২৬ আগ, ২০২৫·8 মিনিট
AI‑চালিত অ্যাডমিন ড্যাশবোর্ডের জন্য একটি ওয়েব অ্যাপ কিভাবে তৈরি করবেন
AI ইনসাইট, সিকিউর অ্যাক্সেস, নির্ভরযোগ্য ডেটা ও পরিমাপযোগ্য গুণমানসহ একটি অ্যাডমিন ড্যাশবোর্ড ওয়েব অ্যাপ ডিজাইন, তৈরি ও লঞ্চ করার ধাপ‑বাই‑ধাপ পরিকল্পনা।
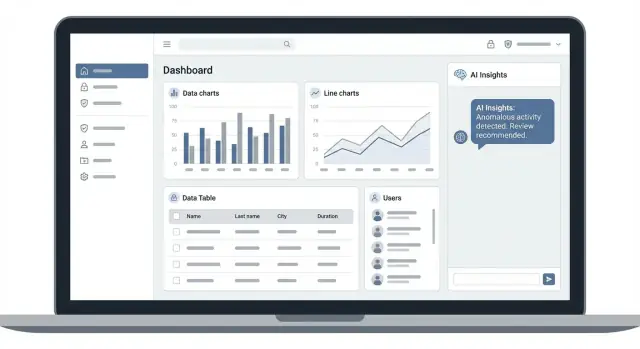
AI ইনসাইট, সিকিউর অ্যাক্সেস, নির্ভরযোগ্য ডেটা ও পরিমাপযোগ্য গুণমানসহ একটি অ্যাডমিন ড্যাশবোর্ড ওয়েব অ্যাপ ডিজাইন, তৈরি ও লঞ্চ করার ধাপ‑বাই‑ধাপ পরিকল্পনা।
চার্ট আঁকার বা কোনো LLM বাছাই করার আগে স্পষ্টভাবে নির্ধারণ করুন এই অ্যাডমিন ড্যাশবোর্ডটি কার জন্য এবং কোন সিদ্ধান্তগুলোকে সহায়তা করবে। অ্যাডমিন ড্যাশবোর্ড সাধারণত ব্যর্থ হয় যখন সেটি “সবার জন্য” হওয়ার চেষ্টা করে এবং কোনো একক দলেরও কাজে আসে না।
প্রধান যে রোলগুলোই ড্যাশবোর্ডে থাকবে সেগুলো তালিকাভুক্ত করুন—সাধারণত ops, support, finance, এবং product। প্রতিটি রোলের জন্য তারা দৈনিক/সাপ্তাহিক কোন ৩–৫টি সিদ্ধান্ত নেয় তা লিখে নিন। উদাহরণ:
যদি কোনো উইজেট কোনো সিদ্ধান্তকে সহায়তা না করে, তাহলে সেটি সম্ভবত শব্দ মাত্র।
“AI‑চালিত অ্যাডমিন ড্যাশবোর্ড” মানে হওয়া উচিত কয়েকটি কংক্রিট সহায়ক ফিচার, একটি সাধারণ চ্যাটবট না জুড়ে দেওয়া। সাধারণ উচ্চ-মূল্যবান AI ফিচারের মধ্যে আছে:
যেসব ওয়ার্কফ্লোতে মুহূর্তের মধ্যে আপডেট দরকার (ফ্রড চেক, আউটেজ, আটকে থাকা পেমেন্ট) এগুলো আলাদা করুন এবং যেগুলো ঘণ্টা বা দৈনিক রিফ্রেশে চলে (সাপ্তাহিক ফাইন্যান্স সারাংশ, কোহরট রিপোর্ট) সেগুলো আলাদা করুন। এই পছন্দ জটিলতা, খরচ, এবং AI উত্তরগুলোর تازা হওয়ার ওপর প্রভাব ফেলে।
প্রকৃত অপারেশনাল মান নির্ধারণ করতে এমন ফলাফল বেছে নিন:
আপনি যদি উন্নতি পরিমাপ করতে না পারেন, আপনি বলতে পারবেন না যে AI ফিচারগুলো সহায়ক নাকি শুধু অতিরিক্ত কাজ তৈরি করছে।
স্ক্রিন ডিজাইন বা AI যোগ করার আগে স্পষ্ট করুন যে ড্যাশবোর্ড কোন ডেটার উপর নির্ভর করবে—এবং সেই ডেটা কীভাবে মিলবে। অনেক অ্যাডমিন ড্যাশবোর্ডের ব্যথা আসে অসামঞ্জস্যপূর্ণ সংজ্ঞা (“একটি active user কী?”) এবং লুকানো উৎস (“refunds billing টুলে আছে, DB-তে নেই”) থেকে।
প্রতিটি জায়গা যেখানে “তথ্য” আছে সেগুলো তালিকাভুক্ত করে শুরু করুন। অনেক টিমের জন্য এতে থাকে:
প্রতিটি সোর্সের জন্য ধরুন: কে মালিক, কিভাবে অ্যাক্সেস (SQL, API, এক্সপোর্ট), এবং সাধারণ জোড়া কী (email, account_id, external_customer_id)। এই কীগুলো পরে ডেটা জোড়ার ক্ষমতা নির্ধারণ করে।
অ্যাডমিন ড্যাশবোর্ডগুলো সবচেয়ে ভালো কাজ করে যখন সেগুলো একটি ছোট সেট এন্টিটির চারপাশে তৈরি করা হয় যা সব জায়গায় দেখা যায়। সাধারণগুলো হলো users, accounts, orders, tickets, এবং events। অতিরিক্ত মডেল করবেন না—শুধু সেই গুলো বাছুন যেগুলো প্র্যাকটিক্যালি admins সার্চ করে ও troubleshoot করে।
একটি সাদাসিধে ডোমেইন মডেল এমন হতে পারে:
এটা পারফেক্ট ডাটাবেস ডিজাইনের ব্যাপার নয়, বরং এই বিষয়ে সম্মতি করার বিষয় যে অ্যাডমিন কোনো রেকর্ড খুললে কী দেখতে চায়।
প্রতিটি গুরুত্বপূর্ণ ফিল্ড এবং মেট্রিকের জন্য কে ডেফাইন করে তা রেকর্ড করুন। উদাহরণ: Finance “MRR”-এর মালিক হতে পারে, Support “First response time” এর মালিক, এবং Product “Activation” এর মালিক। যখন মালিকানা স্পষ্ট থাকে, বিরোধ মীমাংসা করা সহজ হয় এবং সংখ্যাগুলো হঠাৎ পরিবর্তিত হওয়া আটকানো যায়।
ড্যাশবোর্ড প্রায়ই ভিন্ন রিফ্রেশ প্রয়োজনীয়তা বিশিষ্ট ডেটা মিশায়:
এছাড়াও দেরিতে আসা ইভেন্ট ও সংশোধনের (refunds পরে পোস্ট করা, ইভেন্ট ডিলিভারি বিলম্ব, ম্যানুয়াল অ্যাডজাস্টমেন্ট) পরিকল্পনা করুন। নির্ধারণ করুন কতটা পেছনে আপনি ব্যাকফিল অনুমোদন করবেন, এবং কিভাবে সংশোধিত ইতিহাস প্রদর্শন করবেন যাতে admins বিশ্বাস হারান না।
একটি সহজ ডেটা ডিকশনারি তৈরি করুন (একটি ডকই যথেষ্ট) যা নামকরণ ও মান অর্থ স্ট্যান্ডার্ড করে। অন্তর্ভুক্ত করুন:
এটি পরবর্তীতে ড্যাশবোর্ড অ্যানালিটিকস এবং LLM ইন্টিগ্রেশনের জন্য রেফারেন্স পয়েন্ট হয়ে যাবে—কারণ AI কেবলই ততটা ধারাবাহিক হতে পারে যতটা তাকে দেয়া সংজ্ঞা ধারাবাহিক।
একটি ভালো অ্যাডমিন ড্যাশবোর্ড স্ট্যাক নতুনত্বের চেয়ে নির্ভরযোগ্য পারফরম্যান্স—দ্রুত লোড, সুষম UI, এবং AI যোগ করতে সহজ পথ—এর উপর গুরুত্ব দেয়।
একটা মেইনস্ট্রীম ফ্রেমওয়ার্ক বাছুন যা টিম হায়ার এবং রক্ষণাবেক্ষণ করতে পারে। React (Next.js সহ) অথবা Vue (Nuxt সহ) উভয়ই অ্যাডমিন প্যানেলের জন্য দুর্দান্ত।
ডিজাইন কনসিস্টেন্সি রাখতে ও ডেলিভারি ত্বরান্বিত করতে একটি কম্পোনেন্ট লাইব্রেরি ব্যবহার করুন:
কম্পোনেন্ট লাইব্রেরি অ্যাক্সেসিবিলিটি এবং স্ট্যান্ডার্ড প্যাটার্ন (টেবিল, ফিল্টার, মডাল) দিয়ে দেয়, যা কাস্টম ভিজ্যুয়ালের তুলনায় বেশি গুরুত্বপূর্ণ।
উভয়ই কাজ করে, কিন্তু ধারাবাহিকতা বেছে নেওয়া বেশি জরুরি।
/users, /orders, /reports?from=...&to=....অবিশ্বাস হলে REST দিয়ে শুরু করুন ভালো কুয়ারি প্যারামিটার ও পেজিনেশন সহ। পরে প্রয়োজন হলে GraphQL গেটওয়ে যোগ করা যায়।
অধিকাংশ AI-চালিত অ্যাডমিন ড্যাশবোর্ডের জন্য:
একটি সাধারণ প্যাটার্ন হচ্ছে “দামী উইজেটগুলো cache করা” (শীর্ষ KPI, সারাংশ কার্ড) ছোট TTL দিয়ে যাতে ড্যাশবোর্ড দ্রুত থাকে।
LLM ইন্টিগ্রেশন সার্ভারে রাখুন যাতে keys সুরক্ষিত হয় এবং ডেটা অ্যাক্সেস নিয়ন্ত্রণ করা যায়।
যদি আপনার লক্ষ্য একটি ক্রেডিবল অ্যাডমিন ড্যাশবোর্ড MVP দ্রুত অপারেটরদের সামনে নিয়ে আসা (RBAC, টেবিল, ড্রিল‑ডাউন পেজ, এবং AI হেলপারসহ), একটি vibe‑coding প্ল্যাটফর্ম যেমন Koder.ai প্রথম সংস্করণ তৈরি করতে সময় কমাতে পারে। আপনি চ্যাটে স্ক্রিন ও ওয়ার্কফ্লো বর্ণনা করে React ফ্রন্টএন্ড, Go + PostgreSQL ব্যাকএন্ড জেনারেট করতে পারেন এবং পরে সোর্স কোড এক্সপোর্ট করতে পারবেন। প্ল্যানিং মোড ও snapshot/rollback ফিচারগুলো প্রম্পট টেমপ্লেট ও AI UI পুনরাবৃত্তির সময় সহায়ক।
[Browser]
|
v
[Web App (React/Vue)]
|
v
[API (REST or GraphQL)] ---> [Auth/RBAC]
| |
| v
| [LLM Service]
v
[PostgreSQL] <--> [Redis Cache]
|
v
[Job Queue + Workers] (async AI/report generation)
এই সেটআপটি সাদাসিধে থাকে, ধীরে ধীরে স্কেল করে, এবং AI ফিচারগুলোকে প্রতিটি অনুরোধ পথের সাথে জড়িয়ে না দিয়ে অগ্রগতি যোগ করে।
অ্যাডমিন ড্যাশবোর্ড জীবিত বা মৃত হয় যে প্রশ্ন দুটোকে দ্রুত উত্তর দিতে পারে: “কি ভুল?” এবং “পরবর্তী কী করা উচিত?” UX-টা বাস্তব অ্যাডমিন কাজের চারপাশে ডিজাইন করুন, তারপর ব্যবহারকারী হারানো কঠিন করে দিন।
শুরু করুন টপ টাস্ক দিয়ে (refund an order, unblock a user, investigate a spike, update a plan)। ন্যাভিগেশনকে সেই কাজগুলোর চারপাশে গ্রুপ করুন—যদিও ব্যাকগ্রাউন্ড ডেটা একাধিক টেবিলে থাকা সত্ত্বেও।
একটি সাধারণ স্ট্রাকচার যা প্রায়শই কাজ করে:
অ্যাডমিনরা কয়েকটি কাজ বারবার করে: search, filter, sort, compare। ন্যাভিগেশন এমনভাবে ডিজাইন করুন যাতে এগুলো সবসময় থাকে এবং ধারাবাহিক হয়।
চার্ট ট্রেন্ড দেখাতে ভাল, কিন্তু অ্যাডমিনরা প্রায়ই নির্দিষ্ট রেকর্ড চায়। ব্যবহার করুন:
শুরুতেই বেসিকস ইনক্লুড করুন: পর্যাপ্ত কনট্রাস্ট, দৃশ্যমান ফোকাস স্টেট, এবং পূর্ণ কীবোর্ড নেভিগেশন টেবিল কন্ট্রোল ও ডায়ালগের জন্য।
প্রতিটি উইজেটের জন্য empty/loading/error স্টেট পরিকল্পনা করুন:
যখন UX চাপের সময়ও পূর্বানুমানযোগ্য থাকে, admins সেটার বিশ্বাস রাখে এবং দ্রুত কাজ করতে পারে।
অ্যাডমিনরা ড্যাশবোর্ড খোলে AI-র সঙ্গে চ্যাট করতে চায় না; তারা সিদ্ধান্ত নিতে, সমস্যা সমাধান করতে, এবং অপারেশন চালাতে খোলে। আপনার AI ফিচারগুলোকে রিপিটিটিভ কাজ কমানো, তদন্ত সময় শর্ট করা, এবং ত্রুটি কমানো উচিত—নতুন একটি পরিচালনীয় সারফেস যোগ করা নয়।
কোনো ছোট সংখ্যক ফিচার বেছে নিন যা সরাসরি ম্যানুয়াল ধাপগুলো প্রতিস্থাপন করে এবং সহজে যাচাইযোগ্য। ভালো প্রাথমিক প্রার্থীর উদাহরণ:
AI-কে টেক্সট লিখতে দিন যেখানে আউটপুট editable এবং কম-ঝুঁকিপূর্ণ (সারাংশ, ড্রাফট, ইন্টারনাল নোট)। AI-কে কর্ম সুপারিশ করতে বলুন যেখানে মানুষ নিয়ন্ত্রণে থাকবে (প্রস্তাবিত পরবর্তী ধাপ, প্রাসঙ্গিক রেকর্ড লিঙ্ক, পূরণকৃত ফিল্টার)।
প্রায়োগিক রুল: যদি কোনো ভুল টাকা, পারমিশন, বা কাস্টমার অ্যাক্সেস পরিবর্তন করতে পারে, AI-কে প্রস্তাবক হিসেবে ব্যবহার করুন—কখনোই সরাসরি এক্সিকিউট করবেন না।
প্রতিটি AI ফ্ল্যাগ বা সুপারিশের পাশে একটি ছোট “আমি কেন এটি দেখাচ্ছি?” ব্যাখ্যা দিন। এটি ব্যবহৃত সিগন্যালগুলো উল্লেখ করবে (উদাহরণ: “14 দিনের মধ্যে 3টি ব্যর্থ পেমেন্ট” বা “রিলিজ 1.8.4 পরে এরর রেট 0.2% থেকে 1.1% বেড়েছে”)। এটি বিশ্বাস গঠন করে এবং admins‑কে খারাপ ডেটা ধরতে সাহায্য করে।
নির্ধারণ করুন কখন AI প্রত্যাখ্যান করবে (অনুমতি নেই, সংবেদনশীল অনুরোধ, অস্যাপোর্টেড অপারেশন) এবং কখন আরও প্রসঙ্গ চাইবে (অস্পষ্ট অ্যাকাউন্ট নির্বাচন, বিরোধী মেট্রিক, অসম্পূর্ণ টাইম-রেঞ্জ)। এটি অভিজ্ঞতাকে কেন্দ্রভিত্তিক রাখে এবং ভুলে আত্মবিশ্বাসী কিন্তু অনুপযোগী আউটপুট প্রতিরোধ করে।
অ্যাডমিন ড্যাশবোর্ড ইতিমধ্যেই ডেটা ছড়িয়ে আছে: বিলিং, সাপোর্ট, প্রোডাক্ট ইউজ, অডিট লগ এবং ইন্টারনাল নোট। একটি AI অ্যাসিস্ট্যান্ট যতটাই কার্যকর হতে পারে ততটাই নির্ভর করে আপনি দ্রুত, নিরাপদ এবং ধারাবাহিক কন্টেক্সট কতটা গঠন করতে পারেন তার ওপর।
শুরু করুন সেই অ্যাডমিন টাস্কগুলো থেকে যেগুলো আপনি দ্রুত করতে চান (উদাহরণ: “কেন এই অ্যাকাউন্ট ব্লক করা হয়েছিল?” বা “এই কাস্টমারের সাম্প্রতিক ইনসিডেন্টগুলো সারাংশ করো”)। তারপর একটি ছোট, পূর্বানুমানযোগ্য কন্টেক্সট ইনপুট সেট নির্ধারণ করুন:
যদি কোনো ফিল্ড AI-এর উত্তর বদলাবে না, সেটি অন্তর্ভুক্ত করবেন না।
কন্টেক্সটকে একটি প্রোডাক্ট API হিসেবেই বিবেচনা করুন। সার্ভার-সাইডে একটি “context builder” তৈরি করুন যা প্রতিটি এন্টিটির জন্য একটি মিনিমাল JSON পে-লোড উত্পন্ন করে। শুধুমাত্র প্রয়োজনীয় ফিল্ড রাখুন, এবং সংবেদনশীল ডেটা (টোকেন, পূর্ণ কার্ড ডিটেইল, পূর্ণ ঠিকানা, কাঁচা মেসেজ বডি) মাস্ক বা সরিয়ে দিন।
ডিবাগ ও অডিটিং সহজ করার জন্য মেটাডেটা যোগ করুন:
context_versiongenerated_atsources: কোন সিস্টেমগুলো ডেটা দিয়েছেredactions_applied: কি কী রিমুভ/মাস্ক করা হয়েছেপ্রতিটি টিকিট, নোট এবং পলিসি সবকিছু প্রম্পটে ভরিয়ে দেওয়া স্কেল করবে না। পরিবর্তে searchable content (নোট, KB আর্টিকেল, প্লেবুক, টিকিট থ্রেড) ইনডেক্স করে প্রয়োজনীয় স্নিপেটগুলো অনুরোধের সময় তুলে আনুন।
সহজ প্যাটার্ন:
এটি প্রম্পট ছোট রাখে এবং উত্তরকে বাস্তব রেকর্ডে গ্রাউন্ড করে।
AI কল মাঝে মাঝে ব্যর্থ হবে। এর জন্য ডিজাইন করুন:
অনেক অ্যাডমিন প্রশ্ন রিপিট হয় (“অ্যাকাউন্ট হেলথ সারাংশ”). entity + prompt version অনুযায়ী ফলাফল cache করুন, এবং business-meaning অনুযায়ী expiry দিন (উদাহরণ: লাইভ মেট্রিকের জন্য 15 মিনিট, সারাংশের জন্য 24 ঘন্টা)। সব সময় “as of” টাইমস্ট্যাম্প দেখান যাতে admins জানে উত্তর কতটা ফ্রিশ।
অ্যাডমিন ড্যাশবোর্ড একটি উচ্চ‑ট্রাস্ট পরিবেশ: AI অপারেশনাল ডেটা দেখে এবং সিদ্ধান্তকে প্রভাবিত করতে পারে। ভাল prompting “চতুর শব্দচয়নে” কম নির্ভর করে বরং পূর্বানুমানযোগ্য কাঠামো, কঠোর সীমা, এবং ট্রেসিবিলিটির উপর বেশি নির্ভর করে।
প্রতিটি AI অনুরোধকে একটি API কলের মতো বিবেচনা করুন। ইনপুট স্পষ্ট ফরম্যাটে (JSON বা বুলেট ফিল্ড) দিন এবং একটি নির্দিষ্ট আউটপুট স্কিমা দাবী করুন।
উদাহরণস্বরূপ চেয়ে নিন:
এতে আগামি-সৃজনশীলতা কমে এবং UI-তে দেখানোর আগে রিপন্সগুলি ভ্যালিডেট করা সহজ হয়।
টেমপ্লেটগুলো ফিচার জুড়ে কনসিস্টেন্ট রাখুন:
স্পষ্ট নীতি যোগ করুন: কোনও সিক্রেট বলবে না, শুধুমাত্র প্রদত্ত ব্যক্তিগত ডেটা ব্যবহার করবে, এবং ঝুঁকিপূর্ণ অ্যাকশন (ব্যবহারকারী ডিলিট করা, রিফান্ড ইত্যাদি) না করবে মানব কনফার্ম ছাড়া।
যেখানে সম্ভব, citations বাধ্যতামূলক করুন: প্রতিটি দাবিকে একটি সোর্স রেকর্ড (ticket ID, order ID, event timestamp) দেখান। যদি মডেল cite করতে না পারে, সেটি বলা উচিত।
প্রম্পট, রিট্রিভ করা কন্টেক্সট আইডেন্টিফায়ার, এবং আউটপুট লগ করুন যাতে আপনি সমস্যাগুলো পুনরুত্পাদন করতে পারেন। সংবেদনশীল ফিল্ড (টোকেন, ইমেইল, ঠিকানা) রেড্যাক্ট করুন এবং এক্সেস‑কনট্রোলড লগ স্টোর করুন। যখন একজন অ্যাডমিন জিজ্ঞেস করে, “AI কেন এটা সাজেস্ট করলো?” তখন এটি অমূল্য হবে।
অ্যাডমিন ড্যাশবোর্ড ক্ষমতা কেন্দ্রীভূত করে: একটি ক্লিকে মূল্য পরিবর্তন করা, ব্যবহারকারী মুছা, বা ব্যক্তিগত ডেটা প্রকাশ করা যায়। AI‑চালিত ড্যাশবোর্ডে ঝুঁকি আরও বাড়ে—অ্যাসিস্ট্যান্ট সুপারিশ করতে পারে বা সারাংশ তৈরি করতে পারে যা সিদ্ধান্ত প্রভাবিত করে। নিরাপত্তাকে একটি মূল ফিচার মনে করুন, পরে যোগ করার একটি স্তর নয়।
আপনার ডেটা মডেল ও রুটগুলি এখনও বিকাশমান অবস্থায় থাকলেও role‑based access control (RBAC) শুরুতেই বাস্তবায়ন করুন। একটি ছোট সেট রোল নির্ধারণ করুন (উদাহরণ: Viewer, Support, Analyst, Admin) এবং পারমিশনগুলো রোলে লাগান—ব্যক্তি নয়। এটিকে সহজ ও স্পষ্ট রাখুন।
প্রায়োগিক পদ্ধতি হিসেবে একটি permissions matrix রাখুন (একটি সহজ টেবিলও চলবে) যা উত্তর দেয়: “কে এটা দেখতে পাবে?” এবং “কে এটা বদলাতে পারবে?”। সে ম্যাট্রিক্স API ও UI‑কে গাইড করবে এবং ড্যাশবোর্ড বাড়ার সঙ্গে দুর্ঘটনাজনক প্রিভিলেজ বৃদ্ধিকে আটকাবে।
অনেক টিম কেবল “পেজে অ্যাক্সেস আছে” পর্যায়ে থামে। পরিবর্তে পারমিশনগুলো অন্তত দুই স্তরে ভাগ করুন:
এই বিভাজন সেই সময় দরকারি যখন আপনাকে ব্যাপক দৃশ্যমানতা দিতে হবে (উদাহরণ: support স্টাফ) কিন্তু সমালোচনামূলক সেটিংস বদলানোর অধিকার দিতে হবে না।
একটি ভালো UX‑এর জন্য বোতামগুলো UI‑তে লুকান, কিন্তু নিরাপত্তার জন্য UI চেক ভরসা করবেন না। প্রতিটি এন্ডপয়েন্ট কলারের রোল/পারমিশন সার্ভারে যাচাই করা উচিত:
“গুরুত্বপূর্ণ অ্যাকশন”‑গুলো লগ করুন যাতে আপনি উত্তর দিতে পারেন কে কী বদলালো, কখন, এবং কোথা থেকে। ন্যূনতম হিসেবে কেবল নিন: actor user ID, action type, target entity, timestamp, before/after values (বা diff) এবং অনুরোধ মেটাডেটা (IP/user agent)। অডিট লগগুলো append-only, searchable, এবং সম্পাদনা থেকে সুরক্ষিত রাখুন।
আপনার সিকিউরিটি ধারণা ও অপারেটিং রুলগুলো (session handling, admin access process, incident response basics) লিখে রাখুন। যদি আপনি একটি security পৃষ্ঠা বজায় রাখেন, প্রোডাক্ট ডকস থেকে সেটির লিংক দিন (দেখুন /security) যাতে admins এবং অডিটররা জানে কি আশা করা উচিত।
আপনার API আকারই হবে যা বা না হলে অ্যাডমিন অভিজ্ঞতাকে দ্রুত রাখবে—অথবা frontend‑কে প্রতিটি স্ক্রিনে ব্যাকএন্ডের সাথে লড়তে হবে। সরল নিয়ম: UI যে তথ্য চায় তার চারপাশে এন্ডপয়েন্ট ডিজাইন করুন (list views, detail pages, filters, কিছু অগ্রেগেট) এবং রেসপন্স ফরম্যাট ধারাবাহিক রাখুন।
প্রতিটি প্রধান স্ক্রিনের জন্য ছোট সেট এন্ডপয়েন্ট নির্ধারণ করুন:
GET /admin/users, GET /admin/ordersGET /admin/orders/{id}GET /admin/metrics/orders?from=...&to=...“সবকিছু এক জায়গায়” ধরনের এন্ডপয়েন্ট এড়িয়ে চলুন যেমন GET /admin/dashboard যা সবকিছু রিটার্ন করার চেষ্টা করে। সেগুলো বাড়তে থাকে, cache কঠিন হয়, এবং পার্শিয়াল UI আপডেট ব্যথা দেয়।
অ্যাডমিন টেবিলগুলো ধারাবাহিকতার উপর বাঁচে। সমর্থন করুন:
limit, cursor বা page)sort=created_at:desc)status=paid&country=US)ফিল্টারগুলো সময়ের সাথে স্থিতিশীল রাখুন (অর্থাৎ অর্থ বদলাবেন না চুপচাপ), কারণ অ্যাডমিনরা URL বুকমার্ক করে এবং ভিউ শেয়ার করবে।
বড় এক্সপোর্ট, লং‑রানিং রিপোর্ট, এবং AI জেনারেশন asynchronous হওয়া উচিত:
POST /admin/reports → returns job_idGET /admin/jobs/{job_id} → status + progressGET /admin/reports/{id}/download যখন প্রস্তুতএকই প্যাটার্ন AI সারাংশ বা ড্রাফট রেসপন্সের জন্যও কাজ করে যাতে UI রেসপনসিভ থাকে।
ত্রুটিগুলো স্ট্যান্ডার্ডাইজ করুন যাতে frontend সেগুলো পরিষ্কার দেখাতে পারে:
{ "error": { "code": "VALIDATION_ERROR", "message": "Invalid date range", "fields": { "to": "Must be after from" } } }
এটি আপনার AI ফিচারগুলোকে সাহায্য করে: আপনি vague “something went wrong” দেখানোর বদলে actionable failure দেখাতে পারবেন।
একটা দুর্দান্ত অ্যাডমিন ড্যাশবোর্ড ফ্রন্টএন্ড মডুলার লাগে: আপনি একটি নতুন রিপোর্ট বা AI হেলপার যোগ করতে পারবেন পুরো UI পুনর্নির্মাণ না করে। একটি ছোট সেট reusable ব্লক স্ট্যান্ডার্ডাইজ করে শুরু করুন, তারপর তাদের আচরণ অ্যাপ জুড়ে কনসিস্টেন্ট রাখুন।
প্রতিটি স্ক্রিনে পুনরায় ব্যবহার করা যায় এমন একটি “ড্যাশবোর্ড কিট” তৈরি করুন:
এই ব্লকগুলো স্ক্রিনগুলোকে কনসিস্টেন্ট রাখে এবং one-off UI ডিসিশন কমায়।
অ্যাডমিনরা প্রায়ই ভিউ বুকমার্ক করে এবং লিংক শেয়ার করে। URL‑এ মূল স্টেট রাখুন:
?status=failed&from=...&to=...)?orderId=123 সাইড প্যানেল খুলে)Saved views যোগ করুন (“My QA queue”, “Refunds last 7 days”) যা একটি নামকৃত ফিল্টার সেট সংরক্ষণ করে। এটি ইউজারকে দ্রুত অনুভব করায় কারণ তারা বারবার একই কুয়ারি তৈরি করে না।
AI আউটপুটকে একটি খসড়া হিসেবে দেখান, চূড়ান্ত উত্তর হিসেবে নয়। সাইড প্যানেলে (অথবা একটি “AI” ট্যাবে) দেখান:
সব সময় AI কনটেন্ট লেবেল করুন এবং কোন রেকর্ডগুলো কন্টেক্সট হিসেবে ব্যবহার হয়েছে দেখান।
AI যদি কোনো অ্যাকশন সুপারিশ করে (flag user, refund, block payment), তাহলে একটি রিভিউ ধাপ বাধ্যতামূলক করুন:
যা‑ই মাপবেন তা ট্র্যাক করুন: search ব্যবহার, filter পরিবর্তন, export, AI open/click‑through, regenerate rate, এবং feedback। এই সিগন্যালগুলো UI উন্নত করতে এবং কোন AI ফিচারসময় বাঁচাচ্ছে তা নির্ধারণে সাহায্য করে।
অ্যাডমিন ড্যাশবোর্ড টেস্টিং পিক্সেল‑পার্ফেক্ট UI‑এর চেয়ে বাস্তবে আত্মবিশ্বাস তৈরিতে বেশি: স্টেল ডেটা, ধীর কুয়ারি, অসম্পূর্ণ ইনপুট, এবং দ্রুত ক্লিক করা “পাওয়ার ইউজার”‑দের পরিস্থিতি।
কিছু ছোট ওয়ার্কফ্লো আছে যেগুলো কখনো ভেঙে যাবে না—এগুলোর জন্য end‑to‑end (ব্রাউজার + ব্যাকএন্ড + ডাটাবেস) টেস্ট অটোমেট করুন যাতে ইন্টিগ্রেশন বাগ ধরা পড়ে।
সাধারণ “মাস্ট‑পাস” ফ্লো: লগইন (রোল সহ), global search, রেকর্ড এডিট, রিপোর্ট এক্সপোর্ট, এবং কোনো approval/review অ্যাকশন। অন্তত একটি টেস্ট বাস্তব dataset সাইজ কভার করবে—কারণ পারফরম্যান্স রিগ্রেশন ছোট fixtures‑এ লুকিয়ে থাকে।
AI ফিচারগুলোর জন্য আলাদা টেস্ট আর্টিফ্যাক্ট দরকার। ২০–৫০টি প্রম্পটের একটি হালকা মূল্যায়ন সেট তৈরি করুন: বাস্তব অ্যাডমিন প্রশ্নের মত, প্রত্যেকটির সঙ্গে “ভাল” উত্তর ও কিছু “খারাপ” উদাহরণ (hallucinations, policy violations, বা citation‑এর অভাব)।
এটি আপনার রেপোতে versioned রাখুন যাতে প্রম্পট, টুল বা মডেল পরিবর্তন কোডের মত রিভিউ করা যায়।
কয়েকটি সরল মেট্রিক ট্র্যাক করুন:
এছাড়া adversarial ইনপুট (prompt injection প্রচেষ্টা) টেস্ট করুন যাতে গার্ডরেইল কাজ করে।
মডেল ডাউনটাইমের জন্য পরিকল্পনা রাখুন: AI প্যানেল অক্ষম করুন, সাদামাটা অ্যানালিটিকস দেখান, এবং মূল অ্যাকশনগুলো ব্যবহারযোগ্য রাখুন। যদি আপনার কাছে একটি feature flag সিস্টেম থাকে, AI‑কে ফ্ল্যাগের পেছনে রাখুন যাতে দ্রুত রোলব্যাক করা যায়।
শেষে প্রাইভেসি রিভিউ করুন: লগগুলো রেড্যাক্ট করুন, কাঁচা প্রম্পট যেখানে সংবেদনশীল আইডেন্টিফায়ার থাকতে পারে সেগুলো সংরক্ষণ এড়ান, এবং ডিবাগ/মূল্যায়নের জন্য যা প্রয়োজন তা ছাড়া আর কিছু না রাখুন। একটি সরল চেকলিস্ট /docs/release-checklist এ রাখলে টিম নিয়মিতভাবে শিপ করতে পারবে।
AI‑চালিত অ্যাডমিন ড্যাশবোর্ড লঞ্চ করা একবারের কাজ নয়—এটা “ওয়ার্কিং ইন প্রোডাকশন যেখানে অপারেটররা বিশ্বাস করে” পর্যন্ত নিয়ন্ত্রিত ট্রানজিশন। নিরাপদ পদ্ধতি হল লঞ্চকে একটি ইঞ্জিনিয়ারিং ওয়ার্কফ্লো হিসেবে দেখা: আলাদা এনভায়রনমেন্ট, দৃশ্যমানতা, এবং একটি পরিকল্পিত ফিডব্যাক লুপ সহ।
ডেভ, স্টেজ, ও প্রোডাকশন আলাদা রাখুন—বিভিন্ন ডাটাবেস, API কিজ, ও AI প্রোভাইডার ক্রেডেনশিয়াল সহ। স্টেজিং প্রোডাকশনের কনফিগারেশন কাছাকাছি থাকা উচিত (feature flags, rate limits, background jobs) যাতে বাস্তব আচরণ পরীক্ষা করে ঝুঁকিমুক্ত করা যায়।
কনফিগারেশন environment variables দিয়ে এবং ধারাবাহিক ডিপ্লয়মেন্ট প্রসেস রেখে রাখুন। এটি রোলব্যাককে predictable করে এবং “স্পেশাল‑কেস” পরিবর্তন এড়িয়ে যায়।
যদি আপনি এমন একটি প্ল্যাটফর্ম ব্যবহার করেন যা snapshot এবং rollback সাপোর্ট করে (উদাহরণ: Koder.ai‑র বিল্ট‑ইন snapshot flow), আপনি AI ফিচার ইটারেশনেও একই ডিসিপ্লিন প্রয়োগ করতে পারবেন: ফিচারগুলো ফ্ল্যাগের পেছনে ship করুন, মাপুন, এবং যদি prompts বা retrieval admin trust degrade করে তবে দ্রুত রোলব্যাক করুন।
মনিটরিং সেট আপ করুন যা সিস্টেম হেলথ এবং ইউজার এক্সপেরিয়েন্স উভয়কেই ট্র্যাক করে:
ডেটা ফ্রেশনেস সূচকের জন্য alerts যোগ করুন (উদাহরণ: “sales totals 6+ ঘন্টা আপডেট হয়নি”) এবং ড্যাশবোর্ড লোড টাইম‑এর জন্য (উদাহরণ: p95 2 সেকেন্ডের বেশি)। এই দুইটা সমস্যা সবচেয়ে বেশি বিভ্রান্তি তৈরি করে কারণ UI দেখতে “ভালো” লাগতে পারে কিন্তু ডেটা stale বা ধীর থাকে।
একটি ছোট MVP ship করুন, তারপর বাস্তব ব্যবহার অনুযায়ী বাড়ান: কোন রিপোর্ট প্রতিদিন খোলা হয়, কোন AI সুপারিশগুলো গ্রহণ হচ্ছে, এবং কোথায় admins দ্বিধা করে। নতুন AI ফিচারগুলো ফ্ল্যাগের পেছনে রাখুন, সংক্ষিপ্ত পরীক্ষা চালান, এবং মেট্রিক রিভিউ করে এক্সেস বাড়ান।
পরবর্তী ধাপ: /docs এ একটি ইন্টারনাল রানবুক প্রকাশ করুন, এবং আপনি যদি টিয়ার বা ব্যবহার‑সীমা অফার করেন, তা স্পষ্টভাবে /pricing এ উল্লেখ করুন।
প্রাথমিকভাবে অ্যাডমিনের প্রধান রোলগুলো (support, ops, finance, product) তালিকাভুক্ত করুন এবং প্রত্যেক রোলের জন্য সাপ্তাহিক/দৈনিক ৩–৫টি সিদ্ধান্ত লিখে নিন। তারপর এমন উইজেট ও AI সাহায্যকারীর পরিকল্পনা করুন যেগুলো সরাসরি সেই সিদ্ধান্ত গুলোকে সমর্থন করে।
একটি ভালো পরীক্ষক হলো: যদি কোনো উইজেট কারও পরবর্তী কাজ বদলে না দেয়, তাহলে সেটি সম্ভবত গোলমাল।
এটা হওয়া উচিত কাজের মধ্যে এমবেড করা কয়েকটি নির্দিষ্ট সহায়ক বৈশিষ্ট্য, একটি সাধারণ চ্যাটবট নয়।
সাধারণভাবে উচ্চ-মূল্যবান অপশনগুলো:
যেখানে কাউকে দ্রুত প্রতিক্রিয়া জানাতে হবে সেখানে রিয়েল-টাইম রাখুন (ফ্রড চেক, আউটেজ, আটকে থাকা পেমেন্ট)। রিপোর্ট-ভিত্তিক ওয়ার্কফ্লোতে প্রতি ঘণ্টা/প্রতিদিন আপডেট যথেষ্ট (ফাইন্যান্স সারাংশ, কোহরট রিপোর্ট)।
এই সিদ্ধান্তগুলো প্রভাব ফেলবে:
প্রত্যেক জায়গা থেকে “সত্য” কোথায় আছে তা ইনভেন্টরি করে শুরু করুন:
প্রতিটির জন্য ধরুন: কে এর অনউয়ার? কিভাবে অ্যাক্সেস করবেন (SQL, API, এক্সপোর্ট), এবং সাধারণ জোড়া কীসমূহ (email, account_id, external_customer_id)। এই কীগুলোই পরে ডেটা যোগ করার জন্য দরকারি।
সেটি হওয়া উচিত এমন কিছু কোর এন্টিটি যা অ্যাডমিনরা প্রকৃতপক্ষে সার্চ ও ট্রাবলশুট করে—প্রায়শই: Account, User, Order/Subscription, Ticket, Event।
সহজ সম্পর্ক মডেল লিখে রাখুন (উদাহরণ: Account → Users/Orders; User → Events; Account/User → Tickets) এবং মেট্রিক মালিকানা ডকুমেন্ট করুন (যেমন, MRR — Finance)।
এটি স্ক্রিন এবং AI প্রম্পটগুলোকে ভাগ করা সংজ্ঞার মধ্যে রাখে।
একটি ব্যবহারিক বেসলাইন:
LLM কলগুলো সার্ভার-সাইডে রাখুন যাতে কীগুলো সুরক্ষিত থাকে এবং অ্যাক্সেস কন্ট্রোল প্রয়োগ করা যায়।
নেভিগেশনকে কাজ (jobs) অনুযায়ী ডিজাইন করুন, না যে কোন টেবিল ভিত্তিকভাবে। ঘন ঘন করা কাজগুলো (search/filter/sort/compare) সবসময় সহজলভ্য রাখুন।
ব্যবহারিক UI প্যাটার্ন:
যে কাজগুলো রিপিটিটিভ এবং তদন্তের সময় ছোট করে দেয় সেগুলোই ব্যাউন করা শুরু করুন:
রুল: যদি কোনো ভুল টাকা, পারমিশন বা অ্যাক্সেস পরিবর্তন করে ফেলতে পারে, AI কে প্রস্তাব করতে বলুন — সরাসরি এক্সিকিউট করাবেন না।
একটি সার্ভার-সাইড context builder তৈরি করুন যা প্রতিটি এন্টিটির জন্য ছোট, নিরাপদ JSON payload রিটার্ন করে (account/user/ticket)। শুধুমাত্র সেই ফিল্ডগুলো রাখুন যা উত্তরকে প্রভাবিত করে, এবং সংবেদনশীল ডেটা মাস্ক/স্ট্রিপ করুন।
ডিবাগিং ও অডিটের জন্য মেটাডেটা যোগ করুন:
context_versiongenerated_atপ্রাথমিকভাবে RBAC ইমপ্লিমেন্ট করুন এবং প্রতিটি অ্যাকশনের জন্য সার্ভারে এটি প্রয়োগ করুন (AI-জেনারেটেড রিপোর্ট ও এক্সপোর্টসহ)।
আরও যোগ করুন:
sourcesredactions_appliedবড় টেক্সট (টিকিট, নোট, KB) জন্য retrieval ব্যবহার করুন: প্রাসঙ্গিক স্নিপেটগুলোই রেট্রিভ করে প্রম্পটে পাঠান।