১৮ আগ, ২০২৫·8 মিনিট
Chris Lattner-এর LLVM: আধুনিক টুলচেইনের নীরব ইঞ্জিন
জানুন কিভাবে Chris Lattner-এর LLVM একটি মডুলার কম্পাইলার প্ল্যাটফর্ম হয়ে ওঠে—ভাষা ও টুলগুলোর পিছনে থাকা অপ্টিমাইজেশন, উন্নত ডায়াগনস্টিকস, এবং দ্রুত বিল্ড সক্ষম করে।
সাধারণ ভাষায় LLVM কী
LLVMকে সবচেয়ে ভালোভাবে ধরা যায় এমন একটি “ইঞ্জিন রুম” হিসেবে যা বহু কম্পাইলার এবং ডেভেলপার টুল শেয়ার করে।
আপনি যদি C, Swift, বা Rust-এর মতো কোনো ভাষায় কোড লেখেন, তাহলে সেই কোডকে এমন নির্দেশনায় অনুবাদ করা দরকার যা আপনার CPU চালাতে পারে। প্রচলিত কম্পাইলারগুলো প্রায়শই পাইপলাইনের প্রতিটি অংশ নিজে তৈরি করত। LLVM ভিন্ন পথে চলে: এটি একটি উচ্চমানের, পুনঃব্যবহারযোগ্য কোর দেয় যা কঠিন, সময়সাপেক্ষ কাজগুলো — অপ্টিমাইজেশন, বিশ্লেষণ, ও বিভিন্ন প্রসেসরের জন্য মেশিন কোড তৈরি — সামলায়।
অনেক ভাষার জন্য একটি ভাগ করা ভিত্তি
LLVM সাধারণত একটি একক কম্পাইলার হিসেবে ব্যবহার করা হয় না। এটি কম্পাইলার অবকাঠামো: এমন নির্মাণ ব্লকগুলো যা ভাষা দলগুলো টুলচেইন বানাতে একত্রে সাজিয়ে নেয়। এক দল শুধু সিনট্যাক্স, সিম্যান্টিক্স এবং ডেভেলপার-সম্মুখীন ফিচারগুলোর দিকে মনোনিবেশ করতে পারে, তারপর ভারী কাজগুলো LLVM-কে হস্তান্তর করে।
এই ভাগ করা ভিত্তি হল প্রধান কারণ যে আধুনিক ভাষাগুলো দ্রুত, নিরাপদ টুলচেইন সরবরাহ করতে পারে বেসিক কম্পাইলার কাজগুলো পুনরায় আবিষ্কার ছাড়া।
আপনি যদি কম্পাইলার ব্যক্তিজ্ঞান না হন তখনও কেন এটা গুরুত্বপূর্ণ
LLVM প্রতিদিনের ডেভেলপার অভিজ্ঞতায় এইভাবে উপস্থিত হয়:
- গতি: এটা বহু প্ল্যাটফর্মে উচ্চস্তরের কোডকে কার্যকর মেশিন কোডে রূপান্তর করতে পারে।
- ভালো এরর ও ডিবাগিং: LLVM-এর চারপাশের ইকোসিস্টেম সমৃদ্ধ ডায়াগনস্টিক এবং উন্নত টুলিং সক্ষম করে।
- শুধু "কম্পাইলেশন" নয়: স্ট্যাটিক বিশ্লেষণ, স্যানিটাইজার, কোড কভারেরেজ এবং অন্যান্য ডেভেলপার সহায়ক অনেকেই একই অভ্যন্তরীণ প্রতিনিধিত্ব ও লাইব্রেরির উপরে নির্মিত।
এই প্রবন্ধটি কী বলবে (এবং কী বলবে না)
এটি একটি গাইড করা টুর যা Chris Lattner শুরু করা ধারণাগুলো দেখাবে: LLVM কিভাবে সংগঠিত, কেন মধ্যস্তর গুরুত্বপূর্ণ, এবং কিভাবে এটি অপ্টিমাইজেশন ও মাল্টি-প্ল্যাটফর্ম সাপোর্ট সক্ষম করে। এটি কোনো পাঠ্যবই নয়—আমরা ধারণা ও বাস্তব-প্রভাবের দিকে ফোকাস রাখব, আনুষ্ঠানিক তত্ত্বের বদলে।
Chris Lattner-এর মূল ভিশন
Chris Lattner একজন কম্পিউটার বিজ্ঞানী ও ইঞ্জিনিয়ার, যিনি ২০০০-এর প্রথম ভাগে স্নাতকোত্তর ছাত্র হিসেবে LLVM শুরু করেছিলেন একটি ব্যবহারিক হতাশা থেকেই: কম্পাইলার প্রযুক্তি শক্তিশালি ছিল, কিন্তু পুনঃব্যবহারযোগ্য হওয়া কঠিন। যদি আপনি একটি নতুন প্রোগ্রামিং ভাষা, উন্নত অপ্টিমাইজেশন, বা নতুন CPU সাপোর্ট করতে চাইতেন, প্রায়ই আপনাকে একটি শক্তভাবে জড়িত “সর্ব-একটি” কম্পাইলারের সাথে ট tinkering করতে হতো যেখানে প্রতিটি পরিবর্তনের পার্শ্বপ্রতিক্রিয়া ছিল।
তিনি যে সমস্যার সমাধান করতে চেয়েছিলেন
সেই সময়ে অনেক কম্পাইলার একক, বড় মেশিনের মতো তৈরি ছিল: ভাষা বুঝা অংশ, অপ্টিমাইজার অংশ, এবং মেশিন কোড জেনারেটর গভীরভাবে একত্রে বাঁধা ছিল। ফলে সেগুলো মূল উদ্দেশ্যে কার্যকর হলেও অভিযোজন করা ব্যয়বহুল ছিল।
Lattner-এর লক্ষ্য ছিল “একটি ভাষার জন্য কম্পাইলার” নয়। বরং একটি ভাগ করা ভিত্তি যা অনেক ভাষা এবং অনেক টুল চালাতে পারবে—সবাই বারবার একই জটিল অংশগুলো পুনরায় লিখে সময় নষ্ট না করে। মূল বাজি ছিল: পাইপলাইনের মধ্যভাগ স্ট্যান্ডার্ডাইজ করলে প্রান্তগুলোতে দ্রুত উদ্ভাবন করা যাবে।
কেন “মডুলার অবকাঠামো” তখন নতুন ধারণা ছিল
কী শিফটটি করলো তা ছিল: কম্পাইলেশনকে আলাদা করা নির্মাণ ব্লক হিসেবে দেখা এবং স্পষ্ট সীমানা নির্ধারণ করা। একটি মডুলার দুনিয়ায়:
- একটি ভাষা দল পার্সিং এবং ডেভেলপার-সম্মুখীন ফিচারগুলোর দিকে মনোযোগ দিতে পারে,
- একটি অপ্টিমাইজেশন দল একবার উন্নতি করে সেটি ব্যাপকভাবে শেয়ার করতে পারে,
- হার্ডওয়্যার সাপোর্ট যোগ করা যায় উপরের অংশগুলো পুনঃডিজাইন ছাড়াই।
এটা এখন স্পষ্ট মনে হয়, কিন্তু তখন অনেক প্রোডাকশন কম্পাইলারের বিবর্তনের পথে এটা বিরুদ্ধমুখী ছিল।
ওপেন সোর্স, অন্যদের ব্যবহারের জন্য তৈরি
LLVM দ্রুত ওপেন সোর্স হিসেবে মুক্তি পেয়েছিল, যা গুরুত্বপূর্ণ ছিল কারণ একটি ভাগ করা অবকাঠামো তখনই কাজ করে যখন বিভিন্ন গ্রুপ এটাতে বিশ্বাস করতে পায়, পরীক্ষা করে দেখতে পারে, এবং সম্প্রসারিত করতে পারে। সময়ের সঙ্গে বিশ্ববিদ্যালয়, কোম্পানি, এবং স্বাধীন অবদানকারীরা টার্গেট যোগ করে, কণিষ্ঠ কেস ফিক্স করে, পারফরম্যান্স উন্নত করে, এবং নতুন টুল তৈরিতে সাহায্য করেছে।
এই কমিউনিটি অংশ শুধুমাত্র সদিচ্ছা ছিল না—এটি ডিজাইনেরই একটি অংশ: কোরকে ব্যাপকভাবে ব্যবহৃত করার মতো বানাও, এবং একসাথে রক্ষণাবেক্ষণ করা মূল্যবান হয়ে উঠবে।
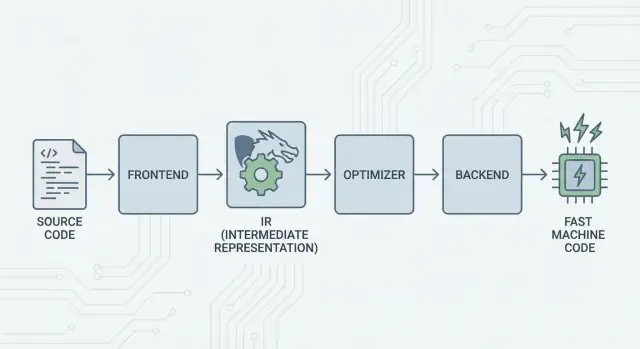
বড় ধারণা: ফ্রন্টএন্ড, একটি ভাগ করা কোর, এবং ব্যাকএন্ড
LLVM-এর মূল ধারণা সরল: কম্পাইলারকে তিনটি প্রধান অংশে ভাগ করা যাতে অনেক ভাষা সবচেয়ে কঠিন কাজগুলো ভাগ করে নিতে পারে।
1) ফ্রন্টএন্ড: “প্রোগ্রামার কী বলতে চেয়েছিল?”
একটি ফ্রন্টএন্ড একটি নির্দিষ্ট প্রোগ্রামিং ভাষা বুঝে। এটি আপনার সোর্স কোড পড়ে, নিয়ম (সিনট্যাক্স ও টাইপ) যাচাই করে, এবং সেটি একটি কাঠামোগত প্রতিনিধিত্বে রূপান্তর করে।
মুখ্য দিক: ফ্রন্টএন্ডকে প্রতিটি CPU বিস্তারিত জানতে হবে না। তাদের কাজ ভাষার ধারণাগুলো—ফাংশন, লুপ, ভ্যারিয়েবল—কিছুটা সাধারণ ফর্মে অনুবাদ করা।
2) ভাগ করা মধ্যভাগ: N×M কাজের বদলে একটি সাধারণ কোর
পরম্পরায়, একটি কম্পাইলার বানাতে একই কাজ বারবার করতেই হত:
- N ভাষা এবং M চিপ টার্গেট থাকলে, আপনি N×M সমন্বয় সমর্থন করতে হতেন।
LLVM এটাকে রূপান্তর করে:
- N ফ্রন্টএন্ড যা একটি ভাগ করা ফর্মে অনুবাদ করে
- M ব্যাকএন্ড যা সেই ভাগ করা ফর্ম থেকে মেশিন কোড তৈরি করে
এই “ভাগ করা ফর্ম” LLVM-এর কেন্দ্র: একটি সাধারণ পাইপলাইন যেখানে অপ্টিমাইজেশন ও বিশ্লেষণ থাকে। মধ্যভাগে করা উন্নতি (উত্তম অপ্টিমাইজেশন বা উন্নত ডিবাগিং ইনফো) অনেক ভাষার উপকার করে, প্রতিটি কম্পাইলারে আলাদা করে তা পুনরায় বাস্তবায়ন করার প্রয়োজন হয় না।
3) ব্যাকএন্ড: “কিভাবে এটাকে সেই CPU-তে দ্রুত চালাবো?”
একটি ব্যাকএন্ড ভাগ করা প্রতিনিধিত্ব নিয়ে নির্দিষ্ট মেশিন আউটপুট তৈরি করে: x86, ARM ইত্যাদি নির্দেশসমূহ। এখানে রেজিস্টার, কলিং কনভেনশন, এবং ইনস্ট্রাকশন সিলেকশনের মতো বিস্তারিত গুরুত্বপূর্ণ।
পাইপলাইনের একটি সূচকতাত্ত্বিক ছবি
কম্পাইলেশনকে ভ্রমণ রুট হিসেবে ভাবুন:
- সোর্স কোড ভাষা-নির্দিষ্ট দেশে শুরু করে (ফ্রন্টএন্ড)।
- এটি একটি ভাগ করা, স্ট্যান্ডার্ডাইজড “মিডল ল্যাঙ্গুয়েজ”-এ পাড়ি জায় (LLVM-এর কোর প্রতিনিধিত্ব ও পাস)।
- তারপর এটি একটি স্থানীয় ট্রেন সিস্টেমে যাত্রা করে নির্দিষ্ট গন্তব্য-শহরে পৌঁছায় (টার্গেট মেশিনের জন্য ব্যাকএন্ড)।
ফলাফল হচ্ছে একটি মডুলার টুলচেইন: ভাষাগুলো স্পষ্টভাবে ধারণা প্রকাশে ফোকাস করতে পারে, যখন LLVM-এর ভাগ করা কোর সেই ধারণাগুলোকে বহু প্ল্যাটফর্মে কার্যকরভাবে চালানোর দিকে কাজ করে।
LLVM IR: পুনরায় ব্যবহার সক্ষম করে এমন মধ্যস্তর
LLVM IR (Intermediate Representation) হল সেই “কমন ল্যাঙ্গুয়েজ” যা প্রোগ্রামিং ভাষা ও আপনার CPU-র মেশিন কোডের মাঝামাঝি থাকে।
একটি কম্পাইলার ফ্রন্টএন্ড (যেমন Clang C/C++ জন্য) আপনার সোর্স কোডকে এই ভাগ করা ফর্মে অনুবাদ করে। তারপর LLVM-এর অপ্টিমাইজার এবং কোড জেনারেটর IR-এ কাজ করে, না যে মূল ভাষায়। শেষে একটি ব্যাকএন্ড IR কে নির্দিষ্ট টার্গেট (x86, ARM ইত্যাদি) এর ইনস্ট্রাকশনে রূপান্তর করে।
টুল ও CPU-এর মধ্যে একটি সাধারণ ভাষা
LLVM IR-কে একটি সূক্ষ্মভাবে ডিজাইন করা সেতু হিসেবে ভাবুন:
- উপর: অনেক সোর্স ভাষা প্লাগ ইন করতে পারে (C, C++, Rust, Swift, Julia ইত্যাদি)।
- নিচে: অনেক CPU লক্ষ্য করা যায়।
- মধ্যერ: একই বিশ্লেষণ ও অপ্টিমাইজেশন টুলগুলো পুনরায় ব্যবহার করা যায়।
এই কারণে মানুষ প্রায়শই LLVM-কে “কম্পাইলার অবকাঠামো” বলে—IR হল সেই ভাগ করা চুক্তি যা ওই অবকাঠামোকে পুনঃব্যবহারযোগ্য করে তোলে।
কেন IR পুনরায় ব্যবহার সক্ষম করে (এবং সবার কাজ বাঁচায়)
একবার কোড LLVM IR-এ গেলে, বেশিরভাগ অপ্টিমাইজেশন পাসগুলোকে জানা জরুরি নেই যে কোড কোন ভাষা থেকে এসেছে—তারা সাধারণ ধারণাগুলি নিয়ে কাজ করে:
- “এই মানটি কনস্ট্যান্ট।”
- “এই হিসাব বারবার করা হচ্ছে; আমরা কি রিজাল্ট রিইউজ করতে পারি?”
- “এই মেমরি লোড নিরাপদে সরানো/সরানো যায়।”
তাই ভাষা দলগুলোকে তাদের নিজস্ব সম্পূর্ণ অপ্টিমাইজার স্ট্যাক বানাতে ও রক্ষণাবেক্ষণ করতে হবে না। তারা ফ্রন্টএন্ড—পার্সিং, টাইপ চেকিং, ভাষা-নির্দিষ্ট নিয়মে—মনোযোগ রেখে কেবল LLVM-কে ভারী কাজ হস্তান্তর করতে পারে।
ধারণাগতভাবে এটা কেমন দেখায়
LLVM IR মেশিন কোডে পরিষ্কারভাবে ম্যাপ করা যায় এমনভাবে পর্যাপ্ত নিম্ন-স্তরের, কিন্তু বিশ্লেষণযোগ্য পর্যাপ্ত গঠনযুক্ত। ধারণাগতভাবে, এটি সাধারণ ইনস্ট্রাকশন (add, compare, load/store), স্পষ্ট কন্ট্রোল ফ্লো (ব্রাঞ্চ) এবং শক্তিশালী-টাইপকৃত মানগুলো দিয়ে গঠিত—কম্পাইলারের জন্য ডিজাইন করা একটি পরিপাটি অ্যাসেম্বলি-র মতো, যা সাধারণত মানুষ সরাসরি লেখে না।
অপ্টিমাইজেশন কিভাবে কাজ করে (গাণিতিক ছাড়া)
“কম্পাইলার অপ্টিমাইজেশন” শুনলে অনেকেই রহস্যময় ট্রিক কল্পনা করে। LLVM-এ বেশিরভাগ অপ্টিমাইজেশনকে ভালোভাবে বোঝায় এমন নিরাপদ, যান্ত্রিক পুনর্লিখন — রূপান্তর যা প্রোগ্রামের আচরণ অপরিবর্তিত রেখে দ্রুততর বা ছোট আউটপুট লক্ষ্য করে।
এটা আবিস্কার করা নয়, সম্পাদনা করা মত
LLVM আপনার কোড (LLVM IR-এ) নিয়ে ছোট ছোট উন্নতি বারবার প্রয়োগ করে, অনেকটা একটি খসড়া পালিশ করার মতো:
- ডুপ্লিকেট কাজ সরানো: যদি কোনো মান দুইবার হিসাব করা হয় এবং মাঝখানে কিছু পরিবর্তন না হয়, LLVM সেটি একবার হিসাব করিয়ে ফল রিইউজ করতে পারে।
- স্পষ্ট লজিক সরল করা: কনস্ট্যান্ট এক্সপ্রেশন আগে থেকেই গোনা যায় (যেমন
3 * 4কে12করা), ফলে CPU রানটাইমে কম কাজ করে। - লুপ সামঞ্জস্য করা: লুপ-সংক্রান্ত পাসগুলো বারবার চেক কমানো, লুপের বাইরে ইনভারিয়ান্ট কাজ সরানো, বা এমন প্যাটার্ন চিনে নেওয়া যা দক্ষভাবে চালানো যায়।
এই পরিবর্তনগুলো সচেতনভাবে সংরক্ষণশীল—একটি পাস শুধুমাত্র তখনই রাইট করে যখন এটি প্রমাণ করতে পারে যে রাইটটি প্রোগ্রামের অর্থ পরিবর্তন করবে না।
সহজবোধ্য উদাহরণগুলো
আপনার প্রোগ্রামটি যদি ধারণাগতভাবে করে:
- প্রতিটি লুপ ইটারেশনে একই কনফিগারেশন মান পড়া
- একই ইনপুটে একই গণনা অনেক জায়গায় করা
- এমন একটি কন্ডিশন চেক করা যা নির্দিষ্ট প্রেক্ষাপটে সবসময় সত্য/মিথ্যা
…LLVM চেষ্টা করে সেটিকে “একবার সেটআপ করো”, “রেজাল্ট রিইউজ করো”, এবং “ডেড ব্রাঞ্চ মুছে ফেলো” তে রূপান্তর করতে। এটা বেশি জাদু নয়, বরং হাউসভাই কাজ।
বাস্তব ট্রেডঅফ: কম্পাইল সময় বনাম রানটাইম
অপ্টিমাইজেশন বিনামূল্যের নয়: বেশি বিশ্লেষণ ও বেশি পাস সাধারণত মানে ধীর কম্পাইলেশন, যদিও চূড়ান্ত প্রোগ্রাম দ্রুত চলে। এজন্য টুলচেইনগুলো লেভেল দেয়—“কিছুটা অপ্টিমাইজ কর” বনাম “ agressively অপ্টিমাইজ কর”।
প্রোফাইলও এখানে সাহায্য করে। প্রোফাইল-গাইডেড অপ্টিমাইজেশন (PGO)-এ, আপনি প্রোগ্রাম চালান, বাস্তব ব্যবহার ডেটা সংগ্রহ করেন, এবং তারপর পুনরায় কম্পাইল করেন যাতে LLVM সেই পাথগুলোতে বেশি মনোযোগ দেয় যা প্রকৃতপক্ষে গুরুত্বপূর্ণ—ট্রেডঅফকে আরো পূর্বানুমেয় করে।
ব্যাকএন্ড: সবকিছুকে পুনরায় লেখার ছাড়া বহু CPU স্পর্শ করা
প্রথম ভার্সনে পৌঁছান
দ্রুত প্রতিক্রিয়া চাইলে দ্রুত একটি ওয়েব, ব্যাকএন্ড, বা মোবাইল অ্যাপ প্রোটোটাইপ করুন।
একটি কম্পাইলারের দুটি ভিন্ন কাজ আছে। প্রথমে, এটি আপনার সোর্স কোড বুঝতে হবে। দ্বিতীয়ত, এটি এমন মেশিন কোড তৈরি করতে হবে যা নির্দিষ্ট একটি CPU চালাতে পারে। LLVM ব্যাকএন্ডগুলো দ্বিতীয় কাজের দিকে ফোকাস করে।
একটি ব্যাকএন্ড বাস্তবে কী করে
LLVM IR-কে একটি “সার্বজনীন রেসিপি” হিসেবে ধরুন। একটি ব্যাকএন্ড সেই রেসিপি নির্দিষ্ট প্রসেসর পরিবারের জন্য সঠিক নির্দেশে রূপান্তর করে—x86-64 ডেস্কটপ/সার্ভার, ARM64 মোবাইল ও নতুন ল্যাপটপ, বা WebAssembly-এর মতো স্পেশাল টার্গেট।
কনক্রীটভাবে, একটি ব্যাকএন্ড দায়িত্ব পালন করে:
- ইনস্ট্রাকশন সিলেকশন: IR অপারেশনগুলোকে আসল CPU ইনস্ট্রাকশনে ম্যাপ করা
- রেজিস্টার অ্যালোকেশন: কোন মানগুলো দ্রুত CPU রেজিস্টারে থাকবে বনাম মেমোরিতে
- স্কেজুলিং: ইনস্ট্রাকশনগুলো এমনভাবে বিন্যস্ত করা যাতে CPU কার্যকরভাবে চালাতে পারে
- অ্যাসেম্বলি/অবজেক্ট আউটপুট: লিঙ্কার ও OS যে কোড বুঝবে তা ইমিট করা
কেন ভাগ করা অবকাঠামো নতুন হার্ডওয়্যার সাপোর্ট সহজ করে
ভাগ করা কোর না থাকলে, প্রতিটি ভাষাকে প্রতিটি CPU-র জন্য সবকিছুই পুনরায় বাস্তবায়ন করতে হত—ইহা বিশাল কাজ এবং লাগাতার রক্ষণাবেক্ষণের বোঝা।
LLVM এটাকে উল্টে দেয়: ফ্রন্টএন্ড (যেমন Clang) একবার LLVM IR তৈরি করে, এবং ব্যাকএন্ডগুলো শেষ মাইলটি প্রতিটি টার্গেটের জন্য সামলায়। নতুন CPU সাপোর্ট যোগ করা সাধারণত একটিমাত্র ব্যাকএন্ড লেখার কথা (বা একটি বিদ্যমান ব্যাকএন্ড বাড়ানো), পুরো প্রতিটি কম্পাইলার পুনলিখতে হয় না।
বহুপ্ল্যাটফর্ম শিপিং দলের জন্য পোর্টেবিলিটি
যে প্রোজেক্টগুলোকে Windows/macOS/Linux, x86 ও ARM, বা এমনকি ব্রাউজারে চলতে হবে, তাদের জন্য LLVM-এর ব্যাকএন্ড মডেল একটি ব্যবহারিক সুবিধা। আপনি একটাই কোডবেস ও সাধারণত একটাই বিল্ড পাইপলাইন রাখতে পারেন, তারপর ভিন্ন ব্যাকএন্ড বেছে বা ক্রস-কম্পাইল করে লক্ষ্য নির্ধারণ করতে পারেন।
এই পোর্টেবিলিটি হল LLVM সব জায়গায় দেখা যাওয়ার কারণ: এটা কেবল গতি নয়—এটি পুনরাবৃত্তি-ভিত্তিক প্ল্যাটফর্ম-নির্দিষ্ট কম্পাইলার কাজ বাদ দেয়, যা দলগুলোকে ধীর করে।
Clang: যেখানে অনেক ডেভেলপার প্রথমবার LLVM অনুভব করে
Clang হল C, C++, এবং Objective-C-এর ফ্রন্টএন্ড যাতে LLVM-এ প্লাগ করে। যদি LLVM একটি ভাগ করা ইঞ্জিন হয় যা অপ্টিমাইজ ও মেশিন কোড জেনারেট করে, তবে Clang সেই অংশ যা আপনার সোর্স ফাইল পড়ে, ভাষার নিয়মগুলো বোঝে, এবং যা আপনি লিখেছেন সেটা LLVM কাজ করার মতো ফর্মে রূপান্তর করে।
কেন Clang নজরে এল
অনেক ডেভেলপাররা কম্পাইলার পেপার পড়ে LLVM খুঁজে পায়নি—তারা প্রথমবার যখন কম্পাইলার বদলে দেখেছেন তখনই লক্ষ্য করেছেন যে প্রতিক্রিয়া হঠাৎ উন্নত হয়েছে।
Clang-এর ডায়াগনস্টিকগুলো পাঠযোগ্য এবং নির্দিষ্ট হওয়ার জন্য পরিচিত। অস্পষ্ট এররের পরিবর্তে, এটি প্রায়ই সেই সঠিক টোকেন দেখায় যা সমস্যার কারণ ও কী আশা করা হচ্ছিল তা ব্যাখ্যা করে। দৈনন্দিন কাজের ক্ষেত্রে এটি গুরুত্বপূর্ণ—"কম্পাইল, ঠিক করা, রিপিট" লুপটি কম হতাশাজনক করে তোলে।
Clang পরিষ্কার, ডকুমেন্টেড ইন্টারফেস (বিশেষত libclang ও বিস্তৃত Clang টুলিং ইকোসিস্টেম)ও exposes করে। এতে এডিটর, IDE, এবং অন্যান্য ডেভেলপার টুলগুলোকে গভীর ভাষা-বুঝার সঙ্গে ইন্টিগ্রেট করা সহজ হয়, পুরো C/C++ পার্সার পুনরায় তৈরি না করেই।
এটি দৈনন্দিন ওয়ার্কফ্লোতে কিভাবে আসে
একবার কোনো টুল নির্ভরযোগ্যভাবে আপনার কোড পার্স ও বিশ্লেষণ করতে পারে, আপনি এমন ফিচার পাবেন যা টেক্সট এডিটিং-এর চেয়ে বেশি স্ট্রাকচার্ড প্রোগ্রামের সাথে কাজ করার মতো লাগে:
- বড়, ম্যাক্রো-ভরক C++ প্রকল্পেও যথাযথ কোড নেভিগেশন ("jump to definition", "find references")
- রিফ্যাক্টরিং সাপোর্ট যা সিম্বল ও স্কোপ বুঝে, শুধু সার্চ-এন্ড-রিপ্লেস নয়
- ইনলাইন হিন্ট ও কুইক ফিক্সেস যা সঠিক সিনট্যাক্স ও টাইপ তথ্য দ্বারা চালিত
এই কারণেই Clang প্রায়ই LLVM-এর প্রথম "টাচ পয়েন্ট": যেখানে ব্যবহারিক ডেভেলপার এক্সপেরিয়েন্সের উন্নতি শুরু হয়। আপনি যদি কখনো LLVM IR বা ব্যাকএন্ড ভাবেন না, তবুও আপনার এডিটরের স্মার্ট অটোকমপ্লিট, স্ট্যাটিক চেকস, ও বিল্ড এররগুলি সহজে কাজ করার কারণে আপনি উপকৃত হন।
কেন অনেক আধুনিক ভাষা LLVM-এর ওপর তৈরি করে
LLVM ভাষা দলগুলোর কাছে আকর্ষণীয় কারণ এটি তাদেরকে ভাষার উপরই ফোকাস করতে দেয়, পুরো একটি অপ্টিমাইজিং কম্পাইলার পুনর্লিখে সময় নষ্ট না করে।
বাজারে দ্রুত পৌঁছানো
একটি নতুন ভাষা তৈরি করা ইতিমধ্যেই পার্সিং, টাইপ-চেকিং, ডায়াগনস্টিকস, প্যাকেজ টুলিং, ডকুমেন্টেশন, এবং কমিউনিটি সাপোর্ট প্রয়োজন। যদি আপনাকে একই সঙ্গে প্রোডাকশন-গ্রেড অপ্টিমাইজার, কোড জেনারেটর, এবং প্ল্যাটফর্ম সাপোর্টও শূন্য থেকে করতে হয়, শিপিং বিলম্বিত হয়—কখনও কখনও বছরে।
LLVM একটি প্রস্তুত কম্পাইলেশন কোর দেয়: রেজিস্টার অ্যালোকেশন, ইনস্ট্রাকশন সিলেকশন, পরিণত অপ্টিমাইজেশন পাস, এবং সাধারণ CPU-গুলোর জন্য টার্গেট। দলগুলো একটি ফ্রন্টএন্ড প্লাগ ইন করে তাদের ভাষাকে LLVM IR-এ নামিয়ে দিতে পারে, তারপর বিদ্যমান পাইপলাইনকে ব্যবহার করে macOS, Linux, ও Windows-এর জন্য নেটিভ কোড উৎপাদন করতে পারে।
উচ্চ পারফরম্যান্স (বিনা ‘হিরোইকস’)
LLVM-এর অপ্টিমাইজার ও ব্যাকএন্ড দীর্ঘমেয়াদী ইঞ্জিনিয়ারিং ও বাস্তব-জগত পরীক্ষায় উন্নত। তার ফলে LLVM গ্রহণ করা ভাষাগুলোর জন্য শক্তিশালী বেসলাইন পারফরম্যান্স মিলে—প্রাথমিক পর্যায়েই যথেষ্ট ভাল, এবং LLVM উন্নত হওয়ার সঙ্গে উন্নতি করা সম্ভব।
এই কারণেই কয়েকটি পরিচিত ভাষা এর চারপাশে নির্মাণ করেছে:
- Swift LLVM ব্যবহার করে Apple প্ল্যাটফর্মগুলোর জন্য উচ্চ-অপ্টিমাইজড নেটিভ বাইনারি জেনারেট করতে।
- Rust কোড জেনারেশন ও বিভিন্ন আর্কিটেকচারের জন্য LLVM-র ওপর নির্ভর করে।
- Julia দ্রুত সংখ্যাসূচক কোড সক্ষম করতে LLVM ব্যবহার করে, runtime কম্পাইলেশনসহ বিশেষায়িত ওয়ার্কলোডের জন্য।
প্রতিটি ভাষায় LLVM লাগবেই এমন নয়
LLVM বেছে নেওয়া একটি ট্রেডঅফ; এটি বাধ্যতামূলক নয়। কিছু ভাষা ছোট বাইনারি, অতিবার্ষিক দ্রুত কম্পাইলেশন, বা পুরো টুলচেইনের পূর্ণ নিয়ন্ত্রণ পছন্দ করে। অন্যরা ইতিমধ্যেই প্রতিষ্ঠিত কম্পাইলার (যেমন GCC-ভিত্তিক) রাখে বা সরল ব্যাকএন্ড পছন্দ করে।
LLVM জনপ্রিয় কারণ এটি ঠিকঠাক একটি শক্তিশালী ডিফল্ট—সব ভাষার জন্য একমাত্র সঠিক পথ নয়।
JIT ও রানটাইম কম্পাইলেশন: দ্রুত ফিডব্যাক লুপ
নিরাপদ পুনরাবৃত্তি
বড় পরিবর্তনের আগে একটি চেকপয়েন্ট সেভ করুন যাতে আত্মবিশ্বাস নিয়ে রিভার্ট করা যায়।
"Just-in-time" (JIT) কম্পাইলেশন সহজভাবে ভাবলে হল রানটাইমে কম্পাইল করা। সব কোড আগেই অনুবাদ না করে, একটি JIT ইঞ্জিন সেই অংশটি তখনই কম্পাইল করে যখন সেটি কার্যত প্রয়োজন হয়—প্রায়ই বাস্তব রানটাইম তথ্য (যেমন নির্দিষ্ট টাইপ বা ডেটার সাইজ) ব্যবহার করে ভাল সিদ্ধান্ত নেয়।
কেন JIT এত দ্রুত মনে হতে পারে
কারণ আপনি সবকিছু আগে কম্পাইল করতে হয় না, JIT সিস্টেম ইন্টারেক্টিভ কাজের জন্য দ্রুত ফিডব্যাক দিতে পারে। আপনি একটি কোড স্নিপেট চালান, সিস্টেম তা সঙ্গে সঙ্গে কম্পাইল করে, এবং যদি একই কোড বারবার চলে তবে JIT কম্পাইল্ড ফলটি ক্যাশ বা "হট" সেকশনগুলো আরো আগ্রাসীভাবে রিকম্পাইল করতে পারে।
বাস্তবে রানটাইম কম্পাইলেশন কোথায় সাহায্য করে
JIT ডায়নামিক বা ইন্টারেক্টিভ ওয়ার্কলোডে জ্বলে:
- REPL ও নোটবুক: টুকরো টুকরো কোড তৎক্ষণাত মূল্যায়ন করে অপরদিকে ভারী লুপগুলোর জন্য নেটিভ-স্পিড এক্সিকিউশন দেয়।
- প্লাগইন ও এক্সটেনশন: অ্যাপ্লিকেশনগুলি রUNTIME-এ ইউজার কোড লোড করে এবং হোস্ট CPU অনুযায়ী কম্পাইল করতে পারে।
- ডায়নামিক ওয়ার্কলোড: ইনপুট বহুবিধ হলে রানটাইম প্রোফাইলিং নির্দেশ করে কোন পথে অপ্টিমাইজেশন প্রয়োজন।
- সায়েন্টিফিক কম্পিউটিং: জেনারেটেড কার্নেল (নির্দিষ্ট মেট্রিক্স সাইজ, মডেল শেইপ, বা হার্ডওয়্যার ফিচার) ডিমান্ডে কম্পাইল করা যায়।
LLVM-এর ভূমিকা (হাইপ ছাড়া)
LLVM নিজে সমস্ত প্রোগ্রামকে জাদুকরভাবে দ্রুত করে না, এবং এটি নিজে সম্পূর্ণ JIT নয়। যা এটি দেয় তা হল একটি টুলকিট: একটি সুসংজ্ঞায়িত IR, বিস্তৃত অপ্টিমাইজেশন পাস, এবং বহু CPU-এর জন্য কোড জেনারেশন। প্রকল্পগুলো এই বিল্ডিং ব্লকের উপরে JIT ইঞ্জিন গড়ে তুলতে পারে, যেখানে স্টার্টআপ টাইম, শীর্ষ পারফরম্যান্স, এবং জটিলতার মধ্যে সঠিক ট্রেডঅফ বেছে নেওয়া হয়।
পারফরম্যান্স, পূর্বানুমেয়তা, এবং বাস্তব-জগত ট্রেডঅফ
LLVM-ভিত্তিক টুলচেইন খুব দ্রুত কোড তৈরি করতে পারে—কিন্তু “দ্রুত” একটি অক্ষরনিয়ত সম্পত্তি নয়। এটি নির্ভর করে নির্দিষ্ট কম্পাইলার সংস্করণ, টার্গেট CPU, অপ্টিমাইজেশন সেটিংস, এবং এমনকি আপনি কম্পাইলারকে প্রোগ্রামের সম্পর্কে কী অনুমান করতে বলছেন তার উপর।
কেন "একই সোর্স, ভিন্ন ফল" ঘটে
দুইটি কম্পাইলার একই সোর্স পড়েও ভিন্ন মেশিন কোড জেনারেট করতে পারে। এর কিছু অংশই সচেতনভাবে: প্রতিটি কম্পাইলারের নিজস্ব পাস, হিউরিস্টিক, এবং ডিফল্ট সেটিংস থাকে। এমনকি LLVM-এর মধ্যে Clang 15 ও Clang 18 বিভিন্ন ইনলাইনিং সিদ্ধান্ত নিতে পারে, বিভিন্ন লুপ ভেক্টরাইজ করতে পারে, বা আলাদা ভাবে ইনস্ট্রাকশন শিডিউল করতে পারে।
এটা কখনও কখনও অসম্পূর্ণ আচরণ (undefined behavior) ও অবিশিষ্ট আচরণ (unspecified behavior)-এর কারণে হতে পারে। যদি আপনার প্রোগ্রাম এমন কোনো জিনিস নির্ভর করে যা স্ট্যান্ডার্ড গ্যারান্টি দেয় না (যেমন C-তে সাইনড ওভারফ্লো), তাহলে বিভিন্ন কম্পাইলার বা ফ্ল্যাগ ভিন্নভাবে "অপ্টিমাইজ" করে ফল বদলে দিতে পারে।
ডিটারমিনিজম, ডিবাগ ও রিলিজ বিল্ড
লোকেরা প্রায়ই আশা করে কম্পাইলেশন ডিটারমিনিস্টিক হবে: একই ইনপুট, একই আউটপুট। বাস্তবে, আপনি কাছাকাছি পাবেন, কিন্তু সবসময় একই বাইনারি পাবেন না। বিল্ড পাথ, টাইমস্ট্যাম্প, লিঙ্ক অর্ডার, PGO ডেটা, এবং LTO পছন্দগুলো চূড়ান্ত আর্টিফ্যাক্টকে প্রভাবিত করতে পারে।
বড়, ব্যবহৃত পার্থক্য হল ডিবাগ বনাম রিলিজ। ডিবাগ বিল্ড সাধারণত অনেক অপ্টিমাইজেশন নিষ্ক্রিয় করে যাতে ধাপে ধাপে ডিবাগিং ও পড়ার যোগ্য স্ট্যাক ট্রেস রাখা যায়। রিলিজ বিল্ড আগ্রাসী রূপান্তর সক্রিয় করে যা কোড রিটার, ইনলাইনিং, ভ্যারিয়েবল অপসারণ করে—পারফরম্যান্সের জন্য চমৎকার, কিন্তু ডিবাগিং কঠিন করতে পারে।
ব্যবহারিক পরামর্শ: অনুমান নয়, পরিমাপ করুন
পারফরম্যান্সকে একটি মাপার সমস্যা হিসেবে দেখুন:
- প্রাতিনিধিক হার্ডওয়্যার ও বাস্তবসম্মত ডেটাসেট ব্যবহার করে বেঞ্চমার্ক করুন।
- ক্যাশ ওয়ার্ম আপ করুন এবং একাধিক ইটারেশন চালান।
- স্পষ্ট ফ্ল্যাগ দিয়ে বিল্ড তুলনা করুন (উদাহরণস্বরূপ
-O2বনাম-O3, LTO চালু/বন্ধ, বা-marchদিয়ে টার্গেট নির্ধারণ)।
ছোট ফ্ল্যাগ পরিবর্তনও পারফরম্যান্সকে উভয় দিকে সরাতে পারে। নিরাপদ কর্মপ্রবাহ: একটি হাইপোথেসিস নিন, তা পরিমাপ করুন, এবং ব্যবহারকারীর বাস্তব চালনার কাছাকাছি বেঞ্চমার্ক রাখুন।
কম্পাইলেশনের বাইরের টুলিং: বিশ্লেষণ, ডিবাগিং, ও সুরক্ষা
আপনার গতিতে স্কেল করুন
আপনি কতদূর নিয়ে যেতে চান তার উপর ভিত্তি করে Free, Pro, Business, বা Enterprise বেছে নিন।
LLVM প্রায়ই একটি কম্পাইলার টুলকিট হিসেবে বর্ণিত হয়, তবে অনেক ডেভেলপার এর প্রভাব টুলগুলোয়ের মাধ্যমে অনুভব করে যা কম্পাইলেশনের "চতুর্পাশে" বসে: বিশ্লেষক, ডিবাগার, এবং টেস্টিং চলাকালে চালু করা সেফটি চেক।
বিশ্লেষণ ও ইনস্ট্রুমেন্টেশন একধরনের "অ্যাড-অন"
কারণ LLVM একটি সুশৃঙ্খল IR ও পাস পাইপলাইন এক্সপোজ করে, তাই এমন অতিরিক্ত ধাপ তৈরি করা স্বাভাবিক যে কোড পরীক্ষা বা পুনর্লিখন করে পারফরম্যান্স ছাড়া অন্য উদ্দেশ্যে। একটি পাস প্রোফাইলিংয়ের জন্য কাউন্টার সন্নিবেশ করতে পারে, সন্দেহজনক মেমরি অপারেশন চিহ্নিত করতে পারে, বা কভারেজ ডেটা সংগ্রহ করতে পারে।
মুখ্য বিষয় হলো: এই ফিচারগুলো ভাষা দলগুলোকে প্রতিটি নিজে প্লাম্বিং পুনরায় তৈরি না করে ইনটিগ্রেট করতে দেয়।
স্যানিটাইজার: বাগ ধরা সফটওয়্যার লাইফসাইকেলে
Clang ও LLVM স্যানিটাইজার পরিবারের জনপ্রিয়তা বাড়িয়েছে, যা রানটাইমে ইনস্ট্রুমেন্ট করে পরীক্ষার সময় সাধারণ বাগ ধরতে সাহায্য করে—আউট-অফ-বাউন্ডস মেমরি অ্যাক্সেস, ইউজ-আফ্টার-ফ্রি, ডাটা রেস, এবং অনিবার্য আচরণ প্যাটার্ন। এগুলো যাদুকর্য নয় এবং সাধারণত প্রোগ্রামকে ধীর করে, তাই সেগুলো মূলত CI ও প্রি-রিলিজ টেস্টিংয়ে ব্যবহার করা হয়। কিন্তু যখন স্যানিটাইজার ট্রিগার করে, তারা প্রায়ই নির্দিষ্ট সোর্স লোকেশন ও পড়ার যোগ্য ব্যাখ্যা দেয়—এটাই দুর্লভ ইন্টারমিটেন্ট ক্র্যাশ অন্বেষণের সময় দলের দরকার।
উন্নত ডায়াগনস্টিক = দ্রুত অনবোর্ডিং
টুলিং মান কেবল প্রযুক্তিগত নয়, এটি যোগাযোগ সম্পর্কেও। পরিষ্কার ও বাস্তবসম্মত ওয়ার্নিং, কার্যকর এরর মেসেজ, এবং ধারাবাহিক ডিবাগ ইনফো নতুনদের জন্য রহস্যকে কমায়। যখন টুলচেইন ব্যাখ্যা করে কি ঘটেছে এবং কিভাবে ঠিক করা যায়, ডেভেলপাররা কম সময় কাটায় কম্পাইলার কৌতুক শিখে এবং বেশি সময় শেখা ও কোডে ব্যয় করে।
LLVM নিজেরাই নিখুঁত ডায়াগনস্টিক বা সুরক্ষা গ্যারান্টি দেয় না, কিন্তু এটি একটি সাধারণ ভিত্তি প্রদান করে যা এই ডেভেলপার-মুখী টুলগুলো তৈরি, রক্ষণাবেক্ষণ, ও ভাগ করা সহজ করে তোলে।
কখন LLVM ব্যবহার করবেন (এবং কখন নয়)
LLVM-কে শ্রেষ্ঠভাবে ভাবা যায় একটি "আপনি-নিজে-আপনার-কম্পাইলার-ও-টুলিং-কিট বানান" হিসেবে। এই নমনীয়তাই অনেক আধুনিক টুলচেইনকে চালায়—কিন্তু ঠিক এই কারণেই এটি প্রতিটি প্রজেক্টের সঠিক উত্তর নয়।
কখন LLVM উপযুক্ত
LLVM তখনই উজ্জ্বল যখন আপনি গুরুতর কম্পাইলার ইঞ্জিনিয়ারিং পুনরায় লিখতে না চাইলে তা পুনরায় ব্যবহার করতে চান।
আপনি যদি একটি নতুন প্রোগ্রামিং ভাষা বানান, LLVM আপনাকে একটি প্রমাণিত অপ্টিমাইজেশন পাইপলাইন, বহু CPU জন্য পাকা কোড জেনারেশন, এবং ভাল ডিবাগ সমর্থনের পথ দিতে পারে।
আপনি যদি ক্রস-প্ল্যাটফর্ম অ্যাপ্লিকেশন শিপ করেন, LLVM-এর ব্যাকএন্ড ইকোসিস্টেম বিভিন্ন আর্কিটেকচারের জন্য কাজ করা কন্ট্রিবিউশন কমিয়ে দেয়। আপনি ভাষা বা প্রোডাক্ট লজিকের দিকে বেশি মনোযোগ দিতে পারেন, আলাদা কোড জেনারেটর লেখার বদলে।
আপনি যদি ডেভেলপার টুলিং—লিন্টার, স্ট্যাটিক বিশ্লেষণ, কোড নেভিগেশন, রিফ্যাক্টরিং—চাইতে থাকেন, LLVM (ও তার পার্শ্ববর্তী ইকোসিস্টেম) একটি শক্তিশালী ভিত্তি কারণ কম্পাইলার ইতিমধ্যেই কোডের গঠন ও টাইপ বুঝে।
কখন এটা অতিরিক্তভারী হতে পারে
LLVM ভারী হতে পারে যদি আপনি নানো এমবেডেড সিস্টেম নিয়ে কাজ করেন যেখানে বিল্ড সাইজ, মেমরি, এবং কম্পাইল টাইম খুবই সীমাবদ্ধ।
এটি খারাপ মানায় যদি আপনার পাইপলাইন খুবই বিশেষায়িত এবং আপনি সাধারণ উদ্দেশ্য অপ্টিমাইজেশনের দরকার না মনে করেন, বা আপনার ভাষা কোনো সরল ডিএসল (DSL) যার সরাসরি-টু-মেশিন-ম্যাপিংই যথেষ্ট।
একটি সহজ চেকলিস্ট
এই তিনটি প্রশ্ন জিজ্ঞাসা করুন:
- আমরা কি একাধিক প্ল্যাটফর্ম/CPU লক্ষ্য করতে চাই এখন বা শীঘ্রই?
- আমরা কি বিদ্যমান অপ্টিমাইজেশন ও ডিবাগ ইনফো থেকে লাভবন্ত হব, নিজেরা তৈরির চেয়ে?
- আমরা কি একটি ইকোসিস্টেম পথ (টুলিং, ইন্টিগ্রেশন, ভাড়াভর্তি) চাই, না কি একটি সর্বনিম্ন কাস্টম কম্পাইলার?
যদি অধিকাংশ প্রশ্নে আপনি “হ্যাঁ” বলেন, LLVM সাধারণত ব্যবহারিক পছন্দ। যদি আপনি মূলত সবচেয়ে ছোট, সবচেয়ে সরল কম্পাইলার চান যা একটুখানি কাজ সমাধান করে, একটি লাইটওয়েট পদ্ধতি জয়ী হতে পারে।
প্রোডাক্ট টিমের জন্য ব্যবহারিক নোট: LLVM-এর সুবিধা, কম্পাইলার বিশেষজ্ঞ হয়ে উঠতে না গিয়েই
অধিকাংশ দল "LLVM গ্রহণ"কে একটি প্রকল্প হিসেবে নিতে চায় না। তারা ফলাফল চায়: ক্রস-প্ল্যাটফর্ম বিল্ড, দ্রুত বাইনারি, ভালো ডায়াগনস্টিক, এবং নির্ভরযোগ্য টুলিং।
এই কারণেই এমন প্ল্যাটফর্মগুলো (যেমন Koder.ai) প্রাসঙ্গিক। আপনার ওয়ার্কফ্লো যদি উচ্চ-স্তরের অটোমেশন (পরিকল্পনা, স্ক্যাফোল্ডিং, দ্রুত লুপে ইটারেশন) দ্বারা চালিত হয়, আপনি তখনও LLVM থেকে পরোক্ষভাবে লাভ পান—সরাসরি না হলেও আপনার টুলচেইনের নিচে থাকা LLVM/Clang ও বন্ধুদের মাধ্যমে। Koder.ai-এর চ্যাট-চালিত “vibe-coding” পদ্ধতি প্রোডাক্ট দ্রুত শিপিংয়ের দিকে ফোকাস করে, আর আধুনিক কম্পাইলার অবকাঠামো (যেখানে প্রযোজ্য) অপ্টিমাইজেশন, ডায়াগনস্টিক, এবং পোর্টেবিলিটির অপ্রশংসিত কাজ করে পটভূমিতে।