২১ আগ, ২০২৫·7 মিনিট
আপনাকে জানা বাধ্যতামূলক 6টি SQL JOIN (সহজ, স্পষ্ট উদাহরণসহ)
INNER, LEFT, RIGHT, FULL OUTER, CROSS এবং SELF—এই ৬টি SQL JOIN প্রত্যেক বিশ্লেষকের জানা উচিত। ব্যবহারযোগ্য উদাহরণ ও সাধারণ জালিয়াপক ত্রুটি সমেত শিখুন।
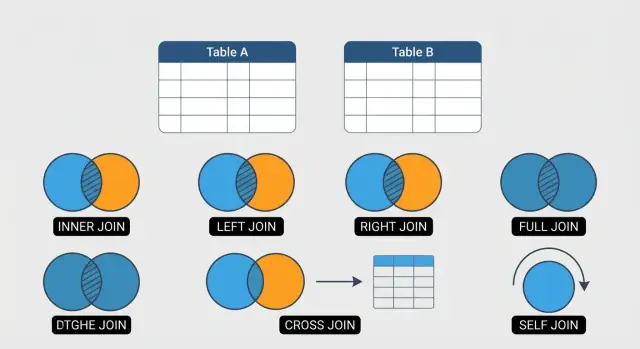
INNER, LEFT, RIGHT, FULL OUTER, CROSS এবং SELF—এই ৬টি SQL JOIN প্রত্যেক বিশ্লেষকের জানা উচিত। ব্যবহারযোগ্য উদাহরণ ও সাধারণ জালিয়াপক ত্রুটি সমেত শিখুন।
একটি SQL JOIN আপনাকে দুই (বা তার বেশি) টেবিলের সারিগুলোকে একত্র করে একটি ফলাফল তালিকা দেয়—সাধারণত একটি সম্পর্কিত কলাম (যেমন একটি id) ব্যবহার করে মিলিয়ে।
বেশিরভাগ বাস্তব ডাটাবেস ইচ্ছাকৃতভাবে আলাদা টেবিলে ভাগ করা থাকে যাতে একই তথ্য বার বার পুনরাবৃত্তি না হয়। উদাহরণস্বরূপ: গ্রাহকের নাম customers টেবিলে থাকে, আর তাদের ক্রয়সমূহ orders টেবিলে থাকে। যখন উত্তর দরকার, JOIN-ই সেই টুকরোগুলোকে আবার জোড়ায়।
এ কারণেই JOIN-গুলো রিপোর্টিং এবং বিশ্লেষণে সর্বত্র দেখা যায়:
JOIN না থাকলে আপনাকে আলাদা করে কুয়েরি চালিয়ে ম্যানুয়ালি ফলাফল মিলাতে হত—ধীর, ত্রুটিপূর্ণ এবং পুনরাবৃত্তিহীন।
যদি আপনি রিলেশনাল ডাটাবেসের উপর পণ্য তৈরি করেন (ড্যাশবোর্ড, অ্যাডমিন প্যানেল, অভ্যন্তরীণ টুল, কাস্টমার পোর্টাল), JOIN-ই কাঁচা টেবিলকে ব্যবহারকারীগণের সামনে প্রদর্শনের উপযোগী ভিউতে পরিণত করে। এমন প্ল্যাটফর্মগুলো দ্রুত ডেভেলপমেন্ট সরবরাহ করলেও (উদাহরণ: React + Go + PostgreSQL অ্যাপ জেনারেট করা টুল), সঠিক JOIN নীতিগুলোই নির্ভুল তালিকা পেইজ, রিপোর্ট ও রেকনসিলিয়েশন স্ক্রিন তৈরিতে প্রয়োজনীয় থাকে।
এই গাইডে এমন ছয়টি JOIN-কে কেন্দ্র করে যেগুলো দৈনন্দিন SQL কাজে বেশিরভাগ কেস কভার করে:
JOIN সিনট্যাক্স বেশিরভাগ SQL ডাটাবেসে (PostgreSQL, MySQL, SQL Server, SQLite) অনুরূপ। কিছু পার্থক্য আছে—বিশেষত FULL OUTER JOIN সাপোর্ট ও কিছু এজ-কেস আচরণ নিয়ে—কিন্তু ধারণা ও মূল নকশা সহজেই ট্রান্সফার করা যায়।
JOIN উদাহরণগুলো সহজ রাখতে আমরা তিনটি ছোট টেবিল ব্যবহার করব যা বাস্তবের সাথে মিল রাখে: গ্রাহকরা অর্ডার করে, আর অর্ডারগুলোর সাথে পেমেন্ট থাকতে বা নাও থাকতে পারে।
একটি ছোট নোট: নিচের স্যাম্পল টেবিলগুলোতে কিছু কলামই দেখানো আছে, কিন্তু পরের কুয়েরিগুলোতে কখনও কখনও অতিরিক্ত ফিল্ড (যেমন order_date, created_at, status, paid_at) উল্লেখ থাকবে—এগুলো সাধারণ প্রোডাকশন স্কিমায় থাকা স্বাভাবিক কলাম হিসেবে ধরুন।
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
মন করুন order_id = 104 customer_id = 5 কে রেফার করছে, যা customers-এ নেই। এই “মিসিং ম্যাচ” দেখে LEFT/RIGHT/FULL OUTER JOIN কিভাবে আচরণ করে তা বোঝা যাবে।
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
এখানে দুটি গুরুত্বপূর্ণ শিক্ষণীয় পয়েন্ট:
order_id = 102-এর জন্য দুটি পেমেন্ট সারি আছে (বিভক্ত পেমেন্ট)। যখন আপনি orders কে payments-এর সাথে জয়েন করবেন, ঐ অর্ডারটি দুটি বার দেখাবে—এটাই ডুপ্লিকেট সম্পর্কে মানুষকে বিভ্রান্ত করে।payment_id = 9004 order_id = 999 কে রেফার করে, যা orders-এ নেই। এটাও একটি “অনম্যাচড” কেস।orders-কে payments-এর সাথে যোগ করলে অর্ডার 102 দুটোবার দেখা যাবে কারণ তার দুইটি পেমেন্ট আছে।INNER JOIN কেবল সেই সারিগুলো রিটার্ন করে যেখানে উভয় টেবিলে মিল আছে। যদি কোনো গ্রাহকের কোনো অর্ডার না থাকে, তারা ফলাফলে থাকবে না। যদি কোনো অর্ডার এমন কোনো গ্রাহককে রেফার করে যা নেই (খারাপ ডেটা), সেটাও বের হবে না।
আপনি একটি “বাম” টেবিল বেছে নেন, একটি “ডান” টেবিল জয়েন করেন, এবং ON ক্লজে কিভাবে মিলবে তা বলে দেন।
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
কী আইডিয়া হলো ON o.customer_id = c.customer_id লাইনটি: এটি SQL-কে বলে কিভাবে সারিগুলো সম্পর্কিত।
যদি আপনি কেবল তাদের গ্রাহকদের তালিকা চান যারা কমপক্ষে একটি অর্ডার করেছেন (এবং অর্ডারের বিবরণ), তাহলে INNER JOIN হলো স্বাভাবিক নির্বাচন:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
এটি এমন কেসের জন্য দরকারি যেমন "অর্ডার ফলো-আপ ইমেইল পাঠান" বা "ক্রেতা অনুযায়ী রাজস্ব হিসাব করুন" (যখন আপনি কেবল ক্রেতাদের নিয়ে কাজ করছেন যারা ক্রয় করেছেন)।
যদি আপনি একটি JOIN লিখেন কিন্তু ON কন্ডিশন ভুলে যান (বা ভুল স্তম্ভে জয়েন করেন), আপনি অসাবধানতাবশত একটি কার্টেসিয়ান প্রোডাক্ট তৈরি করতে পারেন (প্রতিটি গ্রাহক প্রতিটি অর্ডারের সাথে মিলবে) অথবা সূক্ষ্মভাবে ভুল ম্যাচ তৈরি করতে পারেন।
ভুল (এটা করবেন না):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
সবসময় নিশ্চিত করুন যে ON (বা যেখানে প্রযোজ্য USING)-এ স্পষ্ট জয়েন কন্ডিশন আছে।
LEFT JOIN বাম টেবিলের সব সারি ফেরত দেয়, এবং ডান টেবিল থেকে যেখানে মিল পাওয়া যায় সেগুলো যোগ করে। যদি কোনো মিল না থাকে, ডান-সাইড কলামগুলোতে NULL দেখা যাবে।
আপনি যখন আপনার মূল টেবিল থেকে সম্পূর্ণ তালিকা চান এবং সঙ্গে সম্ভাব্য সম্পর্কিত ডেটা যোগ করতে চান তখন LEFT JOIN ব্যবহার করুন।
উদাহরণ: “আমাকে সব গ্রাহক দেখান, এবং তাদের যদি থাকে তাহলে অর্ডারগুলোও দেখান।”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (এবং orders-এর অন্যান্য কলাম) NULL হবে।LEFT JOIN ব্যবহারের একটি খুব সাধারণ কারণ হলো এমন আইটেম খুঁজে পাওয়া যাদের সংক্রান্ত কোনো রেকর্ড নেই।
উদাহরণ: "কোন গ্রাহকরা কখনও অর্ডার করেননি?"
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
এই WHERE ... IS NULL কন্ডিশন কেবল তাদের বাম-টেবিল সারিগুলো রাখে যেখানে মিল খুঁজে পাওয়া যায়নি।
LEFT JOIN বাম-টেবিলের সারিগুলোকে “ঘনীভূত” করতে পারে যখন ডান পাশে একাধিক ম্যাচ থাকে।
যদি এক গ্রাহকের 3টি অর্ডার থাকে, সে গ্রাহক 3 বার দেখাবে—প্রতি অর্ডারের জন্য একবার। এটা প্রত্যাশিত, কিন্তু গ্রাহক কাউন্ট করতে গেলে বিভ্রান্তি সৃষ্টি করতে পারে।
উদাহরণ, এটি অর্ডারগুলোকে গোনে (গ্রাহক নয়):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
যদি আপনার উদ্দেশ্য গ্রাহকদের গণনা করা হয়, আপনি সাধারণত গ্রাহক কীকে গণনা করবেন (প্রসঙ্গক্রমে COUNT(DISTINCT c.customer_id)), যেটা আপনি কী পরিমাপ করতে চান তার ওপর নির্ভর করে।
RIGHT JOIN ডান টেবিলের সব সারি রাখে, এবং কেবল মিল পাওয়া বাম-টেবিলের সারিগুলো। যদি মিল না থাকে, বাম টেবিলের কলামগুলো NULL হবে। এটি মূলত LEFT JOIN-এর অন্য রূপ।
আমাদের উদাহরণ টেবিল ব্যবহার করে, ধরুন আপনি প্রতিটি পেমেন্ট তালিকাভুক্ত করতে চান, এমনকি যদি তা কোনো অর্ডারের সাথে জড়িত না হয় (হয়তো অর্ডার ডিলিট হয়েছে, বা পেমেন্ট ডেটা মেসি)।
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
ফলাফল:
payments ডানদিকে আছে)।o.order_id এবং o.customer_id NULL হবে।প্রায়ই RIGHT JOIN-কে আপনি টেবিলগুলোর ক্রম পাল্টে LEFT JOIN দিয়ে লিখে সমতুল্য ফল পাবেন:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
এটি একই ফল দেয়, কিন্তু অনেকেই পড়তে সুবিধা মনে করেন: আপনি প্রথমে "মেইন" টেবিল শুরু করেন (এখানে payments) এবং তারপর ঐ টেবিলের সাথে অতিরিক্ত ডেটা আনেন।
অনেক SQL স্টাইল গাইড RIGHT JOIN এড়াতে বলে কারণ এটি পাঠককে মানসিকভাবে সাধারণ প্যাটার্ন উল্টে দেখতে বাধ্য করে:
যখন ঐচ্ছিক সম্পর্কগুলো ধারাবাহিকভাবে LEFT JOIN হিসেবে লেখা থাকে, কুয়েরিগুলো দ্রুত স্ক্যান করা যায়।
যখন আপনি একটি বড় কুয়েরি সম্পাদনা করছেন এবং দেখেন যে ‘অবশ্যই থাকা’ টেবিলটি বর্তমানে ডান দিকে আছে, তখন পুরো কুয়েরি পুনরায় সাজানোর বদলে শুধু ঐ জয়েনটিকে RIGHT JOIN করা দ্রুত ও কম ঝুঁকিপূর্ণ হতে পারে।
FULL OUTER JOIN উভয় টেবিলের সব সারি ফেরত দেয়।
NULL হবে।NULL হবে।ক্লাসিক বিজনেস কেস হলো orders বনাম payments রেকনসিলিয়েশন:
উদাহরণ:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN সমর্থিত আছে PostgreSQL, SQL Server, এবং Oracle-এ।
এটি MySQL এবং SQLite-এ নেই (আপনাকে ওয়ার্কঅ্যারাউন্ড করতে হবে)।
যদি আপনার ডাটাবেস সরাসরি FULL OUTER JOIN সাপোর্ট না করে, আপনি এটি নকল করতে পারেন:
orders থেকে সব সারি (যেখানে সম্ভব পেমেন্ট মিল আছে) এবংpayments থেকে যেসব সারি অর্ডারের সাথে মেলে না সেগুলোএকটি সাধারণ প্যাটার্ন:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
টিপ: যখন আপনি এক পাশেই NULL দেখতে পান, সেটাই সিগন্যাল যে সারিটি অন্য টেবিলে অনুপস্থিত ছিল—ঠিক যেটা অডিট ও রেকনসিলিয়েশনের জন্য দরকার।
CROSS JOIN দুটি টেবিলের প্রতিটি সম্ভাব্য জোড় তৈরি করে ফেরত দেয়। যদি টেবিল A-তে 3 সারি এবং টেবিল B-তে 4 সারি থাকে, ফলাফল হবে 3 × 4 = 12 সারি। এটাকেই কার্টেসিয়ান প্রোডাক্ট বলা হয়।
এটা ভয়ানক শোনাতে পারে—এবং কিছু ক্ষেত্রে সেটা—কিন্তু যখন আপনি সত্যিই কম্বিনেশন চান তখন এটি ব্যবহারিক।
ধরুন আপনার প্রোডাক্ট অপশনগুলো আলাদা টেবিলে আছে:
sizes: S, M, Lcolors: Red, BlueCROSS JOIN সব সম্ভাব্য ভ্যারিয়েন্ট তৈরি করতে পারে (SKU তৈরি, ক্যাটালগ প্রি-বিল্ড, টেস্টিং):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
ফলাফল (3 × 2 = 6 সারি):
কারণ সারি সংখ্যা গুণিত হয়, CROSS JOIN খুব দ্রুত বিস্ফোরিত হতে পারে:
এটি কুয়েরি ধীর করে, মেমরি ওভারলোড করতে পারে, এবং এমন আউটপুট তৈরি করতে পারে যা কেউ কাজে লাগাতে না পারে। যদি কম্বিনেশন দরকার, ইনপুট টেবিলগুলো ছোট রাখুন এবং সীমা বা ফিল্টার যোগ করার কথা বিবেচনা করুন।
SELF JOIN ঠিক যেমনটি শোনায়: আপনি একই টেবিলকে নিজের সঙ্গে জয়েন করেন। যখন একটি টেবিলের এক সারি আরেক সারির সাথে সম্পর্কিত হয়—সবচেয়ে সাধারণভাবে কর্মচারী ও তাদের ম্যানেজার—তখন এটি দরকারি।
আপনি একই টেবিল দুইবার ব্যবহার করছেন বলে আপনাকে প্রতিটি “কপি”কে ভিন্ন অ্যলিয়াস দিতে হবে। অ্যলিয়াসগুলি কুয়েরিটিকে পড়তে সহজ করে এবং SQL-কে বলে আপনি কোন সাইডটি বুঝাচ্ছেন।
সাধারণ প্যাটার্ন:
e = employeem = managerধরুন employees টেবিলে আছে:
idnamemanager_id (অন্য employee id-কে পয়েন্ট করে)প্রতিটি কর্মচারীকে তাদের ম্যানেজারের নামসহ দেখাতে:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
উপরের কুয়েরি LEFT JOIN ব্যবহার করেছে, কারণ কিছু কর্মচারীর কোনো ম্যানেজার নাও থাকতে পারে (যেমন CEO)। এই ক্ষেত্রে manager_id প্রায়ই NULL থাকে, এবং LEFT JOIN ওই কর্মচারীর সারি বজায় রেখে manager_name-কে NULL দেখাবে।
যদি আপনি INNER JOIN ব্যবহার করতেন, টপ-লেভেল কর্মচারীরা ফলাফল থেকে হারিয়ে যাবে কারণ তাদের জন্য কোনো ম্যানেজার রো নেই।
JOIN "কিভাবে" দুটি টেবিল সম্পর্কিত তা স্পষ্টভাবে বলে—এটি জয়েন ক্লজেই থাকা উচিত কারণ এটি ব্যাখ্যা করে কীভাবে টেবিলগুলো মিলে, না কীভাবে আপনি শেষ ফলাফল ফিল্টার করবেন।
ON: সবচেয়ে ফ্লেক্সিবল ও সাধারণON ব্যবহার করুন যখন আপনি পুরো কন্ট্রোল চান—বিভিন্ন নামের কলাম, একাধিক শর্ত, বা অতিরিক্ত নিয়ম।
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON-এ আপনি জটিল ম্যাচিং (উদাহরণ: দুই কলামে মিল) নির্ধারণ করতে পারেন।
USING: সংক্ষিপ্ত, কিন্তু শুধু একই নামের কলামের জন্যকিছু ডাটাবেস (PostgreSQL, MySQL) USING সমর্থন করে। যখন দুই টেবিলে একই নামের কলাম থাকে এবং আপনি ঐ কলামে জয়েন করতে চান, USING শর্টহ্যান্ড সুবিধাজনক।
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
একটা ভাল দিক: USING সাধারণত আউটপুটে শুধু একটাই customer_id কলাম দেখায় (দুইটি কপি না করে)।
জয়েন করার পর অনেক কলাম নাম ওভারল্যাপ করে (id, created_at, status)। যদি আপনি SELECT id লিখেন, ডাটাবেস "ambiguous column" ত্রুটি ফেলতে পারে—অথবা খারাপ হলে আপনি ভুল id পড়ে ফেলতে পারেন।
স্পষ্টতার জন্য টেবিল প্রিফিক্স (অথবা অ্যলিয়াস) ব্যবহার করুন:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * এড়িয়ে চলুনজয়েনের সঙ্গে SELECT * দ্রুত বিশৃঙ্খল হয়: আপনি অপ্রয়োজনীয় কলাম টেনে আনেন, নামের ডুপ্লিকেশন ঘটে এবং কুয়েরির উদ্দেশ্য বোঝা কঠিন হয়।
এর বদলে নির্দিষ্ট কলামগুলোই সিলেক্ট করুন। রেজাল্ট ক্লিন থাকবে, মেইনটেইন করা সহজ হবে, এবং টেবিল যদি চওড়া হয় তখন কার্যকারিতাও সাধারণত ভাল হবে।
যখন আপনি টেবিল জয়েন করেন, WHERE এবং ON উভয়ই “ফিল্টার” করে, কিন্তু তারা ভিন্ন সময় এ কাজ করে।
এই টাইমিং পার্থক্যই মানুষকে ভুলবশত LEFT JOIN-কে INNER JOIN-এ বদলে দেয়ার কারণ।
ধরুন আপনি চান সব গ্রাহক, এমনকি যাদের সাম্প্রতিক পেইড অর্ডার নেই।
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
সমস্যা: যেসব গ্রাহকের কোনো মিলত অর্ডার নেই, তাদের o.status এবং o.order_date NULL থাকে। WHERE ক্লজ ঐ সারিগুলো বাতিল করে দেয়—ফলে আপনার LEFT JOIN কার্যত INNER JOIN হয়ে যায়।
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
এখন যোগ্য অর্ডার না থাকা গ্রাহকরাও (সাথে NULL অর্ডার কলাম) দেখা যাবে—এটাই সাধারণত LEFT JOIN-র উদ্দেশ্য।
WHERE o.order_id IS NOT NULL)।জয়েনগুলো শুধু কলাম যোগ করে না—এগুলো সারিও গুণিত করে। সেজন্য মোট যে হঠাৎ দ্বিগুণ হয়ে যায় সে ধরনের আচরণ বহুবার মানুষকে অবাক করে দেয়।
একটি আউটপুট সারি প্রতিটি ম্যাচিং রো-পেয়ারকে প্রতিনিধিত্ব করে।
customers-কে orders-এ জয়েন করলে প্রতিটি গ্রাহক তার প্রতিটি অর্ডারের জন্য একবার করে দেখা যাবে।orders-কে payments-এর সাথে জয়েন করেন এবং প্রতিটি অর্ডারের একাধিক পেমেন্ট থাকে, তাহলে এক অর্ডারের জন্য একাধিক আউটপুট সারি হবে। যদি আপনি আরও একটি “many” টেবিল (যেমন order_items) যোগ করেন, তাহলে payments × items করে বহু গুণ বৃদ্ধির সম্ভাবনা থাকে।আপনার লক্ষ্য যদি “প্রতি গ্রাহকের জন্য এক সারি” বা “প্রতি অর্ডারের জন্য এক সারি” হয়, তাহলে আগে many-পাশকে সারাংশ করে তারপর জয়েন করুন।
-- One row per order from payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
এভাবে জয়েনের আকৃতি predictable থাকে: একটি অর্ডার সারি একটিই থাকে।
SELECT DISTINCT ডুপ্লিকেটগুলোকে দেখে ঠিক করলেও এটি প্রকৃত সমস্যাকে লুকিয়ে রাখতে পারে:
আপনি যখন জানেন ডুপ্লিকেট সম্পূর্ণভাবে অনাকাঙ্খিত এবং কেন ঘটেছে তা নিশ্চিত তখনই এটি ব্যবহার করুন।
ফলাফলের উপর اعتماد করার আগে রো কাউন্ট মিলিয়ে দেখুন:
JOIN-কে প্রায়ই “ধীর কুয়েরি” বলা হয়, কিন্তু প্রকৃত সমস্যাটি সাধারণত কত ডেটা আপনি মিলাতে বলছেন এবং ডাটাবেস কত দ্রুত ম্যাচ খুঁজে পেতে পারে তা।
ইনডেক্সকে একটি বইয়ের টেবল-অফ-কনটেন্টস হিসেবে ভাবুন। এর ছাড়া, ডাটাবেসকে মিল খুঁজতে অনেক সারি স্ক্যান করতে হতে পারে। যদি জয়েন কী-তে (উদা: customers.customer_id ও orders.customer_id) ইনডেক্স থাকে, ডাটাবেস দ্রুত প্রাসঙ্গিক সারিতে যেতে পারে।
আপনাকে ইনটার্নাল কাজ জানার প্রয়োজন নেই: যদি কোন কলাম প্রায়ই ম্যাচিংয়ে ব্যবহৃত হয়, সেটি ইনডেক্স করা ভাল প্রার্থনা।
সম্ভব হলে স্থিতিশীল, ইউনিক আইডিতে জয়েন করুন:
customers.customer_id = orders.customer_idcustomers.email = orders.email বা customers.name = orders.nameনাম বদলে যেতে পারে এবং পুনরাবৃত্তি থাকতে পারে। ইমেল পরিবর্তিত হতে পারে বা অভাবে থাকতে পারে। ID-গুলো কনসিসটেন্ট ম্যাচিং-এর জন্য ডিজাইন করা হয় এবং সাধারণত ইনডেক্স করা থাকে।
দুইটি অভ্যাস JOIN-কে দ্রুত করে:
SELECT * এড়িয়ে চলুন—অতিরিক্ত কলাম মেমরি ও নেটওয়ার্ক ব্যবহার বাড়ায়।উদাহরণ: আগে অর্ডারগুলো সীমাবদ্ধ করে তারপর জয়েন:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
যদি আপনি এই কুয়েরি অ্যাপের একটি রিপোর্টিং পেজে (উদাহরণ: PostgreSQL ব্যাক করা) ব্যবহার করে যাচাই বা কাজ করে থাকেন, টুলগুলো (যেমন Koder.ai) স্ক্যাফোল্ডিং দ্রুত করতে পারে—স্কিমা, এন্ডপয়েন্ট, UI—কিন্তু জয়েন লজিকের সঠিকতা আপনার হাতেই থাকবে।
NULL)NULL যখন অনুপস্থিত)NULLএকটি SQL JOIN দুটি (বা আরও) টেবিলের সারিগুলোকে একটি রেজাল্ট সেটে মিলিয়ে আনে, সাধারণত একটি প্রাইমারি কী থেকে ফরেন কী তে মিলিয়ে (উদাহরণ: customers.customer_id = orders.customer_id)। এটি নরমালাইজড টেবিলগুলোকে রিপোর্ট, অডিট বা বিশ্লেষণের জন্য পুনরায় সংযুক্ত করার উপায়।
যখন আপনি কেবল এমন সারি চান যেগুলোর সম্পর্ক উভয় টেবিলে উপস্থিত আছে তখন INNER JOIN ব্যবহার করুন।
এটি “নিশ্চিত সম্পর্ক” দেখানোর জন্য উপযুক্ত — যেমন কেবল সেই গ্রাহকরা যাঁরা Orders করেছেন।
যখন আপনার প্রধান (বাম) টেবিলের সব সারি দরকার এবং ডান দিকের টেবিল থেকে মিল পাওয়া গেলে সেটি যোগ করতে চান তখন LEFT JOIN ব্যবহার করুন।
“মিসিং ম্যাচ” খুঁজতে নিম্নরূপ লিখে ডান পাশে NULL ফিল্টার করুন:
SELECT c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN ডান টেবিলের প্রতিটি সারি রাখে এবং বাম টেবিলের কেবল মিল পাওয়া সারিগুলো রাখে; মেলে না এমন ক্ষেত্রে বাম টেবিলের কলামগুলো NULL হবে। অনেক দল এটাকে এড়ায় কারণ এটি “উল্টো” পড়ে।
অধিকাংশ ক্ষেত্রে আপনি টেবিলের ক্রম বদলে করে LEFT JOIN ব্যবহার করে সমান ফলাফল পাবেন:
FROM payments p
orders o o.order_id p.order_id
FULL OUTER JOIN reconciliation-এর জন্য আদর্শ: আপনি মিলে যাওয়া সারি, বাম-ইনডেক্সে থাকা কিন্তু ডান-ইনডেক্সে না থাকা সারি, এবং ডান-ইনডেক্সে থাকা কিন্তু বাম-ইনডেক্সে না থাকা সারি—সবই এক সাথে দেখতে পারেন।
অনমনীয় ব্যাপারে (যেমন “অর্ডার আছে কিন্তু পেমেন্ট নেই” এবং “পেমেন্ট আছে কিন্তু অর্ডার নেই”) এটি বিশেষভাবে উপযোগী কারণ অনুপস্থিত পাশের কলামগুলো NULL দেখাবে।
MySQL এবং SQLite-এ সরাসরি FULL OUTER JOIN থাকে না। সাধারণ সমাধান হল দুটি প্রশ্নকে UNION দিয়ে যুক্ত করা:
orders LEFT JOIN paymentsসেটি (বা সহ সতর্ক ফিল্টারিং) ব্যবহার করে করা হয় যাতে বাম-অর্থাৎ এবং ডান-অর্থাৎ একক সারিগুলো ধরা পরে।
CROSS JOIN দুই টেবিলের প্রতিটি সম্ভাব্য কম্বিনেশন ফেরত দেয় (কার্টেসিয়ান প্রোডাক্ট)। এটি সাইজ × কালার-এর মতো সিচুয়েশনে দরকারি হতে পারে বা ক্যালেন্ডার গ্রিড বানাতে সহায়ক।
সতর্ক থাকুন: সারি সংখ্যা দ্রুত বাড়ে, তাই ইনপুট টেবিলগুলো ছোট এবং নিয়ন্ত্রিত না হলে আউটপুট বিস্ফোরিত হয়ে যাবে।
SELF JOIN হলো একই টেবিলকে নিজেই join করা — ব্যবহার হয় যখন একটি টেবিলের একটি সারি আরেকটি সারির সাথে সম্পর্কিত (যেমন কর্মচারী → ম্যানেজার)।
আপনাকে আলিয়াস ব্যবহার করতে হবে যাতে SQL-এ দুইটি কপি পৃথকভাবে বোঝানো যায়:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON join চলাকালীন কীভাবে সারিগুলো ম্যাচ করবে তা নির্ধারণ করে; WHERE join শেষ হয়ে যাওয়ার পর সম্পূরক ফিল্টার করে। LEFT JOIN-এ ডান টেবিলের উপর WHERE শর্ত বসালে অনিচ্ছাকৃতভাবে LEFT JOIN-কে INNER JOIN-এ পরিণত করা যেতে পারে।
যদি আপনি সকল বাম সারি রাখতে চান কিন্তু ডান সারিগুলোকে সীমাবদ্ধ করতে চান, তাহলে সেই ডান-টেবিল সম্পর্কিত শর্তগুলো -এ রাখুন।
জয়েন ব্যবহার করে সারিগুলো গুণিত হলে তা ডুপ্লিকেট তৈরি করে — বিশেষত one-to-many বা many-to-many কেসে। উদাহরণ: একটি অর্ডারের দুইটি পেমেন্ট থাকলে orders JOIN payments করলে ঐ অর্ডারটি দুই বার দেখাবে।
এটা এড়াতে “many” সাইড আগে aggregate করুন (উদা: SUM(amount) গ্রুপ করে), তারপর যোগ করুন। DISTINCT শুধুমাত্র শেষ প্রহর হিসেবে ব্যবহার করুন কারণ তা প্রকৃত সমস্যা লুকাতে পারে এবং টোটাল ভাঙাতে পারে।
UNIONUNION ALLON