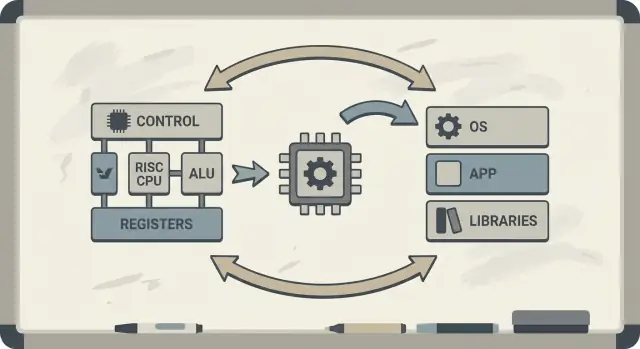
কেন প্যাটারসন ও RISC এখনও গুরুত্বপূর্ণ
ডেভিড প্যাটারসনকে প্রায়ই “RISC পায়োনিয়ার” হিসেবে পরিচয় করানো হয়, কিন্তু তার স্থায়ী প্রভাব কোনো একটি CPU ডিজাইনের চেয়েও বড়। তিনি কম্পিউটার নিয়ে একটি ব্যবহারিক চিন্তার পথ জনপ্রিয় করেছিলেন: পারফরম্যান্সকে মাপুন, সরল করুন এবং শেষ থেকে শেষ পর্যন্ত উন্নত করুন—চিপ যে নির্দেশগুলো বুঝে তা থেকে নিন পর্যন্ত সফটওয়্যার টুলস যা সেই নির্দেশগুলো তৈরি করে।
সাধারণ ভাষায় “RISC চিন্তা”
RISC (Reduced Instruction Set Computing) ধারণাটি যে একটি প্রসেসর দ্রুত এবং আরও পূর্বানুমেয়ভাবে চলতে পারে যখন এটি একটি ছোট সেটের সরল নির্দেশনার উপর ফোকাস করে। জটিল অপারেশনগুলোর একটি বিশাল মেনু হার্ডওয়্যারে তৈরি করার পরিবর্তে সাধারণ অপারেশনগুলোকে দ্রুত, নিয়মিত এবং পাইপলাইনের জন্য সহজ করুন। ফলাফল কোনোভাবে “কম সক্ষমতা” নয়—বরং, সহজ নির্মাণ ব্লকগুলো কার্যকরভাবে চালিত হলে বাস্তব ওয়ার্কলোডে প্রায়ই জয়লাভ করে।
কো‑ডিজাইন: চিপ ও কোড একে অপরকে উন্নত করছে
প্যাটারসন হার্ডওয়্যার‑সফটওয়্যার কো‑ডিজাইনেরও প্রবক্তা ছিলেন: এটি একটি ফিডব্যাক লুপ যেখানে চিপ আর্কিটেক্টরা, কম্পাইলার লেখকরা এবং সিস্টেম ডিজাইনাররা একসাথে পুনরাবৃত্তি করে।
যদি একটি প্রসেসর সাদামাটা প্যাটার্ন ভালোভাবে এক্সিকিউট করার জন্য ডিজাইন করা হয়, তাহলে কম্পাইলারগুলো নির্ভরযোগ্যভাবে সেই প্যাটার্ন তৈরি করতে পারে। যদি কম্পাইলারগুলো দেখায় যে বাস্তব প্রোগ্রামগুলো নির্দিষ্ট অপারেশনে (যেমন মেমরি অ্যাক্সেস) সময় কাটায়, হার্ডওয়্যার সেসব কেস আরও ভালভাবে সামলাতে সমন্বয় করা যায়। এ কারণে ISA (instruction set architecture) নিয়ে আলোচনা স্বাভাবিকভাবেই কম্পাইলার অপ্টিমাইজেশন, ক্যাশিং এবং পাইপলাইনিং‑এর সাথে যুক্ত হয়।
আপনি এই আর্টিকেল থেকে কী পাবেন
আপনি জানতে পারবেন কেন RISC ধারণাগুলো কেবল কাঁচা গতি নয় বরং পারফরম্যান্স‑প্রতি‑ওয়াটের সাথে কিভাবে জড়িত, কেন “পূর্বানুমেয়তা” আধুনিক CPU ও মোবাইল চিপগুলোকে আরও দক্ষ করে তোলে, এবং এই নীতি আজকের ডিভাইসে—ল্যাপটপ থেকে ক্লাউড সার্ভার পর্যন্ত—কিভাবে দেখা যায়।
যদি আপনি গভীরে যাওয়ার আগে মূল ধারণাগুলোর মানচিত্র দেখতে চান, তবে /blog/key-takeaways-and-next-steps এ যান।
যে সমস্যার জন্য RISC সাড়া দিল
শুরুতে মাইক্রোপ্রসেসরগুলো কঠোর সীমাবদ্ধতায় নির্মিত হত: চিপে সারের সার্কিটের জায়গা সীমিত ছিল, মেমরি ব্যয়বহুল ছিল, এবং স্টোরেজ ধীর ছিল। ডিজাইনাররা এমন কম্পিউটার পাঠানোর চেষ্টা করছিলেন যা সাশ্রয়ী এবং “যথেষ্ট দ্রুত”, প্রায়ই ছোট ক্যাশ (বা কোনও ক্যাশই নেই), মার্জিত ক্লক স্পিড, এবং সফটওয়্যারের চাহিদার তুলনায় খুব সীমিত মেইন মেমরি নিয়ে।
পুরনো বাজি: জটিল নির্দেশ = দ্রুত প্রোগ্রাম
সেই সময়ে একটি জনপ্রিয় ধারণা ছিল যে যদি CPU আরো শক্তিশালী, উচ্চ‑স্তরের নির্দেশ অফার করে—যেগুলো একসাথে একাধিক ধাপ করতে পারে—তাহলে প্রোগ্রামগুলো দ্রুত চলবে এবং লেখা সহজ হবে। যদি এক নির্দেশেই “কয়েকটি কাজ করে ফেলা” যায়, তাতে সময় ও মেমরি বাঁচবে—এই যুক্তি চলে।
এটাই অনেক CISC (complex instruction set computing) ডিজাইনের অন্তর্নিহিত অনুভূতি: প্রোগ্রামার ও কম্পাইলারকে ফ্যান্সি অপারেশনের একটি বড় টুলবক্স দিন।
মিল না থাকা: CPU কী দেয় বনাম বাস্তবে কি ব্যবহার হয়
ধরা হয়েছিল যে বাস্তব প্রোগ্রামগুলো (এবং এগুলোকে অনুবাদ করা কম্পাইলারগুলো) সেই জটিলতাকে অভিন্নভাবে উপভোগ করে না। সবচেয়ে জটিল অনেক নির্দেশই বিরলভাবে ব্যবহৃত হত, আর একটি ছোট সেটের সরল অপারেশন—লোড ডেটা, স্টোর ডেটা, যোগ, তুলনা, ব্রাঞ্চ—বারবার দেখা যেত।
একই সময়ে, জটিল নির্দেশগুলোর বিশাল মেনু সমর্থন করা CPU গুলোকে নির্মাণে কঠিন ও অপ্টিমাইজ করতে ধীর করত। জটিলতা চিপের এলাকা ও ডিজাইন প্রচেষ্টাকে শোষণ করত যা সাধারণ, দৈনন্দিন অপারেশনগুলোকে দ্রুত এবং পূর্বানুমেয় করার দিকে ব্যবহার করা যেতে পারত।
RISC সেই ফাঁকটির প্রতিক্রিয়া: CPU‑কে সেভাবে ফোকাস করুন যা সফটওয়্যার বাস্তবে সবচেয়ে বেশি করে, এবং সেই পথগুলোকে দ্রুত করুন—তারপর কম্পাইলারকে আরও ‘বিগ বাজেট’ কাজ করতে দিন একটি পদ্ধতিগতভাবে।
RISC বনাম CISC: সাধারণ ভাষায় ধারণা
CISC (Complex Instruction Set Computing) একটি কর্মশালার মতো যেখানে অনেক বিশেষায়িত, ফ্যান্সি টুলস আছে—প্রতিটি এক ধাক্কায় অনেক কিছু করতে পারে। একটি একক “নির্দেশ” হয়তো মেমরি থেকে ডেটা লোড করে, হিসাব করে, এবং ফলাফলটি সংরক্ষণ করে—সব কিছু একসাথে।
RISC (Reduced Instruction Set Computing) হল একটি ছোট সেট নির্ভরযোগ্য টুল কাঁধে নেওয়ার মতো—যেগুলো আপনি নিয়মিত ব্যবহার করেন: হাতোড়া, স্ক্রু‑ড্রাইভার, পরিমাপের টেপ—এবং সবকিছু পুনরাবৃত্তির ধাপে তৈরি করেন। প্রতিটি নির্দেশ সাধারণত একটি ছোট, স্পষ্ট কাজ করে।
কেন “সরল” হওয়া দ্রুততর হতে পারে
যখন নির্দেশগুলো সরল এবং ইউনিফর্ম হয়, CPU সেগুলোকে একটি পরিষ্কার assembly line (পাইপলাইন) দিয়ে নির্বাহ করতে পারে। সেই assembly line ডিজাইন করা সহজ, উচ্চ ক্লক‑স্পিডে চালানো সহজ, এবং ব্যস্ত রাখা সহজ।
CISC‑ধাঁচের “একটায় অনেক” নির্দেশগুলোর সঙ্গে CPU প্রায়শই একটি জটিল নির্দেশ ডিকোড করে অভ্যন্তরীণভাবে ছোট ধাপে ভেঙে দেয়। এতে জটিলতা বাড়ে এবং পাইপলাইনকে মসৃণ রাখাটা কঠিন হয়ে পড়ে।
পূর্বানুমেয়তা গুরুত্বপূর্ণ
RISC লক্ষ্য করে পূর্বানুমেয় নির্দেশ সময়—অনেক নির্দেশ প্রায় একই সময় নেয়। পূর্বানুমেয়তা CPU‑কে কাজ শিডিউল করতে সাহায্য করে এবং কম্পাইলারকে এমন কোড জেনারেট করতে সুবিধা দেয় যা পাইপলাইনকে খালি না করে।
ব্যবসা‑বদল (trade‑offs) এবং কেন তা প্রায়ই ফলপ্রসূ
RISC সাধারণত একই কাজ করতে আরও নির্দেশ প্রয়োজন করে। এর মানে হতে পারে:\
- সামান্য বড় প্রোগ্রাম সাইজ (আরও কোড বাইট)\n- মেমরি থেকে বেশি নির্দেশ ফেচ করা
কিন্তু যদি প্রতিটি নির্দেশ দ্রুত হয়, পাইপলাইন মসৃণ থাকে, এবং সাধারিত ডিজাইন হয়—তাহলে তা এখনও ভাল সমঝোতা হতে পারে। বাস্তবে, ভাল অনুকূলিত কম্পাইলার ও ভালো ক্যাশিং “আরও নির্দেশ”‑এর নেতিবাচকতা কাটিয়ে দিতে পারে—এবং CPU সময়ের বেশি অংশ কাজে ব্যয় করে, জটিল নির্দেশ খোলার সময়ে নয়।
বার্কলে RISC এবং “মাপো, তারপর ডিজাইন করো” মনোভাব
বার্কলে RISC শুধুমাত্র একটি নতুন ISA ছিল না। এটি একটি গবেষণা মনোভাব ছিল: কাগজে সৌন্দর্যপূর্ণ যা মনে হয় তা দিয়ে শুরু করো না—প্রোগ্রামগুলো বাস্তবে কী করে সেই দিয়েই শুরু করে CPU‑কে সেই বাস্তবতার চারপাশে গঠন করো।
ছোট, দ্রুত কোর + স্মার্ট কম্পাইলার
ধারণাগত স্তরে বার্কলে দলটি এমন একটি CPU কোরের লক্ষ্যে ছিল যা এতটাই সরল যে তা খুব দ্রুত এবং পূর্বানুমেয়ভাবে চালাতে পারে। বহু জটিল নির্দেশের ‘চালচিত্র’ হার্ডওয়্যারে ভরানোর পরিবর্তে তারা কম্পাইলারের উপর বেশি কাজ রেখেছিল: সরল নির্দেশ বেছে নেওয়া, সেগুলো ভালোভাবে শিডিউল করা, এবং ডেটা যতটা সম্ভব রেজিস্টারে রাখা।
এই শ্রমবিভাগটি গুরুত্বপূর্ণ ছিল। ছোট, পরিষ্কার কোরটি কার্যকরভাবে পাইপলাইন করা সহজ, বোঝা সহজ, এবং প্রতি ট্রানজিস্টরে প্রায়ই দ্রুত। কম্পাইলার, পুরো প্রোগ্রাম দেখে, এমনভাবে পরিকল্পনা করতে পারে যা হার্ডওয়্যার অন‑দ‑ফ্লাই সহজে করতে পারে না।
বাস্তব ওয়ার্কলোড মাপো, অনুমানের উপর নয়
ডেভিড প্যাটারসন মাপার উপর জোর দিলে কারণ কম্পিউটার ডিজাইনে প্রচুর মোহনীয় মিথ আছে—এমন ফিচারগুলো যেগুলো শুনতে ব্যবহারযোগ্য মনে হয় কিন্তু বাস্তবে কোডে বিরল। বার্কলে RISC বেঞ্চমার্ক ও ওয়ার্কলোড ট্রেস ব্যবহার করে হট পাথগুলো (লুপ, ফাংশন কল, মেমরি অ্যাক্সেস) খুঁজে পেতে বলেছিল।
এটি সরাসরি “সাধারণ কেসকে দ্রুত করো” নীতির সাথে জড়িত। যদি বেশিরভাগ নির্দেশ সহজ অপারেশন ও লোড/স্টোর হয়, তবে সেই ঘন ঘন ঘটিত কেসগুলোর অপ্টিমাইজেশন বিরল জটিল নির্দেশকে দ্রুত করার চেয়েও বেশি ফল দেবে।
RISC = চিন্তার একটা উপায়
স্থায়ী শিক্ষাটি হল RISC ছিল একদিকে আর্কিটেকচার, অন্যদিকে একটি মানসিকতা: যা ঘনঘন হয় তা সরল করো, ডেটা দিয়ে যাচাই করো, এবং হার্ডওয়্যার ও সফটওয়্যারকে একটি সিস্টেম হিসেবে বিবেচনা করো যা একসাথে টিউন করা যায়।
হার্ডওয়্যার–সফটওয়্যার কো‑ডিজাইন বলতে কী বোঝায়
হার্ডওয়্যার–সফটওয়্যার কো‑ডিজাইন ধারণাটি হল যে আপনি CPU আলাদাভাবে ডিজাইন করো না। আপনি চিপ এবং কম্পাইলার (কখনো‑কখনো অপারেটিং সিস্টেম) একে অপরকে মাথায় রেখে ডিজাইন করো, যাতে বাস্তব প্রোগ্রামগুলো দ্রুত এবং দক্ষভাবে চলে—শুধু সিন্থেটিক “বেস্ট‑কেস” নির্দেশ ধারার জন্য নয়।
একটি সাধারণ ফিডব্যাক লুপ
কো‑ডিজাইন একটি ইঞ্জিনিয়ারিং লুপের মতো কাজ করে:\
- ISA পছন্দ: নির্দেশনা সেট আর্কিটেকচার (ISA) ঠিক করে যে CPU কী সহজে প্রকাশ করতে পারে (উদাহরণস্বরূপ, “load/store” মেমরি অ্যাক্সেস, প্রচুর রেজিস্টার, সরল অ্যাড্রেসিং মোড)।\
- কম্পাইলার কৌশল: কম্পাইলার খাপ খায়—গরম ভেরিয়েবলগুলো রেজিস্টারে রাখে, স্টল এড়াতে নির্দেশগুলোর পুনরায় শিডিউল করে, এবং কলিং কনভেনশন বেছে নেয় যা ওভারহেড কমায়।\
- ওয়ার্কলোড ফলাফল: আপনি বাস্তব প্রোগ্রাম (কম্পাইলার, ডাটাবেস, গ্রাফিক্স, OS কোড) মাপে এবং দেখেন সময় ও শক্তি কোথায় যায়।\
- পরবর্তী ডিজাইন: আপনি ঐ মাপের ভিত্তিতে ISA ও মাইক্রোআর্কিটেকচার (পাইপলাইনের গভীরতা, রেজিস্টারের সংখ্যা, ক্যাশ সাইজ) টুইক করেন।
এখানে একটি ছোট C লুপ যা সম্পর্কটিকে হাইলাইট করে:
for (int i = 0; i < n; i++)
sum += a[i];
RISC‑ধাঁচের ISA‑তে, কম্পাইলার সাধারণত sum ও i রেজিস্টারে রাখে, a[i]‑এর জন্য সরল load নির্দেশ ব্যবহার করে, এবং একটি লোড ফ্লাইট আছে এমন সময় CPU ব্যস্ত রাখার জন্য নির্দেশ শিডিউলিং করে।
যদি কম্পাইলারকে উপেক্ষা করা হয় তাহলে সিলিকন ও শক্তি নষ্ট হয়
যদি একটি চিপ জটিল নির্দেশ বা বিশেষ হার্ডওয়্যার যোগ করে যা কম্পাইলারগুলো অপ্রায়ই ব্যবহার করে, সেই এলাকা তখনও শক্তি এবং ডিজাইন প্রচেষ্টা খরচ করে। এসময় কম্পাইলারের উপর নির্ভর করা “বিরক্তিকর” জিনিসগুলো—যেমন পর্যাপ্ত রেজিস্টার, পূর্বানুমেয় পাইপলাইন, কার্যকর কলিং কনভেনশন—অবহেলিত থাকতে পারে।
প্যাটারসনের RISC চিন্তা বাস্তব সফটওয়্যারের লাভবান হওয়ার সম্ভাবনা থাকা জায়গায় সিলিকন খরচ করার উপর জোর দিয়েছিল।
পাইপলাইন, পূর্বানুমেয়তা, ও কম্পাইলারের সাহায্য
বিল্ডকে ক্রেডিটে পরিণত করুন
আপনি যা তৈরি করেন তা শেয়ার করে বা অন্যদের Koder.ai-এ রেফার করে ক্রেডিট পান।
একটি মূল RISC ধারণা ছিল CPU‑এর “অ্যাসেম্বলি লাইন” রাখার কাজ আরও সহজ করা। ওই assembly line হল পাইপলাইন: প্রতিটি নির্দেশ সম্পূর্ণ শেষ হওয়ার আগে পরেরটি শুরু করার বদলে, প্রসেসর কাজকে পর্যায়ে ভাগ করে (fetch, decode, execute, write‑back) এবং এগুলো ওভারল্যাপ করে। সবকিছু 흐িত হলে, আপনি প্রায় এক নির্দেশ প্রতি সাইকেল পূর্ণ করতে পারেন—যেমন বহু‑স্টেশন ফ্যাক্টরিতে গাড়ি এগিয়ে চলে।
কেন সরল নির্দেশ লাইনকে চলমান রাখে
পাইপলাইন তখনই ভালো কাজ করে যখন লাইনের উপর আসা প্রতিটি আইটেম একরকম। RISC নির্দেশগুলো আপাতত ইউনিফর্ম ও পূর্বানুমেয় (প্রায়শই ফিক্সড লেংথ, সরল অ্যাড্রেসিং) হওয়ার জন্য ডিজাইন করা হয়। এতে "স্পেশাল কেস" কমে—কোনো এক নির্দেশ অতিরিক্ত সময় বা বিরল রিসোর্স দাবি করে না।
যখন পাইপলাইন থামে: হ্যাজার্ড ও স্টল
বাস্তব প্রোগ্রামগুলো নিখুঁতভাবে মসৃণ নয়। কখনও কখনও একটি নির্দেশ পূর্ববর্তীটির ফলাফলের ওপর নির্ভর করে (আপনি কোনো মান আগে তৈরি হওয়ার আগেই ব্যবহার করতে পারবেন না)। অন্য সময় CPU‑কে মেমরি থেকে ডেটার জন্য অপেক্ষা করতে হয়, বা ব্রাঞ্চ‑এর পর কোন পথ নেওয়া হবে তা না জানায়।
এই পরিস্থিতিগুলো স্টল সৃষ্টি করে—ক্ষুদ্র বিরতি যেখানে পাইপলাইনের একটি অংশ নির্গত থাকে। সরল ব্যাখ্যা: স্টল ঘটে যখন পরবর্তী স্টেজটি কাজ করতে পারে না কারণ যা দরকার তা পৌছায়নি।
ট্রাফিক কন্ট্রোলারের মতো কম্পাইলার
এখানেই হার্ডওয়্যার‑সফটওয়্যার কো‑ডিজাইনের সুবিধা স্পষ্টভাবে দেখা যায়। যদি হার্ডওয়্যার পূর্বানুমেয় হয়, তাহলে কম্পাইলার সাহায্য করতে পারে—নির্দেশগুলোর ক্রম পুনরায় সাজিয়ে (প্রোগ্রামের অর্থ বদলায় না) ফাঁকগুলো পূরণ করতে। উদাহরণস্বরূপ, কোনো মান উৎপন্ন হওয়ার জন্য অপেক্ষা করার সময় কম্পাইলার এমন একটি স্বাধীন নির্দেশ শিডিউল করতে পারে যা ঐ মানের ওপর নির্ভর করে না।
ফলাফল হল শেয়ার করা দায়িত্ব: সাধারণ কেসে CPU সহজ ও দ্রুত থাকে, আর কম্পাইলার বেশি পরিকল্পনা করে। একসাথে তারা স্টল কমায় এবং থ্রুপুট বাড়ায়—প্রায়ই জটিল নির্দেশ সেট ছাড়াই বাস্তব কর্মক্ষমতা উন্নত করে।
ক্যাশ ও মেমরি ওয়াল: যেখানে কো‑ডিজাইন ফল দেয়
একটি CPU কয়েক সাইকেলে সরল অপারেশন করতে পারে, কিন্তু মেইন মেমরি (DRAM) থেকে ডেটা ফেচ করতে কয়েক শত সাইকেল লাগতে পারে। সেই ফাঁক রয়েছে কারণ DRAM শারীরিকভাবে দূরে, ক্ষমতা এবং খরচের জন্য অপ্টিমাইজ করা, এবং ল্যাটেন্সি (একটি অনুরোধ কতক্ষণ নেয়) ও ব্যান্ডউইথ (এক সেকেন্ডে কত বাইট পাঠানো যায়) দ্বারা সীমাবদ্ধ।
যেহেতু CPU দ্রুত হলো, মেমরি একই হারে তাল মিলাতে পারেনি—এই বাড়তে থাকা অমিলকে প্রায়ই মেমরি ওয়াল বলা হয়।
কেশ ও লোক্যালিটি
ক্যাশ হল CPU‑র কাছে রাখা ছোট, দ্রুত মেমরি যাতে প্রতিটি অ্যাক্সেসে DRAM‑জালে পড়তে না হয়। এগুলো কাজ করে কারণ বাস্তব প্রোগ্রামগুলোতে লোক্যালিটি থাকে:
- টাইম-পসান লোক্যালিটি (Temporal locality): আপনি যদি কোনো ভ্যালু বা নির্দেশ সাম্প্রতিকভাবে ব্যবহার করে থাকেন, আবার দ্রুতই তা ব্যবহার করার সম্ভাবনা থাকে।
- স্প্যাশিয়াল লোক্যালিটি (Spatial locality): আপনি যদি একটি ঠিকানায় অ্যাক্সেস করে থাকেন, পরবর্তীতে কাছাকাছি ঠিকানায় অ্যাক্সেস করার সম্ভাবনা থাকে।
আধুনিক চিপগুলো কেশ স্ট্যাক করে (L1, L2, L3), চেষ্টা করে কাজের সেটকে কোরের কাছে রাখা।
ISA ও কম্পাইলার কিভাবে কেশ আচরণ প্রভাবিত করে
এখানেই হার্ডওয়্যার‑সফটওয়্যার কো‑ডিজাইন তার ফল দেয়। ISA ও কম্পাইলার একসাথে প্রোগ্রামের কতটা কেশ‑চাপে চাপ সৃষ্টি করে তা আকৃত করে।
- কোড সাইজ গুরুত্বপূর্ণ। বড় বাইনারি ও ভারি নির্দেশসিক্যন্স ইনস্ট্রাকশন ক্যাশ ভর করে ফেলতে পারে, স্টল ঘটায়। কোড ডেনসিটি বাড়ানো (উদাহরণ স্বরূপ, ঐচ্ছিক কমপ্রেসড নির্দেশ) ইনস্ট্রাকশন‑ক্যাশ হিট রেট বাড়াতে পারে।\n- অ্যাক্সেস প্যাটার্ন গুরুত্বপূর্ণ। RISC‑স্টাইল load/store ডিজাইন মেমরি অ্যাক্সেসগুলোকে স্পষ্ট করে তোলে। তখন কম্পাইলার লোডগুলোকে আগে শিডিউল করতে পারে, গরম ভ্যালুগুলো রেজিস্টারে ধরে রাখতে পারে, এবং অনাবশ্যক মেমরি ট্রাফিক কমাতে পারে।\n- লেআউট ও ব্লকিং। লুপ টাইলিং (blocking), ডেটা স্ট্রাকচার পুনরায় সাজানো, এবং প্রিফেচ হিন্টের মতো কম্পাইলার অপ্টিমাইজেশনগুলো “বিষম DRAM‑ভ্রমণ”কে পূর্বানুমেয় ক্যাশ হিটে পরিণত করার লক্ষ্য রাখে।
বাস্তব কর্মক্ষমতায় মেমরি ওয়াল
দৈনন্দিন কথায়, মেমরি ওয়ালই হলো কারণ একটি উচ্চ ক্লক‑স্পিড CPU তবুও স্লগিশ লাগতে পারে: একটি বড় অ্যাপ খোলা, ডাটাবেস কুয়েরি চালানো, একটি ফিড স্ক্রল করা, বা বড় ডেটাসেট প্রসেস করা—প্রায়ই ক্যাশ মিস ও মেমরি ব্যান্ডউইথেই বাধা পড়ে, কাঁচা আরিথমেটিক স্পিড না।
দক্ষতা: কেবল কাঁচা গতি নয়, পারফরম্যান্স‑প্রতি‑ওয়াট
বাস্তব পরিমাপের জন্য ডেপ্লয় করুন
আপনার অ্যাপ ডেপ্লয় ও হোস্ট করে দ্রুত এন্ড-টু-এন্ড আচরণ বেঞ্চমার্ক করুন।
অনেক বছর CPU আলোচনা একটি দৌড়ের মতো ছিল: যে চিপটি একটি কাজ দ্রুত শেষ করে সে “জিতেছে”। কিন্তু বাস্তব কম্পিউটারগুলো শারীরিক সীমার মধ্যে থাকে—ব্যাটারি ক্ষমতা, তাপ, ফ্যান শব্দ, এবং বিদ্যুৎ বিল।
এর কারণে পারফরম্যান্স‑প্রতি‑ওয়াট একটি মূল মেট্রিক হয়ে উঠেছে: আপনি যে শক্তি ব্যয় করে কতটা ব্যবহারযোগ্য কাজ পাচ্ছেন।
“পারফরম্যান্স‑প্রতি‑ওয়াট” বাস্তবে কী বোঝায়
এটি শক্তির প্রতি দক্ষতা হিসেবে ভাবুন, কৌতুকিক নয় শীর্ষ শক্তি। দুটি প্রসেসর দৈনন্দিন ব্যবহারে সমানভাবে দ্রুত অনুভূত হতে পারে, তবুও একটি কম শক্তিতে ঠিক করতে পারে—ঠান্ডা থাকে এবং একই ব্যাটারিতে বেশি সময় চলে।
ল্যাপটপ ও ফোনে এটি সরাসরি ব্যাটারি লাইফ ও আরামকে প্রভাবিত করে। ডেটা‑সেন্টারে এটি হাজার হাজার মেশিনের পাওয়ার ও কুলিং খরচ প্রভৃতি প্রভাবিত করে।
কেন সরল কোরগুলি প্রায়ই কম শক্তি নষ্ট করে
RISC চিন্তা CPU ডিজাইনকে হার্ডওয়্যারে কম কিছুর প্রতি উৎসাহিত করেছে, আরও পূর্বানুমেয়ভাবে কাজ করে। একটি সরল কোর শক্তি কমাতে কয়েকটি কারণ আছে:\
- কম জটিল কন্ট্রোল লজিক: প্রতি সাইকেলে কম অভ্যন্তরীণ অংশ টগল করে\
- পূর্বানুমেয় এক্সিকিউশন: পাইপলাইন ব্যস্ত রাখা সহজ এবং ব্যয়বহুল রিকভারি কাজ কম লাগে\
- কম্পাইলার‑বন্ধু ডিজাইন: সফটওয়্যারকে কাজ শিডিউল করতে দিলে হার্ডওয়্যারকে অতিরিক্ত অনুমান করতে হয় না\
উদ্দেশ্যটি নয় যে “সরল সবসময় ভালো।” বরঞ্চ জটিলতার একটি শক্তি খরচ আছে, এবং সুচিন্তিত ISA ও মাইক্রোআর্কিটেকচার কিছু কল্পনা দিয়ে অনেক দক্ষতা বিনিময় করতে পারে।
মোবাইল ও সার্ভার একই লক্ষ্য ভাগ করে
ফোন ব্যাটারি ও তাপ নিয়ে চিন্তিত; সার্ভার পাওয়ার ডেলিভারি ও কুলিং নিয়ে। ভিন্ন পরিবেশ হলেও একই শিক্ষা: সবথেকে দ্রুত চিপ জরুরি নয়। জিতেছে সেই ডিজাইনগুলো যা ধারাবাহিক থ্রুপুট দেয় কম শক্তি ব্যবহার করে।
RISC‑এর সঠিকতা ও জটিলতাগুলো
RISC কে প্রায়ই সংক্ষেপে “সরল নির্দেশ জিতলো” বলে বলা হয়, কিন্তু দীর্ঘস্থায়ী পাঠ আরও সূক্ষ্ম: ISA‑টি গুরুত্বপূর্ণ, তবু বাস্তব‑বিশ্বে অনেক লাভ এসেছে চিপগুলো কিভাবে নির্মিত হলো তাতে—শুধু কागজে ISA‑র চেহারা নয়।
“ইনস্ট্রাকশন সেট গুরুত্বপুর্ণ” বিতর্ক
শুরুতে RISC যুক্তি ছিল যে পরিষ্কার, ছোট ISA স্বয়ংক্রিয়ভাবে কম্পিউটারকে দ্রুত করে তুলবে। বাস্তবে, সবচেয়ে বড় স্পিডআপগুলো প্রায়ই সেই বাস্তবায়ন পছন্দ থেকেই এসেছে যা RISC সহজতর করেছিল: সরল ডিকোডিং, গভীর পাইপলাইনিং, উচ্চ ক্লক, এবং কম্পাইলার‑শিডিউলিং।
এই কারণেই দুইটি ভিন্ন ISA‑য়ের CPU পারফরম্যান্সে আশ্চর্যজনকভাবে কাছাকাছি হতে পারে যদি তাদের মাইক্রোআর্কিটেকচার, ক্যাশ সাইজ, ব্রাঞ্চ প্রেডিকশন, এবং ম্যানুফ্যাকচারিং প্রসেস আলাদা। ISA নিয়ম নির্ধারণ করে; মাইক্রোআর্কিটেকচার খেলা চালায়।
মাপাই বৈশিষ্ট্য‑চেকলিস্টকে পরাজিত করে
প্যাটারসন‑যুগীয় একটি বড় শিফট ছিল ডেটা থেকে ডিজাইন করা, অনুমানের উপর নয়। যেগুলো ব্যবহারিকভাবে প্রোগ্রামগুলো করে না সেসব নির্দেশ যোগ করার বদলে দলগুলো মাপা ওয়ার্কলোড দেখে হট কেসগুলো অপ্টিমাইজ করত।
এই মনোভাব প্রায়ই “ফিচার‑ড্রিভেন” ডিজাইনকে ছাড়িয়ে গিয়েছে, যেখানে জটিলতা সুবিধার তুলনায় দ্রুত বৃদ্ধি পায়। এটি ট্রেড‑অফগুলিকে পরিষ্কার করে তোলে: একটি নির্দেশ কয়েকটি লাইন কোড বাঁচাতে পারে, কিন্তু তা অতিরিক্ত সাইকেল, শক্তি, বা চিপ এলাকা খরচ করলে সেই খরচ সর্বত্র প্রভাব ফেলে।
একক বিজয়ীর গল্প নয়
RISC চিন্তা শুধু “RISC চিপ”‑কেই আকৃত করেছে না। সময়ের সাথে অনেক CISC CPU RISC‑সদৃশ অভ্যন্তরীণ কৌশল গ্রহণ করেছে (উদাহরণস্বরূপ, জটিল নির্দেশগুলোকে অভ্যন্তরীণভাবে সরল অপসে ভাঙা) তবে তাদের সামঞ্জস্যপূর্ণ ISA রেখেছে।
ফলাফল ছিল না “RISC CISC‑কে হারালো।” বরং এটা বিকাশ—পরিমাপ, পূর্বানুমেয়তা, এবং শক্ত হার্ডওয়্যার‑সফটওয়্যার সমন্বয়কে মূল্যায়ন করা—যা যেকোনো ISA‑র ক্ষেত্রে প্রযোজ্য।
MIPS থেকে RISC‑V: একটি চলমান সূত্র
RISC গবেষণায় থেকে আধুনিক অনুশীলনে পৌঁছাবার সবচেয়ে পরিষ্কার থ্রেডগুলোর একটা MIPS থেকে RISC‑V পর্যন্ত—দুইটি ISA যেগুলো সরলতা ও স্পষ্টতাকে বৈশিষ্ট্য হিসেবে গ্রহণ করেছে।
MIPS: একটি পরিষ্কার ISA যা বানানো ও শেখা সহজ
MIPS একে প্রায়ই শিক্ষামূলক ISA হিসেবে মনে রাখা হয়—and কারণে: নিয়মগুলো বোঝাতে সহজ, নির্দেশ ফরম্যাটগুলো ধারাবাহিক, এবং load/store মডেল কম্পাইলারকে অশান্তি দেয় না।
এই পরিষ্কারতা কেবল একাডেমিক নয়—MIPS প্রসেসর বাস্তবে বহু পণ্যেই পাঠিয়েছিল (ওয়ার্কস্টেশন থেকে এমবেডেড সিস্টেম), কারণ একটি সরল ISA দ্রুত পাইপলাইন, পূর্বানুমেয় কম্পাইলার, এবং কার্যকর টুলচেইন বানানো সহজ করে। হার্ডওয়্যারের আচরণ নিয়মিত হলে সফটওয়্যার সেটি ঘিরে পরিকল্পনা করতে পারে।
RISC‑V: ওপেন, ব্যবহারিক, এবং কো‑ডিজাইন‑সদৃশ
RISC‑V RISC চিন্তাকে নতুন জীবন দিয়েছে একটি বড় ধাপ নিয়ে MIPS কখনো করেনি: এটি একটি ওপেন ISA। এটি প্রণোদনা বদলে দেয়। বিশ্ববিদ্যালয়, স্টার্টআপ এবং বড় কোম্পানিগুলো পরীক্ষানিরীক্ষা, সিলিকন চালিয়ে দেওয়া, এবং টুলিং শেয়ার করতে পারে ISA‑র অ্যাক্সেস নিয়ে আলোচনায় আটকে না থেকে।
কো‑ডিজাইনের জন্য ওপেন হওয়া গুরুত্বপূর্ণ কারণ “সফটওয়্যার দিক” (কম্পাইলার, OS, রানটাইম) পাবলিকভাবে হার্ডওয়্যারের সাথে বিবর্তিত হতে পারে, কৃত্রিম বাধা ছাড়া।
মডিউলার এক্সটেনশন: প্রয়োজন হলে যোগ করুন
আরেকটি কারণ RISC‑V কো‑ডিজাইনের সাথে ভাল মানায় হল এর মডিউলার দৃষ্টিভঙ্গি। আপনি একটি ছোট বেস ISA থেকে শুরু করেন, তারপর নির্দিষ্ট চাহিদার জন্য এক্সটেনশন যোগ করেন—যেমন ভেক্টর ম্যাথ, এমবেডেড কনস্ট্রেইন্ট, বা নিরাপত্তা ফিচার।
এটি একটি স্বাস্থ্যকর ট্রেড‑অফ উৎসাহিত করে: সব সম্ভাব্য ফিচার একক মনোলিথিক ডিজাইনে ভরার পরিবর্তে, দলগুলো হার্ডওয়্যার ফিচারগুলোকে বাস্তবে চালিত সফটওয়্যারের সাথে মিলিয়ে নিতে পারে।
যদি আপনি একটি গভীর প্রাইমার চান, দেখুন /blog/what-is-risc-v।
আধুনিক কম্পিউটিং‑এ কো‑ডিজাইন কিভাবে দেখা যায়
আপনার জন্য উপযোগী টিয়ার বাছুন
আপনি কীভাবে তৈরি ও শিপেন তা অনুযায়ী Free, Pro, Business, এবং Enterprise তুলনা করুন।
কো‑ডিজাইন RISC যুগের একটি ঐতিহ্যগত পাদছায়া নয়—এটি আধুনিক কম্পিউটিং আরও দ্রুত এবং দক্ষ হতে থাকার উপায়। মূল ধারণা এখনও প্যাটারসন‑স্টাইল: আপনি শুধু হার্ডওয়্যার বা শুধু সফটওয়্যার দিয়ে জিতবেন না। জয় তখনই যখন দুটোই একে অপরের শক্তি ও সীমাবদ্ধতার সাথে মিলবে।
প্রতিদিনের ডিভাইসে RISC চিন্তা
স্মার্টফোন ও অনেক এমবেডেড ডিভাইস RISC নীতির উপর জোর দেয় (অften ARM‑ভিত্তিক): সরল নির্দেশ, পূর্বানুমেয় এক্সিকিউশন, এবং শক্তি ব্যবহারে জোর।
পূর্বানুমেয়তা কম্পাইলারকে দক্ষ কোড জেনারেট করতে সাহায্য করে এবং ডিজাইনারদের এমন কোর বানাতে দেয় যা স্ক্রল করার সময় কম শক্তি নিচ্ছে, কিন্তু ক্যামেরা পাইপলাইন বা গেমের জন্য ঝটপট বর্ষণ করতে পারে।
ল্যাপটপ ও সার্ভারও একই লক্ষ্য অনুসরণ করছে—বিশেষত performance‑per‑watt‑এ।_instruction set‑টি ঐতিহ্যগতভাবে “RISC” না হলেও, অনেক অভ্যন্তরীণ ডিজাইন পছন্দ RISC‑সদৃশ দক্ষতার লক্ষ্য রাখে: গভীর পাইপলাইনিং, বিস্তৃত এক্সিকিউশন, এবং বাস্তব সফটওয়্যার আচরণের সাথে টিউন করা শক্তি ব্যবস্থাপনা।
অ্যাক্সেলারেটর‑গুলো কো‑ডিজাইনের বাস্তব অনুশীলন
GPU, AI অ্যাক্সেলারেটর (TPU/ NPU), এবং মিডিয়া ইঞ্জিনগুলো অনুশীলনে কো‑ডিজাইনের একটি রূপ: সাধারণ উদ্দেশ্যের CPU‑র মাধ্যমে সব কাজ চাপানোর বদলে প্ল্যাটফর্ম এমন হার্ডওয়্যার দেয় যা সাধারণ ক্যালকুলেশন প্যাটার্নের সাথে মিলে।
এটি কেবল “অতিরিক্ত হার্ডওয়্যার” নয়; যা এটাকে কো‑ডিজাইন করে তা হল আশেপাশের সফটওয়্যার স্ট্যাক:
- GPU‑গুলো তাদের গতি পায় প্রোগ্রামিং মডেল যেমন CUDA এবং API‑গুলোর (Vulkan/Metal) মাধ্যমে।\n- AI অ্যাক্সেলারেটরগুলো নির্ভর করে কম্পাইলার ও গ্রাফ অপ্টিমাইজারগুলোর ওপর যা একটি মডেলকে চিপের প্রিয় অপারেশনে রূপান্তর করে।\n- ভিডিও এনকোডার/ডিকোডার কাজ করে কারণ OS, ব্রাউজার, এবং অ্যাপগুলো সেগুলো ব্যবহার করার জন্য লেখা হয়।
যদি সফটওয়্যার অ্যাক্সেলারেটরকে টার্গেট না করে, তাত্ত্বিক গতি তাত্ত্বিকই থেকে যায়।
সফটওয়্যার স্ট্যাকও পারফরম্যান্সের অংশ
দুইটি প্ল্যাটফর্ম схожих স্পেস‑স্পেসই ভিন্ন অনুভূতি দিতে পারে কারণ “বাস্তব পণ্য”‑এর মধ্যে কম্পাইলার, লাইব্রেরি, এবং ফ্রেমওয়ার্ক অন্তর্ভুক্ত। একটি ভাল অনুকূলিত ম্যাথ লাইব্রেরি (BLAS), একটি ভালো JIT, বা একটি স্মার্ট কম্পাইলার অনেক বড় লাভ দিতে পারে চিপ না বদলে।
এই কারণেই আধুনিক CPU ডিজাইন প্রায়ই বেঞ্চমার্ক‑চালিত: হার্ডওয়্যার টিমগুলো কম্পাইলার ও ওয়ার্কলোডগুলো কী করে তা দেখে, তারপর কমন কেস দ্রুত করার জন্য ফিচার (ক্যাশ, ব্রাঞ্চ প্রেডিকশন, ভেক্টর নির্দেশ, প্রিফেচিং) গুছায়।
দ্রুত চেকলিস্ট: কি দেখবেন
একটি প্ল্যাটফর্ম (ফোন, ল্যাপটপ, সার্ভার, বা এম্বেডেড বোর্ড) মূল্যায়ন করলে কো‑ডিজাইন সিগন্যালগুলো খুঁজুন:\
- ওয়ার্কলোড ম্যাচ: আপনার অ্যাপগুলো CPU‑বাউন্ড, GPU‑বাউন্ড, মেমরি‑বাউন্ড, না কি অ্যাক্সেলারেটর‑বন্ধু?\
- অ্যাক্সেলারেটরের উপস্থিতি: কি কোনো NPU/GPU/মিডিয়া ইঞ্জিন আছে—এবং আপনার টুলসগুলো সত্যিই সেগুলো ব্যবহার করে?\
- কম্পাইলার/টুলচেইন পরিপক্কতা: কি অপ্টিমাইজড বিল্ড, ভালো প্রোফাইলিং টুল এবং সক্রিয় সাপোর্ট আছে?\
- লাইব্রেরি ইকোসিস্টেম: কি গুরুত্বপূর্ণ লাইব্রেরি (ম্যাথ, ভিশন, ক্রিপ্টো) ওই হার্ডওয়্যারের জন্য টিউন করা আছে?\
- পাওয়ার আচরণ: কি আপনি আপনার থার্মাল/পাওয়ার সীমার মধ্যে টিকে টেকসই পারফরম্যান্স পাচ্ছেন?
আধুনিক কম্পিউটিং অগ্রগতি একটি একক “দ্রুত CPU” দিয়ে কম নয়; বরং একটি সমগ্র হার্ডওয়্যার‑প্লাস‑সফটওয়্যার সিস্টেমের ফলে হয় যা বাস্তব ওয়ার্কলোডের চারপাশে গঠন—মাপা, তারপর ডিজাইন।
মূল শিক্ষা ও ব্যবহারিক পরবর্তী পদক্ষেপ
RISC চিন্তা ও প্যাটারসনের বৃহত্তর বার্তা কয়েকটি স্থায়ী পাঠে সিদ্ধ করা যায়: যা দ্রুত হওয়া উচিত তা সরল করো, বাস্তবে যা ঘটে তা মাপো, এবং হার্ডওয়্যার ও সফটওয়্যারকে এক সিস্টেম মনে করো—কারণ ব্যবহারকারীরা সমগ্র অভিজ্ঞতাটাই দেখে, উপাদান নয়।
রাখার মতো পাঠ
প্রথমত, সরলতা একটি কৌশল, নান্দনিকতা নয়। একটি পরিষ্কার ISA এবং পূর্বানুমেয় এক্সিকিউশন কম্পাইলারকে ভালো কোড জেনারেট করতে এবং CPU‑কে সেই কোড দক্ষভাবে চালাতে সহজ করে।
দ্বিতীয়ত, মাপা অনুমানের চেয়ে ভালো। প্রতিনিধিত্বমূলক ওয়ার্কলোড দিয়ে বেঞ্চমার্ক করুন, প্রোফাইলিং ডেটা সংগ্রহ করুন, এবং বাস্তব বটল‑নেকগুলি ডিজাইন সিদ্ধান্তকে গাইড করে—চাই সেটা কম্পাইলার অপ্টিমাইজেশন টিউন করা, একটি CPU SKU বেছে নেওয়া, বা একটি হট পাথ পুনরায় ডিজাইন করা হোক।
তৃতীয়ত, কো‑ডিজাইনে লাভ একত্রে বাড়ে। পাইপলাইন‑বন্ধু কোড, কেশ‑সচেতন ডেটা স্ট্রাকচার, এবং বাস্তব পারফরম্যান্স‑প্রতি‑ওয়াট লক্ষ্যগুলি সাধারণত তাত্ত্বিক শীর্ষ থ্রুপুটের চেয়ে বেশি ব্যবহারিক গতি দেয়।
প্রোডাক্ট টিমগুলোর জন্য ব্যবহারিক পরবর্তী পদক্ষেপ
যদি আপনি একটি প্ল্যাটফর্ম (x86, ARM, বা RISC‑V ভিত্তিক সিস্টেম) নির্বাচন করছেন, ব্যবহারকারীরা কিভাবে ব্যবহার করবে তা অনুযায়ী এটিকে মূল্যায়ন করুন:\
- এন্ড‑টু‑এন্ড সিনারিও (স্টার্টআপ টাইম, স্টেডি‑স্টেট থ্রুপুট, টেইল ল্যাটেন্সি) বেঞ্চমার্ক করুন, কেবল মাইক্রোবেন্চমার্ক নয়।\
- পারফরম্যান্সের পাশাপাশি দক্ষতা মেট্রিক (ওয়াট, থার্মাল, ব্যাটারি প্রভাব) ট্র্যাক করুন।\
- পুনরাবৃত্তি করুন: প্রোফাইল → এক জিনিস পরিবর্তন → পুনরায় মাপা। ছোট, যাচাইকৃত ধাপগুলো মিলিয়ে বড় লাভে পরিণত হয়।
আপনি যদি এই মাপগুলোকে বাস্তব সফটওয়্যার রিলিজে পরিণত করার কাজ করেন, তাহলে বিল্ড–মাপ লুপটি সংক্ষিপ্ত করা সহায়ক হতে পারে। উদাহরণস্বরূপ, দলগুলো Koder.ai ব্যবহার করে চ্যাট‑চালিত ওয়ার্কফ্লো (ওয়েব, ব্যাকএন্ড, মোবাইল) দিয়ে বাস্তব অ্যাপ প্রোটোটাইপ ও বিবর্তিত করে, তারপর প্রতিটি পরিবর্তনের পরে একই এন্ড‑টু‑এন্ড বেঞ্চমার্ক পুনরায় চালায়। প্ল্যানিং মোড, স্ন্যাপশট, ও রোলব্যাকের মতো ফিচারগুলো প্যাটারসন যে “মাপো, তারপর ডিজাইন করো” শৃঙ্খলাকে আধুনিক প্রোডাক্ট ডেভেলপমেন্টে প্রযোজ্য করে।
দক্ষতার উপর একটি গভীর প্রাইমারের জন্য দেখুন /blog/performance-per-watt-basics। পরিবেশগুলি তুলনা করে খরচ/পারফরম্যান্স ট্রেড‑অফ অনুমান করতে /pricing সাহায্য করতে পারে।
স্থায়ী শিক্ষা: সরলতা, মাপা, এবং কো‑ডিজাইন—এই আইডিয়াগুলো আজও লাভ দিচ্ছে, বাস্তবায়নগুলি MIPS‑যুগের পাইপলাইন থেকে আধুনিক হেটেরোজিনিয়াস কোর ও নতুন ISA‑গুলোর (যেমন RISC‑V) দিকে বিবর্তিত হলেও।