১৪ অক্টো, ২০২৫·7 মিনিট
GraphQL কী? API এবং ডেটা ফেচিং-এর জন্য পরিষ্কার গাইড
জানুন GraphQL কী, কোয়েরি, মিউটেশন এবং স্কিমা কীভাবে কাজ করে, কখন REST-এর বদলে এটি ব্যবহার করবেন—প্রায়োগিক সুবিধা, অসুবিধা ও উদাহরণ সহ।
জানুন GraphQL কী, কোয়েরি, মিউটেশন এবং স্কিমা কীভাবে কাজ করে, কখন REST-এর বদলে এটি ব্যবহার করবেন—প্রায়োগিক সুবিধা, অসুবিধা ও উদাহরণ সহ।
GraphQL হচ্ছে একটি কোয়েরি ল্যাংগুয়েজ এবং API-এর জন্য রনটাইম। সরলভাবে: এটা এমন একটি উপায় যার মাধ্যমে একটি অ্যাপ (ওয়েব, মোবাইল বা অন্য কোনো সার্ভিস) পরিষ্কার, গঠনভিত্তিক রিকোয়েস্ট ব্যবহার করে এক API-কে ডেটা চাইতে পারে—আর সার্ভার সেই রিকোয়েস্টের সাথে মেলে এমন রেসপন্স ফেরত দেয়।
অনেক API ক্লায়েন্টকে নির্দিষ্ট এন্ডপয়েন্ট যা দেয় সেটাই গ্রহণ করতে বাধ্য করে। এতে প্রায়ই দুটি সমস্যা দেখা দেয়:
GraphQL-এ, ক্লায়েন্ট ঠিকমাত্রা ফিল্ডই চাইতে পারে—না বেশি, না কম। এটি বিশেষভাবে উপকারী যখন বিভিন্ন স্ক্রিন বা অ্যাপ একই মূল ডেটার বিভিন্ন "কাট" চায়।
GraphQL সাধারণত ক্লায়েন্ট অ্যাপ ও আপনার ডেটা সোর্সগুলোর মাঝখানে থাকে। ওই ডেটা সোর্সগুলো হতে পারে:
GraphQL সার্ভার একটি কোয়েরি গ্রহণ করে, প্রতিটি অনুরোধকৃত ফিল্ড কোথা থেকে আনা হবে তা নির্ধারণ করে, এবং পরে চূড়ান্ত JSON রেসপন্স সাজায়।
GraphQL-কে ভাবুন কাস্টম‑আকৃতির রেসপন্স অর্ডার করার মতো:
কিছু ভুল ধারণা পরিষ্কার করে বলা দরকার:
যদি আপনি সেই মূল সংজ্ঞা—কোয়েরি ল্যাংগুয়েজ + API-এর জন্য রনটাইম—মনে রাখেন, তাহলে বাকি বিষয়গুলো বোঝা সহজ হবে।
GraphQL তৈরি হয়েছিল একটি প্রায়োগিক প্রোডাক্ট সমস্যার সমাধানে: টিমগুলো UI স্ক্রিনের জন্য API-কে মানিয়ে নিতে অনেকটা সময় নষ্ট করছিল।
পারম্পরিক এন্ডপয়েন্ট‑ভিত্তিক API প্রায়ই বাধ্য করে যে হয় আপনি অপ্রয়োজনীয় ডেটা ছাড়বেন অথবা যে ডেটাগুলো লাগবে তা পেতে একাধিক কল করতে হবে। প্রোডাক্ট বাড়ার সাথে সাথে এই ঘর্ষণ ধীর পেজ, জটিল ক্লায়েন্ট কোড এবং ফ্রন্টএন্ড‑ব্যাকএন্ড সমন্বয়ের কষ্টে পরিণত হয়।
ওভার‑ফেচিং ঘটে যখন একটি এন্ডপয়েন্ট "সম্পূর্ণ" অবজেক্ট কী দেয়, যদিও একটি স্ক্রিনে শুধু কয়েকটি ফিল্ডই দরকার। উদাহরণ: মোবাইল প্রোফাইল ভিউতে শুধুমাত্র নাম ও অবতার লাগে, কিন্তু API ঠিকানাগুলো, প্রেফারেন্স, অডিট ফিল্ড ইত্যাদি ফেরত দেয়—এটি ব্যান্ডউইথ নষ্ট করে এবং ইউজার এক্সপেরিয়েন্সকে ক্ষতিগ্রস্ত করতে পারে।
আন্ডার‑ফেচিং এর বিপরীত: কোনো একক এন্ডপয়েন্টে প্রয়োজনীয় সবকিছু না থাকলে ক্লায়েন্টকে একাধিক রিকুয়েস্ট করে রেজাল্টগুলো জোড়া লাগাতে হয়। এতে লেটেন্সি বাড়ে এবং আংশিক ব্যর্থতার সম্ভাবনা বেড়ে যায়।
অনেক REST‑স্টাইল API পরিবর্তনের জবাবে নতুন এন্ডপয়েন্ট যোগ করে বা ভার্সনিং (v1, v2, v3) করে। ভার্সনিং প্রয়োজনীয় হলেও এতে দীর্ঘমেয়াদি রক্ষণাবেক্ষণের কাজ বাড়ে: পুরোনো ক্লায়েন্টরা পুরোনো ভার্সন ব্যবহার করে যায়, আর নতুন ফিচার অন্য জায়গায় জমা হয়।
GraphQL-এর পদ্ধতি হলো স্কিমা বাড়ানো—নতুন ফিল্ড ও টাইপ যোগ করা—এভাবে বিদ্যমান ফিল্ডগুলো স্থিতিশীল রেখে। এতে অনেক সময় নতুন UI প্রয়োজনের জন্য আলাদা ভার্সন তৈরি করার চাপে কম পড়ে।
আধুনিক প্রোডাক্ট সাধারণত একাই কনজিউমার রাখে না। ওয়েব, iOS, Android এবং পার্টনার ইন্টেগ্রেশন প্রতিটি ভিন্ন ডেটা আকৃতি চায়।
GraphQL যাতে করে প্রত্যেক ক্লায়েন্টই ঠিক প্রয়োজনীয় ফিল্ড চাইতে পারে—ব্যাকএন্ডকে প্রতিটি স্ক্রিন বা ডিভাইসের জন্য আলাদা এন্ডপয়েন্ট তৈরি করতে বাধ্য না করেই—এমনভাবে ডিজাইন করা হয়েছে।
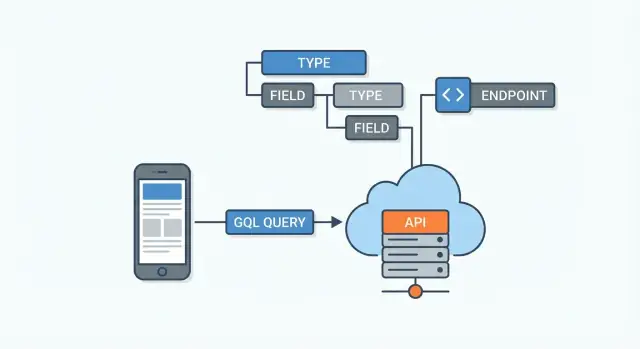
একটি GraphQL API এর সংজ্ঞা তার স্কিমা দ্বারা নির্ধারিত। এটিকে সার্ভার ও সকল ক্লায়েন্টের মধ্যে থাকা চুক্তি হিসেবে ভাবুন: এটি বলে কোন ডেটা আছে, কীভাবে সেটা সংযুক্ত, আর কী চাওয়া বা বদলানো যাবে। ক্লায়েন্টগুলি এন্ডপয়েন্ট অনুমান করে না—তারা স্কিমা পড়ে নির্দিষ্ট ফিল্ড অনুরোধ করে।
স্কিমা টাইপ (যেমন User বা Post) এবং ফিল্ড (যেমন name বা title) দিয়ে গঠিত। ফিল্ডগুলো অন্য টাইপের কাছে নির্দেশ করতে পারে—এভাবেই GraphQL সম্পর্ক মডেল করে।
নিচে Schema Definition Language (SDL)-তে একটি সহজ উদাহরণ আছে:
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
স্কিমা স্ট্রংলি টাইপড হওয়ায়, GraphQL একটি রিকুয়েস্ট চালানোর আগে তা ভ্যালিডেট করতে পারে। যদি ক্লায়েন্ট এমন কোনো ফিল্ড চায় যা নেই (উদাহরণ: Post.publishDate যখন স্কিমায় নেই), সার্ভার স্পষ্ট ত্রুটি দিয়ে রিকুয়েস্ট বাতিল বা আংশিকভাবে পূরণ করতে পারে—অনিশ্চিত "হয়তো কাজ করে" আচরণ ছাড়াই।
স্কিমা বাড়ানোর জন্য ডিজাইন করা—সাধারণত নতুন ফিল্ড যোগ করলে বিদ্যমান ক্লায়েন্ট ভাঙে না, কারণ ক্লায়েন্ট শুধু যা চেয়েছে তাই পায়। ফিল্ড সরানো বা পরিবর্তন করা সংবেদনশীল, তাই টিমগুলো প্রায়ই প্রথমে ফিল্ড ডিপ্রিকেট করে ক্লায়েন্টগুলো ধীরে ধীরে মাইগ্রেট করে।
একটি GraphQL API সাধারণত একটি এন্ডপয়েন্ট (উদাহরণ: /graphql) দিয়ে প্রকাশ করা হয়। বিভিন্ন রিসোর্সের জন্য অনেক URL (যেমন /users, /users/123, /users/123/posts) থাকার বদলে আপনি এক স্থানে একটি কোয়েরি পাঠিয়ে ঠিক কোন ডেটা চান তা বর্ণনা করেন।
কোয়েরি হলো মূলত একটি "শপিং লিস্ট" ফিল্ডগুলোর। আপনি সহজ ফিল্ড (যেমন id, name) এবং নেস্টেড ডেটা (যেমন ইউজারের সাম্প্রতিক পোস্ট) একই অনুরোধে চাইতে পারেন—বিনা অপ্রয়োজনীয় ফিল্ড ডাউনলোড করে।
নিচে একটি ছোট উদাহরণ আছে:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
GraphQL রেসপন্সগুলো প্রেডিক্টেবল: আপনি যে JSON পাবেন তা আপনার কোয়েরির স্ট্রাকচারকে অনুকরণ করে। এটা ফ্রন্টএন্ডে কাজ করা সহজ করে, কারণ আপনাকে আর অনুমান করতে হয় না ডেটা কোথায় থাকবে।
সরলীকৃত রেসপন্সের আউটলাইন এরকম হতে পারে:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
আপনি যদি কোন ফিল্ড ন চান তা রেসপন্সে থাকবে না। আপনি যদি চান, আপনি নির্দিষ্ট স্থানে তা পাবেন—ফ্রন্টএন্ডের জন্য GraphQL কোয়েরিগুলোকে প্রতিটি স্ক্রিন বা ফিচারের প্রয়োজন অনুযায়ী ডেটা আনার পরিষ্কার উপায় বানায়।
কোয়েরি পড়ার জন্য; মিউটেশন হল GraphQL API-তে কিভাবে আপনি ডেটা পরিবর্তন করেন—রেকর্ড তৈরি, আপডেট বা ডিলিট।
বহু মিউটেশন একই প্যাটার্ন অনুসরণ করে:
input অবজেক্ট) পাঠায়, যেমন কোন ফিল্ড আপডেট হবে।GraphQL মিউটেশন সাধারণত উদ্দেশ্যপ্রণোদিতভাবে ডেটা রিটার্ন করে, কেবল "success: true" নয়। আপডেট হওয়া অবজেক্ট (বা কমপক্ষে তার id ও গুরুত্বপূর্ণ ফিল্ড) রিটার্ন করলে UI:
একটি সাধারণ ডিজাইন হলো এমন একটি "পেলোড" টাইপ যা আপডেট হওয়া এনটিটি এবং যেকোনো এরর দুটোই অন্তর্ভুক্ত করে।
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
UI‑চালিত API-এর জন্য একটি ভাল নিয়ম: পরবর্তী রাষ্ট্র রেন্ডার করার জন্য যা দরকার তা রিটার্ন করুন (উদাহরণ: আপডেট হওয়া user এবং কোনো errors)। এতে ক্লায়েন্ট সরল থাকে, কি পরিবর্তিত হয়েছে অনুমান করতে হয় না, এবং ব্যর্থতাগুলো সুন্দরভাবে হ্যান্ডল করা সহজ হয়।
একটি GraphQL স্কিমা বর্ণনা করে কি চাওয়া যেতে পারে। রেজলভারগুলো বর্ণনা করে তথ্য কিভাবে আসবে। একটি রেজলভার হলো আপনার স্কিমার নির্দিষ্ট ফিল্ডে সংযুক্ত একটি ফাংশন। ক্লায়েন্ট যখন ঐ ফিল্ড অনুরোধ করে, GraphQL ঐ রেজলভারকে কল করে মান আনতে বা গণনা করতে।
GraphQL একটি কোয়েরি চালানোর সময় অনুরোধকৃত আকৃতি ধরে হাঁটে। প্রতিটি ফিল্ডের জন্য, এটি মিলযুক্ত রেজলভার খুঁজে পায় এবং চালায়। কিছু রেজলভার সোজাসুজি একটি অবজেক্টের প্রোপার্টি রিটার্ন করে; অন্যরা ডাটাবেস কল করে, অন্য সার্ভিসকে কল করে, বা একাধিক সোর্স সংযুক্ত করে।
উদাহরণস্বরূপ, যদি আপনার স্কিমায় User.posts থাকে, তখন posts রেজলভারটি userId দ্বারা posts টেবিল কোয়েরি করতে পারে, বা আলাদা Posts সার্ভিস কল করতে পারে।
রেজলভারগুলো স্কিমা এবং আপনার বাস্তব সিস্টেমগুলোর মাঝের গ্লু:
এই ম্যাপিংটি নমনীয়: আপনি ব্যাকএন্ড ইমপ্লিমেন্টেশন পরিবর্তন করতে পারবেন ক্লায়েন্ট কোয়েরি আকৃতি অপরিবর্তিত থাকলেই।
রেজলভারগুলো প্রতি ফিল্ড ও তালিকার প্রতিটি আইটেমে চালানো হতে পারে, তাই অসাবধানতায় অনেক ছোট কল ট্রিগার হতে পারে (উদাহরণ: 100 ইউজারের পোস্ট 100টি আলাদা কোয়েরি দিয়ে ফেচ করা)। এই "N+1" প্যাটার্ন রেসপন্সকে ধীর করে দিতে পারে।
সাধারণ সমাধান: বাচিং ও ক্যাশিং (উদাহরণ: আইডি সংগ্রহ করে একবারে ফেচ করা) এবং কোন নেস্টেড ফিল্ডে ক্লায়েন্টকে উৎসাহিত করবেন সেগুলো সম্পর্কে সচেতন হওয়া।
অথরাইজেশন সাধারণত রেজলভারগুলিতে (বা শেয়ার্ড মিডলওয়্যারে) প্রয়োগ করা হয় কারণ রেজলভাররা জানে কে চাচ্ছে (কন্টেক্সটের মাধ্যমে) এবং কি ডেটা অ্যাক্সেস করছে। ভ্যালিডেশন সাধারণত দুই স্তরে হয়: GraphQL টাইপ/আকৃতি ভ্যালিডেশন স্বয়ংক্রিয়ভাবে করে, যখন রেজলভার ব্যবসায়িক নিয়ম (যেমন "শুধু অ্যাডমিনরা এই ফিল্ড সেট করতে পারবে") Enforce করে।
GraphQL-এ নতুনদের জন্য একটি বিস্ময় হলো যে একটি রিকুয়েস্ট "সাফল্য" হতে পারে এবং তবুও ত্রুটি থাকতে পারে। তার কারণ GraphQL ফিল্ড-ওরিয়েন্টেড: কিছু ফিল্ড রেজলভ করা যায় এবং কিছু করা যায় না—তাই আপনি আংশিক ডেটা পেতে পারেন।
একটি সাধারণ GraphQL রেসপন্সে data এবং একটি errors অ্যারে দুটোই থাকতে পারে:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
এটা দরকারী: ক্লায়েন্টের কাছে যা আছে তা রেন্ডার করার সুযোগ থাকে (উদাহরণ: ইউজার প্রোফাইল) এবং মিসিং ফিল্ডটি হ্যান্ডল করা যায়।
data প্রায়ই null হয়।এন্ড‑ইউজারের জন্য ত্রুটি মেসেজ লিখুন, ডিবাগিংয়ের জন্য নয়। স্ট্যাক ট্রেস, ডাটাবেস নাম বা অভ্যন্তরীণ আইডি এক্সপোজ করা এড়ান। ভালো প্যাটার্ন:
messageextensions.coderetryable: true)সার্ভার‑সাইডে বিস্তারিত লগ করুন রিকুয়েস্ট আইডির সঙ্গে যাতে অভ্যন্তরীণ তথ্য প্রকাশ না হয়।
নেটিভ ও ওয়েব অ্যাপগুলোর জন্য ছোট একটি ত্রুটি “চুক্তি” নির্ধারণ করুন: সাধারণ extensions.code মান (যেমন UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), কখন টোস্ট দেখানো হবে বনাম কখন ইনলাইন ফিল্ড ত্রুটি দেখাবেন, এবং আংশিক ডেটা কিভাবে হ্যান্ডল করবেন। এখানে সামঞ্জস্য থাকলে প্রতিটি ক্লায়েন্ট নিজে নিজে নিয়ম আবিষ্কার করবে না।
সাবস্ক্রিপশন হলো GraphQL‑এর উপায় ক্লায়েন্টদের ডেটা পরিবর্তিত হলে তা পুশ করে দেওয়ার, বারবার ক্লায়েন্টকে জিজ্ঞেস করার বদলে। এগুলো সাধারণত একটি স্থায়ী সংযোগ (সবচেয়ে সাধারণত WebSockets) করে দেওয়া হয়, যাতে সার্ভার কোনো ইভেন্ট ঘটলেই সাবস্ক্রাইবারদের পে-লোড পাঠাতে পারে।
একটি সাবস্ক্রিপশন অনেকটা কোয়েরির মতো দেখায়, কিন্তু ফলাফল একক রেসপন্স নয়। এটি একটি রেসাল্ট স্ট্রিম—প্রতিটি আপডেট একটি ইভেন্ট উপস্থাপন করে।
অন্তর্ভুক্ত পদ্ধতিতে, ক্লায়েন্ট একটি টপিক সাবস্ক্রাইব করে (উদাহরণ: চ্যাট অ্যাপে messageAdded)। সার্ভার যখন ইভেন্ট প্রকাশ করে, কানেক্টেড সাবস্ক্রাইবাররা সাবস্ক্রিপশন‑এর সিলেকশন সেট অনুযায়ী পে‑লোড পায়।
সাবস্ক্রিপশনগুলো তখন ভাল যখন ব্যবহারকারীরা তাত্ক্ষণিক পরিবর্তন আশা করে:
পোলিং-এ ক্লায়েন্ট প্রতি N সেকেন্ডে জিজ্ঞেস করে "কিছু নতুন আছে?"। এটা সহজ, কিন্তু যখন কিছুই পরিবর্তিত না হয় তখন অনুরোধ নষ্ট হয় এবং এখনও দেরি মনে হতে পারে।
সাবস্ক্রিপশন-এ সার্ভারই মুহূর্তেই আপডেট পাঠায়। এতে অনাবশ্যক ট্রাফিক কমে এবং অনুভূত গতি বাড়ে—কিন্তু সংযোগ খোলা রাখার ও রিয়েল‑টাইম ইনফ্রা পরিচালনার খরচ থাকে।
সাবস্ক্রিপশন সবসময় প্রয়োজনীয় নয়। যদি আপডেট কম ঘটে, সময়নিষ্ঠ না হয়, বা সহজে ব্যাচ করা যায়, তবে পোলিং বা ইউজার একশন পরে রি‑ফেচ করা যথেষ্ট। সাবস্ক্রিপশন অপারেশনাল ওভারহেড বাড়ায়: সংযোগ স্কেলিং, দীর্ঘজীবী সেশনের অথ, রিট্রাই ও মনিটরিং। নিয়ম: রিয়েল‑টাইম হলে ব্যবহার করুন—শুধু সুখের জন্য নয়।
GraphQL প্রায়ই বলা হয় "ক্লায়েন্টকে ক্ষমতা দেয়", কিন্তু সেই ক্ষমতার দাম আছে। আগে থেকে ট্রেড‑অফগুলো জানা থাকলে সিদ্ধান্ত নেওয়া সহজ হয়—কখন GraphQL ভাল ফিট এবং কখন অতিরিক্ত জটিলতা।
বড় জয় হলো ফ্লেক্সিবল ডেটা ফেচিং: ক্লায়েন্ট ঠিক যে ফিল্ডগুলো চায় তা অনুরোধ করে, যা ওভার‑ফেচিং কমাতে পারে এবং UI পরিবর্তন দ্রুত করতে সাহায্য করে।
আরেকটি বড় সুবিধা হলো স্কিমা দ্বারা প্রদত্ত শক্তিশালী চুক্তি। স্কিমা টাইপ ও উপলব্ধ অপারেশনের একক সোর্স অফ ট্রুথ হয়ে ওঠে, যা সহযোগিতা ও টুলিং উন্নত করে।
টিমগুলো প্রায়ই দেখতে পায় ক্লায়েন্ট প্রোডাক্টিভিটি বাড়ে কারণ ফ্রন্ট‑এন্ড ডেভেলপাররা নতুন এন্ডপয়েন্টের জন্য অপেক্ষা না করেই ইটারেট করতে পারে, এবং Apollo Client মত টুল টাইপ জেনারেট করে ডেটা ফেচিং সহজ করে।
GraphQL‑এ ক্যাশিং জটিল হতে পারে। REST‑এ ক্যাশিং প্রায়ই "প্রতি URL" ভিত্তিক। GraphQL‑এ অনেক কোয়েরি একই এন্ডপয়েন্ট শেয়ার করে, তাই ক্যাশিং কোয়েরি আকৃতি, নরমালাইজড ক্যাশ এবং সাবধানে সার্ভার/ক্লায়েন্ট কনফিগারেশনের ওপর নির্ভর করে।
সার্ভার সাইডে পারফরম্যান্স পিটফলস আছে। একটি ছোট কোয়েরিও অনেক ব্যাকএন্ড কল ট্রিগার করতে পারে যদি রেজলভারগুলো ঠিকমতো ডিজাইন না করা হয় (বাচিং, N+1 এড়ানো, ব্যয়বহুল ফিল্ড নিয়ন্ত্রণ দরকার)।
একটি শেখার বাঁকও আছে: স্কিমা, রেজলভার ও ক্লায়েন্ট প্যাটার্নগুলো ঐসব টিমের জন্য অপরিচিত হতে পারে যারা এন্ডপয়েন্ট‑ভিত্তিক API-এ অভ্যস্ত।
কারণ ক্লায়েন্ট অনেক কিছু চাইতে পারে, GraphQL API-তে কোয়েরি ডেপ্থ ও কমপ্লেক্সিটি লিমিট প্রয়োগ করা উচিত যাতে অপব্যবহার বা দুর্ঘটনাজনিত "অতিবড়" অনুরোধ প্রতিরোধ করা যায়।
অথেন্টিকেশন ও অথরাইজেশন per‑field স্তরে প্রয়োগ করা উচিত, শুধুই রুট‑লেভেলে নয়, কারণ বিভিন্ন ফিল্ডে ভিন্ন এক্সেস নিয়ম থাকতে পারে।
অপারেশনালি, GraphQL‑কে বোঝা যায় এমন লগিং, ট্রেসিং ও মনিটরিং-এ বিনিয়োগ করুন: অপারেশন নাম, ভ্যারিয়েবল (সাবধানে), রেজলভার টাইমিং এবং এরর রেট ট্র্যাক করুন যাতে ধীর কোয়েরি ও রিগ্রেশন দ্রুত ধরে ফেলতে পারেন।
GraphQL এবং REST উভয়ই অ্যাপগুলোকে সার্ভারের সাথে কথা বলাতে সাহায্য করে, কিন্তু তারা সেই কথোপকথনকে ভিন্নভাবে গঠন করে।
REST হলো রিসোর্স‑ভিত্তিক। আপনি বিভিন্ন এন্ডপয়েন্ট (URL) কল করে ডেটা নেন—/users/123 বা /orders?userId=123 এর মতো। প্রতিটি এন্ডপয়েন্ট সার্ভার দ্বারা নির্ধারিত একটি নির্দিষ্ট ডেটা আকার ফেরত দেয়।
REST এছাড়াও HTTP সেমান্টিক্স ব্যবহার করে: GET/POST/PUT/DELETE, স্ট্যাটাস কোড, ও ক্যাশিং নিয়ম। সহজ CRUD বা ব্রাউজার/প্রক্সি ক্যাশের সাথে কাজ করার সময় REST আরো স্বাভাবিক মনে হতে পারে।
GraphQL হলো স্কিমা‑ভিত্তিক। বহু এন্ডপয়েন্টের বদলে সাধারণত একটি এন্ডপয়েন্ট থাকে, এবং ক্লায়েন্ট একটি কোয়েরি পাঠায় যে ঠিক কোন ফিল্ডগুলো চায়। সার্ভার ঐ রিকুয়েস্টকে স্কিমার বিরুদ্ধে ভ্যালিডেট করে এবং কোয়েরির সাথে মেলে এমন রেসপন্স দেয়।
এই "ক্লায়েন্ট‑চালিত সেলেকশন" কারণেই GraphQL ওভার‑ফেচিং ও আন্ডার‑ফেচিং কমাতে পারে, বিশেষ করে এমন UI স্ক্রিনগুলোর জন্য যেগুলো একাধিক সম্পর্কিত মডেল থেকে ডেটা চায়।
REST সাধারণত ভাল ফিট যখন:
অনেক টিম দুটোই মিশিয়ে ব্যবহার করে:
প্রায়োগিক প্রশ্নটি হলো “কোনটা ভালো নয়—কোনটা এই ব্যবহার‑কেসে কম জটিলতার সাথে মানায়?”
GraphQL API ডিজাইন করা সহজ হয় যখন আপনি এটিকে স্ক্রীন তৈরি করা লোকদের জন্য একটি প্রোডাক্ট হিসেবে বিবেচনা করেন, আপনার ডাটাবেসের প্রতিফলন হিসেবে নয়। ছোট করে শুরু করুন, বাস্তব ইউজ‑কেস দিয়ে ভ্যালিডেট করুন, এবং চাহিদা বাড়লে ধীরেই বাড়ান।
আপনার মূল স্ক্রিনগুলো তালিকাভুক্ত করুন (উদাহরণ: "Product list", "Product details", "Checkout")। প্রতিটি স্ক্রিনের জন্য ঠিক কোন ফিল্ড দরকার এবং কি ইন্টার্যাকশন হবে তা লিখে নিন।
এতে আপনি "গড কোয়েরি" এড়াতে পারবেন, ওভার‑ফেচিং কমবে, এবং যতখানে ফিল্টারিং, সোর্টিং ও পেজিনেশন দরকার তা স্পষ্ট হবে।
প্রথমে আপনার কোর টাইপগুলো সংজ্ঞায়িত করুন (উদাহরণ: User, Product, Order) এবং তাদের সম্পর্ক। তারপর যোগ করুন:
বিজনেস‑ল্যাঙ্গুয়েজ নাম ব্যবহার করুন ডাটাবেস নামের বদলে। “placeOrder” ইচ্ছা প্রকাশ করে “createOrderRecord”-এর তুলনায়।
নামকরণ একরকম রাখুন: একক আইটেমের জন্য singular (product), সংগ্রহের জন্য plural (products)। পেজিনেশনের জন্য সাধারণত একটি পছন্দ করুন:
প্রাথমিকভাবে সিদ্ধান্ত নিন কারণ তা আপনার API‑র রেসপন্স কাঠামো গঠন করে।
GraphQL স্কিমা সরাসরি বর্ণনা সমর্থন করে—ফিল্ড, আর্গুমেন্ট এবং এজ‑কেসগুলোর জন্য এগুলো ব্যবহার করুন। পরে ডকুমেন্টে কয়েকটি কপি‑পেস্ট করা উদাহরণ (পেজিনেশন ও সাধারণ এরর সিনারিও সহ) যোগ করুন। ভালোভাবে বর্ণিত স্কিমা ইন্ট্রোসপেকশন ও API‑এক্সপ্লোরারকে অনেক বেশি কাজে লাগায়।
GraphQL শুরু করা মানে কয়েকটি ভালো সমর্থিত টুল পছন্দ করা এবং একটি বিশ্বস্ত ওয়ার্কফ্লো সেটআপ করা। আপনাকে সবকিছু একসাথে গ্রহণ করতে হবে না—একটি কোয়েরি পুরো পথে কাজ করলেই শুরু করুন, তারপর বাড়ান।
স্ট্যাক ও কতটা "ব্যাটারি ইনক্লুডেড" চান তার ওপর ভিত্তি করে সার্ভার বেছে নিন:
একটি ব্যবহারিক প্রথম ধাপ: একটি ছোট স্কিমা (কয়েকটি টাইপ + একটি কোয়েরি) সংজ্ঞায়িত করুন, রেজলভার ইমপ্লিমেন্ট করুন, এবং একটি বাস্তব ডেটা সোর্সের সাথে কানেক্ট করুন (এমনকি যদি সেটা ইন-মেমোরি স্টাবই কেন না)।
যদি আপনি আইডিয়া থেকে ওয়ার্কিং API পর্যন্ত দ্রুত যেতে চান, Koder.ai মত প্ল্যাটফর্ম দ্রুত স্ক্যাফোল্ড করে সাহায্য করতে পারে—React ফ্রন্টএন্ড, Go + PostgreSQL ব্যাকএন্ড সহ এবং চ্যাটের মাধ্যমে স্কিমা/রেজলভার ইটারেট করার সুবিধা; তারপর কোড এক্সপোর্ট করে নেওয়া যায় যখন আপনি ইমপ্লিমেন্টেশন নিজের দায়িত্ব নিতে চান।
ফ্রন্টএন্ডে আপনার পছন্দ সাধারণত এই বিষয়ে নির্ভর করে যে আপনি কি ধার্মিক কনভেনশন চান কিংবা নমনীয়তা:
REST থেকে মাইগ্রেট করলে প্রথমে একটি স্ক্রিন বা ফিচারের জন্য GraphQL ব্যবহার করে শুরু করুন, বাকিটা REST রাখুন যতক্ষণ না নতুন পদ্ধতি প্রমাণ করে নিজের দক্ষতা।
আপনার স্কিমাকে API চুক্তি হিসেবে বিবেচনা করুন। উপকারী টেস্টিং স্তরসমূহ:
আপনার বোঝাপড়া বাড়াতে অব্যাহত রাখুন:
GraphQL হচ্ছে একটি কোয়েরি ল্যাংগুয়েজ এবং রনটাইম ফর এপিআই। ক্লায়েন্টরা একটি কোয়েরি পাঠায় যেখানে তারা ঠিক কোন ফিল্ডগুলো চায় তা বলে, আর সার্ভার এমন একটি JSON রেসপন্স দেয় যা সেই কাঠামোই অনুকরণ করে।
এটিকে সবচেয়ে সহজভাবে ভাবা যায় ক্লায়েন্ট ও এক বা একাধিক ডেটা সোর্সের (ডাটাবেস, REST সার্ভিস, থার্ড-পার্টি API, মাইক্রোসার্ভিস) মধ্যে একটি পরত হিসেবে।
GraphQL মূলত নিম্নোক্ত সমস্যা সমাধান করে:
ক্লায়েন্ট যখন নির্দিষ্ট ফিল্ড (এবং নেস্টেড ফিল্ড) অনুরোধ করে, তখন GraphQL অপ্রয়োজনীয় ডেটা ট্রান্সফার কমাতে এবং ক্লায়েন্ট কোড সরল করতে সাহায্য করে।
GraphQL নয়:
এটাকে একটি স্টোরেজ বা পারফরম্যান্স ম্যাজিক না বলে, একটি API চুক্তি ও এক্সিকিউশন ইঞ্জিন হিসেবে দেখুন।
অনেক GraphQL API একটি একক এন্ডপয়েন্ট (সাধারণত /graphql) দিয়ে প্রকাশ করে। বিভিন্ন URL-এর বদলে আপনি ওই একটি এন্ডপয়েন্টে ভিন্ন অপারেশন (কোয়েরি/মিউটেশন) পাঠান।
প্রায়োগিক দিক: ক্যাশিং ও অবজারভেবিলিটি সাধারণত অপারেশন নাম + ভ্যারিয়েবল অনুসারে নির্ধারিত হয়, URL দ্বারা নয়।
স্কিমা হচ্ছে API কনট্রাক্ট। এটি নির্ধারণ করে:
User, Post)User.name)User.posts)কারণ এটি , সার্ভার কোয়েরি এক্সিকিউট করার আগে ভ্যালিডেশন করে এবং স্পষ্ট ত্রুটি দিতে পারে যখন কোনো ফিল্ড উপস্থিত নেই।
GraphQL কোয়েরিগুলো হলো রিড অপারেশন। আপনি যে ফিল্ডগুলো চান সেগুলো নির্দিষ্ট করেন, আর রেসপন্স JSON সেই কোয়েরির স্ট্রাকচারের সাথে মেলে।
টিপস:
query GetUserWithPosts)।posts(limit: 2))।মিউটেশন হচ্ছে লেখার (write) অপারেশন—create/update/delete। সাধারণ প্যাটার্ন:
input অবজেক্ট পাঠায়ক্লায়েন্টের দ্রুত UI আপডেট, কেশ সামঞ্জস্য ও ফাইলে ত্রুটি হ্যান্ডলিং সহজ করার জন্য মিউটেশন সাধারণত ডেটা রিটার্ন করে (শুধু success: true নয়)।
রেজলভারগুলো হলো ফিল্ড-লেভেল ফাংশন যা বলে GraphQL কীভাবে প্রতিটি ফিল্ডের মান আনবে বা কম্পিউট করবে।
প্রায়ই রেজলভারগুলো:
অথরাইজেশন সাধারণত রেজলভার বা শেয়ার্ড মিডলওয়্যারে কার্যকর করা হয় কারণ রেজলভাররা জানে কে কী চাচ্ছে।
সহজভাবে N+1 প্যাটার্ন তৈরি করা সহজ (উদাহরণ: 100 ইউজারের জন্য প্রতিটি ইউজারের পোস্ট আলাদা আলাদা লোড করা)।
সাধারণ সমাধানগুলো:
রেজলভার টাইমিং মেপুন এবং একই রিকুয়েস্টে বারবার ডাউনস্ট্রীম কল হচ্ছে কিনা মনিটর করুন।
GraphQL একটি রেসপন্সে পাশাপাশি data এবং errors থাকতে পারে—কারণ কিছু ফিল্ড সফলভাবে রেজলভ হয় এবং কিছুতে ত্রুটি আসে (উদাহরণ: অনুমতি নেই, টাইমআউট)।
ভাল অনুশীলন:
message দিনextensions.code ব্যবহার করুন (যেমন FORBIDDEN, BAD_USER_INPUT)ক্লায়েন্টরা সিদ্ধান্ত নেবে কখন আংশিক ডেটা রেন্ডার করবে এবং কখন পুরো অপারেশনকে ব্যর্থ বলে মনে করবে।