০৫ মে, ২০২৫·8 মিনিট
Datadog ও প্ল্যাটফর্ম শিফট: টেলিমেট্রি, ইন্টিগ্রেশন, ও ওয়ার্কফ্লো
কিভাবে Datadog একটি প্ল্যাটফর্মে পরিণত হয় যখন টেলিমেট্রি, ইন্টিগ্রেশন, এবং ওয়ার্কফ্লো প্রোডাক্ট হয়ে ওঠে—এবং আপনার স্ট্যাকের জন্য প্রয়োগযোগ্য বাস্তব টিপস।
কিভাবে Datadog একটি প্ল্যাটফর্মে পরিণত হয় যখন টেলিমেট্রি, ইন্টিগ্রেশন, এবং ওয়ার্কফ্লো প্রোডাক্ট হয়ে ওঠে—এবং আপনার স্ট্যাকের জন্য প্রয়োগযোগ্য বাস্তব টিপস।
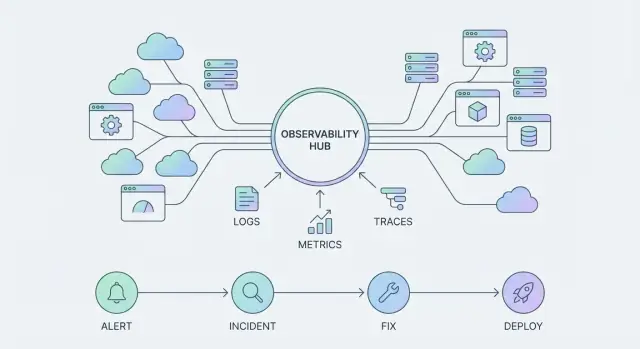
একটি অবজার্ভেবিলিটি টুল আপনাকে সিস্টেম সম্পর্কে নির্দিষ্ট প্রশ্নের উত্তর দিতে সাহায্য করে—সাধারণত চার্ট, লগ, বা একটি কুয়েরি ফলাফল দেখিয়ে। এটা এমন কিছু যা আপনি “ব্যবহার” করেন যখন কোনো সমস্যা হয়।
একটি অবজার্ভেবিলিটি প্ল্যাটফর্ম বেশি বিস্তৃত: এটি নির্ধারণ করে টেলিমেট্রি কিভাবে সংগ্রহ করা হবে, টিমগুলো কিভাবে তা এক্সপ্লোর করবে, এবং ইনসিডেন্ট কিভাবে end-to-end হ্যান্ডেল হবে। এটি এমন কিছু হয়ে ওঠে যা আপনার প্রতিষ্ঠান প্রতিদিন “চালায়”, অনেক সার্ভিস ও টিম জুড়ে।
অধিকাংশ টিম ড্যাশবোর্ড দিয়ে শুরু করে: CPU চার্ট, এরর‑রেট গ্রাফ, কিংবা কিছু লগ সার্চ। এটি উপকারী, কিন্তু আসল লক্ষ্য সুন্দর চার্ট নয়—এটি দ্রুত ডিটেকশন এবং দ্রুত রেজল্যুশন।
প্ল্যাটফর্ম শিফট ঘটে যখন আপনি আর প্রশ্ন করবেন না “এটা গ্রাফ করা যাবে কি?” এবং শুরু করবেন জানতে:
এসব outcome‑ফোকাসড প্রশ্ন, এবং সেগুলো কেবল ভিজ্যুয়ালাইজেশনের চেয়ে বেশি কিছু চায়। এগুলো শেয়ার্ড ডেটা স্ট্যান্ডার্ড, ধারাবাহিক ইন্টিগ্রেশন, এবং টেলিমেট্রিকে অ্যাকশনের সাথে যুক্ত করা ওয়ার্কফ্লো দরকার।
Datadog-এর মতো প্ল্যাটফর্ম যেমন বৃদ্ধি পায়, “প্রোডাক্ট সারফেস” কেবল ড্যাশবোর্ড নয়। এটি তিনটি আন্তঃসংযুক্ত স্তম্ভ:
একটি একক ড্যাশবোর্ড একটি টিমকে সাহায্য করতে পারে। একটি প্ল্যাটফর্ম প্রতিটি সার্ভিস অনবোর্ড হলে, প্রতিটি ইন্টিগ্রেশন যোগ হলে, এবং প্রতিটি ওয়ার্কফ্লো স্ট্যান্ডার্ড হলে শক্তিশালী হয়। সময়ের সাথে, এইটা কম ব্লাইন্ড‑স্পট, কম ডুপ্লিকেটেড টুলিং, এবং ছোটো ইনসিডেন্টে রূপান্তরিত হয়—কারণ প্রতিটি উন্নতি পুনরায় ব্যবহারযোগ্য হয়ে ওঠে, এক‑অফ না।
যখন অবজার্ভেবিলিটি “একটি টুল যা আমরা কুয়েরি করি” থেকে “একটি প্ল্যাটফর্ম যা আমরা বিল্ড করি” এ যায়, তখন টেলিমেট্রি কাঁচা এক্সহোস্ট না থেকে প্রোডাক্ট সারফেস হিসেবে কাজ করে। আপনি কী ইমিট করবেন এবং কতটা ধারাবাহিকভাবে ইমিট করবেন তা নির্ধারণ করে টিমগুলো কী দেখতে, অটোমেট করতে এবং বিশ্বাস করতে পারবে।
অধিকাংশ টিম এক ছোট সেট সিগন্যাল স্ট্যান্ডার্ড করে:
এককভাবে, প্রতিটি সিগন্যাল উপকারী। একসাথে, তারা আপনার সিস্টেমের একক ইন্টারফেস হয়ে যায়—যা আপনি ড্যাশবোর্ড, অ্যালার্ট, ইনসিডেন্ট টাইমলাইন এবং পোস্টমর্টেমে দেখেন।
একটি সাধারণ ব্যর্থতা হলো “সবকিছু” সংগ্রহ করা কিন্তু নামকরণ অনিয়মিত রাখা। যদি একটি সার্ভিস userId ব্যবহার করে, আরেকটি uid ব্যবহার করে, এবং তৃতীয়টি কিছুই লগ না করে, তাহলে আপনি বিশ্বাসযোগ্যভাবে ডেটা স্লাইস বা সিগন্যাল জয়েন করতে পারবেন না।
টিমগুলো বেশি মূল্য পায় যদি তারা কয়েকটি কনভেনশন—service নাম, environment ট্যাগ, request ID, এবং একটি স্ট্যান্ডার্ড অ্যাট্রিবিউট সেট—এ একমত হয়, ইনজেস্ট ভলিউম বাড়ানোর চেয়ে।
High‑cardinality ফিল্ডগুলো অনেক সম্ভাব্য মান রাখে (যেমন user_id, order_id, session_id)। এগুলো “শুধু এক গ্রাহক” সমস্যার ডিবাগিং‑এ শক্তিশালী, কিন্তু এগুলো সবজায়গায় ব্যবহার করলে খরচ বাড়ে এবং কুয়েরি ধীর করে।
প্ল্যাটফর্ম অ্যাপ্রোচ হলো ইচ্ছাকৃত হওয়া: যেখানে স্পষ্ট তদন্তমূলক মান আছে সেখানে হাই‑কার্ডিনালিটি রাখুন, এবং বিশ্বব্যাপী অ্যাগিগ্রেটের জন্য এড়িয়ে চলুন।
ফলাফল হলো গতি। যখন metrics, logs, traces, events, এবং profiles একই কনটেক্সট (service, version, region, request ID) শেয়ার করে, ইঞ্জিনিয়াররা প্রমাণ টানাইয়ের সময় কম কাটায় এবং সমস্যা ঠিক করতে বেশি সময় দেয়। টুলের মধ্য দিয়ে ঝাঁপ দিয়ে অনুমান করার বদলে আপনি একটি থ্রেড অনুসরণ করে সিম্পটম থেকে রুট‑কজে পৌঁছান।
অনেক টিম observability শুরু করে “ডেটা ইন করা” দিয়ে। সেটা দরকারি, কিন্তু এটা কৌশল নয়। একটি টেলিমেট্রি স্ট্র্যাটেজি অনবোর্ডিংকে দ্রুত রাখে এবং আপনার ডেটাকে যথেষ্ট ধারাবাহিক করে যাতে শেয়ার্ড ড্যাশবোর্ড, বিশ্বাসযোগ্য অ্যালার্ট, এবং অর্থবহ SLO চালাতে পারে।
Datadog সাধারণত কয়েকটি ব্যবহারিক রুট দিয়ে টেলিমেট্রি পায়:
শুরুতেই গতি জিতবে: টিমরা একটি এজেন্ট ইনস্টল করে, কিছু ইন্টিগ্রেশন অন করে, এবং তৎক্ষণাৎ মূল্য দেখবে। ঝুঁকি হলো প্রতিটি টিম তার নিজস্ব ট্যাগ, সার্ভিস নাম এবং লগ ফরম্যাট আবিষ্কার করে—যা ক্রস‑সার্ভিস ভিউকে বিবর্ণ করে এবং অ্যালার্টকে অবিশ্বাস্য করে তোলে।
সহজ নিয়ম: "কুইক স্টার্ট" অনুমোদন করুন, কিন্তু ৩০ দিনের মধ্যে স্ট্যান্ডার্ডাইজেশন বাধ্যত করুন। এতে টিমগুলোকে গতি দেয় কিন্তু বিশৃঙ্খলা স্থায়ীভাবে ঢুকতে দেয় না।
বৃহৎ ট্যাক্সোনোমি লাগবে না। শুরু করুন এমন একটি ছোট সেট দিয়ে যা প্রতিটি সিগন্যাল (লগ, মেট্রিক, ট্রেস) বহন করবে:
service: সংক্ষিপ্ত, স্থিতিশীল, লোয়ারকেস (উদা: checkout-api)env: prod, staging, devteam: মালিকানা টিমের আইডি (উদা: payments)version: ডিপ্লয় ভার্সন বা git SHAআরও একটি দিলে দ্রুত ফল দেয়: tier (frontend, backend, data)—ফিল্টার করা সহজ হয়।
কস্ট ইস্যুগুলো সাধারণত অতিরঞ্জিত ডিফল্ট থেকে আসে:
লক্ষ্য হলো কম সংগ্রহ করা নয়—সঠিক ডেটা ধারাবাহিকভাবে সংগ্রহ করা যাতে আপনি ব্যবহার বাড়াতে পারেন কোন অপ্রত্যাশিত খরচ ছাড়াই।
অধিকাংশ মানুষ অবজার্ভেবিলিটি টুলকে “কিছু যা ইনস্টল করা যায়” হিসেবে ভাবেন। বাস্তবে, এটি সেইভাবে ছড়ায় যেমন ভালো কানেক্টর ছড়ায়: একটি ইন্টিগ্রেশন একসময় অন।
একটি ইন্টিগ্রেশন শুধু ডেটা পাইপ নয়; সাধারণত এতে তিনটি অংশ থাকে:
শেষটা ইন্টিগ্রেশনকে বিতরণে রূপান্তর করে। যদি টুল শুধু পড়ে, সেটা ড্যাশবোর্ড ডেস্টিনেশন; যদি সেটা লিখতে ও অ্যাকশন নিতে পারে, তাহলে তা দৈনন্দিন কাজের অংশ হয়ে ওঠে।
ভালো ইন্টিগ্রেশন সেটআপ সময় কমায় কারণ সেগুলো sensible defaults নিয়ে আসে: প্রি‑বিল্ট ড্যাশবোর্ড, সুপারিশকৃত মনিটর, পার্সিং রুল, এবং কমন ট্যাগ। প্রতিটি টিম না গড়ে নিজের “CPU ড্যাশবোর্ড” বা “Postgres alerts”—বরং শেয়ার্ড বেসলাইন থেকে কাস্টমাইজ করে।
স্ট্যান্ডার্ডাইজেশন তখনই জরুরি যখন আপনি টুল কনসোলিডেট করছেন: ইন্টিগ্রেশনগুলো পুনরাবৃত্তিমূলক প্যাটার্ন তৈরি করে যা নতুন সার্ভিসগুলো কপি করতে পারে এবং বৃদ্ধি ম্যানেজেবল রাখে।
বিকল্প যাচাই করার সময় জিজ্ঞাসা করুন: এটি কি সিগন্যাল গ্রহণ করতে পারে এবং অ্যাকশন নিতে পারে? উদাহরণ: আপনার টিকেটিং সিস্টেমে ইনসিডেন্ট খুলে দেওয়া, ইনসিডেন্ট চ্যানেলে আপডেট করা, কিংবা PR বা ডিপ্লয় ভিউতে ট্রেস লিঙ্ক জোড়া—এগুলোই ওয়ার্কফ্লোকে “নেটিভ” বোধ করায়।
ছোটো ও পূর্বানুমেয় দিয়ে শুরু করুন:
একটি নিয়ম: ইন্টিগ্রেশনগুলোকে অগ্রাধিকার দিন যা ইনসিডেন্ট রেসপন্স সরাসরি উন্নত করে, শুধুই আরো চার্ট যোগ না করে।
স্ট্যান্ডার্ড ভিউগুলোই একটি অবজার্ভেবিলিটি প্ল্যাটফর্মকে দৈনন্দিন ব্যবহারযোগ্য করে। টিমগুলো যদি একই মানসিক মডেল শেয়ার করে—কি একটি “সার্ভিস”, “সুস্থ” কেমন, এবং প্রথমে কোথায় ক্লিক করতে হবে—তাহলে ডিবাগিং দ্রুত হয় এবং হ্যান্ডঅফ পরিষ্কার হয়।
একটি ছোট সেট “golden signals” বেছে নিন এবং প্রতিটির জন্য একটি পুনরায় ব্যবহারযোগ্য ড্যাশবোর্ড তৈরী করুন। অধিকাংশ সার্ভিসের জন্য:
কী হল ধারাবাহিকতা: প্রতিটি সার্ভিসে এক ড্যাশবোর্ড লেআউট যা কাজ করে, দশটি কাস্টমাইজড ভালো ডিজাইনড ড্যাশবোর্ডের চেয়ে ভালো।
একটি লাইটওয়েট সার্ভিস ক্যাটালগই “কারো দেখা উচিত” কে “এই টিমের দায়িত্ব” করে দেয়। সার্ভিসগুলো মালিক, পরিবেশ, এবং ডিপেন্ডেন্সিসহ ট্যাগ করা থাকলে প্ল্যাটফর্ম দ্রুত উত্তর দিতে পারে: এই সার্ভিসে কোন মনিটর প্রযোজ্য? কোন ড্যাশবোর্ড খোলা উচিত? কাকে পেজ করা হবে?
এর ফলে ইনসিডেন্ট চলাকালে Slack‑এ ping‑pong কমে এবং নতুন ইঞ্জিনিয়াররা সেল্ফ‑সার্ভ করতে পারে।
নিচেরগুলোকে স্ট্যান্ডার্ড আর্টিফ্যাক্ট হিসেবে বিবেচনা করুন, অপশনাল নয়:
ভ্যানিটি ড্যাশবোর্ড (কোন সিদ্ধান্ত নেই এমন সুন্দর চার্ট), হঠাৎ তৈরি হওয়া এক‑অফ অ্যালার্ট, এবং অনডকুমেন্টেড কুয়েরি (এক ব্যক্তি বাদে কারো বুঝ নেই) প্ল্যাটফর্ম নয়েজ বাড়ায়। যদি একটি কুয়েরি গুরুত্বপূর্ণ হয়, সেটি সেভ করে নাম দিন এবং সার্ভিস ভিউতে লিংক করুন।
অবজার্ভেবিলিটি ব্যবসার জন্য “রিয়েল” হয় যখন এটা সমস্যা আর নিশ্চিত ফিক্সের মধ্যে সময় ছোট করে। এটা ঘটে ওয়ার্কফ্লোসের মাধ্যমে—পুনরাবৃত্ত পথ যা সিগন্যালকে অ্যাকশনে নিয়ে যায়, এবং অ্যাকশন থেকে লার্নিং করে।
একটি স্কেলেবল ওয়ার্কফ্লো কেবল পেজ করা বহির্ভূত।
একটি অ্যালার্টকে একটি ফোকাসড ট্রায়েজ লুপ খোলা উচিত: প্রভাব নিশ্চিত, প্রভাবিত সার্ভিস নির্ধারণ, এবং সবচেয়ে প্রাসঙ্গিক কনটেক্সট টেনে আনা (সাম্প্রতিক ডিপ্লয়, ডিপেন্ডেন্সি হেল্থ, এরর স্পাইক, স্যাচুরেশন সিগন্যাল)।
তারপর যোগাযোগ টেকনিক্যাল ইভেন্টকে সমন্বিত রেসপন্সে পরিণত করে—কে ইনসিডেন্টের মালিক, ব্যবহারকারীরা কী দেখছে, এবং পরবর্তী আপডেট কখন হবে।
মিটিগেশন অংশে আপনার কাছে “সেফ মুভস” থাকা উচিত: ফিচার ফ্ল্যাগ, ট্রাফিক শিফট, রোলব্যাক, রেট‑লিমিট, অথবা পরিচিত ওয়ার্কঅ্যারাউন্ড। শেষমেষ লার্নিং হালকা রিভিউ করে কি বদলেছে, কী কাজ করেছে, এবং পরবর্তীবার কী অটোমেট করা উচিত তা ধরে রাখে।
Datadog‑এর মতো প্ল্যাটফর্মগুলো মূল্য যোগ করে যখন তারা শেয়ার্ড কাজে সহায়তা করে: ইনসিডেন্ট চ্যানেল, স্ট্যাটাস আপডেট, হ্যান্ডঅফ এবং ধারাবাহিক টাইমলাইন। ChatOps ইন্টিগ্রেশনগুলো অ্যালার্টকে স্ট্রাকচার্ড কথোপকথনে রূপান্তর করতে পারে—ইনসিডেন্ট তৈরি, ভূমিকা অ্যাসাইন, এবং চ্যানেলে প্রধান গ্রাফ ও কুয়েরি পোস্ট করা যাতে সবাই একই প্রমাণ দেখে।
একটি ব্যবহারযোগ্য রানবুক সংক্ষিপ্ত, মতামতপূর্ণ এবং সেফ হওয়া উচিত। এতে থাকা উচিত: লক্ষ্য (সার্ভিস রিস্টোর করা), স্পষ্ট মালিক/অন‑কল রোটেশন, ধাপে ধাপে চেক, সঠিক ড্যাশবোর্ড/মনিটরের লিঙ্ক, এবং ঝুঁকি কমানোর “সেফ অ্যাকশন” (রোলব্যাক ধাপসহ)। যদি এটা 3‑টা ভোরে নিরাপদে চালানো যায় না, তাহলে এটাকে সমাপ্ত ভাববেন না।
ইনসিডেন্টগুলো স্বয়ংক্রিয়ভাবে ডিপ্লয়, কনফিগ পরিবর্তন ও ফিচার ফ্ল্যাগ ফ্লিপের সাথে করেলেট করলে রুট‑কজ খুঁজে পাওয়া দ্রুত হয়। “কি বদলেছে?” কে একটি প্রথম–শ্রেণীর ভিউ বানান যাতে ট্রায়েজ প্রমাণ থেকে শুরু করে, অনুমানের থেকে নয়।
একটি SLO (Service Level Objective) হলো একটি সহজ অঙ্গীকার ব্যবহারকারীর অভিজ্ঞতা সম্পর্কে—যেমন “৩০ দিনের মধ্যে 99.9% রিকোয়েস্ট সফল” বা “p95 পেইজ লোড ২ সেকেন্ডের কম”।
এটি green dashboard‑এর চেয়ে ভালো কারণ ড্যাশবোর্ডগুলো প্রায়ই সিস্টেম হেল্থ (CPU, memory, queue depth) দেখায় না কাস্টমার ইম্প্যাক্ট। একটি সার্ভিস সবুজ দেখলেও ব্যবহারকারী ব্যর্থ হতে পারে (উদাহরণ: একটি ডিপেন্ডেন্সি টাইমআউট করছে, বা এরর নির্দিষ্ট একটি রিজিয়নে কেন্দ্রীভূত)। SLO টিমকে যা ব্যবহারকারী অনুভব করে তা মাপতে বাধ্য করে।
একটি error budget হলো আপনার SLO অনুমোদিত অনবিশ্বাস্যতার পরিমাণ। উদাহরণস্বরূপ 30 দিনে 99.9% মানে ~43 মিনিট এরর অনুমোদিত।
এটি সিদ্ধান্ত নেয়ার জন্য একটি বাস্তবিক অপারেটিং সিস্টেম দেয়:
মতবিরোধের বদলে সবাই একটি সংখ্যার উপর আলাপ করে।
SLO অ্যালার্টিং সবচেয়ে ভাল কাজ করে যখন আপনি burn rate‑এ অ্যালার্ট করেন (কত দ্রুত আপনি error budget খরচ করছেন), কাঁচা এরর কাউন্টে নয়। এতে নয়েজ কমে:
অনেক টিম দুইটি উইন্ডো ব্যবহার করে: একটি ফাস্ট বার্ন (দ্রুত পেজ) এবং একটি স্লো বার্ন (টিকিট/নোটিফাই)।
ছোটো শুরু করুন—দুই থেকে চারটি SLO যেগুলো আপনি বাস্তবে ব্যবহার করবেন:
এসব স্থির হলে বাড়ান; নইলে আপনি আরেকটি ড্যাশবোর্ডওয়াল বানিয়ে ফেলবেন। বেশি জানতে দেখুন /blog/slo-monitoring-basics।
অ্যালার্টিং অনেক অবজার্ভেবিলিটি প্রোগ্রামকে আটকে দেয়: ডেটা আছে, ড্যাশবোর্ড ভালো, কিন্তু অন‑কল অভিজ্ঞতা নোইসি এবং অবিশ্বাস্য। মানুষ যদি শিখে অ্যালার্ট উপেক্ষা করতে, প্ল্যাটফর্ম ব্যবসা রক্ষা করার ক্ষমতা হারায়।
সবচেয়ে সাধারণ কারণগুলো:
Datadog টার্মে, ডুপ্লিকেট সিগন্যাল তখন ঘটে যখন মনিটরগুলো বিভিন্ন সারফেস থেকে তৈরি হয় (metrics, logs, traces) কিন্তু কোনটি canonical page হবে তা নির্ধারণ করা হয় না।
অ্যালার্টিং স্কেল করার শুরু হলো মানুষের মতের মতো রাউটিং নিয়ম:
একটি ব্যবহারযোগ্য ডিফল্ট: লক্ষণে অ্যালার্ট করুন, প্রতিটি মেট্রিক পরিবর্তনে নয়। ব্যবহারকারীরা যা অনুভব করে (এরর রেট, ব্যর্থ চেকআউট, ধারাবাহিক ল্যাটেন্সি, SLO burn) সেইগুলোর জন্য পেজ করুন—ইনপুটস (CPU, pod count) কেবল তখনি যদি এগুলো ধারাবাহিকভাবে প্রভাবের পূর্বাভাস দেয়।
অপারেশনের অংশ হিসেবে অ্যালার্ট হাইজিন রাখুন: মাসিক মনিটর প্রুনিং ও টিউনিং। যেগুলো কখনো ফায়ার করে না সেগুলো দূর করুন, অতিরিক্ত ফায়ারিং থ্রেশহোল্ড অ্যাডজাস্ট করুন, এবং ডুপ্লিকেট মিশিয়ে দিন যাতে প্রতিটি ইনসিডেন্টের একটি প্রধান পেজ থাকে এবং সাপোর্টিং কনটেক্সট পাওয়া যায়।
ভাল করে গেলে, অ্যালার্টিং একটি এমন ওয়ার্কফ্লো হয়ে ওঠে যা মানুষ বিশ্বাস করে—শুধু ব্যাকগ্রাউন্ড নয়।
অবজার্ভেবিলিটিকে “প্ল্যাটফর্ম” বলা মানে কেবল লগ, মেট্রিক, ট্রেস, এবং বহু ইন্টিগ্রেশন এক জায়গায় আছে না। এটা গভর্ন্যান্স ও গার্ডরেলও বোঝায়: ধারাবাহিকতা ও নিয়ম যা সিস্টেমটিকে ব্যবহারযোগ্য রাখে যখন টিম, সার্ভিস, ড্যাশবোর্ড এবং অ্যালার্ট বাড়ে।
বিনা গভর্ন্যান্সে Datadog (বা অন্য কোনো প্ল্যাটফর্ম) একটি নয়েজি স্ক্র্যাপবুকে পরিণত হতে পারে—শতকরা সামান্য ভিন্ন ড্যাশবোর্ড, অসামঞ্জস্যপূর্ণ ট্যাগ, অনির্ধারিত মালিকানা, এবং কেউ বিশ্বাস করে না এমন অ্যালার্ট।
ভালো গভর্ন্যান্স বোঝায় কে কি সিদ্ধান্ত নেবে, এবং প্ল্যাটফর্ম গুলিয়ে গেলে কে জবাবদিহি করবে:
কিছু হালকা কন্ট্রোল দীর্ঘ নীতি‑ডকস থেকে বেশি কাজ করে:
service, env, team, tier) এবং অপশনাল ট্যাগের নিয়ম; CI‑তে প্রয়োগ করুনদ্রুত মানের স্কেল করার দ্রুত উপায় হলো কাজ শেয়ার করা:
চাইলে গভর্নড পাথটাকে সহজ করে দিন—কম ক্লিক, দ্রুত সেটআপ, এবং স্পষ্ট মালিকানা।
একবার অবজার্ভেবিলিটি প্ল্যাটফর্মের মত আচরণ করে, এটি প্ল্যাটফর্ম ইকোনমিতে চলে: বেশি টিম অ্যাডপ্ট করলে বেশি টেলিমেট্রি তৈরি হয়, এবং প্ল্যাটফর্ম আরও বেশি কার্যকর হয়।
ফ্লাইহুইল:
ক্যাচ হলো একই লুপ কস্টও বাড়ায়—আরো হোস্ট, কনটেইনার, লগ, ট্রেস, সিন্থেটিকস, কাস্টম মেট্রিকস বাজেট ছাড়িয়ে যেতে পারে যদি না মনোযোগী হন।
কিছু কৌশল:
কয়েকটি ছোট মেজার যা প্ল্যাটফর্ম ফেরত দিচ্ছে কিনা দেখায়:
এটি একটি প্রোডাক্ট রিভিউ হোক, অডিট নয়। প্ল্যাটফর্ম মালিক, কয়েকটি সার্ভিস টিম, এবং ফাইন্যান্স নিয়ে দেখা:
লক্ষ্যটা হলো শেয়ার্ড মালিকানা: কস্ট ইন্সট্রুমেন্টেশন সিদ্ধান্তে ইনপুট, কস্ট কমানোর জন্য পর্যবেক্ষণ বন্ধ করার কারণ নয়।
যদি অবজার্ভেবিলিটি প্ল্যাটফর্মে পরিণত হচ্ছে, আপনার টুল স্ট্যাক কেবল পয়েন্ট সলিউশন আর তার মতো আচরণ বন্ধ করে শেয়ার্ড ইনফ্রাস্ট্রাকচারে পরিণত করে। এই শিফট টুল স্প্রলটকে কেবল বিরক্তিকর নয় করে তোলে: এটি ডুপ্লিকেট ইনস্ট্রুমেন্টেশন, অসামঞ্জস্যপূর্ণ ডেফিনিশন (কি কে কাউন্ট করছে?), এবং অন‑কল লোড বাড়ায় কারণ সিগন্যালগুলো সারিবদ্ধ নয়।
কনসোলিডেশন মানে ডিফল্টভাবে “এক ভেন্ডর সবকিছু” নয়; এটা কম সিস্টেম অব রেকর্ড, স্পষ্ট মালিকানা, এবং কম জায়গায় মানুষকে দেখতে হবে—বিশেষত আউটেজে।
টুল স্প্রলটাইপিক্যালভাবে সময় তিন জায়গায় লুকানো খরচ করে: UI‑গুলোর মধ্যে হপিং‑এ সময়, ভাঙা ইন্টিগ্রেশন যেগুলো আপনাকে মেইনটেইন করতে হয়, এবং ফ্র্যাগমেন্টেড গভর্ন্যান্স (নামকরণ, ট্যাগ, রিটেনশন, এক্সেস)।
একটি বেশি কনসোলিডেটেড প্ল্যাটফর্ম কনটেক্সট সুসংহত করে, কনটেক্সট‑সুইচিং কমায়, সার্ভিস ভিউ স্ট্যান্ডার্ড করে, এবং ইনসিডেন্ট ওয়ার্কফ্লো রিপিটেবল করে তোলে।
স্ট্যাক (Datadog বা বিকল্প) বিবেচনা করার সময় নিচেগুলো চাপ দিন:
১–২ সার্ভিস নিন যেগুলোতে আসল ট্রাফিক আছে। একটি সিঙ্গেল সাকসেস মেট্রিক ঠিক করুন—যেমন “রুট‑কজ শনাক্তকরণ সময় ৩০ মিনিট থেকে ১০ মিনিটে নামানো” বা “নয়সি অ্যালার্ট ৪০% কমানো।” শুধু প্রয়োজনীয় ইনস্ট্রুমেন্টেশন করুন, দুই সপ্তাহ পরে রিভিউ করুন।
অভ্যন্তরীণ ডকস কেন্দ্রীভূত রাখুন যাতে লার্নিং কম্পাউন্ড হয়—পাইলট রানবুক, ট্যাগিং নিয়ম, এবং ড্যাশবোর্ডগুলো এক জায়গায় লিংক করুন (উদাহরণ: /blog/observability-basics ইন্টারনাল শুরু পয়েন্ট হিসেবে)।
আপনি একবারে Datadog “রোল আউট” করবেন না। ছোটো শুরু করুন, স্ট্যান্ডার্ডস আগে স্থির করুন, তারপর কাজগুলো স্কেল করুন যেগুলো কার্যকর।
Days 0–30: Onboard (দ্রুত মূল্য প্রমাণ করুন)
1–2 ক্রিটিক্যাল সার্ভিস এবং একটি কাস্টমার‑ফেসিং জার্নি বেছে নিন। লগ, মেট্রিক এবং ট্রেস ধারাবাহিকভাবে ইনস্ট্রুমেন্ট করুন, এবং যে ইন্টিগ্রেশনগুলোর উপর আপনি নির্ভর করেন সেগুলো সংযুক্ত করুন (ক্লাউড, Kubernetes, CI/CD, অন‑কল)।
Days 31–60: Standardize (পুনরাবৃত্তিমূলক করুন)
শিখেছি যা ডিফল্টে পরিণত করুন: সার্ভিস নামকরণ, ট্যাগিং, ড্যাশবোর্ড টেমপ্লেট, মনিটর নামকরণ ও মালিকানা। গোল্ডেন সিগন্যাল ভিউ তৈরি করুন এবং সবচেয়ে গুরুত্বপূর্ণ এন্ডপয়েন্টের জন্য মিনিমাল SLO সেট করুন।
Days 61–90: Scale (অচলাবস্থা ছাড়াই বিস্তার)
একই টেমপ্লেট দিয়ে অতিরিক্ত টিম অনবোর্ড করুন। গভর্ন্যান্স প্রবর্তন করুন (ট্যাগ রুল, প্রয়োজনীয় মেটাডেটা, নতুন মনিটরের রিভিউ প্রক্রিয়া) এবং কস্ট বনাম ইউসেজ ট্র্যাকিং চালু করুন যাতে প্ল্যাটফর্ম সুস্থ থাকে।
একবার আপনি অবজার্ভেবিলিটিকে প্ল্যাটফর্ম হিসেবে বিবেচনা করলে, সাধারণত ছোটো “গ্লু” অ্যাপ দরকার পড়ে: সার্ভিস ক্যাটালগ UI, রানবুক হাব, ইনসিডেন্ট টাইমলাইন পেজ, বা একটি ইন্টারনাল পোর্টাল যা মালিক → ড্যাশবোর্ড → SLO → প্লেবুক লিংক করে।
এগুলো হলো সেই লাইটওয়েট ইন্টারনাল টুলিং যা আপনি দ্রুত Koder.ai‑তে তৈরি করতে পারেন—চ্যাট‑জেনারেটেড ওয়েব অ্যাপ (সাধারণত React ফ্রন্টএন্ড, Go + PostgreSQL ব্যাকএন্ড), সোর্স‑কোড এক্সপোর্ট এবং ডেপ্লয়/হোস্টিং সাপোর্ট সহ। টিমগুলো এটি ব্যবহার করে গভর্ন্যান্স ও ওয়ার্কফ্লো সহজে ছেড়ে না দিয়ে প্রোটোটাইপ ও শিপ করে।
দুইটি 45‑মিনিট সেশন চালান: (1) “এখানে কিভাবে কুয়েরি করা হয়” শেয়ার্ড কুয়েরি প্যাটার্ন নিয়ে, এবং (2) “ট্রাবলশুটিং প্লেবুক”—সরল প্রবাহ: ইমপ্যাক্ট নিশ্চিত → ডেপ্লয় মার্কার দেখুন → সার্ভিস সংকীর্ণ করুন → ট্রেস দেখুন → ডিপেন্ডেন্সি হেল্থ নিশ্চিত করুন → রোলব্যাক/মিটিগেশন সিদ্ধান্ত।
একটি অবজার্ভেবিলিটি টুল হলো এমন একটি জিনিস যা আপনি যখন কোনো সমস্যা আসে তখন কনসাল্ট করেন (ড্যাশবোর্ড, লগ সার্চ, একটি কুয়েরি)। একটি অবজার্ভেবিলিটি প্ল্যাটফর্ম হলো এমন কিছু যা আপনি ক্রমাগত চালান: এটি টেলিমেট্রি, ইন্টিগ্রেশন, অ্যাক্সেস, মালিকানা, অ্যালার্টিং এবং ইনসিডেন্ট ওয়ার্কফ্লো স্ট্যান্ডার্ড করে যাতে ফলাফল উন্নত হয় (দ্রুত ডিটেকশন ও রেজল্যুশন)।
কারণ সবচেয়ে বড় লাভগুলো আসে ফলাফল থেকে, ভিজ্যুয়াল থেকে নয়:
চার্টগুলো সাহায্য করে, কিন্তু ধারাবাহিকভাবে MTTD/MTTR কমাতে আপনার শেয়ার্ড স্ট্যান্ডার্ড এবং ওয়ার্কফ্লো দরকার।
শুরুতে একটি অনিবার্য বেসলাইন যেখানে প্রতিটি সিগন্যাল থাকতে হবে:
serviceenv (prod, staging, )হাই‑কার্ডিনালিটি ফিল্ডগুলো (যেমন user_id, order_id, session_id) এক‑কাস্টমারের সমস্যা ডিবাগ করার জন্য চমৎকার, কিন্তু এগুলো সবজায়গায় ব্যবহার করলে খরচ বাড়ে এবং কুয়েরি ধীর হতে পারে.
ব্যবহার করুন পরিকল্পিতভাবে:
অধিকাংশ টিম সাধারণত স্ট্যান্ডার্ড করে:
প্রাকটিক্যাল ডিফল্ট হলো:
আপনার কন্ট্রোল চাহিদার সাথে মিলে এমন একটি পথ বাছুন, তারপর সমস্ত পথে একই নামকরণ/ট্যাগ নিয়ম জোরদার করুন।
কাছে‑থেকে মানানসই সিদ্ধান্তগুলো নিন:
এভাবে টিমগুলির গতি বজায় থাকবে কিন্তু প্রতিটি টিম আলাদা স্কিমা তৈরি করে ঝামেলা তৈরি হবে না।
একটি ইন্টিগ্রেশন কেবল ডেটা পাইপ নয়—এতে সাধারণত তিনটি অংশ থাকে:
বিশেষ করে শেষটা ইন্টিগ্রেশনকে বিতরণ চ্যানেলে পরিণত করে। যদি টুল শুধু পড়ে, সেটা ড্যাশবোর্ডিং ডেস্টিনেশন; যদি এটা লিখতেও পারে, তাহলে সেটা দৈনন্দিন কাজের অংশ হয়ে ওঠে।
কারণ ভালো ইন্টিগ্রেশনগুলো sensible ডিফল্টস নিয়ে আসে: prebuilt ড্যাশবোর্ড, সুপারিশকৃত মনিটর, পার্সিং রুল, এবং কমন ট্যাগ। প্রতিটি টিমকে নিজে থেকে আর কোনো “CPU ড্যাশবোর্ড” বা “Postgres alerts” বানাতে হয় না—তারা একটি শেয়ার্ড বেসলাইন থেকে কাস্টমাইজ করে।
এই স্ট্যান্ডার্ডাইজেশন বিশেষ গুরুত্বপূর্ণ যখন আপনি টুল কনসোলিডেট করছেন: ইন্টিগ্রেশনগুলো পুনরাবৃত্তিমূলক প্যাটার্ন তৈরি করে যা নতুন সার্ভিসগুলো অনুকরণ করতে পারে।
প্রায়োগিক তালিকা:
নিয়মগত টিপ: এমন ইন্টিগ্রেশনগুলোকে অগ্রাধিকার দিন যেগুলো ইনসিডেন্ট রেসপন্স তাত্ক্ষণিকভাবে উন্নত করে—শুধু আরো চার্ট যোগ না করে।
একটি প্ল্যাটফর্ম‑ভিত্তিক ভিউ প্রতিদিন ব্যবহারযোগ্য করে তোলে। টিমগুলো যদি একই মানসিক মডেল শেয়ার করে—‘সার্ভিস’ কী, ‘সুস্থ’ হলে কেমন, এবং প্রথমে কোথায় ক্লিক করবে—তবে ডিবাগিং দ্রুত হয় এবং হ্যান্ডঅফ পরিষ্কার হয়।
ভ্যানিটি ড্যাশবোর্ড এবং একবারের জন্য তৈরি করা অ্যালার্ট এড়িয়ে চলুন। যদি একটি কুয়েরি গুরুত্বপূর্ণ, সেটি সেভ করে নাম দিন এবং সার্ভিস ভিউতে লিংক করুন।
একটি ইনসিডেন্ট কেবল কাউকে পেজ করা নয়—এটি একটি ফোকাসড ট্রায়েজ লুপ হওয়া উচিত:
এরপর যোগাযোগ: কে ইনসিডেন্টের মালিক, ব্যবহারকারীরা কী দেখছে, পরবর্তী আপডেট কখন। মিটিগেশন‑এ আপনার কাছে “সেফ মুভস” থাকা ভালো: ফিচার ফ্ল্যাগ, ট্র্যাফিক শিফট, রোলব্যাক, রেট লিমিট, বা পরিচিত ওয়ার্কঅ্যারাউন্ড। শেষমেশ লার্নিং: হালকা পর্যালোচনা যা কি পরিবর্তন হয়েছে, কী কাজ করলো, এবং কী অটোমেট করা উচিত তা ধরে রাখে।
একটি ভাল রানবুক সংক্ষিপ্ত, মতামতপূর্ণ এবং সেফ হওয়া উচিত। এতে থাকা দরকার: লক্ষ্য (সার্ভিস রিস্টোর করা), স্পষ্ট মালিক/অন‑কল রোটেশন, ধাপে ধাপে চেকলিস্ট, সঠিক ড্যাশবোর্ড/মনিটরের লিঙ্ক, এবং যে “সেফ অ্যাকশনগুলো” ঝুঁকি কমায় (রোলব্যাক ধাপসহ)। যদি এটা ৩টা ভোরে চালানো নিরাপদ না হয়, তাহলে সেটি অনুপযুক্ত।
একটি SLO হলো ব্যবহারকারীর অভিজ্ঞতা সম্পর্কে একটি সরল অঙ্গীকার—যেমন “৩০ দিনের মধ্যে 99.9% রিকোয়েস্ট সফল” বা “p95 পেইজ লোড ২ সেকেন্ডের কম”।
ড্যাশবোর্ড যা সিস্টেম হেল্থ দেখায় (CPU, মেমরি) সেগুলোর চেয়ে SLO গ্রাহকের প্রভাব মাপতে বাধ্য করে। SLOs টিমকে সেই মেট্রিকগুলো মাপতে বলবে যেগুলো বাস্তবে ব্যবহারকারী অনুভব করে।
একটি error budget হলো আপনার SLO অনুযায়ী অনুমোদিত অনবিশ্বাস্যতার পরিমাণ। উদাহরণ: 30 দিনের মধ্যে 99.9% সফলতার অঙ্গীকার মানে ~43 মিনিটের ভুল গ্রহণযোগ্য।
এটি সিদ্ধান্ত নেয়ার জন্য ব্যবহারযোগ্য সিস্টেম তৈরি করে:
SLO alerting‑এ সবচেয়ে বেশি কার্যকর হয় burn rate‑এ আলার্ট করা, কাঁচা এরর কাউন্টে নয়। এর ফলে নয়েজ কমে:
অনেক টিম দুটি উইন্ডো ব্যবহার করে: একটি ফাস্ট বার্ন (দ্রুত পেজ) এবং একটি স্লো বার্ন (টিকিট/নোটিফাই)।
অ্যালার্টিং যেখানে অনেক অবজার্ভেবিলিটি প্রোগ্রাম আটকে যায়: ডেটা আছে, ড্যাশবোর্ড চমৎকার, কিন্তু অন‑কল অভিজ্ঞতা নোইসি ও অবিশ্বস্ত হয়। মানুষ যদি অ্যালার্ট উপেক্ষা শেখে, প্ল্যাটফর্ম ব্যবসা রক্ষা করার ক্ষমতা হারায়।
সাধারণ কারণগুলো:
রাউটিং, মালিকানা, সেভারিটি, এবং রক্ষণাবেক্ষণ উইন্ডো সঠিক করা হলে অ্যালার্টিং স্কেল করে।
সরল নিয়মগুলো:
ওপরন্তু, সিম্পল ডিফল্ট: উপসর্গগুলোর পরিবর্তে লক্ষণগুলোর উপর আলার্ট করুন—ইনপুট মেট্রিকস (CPU ইত্যাদি) কেবল তখনই পেজিং‑যোগ্য যদি সেগুলো ধারাবাহিকভাবে প্রভাবের পূর্বাভাস দেয়।
গভর্ন্যান্স বলতে মানুষের ও প্রক্রিয়ার নিয়ম বোঝায় যা প্ল্যাটফর্ম ব্যবহারযোগ্য রাখে যখন টিম, সার্ভিস, ড্যাশবোর্ড ও মনিটরের সংখ্যা বাড়ে।
ভালো গভর্ন্যান্স বলে দেয় কে সিদ্ধান্ত নেয়, কে জবাবদিহি করবে এবং কখন রিভিউ দরকার। প্ল্যাটফর্ম টীম স্ট্যান্ডার্ড ডিফাইন করে, সার্ভিস ওনার টেলিমেট্রি‑র গুণগত মান ধরে, সিকিউরিটি ও কমপ্লায়েন্স ডেটা হ্যান্ডলিং নিয়ম সেট করে, এবং লিডারশিপ বাজেট ও ব্যবসায়িক অগ্রাধিকার মিলায়।
কয়েকটি হালকা নিয়ন্ত্রণ বড়ো নীতিমালার চেয়ে বেশি ফল দেয়:
service, env, team, ) এবং CI-তে জবাবদিহি প্রয়োগপ্ল্যাটফর্ম‑ইকোনমিক্স শুরু হয়: আরো টিম অ্যাডপ্ট করলে বেশি টেলিমেট্রি হয়, ফলাফল আরও ব্যবহারযোগ্য হয়, ট্রাস্ট বাড়ে, আরো ইনস্ট্রুমেন্টেশন হয়।
কিন্তু একই লুপ খরচও বাড়ায়—হোস্ট, কনটেইনার, লগ, ট্রেস, কাস্টম মেট্রিক দ্রুত বাজেট ছাড়িয়ে যেতে পারে যদি তা সচেতনভাবে পরিচালিত না করা হয়।
প্রাকটিক্যাল কস্ট লিভার:
অবজার্ভেবিলিটি প্ল্যাটফর্মে আপনার টুল স্ট্যাক হলো শেয়ার্ড ইন্ফ্রাস্ট্রাকচার—এটি পয়েন্ট সলিউশনের সমষ্টি হিসেবে থাকা বন্ধ করে। টুল স্প্রল কেবল বিরক্তিকর নয়, এটি ডুপ্লিকেট ইনস্ট্রুমেন্টেশন, অসামঞ্জস্যপূর্ণ ডেফিনিশন, এবং অন‑কল লোড বাড়ায় কারণ সিগনালগুলো লাইনআপ করে না।
কনসোলিডেশন মানে স্বয়ংক্রিয়ভাবে “একটি ভেন্ডর” নয়; এটি কম সংখ্যক সিস্টেম অব রেকর্ড, স্পষ্ট মালিকানা, এবং আউটেজে মানুষগুলোকে কম জায়গায় দেখার সুবিধা দেয়।
একটি সিদ্ধান্ত চেকলিস্ট:
Datadog-কে একবারেই “রোল আউট” করা হয় না। ছোটো শুরু করুন, স্ট্যান্ডার্ডস দ্রুত নির্ধারণ করুন, তারপর যা কাজ করে তাকে স্কেল করুন।
30/60/90 দিনের রোলআউট:
Days 0–30: Onboard — 1–2 ক্রিটিক্যাল সার্ভিস ও কাস্টমার‑ফেসিং জার্নি ইনস্ট্রুমেন্ট করুন, লগ/মেট্রিক/ট্রেস সংযুক্ত করুন এবং প্রধান ইন্টিগ্রেশনগুলো যুক্ত করুন
Days 31–60: Standardize — সার্ভিস নামকরণ, ট্যাগ, ড্যাশবোর্ড টেমপ্লেট, মনিটর নামকরণ, মালিকানা নির্ধারণ; golden signals এবং মিনিমাল SLO
Days 61–90: Scale — একই টেমপ্লেট দিয়ে আরো টিম অনবোর্ড করুন; গভর্ন্যান্স চালু করুন এবং কস্ট বনাম ইউসেজ ট্র্যাক করা শুরু করুন
Koder.ai‑এর জায়গা: ছোটো “গ্লু” অ্যাপ—সার্ভিস ক্যাটালগ UI, রানবুক হাব, ইনসিডেন্ট টাইমলাইন, অথবা একজন মালিক → ড্যাশবোর্ড → SLO → প্লেবুক লিংক করা ইন্টারনাল পোর্টাল দ্রুত প্রোটোটাইপ ও ডিপ্লয় করতে সাহায্য করে।
প্রথম সপ্তাহে দ্রুত শিপ করার কুইক‑উইন:
ট্রেনিং: দুইটি 45‑মিনিট সেশন—(1) “এখানে কিভাবে কুয়েরি করা হয়” এবং (2) “ট্রাবলশুটিং প্লেবুক” ফ্লো
একটি কপি/পেস্ট চেকলিস্ট:
devteamversion (ডিপ্লয় ভার্সন বা git SHA)তাহলে চাইলে tier (frontend, backend, data) যোগ করতে পারেন—সরল কিন্তু দ্রুত ফল দেয় এমন ফিল্টার।
কিন্তু মূল ব্যাপার হলো এগুলো একই কনটেক্সট (service/env/version/request ID) শেয়ার করলে করেলেশন দ্রুত হয়।
এখানে মতবিরোধের বদলে সবাই দেখতে পায় একটি সংখ্যা যেটি ভিত্তি করে সিদ্ধান্ত নেওয়া যায়।
tierপুনরায় ব্যবহার করাই পুনরাবৃত্তি প্রতিরোধের দ্রুততম উপায়—শেয়ার্ড লাইব্রেরি, রিইউজেবল ড্যাশবোর্ড, ভার্সনড স্ট্যান্ডার্ড ইত্যাদি।
KPIs:
ত্রৈমাসিক ভ্যালু বনাম কস্ট রিভিউ চালান—টিম, ফাইন্যান্স ও প্ল্যাটফর্ম মালিকদের নিয়ে।
একটি পাইলট চালান: ১–২ সার্ভিস নিন, একটি সফলতার মেট্রিক বেছে নিন (যেমন রুট কজ শনাক্তকরণ সময় ৩০ মিনিট থেকে ১০ মিনিটে নামানো) এবং দুই সপ্তাহ পর রিভিউ করুন। অভ্যন্তরীণ ডকস কেন্দ্রীভূত রাখুন (উদা: /blog/observability-basics)।