১২ জুন, ২০২৫·8 মিনিট
ইউজার স্টোরি থেকে ডেটাবেস স্কিমা: AI-নির্দেশিত পদ্ধতি
ইউজার স্টোরি, সত্তা, এবং ওয়ার্কফ্লোকে কিভাবে পরিষ্কার ডেটাবেস স্কিমায় রূপান্তর করবেন এবং কীভাবে AI যুক্তিবাদ আপনাকে গ্যাপ ও নিয়ম পরীক্ষা করতে সাহায্য করতে পারে তা শিখুন।
ইউজার স্টোরি, সত্তা, এবং ওয়ার্কফ্লোকে কিভাবে পরিষ্কার ডেটাবেস স্কিমায় রূপান্তর করবেন এবং কীভাবে AI যুক্তিবাদ আপনাকে গ্যাপ ও নিয়ম পরীক্ষা করতে সাহায্য করতে পারে তা শিখুন।
একটি ডেটাবেস স্কিমা হলো আপনার অ্যাপ কীভাবে বিষয়গুলি মনে রাখবে তার পরিকল্পনা। ব্যবহারিকভাবে, এটি হল:
যখন স্কিমা বাস্তব কাজের সাথে মিলে যায়, তখন তা মানুষের করা কাজগুলো—create, review, approve, schedule, assign, cancel—প্রতিফলিত করে, সাদা বোর্ডে সুন্দর শোনা কথার বদলে।
ইউজার স্টোরি ও অ্যাকসেপ্টেন্স ক্রাইটেরিয়া বাস্তব প্রয়োজনগুলো সহজ ভাষায় বলে: কে কি করে, এবং “সম্পূর্ণ” মানে কি। যদি আপনি এগুলোকে উৎস হিসেবে ব্যবহার করেন, তাহলে স্কিমা গুরুত্বপূর্ণ বিবরণ মিস করার সম্ভাবনা কম (যেমন “আমাদের কে রিফান্ড অনুমোদন করেছে তা ট্র্যাক করতে হবে” বা “একটি বুকিং একাধিকবার reschedule করা যেতে পারে”)।
স্টোরি থেকে শুরু করলে স্কোপ সম্পর্কে সৎ থাকা সহজ হয়। যদি এটা স্টোরিতে (অথবা ওয়ার্কফ্লোতে) না থাকে, তবে এটিকে ঐচ্ছিক হিসেবে বিবেচনা করুন, না যে চুপচাপ জটিল মডেল তৈরি করবেন “কখনও লাগতে পারে” বলে।
AI আপনাকে দ্রুত করতে সাহায্য করতে পারে:
AI নির্ভরযোগ্যভাবে করতে পারে না:
AI-কে একটি শক্তিশালী সহকারী হিসেবে দেখুন, সিদ্ধান্ত-নির্ধারক হিসেবে নয়।
যদি আপনি সেই সহকারীকে গতিশীল করতে চান, একটি ভাইব-কোডিং প্ল্যাটফর্ম যেমন Koder.ai আপনাকে স্কিমা সিদ্ধান্ত থেকে কাজ করা React + Go + PostgreSQL অ্যাপে দ্রুত পৌঁছাতে সাহায্য করতে পারে—এবং আপনি মডেল, কনস্ট্রেইন্ট, ও মাইগ্রেশন কন্ট্রোলেই রাখতে পারবেন।
স্কিমা ডিজাইন একটি লুপ: ড্রাফট → স্টোরির বিরুদ্ধে টেস্ট → মিসিং ডেটা খোঁজা → পরিমার্জন। লক্ষ্যটি প্রথমবারে নিখুঁত আউটপুট নয়; বরং এমন একটি মডেল যেটি আপনি প্রতিটি ইউজার স্টোরির সঙ্গে ট্রেস করতে পারবেন এবং আত্মবিশ্বাসের সঙ্গে বলতে পারবেন: “হ্যাঁ, আমরা এই ওয়ার্কফ্লোতে যা কিছু দরকার তা স্টোর করতে পারি—এবং প্রতিটি টেবিল কেন আছে সেটা ব্যাখ্যা করতে পারি।”
রিকোয়ারমেন্টগুলো টেবিলে রূপান্তর করার আগে, আপনি কী মডেল করছেন সেটা স্পষ্ট করুন। একটি ভালো স্কিমা খুব কমই শূন্য পেজ থেকে শুরু করে—এটি মানুষ যে কংক্রিট কাজগুলো করে এবং পরে যে প্রমাণ লাগবে (স্ক্রীন, আউটপুট, এজ কেস) থেকে শুরু হয়।
ইউজার স্টোরি শিরোনাম হলেও, একজোট করুন:
যদি আপনি AI ব্যবহার করেন, এই ইনপুটগুলো মডেলকে ভিত্তি দেয়। AI দ্রুত সত্তা ও ফিল্ড প্রস্তাব করতে পারে, কিন্তু বাস্তব আর্টিফ্যাক্ট ছাড়া এটি এমন স্ট্রাকচার উদ্ভাবন করতে পারে যা আপনার প্রোডাক্টের সাথে মেলে না।
অ্যাকসেপ্টেন্স ক্রাইটেরিয়াগুলোই প্রায়শই সবচেয়ে গুরুত্বপূর্ণ ডেটাবেস নিয়ম রাখে, যদিও সেগুলো সরাসরি ডেটা উল্লেখ না করে। এরকম বিবৃতি খুঁজুন:
অস্পষ্ট স্টোরি ("As a user, I can manage projects") অনেক সত্তা ও ওয়ার্কফ্লো লুকিয়ে রাখতে পারে। অন্য একটি সাধারণ গ্যাপ হলো ক্যান্সেলেশন, রিট্রাই, পার্শিয়াল রিফান্ড, বা রিএসাইনমেন্টের মতো এজ কেসগুলো অনুপস্থিত থাকা।
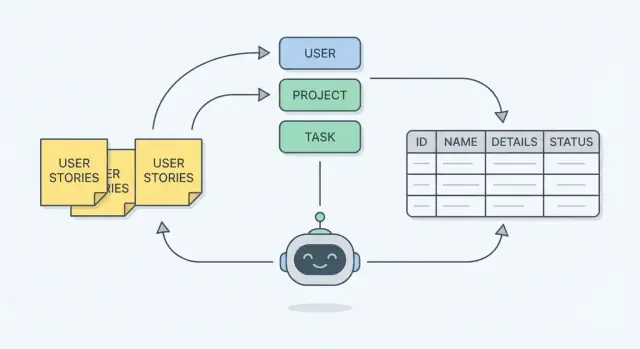
টেবিল বা ডায়াগ্রাম ভাবার আগে, ইউজার স্টোরিগুলো পড়ে নাউনগুলো হাইলাইট করুন। রিকোয়ারমেন্ট লেখায় নাউনগুলো প্রায়শই সেই “বস্তু” নির্দেশ করে যেগুলো সিস্টেমকে মনে রাখতে হবে—এগুলো সাধারণত আপনার স্কিমায় সত্তা হয়।
একটি দ্রুত মানসিক মডেল: নাউনগুলো সত্তায় পরিণত হয়, আর ভার্বগুলো অ্যাকশন বা ওয়ার্কফ্লো নির্দেশ করে। যদি স্টোরিটা বলে “A manager assigns a technician to a job,” সম্ভাব্য সত্তাগুলো হল manager, technician, এবং job—আর "assigns" একটি সম্পর্ক মডেল করার ইঙ্গিত দেয়।
প্রতিটি নাউন আলাদা টেবিলের যোগ্য নয়। একটি নাউন শক্ত প্রার্থী যখন:
যদি একটি নাউন কেবল একবার আসে, বা অন্য কিছুকে বর্ণনা করে ("red button", "Friday"), তাহলে সম্ভবত এটি সত্তা নয়।
সব বিস্তারিত আলাদা টেবিলে পরিণত করার ভুল করবেন না। এই নীতিটি অনুসরণ করুন:
Customer.phone_number)।দুটি ক্লাসিক উদাহরণ:
AI স্টোরি স্ক্যান করে দ্রুত প্রার্থী নাউনের তালিকা গ্রুপ করে দিতে পারে (লোক, ওয়ার্ক আইটেম, ডকুমেন্ট, লোকেশন ইত্যাদি)। একটি ভালো প্রম্পট হতে পারে: “Extract nouns that represent data we must store, and group duplicates/synonyms.”
আউটপুটকে শুরু হিসেবে নিন, উত্তর হিসেবে নয়। ফলো-আপ জিজ্ঞাসা করুন যেমন:
ধাপ 1-এর লক্ষ্য একটি সংক্ষিপ্ত, পরিষ্কার সত্তার তালিকা যা আপনি বাস্তব স্টোরি দিয়ে রক্ষা করতে পারবেন।
একবার আপনি সত্তাগুলো নামকরণ করলে (যেমন Order, Customer, Ticket), পরবর্তী কাজ হল পরে যা প্রয়োজন তা ক্যাপচার করা। ডেটাবেসে সেই ডিটেইলগুলো ফিল্ড (বা অ্যাট্রিবিউট)—আপনার সিস্টেম যে রিমাইন্ডারগুলো ভুলে যেতে পারবেনা সেগুলো।
ইউজার স্টোরি দিয়ে শুরু করে, তারপর অ্যাকসেপ্টেন্স ক্রাইটেরিয়াকে একটি চেকলিস্ট হিসেবে পড়ুন কোনগুলো অবশ্যই স্টোর করা দরকার।
যদি একটি রিকোয়ারমেন্ট বলে “Users can filter orders by delivery date,” তাহলে delivery_date অপশনাল নয়—এটি একটি ফিল্ড হিসেবে থাকতে হবে (অথবা অন্য সংরক্ষিত ডেটা থেকে নির্ভরযোগ্যভাবে ডেরাইভ করা যাবে)। যদি লেখা থাকে “Show who approved the request and when,” আপনাকে সম্ভবত approved_by এবং approved_at রাখতে হবে।
একটি বাস্তব পরীক্ষাঃ একজন কেউ এইটা ডিসপ্লে, সার্চ, সোর্ট, অডিট, বা হিসাব করার জন্য প্রয়োজন হবে? যদি হ্যাঁ, তাহলে হয়ত এটা একটি ফিল্ড।
Customers-এ রাখুন এবং অন্য জায়গায় রেফার করুন।অনেক স্টোরিতে “status”, “type”, বা “priority” মতো শব্দ থাকে। এগুলোকে কন্ট্রোলড ভোকাবুলারি হিসেবে যান—অপরিমিত মানের একটি সীমিত সেট।
যদি সেট ছোট ও স্থিতিশীল হয়, একটি enum-স্টাইল ফিল্ড কাজ করবে। যদি এটা বাড়তে পারে, লেবেল দরকার, বা পারমিশন-ভিত্তিক (উদাহরণ: অ্যাডমিন-ম্যানেজড ক্যাটাগরি), তাহলে আলাদা লুকআপ টেবিল (যেমন status_codes) ব্যবহার করুন এবং রেফারেন্স রাখুন।
এভাবেই স্টোরিগুলো এমন ফিল্ডে রূপান্তর পায় যা বিশ্বাসযোগ্য—সার্চযোগ্য, রিপোর্টেবল, এবং ভুল প্রবেশ করা কঠিন।
একবার আপনি সত্তাগুলো (User, Order, Invoice, Comment, ইত্যাদি) এবং তাদের ফিল্ডগুলো ড্রাফট করে ফেললে, পরবর্তী ধাপ হলো সেগুলোকে সংযুক্ত করা। সম্পর্কগুলো হলো "কীভাবে এই জিনিসগুলো পরস্পরের সাথে মিথস্ক্রিয়া করে"—এগুলো আপনার স্টোরিগুলোতে ইঙ্গিত থাকে।
One-to-one (1:1) মানে “একটি বস্তুর ঠিক একটি আরেকটি বস্তু আছে।”
User ↔ Profile (সাধারণত একত্রিত করা যায় যদি আলাদা রাখার কারণ না থাকে)।One-to-many (1:N) মানে “একটি জিনিসের অনেকগুলো আরেকটি জিনিস থাকতে পারে।” এটি সবচেয়ে সাধারণ।
User → Order (টেবিলে user_id রাখুন)।Many-to-many (M:N) মানে “অনেকগুলো জিনিস অনেকগুলো জিনিশের সাথে সম্পর্কিত।” এটি একটি অতিরিক্ত টেবিল প্রয়োজন করে।
ডেটাবেসে Order-এর মধ্যে “প্রোডাক্ট আইডির তালিকা” নীচে রাখার বদলে একটি জয়েন টেবিল ব্যবহার করুন।
উদাহরণ:
OrderProductOrderItem (জয়েন টেবিল)OrderItem সাধারণত রাখে:
order_idproduct_idquantity, unit_price, discountমনে রাখবেন স্টোরির বিস্তারিত (যেমন “quantity”) প্রায়শই সম্পর্কের উপর থাকা উচিত, দুই সত্তার উপর নয়।
স্টোরিও আপনাকে বলে সম্পর্কটি অবশ্যক নাকি মাঝে মাঝে অনুপস্থিত।
Order-এর user_id থাকা উচিত (খালি থাকা উচিত নয়)।phone ফাঁকা থাকতে পারে।shipping_address_id ডিজিটাল অর্ডারের জন্য ফাঁকা হতে পারে।দ্রুত চেক: যদি স্টোরি বলে যে রেকর্ডটা তৈরি করা যাবে না সেই লিঙ্ক ছাড়া, তবে এটি আবশ্যক হিসেবে বিবেচনা করুন। যদি স্টোরি বলে “can”, “may”, বা ব্যতিক্রম দেয়, তবে সেটি ঐচ্ছিক।
প্রতিটি স্টোরি পড়ে এটাকে সহজ জুড়ি বাক্যে লিখুন:
User 1:N CommentComment N:1 Userপ্রতিটি ইন্টারঅ্যাকশনের জন্য এটা করুন। শেষের দিকে আপনার কাছে এমন একটি সংযুক্ত মডেল থাকবে যা কাজটি কীভাবে হয় সেটা প্রতিফলিত করে—ER টুল খুলার আগেই।
ইউজার স্টোরি বলে আপনি কি চান। ওয়ার্কফ্লো দেখায় কাজ কিভাবে ধাপে ধাপে এগোয়। ওয়ার্কফ্লোকে ডেটায় ট্রান্সলেট করলে প্রায়শই “আমরা যে জিনিসটি স্টোর করা ভুলে গিয়েছিলাম” সমস্যা আগে থেকেই ধরা পড়ে—বিল্ড করার আগে।
ওয়ার্কফ্লোকে অ্যাকশন ও স্টেট চেইন হিসেবে লিখুন। উদাহরণ:
এই বোল্ড শব্দগুলো প্রায়ই একটি status ফিল্ড (বা ছোট "state" টেবিল) হয়ে ওঠে, স্পষ্ট অনুমোদিত মানগুলোর সঙ্গে।
প্রতিটি ধাপ চালিয়ে যান এবং প্রশ্ন করুন: “পরে কী জানা লাগবে?” ওয়ার্কফ্লো সাধারণত এগুলো আবিষ্কার করে:
submitted_at, approved_at, completed_atcreated_by, assigned_to, approved_byrejection_reason, approval_notesequenceযদি ওয়ার্কফ্লোতে অপেক্ষা, এসকেলেশন, বা হ্যান্ডঅফ থাকে, সাধারণত আপনাকে অন্তত একটি টাইমস্ট্যাম্প এবং একটি “এখন কে এটি ধরে আছে” ফিল্ড লাগবে।
কিছু ওয়ার্কফ্লো স্টেপ কেবল ফিল্ড নয়—এগুলো আলাদা ডেটা স্ট্রাকচার:
AI-কে দিন: (1) ইউজার স্টোরি ও অ্যাকসেপ্টেন্স ক্রাইটেরিয়া, এবং (2) ওয়ার্কফ্লো ধাপগুলো। জিজ্ঞাসা করুন প্রতিটি ধাপের জন্য কোন ডেটা লাগবে (স্টেট, অভিনেতা, টাইমস্ট্যাম্প, আউটপুট) এবং কোন রিকোয়ারমেন্ট বর্তমান ফিল্ড/টেবিল দিয়ে সাপোর্ট হচ্ছে না—AI এগুলো হাইলাইট করতে পারে।
Koder.ai-এর মতো প্ল্যাটফর্মে এই “গ্যাপ চেক” প্রাকটিক্যাল হয়ে ওঠে কারণ আপনি দ্রুত ইটারেট করতে পারেন: স্কিমা অনুমান ঠিক করুন, স্ক্যাফোল্ড রিজেনারেট করুন, এবং দীর্ঘ ম্যানুয়াল বয়লারপ্লেট ছাড়াই আগিয়ে যান।
ইউজার স্টোরি থেকে টেবিলে পরিণত করার সময়, আপনি শুধু ফিল্ডগুলোর তালিকা বানাচ্ছেন না—আপনি সিদ্ধান্ত নিচ্ছেন কিভাবে ডেটা সময়ের সাথে সনাক্তযোগ্য ও সামঞ্জস্যপূর্ণ থাকবে।
একটি primary key একটি রেকর্ডকে অনন্যভাবে সনাক্ত করে—একটি স্থায়ী ID কার্ডের মত।
কেন প্রতিটি রো-র লাগবে: স্টোরিগুলো আপডেট, রেফারেন্স, ও ইতিহাস নির্দেশ করে। যদি স্টোরি বলে “Support can view an order and issue a refund,” আপনাকে একটি স্থিতিশীল উপায় থাকা দরকার সেই order-কে পয়েন্ট করার জন্য—গ্রাহক ইমেইল বদলালেও বা ঠিকানা এডিট হলে সেটিকে ঠিক করে রাখতে।
প্রায়শই এটি একটি অভ্যন্তরীণ id (নম্বার বা UUID) যা কখনও বদले না।
একটি foreign key হল কিভাবে একটি টেবিল সুরক্ষিতভাবে আরেকটাকে পয়েন্ট করে। যদি orders.customer_id customers.id-কে রেফার করে, ডেটাবেস নিশ্চিত করতে পারে প্রতিটি অর্ডার বাস্তব গ্রাহকের সাথে যুক্ত।
এটি সেই স্টোরিগুলোর সাথে মেলে যেগুলো বলে “As a user, I can see my invoices.” ইনভয়েসটি ভাসমান নয়; এটি একজন গ্রাহকের সাথে সংযুক্ত।
ইউজার স্টোরি প্রায়ই লুকানো ইউনিকনেস রুল রাখে:
এই নিয়মগুলো ডুপ্লিকেটগুলি রোধ করে যা পরে ডাটা-বাগ তৈরি করে।
ইনডেক্সগুলো সার্চ দ্রুত করে (যেমন “find customer by email” বা “list orders by customer”)। প্রথমে সেই ইন্ডেক্সগুলো দিন যেগুলো আপনার সবচেয়ে সাধারণ কুয়েরি ও ইউনিকনেস রুলের সাথে মেলে।
কি পিছিয়ে রাখবেন: বিরল রিপোর্ট বা অনুমানীয় ফিল্টারের জন্য ভারী ইনডেক্সিং। স্কিমা নেবার পরে বাস্তব ব্যবহার ও স্লো কুয়েরি প্রমাণ দেখেই অপ্টিমাইজ করুন।
নরমালাইজেশনের একটি সহজ লক্ষ্য: বিরোধী ডুপ্লিকেট প্রতিরোধ করা। একই তথ্য যদি দুই জায়গায় সংরক্ষিত থাকে, একজন কিংবা পরেই তা ভিন্ন হয়ে যাবে (দুই বানান, দুই দাম, দুই “কারেন্ট” ঠিকানা)। একটি নরমালাইজড স্কিমা প্রতিটি তথ্য একবার রাখে, তারপর রেফার করে।
1) পুনরাবৃত্ত গ্রুপ থেকে সতর্ক থাকুন
যদি আপনি Phone1, Phone2, Phone3 বা ItemA, ItemB, ItemC টাইপ প্যাটার্ন দেখেন, সেটা আলাদা টেবিলের জন্য ইঙ্গিত (যেমন CustomerPhones, OrderItems)।
2) একই নাম/বিবরণ একাধিক টেবিলে কপি করবেন না
যদি CustomerName Orders, Invoices, এবং Shipments-এ হয়, আপনি সত্যের একাধিক উৎস তৈরি করেছেন। গ্রাহক বিবরণ Customers-এ রাখুন এবং কেবল customer_id অন্যত্র রাখুন।
3) একই জিনিসের জন্য একাধিক কলাম এড়ান
যেমন billing_address, shipping_address, home_address—এগুলো ঠিক থাকবেই যদি তারা বাস্তবেই আলাদা ধারণা। কিন্তু যদি আপনি "ধরুন অনেক ঠিকানা টাইপ" মডেল করেন, তাহলে একটি Addresses টেবিল ব্যবহার করুন যার মধ্যে type ফিল্ড আছে।
4) লুকআপগুলোকে ফ্রি টেক্সট থেকে আলাদা করুন
যদি ইউজার একটি পরিচিত সেট থেকে পছন্দ করে (status, category, role), তাকে কনসিস্টেন্টভাবে মডেল করুন: enum বা লুকআপ টেবিল। এটা “Pending” বনাম “pending” বনাম “PENDING” সমস্যা রোধ করে।
5) পরীক্ষা করুন প্রতিটি নন-ID ফিল্ড ঠিক কী-র উপর নির্ভরশীল
একটি দ্রুত আবেগগত চেক: টেবিলে যদি একটি কলাম টেবিলের মূল সত্তা ব্যতীত অন্য কিছু বর্ণনা করে, সম্ভবত এটি অন্যত্র থাকা উচিত। উদাহরণ: Orders-এ product_price রাখা উচিত নয় যদি না এটা “অর্ডারের সময়ের মূল্য” (ইতিহাস) বোঝায়।
কখনও কখনও আপনি ইচ্ছাকৃতভাবে ডুপ্লিকেট রাখেন:
কী গুরুত্বপূর্ণ: এটি ইচ্ছাকৃত করা—কোন স্থানটি সত্যের উৎস এবং কপি কিভাবে আপডেট হবে তা ডকুমেন্ট করুন।
AI সন্দেহজনক ডুপ্লিকেশন (পুনরাবৃত্ত কলাম, অনুরূপ ফিল্ড নাম, অসঙ্গত “status” ফিল্ড) ফ্ল্যাগ করতে পারে এবং টেবিলে ভাগ করার পরামর্শ দিতে পারে। মানুষ এখনও ট্রেড-অফগুলো (সরলতা বনাম নমনীয়তা বনাম পারফরম্যান্স) পণ্য কিভাবে ব্যবহার হবে তার ওপর ভিত্তি করে নির্ধারণ করে।
একটি ব্যবহারযোগ্য নিয়ম: যে তথ্য আপনি বিশ্বাসযোগ্যভাবে পরে পুনরায় তৈরি করতে পারবেন না, তা রাখুন; বাকিগুলো ক্যালকুলেট করুন।
সংরক্ষিত ডেটা হলো সত্যের উৎস: পৃথক লাইন আইটেম, টাইমস্ট্যাম্প, স্ট্যাটাস পরিবর্তন, কে কি করেছে। ক্যালকুলেটেড ডেটা হলো সেই সত্যগুলোর থেকে উৎপন্ন: টোটাল, কাউন্টার, is overdue-এর মতো ফ্ল্যাগ, এবং রোল-আপস।
যদি দুটি মান একই অ্যান্ডারলাইং ফ্যাক্ট থেকে হিসাব করা যায়, তাহলে ফ্যাক্টগুলো স্টোর করুন এবং বাকি ক্যালকুলেট করুন—অন্যথায় বিরোধ সৃষ্টি হবে।
ডেরাইভড মানগুলো ইনপুট বদলালে বদলে যায়। যদি আপনি ইনপুট ও ডেরাইভড ফলাফল দুটোই রাখেন, তখন সেগুলোকে সব ওয়ার্কফ্লো ও এজ কেসে সিঙ্ক রাখতে হবে (এডিট, রিফান্ড, পারশিয়াল শিপমেন্ট, ব্যাকডেটেড চেঞ্জ)। একবার একটি আপডেট বাদ গেলে ডাটাবেস ভিন্ন গল্প বলা শুরু করে।
উদাহরণ: order_total স্টোর করা যখন order_items-ও আছে। কেউ quantity বদলে দিলে বা ডিসকাউন্ট দিলে এবং টোটাল আপডেট না হলে ফাইনান্স ও কার্ট আলাদা সংখ্যা দেখবে।
ওয়ার্কফ্লো আপনাকে বলে কখন ইতিহাসগত সত্য দরকার, শুধু “বর্তমান সত্য” নয়। যদি ইউজারদের জানতে হবে কিভাবে মান তত্ক্ষণিক সময়ে ছিল, তাহলে একটি স্ন্যাপশট স্টোর করুন।
একটি অর্ডারের জন্য আপনি রাখতে পারেন:
order_total (স্ন্যাপশট), কারণ ট্যাক্স, ডিসকাউন্ট, ও প্রাইসিং রুল পরে বদলাতে পারেইনভেন্ট-ভিত্তিক ডেটার জন্য (যেমন লগইন), last_login_at-এর মত ইভেন্ট টাইমস্ট্যাম্প স্টোর করুন। “গত ৩০ দিনে সক্রিয়?” টাইপ ক্যালকুলেটেড রাখুন।
চলুন একটি পরিচিত সাপোর্ট টিকিট অ্যাপ নিই। আমরা পাঁচটি ইউজার স্টোরি থেকে একটি সহজ ER মডেলে যাব (সত্তা + ফিল্ড + সম্পর্ক), তারপর একটি ওয়ার্কফ্লো দিয়ে চেক করব।
এই নাউনের থেকে আমরা মূল সত্তাগুলো পাই:
আগে (সাধারণ ভুল): Ticket-এ assignee_id আছে, কিন্তু আমরা নিশ্চিত করা ভুলে গিয়েছি যে কেবলমাত্র agent-রাই assignee হতে পারবে।
পরে: AI এটাকে ফ্ল্যাগ করে এবং আপনি একটি ব্যবহারিক নিয়ম যোগ করেন: assignee অবশ্যই role = “agent” থাকা উচিত (স্ট্যাক অনুযায়ী অ্যাপ্লিকেশন ভ্যালিডেশন বা ডেটাবেস কনস্ট্রেইন্ট/পলিসি দ্বারা ইমপ্লিমেন্ট করা যেতে পারে)। এটা “কাস্টমারকে অ্যাসাইন করা” ডেটা বাধা দেয় যা পরে রিপোর্ট ভাঙাবে।
কোনো স্কিমা “ডন” তখনই যখন প্রতিটি ইউজার স্টোরি এমনভাবে ডাটাবেস দিয়ে উত্তরযোগ্য হয় যেটা আপনি প্রতিটি কেসে নির্ভরযোগ্যভাবে করতে পারেন। সবচেয়ে সরল যাচাইকরণ ধাপ হল প্রতিটি স্টোরি নিন এবং জিজ্ঞাসা করুন: “আমরা কি এই প্রশ্নটি ডাটাবেস থেকে নির্ভুলভাবে, প্রতিটি কেসে উত্তর করতে পারি?” যদি উত্তর “হয়ত” হয়, আপনার মডেলে গ্যাপ আছে।
প্রতিটি স্টোরি এমন প্রশ্নে রিরাইট করুন যা একটি রিপোর্ট, স্ক্রীন, বা API জিজ্ঞাসা করবে। উদাহরণ:
যদি আপনি একটি স্টোরিকে স্পষ্ট প্রশ্নে রূপান্তর করতে না পারেন, স্টোরিটি অস্পষ্ট। যদি রূপান্তর করা যায়—কিন্তু আপনার স্কিমা দিয়ে উত্তর করা না যায়—তাহলে ফিল্ড, সম্পর্ক, স্ট্যাটাস/ইভেন্ট, বা কনস্ট্রেইন্ট মিসিং।
প্রতি কী টেবিলে ছোট ডেটাসেট (5–20 সারি) তৈরি করুন যা সাধারণ ও অদ্ভুত কেস (ডুপ্লিকেট, মিসিং ভ্যালু, ক্যান্সেলেশন) অন্তর্ভুক্ত করে। তারপর সেই ডেটা নিয়ে স্টোরিগুলো “প্লে থ্রু” করুন। আপনি দ্রুতই এমন সমস্যা দেখতে পাবেন যেমন “আমাদের নেই যেভাবে বলা আছে ওই সময়ে কোন ঠিকানা ব্যবহৃত হয়েছিল তা জানা” অথবা “আমাদের কোথাও নেই যিনি অনুমোদন করেছিলেন তা স্টোর করার জন্য।”
AI-কে বলুন প্রতিটি স্টোরির জন্য ভ্যালিডেশন প্রশ্ন জেনারেট করতে (এজ কেস ও ডিলিশন সিনারিওসহ), এবং প্রতিটি প্রশ্নের উত্তর দিতে কোন ডেটা লাগবে। তারপর সেই তালিকাকে আপনার স্কিমার সাথে তুলনা করুন: কোনো মেল না হলে সেটা একটি স্পষ্ট অ্যাকশন আইটেম।
AI ডেটা মডেলিং দ্রুত করতে পারে, কিন্তু এটি একই সঙ্গে সংবেদনশীল তথ্য ফাঁসের ঝুঁকি বা ভুল অনুমান হার্ড-কোড করার ঝুঁকি বাড়ায়। এটাকে দ্রুত সহকারী হিসেবে ব্যবহার করুন—উপকারী, কিন্তু গার্ডরেইল দরকার।
মডেল করার জন্য পর্যাপ্ত বাস্তবসম্মত কিন্তু নিরাপদ ইনপুট শেয়ার করুন:
invoice_total: 129.50, status: "paid")এড়িয়ে চলুন এমন কিছু যা ব্যক্তিকে শনাক্ত করে বা কনফিডেনশিয়াল অপারেশন ফাঁস করে:
যদি বাস্তবসম্মততা দরকার হয়, সিন্থেটিক নমুনা জেনারেট করুন—কখনও প্রোডাকশন সারি কপি করবেন না।
স্কিমা সবচেয়ে বেশিই তখন ব্যর্থ হয় যখন “সবারই আলাদা ধারণা” থাকে। আপনার ER মডেল (বা একই রিপো) পাশে ছোট একটি সিদ্ধান্ত লগ রাখুন:
এতে AI আউটপুট টিম জ্ঞানে পরিণত হয়, একক-বারের নিকাশ নয়।
আপনার স্কিমা স্টোরিগুলোর সঙ্গে উন্নত হবে। নিরাপদ রাখুন:
যদি আপনি Koder.ai-এর মতো প্ল্যাটফর্ম ব্যবহার করেন, স্কিমা চেঞ্জ ইটারেট করার সময় স্ন্যাপশট ও রোলব্যাকের মত গার্ডরেইল ব্যবহার করুন, এবং দরকারে সোর্স কোড এক্সপোর্ট করুন।
স্টোরি থেকে শুরু করে এমন নাউনগুলো হাইলাইট করুন যেগুলো আপনার সিস্টেমকে মনে রাখতে হবে (যেমন Ticket, User, Category)।
একটি নাউনকে সত্তায় পরিণত করুন যখন:
একটি সংক্ষিপ্ত তালিকা রাখুন যা আপনি নির্দিষ্ট স্টোরি বাক্যাংশ দিয়ে ব্যাখ্যা করতে পারবেন।
“অ্যাট্রিবিউট বনাম সত্তা” পরীক্ষা ব্যবহার করুন:
customer.phone_number).একটি সহজ ইঙ্গিত: যদি কখনো আপনার কাছে “অনেকগুলো” দরকার হবে, সম্ভবত আলাদা টেবিল দরকার।
এগ্রেসপ্টেন্স ক্রাইটেরিয়া-কে একটি স্টোরেজ চেকলিস্ট হিসেবে দেখুন। যদি কোনো রিকোয়ারমেন্ট বলে আপনি কিছু ফিল্টার/সার্ট/ডিসপ্লে/অডিট করবেন, তবে আপনাকে তা স্টোর করতে হবে (অথবা বিশ্বাসযোগ্যভাবে বের করতে সক্ষম হতে হবে)।
উদাহরণ:
approved_by, approved_atস্টোরি বাক্যগুলোকে রিলেশনশিপ বাক্যে রিরাইট করুন:
customer_id রাখুন, উদাহরণ: orders.customer_id)order_items)যদি সম্পর্কের নিজের ডেটা থাকে (quantity, price, role), সেই ডেটা জয়েন টেবিলে রাখুন।
M:N-কে জয়েন টেবিলে মডেল করুন যা दोनों ফরেন কীস সহ সম্পর্ক-নির্দিষ্ট ফিল্ডগুলো রাখে।
সাধারণ প্যাটার্ন:
ordersproductsওয়ার্কফ্লো ধাপে ধাপে চালিয়ে যান এবং জিজ্ঞেস করুন: “ভবিষ্যতে এটি প্রমাণ করার জন্য আমাদের কী জানতেই হবে?”
সাধারণ যোগ:
submitted_at, closed_atপ্রথমে নিচেরগুলো যোগ করুন:
id)orders.customer_id → customers.id)তারপর আপনার সবচেয়ে সাধারণ লুকআপগুলোর জন্য ইন্ডেক্স দিন (যেমন , , )। আপাতত স্পেকুলেটিভ ইন্ডেক্সিং পিছিয়ে রাখুন—বাস্তব কুয়েরি প্যাটার্ন দেখে অপ্টিমাইজ করুন।
দ্রুত কনসিস্টেন্সি চেক চালান:
Phone1/Phone2 মত প্যাটার্ন দেখেন, একটি চাইল্ড টেবিলে ভাগ করুন।পারফরম্যান্স/রিপোর্টিং/অডিট স্ন্যাপশটের মতো স্পষ্ট কারণ ছাড়া ওভার-নরমালাইজ করার ঝুঁকি নেই।
যেসব তথ্য আপনি পুনরায় নির্ভরযোগ্যভাবে পুনরায় তৈরি করতে পারবেন না সেগুলো স্টোর করুন; বাকিগুলো হিসাব করে দেখান।
স্টোর করা ভাল:
ক্যালকুলেট করা ভাল:
যদি আপনি ডেরাইভড ভ্যালু যেমন স্টোর করেন, কিভাবে সেগুলো সিঙ্ক থাকবে তা স্পষ্ট করে নিন এবং এজ কেস টেস্ট করুন (রিফান্ড, এডিট, পারশিয়াল শিপমেন্ট)।
AI-কে ড্রাফট তৈরিতে ব্যবহার করুন, তারপর আপনার আর্টিফ্যাক্টগুলোর বিরুদ্ধে যাচাই করুন।
প্রাকটিকাল প্রম্পট উদাহরণ:
গার্ডরেইলস:
delivery_dateemail-এ ইউনিক কনস্ট্রেন্ট/ইন্ডেক্সorder_items (রাখে order_id, product_id, quantity, unit_price)একক কলামে “ID-এর তালিকা” স্টোর করা থেকে বিরত থাকুন—কোয়েরি, আপডেট, এবং ইন্টিগ্রিটি বজায় রাখা সমস্যা করে দেয়।
created_by, assigned_to, closed_byrejection_reasonযদি জানতে চান “কে কখন কি বদলে ফেলেছে”, একটি ইভেন্ট/অডিট টেবিল যোগ করুন—একটি একটিমাত্র ফিল্ড ওভাররাইট করার বদলে।
emailcustomer_idstatus + created_atorder_total