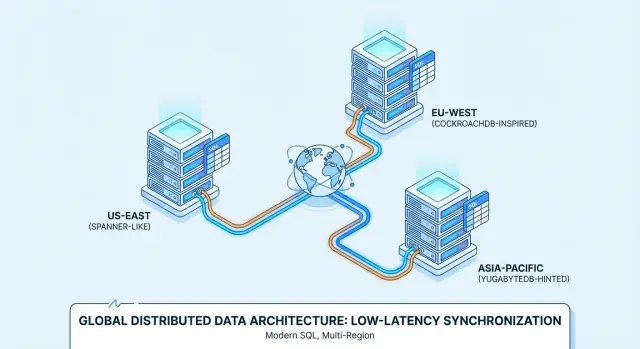
“ডিস্ট্রিবিউটেড SQL” বলতে কী বোঝায় (হাইপ ছাড়া)
“ডিস্ট্রিবিউটেড SQL” এমন একটি ডাটাবেস যা ঐতিহ্যবাহী রিলেশনাল ডাটাবেসের মতোই লাগে—টেবিল, সারি, JOIN, ট্রানজ্যাকশন, এবং SQL—কিন্তু এটিকে ক্লাস্টার হিসেবে অনেক মেশিনে (প্রায়ই বিভিন্ন রিজিয়নে) চালানোর জন্য ডিজাইন করা হয়, তারপরও এটি একটি লজিক্যাল ডাটাবেস হিসেবেই আচরণ করে।
এই সংমিশ্রণটি গুরুত্বপূর্ণ কারণ এটি একসঙ্গে তিনটি জিনিস দেওয়ার চেষ্টা করে:
- SQL ও রিলেশনাল মডেলিং: পরিচিত স্কিমা, কনস্ট্রেইন্ট, এবং কুয়েরি টুলিং।
- স্কেল-আউট: বড় সার্ভার কেনার বদলে নোড যোগ করে ক্ষমতা বাড়ান।
- শক্ত কনসিস্টেন্সি: ডেটা ছড়িয়ে থাকা সত্ত্বেও রিড ও রাইট স্পষ্ট ট্রানজ্যাকশোনাল নিয়ম মেনে চলে।
ক্লাসিক RDBMS ও NoSQL এর মধ্যে
একটি ক্লাসিক RDBMS (যেমন PostgreSQL বা MySQL) সাধারণত সবচেয়ে সহজে চালানো যায় যখন সবকিছু একটি প্রাইমারি নোডে থাকে। আপনি রিড স্কেল করতে রিপ্লিকা ব্যবহার করতে পারেন, কিন্তু লিখন স্কেল করা এবং রিজিয়ন-আউটেজ টিকে থাকা সাধারণত অতিরিক্ত আর্কিটেকচার (শার্ডিং, ম্যানুয়াল ফেলওভার, এবং সাবধানে অ্যাপ্লিকেশন লজিক) দাবি করে।
অনেক NoSQL সিস্টেম উল্টা পথ নিয়েছে: প্রথমে স্কেল ও হাই-অ্যাভেইলেবিলিটি; কখনো কখনো কনসিস্টেন্সি শিথিল করে বা সহজ কুয়েরি মডেল দেয়।
ডিস্ট্রিবিউটেড SQL মধ্যম পথ রাখে: রিলেশনাল মডেল ও ACID ট্রানজ্যাকশন বজায় রাখে, কিন্তু ডেটা স্বয়ংক্রিয়ভাবে বিতরণ করে বৃদ্ধির ও ব্যর্থতার মোকাবিলা করে।
এটি কী সমস্যা সমাধান করতে চায়
ডিস্ট্রিবিউটেড SQL ডাটাবেসগুলো এমন সমস্যার জন্য তৈরি:
- গ্লোবাল অ্যাপ্লিকেশন যেখানে ব্যবহারকারীরা একাধিক রিজিয়নে আছে, এবং লেটেন্সি ও আপটাইম—দুটোই গুরুত্বপূর্ণ।
- উচ্চ প্রাপ্যতা জটিল, ম্যানুয়াল ফেলওভার ছাড়া।
- সময়ের সঙ্গে বৃদ্ধি—আপনি চাইলে ক্ষমতা ধাপে ধাপে বাড়াতে এবং একটি একক ডাটাবেস ইন্টারফেস রাখতে।
এই কারণেই Google Spanner, CockroachDB, और YugabyteDB প্রায়ই মাল্টি-রিজিয়ন ডিপ্লয়মেন্ট ও অলওয়েজ-অন সার্ভিসের জন্য বিবেচিত হয়।
প্রত্যাশা নির্ধারণ করুন (এটি ডিফল্ট নয়)
ডিস্ট্রিবিউটেড SQL নিজে থেকেই “বেশি ভাল” নয়। আপনি বেশি চলমান অংশ ও ভিন্ন পারফরম্যান্স বাস্তবতাগুলি (নেটওয়ার্ক হপ, কনসেনসাস, ক্রস-রিজিয়ন লেটেন্সি) গ্রহণ করছেন প্রতিস্থাপনের জন্য রেসিলিয়েন্স ও স্কেল।
যদি আপনার ওয়ার্কলোড একটি ভালোভাবে ম্যানেজ হওয়া একক ডাটাবেসে ফিট করে এবং সাধারণ রিপ্লিকেশন সেটআপ থাকে, একটি প্রচলিত RDBMS সহজতর ও সস্তা হতে পারে। ডিস্ট্রিবিউটেড SQL তখন মূল্য অর্জন করে যখন বিকল্পটি কাস্টম শার্ডিং, জটিল ফেলওভার, বা এমন ব্যবসায়িক প্রয়োজন যেখানে মাল্টি-রিজিয়ন কনসিস্টেন্সি ও আপটাইম আবশ্যক।
ডিস্ট্রিবিউটেড SQL নিচ থেকে উপরে কিভাবে কাজ করে
ডিস্ট্রিবিউটেড SQL পরিচিত SQL ডাটাবেসের মতো অনুভব করাতে চায়, তবুও ডেটা অনেক মেশিনে (এবং প্রায়ই বহু রিজিয়নে) সংরক্ষণ করে। কঠিন অংশ হলো অনেক কম্পিউটারকে সমন্বয় করে এমনভাবে চালানো যাতে তারা এক নির্ভরযোগ্য সিস্টেমের মতো আচরণ করে।
রিপ্লিকেশন + কনসেনসাস: কীভাবে নোডগুলো একমত হয়
প্রতিটি ডেটার অংশ সাধারণত কয়েকটি নোডে কপি করা হয় (রিপ্লিকেশন)। যদি একটি নোড ব্যর্থ হয়, অন্য কপি রিড সার্ভ করতে ও রাইট গ্রহণ করতে পারে।
রেপ্লিকাগুলো বিচ্ছিন্ন না হয়ে থাকতে কনসেনসাস প্রটোকল ব্যবহার করা হয়—সাধারণত Raft (CockroachDB, YugabyteDB) বা Paxos (Spanner)। উচ্চ-স্তরে কনসেনসাস মানে:
- একটি রেপ্লিকা গ্রুপের জন্য একটি “লিডার” থাকে।
- রাইটগুলো লিডারকে যায়।
- লিডার শুধুমাত্র তখনই রাইট নিশ্চিত করে যখন রেপ্লিকার মেজরিটি স্বীকৃতি দেয়।
এই “মেজরিটি ভোট” আপনাকে দেয় শক্ত কনসিস্টেন্সি: একবার ট্রানজ্যাকশন কমিট হলে অন্যান্য ক্লায়েন্ট পুরোনো ডেটা দেখবে না।
শার্ডিং/পার্টিশনিং: ডেটা কোথায় থাকে
কোন একক মেশিন সবকিছু ধারণ করতে পারে না, তাই টেবিলগুলো ছোট টুকরোতে বিভক্ত করা হয়—এগুলোকে বলা হয় শার্ড/পার্টিশন (Spanner এ এগুলোকে splits বলে; CockroachDB এ ranges; YugabyteDB এ tablets)।
প্রতিটি পার্টিশন কনসেনসাস ব্যবহার করে রিপ্লিকেটেড এবং নির্দিষ্ট নোডে স্থাপন করা হয়। প্লেসমেন্ট এলোমেলো নয়: আপনি নীতির মাধ্যমে প্রভাব ফেলতে পারেন (উদাহরণ: EU গ্রাহকের রেকর্ড EU রিজিয়েনেই রাখুন, অথবা হট পার্টিশন দ্রুত নোডে রাখুন)। ভালো প্লেসমেন্ট ক্রস-নেটওয়ার্ক ট্রিপ কমায় এবং পারফরম্যান্স আরও পূর্বানুমানযোগ্য রাখে।
নোড জুড়ে ট্রানজ্যাকশন (এবং কেন এটি লেটেন্সি বাড়ায়)
একক-নোড ডাটাবেসে একটি ট্রানজ্যাকশন প্রায়শই লোকাল ডিস্ক কাজ করেই কমিট হয়ে যায়। ডিস্ট্রিবিউটেড SQL-এ একটি ট্রানজ্যাকশন বহু পার্টিশন স্পর্শ করতে পারে—সম্ভবত ভিন্ন নোডে।
নিরাপদভাবে কমিট করতে সাধারণত দরকার:
- সম্পৃক্ত পার্টিশনগুলিতে লকিং বা ভ্যালিডেশন
- কনসেনসাসের মাধ্যমে রাইট রিপ্লিকেট করা (মেজরিটি স্বীকৃতি)
- সমস্ত অংশগ্রহণকারী একমত হয়ে কমিট সিদ্ধান্ত চূড়ান্ত করা
এই ধাপগুলো নেটওয়ার্ক রাউন্ড ট্রিপ যোগ করে—যার ফলে ডিস্ট্রিবিউটেড ট্রানজ্যাকশন সাধারণত লেটেন্সি বাড়ায়, বিশেষত যখন ডেটা রিজিয়ন জুড়ে বিস্তৃত।
মাল্টি-রিজিয়ন আচরণ: লোক্যালিটি-অ্যাওয়ার রিড ও রাইট
ডিপ্লয়মেন্টগুলো রিজিয়ন জুড়ে বিস্তৃত হলে, সিস্টেমগুলো চেষ্টা করে অপারেশনগুলো ব্যবহারকারীর কাছাকাছি রাখতে:
- লোক্যালিটি-অ্যাওয়ার রিড প্রায়ই নিকটস্থ রিপ্লিকা থেকে সার্ভ করে যখন নিরাপদ।
- লোক্যালিটি-অ্যাওয়ার রাইট লিডারকে এমন রিজিয়নে রুট করতে পারে যেখানে প্রধান লেখক আছে, বা লিডারকে প্রধান লেখকদের কাছে রাখতে পারে।
এটাই মূল মাল্টি-রিজিয়ন ব্যালান্সিং: আপনি লোকাল রেস্পনসিভনেস অপটিমাইজ করতে পারেন, কিন্তু দীর্ঘ দূরত্ব জুড়ে শক্ত কনসিস্টেন্সি রাখলে নেটওয়ার্ক খরচ এখনও থাকবে।
কখন সত্যিই দরকার (এবং কখন নয়)
ডিস্ট্রিবিউটেড SQL-এ যাওয়ার আগে আপনার প্রাথমিক চাহিদা যাচাই করুন। যদি আপনার আছে একটি একক প্রাইমারি রিজিয়ন, পূর্বানুমানযোগ্য লোড, এবং ছোট অপস ফুটপ্রিন্ট—তাহলে প্রচলিত রিলেশনাল ডাটাবেস (বা managed Postgres/MySQL) সাধারণত দ্রুত ফিচার চালানোর সহজতম উপায়। আপনি প্রায়ই একটি একক-রিজিয়ন সেটআপ অনেক দূর পর্যন্ত সম্প্রসারণ করতে পারেন রিড রিপ্লিকা, ক্যাশিং, এবং সাবধানে স্কিমা/ইন্ডেক্স কাজ করে।
স্পষ্ট ট্রিগার: কখন ডিস্ট্রিবিউটেড SQL মূল্য দেয়
ডিস্ট্রিবিউটেড SQL যথেষ্ট বিবেচনার বিষয় যখন নিম্নের মধ্যে একটি (বা বেশি) সত্য হয়:
- আপনার বাস্তব ব্যবহারকারীরা একাধিক রিজিয়নে এবং আপনি চান ডাটাবেস তাদের কাছে কাছাকাছি থাকুক, অ্যাপ-লেভেল শার্ডিং না করে।
- আপনার আপটাইম চাহিদা উচ্চ (উদাহরণ: জোন/রিজিয়ন ব্যর্থতা টিকিয়ে রাখতে হবে) এবং একটি একক প্রাইমারি রিজিয়ন গ্রহণযোগ্য ঝুঁকি নয়।
- ডেটা ভলিউম বা রাইট থ্রুপুট উল্লঙ্ঘন করছে ভের্টিক্যাল স্কেলিং, এবং আপনি SQL সেমান্টিক্স রেখে অনুভূমিক স্কেল চান।
- আপনি নোড/রিজিয়ন জুড়ে শক্ত কনসিস্টেন্সি চান মূল ট্রানজ্যাকশনের জন্য (অর্ডার, ব্যাল্যান্স, রিজার্ভেশন) একাধিক সিস্টেম জোড়া না করে।
- কমপ্লায়েন্স জোর দেয় ভৌগোলিক প্লেসমেন্ট (ডেটা রেসিডেন্সি) এবং আপনি একটি লজিক্যাল ডাটাবেস চান।
অ্যান্টি-ট্রিগার: কখন সাধারণত এটি সঠিক নয়
ডিস্ট্রিবিউটেড সিস্টেম জটিলতা ও খরচ বাড়ায়। সাবধান থাকুন যদি:
- আপনার টিম ছোট এবং নতুন ব্যর্থতার মোড ও অপারেশনাল প্যাটার্ন শিখতে সময় নেই।
- ট্রাফিক কম বা অনিয়মিত এবং আপনি শীঘ্রই একক-রিজিয়ন ডাটাবেস ছাড়িয়ে যাবেন না।
- আপনার ল্যাটেন্সি বাজেট খুব কড়া এবং একক-কী রাইটের জন্য কর্ডিনেশন ওভারহেড সহ্য করা যাবে না।
- আপনার ওয়ার্কলোড এনালিটিক্স-ভারী (বড় স্ক্যান, জটিল রিপোর্ট)। OLTP আলাদা করে রাখা ভাল।
দ্রুত সিদ্ধান্ত চেকলিস্ট
আপনি যদি দুই বা আরো প্রশ্নের উত্তর “হ্যাঁ” দিতে পারেন, ডিস্ট্রিবিউটেড SQL মূল্যায়নের যোগ্য:
- আপনার কি মাল্টি-রিজিয়ন ব্যবহারকারী দরকার, সাথে কনসিস্টেন্ট ডেটা?
- আপনার কি অটোমেটিক ফেলওভার দরকার জোন/রিজিয়ন জুড়ে?
- স্কেলিং ক্রমাগত একটা সমস্যা কি?
- শার্ডিং কি ডাটাবেসের চেয়ে বেশি ইঞ্জিনিয়ারিং ওভারহেড যোগ করবে?
- আপনাকে কি ডেটা রেসিডেন্সি এক অপারেশনাল মডেলে বজায় রাখতে হবে?
কনসিস্টেন্সি, অ্যাভেইলেবিলিটি এবং লেটেন্সি: মূল ট্রেডঅফ
ডিস্ট্রিবিউটেড SQL শুনতে দেয় “সবই একসাথে পাওয়া যাবে,” কিন্তু বাস্তব সিস্টেমগুলো সিদ্ধান্ত নিতে বাধ্য করে—বিশেষত যখন রিজিয়নগুলো একে অপরের সাথে নির্ভরশীল নয়।
CAP, প্রোডাক্ট সিদ্ধান্তের জন্য ব্যাখ্যা
একটি নেটওয়ার্ক পার্টিশন ভাবুন যেন “রিজিয়নের মধ্যে লিংক ঝাপসা বা ডাউন।” সেই মুহূর্তে ডাটাবেস প্রাধান্য দিতে পারে:
- Consistency: সবাই একই, আপ-টু-ডেট উত্তর দেখে (অথবা অপারেশন ব্যর্থ হয়)।
- Availability: অ্যাপ প্রতিটি রিজিয়নে রিড/রাইট নিতে থাকুক (যা কিছু সময় সত্যি সত্যি বিচ্ছিন্ন উত্তরও হতে পারে)।
ডিস্ট্রিবিউটেড SQL সিস্টেম সাধারণত ট্রানজ্যাকশনের জন্য কনসিস্টেন্সি-কে প্রাধান্য দেয়। দলগুলো সাধারণত এটাই চায়—তখনই না, যখন পার্টিশন মানে কিছু অপারেশন অপেক্ষা বা ব্যর্থ হবে।
শক্ত কনসিস্টেন্সি (কেন পয়সা ও ইনভেন্টরি-তে গুরুত্বপূর্ণ)
শক্ত কনসিস্টেন্সি মানে একবার ট্রানজ্যাকশন কমিট হলে পরে কোনো রিড সেই কমিট হওয়া ভ্যালু দেখাবে—কোনো “এক রিজিয়নে কাজ হয়েছে কিন্তু অন্যে নেই” থাকবে না। এটি গুরুত্বপূর্ণ:
- পেমেন্ট ও ব্যাল্যান্স (ডবল-স্পেন্ড বা ভুল মোট এড়ানো)
- ইনভেন্টরি / রিজার্ভেশন (ওভারসেল প্রতিরোধ)
যদি আপনার প্রোডাক্ট প্রমিজ হয় “যখন আমরা নিশ্চিত বলি, সেটা বাস্তব,” শক্ত কনসিস্টেন্সি ফিচার, বিলকুল বিলাসিতা নয়।
রিড-ইউর-রাইটস ও আইসোলেশন বাস্তব অ্যাপে
দুই ব্যবহারিক আচরণ গুরুত্বপূর্ণ:
- রিড-ইউর-রাইটস: একজন ব্যবহারকারী তাদের প্রোফাইল আপডেট করার পরে পরবর্তী স্ক্রিনে নতুন অবস্থা দেখতে হবে, পুরোনো রিপ্লিকা নয়।
- ট্রানজ্যাকশন আইসোলেশন: কনকারেন্ট অ্যাকশনগুলো কিভাবে ইন্টারঅ্যাক্ট করে নির্ধারণ করে। শক্ত আইসোলেশন থাকলে সূক্ষ্ম বাগ (যেমন দুই কাস্টমার একই সিট সফলভাবে বুক করা) এড়ায়।
ক্রস-রিজিয়ন কনসেনসাসের লেটেন্সি খরচ
রিজিয়ন জুড়ে শক্ত কনসিস্টেন্সি সাধারণত কনসেনসাস দাবি করে (কমিটের আগে বহু রেপ্লিকার একমত হতে হবে)। যদি রেপ্লিকাগুলো মহাদেশগুলোর ওপর ছড়িয়ে থাকে, আলো-গতির সীমা একটি পণ্যগত সীমা হয়ে দাঁড়ায়: প্রতিটি ক্রস-রিজিয়ন রাইট দশক থেকে শত মিলিসেকেন্ড যোগ করতে পারে।
ট্রেড-অফ সহজ: আরোহী ভৌগোলিক নিরাপত্তা ও সঠিকতা সাধারণত উচ্চতর রাইট লেটেন্সি মানে যদি না আপনি সাবধানে ডেটা কোথায় থাকে ও ট্রানজ্যাকশন কোথায় কমিট হবে তা নির্ধারণ করেন।
Spanner বনাম CockroachDB বনাম YugabyteDB: একটি ব্যবহারিক ওভারভিউ
Google Spanner হলো একটি ডিস্ট্রিবিউটেড SQL ডাটাবেস যা প্রধানত Google Cloud-এ managed সার্ভিস হিসেবে দেওয়া হয়। এটি মাল্টি-রিজিয়ন ডিপ্লয়মেন্টের জন্য ডিজাইন করা, যেখানে আপনি এক লজিক্যাল ডাটাবেস চান এবং ডেটা নোড ও রিজিয়নে রিপ্লিকেট করা হয়। Spanner দুই ধরনের SQL ডায়ালেক্ট সমর্থন করে—GoogleSQL (এটির নিজস্ব ডায়ালেক্ট) এবং PostgreSQL-কম্প্যাটিবল ডায়ালেক্ট—তাই পোর্টেবিলিটি আপনি কোনটি বেছে নেন ও আপনার অ্যাপ কোন ফিচারগুলোর উপর নির্ভর করে তার ওপর নির্ভর করে।
CockroachDB হলো একটি ডিস্ট্রিবিউটেড SQL ডাটাবেস যা PostgreSQL-ব্যবহারকারীদের জন্য পরিচিত অনুভব দেওয়ার চেষ্টা করে। এটি PostgreSQL ওয়্যার প্রটোকল ব্যবহার করে এবং PostgreSQL-শৈলীর SQL-এর বড় একটি সাবসেট সমর্থন করে, কিন্তু এটি Postgres-এর পুরোপুরি প্রতিস্থাপন নয় (কিছু এক্সটেনশন ও এজ-কেস আচরণ আলাদা)। আপনি এটিকে managed সার্ভিস (CockroachDB Cloud) হিসেবে চালাতে পারেন অথবা নিজে হোস্ট করতে পারেন।
YugabyteDB হলো একটি ডিস্ট্রিবিউটেড ডাটাবেস যার PostgreSQL-কম্প্যাটিবল SQL API (YSQL) এবং অতিরিক্ত Cassandra-কম্প্যাটিবল API (YCQL) আছে। CockroachDB-এর মতোই, এটি প্রায়ই এমন দল দ্বারা মূল্যায়িত হয় যারা Postgres-অনুরূপ ডেভেলপমেন্ট আরাম চান অথচ নোড ও রিজিয়নে স্কেল করতে চান। এটি self-hosted এবং managed (YugabyteDB Managed) উভয়ই উপলব্ধ, এবং সাধারণ ডিপ্লয়মেন্টে single-region HA থেকে multi-region পর্যন্ত দেখা যায়।
Managed বনাম self-hosted: কী পরিবর্তন হয়
Managed সার্ভিস সাধারণত অপারেশনাল কাজ হ্রাস করে (আপগ্রেড, ব্যাকআপ, মনিটরিং ইন্টিগ্রেশন), আর self-hosting আপনাকে নেটওয়ার্কিং, ইনস্ট্যান্স টাইপ, এবং ডেটা কোথায় চলে তার নিয়ে বেশি নিয়ন্ত্রণ দেয়। Spanner সাধারণত GCP-এ managed হিসেবে খাওয়ানো হয়; CockroachDB ও YugabyteDB উভয়ই managed ও self-hosted মডেলে দেখা যায়, সহ মাল্টি-ক্লাউড ও অন-প্রিম অপশন।
বাস্তবে SQL কম্প্যাটিবিলিটি
তিনোটিই “SQL” বলে, কিন্তু দৈনন্দিন কম্প্যাটিবিলিটি নির্ভর করে ডায়ালেক্ট পছন্দ (Spanner), Postgres ফিচার কভারেজ (CockroachDB/YugabyteDB), এবং আপনার অ্যাপ নির্ভর করে কি-কি Postgres এক্সটেনশন, ফাংশন বা ট্রানজ্যাকশন সেমান্টিক্সে।
পরিকল্পনা করার সময় পরীক্ষা করাটাই বুদ্ধিমানের কাজ: আপনার কুয়েরি, মাইগ্রেশন, এবং ORM আচরণ শুরু থেকেই টেস্ট করুন—drop-in সমতুল্য ধরে নেওয়া ঠিক নয়।
ব্যবহার-কেস: রিজিয়নাল ব্যবহারকারীদের সঙ্গে গ্লোবাল SaaS
আপনার স্ট্যাকের নিয়ন্ত্রণ রাখুন
সোর্স কোডের মালিকানায় থাকুন যাতে প্রোটোটাইপ প্রস্তুত হলে আপনি আপনার রেপোতে কাজ চালিয়ে যেতে পারেন।
ডিস্ট্রিবিউটেড SQL-এর একটি সাধারণ ফিট হল একটি B2B SaaS পণ্য যার গ্রাহকরা উত্তর আমেরিকা, ইউরোপ, এবং APAC-এ ছড়িয়ে—ধরুন সাপোর্ট টুল, HR প্ল্যাটফর্ম, অ্যানালিটিক্স ড্যাশবোর্ড, বা মার্কেটপ্লেস।
ব্যবসায়িক প্রয়োজন সরল: ব্যবহারকারীরা চান “লোকাল অ্যাপ” রেসপনসিভনেস, কোম্পানি চায় এক লজিক্যাল ডাটাবেস যা সবসময় উপলব্ধ।
ডেটা রেসিডেন্সি ও প্রতি-টেন্যান্ট প্লেসমেন্ট
অনেক SaaS দল মিশ্র চাহিদার সম্মুখীন হয়:
- EU গ্রাহকরা আশা করে তাদের ডেটা EU-র ভিতর থাকবে (GDPR, চুক্তিগত বাধ্যবাধকতা)।
- কিছু গ্রাহক দেশ-ভিত্তিক স্টোরেজ চায় (উদাহরণ: জার্মানি, অস্ট্রেলিয়া, সিঙ্গাপুর)।
- বাকিরা পাত্তা দেয় না, তবে কম লেটেন্সি চান।
ডিস্ট্রিবিউটেড SQL এটি পরিষ্কারভাবে মডেল করতে পারে প্রতি-টেন্যান্ট লোকালিটি দিয়ে: প্রতিটি টেন্যান্টের প্রধান ডেটা একটি নির্দিষ্ট রিজিয়ন (অথবা রিজিয়নের সেট) এ রাখুন, সঙ্গে থাকা সার্কিট কিন্তু পুরো সিস্টেমে একই স্কিমা ও কুয়েরি মডেল রাখে। এতে আপনি “এক রিজিয়নের প্রতি ডাটাবেস” বিস্তার এড়াতে পারেন এবং রেসিডেন্সি প্রয়োজন মেটাতে পারেন।
লেটেন্সি হ্রাস: রিজিয়নাল রিড ও রাইট প্লেসমেন্ট
অ্যাপ দ্রুত রাখতে সাধারণত লক্ষ্য হয়:
- রিজিয়নাল রিড: রিড-হেভি কুয়েরি নিকটস্থ রিপ্লিকা থেকে সার্ভ করুন।
- রাইট প্লেসমেন্ট: লেখার লিডার (বা প্রাইমারি রিপ্লিকা সেট) সেই রিজিয়নে রাখুন যেখান থেকে টেন্যান্টের লেখাগুলো বেশিরভাগ আসে।
এটি গুরুত্বপূর্ণ কারণ ক্রস-রিজিয়ন রাউন্ড ট্রিপ ব্যবহারকারীর অনুভূত লেটেন্সি নির্ধারণ করে। শক্ত কনসিস্টেন্সি থাকলেও ভালো লোক্যালিটি ডিজাইন নিশ্চিত করে যে অধিকাংশ অনুরোধ আন্তঃমহাদেশীয় নেটওয়ার্ক খরচ নেয় না।
অপারেশনাল বাস্তবতা
টেকনিক্যাল জিত তখনই মুল্য রাখে যখন অপারেশন বজায় রাখা যায়। গ্লোবাল SaaS-এর জন্য পরিকল্পনা করুন:
- অনলাইন স্কিমা চেঞ্জ যা রিজিয়ন জুড়ে টেবিল লক করে না।
- টেন্যান্ট মাইগ্রেশন (এক রিজিয়ন থেকে অন্য রিজিয়নে টেন্যান্ট সরানো কম ডাউনটাইমে)।
- মনিটরিং ও অ্যালার্টিং replication lag, hotspots, ধীর কুয়েরি, এবং রিজিয়ন-লেভেল ইনসিডেন্টের জন্য।
ভালো করলে, ডিস্ট্রিবিউটেড SQL আপনাকে একটি একক প্রোডাক্ট অভিজ্ঞতা দেয় যা তবুও লোকাল মনে হয়—আপনার ইঞ্জিনিয়ারিং টিমকে “EU স্ট্যাক” ও “APAC স্ট্যাক” এ ভাগ না করে।
ব্যবহার-কেস: ফাইন্যান্সিয়াল ওয়ার্কফ্লো এবং লেজার
ফাইন্যান্সিয়াল সিস্টেমগুলোতে “পরোক্ষ কনসিস্টেন্সি” আসলে বাস্তব অর্থের ক্ষতি ঘটাতে পারে। যদি একটি গ্রাহক অর্ডার দেয়, পেমেন্ট অথরাইজ হয়, এবং ব্যাল্যান্স আপডেট হয়—এই ধাপগুলো বর্তমান একক সত্যে মিলতে হবে।
শক্ত কনসিস্টেন্সি গুরুত্বপূর্ণ কারণ এটি বিভিন্ন রিজিয়ন (বা বিভিন্ন সার্ভিস) দ্বারা আলাদা “যুক্তিসঙ্গত” সিদ্ধান্ত নেওয়ার ফলে ভুল লেজার হওয়া প্রতিরোধ করে।
কেন শক্ত কনসিস্টেন্সি দরকার নিঃস্বার্থ
সাধারণ ওয়ার্কফ্লো—create order → reserve funds → capture payment → update balance/ledger—তালিকা দায়িত্বশীল গ্যারান্টি চান যেমন:
- যদি payment capture না ঘটে, তাহলে কোনো অর্ডার “paid” মার্ক করা যাবে না।
- একই সময়ে দুইটি ট্রানজ্যাকশন হলে ব্যাল্যান্স নেগেটিভ হওয়া উচিত নয়।
- একই জব দুইবার রি-ট্রাই করলে refund দুইবার প্রয়োগ হবে না।
ডিস্ট্রিবিউটেড SQL এখানে ফিট করে কারণ এটি নোড জুড়ে (এবং প্রায়শই রিজিয়ন জুড়ে) ACID ট্রানজ্যাকশন ও কনস্ট্রেইন্ট দেয়, ফলে লেজার ইনভারিয়ান্টগুলো ব্যর্থতাতেও বজায় থাকে।
idempotency ও “ডবল চার্জ না হওয়া” প্যাটার্ন
অধিকাংশ পেমেন্ট ইন্টিগ্রেশন রি-ট্রাই-ভিত্তিক: টাইমআউট, webhook রি-ট্রাই, এবং জব রি-প্রসেসিং সাধারণ। ডাটাবেসকে আপনাকে রি-ট্রাই নিরাপদ করার জন্য সাহায্য করতে হবে।
প্র্যাকটিক্যাল পদ্ধতি হলো অ্যাপ-লেভেল idempotency কিজকে ডাটাবেস-এ ইউনিক কনস্ট্রেইন্টের সঙ্গে জোড়া:
- প্রতিটি কাস্টমার/পেমেন্ট চেষ্টার জন্য একটি
idempotency_key স্টোর করুন।
(account_id, idempotency_key) মত একটি ইউনিক কনস্ট্রেইন্ট যোগ করুন।- “create payment record + apply ledger entries” এক ট্রানজ্যাকশনে র্যাপ করুন।
এইভাবে দ্বিতীয় চেষ্টাটি নির্দোষ নল-অপ হবে, ডবল চার্জ নয়।
স্পাইক সামলানো একই সঙ্গে সঠিকতা বজায় রেখে
সেল ইভেন্ট ও পেইরোল রান হঠাৎ করে বড় রাইট স্পাইক তৈরি করতে পারে (অথরাইজেশন, ক্যাপচার, ট্রান্সফার)। ডিস্ট্রিবিউটেড SQL-এ আপনি নোড যোগ করে রাইট থ্রুপুট বাড়াতে পারেন একই কনসিস্টেন্সি মডেল রেখে।
কীটি হলো হট কী-এর পরিকল্পনা (যেমন একটি মার্চেন্ট অ্যাকাউন্টে সব ট্র্যাফিক) এবং লোড ছড়ানোর জন্য স্কিমা প্যাটার্ন ব্যবহার।
কমপ্লায়েন্স, অডিট, ও রিটেনশন
ফাইন্যান্সিয়াল ওয়ার্কফ্লো সাধারণত অপরিবর্তনীয় অডিট ট্রেইল, ট্রেসেবিলিটি (কে/কি/কখন), এবং পূর্বানুমানযোগ্য রিটেনশন পলিসি দাবি করে। কোনো নির্দিষ্ট নিয়ম না-জানালেও ধরে নিন আপনাকে লাগবে: append-only লেজার এন্ট্রি, টাইমস্ট্যাম্প করা রেকর্ড, কন্ট্রোলড অ্যাক্সেস, এবং রিটেনশন/আর্কাইভ নীতি যা অডিটেবিলিটি ক্ষুন্ন করে না।
ব্যবহার-কেস: ইনভেন্টরি, বুকিং ও রিজার্ভেশন
দ্রুত PoC তৈরি করুন
React + Go স্টার্টার অ্যাপ চালু করে আপনার ডিস্ট্রিবিউটেড SQL PoC-কে বাস্তব প্রোডাক্টে পরিণত করুন।
ইনভেন্টরি ও রিজার্ভেশন সহজ মনে হয় যতক্ষণ না একই কম সম্পদ বহু রিজিয়নে সার্ভ করে: শেষ কনসার্ট সিট, একটি লিমিটেড ড্রপ প্রোডাক্ট, বা নির্দিষ্ট রাতের জন্য একটি হোটেল রুম।
কঠিন অংশটি পড়া না—এটি হলো একই আইটেমকে প্রায় এক সময়ে দুইজন মানুষ থেকে সফলভাবে প্রতিহত করা প্রতিরোধ করা।
কনফ্লিক্ট কোথা থেকে আসে
মাল্টি-রিজিয়ন সেটআপে শক্ত কনসিস্টেন্সি না থাকলে প্রতিটি রিজিয়ন অল্পদিনের জন্য পুরোনো ডেটা দেখে উপলব্ধতা মনে করতে পারে। যদি দুইজন ব্যবহারকারী ওই সময়ে ভিন্ন রিজিয়নে চেকআউট করে, দুজনকেই লোকালি সফল বলে মনে হতে পারে এবং পরে রিকনসিলিয়েশনে কনফ্লিক্ট দেখা দেয়।
এভাবেই ক্রস-রিজিয়ন ওভারসেল ঘটে: সিস্টেম “ভুল” নয়, বরং এটি অল্প সময়ের জন্য বিভক্ত সত্য রাখতে দিয়েছে।
ডিস্ট্রিবিউটেড SQL ডাটাবেসগুলো প্রায়ই এখানে নির্বাচিত হয় কারণ তারা লিখন-উপর নির্ভরশীল একক কর্তৃত্বশীল ফলাফল প্রয়োগ করতে পারে—তাই “শেষ সিট” একবারই বরাদ্দ হয়, এমনকি অনুরোধ মহাদেশ থেকে আসলেও।
বাস্তব উদাহরণ
- সিট বুকিং: দুইজন ব্যবহারকারী একই সিটে ক্লিক করে। শক্ত কনসিস্টেন্সি থাকলে শুধুমাত্র একটি ট্রানজ্যাকশন কমিট হবে; অন্যটি ব্যর্থ হবে এবং UI রিফ্রেশের নির্দেশ দিতে পারে।
- লিমিটেড ড্রপ: 500 আইটেম লাইভ হলে হাজার হাজার চেকআউট চেষ্টা করে; আপনি চান এটম অটমিক ডিসমিনিশন-এ এবং বরাদ্দে, পরে রিফান্ডের উপর নির্ভর না করে।
- হোটেল রিজার্ভেশন: ইনভেন্টরি ইউনিট কেবল রুম নয়, বরং রুম-নাইট; একটি তারিখ পরিসরের ডাবল-বুকিং ব্যয়সাপেক্ষ এবং ফেরানো কঠিন।
সাধারণ প্যাটার্ন যা Distributed SQL-এ ভালো চলে
হোল্ড + কনফার্ম: একটি টেম্পোরারি হোল্ড (রিজার্ভেশন রেকর্ড) ট্রানজ্যাকশনে রাখুন, পরে পেমেন্ট কনফার্মেশনে দ্বিতীয় ধাপ।
এক্সপায়ারেশন: হোল্ডগুলো স্বয়ংক্রিয়ভাবে মেয়াদোত্তীর্ণ হওয়া উচিত (উদাহরণ: 10 মিনিট) যাতে ব্যবহারকারী ব্যাক নিয়ে গেলে ইনভেন্টরি আটকে না থাকে।
ট্রানজ্যাকশনাল আউটবক্স: যখন একটি রিজার্ভেশন কনফার্ম হয়, একই ট্রানজ্যাকশনে একটি “পাঠানোর ইভেন্ট” সারি লিখুন, পরে সেটি অ্যাসিঙ্ক্রোনাসভাবে ইমেইল, ফুলফিলমেন্ট, অ্যানালিটিক্স বা মেসেজ বাস-এ পাঠান—এভাবে “বুক হয়েছে কিন্তু কোনো কনফার্মেশন পাঠানো হয়নি” গ্যাপ এড়ানো যায়।
নিষ্কর্ষ: যদি আপনার ব্যবসা ক্রস-রিজিয়নে ডবল-অ্যালোকেশন সহ্য করতে পারে না, শক্ত ট্রানজ্যাকশনাল গ্যারান্টি একটি প্রোডাক্ট ফিচার—টেকনিক্যাল নয়।
ব্যবহার-কেস: উচ্চ প্রাপ্যতা ও ডিজাস্টার রিকভারি
উচ্চ প্রাপ্যতা (HA) ডিস্ট্রিবিউটেড SQL-এর জন্য উপযুক্ত যখন ডাউনটাইম ব্যয়বহুল, অনিশ্চিত আউটেজ গ্রহণযোগ্য নয়, এবং আপনি চাইবেন রক্ষণাবেক্ষণ যেন সাধারণ কাজ হয়।
লক্ষ্য নয় “কখনও ব্যর্থ হবে না”—লক্ষ্য হলো স্পষ্ট SLO মেটানো (উদাহরণ: 99.9% বা 99.99% আপটাইম) এমনকি নোড মরলে, জোন ডার্ক হলে, বা আপগ্রেড চলাকালীনও।
“অলওয়েজ-অন” বাস্তবে: SLO, রক্ষণাবেক্ষণ, ব্যর্থতা
শুরু করুন “অলওয়েজ-অন” কে পরিমাপযোগ্য প্রত্যাশায় অনুবাদ করে: মাসিক সর্বোচ্চ ডাউনটাইম, RTO, এবং RPO।
ডিস্ট্রিবিউটেড SQL সিস্টেমগুলো অনেক সাধারণ ব্যর্থতার মধ্যেও রিড/রাইট সার্ভ করতে পারে, কিন্তু শুধুমাত্র যদি আপনার টপোলজি আপনার SLO-কে মেলে এবং আপনার অ্যাপ অস্থায়ী ত্রুটি (রিট্রাই, idempotency) পরিষ্কারভাবে হ্যান্ডেল করে।
পরিকল্পিত রক্ষণাবেক্ষণও গুরুত্বপূর্ণ। রোলিং আপগ্রেড ও ইনস্ট্যান্স রিপ্লেসমেন্ট তখনই সহজ হয় যখন ডাটাবেস লিডার/রেপ্লিকা প্রভাবিত নোডগুলো থেকে সরিয়ে ক্লাস্টারকে পুরোবার ডাউন না করে চালাতে পারে।
মাল্টি-জোন বনাম মাল্টি-রিজিয়ন রেডানডেন্সি
মাল্টি-জোন ডিপ্লয়মেন্ট আপনাকে একটি AZ/জোন আউটেজ থেকে রক্ষা করে এবং অনেক হার্ডওয়্যার ব্যর্থতা থেকে; সাধারণত লেটেন্সি ও খরচ কম। যদি আপনার কমপ্লায়েন্স ও ব্যবহারকারী বেস প্রধানত এক রিজিয়নের মধ্যে হয়, এগুলো প্রায়ই যথেষ্ট।
মাল্টি-রিজিয়ন ডিপ্লয়মেন্ট একটি পূর্ণ রিজিয়ন আউটেজ থেকে রক্ষা করে এবং রিজিয়ন-লেভেল ফেলওভার সমর্থন করে। ট্রেড-অফ হচ্ছে শক্ত কনসিস্টেন্ট ট্রানজ্যাকশনের জন্য উচ্চতর রাইট লেটেন্সি এবং জটিল ক্যাপাসিটি পরিকল্পনা।
ফেলওভার প্রত্যাশা (এবং গেম ডে দিয়ে টেস্ট)
ফেলওভার অবিলম্বে বা অদৃশ্য হবে এমন আশা করবেন না। আপনার পরিষেবার জন্য “ফেলওভার” কী মানে তা সংজ্ঞায়িত করুন: সংক্ষিপ্ত ত্রুটি উত্থান? রিড-অনলি সময়? কয়েক সেকেন্ডের জন্য বাড়তি লেটেন্সি?
“গেম ডে” চালান:
- একটি নোড কিল করুন, পরে একটি জোন; আপনার SLO ড্যাশবোর্ড ও ক্লায়েন্ট ত্রুটি বাজেট যাচাই করুন।
- নেটওয়ার্ক পার্টিশন সিমুলেট করুন এবং লিডার/রেপ্লিকা আচরণ যাচাই করুন।
- রিজিয়ন ইভাকুয়েশন অনুশীলন করুন এবং আসল RTO মাপুন।
রিপ্লিকেশন ব্যাকআপ নয়
সিঙ্ক্রোনাস রিপ্লিকেশনের সত্ত্বেও, ব্যাকআপ রাখুন এবং রিস্টোর অনুশীলন করুন। ব্যাকআপ অপারেটর ভুল (মন্দ মাইগ্রেশন, দুর্ঘটনাজনিত ডিলিট), অ্যাপ বাগ, এবং করাপশন থেকে রক্ষা করে—যা রিপ্লিকেট হতে পারে।
পয়েন্ট-ইন-টাইম রিকভারি (যদি সমর্থিত) যাচাই করুন, রিস্টোরের গতি পরীক্ষা করুন, এবং প্রোডাকশন ছুঁয়েই না গিয়ে পরিষ্কার পরিবেশে পুনরুদ্ধার করতে পারবেন কি না নিশ্চিত করুন।
ব্যবহার-কেস: ডেটা রেসিডেন্সি ও কমপ্লায়েন্স-চালিত আর্কিটেকচার
ডেটা রেসিডেন্সি প্রয়োজন তখন আসে যখন নিয়ম, চুক্তি, বা অভ্যন্তরীণ নীতি বলে নির্দিষ্ট রেকর্ডগুলো একটি দেশের বা রিজিয়নের মধ্যে সংরক্ষণ (এবং কখনো কখনো প্রসেস) করা উচিত।
এটি প্রযোজ্য হতে পারে পার্সোনাল ডেটা, হেলথকেয়ার ইনফো, পেমেন্ট ডেটা, সরকারি ওয়ার্কলোড, বা “কাস্টমার-অধীন” ডেটাসেট যেখানে ক্লায়েন্ট চুক্তি নির্ধারিত করে ডেটা কোথায় থাকবে।
ডিস্ট্রিবিউটেড SQL এখানে বিবেচিত হয় কারণ এটি একটি লজিক্যাল ডাটাবেস রেখে শারীরিকভাবে ডেটা বিভিন্ন রিজিয়নে রাখার সুবিধা দেয়—বিনা প্রতিটি ভূগোলে সম্পূর্ণ আলাদা অ্যাপ স্ট্যাক চালানোর প্রয়োজন।
কেন রেসিডেন্সি রুলগুলো ডাটাবেস ডিজাইন বদলে দেয়
যদি কোনো নিয়ন্ত্রক বা কাস্টমার দাবি করে “ডেটা রিজিয়নের মধ্যে থাকে,” শুধুই নিকটস্থ রিপ্লিকা রাখা যথেষ্ট নয়। হতে পারে আপনাকে নিশ্চিত করতে হবে:
- নির্দিষ্ট ডেটার প্রাইমারি কপি (অথবা সব কপি) শুধুমাত্র অনুমোদিত রিজিয়নে রাখা হয়
- ব্যাকআপ ও স্ন্যাপশট একই নিয়ম মেনে চলে
- রিজিয়নের বাইরে অপারেটর ও সার্ভিসরা কাঁচা ডেটা অ্যাক্সেস করতে পারে না
এটি দলগুলোকে এমন আর্কিটেকচারের দিকে ঠেলে দেয় যেখানে অবস্থান একটি প্রথম-শ্রেণীর বিবেচ্য বিষয়।
প্রতি-গ্রাহক প্লেসমেন্ট ও অ্যাক্সেস কন্ট্রোল (উচ্চ-স্তরে)
SaaS-এ প্রতি-টেন্যান্ট (প্রতি-গ্রাহক) ডেটা প্লেসমেন্ট একটি সাধারণ প্যাটার্ন। উদাহরণ: EU গ্রাহকের সারি বা পার্টিশনগুলো EU রিজিয়নে পিন করা, US গ্রাহকরা US রিজিয়নে।
সাধারণভাবে আপনি যে তিনটি জিনিস মিলাবেন:
- ডেটা প্লেসমেন্ট পলিসি (কোন টেন্যান্টের ডেটা কোথায় থাকতে পারে)
- আইডেন্টিটি ও অ্যাক্সেস কন্ট্রোল (কোন সার্ভিস/মানুষ তা পড়তে পারে)
- ইনক্রিপশন ও কী ম্যানেজমেন্ট (কখনো কখনো রিজিয়ন-বাইন্ড কী)
লক্ষ্য হলো অপারেশনাল অ্যাক্সেস, ব্যাকআপ রিস্টোর, বা ক্রস-রিজিয়ন রিপ্লিকেশনের মাধ্যমে অনিচ্ছাকৃতভাবে রেসিডেন্সি লঙ্ঘন করা কঠিন করা।
আইনি প্রয়োজন ভিন্ন—কাউন্সেল নিন
রেসিডেন্সি ও কমপ্লায়েন্স বাধ্যবাধকতাগুলো দেশ, শিল্প, ও চুক্তি অনুযায়ী ব্যাপকভাবে ভিন্ন। এরা সময়ের সঙ্গে বদলে যায়।
ডাটাবেস টপোলজি আপনার কমপ্লায়েন্স প্রোগ্রামের অংশ হিসেবে বিবেচনা করুন, এবং আপনার কল্পনা আইনি উপদেশ ও (যেখানে প্রাসঙ্গিক) অডিটরদের সাথে যাচাই করুন।
মাল্টি-রিজিয়ন টপোলজি কীভাবে রিপোর্টিং ও অ্যানালিটিক্সে প্রভাব ফেলে
রেসিডেন্সি-সহনশীল টপোলজি “গ্লোবাল ভিউ” জটিল করতে পারে। যদি গ্রাহক ডেটা অভিপ্রায়ক্রমে আলাদা রিজিয়নে থাকে, অ্যানালিটিকস ও রিপোর্টিং হতে পারে:
- রিজিয়নাল রিপোর্টিং পাইপলাইন (ডেটা যেখানে আছে সেখানেই কম্পিউট চালায়)
- এগ্রিগেটেড এক্সপোর্ট (শুধু অনুমোদিত মেট্রিকসই রিজিয়নের বাইরে যায়)
- ক্রস-রিজিয়ন ড্যাশবোর্ডে উচ্চ লেটেন্সি গ্রহণ করা
প্রায়ই টিমগুলো অপারেশনাল ওয়ার্কলোড (শক্ত কনসিস্টেন্ট, রেসিডেন্সি-সচেতন) আলাদা রাখে অ্যানালিটিকস থেকে (রিজিয়ন-স্কোপড ওয়্যারহাউস বা মনোনীত এগ্রিগেটেড ডেটাসেট) যাতে কমপ্লায়েন্স ম্যানেজযোগ্য থাকে এবং প্রতিদিনের রিপোর্টিং ধীরে না যায়।
ডিস্ট্রিবিউটেড SQL-এর জন্য খরচ ও পারফরম্যান্স পরিকল্পনা
নির্ভরযোগ্য ইভেন্ট মডেল করুন
ট্রানজ্যাকশনাল আউটবক্স ওয়ার্কফ্লো খসড়া করুন এবং স্কিমা ও হ্যান্ডলার দ্রুত পুনরাবৃত্তি করুন।
ডিস্ট্রিবিউটেড SQL আপনাকে ব্যয়বহুল আউটেজ ও আঞ্চলিক সীমাবদ্ধতা থেকে রক্ষা করতে পারে, কিন্তু এটি নিজে থেকেই সাধারণত অর্থ সাশ্রয় করে না। আগে থেকেই পরিকল্পনা করলে আপনি এমন “বীমা”-এর জন্য অর্থ না দেওয়ার ঝুঁকি এড়াতে পারবেন যা আপনাকে দরকার নেই।
প্রধান খরচ চালক
বেশিরভাগ বাজেট চারটি বাকেটে ভাঙে:
- নোড (কম্পিউট): আপনি অনেক রেপ্লিকা অনলাইন রাখার জন্য পে করবেন—সাধারণত প্রতিটি রিজিয়নে 3+ রেপ্লিকা—সাথে ফেলওভারের জন্য অতিরিক্ত ক্ষমতা। মাল্টি-রিজিয়ন ডিজাইন সাধারণত single-region Postgres থেকে বেশি হেডরুম দাবি করে।
- স্টোরেজ: রিপ্লিকেশন ডেটা সাইজ বাড়ায়। 2 TB ডেটাসেটে তিনটি রেপ্লিকা থাকলে ~6 TB হবে ব্যাকআপ, ইনডেক্স, ও ওভারহেড ছাড়া।
- ইন্টার-রিজিয়ন ট্র্যাফিক: ক্রস-রিজিয়ন রিপ্লিকেশন, রিড, এবং ক্লায়েন্ট ট্র্যাফিক একটি উল্লেখযোগ্য লাইন আইটেম হতে পারে। এটি সাধারণত প্রথম “আশ্চর্য” যা মাল্টি-একটিভ হলে আসে।
- অপস সময়: এমনকি managed অফারিংগুলিও কাজ দাবি করে: স্কিমা ও কুয়েরি টিউনিং, ইনসিডেন্ট রেসপন্স, ক্যাপাসিটি পরিকল্পনা, আপগ্রেড টেস্টিং, এবং গভর্নেন্স (বিশেষত রেসিডেন্সি/কমপ্লায়েন্স সম্পর্কিত)।
বাস্তব ব্যবহারকারী জার্নিতে লেটেন্সি প্রভাব অনুমান করা
ডিস্ট্রিবিউটেড SQL সিস্টেমগুলো সমন্বয় যোগ করে—বিশেষত শক্ত কনসিস্টেন্ট রাইটগুলোর জন্য যা কোয়ারামে নিশ্চিত হতে হবে।
একটি ব্যবহারিক উপায় প্রভাব অনুমান করার:
- 2–3টি গুরুত্বপূর্ণ জার্নি বেছে নিন (চেকআউট, বুকিং, “সেভ চেঞ্জস”)।
- ক্রিটিক্যাল পাথের কতগুলো রাইট ট্রানজ্যাকশন এবং রিড-আফটার-রাইট ধাপ আছে তা গণনা করুন।
- প্রতিটি ধাপের জন্য, যেখানে সমন্বয় দরকার সেখানে একটি মাল্টি-রিজিয়ন রাউন্ড ট্রিপ ধরুন। ক্রস-রিজিয়ন RTT যদি 80–120 ms হয়, দুটি সিকোয়েন্সিয়াল রাইট ধাপ অ্যাপ টাইমে 160–240 ms যোগ করতে পারে।
এর মানে এই নয় “এটি করবেন না,” বরং জার্নিগুলো ডিজাইন করুন যাতে সিকোয়েন্সিয়াল রাইট কম হয় (ব্যাচিং, idempotent রিট্রাই, কম চ্যাটি ট্রানজ্যাকশন)।
জটিলতা বনাম সহজ বিকল্প
যদি আপনার ব্যবহারকারীরা প্রধানত এক রিজিয়নের মধ্যে থাকে, একটি একক-রিজিয়ন Postgres সহ রিড রিপ্লিকা, ভালো ব্যাকআপ, এবং পরীক্ষা করা ফেলওভার প্ল্যান সস্তা এবং সহজ হতে পারে—এবং দ্রুত।
ডিস্ট্রিবিউটেড SQL তার খরচ তখনই ন্যায্য করে যখন আপনি সত্যি মাল্টি-রিজিয়ন রাইট, খাঁটি RPO/RTO, অথবা রেসিডেন্সি-সচেতন প্লেসমেন্ট প্রয়োজন।
একটি সহজ ROI ফ্রেমিং
খরচটিকে একটি ট্রেড হিসেবে বিবেচনা করুন:
- ঝুঁকি এড়ানো: আয়-প্রভাবে পতিত আউটেজ কম, ডেটা লস কম, গ্লোবাল ইনসিডেন্ট উইকেন্ড কম।
- রেভিনিউ রক্ষা: রিজিয়নাল ব্যবহারকারীদের জন্য কম লেটেন্সি দিয়ে কনভার্শন বাড়ে, বৃহৎ এন্টারপ্রাইজকে SLA ও কমপ্লায়েন্স দিয়ে আকৃষ্ট করা যায়।
- ব্যয়: বেসলাইন ক্লাস্টার + রিপ্লিকেশন ওভারহেড + ট্র্যাফিক + ইঞ্জিনিয়ারিং সময়।
যদি এড়ানো লস (ডাউনটাইম + চর্ণ + কমপ্লায়েন্স ঝুঁকি) চলমান প্রিমিয়ামের চেয়ে বড় হয়, মাল্টি-রিজিয়ন ডিজাইন ন্যায্য। না হলে, সরলভাবে শুরু করুন—এবং পরে বিকাশের পথ রাখুন।
গ্রহণযোগ্যতা চেকলিস্ট ও পরবর্তী ধাপ
ডিস্ট্রিবিউটেড SQL গ্রহণ করা মানে শুধু ডাটাবেস লিফট-শিফট নয়; এটি প্রমাণ করা যে আপনার নির্দিষ্ট ওয়ার্কলোড ডেটা ও কনসেনসাস ছড়ানো অবস্থায় ভাল আচরণ করে। একটি হালকা-ওজন পরিকল্পনা আপনাকে বিস্ময় এড়াতে সাহায্য করবে।
একটি ফোকাসড প্রুফ-অফ-কনসেপ্ট (PoC)
একটি ওয়ার্কলোড বেছে নিন যা বাস্তব ব্যথা প্রতিনিধিত্ব করে: উদাহরণ: checkout/booking, account provisioning, বা ledger posting।
সাফল্যের মেট্রিক নির্ধারণ করুন আগে থেকে:
- সঠিকতা: ডাবল-বুকিং নেই, লস্ট-আপডেট নেই, পূর্বানুমানযোগ্য ট্রানজ্যাকশন আচরণ
- লেটেন্সি SLO: শীর্ষ ৩ কুয়েরির p50/p95 (প্রয়োজনে ক্রস-রিজিয়ন টার্গেট সহ)
- থ্রুপুট: পিকে টেকসই QPS + সেফটি মার্জিন (প্রায় 2–3×)
- রেসিলিয়েন্স: নোড ব্যর্থতা ও (প্রাসঙ্গিক হলে) রিজিয়ন লসের সময় আচরণ
- অপারেশনাল প্রচেষ্টা: সিমুলেটেড ইনসিডেন্ট থেকে শনাক্ত, ডায়াগনোসিস ও রিকভারি সময়
PoC স্টেজে দ্রুত সরতে চাইলে, একটি ছোট “বাস্তবসম্মত” অ্যাপ সারফেস (API + UI) বানানো সাহায্য করে—শুধুমাত্র সিনথেটিক বেঞ্চমার্ক নয়। উদাহরণস্বরূপ, দলগুলো কখনো কখনো Koder.ai ব্যবহার করে একটি হালকা React + Go + PostgreSQL বেসলাইন অ্যাপ দ্রুত ঘোরে, তারপর ডাটাবেস লেয়ারকে CockroachDB/YugabyteDB-তে বদলে PoC করে (অথবা Spanner-এ কানেক্ট করে) ট্রানজ্যাকশন প্যাটার্ন, রিট্রাই, এবং ফেলিয়ার আচরণ এন্ড-টু-এন্ড টেস্ট করার জন্য। মূল উদ্দেশ্য: “ধারণা” থেকে “পরিমাপযোগ্য কাজ” পর্যন্ত লুপ সংক্ষিপ্ত করা।
ডিজাইন চেকলিস্ট (পরে ব্যথা দেয় এমনগুলো)
- স্কিমা: প্রাইমারি কী নির্বাচন করুন যা রাইট ছড়ায়; ধারাবাহিক “হট” কী এড়ান
- ইন্ডেক্স: জরুরি না হলে রাখবেন না; সেকেন্ডারি ইন্ডেক্স থেকে লিখন অ্যাম্প্লিফিকেশন বুঝুন
- পার্টিশনিং/প্লেসমেন্ট: অ্যাক্সেস প্যাটার্ন অনুযায়ী পার্টিশন কী নির্ধারণ করুন
- হটস্পট: “সেলিব্রিটি রো” (গ্লোবাল কাউন্টার, সিঙ্গেল-টেন্যান্ট টেবিল) চিহ্নিত করুন এবং শুরুতেই রিডিজাইন করুন
- মাইগ্রেশন: অনলাইন স্কিমা চেঞ্জ ও ব্যাকফিল পরিকল্পনা করুন; রোলব্যাক পথ টেস্ট করুন
অপারেশনাল বেসিকস শুরুতেই থাকা উচিত
মনিটরিং ও রানবুক SQL-পর্যায়ের মতোই গুরুত্বপূর্ণ:
- লেটেন্সি, রিট্রাই, কনটেনশন, রিপ্লিকেশন/কনসেনসাস স্বাস্থ্যের ড্যাশবোর্ড
- ইনসিডেন্ট রানবুক: ধীর কুয়েরি, নোড রিস্টার্ট, ফেলিং রেপ্লিকা, অসমান লোড
- লোড টেস্টিং যা প্রোডাকশনের মতো (রিড/রাইট মিশ্রণ, স্পাইক, লং ট্রানজ্যাকশন)
- ব্যাকআপ + রিস্টোর ড্রিল (পয়েন্ট-ইন-টাইম রিকভারি থাকলে সেটিও)
পরবর্তী ধাপ
একটি PoC স্প্রিন্ট দিয়ে শুরু করুন, তারপর প্রোডাকশন রেডিনেস রিভিউ এবং ধীরে ধীরে কাটওভার (যতটা সম্ভব dual writes বা shadow reads) পরিকল্পনা করুন।
আপনি যদি খরচ বা টিয়ার স্কোপ করতে সাহায্য চান, দেখুন /pricing। বাস্তবায়ন-পর্দশ ও মাইগ্রেশন প্যাটার্নগুলির জন্য দেখুন /blog।
যদি আপনি আপনার PoC ফলাফল, আর্কিটেকচার ট্রেডঅফ, বা মাইগ্রেশন পাঠ শেয়ার করেন, তা টিমের সঙ্গে (এবং সম্ভব হলে প্রকাশ্যে) ভাগ করার কথা ভাবুন: Koder.ai-এর মতো প্ল্যাটফর্মগুলো কখনও কখনও শিক্ষামূলক কনটেন্ট তৈরির জন্য ক্রেডিট দেয় বা রেফারেল ক্রেডিট প্রদান করে, যা পরীক্ষামূলক খরচ কমাতে সাহায্য করে।