০৭ নভে, ২০২৫·7 মিনিট
জেফরি হিন্টনের নিউরাল নেটওয়ার্ক সাফল্য — সহজ ব্যাখ্যা
ব্যাকপ্রপ ও বোল্টজমান মেশিন থেকে গভীর নেট এবং আলেক্সনেট—জেফরি হিন্টনের মূল ধারণাগুলো ও সেগুলো কিভাবে আধুনিক এআই গঠনে ভূমিকা রেখেছে, সহজ ভাষায়।
ব্যাকপ্রপ ও বোল্টজমান মেশিন থেকে গভীর নেট এবং আলেক্সনেট—জেফরি হিন্টনের মূল ধারণাগুলো ও সেগুলো কিভাবে আধুনিক এআই গঠনে ভূমিকা রেখেছে, সহজ ভাষায়।
এই গাইডটি কৌতুহলী, অ-প্রযুক্তিগত পাঠকদের জন্য, যারা বারবার শুনছেন “নিউরাল নেটওয়ার্ক সবই বদলে দিয়েছে” এবং আসলে সেটাই কী বোঝায়—সেটি ক্যালকুলাস বা প্রোগ্রামিং ছাড়াই—একটি পরিষ্কার, মজবুত ব্যাখ্যা চাচ্ছেন।
আপনি জেফরি হিন্টন যে ধারণাগুলো এগিয়ে নিয়ে গেছেন সেগুলোর সাধারণ-ভাষায় সফর পাবেন—কেন সেগুলো তখন গুরুত্বপূর্ণ ছিল এবং কিভাবে সেগুলো আজকের এআই টুলগুলোর সঙ্গে সম্পর্কিত। এটিকে ভাবুন এমন এক গল্প হিসেবে: কিভাবে কম্পিউটারকে উদাহরণ থেকে শেখিয়ে শব্দ, ছবি, শব্দের প্যাটার্ন চিনতে শেখানো যায়।
হিন্টন “এআই আবিষ্কার” করলেন না, এবং একাই আধুনিক মেশিন লার্নিং তৈরি করেননি। তার গুরুত্ব হলো তিনি বারবার নিউরাল নেটওয়ার্কগুলোকে প্রায়োগিকভাবে কার্যকর করতে সাহায্য করেছেন, এমন সময় অনেক গবেষক এগুলোকে পুরোনো উপায় মনে করতেন। তিনি মূল ধারণা, পরীক্ষণ এবং এমন একটি গবেষণা-সংস্কৃতিতে অবদান রেখেছেন যা শিক্ষিত প্রতিনিধিত্ব (ইন্টারনাল দরকারী ফিচার) কে কেন্দ্রীয় সমস্যা হিসেবে ধরেছে—হাত-নির্মিত নিয়ম লেখার বদলে।
পরবর্তী অংশগুলোতে আমরা খুলে বলব:
এই লেখায়, সাফল্য বলতে এমন একটা পরিবর্তন বোঝানো হয়েছে যা নিউরাল নেটওয়ার্ককে বেশি ব্যবহারযোগ্য করেছে: তারা বেশি নির্ভরযোগ্যভাবে ট্রেন হয়, ভালো ফিচার শেখে, নতুন ডেটায় সঠিকভাবে সাধারণীকরণ করে, বা বড় কাজগুলোতে স্কেল করে। এটা একক ঝলমলে ডেমোর চেয়ে বেশি—এটি একটি ধারণাকে নির্ভরযোগ্য পদ্ধতিতে রূপান্তর করা।
নিউরাল নেটওয়ার্কগুলো প্রোগ্রামারদের বদলি করার জন্য সৃষ্টি হয়নি। তাদের মূল প্রতিশ্রুতি ছিল আরও নির্দিষ্ট: এমন মেশিন তৈরি করা যা কাঁচা বাস্তব-জগতের ইনপুট (চিত্র, বক্তৃতা, টেক্সট) থেকে নিজে দরকারি অভ্যন্তরীণ প্রতিনিধিত্ব শিখতে পারে—প্রতিটি নিয়ম ইঞ্জিনিয়াররা হাতে লিখবে না।
একটি ফটো কেবল কোটি কোটি পিক্সেল মান। একটি শব্দ রেকর্ডিং চাপের সিরিজ। চ্যালেঞ্জ হলো ঐ কাঁচা সংখ্যাগুলোকে এমন ধারণায় বদল করা যা মানুষের কাছে অর্থপূর্ণ: প্রান্ত, আকার, ফোনিম, শব্দ, বস্তু, অভিপ্রায়।
নিউরাল নেটওয়ার্কগুলি স্বয়ংক্রিয়ভাবে, স্তরভিত্তিকভাবে ফিচার শেখার চেষ্টা করেছিল। যদি একটি সিস্টেম নিজে intermediate বিল্ডিং ব্লক আবিষ্কার করতে পারে, তাহলে সেটা উন্নতভাবে সাধারণীকরণ করতে পারে এবং কম ম্যানুয়াল ইঞ্জিনিয়ারিং দিয়ে নতুন টাস্কে খাপ খাইয়ে নিতে পারে।
ধারণা আকর্ষণীয় ছিল, কিন্তু কয়েকটি বাধা ছিল যা নিউরাল নেটকে দীর্ঘসময় বাস্তবে সফল হতে বাধা দিয়েছে:
যখন নিউরাল নেটওয়ার্ক অপ্রচলিত ছিল—বিশেষত ১৯৯০-এর দশক ও ২০০০-এর শুরুর দিকে—জেফরি হিন্টনের মতো গবেষকরা প্রতিনিধিত্ব শেখা নিয়ে কাজ চালিয়ে গেছেন। তিনি ধারণাগুলো প্রস্তাব করেছেন (১৯৮০-এর মাঝামাঝি থেকে) এবং পুরনো ধারণাগুলো পুনর্বিবেচনা করেছেন (যেমন এনার্জি-ভিত্তিক মডেল) যতক্ষণ না হার্ডওয়্যার, ডেটা ও পদ্ধতি মিলে যায়।
এই স্থায়িত্ব মূল লক্ষ্যকে জীবিত রেখেছে: মেশিন এমন প্রতিনিধিত্ব শিখুক যা ঠিক।
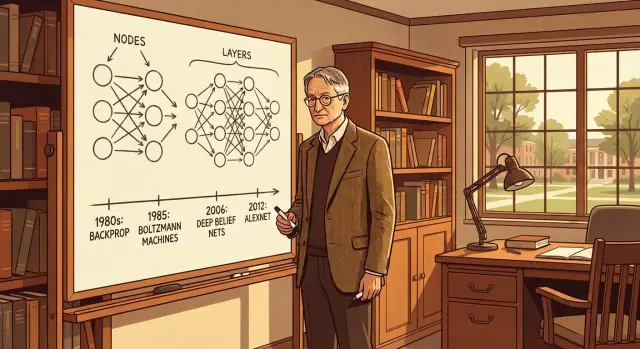
ব্যাকপ্রপাগেশন (প্রায়শই "ব্যাকপ্রপ" বলা হয়) হলো এমন একটি পদ্ধতি যা নেটওয়ার্ককে ভুল থেকে শেখায়। নেটওয়ার্ক একটি পূর্বানুমান করে, আমরা কতটা ভুল তা পরিমাপ করি, এবং তারপর নেটওয়ার্কের অভ্যন্তরীণ “নব” (ওজন) গুলো সামঞ্জস্য করি যাতে পরের বার আরো ভাল হয়।
ধরা যাক একটি নেটওয়ার্ক একটি ছবিকে "বিড়াল" বা "কুকুর" হিসেবে লেবেল করতে চাচ্ছে। এটি অনুমান করে "বিড়াল", কিন্তু সঠিক উত্তর "কুকুর"। ব্যাকপ্রপ সেই চূড়ান্ত ত্রুটি থেকে শুরু করে নেটওয়ার্কের স্তরগুলোর মধ্য দিয়ে পিছনে কাজ করে, প্রতিটি ওজন কতটা এই ভুলে ভুমিকা রেখেছে তা নির্ণয় করে।
প্রায়োগিকভাবে বুঝতে সহজ উপায়:
সেসব ধাক্কা সাধারণত গ্রেডিয়েন্ট ডিসেন্ট নামে একটি উপায় দিয়ে করা হয়—যার মানে হল "ত্রুটির উপর দিয়ে ছোট ছোট ধাপে নিচে নামা।"
ব্যাকপ্রপ ব্যাপকভাবে গ্রহণের আগ পর্যন্ত, বহু-স্তর নেটওয়ার্ক ট্রেন করা অবিশ্বাস্য এবং ধীর ছিল। ব্যাকপ্রপ বহু স্তর একসঙ্গে টিউন করার একটি সিস্টেম্যাটিক, পুনরাবৃত্ত পদ্ধতি দিল—শুধু শেষ স্তরকে টুইক করার বদলে।
এই পরিবর্তন পরবর্তী সাফল্যগুলোর জন্য গুরুত্বপূর্ণ ছিল: একবার বহু স্তর কার্যকরভাবে ট্রেন করা যায়, নেটওয়ার্কগুলো আরও সমৃদ্ধ ফিচার (প্রান্ত → আকার → বস্তু) শিখতে পারে।
ব্যাকপ্রপ নেটওয়ার্ককে মানুষ রকম "ভাবছে" বা "বুঝছে" বলে না—এটি গণিত-চালিত প্রতিক্রিয়া: একটি প্যারামিটার সমন্বয় পদ্ধতি যাতে উদাহরণগুলোর সাথে মিল বাড়ে।
এছাড়া, ব্যাকপ্রপ কোনো একক মডেল নয়—এটি একটি প্রশিক্ষণ পদ্ধতি যা বিভিন্ন ধরণের নিউরাল নেটওয়ার্কে ব্যবহার করা যায়।
আরেকটু নমনীয় বর্ণনার জন্য দেখুন /blog/neural-networks-explained।
বোল্টজমান মেশিন ছিল জেফরি হিন্টনের একটি গুরুত্বপূর্ণ পদক্ষেপ—যেটি নিউরাল নেটওয়ার্ককে কেবল উত্তর দেয়ার বাইরে উপযোগী অভ্যন্তরীণ প্রতিনিধিত্ব শেখানোর দিকে নিয়ে গেছে।
বোল্টজমান মেশিনটিতে সিম্পল ইউনিটগুলো চালু/বন্ধ (বা আধুনিক সংস্করণে রিয়েল ভ্যালু) হতে পারে। এটি সরাসরি একটি আউটপুট ভবিষ্যতবাণী না করে, বরং ইউনিটের পুরো কনফিগারেশনের উপর একটি এনার্জি নির্ধারণ করে। কম এনার্জি মানে "এই কনফিগারেশনটি সম্ভাব্য।"
একটি সহায়ক উপমা হলো একটি টেবিল যার উপর ছোট গর্ত ও উপত্যকা আছে। আপনি যদি একটি মার্বেল ছেড়ে দেন, এটি ঘুরে ঘুরে নিম্ন বিন্দুতে জায়গা ধরে বসবে। বোল্টজমান মেশিনগুলো অনুরূপভাবে কাজ করে: আংশিক তথ্য (কিছু ভিজিবল ইউনিট ডেটা দিয়ে সেট করা) দিলে, নেটওয়ার্ক তার অভ্যন্তরীণ ইউনিটগুলোকে "কাঁপতে" দেয় যতক্ষণ না সেগুলো কম-এনার্জি অবস্থায় স্থিতিশীল হয়—যে অবস্থাগুলোকে এটি সম্ভাব্য বলে শিখেছে।
ক্লাসিক বোল্টজমান মেশিন ট্রেন করতে প্রচুর সম্ভাব্য রাজ্যসিলেকশন করতে হয়েছিল—মডেলের বিশ্বাস বনাম ডেটা কি দেখাচ্ছে তা অনুমান করতে বারবার স্যাম্পল করতে হতো। বড় নেটওয়ার্কে এটি অত্যন্ত ধীর।
তারপরও, এই পদ্ধতি প্রভাববিস্তার করেছিল কারণ এটি:
আজকের বেশিরভাগ প্রোডাক্ট ফিডফরওয়ার্ড ডিপ নেটওয়ার্ক ব্যবহার করে যা ব্যাকপ্রপাগেশন দিয়ে ট্রেন করা হয়—কারণ সেগুলো দ্রুত এবং স্কেল করাটা সহজ।
বোল্টজমান মেশিনের উত্তরাধিকার বেশি ধারণাগত: ভালো মডেলগুলো বিশ্বের “প্রিয় অবস্থা” শিখে এবং শেখাকে সেই কম-এনার্জি উপত্যকাগুলোর দিকে সম্ভাব্যতা সরানোর মতো হিসেবে দেখা যায়।
নিউরাল নেটওয়ার্কগুলো কেবল কৌতুকসুলভ বক্ররেখা ফিট করতেই ভাল হয়নি—তারা সঠিক ফিচার আবিষ্কার করতে পারল। এটাই প্রতিনিধিত্ব শেখার মানে: মানুষ হাত দিয়ে কী দেখতে হবে লিখে না দেওয়ার বদলে, মডেল এমন অভ্যন্তরীণ বর্ণনা (রেপ্রেসেন্টেশন) শিখে যা কাজকে সহজ করে।
একটি প্রতিনিধিত্ব হলো মডেলের কাঁচা ইনপুট সংক্ষেপ করার নিজস্ব উপায়। এটা এখনই "বিড়াল"ের মতো লেবেল নয়; বরঞ্চ এটা সেই দরকারী কাঠামো যা লেবেল তৈরির পথে থাকে—প্যাটার্ন যা ব্যাপকভাবে গুরুত্বপূর্ণ। প্রাথমিক স্তরগুলো সাধারণ সিগন্যালের প্রতি সাড়া দেয়, পরে স্তরগুলো তা একত্র করে বেশি অর্থবহ ধারণা তৈরী করে।
এর আগে বহু সিস্টেম এক্সপার্ট-ডিজাইন করা ফিচারে নির্ভর করত: ইমেজের জন্য এজ ডিটেক্টর, অডিওর জন্য বিশেষ হ্যান্ডক্রাফটেড কিউ, টেক্সটের জন্য নির্দিষ্ট পরিসংখ্যান। এই ফিচারগুলো সীমিত সেটিংয়ে কাজ করলেও আলোর পরিবর্তন, উচ্চারণ, বা পরিবেশ বদলালে ভেঙে পড়ার প্রবণতা ছিল।
প্রতিনিধিত্ব শেখা মডেলগুলোকে ডেটা অনুযায়ী ফিচার খাপ খাইয়ে নিতে দেয়, যা পারফরম্যান্স বাড়ায় এবং বাস্তব ইনপুটে আরও সহনশীল করে।
কমন থ্রেড হলো হায়ারার্কি: সরল প্যাটার্নগুলি জড়ো হয়ে সমৃদ্ধ প্যাটার্ন গঠন করে।
ইমেজ রিকগনিশনে, একটি নেটওয়ার্ক প্রথমে প্রান্ত-সদৃশ প্যাটার্ন শিখতে পারে। পরে তা কোণ ও বক্ররেখায় মিলিয়ে অংশগুলো তৈরি করে—যেমন চাকা বা চোখ—অবশেষে পুরো বস্তু যেমন “সাইকেল” বা “মুখ” চিনতে পারে।
হিন্টনের সাফল্যগুলো এই স্তরভিত্তিক ফিচার নির্মাণকে ব্যবহারিক করে তুলেছিল—এবং সেটাই ডিপ লার্নিং বাস্তবে জয়ী হওয়ার বড় কারণ।
ডিপ বিলিফ নেটওয়ার্ক (DBN) ছিল একটি গুরুত্বপূর্ণ ধাপ যা গভীরতার ব্যবহারিকতা প্রমাণ করতে সাহায্য করেছিল। সারাংশে, একটি DBN হলো স্তরের স্তরগুলো যেখানে প্রতিটি স্তর নিচের স্তরকে উপস্থাপন করতে শিখে—কাঁচা ইনপুট থেকে ধীরে ধীরে বেশি বিমূর্ত ধারণা তৈরী করে।
ভাবুন হাতের লেখা সনাক্ত করা শেখানো হচ্ছে। একবারে সবকিছু শেখানোর বদলে, DBN প্রথমে সহজ নিদর্শন (প্রান্ত ও আঘাত) শিখে, তারপর এসব মিলিয়ে লুপ ও কোণ, এবং পরে ডিজিটের অংশগুলোর মতো উচ্চ-স্তরের আকৃতি শেখে।
মূল ধারণা হলো প্রতিটি স্তর তার ইনপুটে থাকা প্যাটার্নগুলো শেখে—প্রায়ই লেবেল ছাড়াই—তারপর স্তরগুলোকে একত্র করে পুরো নেটওয়ার্কটি নির্দিষ্ট টাস্কে ফাইন-টিউন করা যায়।
আগের গভীর নেটওয়ার্কগুলো র্যান্ডমভাবে ইনিশিয়ালাইজ করলে ভালোভাবে ট্রেন করতে হত না। প্রশিক্ষণ সংকেত অনেক স্তর পার হয়ে দুর্বল বা অস্থিতিশীল হতে পারে, এবং নেটওয়ার্ক অনুকূল নয় এমন সেটিংসে আটকে যেতে পারে।
লেয়ার-বাই-লেয়ার প্রিট্রেনিং মডেলটিকে "ওয়ার্ম স্টার্ট" দিয়েছিল। প্রতিটি স্তর ডেটার কাঠামো নিয়ে একটি যুক্তিসঙ্গত ধারণা নিয়ে শুরু করত, ফলে পুরো নেটওয়ার্কটি বেচে না বেড়েই অন্ধভাবে সন্ধান করছিল না।
প্রিট্রেনিং সব সমস্যা সমাধান করেনি, কিন্তু এটি তখনকার সীমিত ডেটা ও কম্পিউটিং পরিস্থিতিতে গভীরতা ব্যবহার যোগ্য করে তুলেছিল।
DBN দেখিয়েছিল বহু স্তর জুড়ে ভাল প্রতিনিধিত্ব শেখানো যায়—এবং গভীরতা কেবল তত্ত্ব নয়, প্রয়োগযোগ্য পথ।
নিউরাল নেটওয়ার্কগুলো কখনো কখনো টেস্টের জন্য ‘রুটিন মুখস্ত’ করে ফেলতে পারে: তারা ট্রেনিং ডেটা স্মরণ করে, বাস্তব পৃথিবীর ইনপুটে খারাপ পারফর্ম করে—এটিই ওভারফিটিং।
ভাবুন আপনি ড্রাইভিং পরীক্ষার প্রস্তুতি নিচ্ছেন এবং গতবার পরীক্ষক যে রুট দেখিয়েছিল সেটি মুখস্ত করে নিচ্ছেন—প্রতিটি মোড়, প্রতিটি স্টপসাইন, প্রতিটি গর্ত। যদি পরীক্ষাটি একই রুটে হয়, আপনি চমৎকার করবেন। কিন্তু রুট ভিন্ন হলে পারফরম্যান্স পড়ে যাবে কারণ আপনি সাধারণ ড্রাইভিং দক্ষতা শিখেননি—কেবল একটি নির্দিষ্ট স্ক্রিপ্ট।
এটাই ওভারফিটিং: পরিচিত উদাহরণে উচ্চ নির্ভুলতা, নতুন উদাহরণে দুর্বল ফল।
ড্রপআউট জেফরি হিন্টন ও সহযোগীরা জনপ্রিয় করেছে—a প্রশিক্ষণ ট্রিক যা খুব সরল কিন্তু কার্যকর। প্রশিক্ষণের সময় নেটওয়ার্ক র্যান্ডমভাবে কিছু ইউনিট “বন্ধ” করে দেয় প্রতি পাসে।
এতে মডেল কোনো একক পথ বা "মনোনীত" ফিচারের ওপর অতিরিক্ত নির্ভর করতে পারে না—পরিবর্তে, এটি তথ্য অনেক সংযোগ জুড়ে ছড়িয়ে নিতে বাধ্য হয় এবং এমন প্যাটার্ন শিখে যা মডেলের অংশ অনুপস্থিত থাকলেও কার্যকর থাকে।
একটি সহায়ক মানসিক মডেল: আপনি যখন অধ্যয়ন করছেন এবং মাঝে মাঝে নোটের র্যান্ডম পৃষ্ঠাগুলো হারিয়ে ফেলছেন—তাহলে আপনি নির্দিষ্ট বাক্য মনে না রেখে ধারণাটাই বেশি বোঝার জন্য প্ররোচিত হন।
মূল ফলাফল হলো অধিক সাধারণীকরণ: মডেল নতুন ডেটায় বেশি নির্ভরযোগ্য হয়ে ওঠে। বাস্তবে, ড্রপআউট বড় নিউরাল নেটওয়ার্কগুলোকে ট্রেন করতে সাহায্য করেছে যাতে সেগুলো কেবল জোর করে স্মৃতি না করে, এবং এটি বহু ডীপ লার্নিং সেটআপে একটি স্ট্যান্ডার্ড টুল হয়ে গেছে।
আলেক্সনেটের আগে, “ইমেজ রিকগনিশন” ছিল পরিমাপযোগ্য প্রতিযোগিতা। ImageNet মতো বেঞ্চমার্ক জিজ্ঞেস করত: একটি ফটো দিলে, আপনার সিস্টেম কি বস্তুটি নামতে পারে?
চ্যালেঞ্জ ছিল স্কেলে: মিলিয়ন মিলিয়ন ছবি এবং হাজার হাজার ক্যাটেগরি। ওই পরিমাণই পার্থক্য তৈরি করত—ছোট পরীক্ষা যেখানে ধারণা কাজ করে, বড় বাস্তবে ঠিক থাকবার মতো না।
সাধারণত লিডারবোর্ডে উন্নতি ধীর ছিল। তারপর AlexNet (Alex Krizhevsky, Ilya Sutskever এবং Geoffrey Hinton দ্বারা তৈরি) এসে ফলাফলকে ধাপে ধাপে উন্নতির বদলে এক ধাক্কায় বদলে দিল।
আলেক্সনেট দেখিয়েছিল যে একটি গভীর কনভোলিউশনাল নিউরাল নেটওয়ার্ক সেরা প্রচলিত কম্পিউটার-ভিশন পদ্ধতিগুলোকে পার করতে পারে যখন তিনটি উপাদান মিলিত হয়:
এটি কেবল "বড় মডেল" ছিল না—এটি গভীর নেটওয়ার্ক কার্যকরভাবে বাস্তবে ট্রেন করার একটি ব্যবহারিক রেসিপি দেখিয়েছিল।
ভাবুন একটি ছোট "উইন্ডো" ছবি জুড়ে স্লাইড করা হচ্ছে—প্রতিটি জায়গায় নেটওয়ার্ক একটি সাধারণ প্যাটার্ন খুঁজে দেখছে: একটি প্রান্ত, একটি কোণ, একটি ডোরাকাটা। একই প্যাটার্ন-চেকারটি পুরো ছবিতেই পুনরায় ব্যবহার করা হয়, তাই এটি ছবি কোথায় থাকুক—উপর, নীচে, বামের দিকে বা ডানে—প্রান্ত-সদৃশ জিনিসগুলো শনাক্ত করতে পারে।
এই স্তরগুলো স্ট্যাক করলে একটি হায়ারার্কি গড়ে ওঠে: প্রান্তগুলো টেক্সচারে পরিণত হয়, টেক্সচারগুলো অংশে, অংশগুলো অবশেষে বস্তুতে রূপান্তরিত হয়।
আলেক্সনেট ডীপ লার্নিংকে নির্ভরযোগ্য ও বিনিয়োগযোগ্য করে তুলে দিয়েছিল। যদি গভীর নেটওয়ার্ক কঠোর বেঞ্চমার্কে প্রাধান্য পায়, তাহলে তারা পণ্যেও উন্নতি আনতে পারে—সার্চ, ফটো ট্যাগিং, ক্যামেরা ফিচার, অ্যাক্সেসিবিলিটি টুল ইত্যাদি।
এটি নিউরাল নেটওয়ার্ককে "প্রতিশ্রুতিশীল গবেষণা" থেকে বাস্তব সিস্টেম নির্মাণের জন্য একটি স্পষ্ট দিশা করে তুলেছিল।
ডিপ লার্নিং রাতারাতি ‘‘আসেনি।’’ এটি তখনই নাটকীয় মনে হয়েছিল যখন কয়েকটি উপাদান মিলে গেছে—বছরের পর বছর আগে থেকেই ধারণাগুলো প্রতিশ্রুতিশীল ছিল কিন্তু স্কেলে করা কঠিন ছিল।
আরও ডেটা। ওয়েব, স্মার্টফোন এবং বড় লেবেলড ডেটাসেট (যেমন ImageNet) মুলত মিলে নিয়ে এসেছে যে নিউরাল নেটওয়ার্ক মিলিয়ন মিলিয়ন উদাহরণ থেকে শিখতে পারে। ছোট ডেটাসেটে বড় মডেল সাধারণত মুখস্থ করে ফেলে।
আরও কম্পিউট (বিশেষ করে GPU)। একটি ডিপ নেটওয়ার্ক ট্রেন করা মানে একই গণিতবার বার করা। GPU সেই কাজটি দ্রুত ও সাশ্রয়ী করে তুলল। যা আগে সপ্তাহ সময় নিত, এখন দিন বা ঘণ্টা। ফলে গবেষকরা বেশি আর্কিটেকচার ট্রাই করতে পারল, বেশি হাইপারপ্যারামিটার পরীক্ষা করতে পারল এবং দ্রুত ব্যর্থতা থেকে শেখার সুযোগ পেল।
ভাল প্রশিক্ষণ কৌশল। ব্যবহারিক উন্নতি এমন র্যান্ডমনেস কমাল:
এগুলো মূল নিউরাল নেটওয়ার্ক ধারণা পরিবর্তন করেনি; বরং সেগুলোকে কাজ করার যোগ্য করা হয়েছে।
একবার কম্পিউট ও ডেটা একটি নির্দিষ্ট সীমা ছাড়িয়ে যায়, উন্নতিগুলো সাজানোভাবে ঘটা শুরু করল। ভালো ফলাফল আরো বিনিয়োগ আকর্ষণ করলো, যা বড় ডেটাসেট ও দ্রুত হার্ডওয়্যার চালায়—ফলস্বরূপ বাইরে থেকে এটা একটা বড় লাফ মনে করে।
স্কেল বাড়ানো বাস্তবে খরচ বাড়ায়: বেশি শক্তি ব্যবহার, ট্রেনিং রান বেশি ব্যয়বহুল, এবং প্রোডাকশনে মোতায়েন কঠিন। এছাড়া বড় মডেল শুধুমাত্র বড় ল্যাবে ট্রেন করা সম্ভব—একজন ছোট দলের পক্ষে পুরোপুরি নতুন মডেল শূন্য থেকে ট্রেন করা কঠিন।
হিন্টনের মূল ধারণা—ডেটা থেকে দরকারী প্রতিনিধিত্ব শেখা, গভীর নেটওয়ার্ক স্থিতিশীলভাবে ট্রেন করা, এবং ওভারফিটিং প্রতিরোধ করা—এইগুলো এমন কোনো "ফিচার" নয় যাকে আপনি কোনো অ্যাপে সরাসরি দেখেন। বরং এগুলোই কারনে অনেক দৈনন্দিন ফিচার দ্রুত, সঠিক ও কম হতাশাজনক মনে হয়।
আধুনিক সার্চ সিস্টেম শুধু কীওয়ার্ড মিলায় না। তারা কুয়েরি ও কনটেন্টের প্রতিনিধিত্ব শিখে যাতে “best noise-canceling headphones”-এর মতো কুয়েরি এমন পেজ দেখায় যা ঠিক সেই শব্দটি পুনরাবৃত্তি করেনা। একই প্রতিনিধিত্ব শেখা সুপারিশ ফিডগুলোকে বোঝায় যে দুইটি আইটেম "সদৃশ" যদিও তাদের বর্ণনা আলাদা।
মেশিন অনুবাদ ব্যাপকভাবে উন্নত হয়েছে যখন মডেলগুলো স্তরভিত্তিক প্যাটার্ন শেখা শুরু করে—ক্যারেক্টার থেকে শব্দ ও তারপর অর্থ। যদিও আর্কিটেকচার বদলে যেতে পারে, শেখার প্লেবুক—বড় ডেটাসেট, যত্নশীল অপ্টিমাইজেশন এবং ড্রপআউটের মতো নিয়মকরণ—এখনো ভাষা ফিচার তৈরিতে প্রভাব ফেলছে।
ভয়েস সহকারী ও ডিক্টেশন সেই নিউরাল নেটওয়ার্কের উপর নির্ভর করে যা গোলমাল অডিওকে পরিষ্কার টেক্সটে বদলে দেয়। ব্যাকপ্রপাগেশন এগুলো টিউন করার কাজ করে, আর ড্রপআউট মত কৌশল মডেলকে কোনও নির্দিষ্ট স্পিকার বা মাইক্রোফোনের কুইর্ক মুখস্থ না করতে সাহায্য করে।
ফটো অ্যাপগুলো মুখ চিনতে পারে, একইরকম দৃশ্য গোষ্ঠী করতেছে, এবং “বিচ” খুঁজলে ম্যানুয়াল লেবেল ছাড়াই ছবিগুলো তুলে আনতে পারে। এটাই প্রতিনিধিত্ব শেখার বাস্তব প্রয়োগ: সিস্টেম ভিজ্যুয়াল ফিচার শিখে (প্রান্ত → টেক্সচার → বস্তু) যা ট্যাগিং ও রিট্রিভালে কাজে লাগে।
আপনি শূন্য থেকে মডেল ট্রেন না করলেও, এই নীতিগুলো দৈনন্দিন প্রোডাক্ট কাজে দেখা যায়: ভালো প্রতিনিধিত্ব দিয়ে শুরু করা (প্রতিনিয়ত pretrained মডেল ব্যবহার করে), প্রশিক্ষণ ও মূল্যায়ন স্থিতিশীল করা, এবং নেটওয়ার্ক যখন ব্যাচে ‘মুখস্থ’ করতে শুরু করে তখন নিয়মকরণ ব্যবহার করা।
এটা কারণেই আধুনিক “ভাইব-কোডিং” টুলগুলো এত সক্ষম মনে হয়। যেমন Koder.ai প্ল্যাটফর্মগুলো বর্তমান-প্রজন্ম LLM ও এজেন্ট ওয়ার্কফ্লোরের উপর বসে টিমগুলোকে সাধারণ ভাষা স্পেসিফিকেশন থেকে কাজ করে চালিত ওয়েব, ব্যাকএন্ড বা মোবাইল অ্যাপ বানাতে দ্রুত সহায়তা করে—সাধারণত প্রচলিত পাইপলাইনের তুলনায় দ্রুত—আর একই সঙ্গে সোর্স কোড এক্সপোর্ট করে প্রথাগত ইঞ্জিনিয়ারিং দলের মত প্রয়োগ করার সুযোগ দেয়।
উচ্চ-স্তরের প্রশিক্ষণ অনুধাবনের জন্য দেখুন /blog/backpropagation-explained।
বড় সাফল্যগুলো প্রায়ই সহজ গল্পে পরিণত হয়। সেটি মনে রাখা সহজ হলেও, অনেক সময় বাস্তব ঘটনাকে ঢাকতে ভুল ধারণা তৈরি করে।
হিন্টন কেন্দ্রীয় চরিত্র, কিন্তু আধুনিক নিউরাল নেটওয়ার্ক বহু বছরের কাজ—অপটিমাইজেশন উন্নত করা, ডেটাসেট তৈরি, GPU-কে প্রশিক্ষণে ব্যবহারযোগ্য করা, এবং ধারণাগুলো স্কেলে প্রমাণ করার কাজ—অনেক গ্রুপ ও ব্যক্তির চেইন অবদান।
হিন্টনের কাজেও তার ছাত্র ও সহযোগীরা বড় ভূমিকা রেখেছেন। প্রকৃত কাহিনী হলো বহু অবদানের শৃঙ্খল যা মিলেছিল।
নিউরাল নেটওয়ার্ক গবেষণা মধ্য-২০শ শতক থেকেই চলছে, উত্থান-পতনসহ। যা বদলেছে তা হলো বড় মডেল স্থিরভাবে প্রশিক্ষিত করার ক্ষমতা এবং বাস্তব সমস্যায় স্পষ্ট জয় দেখানোর সামর্থ্য।
"ডিপ লার্নিং এরা" একটি পুনরুত্থান—হঠাৎ আবির্ভাব নয়।
গভীর মডেল সাহায্য করতে পারে, কিন্তু তারা যাদুময় নয়। ট্রেনিং সময়, খরচ, ডেটার গুণমান, ও লাভের হ্রাস আসা বাস্তব সীমা। কখনও ছোট মডেলই বড় মডেলের চেয়ে ভাল হতে পারে—কারণ সেগুলো টিউন করা সহজ, নয়েজের প্রতি কম সংবেদনশীল, অথবা টাস্কের সাথে ভাল মিলায়।
ব্যাকপ্রপ হলো লেবেল-ভিত্তিক প্রতিক্রিয়া ব্যবহার করে প্যারামিটার সামঞ্জস্য করার একটি ব্যবহারিক উপায়। মানুষ অনেক কম উদাহরণে শিখে, গভীর prior জ্ঞান ব্যবহার করে, এবং একরকম স্পষ্ট ত্রুটির সংকেতের ওপর নির্ভর করে না।
নিউরাল নেটওয়ার্ক জৈবিক অনুপ্রেরণা নিতে পারে, কিন্তু মস্তিষ্কের প্রকৃত অনুকরণ নয়।
হিন্টনের গল্প শুধু আবিষ্কারগুলোর তালিকা নয়। এটি একটি নিদর্শন: একটি সরল শেখার ধারণা রাখুন, তা নিরন্তর পরীক্ষণ করুন, এবং পারিপার্শ্বিক উপাদানগুলো (ডেটা, কম্পিউট, প্রশিক্ষণ কৌশল) আপগ্রেড করুন যতক্ষণ না তা স্কেলে কাজ করে।
সবচেয়ে ব্যবহারযোগ্য অভ্যাসগুলো হলো:
শিরোনামীয় পাঠ্যকে “বড় মডেলই সবসময় জয়ী” হিসেবে নেওয়া লোভজনক। সেটি অসম্পূর্ণ।
নিয়ম ছাড়া আকার বাড়ানো প্রায়শই নিয়ে আসে:
ভাল নীতি: ছোটে শুরু করুন, মান প্রমাণ করুন, তারপর স্কেল করুন—এবং শুধুমাত্র সেই অংশটুকুই স্কেল করুন যা স্পষ্টভাবে পারফরম্যান্স সীমিত করছে।
এগুলো আপনার দিন-প্রতিদিন অনুশীলনে রূপান্তর করতে সহায়ক:
ব্যাকপ্রপের মৌলিক শেখার নিয়ম থেকে, অর্থ ধারণা করে এমন প্রতিনিধিত্ব, ড্রপআউটের মতো ব্যবহারিক ট্রিক, এবং আলেক্সনেটের মত একটি সাফল্য—বৃত্তান্তটি সঙ্গতিপূর্ণ: ডেটা থেকে দরকারী ফিচার শিখুন, প্রশিক্ষণকে স্থিতিশীল করুন, এবং বাস্তব ফলাফল দিয়ে উন্নতি যাচাই করুন।
এটিই সেই প্লেবুক যা বজায় রাখতে হবে।
জেফরি হিন্টন গুরুত্বপূর্ণ কারণ তিনি বারবার নিউরাল নেটওয়ার্কগুলোকে প্রয়োগযোগ্যভাবে কাজ করাতে সহায়তা করেছেন, এমন সময় অনেক গবেষক এগুলোকে আর কার্যকর উপায় মনে করতেন না।
“এআই আবিষ্কার করা” বলার বদলে, তার প্রভাব আসে প্রতিনিধিত্ব শেখা (representation learning) এগিয়ে নেওয়া, প্রশিক্ষণ পদ্ধতিতে অগ্রগতি আনা, এবং এমন গবেষণা-সংস্কৃতি গড়ে তোলা যেটি ডেটা থেকে ফিচার শিখাকে হাতেই লিখে দেওয়ার বদলে কেন্দ্রীয় সমস্যা হিসেবে ধরা হয়।
এখানে “সাফল্য” বলতে বোঝানো হয়েছে এমন পরিবর্তন যা নিউরাল নেটওয়ার্ককে আরও নির্ভরযোগ্য ও উপযোগী করে তোলে: তারা বেশি সুশৃঙ্খলভাবে ট্রেন হয়, ভিতরের ফিচারগুলো ভালোভাবে শেখে, নতুন ডেটায় সাধারণীকরণ বাড়ে, বা বড় কাজের দিকে স্কেল করা যায়।
এটি ঝলকপ্রদ ডেমোকে ছাড়া—একটি ধারণাকে পুনরাবৃত্তিযোগ্য পদ্ধতিতে রূপান্তর করার বিষয়।
নিউরাল নেটওয়ার্কের লক্ষ্য হলো অনিয়মিত কাঁচা ইনপুট (পিক্সেল, অডিও তরঙ্গ, টেক্সট টোকেন) থেকে দরকারি প্রতিনিধিত্ব তৈরি করা—অভ্যন্তরীণ ফিচার যা তাৎপর্য ধারণ করে।
মানুষ যদি প্রতিটি ফিচার হাতের লেখা না করে দেয়, তাহলে মডেল নিজে উদাহরণ থেকে স্তরভিত্তিক ফিচার শিখে নিতে পারে, যা আলাদা পরিস্থিতিতে (আলো পরিবর্তন, ভিন্ন উচ্চারণ, ভিন্ন লেখনশৈলী) বেশি স্থিতিশীল ফল দেয়।
ব্যাকপ্রপাগেশন হলো একটি প্রশিক্ষণ পদ্ধতি যা নেটওয়ার্ককে ভুল থেকে শেখায়:
এটি গ্রেডিয়েন্ট דיסেন্টের মতো অ্যালগরিদমের সঙ্গে কাজ করে—যা ত্রুটি কমানোর জন্য ছোট ধাপে নীচের দিকে এগোতে বলে়।
ব্যাকপ্রপাগেশন এই কারণে বড় ব্যাপার ছিল যে এটি ধারাবাহিকভাবে একাধিক স্তর একসঙ্গে টিউন করা সম্ভব করে তুলেছিল।
এটি গুরুত্বপূর্ণ কারণ গভীর নেটওয়ার্কগুলো ফিচার হায়ারার্কি বানাতে পারে (যেমন: প্রান্ত → আকৃতি → বস্তু)। অনেক স্তর একসঙ্গে ট্রেন করার দীর্ঘস্থায়ী উপায় না থাকলে গভীরতা প্রায়ই বাস্তবে লাভ দিত না।
বোল্টজমান মেশিনগুলো একটি কনফিগারেশনের উপর এনার্জি (স্কোর) নিয়োগ করে শিখে; কম এনার্জি মানে “এই কনফিগারেশনটি যুক্তিযুক্ত।”
ইতিহাসগতভাবে এগুলো গুরুত্বপূর্ণ কারণ তারা:
আজকের বেশিরভাগ প্রোডাক্টে এগুলো কম দেখা যায়—প্রচলিত বোল্টজমান প্রশিক্ষণ বড় নেটওয়ার্কে ধীর। তবে তাদের ধারণাগত উত্তরাধিকার খুবই মূল্যবান: যে ভালো মডেলগুলো জগতের “প্রিয় অবস্থা” শিখে এবং শেখার উদ্দেশ্য সেই কম-এনার্জি উপত্যকাগুলোর দিকে সম্ভাব্যতা সরানো।
প্রতিনিধিত্ব শেখা মানে মডেল তার নিজস্ব অভ্যন্তরীণ ফিচার শেখানে—যা কাজকে সহজ করে—মানুষের হাতে ফিচার ডিজাইন করার বদলে।
প্র্যাকটিকালি, এটি স্থিতিশীলতা বাড়ায়: শেখা ফিচারগুলো বাস্তব ডেটার বিচিত্রতা (শব্দগত ভিন্নতা, আলোর পরিবর্তন, ক্যামেরার পার্থক্য) অনুযায়ী খাপ খাইয়ে নিতে পারে, যেখানে কড়াই করে ডিজাইন করা ফিচার ভাঙতে পারে।
ডিপ বিলিফ নেটওয়ার্ক (DBN) গভীর মডেল গঠনে একটি মধ্যবর্তী ধাপ হিসেবে কাজ করেছিল, যেখানে প্রতিটি স্তর নিচের স্তরের প্রতিনিধিত্ব শেখে—কাঁচা ইনপুট থেকে ধীরে ধীরে আরও বিমূর্ত ধারণা তৈরি হয়।
প্রতিটি স্তর প্রথমে তার ইনপুটের কাঠামো শেখে (সাধারণত লেবেল ছাড়াই), ফলে পূর্ণ নেটওয়ার্কটি ‘ওয়ার্ম স্টার্ট’ পায়। পরে পুরো স্ট্যাকটি একটি নির্দিষ্ট টাস্ক (যেমন শ্রেণীবিভাগ) জন্য ফাইন-টিউন করা যায়।
এই লেয়ার-বাই-লেয়ার প্রিট্রেনিং অনেক সময়ে গভীরতার ব্যবহারিকতা বাড়িয়েছে, বিশেষ করে যখন ডেটা, কম্পিউটিং ও ট্রেনিং কৌশল সীমিত ছিল।
ড্রপআউট ওভারফিটিং প্রতিরোধ করে যেভাবে: প্রশিক্ষণের সময় নেটওয়ার্কের কিছু ইউনিট র্যান্ডম ভাবে ‘বন্ধ’ করে দেয়া হয়।
এটি নেটওয়ার্ককে কোনো একমাত্র পথ বা নির্দিষ্ট ফিচারের উপর অতিরিক্ত নির্ভর করতে দেয় না—ফলস্বরূপ মডেলটিকে এমন ফিচার শিখতে প্ররোচিত করা হয় যা যখন মডেলের কিছু অংশ অনুপস্থিত থাকে তখনও কার্যকর থাকে।
ফলাফল: নতুন, দেখা না থাকা ডেটায় ভালো সাধারণীকরণ এবং বড় নেটওয়ার্কগুলোকে স্মৃতিপরক অনুকরণ এড়াতে সাহায্য।
আলেক্সনেটই একটি ব্যবহারিক রেসিপি দেখিয়েছে: ডীপ কনভোলিউশনাল নেটওয়ার্ক + GPU + প্রচুর লেবেল্ড ডেটা (ImageNet)।
এটি শুধু বড় মডেল ছিল না—এটি দেখিয়েছিল যে গভীর লার্নিং কঠোর, বড় স্কেলে প্রতিদ্বন্দ্বিতা করে বাড়তি কার্যকারিতা দিতে পারে, এবং তাই শিল্প বিনিয়োগ আকর্ষণ করে।