১৫ জুন, ২০২৫·8 মিনিট
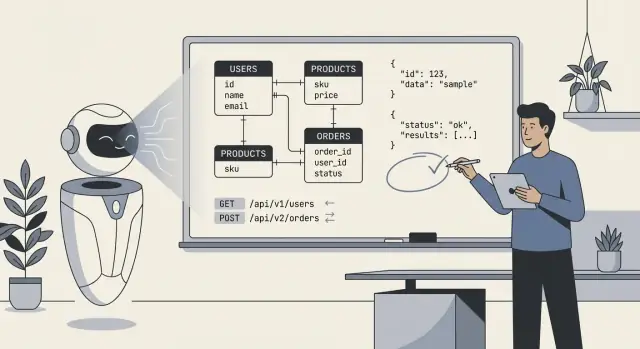
এআইকে ব্যাকএন্ড স্কিমা, এপিআই এবং ডেটা মডেল ডিজাইন করতে দেওয়া
এআই-জেনারেটেড স্কিমা ও এপিআই কিভাবে ডেলিভারি দ্রুত করে, কোথায় ব্যর্থ হয়, এবং ব্যাকএন্ড ডিজাইন পর্যালোচনা, টেস্ট এবং গভর্ন করার জন্য বাস্তব কর্মপ্রবাহ।
এআই-জেনারেটেড স্কিমা ও এপিআই কিভাবে ডেলিভারি দ্রুত করে, কোথায় ব্যর্থ হয়, এবং ব্যাকএন্ড ডিজাইন পর্যালোচনা, টেস্ট এবং গভর্ন করার জন্য বাস্তব কর্মপ্রবাহ।
যখন বলা হয় “এআই আমাদের ব্যাকএন্ড ডিজাইন করেছে,” সাধারণত এর অর্থ মডেলটি মূল টেকনিক্যাল ব্লুপ্রিন্টের একটি প্রথম খসড়া তৈরি করেছে: ডাটাবেস টেবিল (বা কালেকশন), তাদের সম্পর্ক, এবং যে এপিআইগুলো ডেটা পড়ে/লেখে। বাস্তবে, এটি কম "এআই সবকিছু তৈরি করেছে" এবং বেশি "এআই এমন একটি স্ট্রাকচার প্রস্তাব করেছে যা আমরা বাস্তবায়ন ও পরিমার্জন করতে পারি।"
কমপক্ষে, AI নিম্নগুলো জেনারেট করতে পারে:
users, orders, subscriptions-এর মতো টেবিল/কলেকশন, সাথে ফিল্ড ও মৌলিক টাইপ।AI সাধারণ "টিপিক্যাল" প্যাটার্ন অনুমান করতে পারে, কিন্তু যখন প্রয়োজনগুলো অস্পষ্ট বা ডোমেইন-নির্দিষ্ট হয়, সঠিক মডেল বাছাই করা নির্ভরযোগ্যভাবে করতে পারে না। এটি জানে না আপনার প্রকৃত পলিসিগুলি:
cancelled বনাম refunded বনাম voided)AI আউটপুটকে দ্রুত, কাঠামোগত শুরুর বিন্দু হিসেবে বিবেচনা করুন—বিকল্প অন্বেষণে ও ত্রুটিগুলি ধরতে উপযোগী—কিন্তু এটি এমন একটি স্পেসিফিকেশন নয় যা আপনি অচিন্ত্যভাবে প্রোডাকশনে পাঠাতে পারেন। আপনার কাজ হল স্পষ্ট নিয়ম ও এজ-কেস সরবরাহ করা, তারপর AI যা তৈরি করেছে তা একইভাবে পর্যালোচনা করা যেমন আপনি জুনিয়র ইঞ্জিনিয়ারের প্রথম খসড়া দেখতেন: সহায়ক, মাঝে মাঝে প্রভাৱশালী, কিন্তু সূক্ষ্ম ভুল থাকতে পারে।
AI দ্রুত একটি স্কিমা বা API খসড়া করতে পারে, কিন্তু এমন অনুপস্থিত তথ্যগুলো আবিষ্কার করতে পারে না যেগুলো একটি ব্যাকএন্ডকে আপনার প্রোডাক্টের সাথে “ফিট” করে তোলে। সেরা ফলাফল আসে যখন আপনি AI-কে একটি দ্রুত জুনিয়র ডিজাইনার হিসাবে ব্যবহার করেন: আপনি স্পষ্ট কনস্ট্রেইন্ট দেবেন, এবং এটি বিকল্প প্রস্তাব করবে।
টেবিল, এন্ডপয়েন্ট বা মডেল চাওয়ার আগে, নিম্নগুলো লিখে রাখুন:
চাহিদা অনিশ্চিত হলে AI ডিফল্ট অনুমান করে: সর্বত্র অপশনাল ফিল্ড, সাধারণ স্ট্যাটাস কলাম, অস্পষ্ট মালিকানা, ও অনিয়মিত নামকরণ। ফলে স্কিমাগুলো প্রথমদৃষ্টিতে যুক্তিযুক্ত দেখাতে পারে কিন্তু বাস্তব ব্যবহারের সময়—বিশেষ করে পারমিশন, রিপোর্টিং, ও এজ-কেস (রিফান্ড, ক্যানসেলেশন, আংশিক শিপমেন্ট, মাল্টি-স্টেপ অনুমোদন)—ভঙ্গুর প্রমাণিত হয়। পরে এর জন্য মাইগ্রেশন, ওয়ার্কঅ্যারাউন্ড, ও বিভ্রান্তিকর API-রূপে মূল্য দিতে হবে।
প্রম্পটে এটা পেস্ট করে শুরু করুন:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
(উপরের fenced ব্লকটি কোড ব্লক—তার মধ্যে থাকা টেক্সট অপরিবর্তিত রাখুন)।
AI দ্রুত খসড়া তৈরি করার ক্ষেত্রে সেরা: এটি মিনিটের মধ্যে একটি যুক্তিযুক্ত প্রথম-ধাপ ডেটা মডেল এবং মিলানযোগ্য এন্ডপয়েন্ট সেট স্কেচ করতে পারে। এই গতি কাজের ধরণ বদলে দেয়—না যে আউটপুট জাদুকরীভাবে সঠিক, বরং আপনি তাত্ক্ষণিকভাবে একটি কংক্রিট ভিত্তির উপর পুনরাবৃত্তি করতে পারেন।
সবচেয়ে বড় লাভ হল কোল্ড স্টার্ট নির্মূল করা। AI-কে সংক্ষিপ্ত এন্টিটি বিবরণ, প্রধান ইউজার ফ্লো এবং কনস্ট্রেইন্ট দিন, এবং এটি টেবিল/কলেকশন, সম্পর্ক ও বেসলাইন API সারফেস প্রস্তাব করতে পারবে। ডেমো ত্বরান্বিত করতে বা অনিশ্চিত প্রয়োজনীয়তা এক্সপ্লোর করতে এটি বিশেষভাবে মূল্যবান।
গতি সবচেয়ে উপকারী যেখানে:
মানুষ ক্লান্ত হয়ে ড্রিফ্ট করে; AI করে না—তাই এটি সম্পূর্ণ ব্যাকএন্ড জুড়ে কনভেনশান রিপিট করতে ভালো:
createdAt, updatedAt, customerId)/resources, /resources/:id) ও পে-লোডএই ধারাবাহিকতা ডকুমেন্টেশন, টেস্টিং ও হ্যান্ড-অফ সহজ করে।
AI সম্পূর্ণতার দিকেও ভালো: আপনি যদি একটি পূর্ণ CRUD সেট ও সাধারণ অপারেশন (সার্চ, লিস্ট, বাল্ক আপডেট) চান, এটি সাধারণত দ্রুত একটি বিস্তৃত স্টার্টিং সারফেস জেনারেট করে—প্রায়ই দ্রুত মানুষের রাশিটিক খসড়ার চেয়ে সম্পূর্ণ।
একটি সাধারণ দ্রুত বিজয় হল স্ট্যান্ডার্ডাইজড এরর: সার্বত্র একটি এরর এনভেলপ (code, message, details)। পরবর্তীতে আপনি এটি পরিমার্জন করলেও, শুরুতে এক রূপ থাকা মিশ্র-অভিস্কারের ঝুঁকি কমায়।
কী মানসিকতা: AI প্রথম ৮০% দ্রুত তৈরি করুক, আপনার সময় ব্যয় করুন সেই ২০%-এ যা বিচার দরকার—ব্যবসায়িক নিয়ম, এজ‑কেস, এবং মডেলের "কেন"।
AI-জেনারেটেড স্কিমা প্রথমদৃষ্টিতে “পরিষ্কার” দেখায়: পরিমার্জিত টেবিল, যৌক্তিক নাম, এবং হ্যাপি পাথে মিলমান সম্পর্ক। সমস্যা দেখা দেয় যখন বাস্তব ডেটা, ব্যবহারকারী, এবং বাস্তব ওয়ার্কফ্লো সিস্টেমে আঘাত করে।
AI দুইদিকে ঝুঁকতে পারে:
দ্রুত গন্ধ পরীক্ষা: যদি আপনার সাধারণ পেজগুলি ৬+ জয়েন প্রয়োজন করে, আপনি ওভার-নর্মালাইজড হতে পারেন; যদি আপডেটে একই মান অনেক সারিতে পরিবর্তন করতে হয়, আপনি আন্ডার-নর্মালাইজড হতে পারেন।
AI প্রায়ই “বোরিং” নিয়মগুলো বাদ দেয় যা বাস্তব ব্যাকএন্ড ডিজাইন নির্ধারণ করে:
tenant_id ভুলে যাওয়া, বা ইউনিক কনস্ট্রেইন্টে টেন্যান্ট স্কোপিং না করা।deleted_at যোগ করা কিন্তু ইউনিকনেস বা কোয়েরি প্যাটার্ন আপডেট না করা।created_by/updated_by, পরিবর্তনের ইতিহাস, অথবা অপরিবর্তনীয় ইভেন্ট লগ অনুপস্থিত।date ও timestamp মিশ্রিত করা, স্পষ্ট নীতি (UTC-এ স্টোর vs লোকাল ডিসপ্লে) না থাকা, ফলে off-by-one-day বাগ।AI অনুমান করতে পারে:
এই ত্রুটিগুলো সাধারণত বিব্রতকর মাইগ্রেশন ও অ্যাপ্লিকেশন-সাইড ওয়ার্কঅ্যারাউন্ড হিসেবে প্রকাশ পায়।
অনেকে জেনারেটেড স্কিমা কিভাবে কুয়েরি করা হবে তা প্রতিফলিত করে না:
tenant_id + created_at)যদি মডেল আপনার টপ ৫ কুয়েরি বর্ণনা না করতে পারে, এটি সেগুলোর জন্য নির্ভরযোগ্যভাবে ডিজাইন করতে পারবে না।
AI প্রায়ই এমন একটি API তৈরি করে যা “স্ট্যান্ডার্ড দেখতে” পারে। এটি জনপ্রিয় ফ্রেমওয়ার্ক ও পাবলিক API-র পরিচিত প্যাটার্ন অনুকরণ করে—যা সময় বাঁচায়। ঝুঁকি হল এটি যা বাস্তভিকভাবে আপনার প্রোডাক্ট, ডেটা মডেল ও ভবিষ্যৎ পরিবর্তনের জন্য সঠিক তার চেয়ে যা সম্ভবত দেখায় তা অপ্টিমাইজ করতে পারে।
রিসোর্স মডেলিং বেসিক্স। স্পষ্ট ডোমেইন দিলে AI যুক্তিযুক্ত নাম ও URL স্ট্রাকচার বেছে নেয় (যেমন /customers, /orders/{id}, /orders/{id}/items) এবং এন্ডপয়েন্ট জুড়ে ধারাবাহিক নামকরণ রাখে।
কমন এন্ডপয়েন্ট স্ক্যাফোল্ডিং। AI সাধারণত লিস্ট বনাম ডিটেইল, create/update/delete অপারেশন, এবং পূর্বানুমানযোগ্য রিকোয়েস্ট/রেসপন্স আকার অন্তর্ভুক্ত করে।
বেসলাইন কনভেনশন। আপনি স্পষ্টভাবে চাইলে এটি পেজিনেশন, ফিল্টারিং, ও সর্টিং স্ট্যান্ডার্ডাইজ করতে পারে—উদাহরণ: ?limit=50&cursor=... (কার্সার পেজিনেশন) অথবা ?page=2&pageSize=25 (পেজ-ভিত্তিক), সাথে ?sort=-createdAt এবং ?status=active মত ফিল্টার।
লিকি অ্যাবস্ট্র্যাকশন। একটি ক্লাসিক ত্রুটি হল ইন্টারনাল টেবিল সরাসরি “রিসোর্স” হিসেবে প্রকাশ করা, বিশেষত যখন স্কিমায় join টেবিল, ডিনরমালাইজড ফিল্ড, বা অডিট কলাম আছে। ফলে আপনি এমন এন্ডপয়েন্ট পেতে পারেন যেমন /user_role_assignments যা বাস্তবে ব্যবহারকারীর মানসিক মডেলকে প্রতিফলিত করে না (“user-এর জন্য role”)। এটি API-কে ব্যবহার করা কঠিন ও পরে পরিবর্তন করা কঠিন করে দেয়।
অসামঞ্জস্যপূর্ণ এরর হ্যান্ডলিং। AI মিলিত শৈলী ব্যবহার করতে পারে: কখনও 200 দিয়ে এরর বডি, কখনও 4xx/5xx। একটি পরিষ্কার কনট্রাক্ট চাই:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })ভার্সনিংকে ভাবা পরে করা। অনেক AI-জেনারেটেড ডিজাইন ভার্সনিং স্ট্র্যাটেজি বাদ দেয় যতক্ষণ না ব্যথা হয়ে ওঠে। প্রথম দিনেই সিদ্ধান্ত নিন আপনি path-versioning (/v1/...) ব্যবহার করবেন নাকি হেডার-ভিত্তিক ভার্সনিং, এবং কী পরিবর্তন ব্রেকিংভাবে বিবেচিত হবে। এমনকি যদি আপনি কখনও ভার্সন না বাড়ান, নিয়মগুলো থাকলে দুর্ঘটনাচার্যিক প্রভেদ রোধ করে।
AI-কে গতি ও ধারাবাহিকতার জন্য ব্যবহার করুন, কিন্তু API ডিজাইনকে একটি প্রোডাক্ট ইন্টারফেস হিসেবে বিবেচনা করুন। যদি কোনো এন্ডপয়েন্ট আপনার ডাটাবেস-কে প্রতিফলিত করে ব্যবহারকারীর মানসিক মডেল না, তাহলে AI সহজভাবে জেনারেট করা—দীর্ঘমেয়াদী ব্যবহারযোগ্যতার জন্য ভাল নয়।
AI-কে দ্রুত জুনিয়র ডিজাইনার হিসাবে বিবেচনা করুন: খসড়া তৈরিতে দারুণ, চূড়ান্ত সিস্টেমের দািয়িত্ব নয়। লক্ষ্য হল এর গতি ব্যবহার করা, কিন্তু আর্কিটেকচার সচেতন, পর্যালোযোগ্য এবং টেস্ট-চালিত রাখা।
যদি আপনি Koder.ai এর মতো ভিব-কোডিং টুল ব্যবহার করেন, এই দায়িত্ব বিভাজন আরও গুরুত্বপূর্ণ: প্ল্যাটফর্ম দ্রুত ব্যাকএন্ড (উদাহরণ: Go সার্ভিস + PostgreSQL) খসড়া ও বাস্তবায়ন করতে পারে, কিন্তু আপনাকে ইনভারিয়েন্ট, অথরাইজেশন সীমানা, এবং মাইগ্রেশন নিয়ম নির্ধারণ করতে হবে।
কঠোর প্রম্পট দিয়ে শুরু করুন যা ডোমেইন, কনস্ট্রেইন্ট, এবং “সাফল্য কেমন দেখায়” ব্যাখ্যা করে। প্রথমে একটি ধারণাগত মডেল (এন্টিটি, সম্পর্ক, ইনভারিয়েন্ট) চান—টেবিল নয়।
তারপর এই নির্দিষ্ট লুপে কাজ করুন:
এই লুপ কাজ করে কারণ এটি “AI প্রস্তাব” কে এমন আর্টিফ্যাক্টে পরিণত করে যা প্রমাণিত বা প্রত্যাখ্যাত করা যায়।
তিনটি লেয়ার আলাদা রাখুন:
AI-কে অনুরোধ করুন এই তিনটিকে আলাদা অংশ হিসেবে আউটপুট দিতে। যখন কিছু পরিবর্তন হবে (যেমন একটি নতুন স্ট্যাটাস), প্রথমে ধারণাগত স্তর আপডেট করুন, তারপর স্কিমা ও API মিলান করুন। এতে আকস্মিক কাপলিং কমে এবং রিফ্যাক্টর সহজ হয়।
প্রতিটি ইটারেশন একটি ট্রেইল রাখুক। ছোট ADR-স্টাইল সারাংশ ব্যবহার করুন (এক পৃষ্ঠা বা কম) যা ধারণ করে:
deleted_at”)।আপনি যখন AI-তে ফিডব্যাক পেস্ট করবেন, সংশ্লিষ্ট সিদ্ধান্ত নোটগুলো সরাসরি অন্তর্ভুক্ত করুন—এটি মডেলকে পূর্বের পছন্দগুলি "ভুলে যাওয়া" থেকে রোধ করে এবং দলের জন্য মাস পরে বোঝা সহজ করে।
AI-কে স্টিয়ার করা সহজ যখন আপনি প্রম্পটকে একটি স্পেসিফিকেশন লেখার অনুশীলনের মতো বিবেচনা করবেন: ডোমেইন নির্ধারণ করুন, কনস্ট্রেইন্ট বলুন, এবং কনক্রিট আউটপুট দাবি করুন (DDL, এন্ডপয়েন্ট টেবিল, উদাহরণ)। লক্ষ্য হচ্ছে “সৃজনশীল হও” নয়—লক্ষ্য হচ্ছে “নির্দিষ্ট হও।”
ডেটা মডেল এবং এটিকে সঙ্গত রাখার নিয়ম চাইবেন।
আপনার কনভেনশন থাকে বলুন: নামকরণ স্টাইল, ID টাইপ (UUID vs bigint), nullable নীতি, এবং ইনডেক্সিং প্রত্যাশা।
শুধু রুটের তালিকা নয়, একটি API টেবিল দাবী করুন।
ব্যবসায়িক আচরণ যোগ করুন: পেজিনেশন স্টাইল, সর্টিং ফিল্ড, এবং ফিল্টারিং কিভাবে কাজ করে।
মডেলকে রিলিজ ভিত্তিকভাবে ভাবান।
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field.”অস্পষ্ট প্রম্পট অস্পষ্ট সিস্টেম দেয়:
আপনি যখন ভালো আউটপুট চান, প্রম্পট কড়া করুন: নিয়ম, এজ-কেস, এবং ডেলিভারেবল ফরম্যাট নির্দিষ্ট করুন।
AI একটি স্বীকৃত ব্যাকএন্ড খসড়া তৈরি করতে পারে, কিন্তু নিরাপদভাবে চালানোর আগে মানবিক যাচাই এখনও প্রয়োজন। এই চেকলিস্টটিকে একটি “রিলিজ গেট” হিসেবে বিবেচনা করুন: আপনি যদি কোনো আইটেম আত্মবিশ্বাসের সাথে উত্তর করতে না পারেন, থামুন এবং প্রোডাকশন ডেটা হওয়ার আগে তা ঠিক করুন।
(tenant_id, slug))।_id সাফিক্স, টাইমস্ট্যাম্প) এবং সম্মিলিতভাবে প্রয়োগ করুন।সিস্টেমের নিয়মগুলি লিখে নিশ্চিত করুন:
মার্জ করার আগে একটি দ্রুত “হ্যাপি পাথ + ওরস্ট পাথ” রিভিউ চালান: একটি সাধারণ অনুরোধ, একটি অবৈধ অনুরোধ, একটি অননুমোদিত অনুরোধ, এবং একটি উচ্চ-ভলিউম সিনারিও। যদি API আচরণ আপনাকে অবাক করে, এটি ব্যবহারকারীকেও অবাক করবে।
AI একটি যুক্তিযুক্ত স্কিমা ও API সারফেস দ্রুত তৈরি করতে পারে, কিন্তু এটি প্রমাণ করতে পারে না যে ব্যাকএন্ড বাস্তব ট্র্যাফিক, বাস্তব ডেটা, এবং ভবিষ্যৎ পরিবর্তনে সঠিকভাবে আচরণ করবে। AI আউটপুটকে একটি খসড়া হিসেবে বিবেচনা করুন এবং টেস্ট দিয়ে এটিকে লক করুন।
রিকুয়েস্ট, রেসপন্স, ও এরর সেম্যান্টিক্স যাচাই করা কনট্রাক্ট টেস্ট দিয়ে শুরু করুন—শুধু হ্যাপি পাথ নয়। একটি ছোট সুইট তৈরি করুন যা বাস্তব ইনস্ট্যান্স (বা কনটেইনার) বিরুদ্ধে চলে।
ফোকাস:
আপনি যদি OpenAPI স্পেক প্রকাশ করেন, স্পেক থেকে টেস্ট জেনারেট করুন—কিন্তু স্পেক প্রকাশ করতে না পারা জটিল অংশ (অথরাইজেশন নিয়ম, ব্যবসায়িক কনস্ট্রেইন্ট) এর জন্য হাতে লেখা কেস যোগ করুন।
AI-জেনারেটেড স্কিমা প্রায়ই অপারেশনাল ডিটেইলস মিস করে: সেফ ডিফল্ট, ব্যাকফিল, এবং উল্টাতে পারার পরিকল্পনা। মাইগ্রেশন টেস্ট যোগ করুন যা:
প্রোডাকশনের জন্য একটি স্ক্রিপ্টেড রোলব্যাক পরিকল্পনা রাখুন: যদি মাইগ্রেশন ধীর হয়, টেবিল লক করে, বা কম্প্যাটিবিলিটি ভাঙে কী করবেন।
সাধারণ এন্ডপয়েন্টের উপর বেঞ্চমার্ক না করুন। প্রতিনিধিত্বশীল কুয়েরি প্যাটার্ন (শীর্ষ লিস্ট ভিউ, সার্চ, জয়েন, অ্যাগ্রিগেশন) ধরুন এবং সেগুলোর ওপর লোড টেস্ট চালান।
মাপুন:
এখানেই AI-র ডিজাইন সাধারণত ব্যর্থ হয়: “যুক্তিযুক্ত” টেবিলগুলো লোডে ব্যয়বহুল জয়েন উত্পন্ন করে।
স্বয়ংক্রিয় পরীক্ষাগুলো যোগ করুন যেগুলো চেক করে:
এই মৌলিক সিকিউরিটি টেস্টগুলো AI-র সবচেয়ে খরচসাপেক্ষ ভুলগুলো—এন্ডপয়েন্টগুলো কাজ করে কিন্তু অনেক কিছু প্রকাশ করে—রোধ করে।
AI একটি ভাল “ভার্সন 0” স্কিমা খসড়া করতে পারে, কিন্তু আপনার ব্যাকএন্ড ভার্সন ৫০-এর মধ্য দিয়ে বাঁচবে। একটি ব্যাকএন্ড যা ভালোভাবে বুড়ো হবে এবং একটি যা পরিবর্তনের সাথে ভেঙে পড়বে—এর মধ্যে পার্থক্য হল কিভাবে আপনি এটি বিবর্ধন করেন: মাইগ্রেশন, নিয়ন্ত্রিত রিফ্যাক্টর, এবং উদ্দেশ্যের স্পষ্ট ডকুমেন্টেশন।
প্রতি স্কিমা পরিবর্তনকেই মাইগ্রেশন হিসেবে বিবেচনা করুন, এমনকি AI বললেও "শুধু টেবিল alter করুন"। স্পষ্ট, উল্টানো যোগ্য ধাপ ব্যবহার করুন: প্রথমে নতুন কলাম যোগ করুন, ব্যাকফিল করুন, তারপর কনস্ট্রেইন্ট শক্ত করুন। অতিরিক্ত পরিবর্তনের (নাম পরিবর্তন/ড্রপ) থেকে বিরত থাকুন যতক্ষণ না নিশ্চিত হোন পুরোনো আকৃতি কোনো ডিপেন্ডেন্সি রাখে না।
যখন আপনি AI-কে স্কিমা আপডেট চাইবেন, বর্তমান স্কিমা এবং আপনার মাইগ্রেশন নিয়ম (উদাহরণ: “কলাম ড্রপ না করা; expand/contract”) অন্তর্ভুক্ত করুন—এটি AI-কে এমন প্রস্তাব করা থেকে রোধ করে যা তত্ত্বগতভাবে সঠিক কিন্তু প্রোডাকশনে ঝুঁকিপূর্ণ।
ব্রেকিং পরিবর্তনরা সাধারণত এক মুহূর্তের ঘটনা না; তারা একটি ট্রানজিশন।
AI SQL স্নিপেট ও রোলআউট অর্ডার প্রস্তাব করতে সহায়ক, কিন্তু রানটাইম প্রভাব যাচাই করা আপনার দায়িত্ব: লক, দীর্ঘ র্আশণ৷ এবং ব্যাকফিল পুনরায় চালু করা যাবে কি না তা দেখা।
রিফ্যাক্টরিংয়ের উদ্দেশ্য হওয়া উচিত পরিবর্তনকে বিচ্ছিন্ন করা। যদি আপনাকে নর্মালাইজ করতে, একটি টেবিল বিভক্ত করতে, বা ইভেন্ট লগ পরিচয় করাতে হয়, সমতুল্য Compat লেয়ার রাখুন: ভিউ, ট্রান্সলেশন কোড, বা “শ্যাডো” টেবিল। AI-কে এমন একটি রিফ্যাক্টর প্রস্তাব করতে বলুন যা বিদ্যমান API কনট্রাক্ট বজায় রাখে, এবং তালিকা বানাতে বলুন কী কী কুয়েরি, ইনডেক্স এবং কনস্ট্রেইন্ট বদলাতে হবে।
দীর্ঘমেয়াদী ড্রিফট সবচেয়ে বেশি হয় কারণ পরবর্তী প্রম্পট মূল উদ্দেশ্য ভুলে যায়। একটি ছোট “ডেটা মডেল কনট্রাক্ট” ডকুমেন্ট রাখুন: নামকরণ নিয়ম, ID স্ট্র্যাটেজি, টাইমস্ট্যাম্প সেমান্টিক্স, সফট-ডিলিট নীতি, এবং ইনভারিয়েন্টস (“অর্ডার টোটাল নির্ধারিত, স্টোর করা নয়”)। এটি আপনার অভ্যন্তরীণ ডক্সে (/docs/data-model) লিংক করুন এবং ভবিষ্যৎ AI প্রম্পটগুলোতে পুনঃব্যবহার করুন যাতে সিস্টেম একই সীমানার মধ্যে ডিজাইন করে।
AI দ্রুত টেবিল ও এন্ডপয়েন্ট খসড়া করতে পারে, কিন্তু এটি আপনার ঝুঁকি ধারণ করে না। নিরাপত্তা ও গোপনীয়তাকে প্রথম শ্রেণীর প্রয়োজন হিসেবে প্রম্পটে যোগ করুন, তারপর পর্যালোচনায় যাচাই করুন—বিশেষত সংবেদনশীল ডেটা সংক্রান্ত অংশে।
কোনো স্কিমা গ্রহণ করার আগে ফিল্ডগুলোকে সংবেদনশীলতার উপর লেবেল করুন (public, internal, confidential, regulated)। সেই শ্রেণীবিভাগ নির্ধারণ করবে কী এনক্রিপ্ট করা হবে, কী মাস্ক করা হবে বা কী মিনিমাইজ করতে হবে।
উদাহরণ: পাসওয়ার্ড কখনই সংরক্ষণ করা যাবে না (শুধু সল্টেড হ্যাশ), টোকেনগুলো সংক্ষিপ্তকালীন এবং অ্যাট-রেস্ট এনক্রিপ্টেড, ও PII (ইমেইল/ফোন) অ্যাডমিন ভিউ ও এক্সপোর্টে মাস্ক করা দরকার হতে পারে। যদি কোনো ফিল্ড প্রোডাক্ট ভ্যালু দেয় না, সংরক্ষণ করবেন না—AI প্রায়ই এমন "নাইস টু হ্যাভ" অ্যাট্রিবিউট যোগ করে যা এক্সপোজার বাড়ায়।
AI-জেনারেটেড API প্রায়ই সরল “রোল চেক” ডিফল্ট করে। RBAC সহজ বোঝার জন্য ভাল, কিন্তু ওনার্শিপ নিয়ম ("ইউজাররা কেবল নিজেদের ইনভয়েস দেখতে পাবে") বা কনটেক্সটাল নিয়মে ("সাপোর্ট কেবল সক্রিয় টিকিটের সময় ডেটা দেখতে পারবে") ভেঙে যায়। ABAC এইগুলো ভালোভাবে পরিচালনা করে, কিন্তু স্পষ্ট পলিসি দরকার।
আপনি যে প্যাটার্ন ব্যবহার করবেন তা স্পষ্ট করুন, এবং নিশ্চিত করুন প্রতিটি এন্ডপয়েন্ট ধারাবাহিকভাবে তা প্রয়োগ করে—বিশেষত লিস্ট/সার্চ এন্ডপয়েন্ট, যা সাধারণ তথ্য ফাঁসের পয়েন্ট।
জেনারেটেড কোড ডিফল্টভাবে পূর্ণ রিকোয়েস্ট বডি, হেডার, বা DB সারি লগ করতে পারে। এতে পাসওয়ার্ড, অথ টোকেন, এবং PII লগ হয়ে যেতে পারে। ডিফল্ট ঠিক করুন:
শুরুর দিন থেকেই ডিলিশনের জন্য ডিজাইন করুন: ব্যবহারকারী-অনুরোধকৃত ডিলিট, অ্যাকাউন্ট ক্লোজার, এবং “ওপেন-টু-ভে-ফরগট” কার্যপ্রবাহ। ডেটা ক্লাস অনুযায়ী রিটেনশন উইন্ডো নির্ধারণ করুন (উদাহরণ: অডিট ইভেন্ট বনাম মার্কেটিং ইভেন্ট), এবং প্রমাণযোগ্যভাবে কী মুছে গেছে ও কখন মুছে গেছে সেটি দেখানোর উপায় রাখুন।
আপনি যদি অডিট লগ রাখেন, তখন ন্যূনতম আইডেন্টিফায়ার রাখুন, কঠোর অ্যাক্সেস নিয়ন্ত্রণ করুন, এবং ডেটা রপ্তানি/মুছার পদ্ধতি ডকুমেন্ট করুন।
AI-কে দ্রুত জুনিয়র আর্কিটেক্ট হিসেবে ব্যবহার করুন: প্রথম খসড়া তৈরিতে দারুণ, ডোমেইন-সমালোচনামূলক ট্রেড‑অফ নিয়ে সিদ্ধান্ত নেওয়ার ক্ষেত্রে দুর্বল। সঠিক প্রশ্নটি হল “AI আমার ব্যাকএন্ড ডিজাইন করতে পারবে কি?” না—বরং “কোন অংশগুলো AI নিরাপদে খসড়া করতে পারে, এবং কোন অংশগুলো বিশেষজ্ঞের মালিকানায় থাকা উচিত?”
AI সময় বাঁচায় যখন আপনি বানাচ্ছেন:
এখানে AI গতি, ধারাবাহিকতা, ও কভারেজে মূল্য দেয়—বিশেষ করে যখন আপনি জানেন কিভাবে প্রোডাক্ট আচরণ করবে এবং ভুলগুলো ধরতে পারবেন।
সতর্ক থাকুন (অথবা AI-জেনারেটেড ডিজাইনকে শুধুই অনুপ্রেরণা হিসেবে ব্যবহার করুন) যখন আপনি কাজ করছেন:
এই ক্ষেত্রগুলোতে ডোমেইন দক্ষতা AI-র গতি থেকে বেশি মূল্যবান। সূক্ষ্ম প্রয়োজনীয়তা—আইনি, ক্লিনিকাল, হিসাবরক্ষণ—প্রম্পটে অনুপস্থিত থাকতে পারে, এবং AI আত্মবিশ্বাসের সঙ্গে গ্যাপ পূরণ করবে।
একটি ব্যবহারিক নিয়ম: AI বিকল্প প্রস্তাব করুক, কিন্তু ডেটা মডেল ইনভারিয়েন্ট, অথরাইজেশন সীমানা, এবং মাইগ্রেশন কৌশলের জন্য চূড়ান্ত পর্যালোচনা লাগুক। যদি আপনি কেউ বলতে না পারেন যে স্কিমা ও API কনট্রাক্টের জন্য কে জবাবদিহি রাখে, AI-ডিজাইন করা ব্যাকএন্ড শিপ করবেন না।
আপনি যদি কর্মপ্রবাহ ও গার্ডরেল মূল্যায়ন করছেন, /blog-এ সম্পর্কিত গাইড দেখুন। যদি আপনি এই অনুশীলনগুলো আপনার দলের প্রক্রিয়ায় প্রয়োগ করতে সহায়তা চান, /pricing চেক করুন।
যদি আপনি চ্যাটের মাধ্যমে ইটারেট করতে, একটি কাজ করা অ্যাপ জেনারেট করতে, এবং সোর্স কোড এক্সপোর্ট ও রোলব্যাক-বন্ধুগত স্ন্যাপশট বজায় রেখে নিয়ন্ত্রণ রাখতে চান, Koder.ai ঠিক এই ধরনের বিল্ড-এন্ড-রিভিউ লুপের জন্য ডিজাইন করা হয়েছে।
এটি সাধারণত মডেলটি একটি প্রথম খসড়া তৈরি করেছে যা অন্তর্ভুক্ত করে:
একটি মানব দল এখনও ব্যবসায়িক নিয়ম, সিকিউরিটি বর্ডার, কোয়েরি পারফরম্যান্স এবং মাইগ্রেশন নিরাপত্তা যাচাই করতে হবে আগে যে এটি প্রোডাকশনে পাঠানো হবে।
AI-কে এমন ইনপুট দিন যা এটি নিরাপদে অনুমান করতে পারে না:
যত বেশি স্পষ্ট কনস্ট্রেইন্ট দেবেন, তত কম AI জটিল ও ভঙ্গুর ডিফল্ট দিয়ে “গ্যাপ পূরণ” করবে।
প্রথমে একটি ধারণাগত মডেল (ব্যবসায়িক কন্সেপ্ট + ইনভারিয়েন্ট) তৈরি করুন, তারপর ক্রমান্বয়ে:
এই স্তরগুলো আলাদা রাখলে স্টোরেজ বদলালে API নষ্ট হওয়া সহজতর হয় না—অথবা API বদলালে ব্যবসায়িক নিয়ম অনিচ্ছাকৃতভাবে ক্ষতিগ্রস্ত হবে না।
সাধারণ সমস্যা হলো:
tenant_id না থাকা, কম্পোজিট ইউনিক কনস্ট্রেইন্ট অনুপস্থিত)deleted_at-কে বিবেচনা না করা)AI-কে বলুন আপনার টপ কোয়েরিগুলি কী এবং তারপর যাচাই করুন:
tenant_id + created_at)আপনি যদি শীর্ষ ৫ কোয়েরি/এন্ডপয়েন্ট তালিকাভুক্ত করতে না পারেন, তাহলে যে কোনো ইনডেক্সিং পরিকল্পনাকে অসম্পূর্ণ বলে নিন।
AI সাধারণত স্ট্যান্ডার্ড স্ক্যাফোল্ডিং ভালো করে, কিন্তু খেয়াল রাখুন:
200 দিয়ে এরর বডি, কখনও উপযুক্ত 4xx/5xx)API কে প্রোডাক্ট ইন্টারফেস হিসাবে ভেবে ডিজাইন করুন: এন্ডপয়েন্টগুলো ব্যবহারকারীর ধারণার ওপর্ভিত হওয়া উচিত, ডাটাবেস ইমপ্লিমেন্টেশনের ওপর নয়।
একটি পুনরাবৃত্তি লুপ ব্যবহার করুন:
নিম্নলিখিত ধাপগুলোকে অগ্রাধিকার দিন:
টেস্টগুলোই সেই ডিজাইনকে আপনি 'own' করবেন; AI-র অনুমানের উপর নির্ভর করা নয়।
নিয়মিত HTTP কোড ব্যবহার করুন এবং একটি একক এরর এনভেলপ রাখুন, উদাহরণ:
400, 401, 403, 404, 409, , AI-কে খসড়া তৈরি করতে দিন যখন প্যাটার্নগুলো ভালোভাবে বোঝা হয়েছে (CRUD-ভিত্তিক MVP, আভ্যন্তরীণ টুল)। সতর্ক থাকুন যখন:
নীতি: AI বিকল্প প্রস্তাব করতে পারে, কিন্তু স্কিমা ইনভারিয়েন্ট, অথরাইজেশন ও রোলআউট/মাইগ্রেশন কৌশলে মানব সাইন-অফ বাধ্যতামূলক করুন।
একটি স্কিমা “পরিষ্কার” দেখালেও বাস্তব কর্মপ্রবাহ ও লোডে ব্যর্থ হতে পারে।
এই লুপ AI আউটপুটকে এমন আর্টিফ্যাক্টে পরিণত করে যা প্রমাণ করা যায় বা প্রত্যাখ্যাত করা যায়—প্রোফ্যানেটিভ প্রোডাক্ট নয়।
422429{"error":{"code":"...","message":"...","details":[...]}}
আরও নিশ্চিত করুন এরর মেসেজ ইন্টারনাল (SQL, স্ট্যাকট্রেস, সিক্রেট) ফাঁস না করে এবং সব এন্ডপয়েন্টে ধারাবাহিক থাকে।