২৪ অক্টো, ২০২৫·8 মিনিট
কেন ডাটাবেস ইনডেক্সিং হল সবচেয়ে গুরুত্বপূর্ণ পারফরম্যান্স বুস্ট
জানুন কীভাবে ডাটাবেস ইনডেক্স কোয়েরি সময় কমায়, কখন তা সাহায্য করে (এবং কখন ক্ষতি করে), এবং বাস্তব অ্যাপে ইনডেক্স ডিজাইন, টেস্ট ও রক্ষণাবেক্ষণের পদক্ষেপ।
জানুন কীভাবে ডাটাবেস ইনডেক্স কোয়েরি সময় কমায়, কখন তা সাহায্য করে (এবং কখন ক্ষতি করে), এবং বাস্তব অ্যাপে ইনডেক্স ডিজাইন, টেস্ট ও রক্ষণাবেক্ষণের পদক্ষেপ।
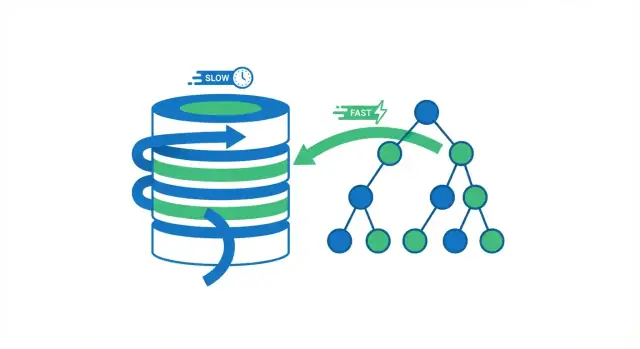
ডাটাবেস ইনডেক্সটি একটি আলাদা লুকআপ স্ট্রাকচার যা ডাটাবেসকে সারি দ্রুত খুঁজতে সাহায্য করে। এটা আপনার টেবিলের একটি সম্পূর্ণ কপি নয়। বইয়ের ইনডেক্সের মত ভাবুন: আপনি ইনডেক্স ব্যবহার করে প্রায় সঠিক স্থানে লাফ দেন, তারপর নির্দিষ্ট পৃষ্ঠা (সারি) পড়েন যা দরকার।
ইনডেক্স না থাকলে ডাটাবেসের কাছে সাধারণত একটি নিরাপদ অপশনই থাকে: অনেক সারি ধরে পড়ে দেখে কোনগুলো কিউরির সঙ্গে মিলছে। এটি কয়েক হাজার সারির টেবিলের জন্য ঠিক আছে। কিন্তু টেবিল যখন মিলিয়ন সারিতে পৌঁছায়, “আরও সারি চেক করা” মানে আরও ডিস্ক রিড, আরও মেমোরি চাপ, এবং বেশী সিপিইউ কাজ—তাই একই কিউরি যা আগে লাইট ফিল করত, ধীর হয়ে যায়।
ইনডেক্সগুলো এমনভাবে কাজ করে যে ডাটাবেসকে প্রতি প্রশ্নে পরীক্ষা করতে কম ডেটা লাগবে — যেমন “ID 123 অর্ডারটি খুঁজে বের কর” বা “এই ইমেইলের ইউজারগুলো আন।” টেবিল স্ক্যান করার বদলে, ডাটাবেস একটি কম্প্যাক্ট স্ট্রাকচার অনুসরণ করে দ্রুত সার্চ সংকুচিত করে।
কিন্তু ইনডেক্স সব সমস্যার সমাধান নয়। কিছু কিউরি এখনও অনেক সারি প্রসেস করতে হবে (বৃহৎ রিপোর্ট, কম সিলেক্টিভিটি ফিল্টার, ভারী অ্যাগ্রেগেশন)। এবং ইনডেক্সের বাস্তব খরচ আছে: অতিরিক্ত স্টোরেজ এবং ধীর রাইট, কারণ ইনসার্ট ও আপডেটগুলোকেও ইনডেক্স আপডেট করতে হয়।
আপনি জানবেন:
যখন ডাটাবেস একটি কিউরি চালায়, তখন তার দুইটি বড় অপশন আছে: পুরো টেবিল সারি বাই সারি স্ক্যান করা, অথবা সরাসরি মিল থাকা সারিগুলোতে লাফ দেয়া। অধিকাংশ ইনডেক্স গেইন হয় অপ্রয়োজনীয় রিড কমানোর ফলে।
একটি ফুল টেবিল স্ক্যান ঠিক যেটা নাম থেকে বোঝায়: ডাটাবেস প্রতিটি সারি পড়ে, দেখে সেটা WHERE কন্ডিশনের সাথে মিলছে কি না, এবং তারপর ফলাফল দেয়। ছোট টেবিলের জন্য এটা গ্রহণযোগ্য, কিন্তু টেবিল বাড়ার সাথে সাথে ধীর হয়ে যায় — সারি বাড়লে কাজও বাড়ে।
ইনডেক্স ব্যবহার করলে, ডাটাবেস প্রায়ই বেশিরভাগ সারি পড়া এড়িয়ে যেতে পারে। পরিবর্তে, এটি প্রথমে ইনডেক্স দেখে (একটি সন্ধানযোগ্য কম্প্যাক্ট স্ট্রাকচার) যেখানে মিল থাকা সারিগুলো আছে, তারপর কেবল সেই নির্দিষ্ট সারিগুলো পড়ে।
একটি বইয়ের কথা ভাবুন। যদি আপনি "photosynthesis" উল্লেখ করা প্রতিটি পৃষ্ঠা দেখতে চান, পুরো বই পড়তে পারেন (ফুল স্ক্যান)। অথবা বইয়ের ইনডেক্স ব্যবহার করে তালিকাভুক্ত পৃষ্ঠাগুলোতে লাফ দিন এবং কেবল সেই অংশগুলো পড়ুন (ইনডেক্স লুকআপ)। দ্বিতীয় পদ্ধতি দ্রুত, কারণ আপনি প্রায় সব পৃষ্ঠা বাদ দিচ্ছেন।
ডাটাবেসগুলি অনেক সময় পড়ার জন্য অপেক্ষায় কাটায়—বিশেষত যখন ডেটা মেমরিতে না থাকে। যে সারি (এবং পেজ) ডাটাবেসকে টাচ করতে হয় তা কমানো সাধারণত কমায়:
ইনডেক্স তখনই সাহায্য করে যখন ডেটা বড় এবং কিউরি প্যাটার্ন সিলেক্টিভ (উদাহরণ: ১০ মিলিয়ন থেকে ২০ মিলিয়ন মিলানো সারি ফেরত দেয়ার বদলে ২০টি সারি)। যদি আপনার কিউরি সব সারিই ফেরত দেয় বা টেবিলটি ছোটভাবে মেমরিতে সহজে থাকে, ফুল স্ক্যান সমান দ্রুত বা দ্রুততর হতে পারে।
ইনডেক্সগুলো কাজ করে কারণ তারা মানগুলোকে এমনভাবে সাজায় যাতে ডাটাবেস প্রতিটি সারি পরীক্ষা না করে প্রয়োজনীয় স্থানে লাফ দিতে পারে।
SQL ডাটাবেসে সবচেয়ে সাধারণ ইনডেক্স স্ট্রাকচার হল B-tree (বা “B+tree”)। ধারণাগতভাবে:
সাজানোর কারণে, B-tree সমানভাবে ভাল কাজ করে সমানতা লুকআপ (WHERE email = ...) এবং রেঞ্জ কিউরি (WHERE created_at \u003e= ... AND created_at \u003c ...) উভয়ের জন্য। ডাটাবেস ঠিক এলাকায় নেভিগেট করে এবং তারপর অর্ডার ধরে এগিয়ে পড়তে পারে।
মানুষ বললে B-tree লুকআপ "লগারিদমিক" — ব্যবহারিকভাবে এর মানে: টেবিল হাজার থেকে মিলিয়নে বাড়লে, একটি মান খুঁজতে ধাপগুলো ধীরে ধীরে বাড়ে, পুরোপুরি গুণানুপাতে নয়। বড় ডেটা মানে অবশ্যই অতটা বেশি কাজ নয়, কারণ ডাটাবেস গাছের কয়েকটি স্তর পয়েন্টার অনুসরণ করে দ্রুত পৌঁছায়।
কিছু ইঞ্জিন হ্যাশ ইনডেক্স দেয়। এগুলো এক্স্যাক্ট ইকোয়ালিটির জন্য খুব দ্রুত হতে পারে কারণ মানকে হ্যাশ করে সরাসরি এন্ট্রিতে পৌঁছানো হয়।
ট্রেডঅফ: হ্যাশ ইনডেক্স সাধারণত রেঞ্জ বা অর্ডারড স্ক্যানে সাহায্য করে না, এবং ডাটাবেস অনুযায়ী উপলব্ধতা/বিহেভিয়ার ভিন্ন।
PostgreSQL, MySQL/InnoDB, SQL Server ইত্যাদি ইনডেক্স সংরক্ষণ ও ব্যবহার আলাদা করে (পেজ সাইজ, ক্লাস্টারিং, ইনক্লুডেড কলামস, ভিজিবিলিটি চেকস)। কিন্তু মূল ধারণা একই: ইনডেক্স একটি কম্প্যাক্ট, নেভিগেবল স্ট্রাকচার তৈরি করে যা ডাটাবেসকে মিল থাকা সারি কম কাজ করে খুঁজতে দেয়।
ইনডেক্স সাধারণভাবে “SQL” কে দ্রুত করে না—এটা নির্দিষ্ট অ্যাক্সেস প্যাটার্নগুলোকে দ্রুত করে। যখন ইনডেক্স আপনার কিউরির ফিল্টার, জয়েন, বা সোর্টের সাথে মিলে যায়, ডাটাবেস প্রাসঙ্গিক সারিগুলোতে সরাসরি লাফ দিতে পারে।
1) WHERE ফিল্টার (বিশেষত সিলেক্টিভ কলামগুলোতে)
যদি আপনার কিউরি প্রায়ই একটি বড় টেবিলকে ছোট সারিসেটে সংকুচিত করে, ইনডেক্স সাধারণত প্রথম জিনিস হওয়া উচিত। যেমন ব্যবহারকারী আইডি দিয়ে খোঁজা।
users.email-এ ইনডেক্স না থাকলে, ডাটাবেসকে প্রতিটি সারি স্ক্যান করতে হতে পারে:
SELECT * FROM users WHERE email = '[email protected]';
email-এ ইনডেক্স থাকলে এটি দ্রুত মিলতে পারে এবং বন্ধ করতে পারে।
2) JOIN কী (ফরেন কিজ এবং referenced কী)
জয়েনগুলোতে ছোট অনুকূলতা বড় খরচে পরিণত হয়। যদি আপনি orders.user_id কে users.id এর সাথে যোগ করেন, তখন জয়েন কলামগুলো (সাধারণত orders.user_id এবং প্রাইমারি কী users.id) ইনডেক্স করলে ডাটাবেস বারবার স্ক্যান না করেই ম্যাচ করতে পারে।
3) ORDER BY (যখন আপনি ফলাফল সাজানোই চান)
সার্ট করা ব্যয়বহুল যখন ডাটাবেসকে অনেক সারি সংগ্রহ করে পরে সেগুলো সোজানো লাগে। যদি আপনি প্রায়ই চালান:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
তবে user_id এবং সাজানোর কলাম created_at মিল রেখে একটি ইনডেক্স ইঞ্জিনকে পৌঁছতে দেয় যাতে বড় মধ্যবর্তী ফলাফল সাজাতে না হয়।
4) GROUP BY (যখন গ্রুপিং ইনডেক্সের সঙ্গে সঙ্গত থাকে)
গ্রুপিং তখন উপকৃত করতে পারে যখন ডাটাবেস গ্রুপকৃত অর্ডারে ডেটা পড়তে পারে। এটা নিশ্চিত নয়, কিন্তু যদি আপনি সাধারণত এমন কোনো কলামে গ্রুপ করেন যা ফিল্টারেও ব্যবহৃত হয় বা ইনডেক্সে ক্লাস্টার করা থাকে, ইঞ্জিন কম কাজ করতে পারে।
B-tree ইনডেক্সগুলো রেঞ্জ কন্ডিশন-এ বিশেষভাবে ভাল—ধরুন তারিখ, দাম, এবং "between" কিউরি:
SELECT * FROM orders
WHERE created_at \u003e= '2025-01-01' AND created_at \u003c '2025-02-01';
ড্যাশবোর্ড, রিপোর্ট, এবং “সাম্প্রতিক কার্যকলাপ” দেখানোর স্ক্রিনগুলিতে এই প্যাটার্ন সাধারণ, এবং রেঞ্জ কলামে ইনডেক্স রাখা প্রায়ই তাৎক্ষণিক উন্নতি দেয়।
মূল থিম সহজ: ইনডেক্স সবচেয়ে কাজে দেয় যখন এগুলো আপনার সার্চ ও সোর্ট করার প্যাটার্নকে মিরর করে। যদি আপনার কিউরি সেই প্যাটার্নগুলোর সাথে মিলবে, ডাটাবেস লক্ষ্যভিত্তিক রিড করতে পারবে বদলে বিস্তৃত স্ক্যানের।
একটি ইনডেক্স সাহায্য করে যখন এটি স্পষ্টভাবে টেবিলকে ছোট করে দেয়—এই গুণটাকে বলা হয় সিলেক্টিভিটি।
সিলেক্টিভিটি হচ্ছে: নির্দিষ্ট মানের জন্য কতগুলো সারি মিলবে? উচ্চ সিলেক্টিভিটি মানে অনেক ভিন্ন মান আছে, তাই প্রতিটি লুকআপে কম সারি মিলবে।
email, user_id, order_number (অften ইউনিক বা কাছাকাছি)is_active, is_deleted, status যেখানে কয়েকটি সাধারণ মান আছেউচ্চ সিলেক্টিভিটির ক্ষেত্রে, ইনডেক্স দ্রুত ছোট সারিসেটে লাফ দিতে পারে। নিম্ন সিলেক্টিভিটিতে ইনডেক্স টেবিলের একটি বড় অংশ নির্দেশ করে—সুতরাং ডাটাবেসকে এখনও অনেক পড়তে হবে।
ধরুন একটি টেবিলে ১০ মিলিয়ন সারি আছে এবং is_deleted কলামে ৯৮% মান false। is_deleted-এ ইনডেক্সটি নিম্নোক্ত কিউরির জন্য বেশি সুবিধা দেয় না:
SELECT * FROM orders WHERE is_deleted = false;
ম্যাচ সেটটি এখনও প্রায় পুরো টেবিল। ইনডেক্স ব্যবহার করা সিকোয়েন্সিয়াল স্ক্যানের চেয়েও ধীর হতে পারে কারণ ইঞ্জিন ইন্ডেক্স এন্ট্রি এবং টেবিল পেজগুলোর মধ্যে হপ করে অতিরিক্ত কাজ করে।
কিউরি প্ল্যানার কাজের (কস্ট) হিসেব করে। যদি ইনডেক্স যথেষ্টভাবে কাজ কমিয়ে না আনবে—কারণ অনেক সারি মিলছে, অথবা কিউরি অনেক কলাম চায়—তারা ফুল টেবিল স্ক্যান বেছে নিতে পারে।
ডেটা বিতরণ স্থির নয়। একটি status কলাম প্রথমে সমভাবে বন্টিত থাকতে পারে, পরে এক মান ডমিনেট করে। যদি স্ট্যাটিস্টিক্স আপডেট না থাকে, প্ল্যানার ভুল সিদ্ধান্ত নিতে পারে, এবং আগে সাহায্য করা ইনডেক্স আর লাভজনক নাও থাকতে পারে।
একক কলামের ইনডেক্স ভালো শুরু, কিন্তু বাস্তব কিউরিগুলো প্রায়ই এক কলামে ফিল্টার করে এবং আরেকটায় সোর্ট/ফিল্টার করে। তখন কম্পোজিট (মাল্টি-কলাম) ইনডেক্স উপকারী: একটি ইনডেক্স একাধিক অংশে কিউরিকে সার্ভ করতে পারে।
বহু ডাটাবেসে (বিশেষত B-tree) কম্পোজিট ইনডেক্স কার্যকরভাবে কেবল বামদিকের কলামগুলো থেকেই ব্যবহার যোগ্য। ইনডেক্সটি প্রথমে কলাম A দিয়ে সাজানো, তারপর ভিতরে কলাম B ইত্যাদি।
এর মানে:
account_id দ্বারা ফিল্টার করে এবং তারপর created_at দ্বারা সাজানোর/ফিল্টারের জন্য দুর্দান্তcreated_at দ্বারা শুধুমাত্র ফিল্টার করা কিউরির জন্য সহায়ক নয় (কারণ এটি বামদিকের নয়)কমন ওয়ার্কলোড হচ্ছে “এই অ্যাকাউন্টের সর্বশেষ ইভেন্টগুলো দেখাও।” প্যাটার্নটি:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
প্রায়ই নিচের ইনডেক্স থেকে প্রচুর লাভ হয়:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
ডাটাবেস ইনডেক্সের ওই অ্যাকাউন্ট অংশে সরাসরি লাফ দিতে পারে এবং সময়ক্রমে পড়তে পারে, বড় সেট স্ক্যান ও সোর্ট করার বদলে।
একটি কভারিং ইনডেক্স কিউরিতে প্রয়োজনীয় সব কলাম থাকে, তাই ডাটাবেস টেবিল সারি না খুলেই ইনডেক্স থেকেই ফলাফল দিতে পারে (কম রিড, কম র্যান্ডম I/O)।
সাবধান: অতিরিক্ত কলাম যোগ করলে ইনডেক্স বড় ও ব্যয়বহুল হয়ে যায়।
বিস্তৃত কম্পোজিট ইনডেক্স রাইট ধীর করে এবং স্টোরেজ খায়। শুধুমাত্র নির্দিষ্ট উচ্চ-মূল্যের কিউরিগুলোর জন্যই যোগ করুন, এবং EXPLAIN প্ল্যান ও বাস্তব মাপজোক করে আগে ও পরে যাচাই করুন।
ইনডেক্সকে প্রায়শই "ফ্রি স্পিড" বলা হয়, কিন্তু তা সত্য নয়। ইনডেক্স স্ট্রাকচারগুলো প্রতিটি টেবিল পরিবর্তনের সময় রক্ষণাবেক্ষণ করতে হয়, এবং এগুলো বাস্তব রিসোর্স খায়।
যখন আপনি একটি নতুন সারি INSERT করেন, ডাটাবেস শুধু সারি রাইট করে না—এটি টেবিলের প্রতিটি ইনডেক্সেও সংশ্লিষ্ট এন্ট্রি যোগ করে। একই কথা DELETE ও অনেক UPDATE-এ লাগে।
এই কারণে "আরও ইনডেক্স" রাইট-হেভি ওয়ার্কলোডে লক্ষণীয় ধীরতা আনতে পারে। একটি UPDATE যদি একটি ইনডেক্সড কলাম ছোয়, তাহলে পুরনো এন্ট্রি মুছে নতুন যোগ করা লাগতে পারে (কিছু ইঞ্জিনে এটা পেজ স্প্লিট বা রিব্যালান্সিংও ট্রিগার করে)। যদি আপনার অ্যাপ অনেক রাইট করে—অর্ডার ইভেন্ট, সেন্সর ডেটা, অডিট লগ—তবে সবকিছুকে ইনডেক্স করা ডাটাবেসকে স্তব্ধ মনে করাতে পারে যদিও রিড দ্রুত।
প্রতিটি ইনডেক্স ডিস্ক স্পেস নেয়। বড় টেবিলে ইনডেক্সগুলোর সাইজ টেবিলের সাইজের সাথে তুলনীয় বা বড়ও হতে পারে, বিশেষত যদি আপনি বেশ কয়েকটি ওভারল্যাপিং ইনডেক্স রাখেন।
এটা মেমরিতেও প্রভাব ফেলে। ডাটাবেস ভারি কেশিং-এর ওপর নির্ভর করে; যদি আপনার ওয়ার্কিং সেটে অনেক বড় ইনডেক্স থাকে, ক্যাশে আরও পেজ রাখতে হবে দ্রুত রাখতে। না হলে আপনি আরও ডিস্ক I/O ও কম পূর্বানুমেয় পারফরম্যান্স পাবেন।
ইনডেক্সিং মানে কি দ্রুততাকে বেছে নেওয়া। যদি ওয়ার্কলোড রিড-হেভি হয়, বেশি ইনডেক্স লাভজনক হতে পারে। যদি রাইট-হেভি হয়, তখন সবচেয়ে গুরুত্বপূর্ণ কিউরিগুলোর জন্য ইনডেক্স রাখুন এবং নকল ইনডেক্স এড়িয়ে চলুন। একটি ব্যবহারিক নিয়ম: একটি ইনডেক্স যোগ করুন কেবল যখন আপনি সেটা সাহায্য করে এমন কিউরিটি নাম করতে পারেন—এবং যাচাই করুন যে রিড গেইন রাইট ও মেইনটেন্যান্স খরচ ছাপিয়ে যায়।
ইনডেক্স যোগ করা মনে হতে পারে সাহায্য করবে—কিন্তু আপনি এটা যাচাই করবেন। দুইটি সরঞ্জাম যা এটি কংক্রিট করে: কিউরি প্ল্যান (EXPLAIN) এবং বাস্তব আগে/পরে মাপজোক।
আপনি যেই কিউরি পছন্দ করেন তার উপর EXPLAIN (অথবা EXPLAIN ANALYZE) চালান।
EXPLAIN ANALYZE): যদি প্ল্যান estimate করে ১০০ সারি কিন্তু actually ১০০,০০০ টাচ করে, প্ল্যানার ভুল অনুমান করেছে—সাধারণত স্ট্যাটিস্টিক্স স্টেলে থাকার কারণে বা ফিল্টারটি কম সিলেক্টিভ হওয়ার কারণে।ORDER BY-এর সাথে মেলে, তাহলে সেই sort ধাপটি হারিয়ে যেতে পারে, যা বড় গেইন।একই প্যারামিটার, প্রতিনিধি ডেটা সাইজে কিউরির বেঞ্চমার্ক নিন এবং গ্রহণ করুন দুইটি: লেটেন্সি এবং স্ক্যান করা সারি।
ক্যাশিং নিয়ে সতর্ক থাকুন: প্রথম রান ধীর হতে পারে কারণ ডেটা এখনও মেমরিতে নেই; বারবার চালালে তা দ্রুত হলেও সেটা ইনডেক্স ছাড়াই কেশের কারণে হতে পারে। নিজেকে বিভ্রান্ত না করতে একাধিক রান পছন্দ করুন এবং দেখুন প্ল্যান পরিবর্তন করে কিনা (ইনডেক্স ব্যবহৃত হচ্ছে, কম সারি পড়া হচ্ছে) শুধু সময়ের পরিবর্তনের পাশাপাশি।
যদি EXPLAIN ANALYZE কম সারি টাচ দেখায় এবং কম ব্যয়বহুল ধাপ (যেমন sort) থাকে, তখন আপনি প্রমাণ করেছেন ইনডেক্স সাহায্য করেছে—কেবল আশা নয়।
আপনি সঠিক ইনডেক্স যোগ করলেও কিউরি এমনভাবে লেখা থাকলে ডাটাবেস সেটি ব্যবহার করতে পারে না। এই ধরণের সমস্যা প্রায়ই সূক্ষ্ম, কারণ কিউরি সঠিক ফলাফল দেয়—তবে ধীর প্ল্যানে।
1) লিডিং ওয়াইল্ডকার্ড
যখন আপনি লিখেন:
WHERE name LIKE '%term'
সাধারণ B-tree ইনডেক্সটি ব্যবহার করা যায় না, কারণ এটি জানে না কোথা থেকে "%term" শুরু হবে। প্রায়ই এটি অনেক সারি স্ক্যান করে।
বিকল্প:
WHERE name LIKE 'term%'.2) ইনডেক্সড কলামে ফাংশন ব্যবহার
এটি ভ্রান্ত মনে হতে পারে:
WHERE LOWER(email) = '[email protected]'
কিন্তু LOWER(email) ইনডেক্সযুক্ত email কলামকে সরাসরি ব্যবহার করতে দেয় না।
বিকল্প:
WHERE email = ... করুন।ইমপ্লিসিট টাইপ কাস্ট: ভিন্ন ডেটা টাইপ তুলনা করলে ডাটাবেস একপাশ কাস্ট করতে পারে, যা ইনডেক্স নিষ্ক্রিয় করে। উদাহরণ: একটি ইন্টিজার কলামকে স্ট্রিং লিটারালের সঙ্গে তুলনা করা।
মিসম্যাচড কলেশন/এনকোডিং: যদি তুলনা ইনডেক্স তৈরি করা কোলেশনের থেকে ভিন্ন কোলেশন ব্যবহার করে, অপ্টিমাইজার ইনডেক্স এড়াতে পারে।
LIKE '%x')?LOWER(col), DATE(col), CAST(col))?EXPLAIN দিয়ে প্ল্যান চেক করেছেন কি দেখার জন্য ডাটাবেস কী নির্বাচন করেছে?ইনডেক্সগুলো "একবার করে ভুলে যাও" ধরনের নয়। সময়ের সাথে ডেটা বদলে যায়, কিউরি প্যাটার্ন শিফট করে, এবং টেবিল/ইনডেক্সের ফিজিক্যাল আকার খারাপ হতে পারে। ভালভাবে বাছাই করা ইনডেক্স ধীরে ধীরে কম কার্যকর বা এমনকি ক্ষতিকর হয়ে যেতে পারে যদি আপনি এটি মেইনটেইন না করেন।
অধিকাংশ ডাটাবেস কিউরি প্ল্যানার (অপ্টিমাইজার)-এর ওপর নির্ভর করে কিউরি কীভাবে চালাবে তা সিদ্ধান্ত নিতে: কোন ইনডেক্স ব্যবহার করবে, কোন জয়েন অর্ডার বেছে নেবে, এবং ইনডেক্স লুকআপটা কি মূল্যসাপেক্ষ তা। সেই সিদ্ধান্তের জন্য প্ল্যানার স্ট্যাটিস্টিক্স ব্যবহার করে—মান বিতরণ, সারি সংখ্যা, এবং ডাটা স্কিউ সম্পর্কে সারাংশ।
যখন স্ট্যাটিস্টিক্স স্টেলে যায়, প্ল্যানারের রো অনুমান ভাঙ্গতে পারে। এর ফলে খারাপ প্ল্যান বেছে নেওয়া হয়—যেমন একটি ইনডেক্স বেছে নেওয়া যা প্রত্যাশিতের তুলনায় অনেক বেশি সারি ফেরত দেয়, বা এমন ইনডেক্স বাদ দেয় যা দ্রুত হতে পারে।
রুটিন ফিক্স: নিয়মিত স্ট্যাটস আপডেট নির্ধারণ করুন (অften ANALYZE বা সমতুল্য)। বড় ডেটা লোড, বড় ডিলেট, বা তীব্র চেঞ্জ হলে স্ট্যাটস আগেই রিফ্রেশ করুন।
সারি ইনসার্ট, আপডেট, ডিলেট হয়ে গেলে ইনডেক্সে ব্লোট (অপ্রয়োজনীয় পেজ) এবং ফ্র্যাগমেন্টেশন জমতে পারে, যা ইনডেক্সকে বড় করে এবং I/O বাড়ায়—বিশেষত রেঞ্জ কিউরির জন্য।
রুটিন ফিক্স: ভারী ব্যবহৃত বা অনুপাতভাবে বড় হয়ে যাওয়া ইনডেক্সগুলো_periodically_ rebuild বা reorganize করুন। নির্দিষ্ট টুলিং ও প্রভাব ডাটাবেস অনুযায়ী ভিন্ন, তাই এটি মাপজোক করে চালান।
নিম্ন মনিটরিং সেট করুন:
এই ফিডব্যাক লুপ আপনাকে ধরতে সাহায্য করে কখন মেইনটেন্যান্স দরকার—আর কখন ইনডেক্স সামঞ্জস্য বা অপসারণ উচিত। আরও যাচাইয়ের জন্য দেখুন /blog/how-to-prove-an-index-helps-explain-and-measurements।
ইনডেক্স যোগ করা হওয়া উচিত বেগে করা সিদ্ধান্ত নয়, অনুমান নয়। একটি হালকা ওয়ার্কফ্লো আপনাকে মাপযোগ্য গেইনে রাখে এবং “ইনডেক্স স্প্রল” রোধ করে।
প্রমাণ নিয়ে শুরু করুন: স্লো-কিউরি লগ, APM ট্রেস, বা ইউজার রিপোর্ট। এমন একটি কিউরি নিন যা একই সাথে ধীর ও ঘন—একটি বিরল ১০ সেকেন্ড রিপোর্ট কম জরুরী একটি সাধারণ ২০০ মি.সেক লুকআপের চেয়ে।
ঠিক SQL এবং প্যারামিটার প্যাটার্ন ক্যাপচার করুন (উদাহরণ: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50)। ক্ষুদ্র পার্থক্যগুলো কোন ইনডেক্স সাহায্য করবে তা বদলে দিতে পারে।
বর্তমান লেটেন্সি (p50/p95), স্ক্যান করা সারি, এবং CPU/IO প্রভাব নথিভুক্ত করুন। বর্তমান প্ল্যান আউটপুট সংরক্ষণ করুন (যেমন EXPLAIN / EXPLAIN ANALYZE) যাতে পরে তুলনা করা যায়।
কলাম বেছে নিন যা কিউরি ফিল্টার ও সাজানো অনুযায়ী মেলে। সেই ছোট ইনডেক্সই ডিজাইন করুন যা প্ল্যানকে বড় রেঞ্জ স্ক্যান করা বন্ধ করায়।
প্রোডাকশন-মত ডেটা ভলিউমে স্টেজিং-এ টেস্ট করুন। ছোট ডেটাসেটে অনেক ইনডেক্স ভালো দেখায় কিন্তু স্কেলে হতাশ করতে পারে।
বড় টেবিলে, অনলাইন অপশন ব্যবহার করুন যেখানে সমর্থিত (উদাহরণ: PostgreSQL CREATE INDEX CONCURRENTLY)। যদি আপনার ডাটাবেস লেখাকে লক করতে পারে, খুব কম ট্রাফিকের সময়ে শিডিউল করুন।
একই কিউরি পুনরায় চালান এবং তুলনা করুন:
যদি ইনডেক্স রাইট খরচ বাড়ায় বা মেমরি ব্লোট বাড়ায়, পরিষ্কারভাবে অপসারণ করুন (উদাহরণ: DROP INDEX CONCURRENTLY যেখানে আছে)। মাইগ্রেশনটি রিভার্সেবল রাখুন।
মাইগ্রেশন বা স্কিমা নোটে লিখে রাখুন কোন কিউরিটি ইনডেক্স সার্ভ করে এবং কোন মেট্রিক উন্নত হয়েছিল। ভবিষ্যতের আপনি (বা সহকর্মী) জানবেন কেন এটি আছে এবং কখন নিরাপদে মুছবে।
নতুন সার্ভিস বিল্ড করলে এবং প্রাথমিকভাবে “ইনডেক্স স্প্রল” এড়াতে চাইলে, Koder.ai আপনাকে পুরো লুপ দ্রুত করতে সাহায্য করতে পারে: চ্যাট থেকে React + Go + PostgreSQL অ্যাপ জেনারেট, প্রয়োজন মাফিক স্কিমা/ইনডেক্স মাইগ্রেশন গঠন, এবং যখন প্রয়োজন উৎস কোড এক্সপোর্ট করা। বাস্তবে, এটা সহজ করে দেয় “এই এন্ডপয়েন্ট ধীর” থেকে “EXPLAIN প্ল্যান, ক্ষুদ্র ইনডেক্স, এবং রিভার্সিবল মাইগ্রেশন” পর্যন্ত দ্রুত পৌঁছাতে।
ইনডেক্স বড় লিভার, কিন্তু সবসময় ম্যাজিক নয়। কখনও কখনও রিকোয়েস্টের ধীর অংশটি ডাটাবেস সার্চের পরে ঘটে—অথবা আপনার কিউরি প্যাটার্ন ইনডেক্সকে ভুল জায়গায় টেনে নেয়।
যদি আপনার কিউরি ইতিমধ্যে একটি ভাল ইনডেক্স ব্যবহার করলেও ধীর থাকে, নিচের জিনিসগুলো দেখুন:
OFFSET 999000 দিয়ে পেজ 1000 ফেচ করা ইনডেক্স থাকলেও ধীর হতে পারে। কীসেট পেজিং (keyset pagination) ব্যবহার করুন (যেমন শেষ দেখা id/timestamp পরে সারি)।SELECT * বা হাজার হাজার রেকর্ড ফেরত দেওয়া নেটওয়ার্ক, JSON সিরিয়ালাইজেশন, বা অ্যাপ প্রসেসিং-এ বটলনেক হতে পারে।LIMIT ব্যবহার করুন, এবং পেজিং ইন্টেনশনালি করুন।যদি আপনি বটলনেক নির্ণয়ের গভীর পদ্ধতি চান, এটি /blog/how-to-prove-an-index-helps-র ওয়ার্কফ্লো-র সঙ্গে জুড়ে দেখুন।
অনুমান করবেন না। সময় কোথায় লাগছে সেটা পরিমাপ করুন (ডাটাবেস এক্সিকিউশন বনাম ফেরত দেয়া সারি বনাম অ্যাপ কোড)। যদি ডাটাবেস দ্রুত কিন্তু API ধীর হয়, আরো ইনডেক্স কিছুই করবে না।
A database index is a separate data structure (often a B-tree) that stores selected column values in a searchable, sorted form with pointers back to table rows. The database uses it to avoid reading most of the table when answering selective queries.
It’s not a second full copy of the table, but it does duplicate some column data plus metadata, which is why it consumes extra storage.
Without an index, the database may have to do a full table scan: read many (or all) rows and check each one against your WHERE clause.
With an index, it can often jump directly to the matching row locations and read only those rows, reducing disk I/O, CPU filter work, and cache pressure.
A B-tree index keeps values sorted and organized into pages that point to other pages, so the database can navigate quickly to the right “neighborhood” of values.
That’s why B-trees work well for both:
WHERE email = ...)WHERE created_at \u003e= ... AND created_at \u003c ...)Hash indexes can be very fast for exact equality (=) because they hash a value and jump to its bucket.
Tradeoffs:
In many real workloads, B-trees are the default because they support more query patterns.
Indexes usually help most for:
WHERE filters (few rows match)JOIN keys (foreign keys and referenced keys)ORDER BY that matches an index order (can avoid a sort)GROUP BY cases when reading in grouped order reduces workIf a query returns a large fraction of the table, the benefit is often small.
Selectivity is “how many rows match a given value.” Indexes pay off when a predicate narrows a large table down to a small result set.
Low-selectivity columns (e.g., is_deleted, is_active, small status enums) often match huge portions of the table. In those cases, using the index can be slower than scanning because the engine still has to fetch and filter many rows.
Because the optimizer estimates that using it won’t reduce work enough.
Common reasons include:
In most B-tree implementations, the index is effectively sorted by the first column, then within that by the second, etc. So the database can efficiently use the index starting from the leftmost column(s).
Example:
(account_id, created_at) is great for WHERE account_id = ? plus time filtering/sorting.created_at (since it’s not leftmost).A covering index includes all columns needed by the query so the database can return results from the index without fetching the table rows.
Benefits:
Costs:
Use covering indexes for specific high-value queries, not “just in case.”
Check two things:
EXPLAIN / EXPLAIN ANALYZE and confirm the plan changes (e.g., Seq Scan → Index Scan/Seek, fewer rows read, sort step removed).Also watch write performance, since new indexes can slow INSERT/UPDATE/DELETE.