স্কোপ ও ব্যবহারকারীর চাহিদা নির্ধারণ করুন
স্ক্রিন ডিজাইন বা ফাইল পার্সার বেছে নেওয়ার আগে স্পষ্ট করুন কারা আপনার প্রোডাক্টে ডেটা আনছে/নিয়ে যাচ্ছে এবং কেন। ইন্টারনাল অপারেটরের জন্য বানানো একটি ডেটা ইমপোর্ট ওয়েব অ্যাপ গ্রাহকদের জন্য স্ব-সার্ভ Excel ইমপোর্ট টুল থেকে অনেক ভিন্ন দেখাবে।
ব্যবহারকারীরা কারা?
ইমপোর্ট/এক্সপোর্টে যে সব রোল টাচ করবে সেগুলো তালিকা করুন:
- অ্যাডমিন যারা ম্যাপিং, রুল এবং পারমিশন কনফিগার করে
- অপারেটর যারা নিয়মিত ইমপোর্ট চালায় ও এক্সসেপশন হ্যান্ডেল করে
- গ্রাহক যারা নিজ ফাইল (CSV/Excel) আপলোড করে এবং পরিষ্কার নির্দেশনা আশা করে
প্রতি রোলে প্রত্যাশিত দক্ষতা এবং জটিলতা সহ্য করার ক্ষমতা নির্ধারণ করুন। গ্রাহকদের সাধারণত কম অপশন ও অনেক ভালো ইন-প্রোডাক্ট ব্যাখ্যার দরকার হয়।
প্রধান ব্যবহারকেস (এবং ‘ডান’ মানে কি)
আপনার শীর্ষ সিনারিওগুলো লিখে অগ্রাধিকার দিন। সাধারণগুলো:
- অনবোর্ডিং-এর সময় ইনিশিয়াল বাল্ক লোড (উচ্চ ভলিউম, অগোছালো ডেটা)
- পিরিয়ডিক সিঙ্ক (সাপ্তাহিক/মাসিক আপডেট, কনসিস্টেন্সি গুরুত্বপূর্ণ)
- ওয়ান-অফ এক্সপোর্ট রিপোর্টিং, মাইগ্রেশন বা ব্যাকআপের জন্য
তারপর সফলতার মেট্রিক্স নির্ধারণ করুন যা মাপা যাবে: কম ফেইলড ইমপোর্ট, এরর রেজোলিউশনের দ্রুত সময়, এবং কম সাপোর্ট টিকেট—এগুলো পরে ট্রেডঅফ নিতে সাহায্য করবে (যেমন স্পষ্ট এরর রিপোর্টিং বনাম আরও ফাইল ফরম্যাট সাপোর্ট)।
ফরম্যাট, সীমা, এবং কমপ্লায়েন্স
প্রথম দিন কী সাপোর্ট করবেন সেটা স্পষ্ট করুন:
- ফাইল ফরম্যাট: CSV, Excel (XLSX), JSON
- সর্বোচ্চ ফাইল সাইজ ও রো লিমিট (ও কী হবে যখন সীমা অতিক্রম করে)
- এনকোডিং এক্সপেকটেশন (যেমন UTF-8) এবং ডেটের জন্য টাইমজোন নিয়ম
কমপ্লায়েন্স প্রয়োজন early-তে চিহ্নিত করুন: ফাইলগুলোতে কি PII আছে, রিটেনশন রুল, এবং অডিট চাহিদা (কে কি ইমপোর্ট করলো, কখন, কী পরিবর্তন হল)। এই সিদ্ধান্তগুলো স্টোরেজ, লগিং এবং পারমিশনকে প্রভাবিত করবে।
আর্কিটেকচার ও টেক স্ট্যাক বেছে নিন
ফ্যান্সি কলাম ম্যাপিং UI বা CSV ভ্যালিডেশন রুল বেছে নেওয়ার আগে এমন একটি আর্কিটেকচার বেছে নিন যা আপনার টিম দ্রুত ডেলিভার ও অপারেট করতে পারে। ইমপোর্ট/এক্সপোর্ট “বোরিং” ইনফ্রা—ইটারেশনের স্পিড ও ডিবাগযোগ্যতা নতুনত্বের চেয়েও বেশি গুরুত্বপূর্ণ।
আপনার টিম যেটা জানে সেটা থেকে শুরু করুন
যেকোনো মেইনস্ট্রীম ওয়েব স্ট্যাক একটি ডেটা ইমপোর্ট ওয়েব অ্যাপ চালাতে পারে। বিদ্যমান দক্ষতা ও হায়ারিং বাস্তবতার ভিত্তিতে বেছে নিন:
- React + Node (TypeScript) যদি আপনি একক-ভাষার ফুল-স্ট্যাক এবং ব্যাকগ্রাউন্ড জব ইকোসিস্টেম চান।
- Django যদি আপনি batteries-included অ্যাডমিন, পরিণত ORM এবং দ্রুত ডেলিভারি চান।
- Rails যদি আপনি কনভেনশন, দ্রুত CRUD, এবং ভালভাবে টেইল-ওয়র্ন ব্যাকগ্রাউন্ড জব প্যাটার্ন পছন্দ করেন।
কী গুরুত্বপূর্ণ: কনসিস্টেন্সি—স্ট্যাকটি নতুন ইমপোর্ট টাইপ, নতুন ভ্যালিডেশন রুল এবং নতুন এক্সপোর্ট ফরম্যাট যোগ করা সহজ করবে।
যদি আপনি দ্রুত স্ক্যাফোল্ড করতে চান, কাস্টম প্রোটোটাইপ এ আটকে না থেকে কিছুকে ব্যবহার করতে পারেন—উদাহরণস্বরূপ Koder.ai: আপনি চ্যাটে আপনার ইমপোর্ট ফ্লো (upload → preview → mapping → validation → background processing → history) বর্ণনা করে React UI এবং Go + PostgreSQL ব্যাকএন্ড জেনারেট করতে পারেন, এবং দ্রুত ইটারেট করতে planning mode ও স্ন্যাপশট/রোলব্যাক ব্যবহার করতে পারেন।
স্টোরেজ: “র’ ফাইল” আলাদা রাখুন “নরমালাইজড রেকর্ড” থেকে
স্ট্রাকচার্ড রেকর্ড, আপসার্ট এবং অডিট লগের জন্য একটি রিলেশনাল ডাটাবেস (Postgres/MySQL) ব্যবহার করুন।
অরিজিনাল আপলোড (CSV/Excel) অবজেক্ট স্টোরেজে (S3/GCS/Azure Blob) রাখুন। র’ ফাইল রাখা সাপোর্টের জন্য অমূল্য: আপনি পার্সিং ইস্যু পুনরুত্পাদন করতে পারবেন, জব পুনরায় চালাতে পারবেন, এবং এরর হ্যান্ডলিং সিদ্ধান্ত ব্যাখ্যা করতে পারবেন।
ইমপোর্ট কিভাবে রান করবে তা নির্ধারণ করুন
ছোট ফাইলগুলো সিঙ্ক্রোনাস (upload → validate → apply) চালানো যেতে পারে একটি স্মৃতি-ভিত্তিক UX এর জন্য। বড় ফাইলের ক্ষেত্রে কাজকে ব্যাকগ্রাউন্ড জব-এ নিয়ে যান:
- upload → enqueue job → show progress/history → notify on completion
এতে রিট্রাই ও রেট-লিমিটেড রাইটস সহজ হয়।
মাল্টি-টেন্যান্ট বনাম সিঙ্গেল-টেন্যান্ট
আপনি যদি SaaS তৈরি করছেন, আগে থেকেই ঠিক করুন কীভাবে টেন্যান্ট ডেটা আলাদা করবেন (রো-লেভেল স্কোপিং, আলাদা স্কিমা, বা আলাদা ডাটাবেস)। এই পছন্দ আপনার ডেটা এক্সপোর্ট API, পারমিশন, এবং পারফরম্যান্সকে প্রভাবিত করবে।
নন-ফাংশনাল রিকোয়ায়ারমেন্টস এখনই ডকুমেন্ট করুন
আপটাইম লক্ষ্যমাত্রা, ম্যাক্স ফাইল সাইজ, প্রত্যাশিত রো/ইমপোর্ট, সম্পন্ন হওয়ার সময়, এবং খরচ সীমা লিখে রাখুন। এই সংখ্যাগুলো জব কিউ নির্বাচন, ব্যাচিং স্ট্র্যাটেজি, এবং ইনডেক্সিং চালিত করবে—UI পলিশ করার অনেক আগে থেকেই।
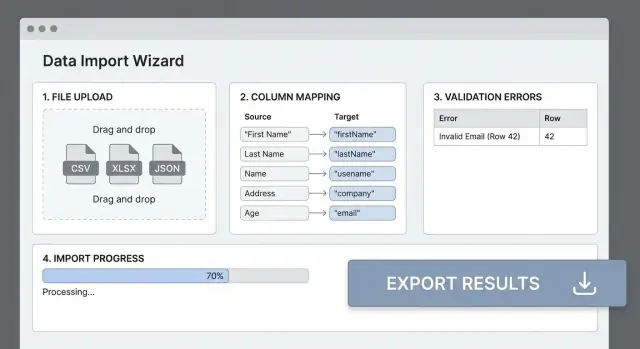
ইমপোর্ট ইন্টেক ফ্লো ডেভেলপ করুন
ইন্টেক ফ্লো প্রতিটি ইমপোর্টের টোন নির্ধারণ করে। যদি এটি ভবিষ্যদ্বাণীময় ও নমনীয় মনে হয়, ব্যবহারকারীরা কোনো সমস্যা হলে আবার চেষ্টা করবে—ফলে সাপোর্ট টিকেট কমবে।
এন্ট্রি পয়েন্ট: UI আপলোড এবং API
ওয়েব UI-এর জন্য একটি ড্র্যাগ-এন্ড-ড্রপ জোন এবং একটি ক্লাসিক ফাইল পিকার উভয় দিন। ড্র্যাগ-এন্ড-ড্রপ পাওয়ার ইউজারদের জন্য দ্রুত, আর ফাইল পিকার অ্যাক্সেসিবিলিটি ও পরিচিতির জন্য উপযুক্ত।
যদি আপনার গ্রাহকরা অন্য সিস্টেম থেকে ইমপোর্ট করে, একটি API এন্ডপয়েন্ট যোগ করুন। এটি multipart আপলোড (ফাইল + মেটাডাটা) গ্রহণ করতে পারে বা বড় ফাইলের জন্য প্রি-সাইনড URL ফ্লো ব্যবহার করতে পারে।
নিরাপদভাবে পার্স করুন: হেডার, এনকোডিং, স্যাম্পলিং
আপলোডে হালকা খুঁটে পার্সিং করুন যাতে একটি “প্রিভিউ” তৈরি হয় কিন্তু ডেটা কমিট না করা হয়:
- হেডার ডিটেক্ট করুন এবং রো স্যাম্পল দেখান (উদাহরণ: প্রথম 20–100)
- সাধারণ এনকোডিং (UTF‑8, UTF‑16) এবং ডিলিমিটার (কমা, ট্যাব, সেমিকোলন) হ্যান্ডেল করুন
- নতুনলাইন নরমালাইজ করুন এবং স্পষ্ট ফরম্যাটিং সমস্যাগুলো ট্রিম করুন
এই প্রিভিউ পরে কলাম ম্যাপিং ও ভ্যালিডেশনের জন্য ভিত্তি হবে।
র’ ফাইল রিপ্লে করার জন্য স্টোর করুন
অরিজিনাল ফাইলটি সুরক্ষিতভাবে (অবজেক্ট স্টোরেজে) সবসময় সংরক্ষণ করুন। এটিকে immutable রাখুন যাতে:
- আপনার ভ্যালিডেশন রুল বদলালে ইমপোর্ট পুনরায় চালানো যায়
- নির্দোষ পার্সিং বাগ পুনরুত্পাদন করা যায়
- ইমপোর্ট হিস্ট্রির “ডাউনলোড অরিজিনাল” অপশন প্রদান করা যায়
প্রথম দিন থেকেই মেটাডাটা ক্যাপচার করুন
প্রতিটি আপলোডকে একটি ফার্স্ট‑ক্লাস রেকর্ড হিসেবে বিবেচনা করুন। আপলোডার, টাইমস্ট্যাম্প, সোর্স সিস্টেম, ফাইল নাম, এবং চেকসাম (ডুপ্লিকেট সনাক্ত করার জন্য) মতো মেটাডাটা সংরক্ষণ করুন। এটি অডিটেবিলিটি ও ডিবাগিং‑এ অনস্বীকার্য হবে।
প্রি-চেক: ব্যবহারকারী সময় নষ্ট করার আগে পরীক্ষা করুন
দ্রুত প্রি‑চেক চালান এবং যত দ্রুত সম্ভব ব্যর্থ করুন:
- ফাইল টাইপ ও সাইজ লিমিট
- বেসিক রিডেবলিটি (পার্স করা যায়?)
- রিকোয়ার্ড কলাম উপস্থিত আছে কি (আপনার ইমপোর্ট টাইপ অনুযায়ী)
যদি প্রি‑চেক ফেল করে, একটি পরিষ্কার মেসেজ দিন এবং কী ঠিক করতে হবে তা দেখান। উদ্দেশ্য হলো সত্যিই খারাপ ফাইলগুলো দ্রুত ব্লক করা—কিন্তু সেই ডেটাকে ব্লক করা নয় যেটা পরে ম্যাপ বা ক্লিন করে নেওয়া যাবে।
কলাম ম্যাপিং ও ট্রান্সফরমেশন যোগ করুন
অধিকাংশ ইমপোর্ট ফেইলিং হয় কারণ ফাইলের হেডার আপনার অ্যাপের ফিল্ডের সাথে মিলে না। একটি পরিষ্কার কলাম ম্যাপিং স্টেপ “অগোছালো CSV”‑কে predictable ইনপুটে পরিণত করে এবং ব্যবহারকারীকে ট্রায়াল‑এন্ড‑এরর থেকে বাঁচায়।
মানুষ বুঝতে পারার মতো ম্যাপিং UI
একটি সহজ টেবিল দেখান: Source column → Destination field। সম্ভাব্য ম্যাচগুলো অটো-ডিটেক্ট করুন (কেস‑ইনসেন্সিটিভ হেডার ম্যাচিং, “E-mail” → email মত সিনোনিম) কিন্তু ব্যবহারকারীকে সবসময় ওভাররাইড করার সুযোগ দিন।
কিছু কিউট‑টু‑হেভ টাচ যোগ করুন:
- রিকোয়ার্ড ডেস্টিনেশন ফিল্ডগুলো চিহ্নিত করুন এবং ম্যাপেড কি না দেখান
- অনাবশ্যক কলামের জন্য “Ignore this column” দিন
- আনম্যাপড কলামগুলো হাইলাইট করুন যাতে ব্যবহারকারী কিছু না মিস করে
সংরক্ষিত ম্যাপিং টেমপ্লেট (প্রতি গ্রাহক বা ডেটাসেট)
যদি গ্রাহকরা সাপ্তাহিক একই ফরম্যাট ইমপোর্ট করে, এক‑ক্লিকে সেটা করা যায়। টেমপ্লেটগুলোকে স্কোপ করুন:
- একটি গ্রাহক/অ্যাকাউন্ট
- একটি ডেটাসেট/টাইপ (উদাহরণ: Contacts বনাম Invoices)
- ঐচ্ছিকভাবে, একটি নির্দিষ্ট ইন্টিগ্রেশন বা সোর্স সিস্টেম
নতুন ফাইল আপলোডে কলাম ওভারল্যাপের ভিত্তিতে টেমপ্লেট সাজেস্ট করুন। ভার্সনিং সাপোর্ট করুন যাতে ইউজাররা একটি টেমপ্লেট আপডেট করলেও পুরনো রানগুলো ভেঙে না যায়।
ট্রান্সফরমেশন: ডেটাকে আপনার স্কিমায় ফিট করান
ম্যাপড ফিল্ড প্রতি হালকা ট্রান্সফর্মস দিন:
- ওয়াইটস্পেস ট্রিম করা; খালি স্ট্রিং → null
- ডেট পার্সিং (MM/DD/YYYY বনাম DD.MM.YYYY) টাইমজোন অপশনসহ
- কারেন্সি নরমালাইজেশন (যেমন “$1,200.00” → 1200.00 + কারেন্সি)
- এনামস (যেমন “Active”, “enabled”, “1” → ACTIVE)
- ফিল্ড বিভক্ত/একত্র (Full Name → First/Last, বা উল্টো)
UI-তে ট্রান্সফর্মগুলো এক্সপ্লিসিট রাখুন (“Applied: Trim → Parse Date”) যাতে আউটপুট ব্যাখ্যাত্মক হয়।
কমিট করার আগে প্রিভিউ দেখান
পুরা ফাইল প্রসেস করার আগে (ধরা যাক) 20 রো‑র একটি ম্যাপড প্রিভিউ দেখান। অরিজিনাল ভ্যালু, ট্রান্সফর্মড ভ্যালু, এবং সতর্কিকাগুলো দেখান (যেমন “Could not parse date”)—এখানেই ব্যবহারকারী সমস্যা ধরে ফেলবে।
ডুপ্লিকেট ও কী ফিল্ড ডিটেক্ট করুন
ব্যবহারকারীদেরকে একটি কি ফিল্ড (email, external_id, SKU) বেছে নিতে বলুন এবং ব্যাখ্যা করুন ডুপ্লিকেট হলে কী হবে। যদিও পরে আপসার্ট হ্যান্ডেল করতে পারেন, কিন্তু এই স্টেপ প্রত্যাশা সেট করে: ফাইলের মধ্যে ডুপ্লিকেট কী‑এর ক্ষেত্রে কোন রেকর্ড “জিতে” যাবে (first, last, অথবা error) সে সম্পর্কে সতর্ক করুন।
ভ্যালিডেশন সিস্টেম ডিজাইন করুন
ভ্যালিডেশনই আলাদা করে দেয় একটি “ফাইল আপলোডার” ও একটি বিশ্বাসযোগ্য ইমপোর্ট ফিচারের মধ্যে পার্থক্য। লক্ষ্যটি কঠোর হওয়া নয়—এটি হল খারাপ ডেটা ছড়িয়ে পড়া রোধ করা এবং ব্যবহারকারীকে স্পষ্ট, অ্যাকশনযোগ্য ফিডব্যাক দেয়া।
ভ্যালিডেশনকে স্তরে ভাগ করুন
ভ্যালিডেশনকে তিনটি ভিন্ন চেক হিসেবে বিবেচনা করুন, প্রতিটির আলাদা উদ্দেশ্য আছে:
- স্কিমা ভ্যালিডেশন (টাইপ ও রিকোয়্যার্ড ফিল্ড): “email কি স্ট্রিং?”, “amount কি নম্বর?”, “customer_id আছে কি?” এটি দ্রুত চলে এবং পার্সিংয়ের পরে সঙ্গে সঙ্গে চালানো যায়।
- বিজনেস রুলস: “Amount পজিটিভ হতে হবে”, “Status হওয়া উচিত Active/Paused-এর মধ্যে”, “Start date অতীতে হতে পারবে না।” এগুলো আপনার প্রোডাক্ট কিভাবে কাজ করে তা প্রতিফলিত করে।
- ক্রস‑ফিল্ড ও রিলেশনাল রুলস: “যদি country=US হয়, তবে state অবশ্যক”, “end_date অবশ্যই start_date পরে হতে হবে”, “Plan name ওই ওয়ার্কস্পেসে এক্সিস্ট করে কিনা।” এগুলো প্রায়শই কনটেক্সট চায় (অন্যান্য কলাম বা DB লুকআপ)।
এই লেয়ারগুলো আলাদা রাখলে সিস্টেম বিস্তৃত করা সহজ হয় এবং UI-তেও ব্যাখ্যা সহজ হয়।
স্ট্রিক্ট বনাম লেনিয়েন্ট মোড (এবং কেন তা গুরুত্বপূর্ণ)
শুরুতেই নির্ধারণ করুন একটি ইমপোর্ট:
- পুরো ফাইল ফেল করবে (স্ট্রিক্ট): অর্থনীতিক ডেটা, পারমিশন, বা এমন কিছু যেখানে পার্শিয়াল আপডেট রিস্ক তৈরি করে—এর জন্য ভাল।
- **ভ্যালিড রো গুলো আ্� \nNOTE: preserving content here