips.
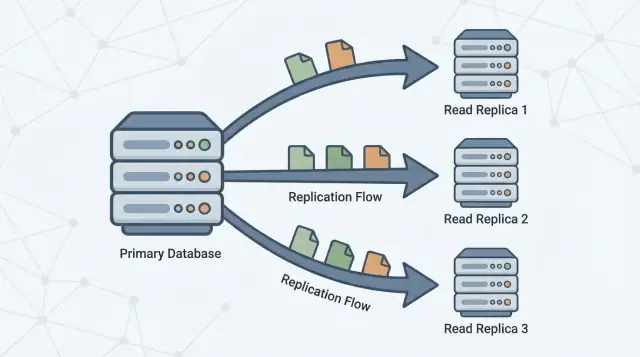
A read replica is a copy of your main database (often called the primary) that stays up to date by continuously receiving changes from it. Your application can send read-only queries (like SELECT) to the replica, while the primary continues to handle all writes (like INSERT, UPDATE, and DELETE).
The promise is simple: more read capacity without putting more pressure on the primary.
If your app has lots of “fetch” traffic—homepages, product pages, user profiles, dashboards—moving some of those reads to one or more replicas can free the primary to focus on write work and critical reads. In many setups, this can be done with minimal application change: you keep one database as the source of truth and add replicas as additional places to query.
Read replicas are useful, but they’re not a magic performance button. They do not:
Think of replicas as a read-scaling tool with trade-offs. The rest of this article explains when they actually help, the common ways they backfire, and how concepts like replication lag and eventual consistency affect what users see when you start reading from a copy instead of the primary.
A single primary database server often starts out feeling “big enough.” It handles writes (inserts, updates, deletes) and it also answers every read request (SELECT queries) from your app, dashboards, and internal tools.
As usage grows, reads usually multiply faster than writes: every page view might trigger several queries, search screens can fan out into many lookups, and analytics-style queries can scan lots of rows. Even if your write volume is moderate, the primary can still become a bottleneck because it has to do two jobs at once: accept changes safely and quickly, and serve a growing pile of read traffic with low latency.
Read replicas exist to split that workload. The primary stays focused on processing writes and maintaining the “source of truth,” while one or more replicas handle read-only queries. When your application can route some queries to replicas, you reduce CPU, memory, and I/O pressure on the primary. That typically improves overall responsiveness and leaves more headroom for write bursts.
Replication is the mechanism that keeps replicas up to date by copying changes from the primary to other servers. The primary records changes, and replicas apply those changes so they can answer queries using nearly the same data.
This pattern is common across many database systems and managed services (for example PostgreSQL, MySQL, and cloud-hosted variants). The exact implementation differs, but the goal is the same: increase read capacity without forcing your primary to scale vertically forever.
Think of a primary database as the “source of truth.” It accepts every write—creating orders, updating profiles, recording payments—and assigns those changes a definite order.
One or more read replicas then follow the primary, copying those changes so they can answer read queries (like “show my order history”) without putting more load on the primary.
Reads can be served from replicas, but writes still go to the primary.
Replication can happen in two broad modes:
That delay—replicas being behind the primary—is called replication lag. It’s not automatically a failure; it’s often the normal trade-off you accept to scale reads.
For end users, lag shows up as eventual consistency: after you change something, the system will become consistent everywhere, but not necessarily instantly.
Example: you update your email address and refresh your profile page. If the page is served from a replica that’s a few seconds behind, you might briefly see the old email—until the replica applies the update and “catches up.”
Read replicas help when your primary database is healthy for writes but gets overwhelmed serving read traffic. They’re most effective when you can offload a meaningful chunk of SELECT load without changing how you write data.
Look for patterns like:
SELECT queries compared to INSERT/UPDATE/DELETEBefore adding replicas, validate with a few concrete signals:
SELECT statements (from your slow query log/APM).Often, the best first move is tuning: add the right index, rewrite one query, reduce N+1 calls, or cache hot reads. These changes can be faster and cheaper than operating replicas.
Choose replicas if:
Choose tuning first if:
Read replicas are most valuable when your primary database is busy handling writes (checkouts, sign-ups, updates), but a big share of traffic is read-heavy. In a primary–replica architecture, pushing the right queries to replicas improves database performance without changing application features.
Dashboards often run long queries: grouping, filtering across large date ranges, or joining multiple tables. Those queries can compete with transactional work for CPU, memory, and cache.
A read replica is a good place for:
You keep the primary focused on fast, predictable transactions while analytics reads scale independently.
Catalog browsing, user profiles, and content feeds can produce a high volume of similar read queries. When that read scaling pressure is the bottleneck, replicas can absorb traffic and reduce latency spikes.
This is especially effective when reads are cache-miss heavy (many unique queries) or when you can’t rely solely on an application cache.
Exports, backfills, recomputing summaries, and “find every record that matches X” jobs can thrash the primary. Running these scans against a replica is often safer.
Just make sure the job tolerates eventual consistency: with replication lag, it may not see the newest updates.
If you serve users globally, placing read replicas closer to them can reduce round-trip time. The trade-off is stronger exposure to stale reads during lag or network issues, so it’s best for pages where “nearly up to date” is acceptable (browse, recommendations, public content).
Read replicas are great when “close enough” is good enough. They backfire when your product quietly assumes every read reflects the latest write.
A user edits their profile, submits a form, or changes account settings—and the next page load pulls from a replica that’s a few seconds behind. The update succeeded, but the user sees old data and retries, double-submits, or loses trust.
This is especially painful in flows where the user expects immediate confirmation: changing an email address, toggling preferences, uploading a document, or posting a comment and then being redirected back.
Some reads can’t tolerate being stale, even briefly:
If a replica is behind, you can show the wrong cart total, oversell stock, or display an outdated balance. Even if the system later corrects itself, the user experience (and support volume) takes the hit.
Internal dashboards often drive real decisions: fraud review, customer support, order fulfillment, moderation, and incident response. If an admin tool reads from replicas, you risk acting on incomplete data—e.g., refunding an order that was already refunded, or missing the latest status change.
A common pattern is conditional routing:
This preserves the benefits of replicas without turning consistency into a guessing game.
Replication lag is the delay between when a write is committed on the primary database and when that same change becomes visible on a read replica. If your app reads from a replica during that delay, it can return “stale” results—data that was true a moment ago, but not anymore.
Lag is normal, and it usually grows under stress. Common causes include:
Lag doesn’t just affect “freshness”—it affects correctness from a user’s perspective:
Start by deciding what your feature can tolerate:
Track replica lag (time/bytes behind), replica apply rate, replication errors, and replica CPU/disk I/O. Alert when lag exceeds your agreed tolerance (e.g., 5s, 30s, 2m) and when lag keeps increasing over time (a sign the replica will never catch up without intervention).
Read replicas are a tool for read scaling: adding more places to serve SELECT queries. They are not a tool for write scaling: increasing how many INSERT/UPDATE/DELETE operations your system can accept.
When you add replicas, you add read capacity. If your application is bottlenecked on read-heavy endpoints (product pages, feeds, lookups), you can spread those queries across multiple machines.
This often improves:
SELECTs)A common misconception is that “more replicas = more write throughput.” In a typical primary-replica setup, all writes still go to the primary. In fact, more replicas can slightly increase work for the primary, because it must generate and ship replication data to every replica.
If your pain is write throughput, replicas won’t fix it. You’re usually looking at different approaches (query/index tuning, batching, partitioning/sharding, or changing the data model).
Even if replicas give you more read CPU, you can still hit connection limits first. Each database node has a maximum number of concurrent connections, and adding replicas can multiply the number of places your app could connect—without reducing the total demand.
Practical rule: use connection pooling (or a pooler) and keep your per-service connection counts intentional. Otherwise, replicas can simply become “more databases to overload.”
Replicas add real costs:
The trade-off is simple: replicas can buy you read headroom and isolation, but they add complexity and don’t move the write ceiling.
Read replicas can improve read availability: if your primary is overloaded or briefly unavailable, you may still be able to serve some read-only traffic from replicas. That can keep customer-facing pages responsive (for content that tolerates slightly stale data) and reduce the blast radius of a primary incident.
What replicas don’t provide is a complete high-availability plan by themselves. A replica is usually not ready to take writes automatically, and a “readable copy exists” is different from “the system can safely and quickly accept writes again.”
Failover typically means: detect primary failure → pick a replica → promote it to become the new primary → redirect writes (and usually reads) to the promoted node.
Some managed databases automate most of this, but the core idea stays the same: you’re changing who is allowed to accept writes.
Treat failover as something you practice. Run game-day tests in staging (and carefully in production during low-risk windows): simulate primary loss, measure time-to-recover, verify routing, and confirm your app handles read-only periods and reconnections cleanly.
Read replicas only help if your traffic actually reaches them. “Read/write splitting” is the set of rules that sends writes to the primary and eligible reads to replicas—without breaking correctness.
The simplest approach is explicit routing in your data access layer:
INSERT/UPDATE/DELETE, schema changes) go to the primary.This is easy to reason about and easy to roll back. It’s also where you can encode business rules like “after checkout, always read order status from primary for a while.”
Some teams prefer a database proxy or smart driver that understands “primary vs replica” endpoints and routes based on query type or connection settings. This reduces application code changes, but be careful: proxies can’t reliably know which reads are “safe” from a product perspective.
Good candidates:
Avoid routing reads that immediately follow a user write (e.g., “update profile → reload profile”) unless you have a consistency strategy.
Within a transaction, keep all reads on the primary.
Outside transactions, consider “read-your-writes” sessions: after a write, pin that user/session to the primary for a short TTL, or route specific follow-up queries to the primary.
Add one replica, route a limited set of endpoints/queries, and compare before/after:
Expand routing only when the impact is clear and safe.
Read replicas aren’t “set and forget.” They’re extra database servers with their own performance limits, failure modes, and operational chores. A little monitoring discipline is usually the difference between “replicas helped” and “replicas added confusion.”
Focus on indicators that explain user-facing symptoms:
Start with one replica if your goal is offloading reads. Add more when you have a clear constraint:
A practical rule: scale replicas only after you’ve confirmed reads are the bottleneck (not indexes, slow queries, or app caching).
Read replicas are one tool for read scaling, but they’re rarely the first lever to pull. Before adding operational complexity, check whether a simpler fix gets you the same outcome.
Caching can remove entire classes of reads from your database. For “read-mostly” pages (product details, public profiles, configuration), an application cache or CDN can cut load dramatically—without introducing replication lag.
Indexes and query optimization often outperform replicas for the common case: a few expensive queries burning CPU. Adding the right index, reducing SELECT columns, avoiding N+1 queries, and fixing bad joins can turn “we need replicas” into “we just needed a better plan.”
Materialized views / pre-aggregation help when the workload is inherently heavy (analytics, dashboards). Instead of re-running complex queries, you store computed results and refresh on a schedule.
If your writes are the bottleneck (hot rows, lock contention, write IOPS limits), replicas won’t help much. That’s when partitioning tables by time/tenant, or sharding by customer ID, can spread write load and reduce contention. It’s a bigger architectural step, but it addresses the real constraint.
Ask four questions:
If you’re prototyping a new product or spinning up a service quickly, it helps to bake these constraints into the architecture early. For example, teams building on Koder.ai (a vibe-coding platform that generates React apps with Go + PostgreSQL backends from a chat interface) often start with a single primary for simplicity, then graduate to replicas as soon as dashboards, feeds, or internal reporting begin competing with transactional traffic. Using a planning-first workflow makes it easier to decide upfront which endpoints can tolerate eventual consistency and which must be “read-your-writes” from the primary.
If you want help choosing a path, see /pricing for options, or browse related guides in /blog.
A read replica is a copy of your primary database that continuously receives changes and can answer read-only queries (for example, SELECT). It helps you add read capacity without increasing load on the primary for those reads.
No. In a typical primary–replica setup, all writes still go to the primary. Replicas can even add a bit of overhead because the primary must ship changes to each replica.
Mostly when you’re read-bound: lots of SELECT traffic is driving CPU/I/O or connection pressure on the primary, while write volume is relatively stable. They’re also useful to isolate heavy reads (reporting, exports) from transactional workloads.
Not necessarily. If a query is slow due to missing indexes, poor joins, or scanning too much data, it will often be slow on a replica too—just slow somewhere else. Tune queries and indexes first when a few queries dominate total time.
Replication lag is the delay between a write being committed on the primary and that change becoming visible on a replica. During lag, replica reads can be stale, which is why systems using replicas often behave with eventual consistency for some reads.
Common causes include:
Avoid replicas for reads that must reflect the latest write, such as:
For these, prefer reading from the primary, at least in critical paths.
Use a read-your-writes strategy:
Track a small set of signals:
Alert when lag exceeds your product’s tolerance (for example, 5s/30s/2m).
Common alternatives include:
Replicas are best when reads are already reasonably optimized and you can tolerate some staleness.