জো আর্মস্ট্রং এবং এরল্যাং: নির্ভরযোগ্য প্ল্যাটফর্মের জন্য 'লেট ইট ক্র্যাশ'
জো আর্মস্ট্রং কীভাবে Erlang‑এর কনকারেন্সি, সুপারভিশন এবং “লেট ইট ক্র্যাশ” মানসিকতা গড়ে তুলতে সাহায্য করেছেন—এবং কেন সেই ধারণাগুলো আজও নির্ভরযোগ্য রিয়েল‑টাইম সার্ভিস তৈরিতে ব্যবহার করা হয়।
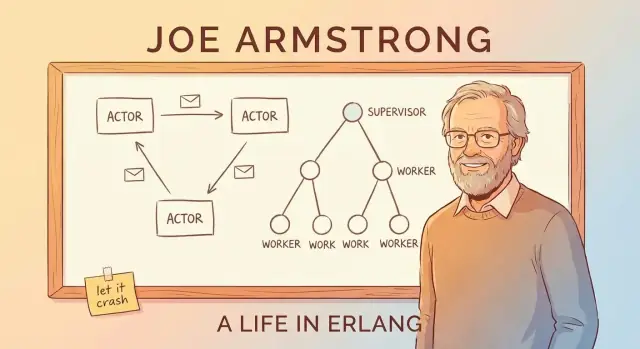
এই পোস্টে কী কভার করা হয়েছে (এবং কেন এটা আজও গুরুত্বপূর্ণ)
জো আর্মস্ট্রং শুধু Erlang তৈরি করেননি—তিনি এটিকে সবচেয়ে স্পষ্ট ও প্রভাবশালীভাবে ব্যাখ্যা করেন। টক, পেপার এবং বাস্তবমুখী দৃষ্টিভঙ্গির মাধ্যমে তিনি একটি সরল ধারণা জনপ্রিয় করেছেন: যদি আপনি এমন সফটওয়্যার চান যা স্থিতিশীল থাকে, তাহলে ব্যর্থতাকে এড়ানোর ভান করার বদলে ব্যর্থতার জন্য ডিজাইন করুন।
এই পোস্টটি Erlang-এর মানসিকতায় একটি গাইডেড ট্যুর এবং কেন এটি এখনও গুরুত্বপূর্ণ—বিশেষত যখন আপনি নির্ভরযোগ্য রিয়েল-টাইম প্ল্যাটফর্ম (চ্যাট সিস্টেম, কল রাউটিং, লাইভ নোটিফিকেশন, মাল্টিপ্লেয়ার সমন্বয় এবং এমন ইনফ্রাস্ট্রাকচার যা খারাপ আচরণ করা অংশ সত্ত্বেও দ্রুত ও ধারাবাহিকভাবে প্রতিক্রিয়া দিতে হবে) তৈরি করছেন।
সাধারণ কথায় “রিয়েল-টাইম”
রিয়েল-টাইম সবসময় “মাইক্রোসেকেন্ড” বা “হার্ড ডেডলাইন” মানে নয়। অনেক প্রোডাক্টে এর মানে হচ্ছে:
- ব্যবহারকারী অনুভব করতে পারবে এমন দ্রুত প্রতিক্রিয়া (কোন অজানা বিরতি নেই)
- লোডের সময় পূর্বানুমেয় আচরণ (স্লো হতে পারে, কিন্তু কাঁচামাল নয়)
- আংশিক ব্যর্থতার সময়ও সার্ভিস চালু রাখা (একটি খারাপ কম্পোনেন্ট সবকিছু বন্ধ করে দেয়া উচিত নয়)
Erlang টেলিকম সিস্টেমের জন্য তৈরি করা হয়েছিল যেখানে এই প্রত্যাশাগুলো আপস করা যায় না—এবং সেই চাপে এর সবচেয়ে প্রভাবশালী ধারণাগুলো গড়ে উঠেছে।
আমরা যে তিনটি স্তম্ভের ওপর ফোকাস করব
সিনট্যাক্সে ডুব না দিয়ে, আমরা সেই ধারণাগুলোতে ফোকাস করব যেগুলো Erlang-কে বিখ্যাত করেছে এবং আধুনিক সিস্টেম ডিজাইনে বারবার দেখা যায়:
- ডিফল্ট হিসেবে কনকারেন্সি: কয়েকটি বৃহৎ কম্পোনেন্টের বদলে অনেক ছোট, বিচ্ছিন্ন ওয়ার্কার তৈরি করুন।
- ডিজাইনের লক্ষ্য হিসেবে ত্রুটি সহনশীলতা: বাগ, টাইমআউট ও ক্র্যাশ ঘটবে বলে ধরে নিন—এবং পরবর্তী কী হওয়া উচিত তা প্ল্যান করুন।
- “লেট ইট ক্র্যাশ”: প্রতিটি লাইনের জন্য অতিরিক্ত প্রতিরক্ষামূলক কোড লিখবেন না; দ্রুত ব্যস্ত হয়ে পড়ুন এবং কাঠামো (হিরোইক নয়) ব্যবহার করে সাফ পুনরুদ্ধার করুন।
পথে আমরা অ্যাক্টর মডেল ও মেসেজ পাসিং-এর সঙ্গে যুক্ত করব, সুপারভিশন ট্রি ও OTP সহজ ভাষায় ব্যাখ্যা করব, এবং দেখাবো কেন BEAM VM পুরো পদ্ধতিটিকে ব্যবহারযোগ্য করে তোলে।
যদিও আপনি Erlang ব্যবহার করছেন না (এবং হয়তো কখনো করবেন না), আর্মস্ট্রং-এর ফ্রেমিং আপনাকে এমন একটি শক্তিশালী চেকলিস্ট দেয় যা বাস্তব বিশ্বের বিশৃঙ্খলা হওয়ার সময়ও সিস্টেমকে রেসপন্সিভ ও উপলব্ধ রাখে।
জো আর্মস্ট্রং-এর প্রেরণা: এমন সিস্টেম গঠন করা যা চলতেই থাকে
টেলিকম সুইচ ও কল-রাউটিং প্ল্যাটফর্মগুলো সেই রকম নয় যে তারা “মেইনটেন্যান্সের জন্য বন্ধ” হতে পারে। এগুলোকে সারাবেলা কল, বিলিং ইভেন্ট এবং সিগনালিং ট্রাফিক পরিচালনা করতে হয়—প্রায়শই উচ্চ উপলব্ধতা এবং পূর্বনির্ধারিত প্রতিক্রিয়া সময়ের সঙ্গে।
Erlang ১৯৮০-এর শেষভাগে Ericsson-এ শুরু হয়েছিল এই বাস্তবতাগুলো সফটওয়্যার দিয়ে মোকাবিলা করার চেষ্টা হিসেবে, শুধুমাত্র বিশেষ হার্ডওয়্যার নয়। জো আর্মস্ট্রং এবং তাঁর সহকর্মীরা সৌন্দর্যের জন্য বিবেচনা করছিলেন না; তারা এমন সিস্টেম গড়ছিলেন যা অপারেটররা নির্ভর করতে পারে যখন লোড, আংশিক ব্যর্থতা এবং বাস্তব বিশ্বের জটিলতা চলতেই থাকে।
বাস্তবে “নির্ভরযোগ্য” মানে কী
চিন্তার একটি মূল পরিবর্তন হচ্ছে: নির্ভরযোগ্যতা মানে “কখনও ব্যর্থ না হওয়া” নয়। বড়, দীর্ঘকাল চলমান সিস্টেমে কিছু না কিছু ব্যর্থতা ঘটবেই: একটি প্রসেস অপ্রত্যাশিত ইনপুট পাবে, একটি নোড রিবুট হবে, নেটওয়ার্ক লিঙ্ক খারাপ হবে, বা একটি ডিপেনডেন্সি আটকে যাবে।
তাই লক্ষ্যগুলো হয়ে ওঠে:
- অংশগুলো খারাপ আচরণ করলেও ইউজারদের পরিবেশন চালিয়ে যাওয়া
- দ্রুত ব্যর্থতা সনাক্ত করা
- মানব হস্তক্ষেপ ছাড়াই স্বয়ংক্রিয়ভাবে পুনরুদ্ধার করা
- ত্রুটিগুলো আলাদা রাখা যাতে একটি বাগ সবকিছু ধ্বংস না করে
এই মানসিকতা পরে সুপারভিশন ট্রি ও “লেট ইট ক্র্যাশ”-কে যুক্তিযুক্ত করে তোলে: আপনি ব্যর্থতাকে একটি সাধারণ ঘটনা হিসেবে ডিজাইন করেন, একেবারে বিরল দুর্যোগ হিসেবে নয়।
কম মিথ, বেশি সমস্যা-সমাধান
কাহিনীটি একটি একক দৃষ্টিভঙ্গির আবিষ্কার বলে বলা সহজ, কিন্তু ব্যবহারিক দৃষ্টিকোণটি সহজ: টেলিকমের সীমাবদ্ধতাগুলো আলাদা ট্রেডঅফগুলো ব্যবহার করতে বাধ্য করেছিল। Erlang সমান্তরালতা, বিচ্ছিন্নতা এবং পুনরুদ্ধারকে গুরুত্ব দিয়েছে কারণ সেগুলো ছিল বাস্তবে সার্ভিস চালু রাখার দরকারি সরঞ্জাম।
এই প্রোবলেম-ফার্স্ট ফ্রেমিংই Erlang-এর পাঠ আজও কাজে লাগে—যেখানে আপটাইম এবং দ্রুত পুনরুদ্ধার নিখুঁত প্রতিরোধের চেয়ে বেশি গুরুত্বপূর্ণ।
ডিফল্ট হিসেবে কনকারেন্সি: বহু ছোট ওয়ার্কার
Erlang-এর একটি মূল ধারণা হচ্ছে “একসাথে অনেক কাজ করা” একটি বিশেষ বৈশিষ্ট্য নয় যা পরে বোল্ট-অন হয়—এটি সিস্টেম গঠনের স্বাভাবিক উপায়।
সরলভাবে ব্যাখ্যা করা লাইটওয়েট প্রসেস
Erlang-এ কাজ অনেক ছোট “প্রসেস”-এ ভাগ করা হয়। এগুলোকে ভাবুন ছোট ওয়ার্কার হিসেবে, প্রতিটি একটি কাজের জন্য দায়ী: একটি ফোন কল হ্যান্ডল করা, একটি চ্যাট সেশন ট্র্যাক করা, একটি ডিভাইস মনিটর করা, পেমেন্ট পুনরায় চেষ্টা করা, বা একটি কিউ দেখা।
এগুলো লাইটওয়েট, অর্থাৎ আপনি অনেকগুলোর উপরভার সত্ত্বেও বড় হার্ডওয়্যার ছাড়া প্রচুর সংখ্যা চালাতে পারবেন। একটি ভারি ওয়ার্কার সবকিছু সামলানোর চেষ্টা করার বদলে, আপনি অনেক মনোযোগী ওয়ার্কার পাবেন যারা দ্রুত শুরু হয়, দ্রুত থামে এবং দ্রুত প্রতিস্থাপিত হয়।
কেন “একটি বড় প্রোগ্রাম” আলাদা ভাবে ভেঙে যায়
অনেক সিস্টেম একক বড় প্রোগ্রাম হিসেবে ডিজাইন করা হয় যেখানে অনেক অংশ ঢিলেঢালা ভাবে যুক্ত থাকে। যখন এমন সিস্টেমে গুরুতর বাগ, মেমরি সমস্যা বা ব্লকিং অপারেশন হয়, ব্যর্থতা ছড়িয়ে পড়তে পারে—যেমন একটি সার্কিট ট্রিপ করে পুরো ভবন অন্ধকার হয়ে যাওয়া।
Erlang বিপরীতটি প্ররোচিত করে: দায়িত্ব আলাদা করা। যদি একটি ছোট ওয়ার্কার খারাপ আচরণ করে, আপনি সেই ওয়ার্কারটি ফেলে দিয়ে প্রতিস্থাপন করতে পারেন যাতে সম্পর্কহীন কাজগুলো ব্যাহত না হয়।
মেসেজ পাসিংকে “নোট পাঠানো” হিসেবে দেখা
এই ওয়ার্কাররা কীভাবে সমন্বয় করে? তারা একে অপরের অভ্যন্তরীণ স্টেটে হাত দেয় না। তারা মেসেজ পাঠায়—মেসেজ পাঠানো মানে একে অপরকে নোট দেয়া, মেসেজিং বোর্ডের মত নয়।
এক ওয়ার্কার বলতে পারে, “এখানে একটি নতুন রিকোয়েস্ট,” “এই ব্যবহারকারী ডিসকানেক্ট হয়েছে,” বা “৫ সেকেন্ড পরে আবার চেষ্টা করো।” গ্রহণকারী ওয়ার্কার নোটটি পড়ে সিদ্ধান্ত নেয় কী করবে।
মূল সুবিধা হলো কনটেইনমেন্ট: কারণ ওয়ার্কাররা বিচ্ছিন্ন এবং মেসেজের মাধ্যমে যোগাযোগ করে, ব্যর্থতাগুলো সিস্টেম জুড়ে ছড়াতে কম সম্ভাবনা থাকে।
মেসেজ পাসিং ও অ্যাক্টর মডেল (জার্গন ছাড়াই)
Erlang-এর “অ্যাক্টর মডেল” সহজভাবে বোঝার একটি উপায় হলো একটি সিস্টেম কল্পনা করা যে অনেক ছোট, স্বাধীন ওয়ার্কার নিয়ে গঠিত।
অ্যাক্টর: এমন ছোট ওয়ার্কার যারা শুধুমাত্র মেসেজ পাঠায়
একটি অ্যাক্টর হল একটি স্বনজ্ড ইউনিট যার নিজস্ব প্রাইভেট স্টেট এবং একটি মেইলবক্স আছে। এটি তিনটি মৌলিক কাজ করে:
- মেইলবক্স থেকে মেসেজ গ্রহণ করে (একবারে একটি)
- নিজের অভ্যন্তরীণ স্টেট আপডেট করে
- অন্য অ্যাক্টরদের মেসেজ পাঠায়
এটুকুই। কোনো লুকানো শেয়ার্ড ভ্যারিয়েবল নেই, অন্য ওয়ার্কারের মেমরিতে পৌঁছানোর সুযোগ নেই। যদি এক অ্যাক্টর অন্যটির কাছ থেকে কিছু চায়, তাহলে সেটা মেসেজ পাঠিয়ে অনুরোধ করে।
শেয়ার্ড স্টেট এড়ালে কী ধরণের বাগগুলো নড়ে যায়
যখন একাধিক থ্রেড একই ডেটা শেয়ার করে, আপনি রেস কন্ডিশনে পড়তে পারেন: একই ভ্যালু একসাথে দুইবার বদলায় এবং ফলাফল টাইমিং-এ নির্ভর করে। সেটাই সেই ধরার বাগকে ইন্টারমিটেন্ট ও রি-প্রোডিউস করা কঠিন করে তোলে।
মেসেজ পাসিংয়ে, প্রতিটি অ্যাক্টরের ডেটা তারই মালিকানা। অন্য অ্যাক্টররা সরাসরি এটি মিউটেট করতে পারে না। এটা সবাইকে প্রতিটি সমস্যা থেকে মুক্ত করে না, কিন্তু একসাথে একি ডেটা অ্যাক্সেস থেকে উদ্ভূত সমস্যা নাটকীয়ভাবে কমায়।
ব্যাক-প্রেশার: কফি শপের কিউ-র মতো ব্যাখ্যা
মেসেজ ফ্রি ভাবে আসে না। যদি কোনো অ্যাক্টর মেসেজ তুলনায় ধীর গতিতে প্রক্রিয়াকরণ করে, তার মেইলবক্স বেড়ে যায়। সেটাই ব্যাক-প্রেশার: সিস্টেম আপনাকে অনপারি ভাবে বলছে, “এই অংশটা অতিরিক্ত লোডে আছে।”
বাস্তবে, আপনি মেইলবক্স সাইজ মনিটর করে সীমা আরোপ করবেন: লোড বাদ দেওয়া, ব্যাচিং, স্যাম্পলিং, বা কাজকে আরও বেশি ওয়ার্কারদের কাছে পাঠানো যাতে কিউ অনন্তকাল বাড়ে না।
একটি বাস্তব উদাহরণ: চ্যাট নোটিফিকেশন
চ্যাট অ্যাপ কল্পনা করুন। প্রতিটি ব্যবহাকারীর জন্য একটি অ্যাক্টর থাকতে পারে যা নোটিফিকেশন ডেলিভারি দেখভাল করে। যখন ব্যবহারকারী অফলাইনে যায়, মেসেজগুলো আসে চলতে থাকে—ফলে মেইলবক্স বাড়ে। একটি ভালো ডিজাইন করা সিস্টেম কিউ ক্যাপ করতে পারে, অ-প্রয়োজনীয় নোটিফিকেশন ড্রপ করতে পারে, বা ডাইজেস্ট মোডে সুইচ করতে পারে, যাতে একজন ধীর ব্যবহারকারী পুরো সার্ভিসকে ধসিয়ে না দেয়।
“লেট ইট ক্র্যাশ” ব্যাখ্যা: দ্রুত ব্যর্থ হও, দ্রুত পুনরুদ্ধার কর
“লেট ইট ক্র্যাশ” কোনো অবহেলা স্লোগান নয়। এটা একটি নির্ভরযোগ্যতা কৌশল: যখন কোনো কম্পোনেন্ট খারাপ বা অপ্রত্যাশিত অবস্থায় যায়, তখন সেটা ধীরে ধীরে চলার চাইতে দ্রুত এবং স্পষ্টভাবে বন্ধ হওয়া উচিত।
এর বাস্তব অর্থ
একই প্রসেসের ভেতর প্রতিটি সম্ভাব্য এজকেস কেস হ্যান্ডেল করার বদলে, Erlang প্রতিটি ওয়ার্কারকে ছোট ও ফোকাসড রাখার পরামর্শ দেয়। যদি সেই ওয়ার্কার এমন কিছু পায় যা সেটা সামলাতে পারে না (দুর্নীতিগ্রস্ত স্টেট, ভাঙা অনুমান, অপ্রত্যাশিত ইনপুট), এটি exit করে। সিস্টেমের আরেকটি অংশ সেটাকে ফিরিয়ে আনার দায়িত্বে থাকে।
এটি মূল প্রশ্নটি বদলে দেয়: “কিভাবে ব্যর্থতা ঠেকাব?” থেকে “ব্যর্থতা ঘটলে কীভাবে পরিষ্কারভাবে পুনরুদ্ধার করা যায়?”
ট্রেড-অফ: কম প্রতিরক্ষামূলক চেক, পরিষ্কার লজিক
প্রতিটি স্থানে প্রতিরক্ষামূলক কোড লেখা সহজ প্রবাহগুলোকে শর্তের জালায় পরিণত করতে পারে। “লেট ইট ক্র্যাশ” কিছুটা এই জটিলতাকে কমিয়ে দেয় এবং পরিবর্তে দেয়:
- সহজ, পড়তে সুবিধাজনক কোড ফ্লো
- ভাঙা অনুমান দ্রুত সনাক্ত হওয়া
- পুনরুদ্ধার কেন্দ্রভূত এবং পূর্বানুমেয় (কারণ তা কেন্দ্রীভূত)
বড় ধারণা হচ্ছে পুনরুদ্ধার হওয়া উচিত পূর্বনির্ধারিত ও পুনরাবৃত্তিযোগ্য, না প্রতিটি ফাংশনে ইম্প্রোভাইজ করা।
কখন এটি মানায়—এবং কখন মানায় না
এটি সবচেয়ে ভালো কাজ করে যখন ব্যর্থতাগুলো পুনরুদ্ধারযোগ্য এবং আলাদা করা যায়: অস্থায়ী নেটওয়ার্ক সমস্যা, খারাপ অনুরোধ, আটকে থাকা ওয়ার্কার, থার্ড-পার্টি টাইমআউট।
এটি খারাপ ফিট যখন একটি ক্র্যাশ অপরিবর্তনীয় ক্ষতি সৃষ্টি করতে পারে, যেমন:
- দৃঢ় উৎস ছাড়া ডেটা লস
- যেখানে “পুনরায় চেষ্টা করুন” গ্রহণযোগ্য নয় (সেফটি-ক্রিটিকাল অপারেশন)
দ্রুত রিস্টার্ট এবং জানা-ভাল স্টেট
ক্র্যাশ কেবল কাজ করবে যদি ফিরে আসা দ্রুত ও নিরাপদ হয়। বাস্তবে এর মানে হচ্ছে ওয়ার্কারদের একটি জানা-ভাল স্টেটে রিস্টার্ট করা—প্রায়ই কনফিগ লোড করা, ইন-মেমরি ক্যাশগুলো টেকসই স্টোরেজ থেকে পুনর্নির্মাণ করা, এবং ভাঙা স্টেটটি কখনও ছিল না ভেবেই কাজ চালিয়ে না গিয়ে সঠিকভাবে পুনরায় শুরু করা।
সুপারভিশন ট্রি: পরিকল্পিতভাবে ব্যর্থতার জন্য ডিজাইন
Erlang-এর “লেট ইট ক্র্যাশ” তখনই কাজ করে যখন ক্র্যাশগুলো ছেড়ে দেওয়া হয় না। মূল প্যাটার্নটি হল সুপারভিশন ট্রি: একটি হায়ারার্কি যেখানে সুপারভাইজাররা ম্যানেজার মত কাজ করে এবং ওয়ার্কাররা প্রকৃত কাজ করে (কল হ্যান্ডল করা, সেশন ট্র্যাক করা, কিউ খাওয়া ইত্যাদি)। যখন একটি ওয়ার্কার খারাপ আচরণ করে, ম্যানেজার লক্ষ্য করে এবং সেটিকে রিস্টার্ট করে।
ওয়ার্কার রিস্টার্ট করার ম্যানেজাররা
একটি সুপারভাইজার ভাঙ্গা ওয়ার্কারকে জায়গায় ঠিক করার চেষ্টা করে না। বরং এটি একটি সরল, ধারাবাহিক নিয়ম প্রয়োগ করে: যদি ওয়ার্কারটি মরে যায়, একটি নতুনটি শুরু করুন। এটি পুনরুদ্ধার পথকে পূর্বনির্ধারিত করে এবং কোডজুড়ে অ-শৃঙ্খল ত্রুটি হ্যান্ডলিংয়ের প্রয়োজন কমায়।
ততটাই গুরুত্বপূর্ণ, সুপারভাইজাররা সিদ্ধান্ত নিতে পারে কখন রিস্টার্ট না করাই উত্তম—যদি কিছু খুবই বারবার ক্র্যাশ করে, তা গভীর সমস্যা নির্দেশ করতে পারে, এবং বারবার রিস্টার্ট করা পরিস্থিতিকে আরও খারাপ করে তুলতে পারে।
রিস্টার্ট স্ট্র্যাটেজি (উচ্চ-স্তরের)
সুপারভিশন সবক্ষেত্রে একরকম নয়। সাধারণ স্ট্র্যাটেজি অন্তর্ভুক্ত:
- One-for-one: কেবল ব্যর্থ ওয়ার্কারটাই রিস্টার্ট করা হয়। স্বতন্ত্র টাস্কগুলোর জন্য ভাল।
- Group restarts: যদি একটি ওয়ার্কার ফেল হয়, সংশ্লিষ্ট সেটগুলো একসাথে রিস্টার্ট করা হয়। টাইটলি কাপলড কম্পোনেন্টগুলোর জন্য উপযোগী।
ডিপেনডেন্সি: যেটা আপনাকে চিন্তা করতে হবে
ভালো সুপারভিশন ডিজাইন ডিপেনডেন্সি ম্যাপ থেকে শুরু করে: কোন কম্পোনেন্ট কোনগুলোর উপর নির্ভরশীল, এবং “ফ্রেশ স্টার্ট” তাদের জন্য বাস্তবে কী মানে।
যদি একটি সেশন হ্যান্ডলার একটি ক্যাশ প্রসেসের উপর নির্ভরশীল হয়, কেবল হ্যান্ডারটি রিস্টার্ট করলে সেটি একটি খারাপ স্টেটের সঙ্গে যুক্ত থাকতে পারে। সঠিক সুপারভাইজারের অধীনে গ্রুপ করা (অথবা একসাথে রিস্টার্ট করা) জটিল ব্যর্থ মোডগুলোকে পূর্বনির্ধারিত, পুনরাবৃত্তিযোগ্য পুনরুদ্ধার আচরণে পরিণত করে।
OTP: নির্ভরযোগ্য সার্ভিসের পুনঃব্যবহারযোগ্য বিল্ডিং ব্লক
যদি Erlang ভাষা হয়, OTP (Open Telecom Platform) হল সেই কিট-অফ-পার্টস যা “লেট ইট ক্র্যাশ” কে এমন কিছু করে তোলে যা আপনি প্রোডাকশনে বছরের পর বছর চালাতে পারেন।
OTP—প্রুভেন প্যাটার্নের টুলবক্স
OTP একটি একক লাইব্রেরি নয়—এটি কনভেনশন ও প্রস্তুত কম্পোনেন্টের সেট (জানাযায় behaviours) যা সার্ভিস তৈরি করার বোরিং কিন্তু ক্রিটিক্যাল অংশগুলো সমাধান করে:
gen_server: একটি লং-রানিং ওয়ার্কার যে স্টেট রাখে এবং একবারে রিকোয়েস্ট হ্যান্ডেল করেsupervisor: নির্ধারিত নিয়ম মেনে ব্যর্থ ওয়ার্কার অটোমেটিক রিস্টার্ট করেapplication: কীভাবে একটি সার্ভিস শুরু/বন্ধ হয় এবং একটি রিলিজে কিভাবে ফিট করে
এগুলো “জাদু” নয়; এগুলো টেমপ্লেট যা ডিফাইনড কলব্যাকস দিয়ে আপনার কোডকে একটি পরিচিত আকৃতিতে প্লাগ করে।
কেন স্ট্যান্ডার্ড প্যাটার্ন কাস্টম ফ্রেমওয়ার্ক-এ ভালো
টিমগুলো প্রায়ই অ্যাড-হক ব্যাকগ্রাউন্ড ওয়ার্কার, হোমগ্রোন মনিটরিং হুক এবং ওয়ান-অফ রিস্টার্ট লজিক তৈরি করে। এটা কাজ করে—যতক্ষণ না করে না। OTP সেই ঝুঁকি কমায় কারণ সবাইকে একেই ভোকাবুলারি ও লাইফসাইকেলে টেনে আনে। যখন নতুন ইঞ্জিনিয়ার যোগ হয়, তাদের আপনাদের কাস্টম ফ্রেমওয়ার্ক শেখার আগে না, তারা সাধারণ প্যাটার্নগুলোর উপর নির্ভর করতে পারবে।
OTP দৈনন্দিন আর্কিটেকচারে কীভাবে নির্দেশ করে
OTP আপনাকে প্রসেস রোল এবং দায়িত্ব নিয়ে ভাবতে বাধ্য করে: কোনটি ওয়ার্কার, কোনটি কওঅর্ডিনেটর, কোনটি কী রিস্টার্ট করবে, এবং কোনটি কখনও অটোম্যাটিকভাবে রিস্টার্ট করা উচিত নয়।
এটি ভাল হাইজিনও উৎসাহিত করে: স্পষ্ট নামকরণ, নির্দিষ্ট স্টার্টআপ ক্রম, পূর্বানুমেয় শাটডাউন, এবং বিল্ট-ইন মনিটরিং সিগন্যাল। ফলাফল হচ্ছে এমন সফটওয়্যার যা ধারাবাহিকভাবে চলার জন্য ডিজাইন করা—ত্রুটি থেকে পুনরুদ্ধার করতে পারে, সময়ের সাথে বিকাশ করতে পারে, এবং স্থায়ী মানুষের পর্যবেক্ষণ ছাড়া কাজ চালায়।
BEAM VM: সেই রানটাইম যা মডেলকে ব্যবহারিক করে তোলে
Erlang-এর বড় ধারণাগুলো—ছোট প্রসেস, মেসেজ পাসিং, এবং “লেট ইট ক্র্যাশ”—প্রোডাকশনে ব্যবহার করা বেশ কঠিন হত যদি না BEAM ভার্চুয়াল মেশিন (VM) থাকত। BEAM হল সেই রানটাইম যা এই প্যাটার্নগুলোকে সহজ ও নির্ভরযোগ্য করে তোলে।
শিডিউলিং: একটি বড় থ্রেডের পরিবর্তে ন্যায়বিচার
BEAM অনেক লাইটওয়েট প্রসেস চালানোর জন্য তৈরি। OS-থ্রেডগুলোর ওপর নির্ভর করার বদলে BEAM নিজেই Erlang প্রসেসগুলোর শিডিউলিং করে।
প্রায়োগিক সুবিধা হলো লোডের সময় রেসপন্সিভনেস: কাজগুলো ছোট টুকরো করে ঘুরপাক খায়, যাতে কোনো একই ওয়ার্কার সিস্টেম দখল করতে না পারে। এটা সেই সার্ভিসের সাথে ভালোভাবে মেলে যা অনেক স্বাধীন টাস্ক নিয়ে গঠিত—প্রতিটি একটু কাজ করে, তারপর yielding করে।
আইসোলেশন এবং “প্রতি-প্রসেস” মেমরি ক্লিনআপ
প্রতিটি Erlang প্রসেসের নিজস্ব হিপ এবং নিজস্ব গার্বেজ কালেকশন আছে। এটা এক গুরুত্বপূর্ণ বিবরণ: একটি প্রসেসের মেমরি ক্লিনআপে পুরো প্রোগ্রামকে থামাতে হয় না।
ততটাই গুরুত্বপূর্ণ যে, প্রসেসগুলো বিচ্ছিন্ন। একটি ক্র্যাশ হলে এটি দুসরি প্রসেসগুলোর মেমরি নষ্ট করে না এবং VM চালু থাকে। এই আইসোলেশনই সুপারভিশন ট্রি বাস্তবসম্মত করে তোলে: ব্যর্থতা সীমাবদ্ধ করা হয়, তারপর ব্যর্থ অংশটি রিস্টার্ট করে হ্যান্ডেল করা হয় পুরো সিস্টেম ডাউন না করে।
ডিস্ট্রিবিউশন: একাধিক নোড, একটি সিস্টেম
BEAM ডিসট্রিবিউশনও সরলভাবে সাপোর্ট করে: আপনি একাধিক Erlang নোড (বিভিন্ন VM ইনস্ট্যান্স) চালাতে পারেন এবং তাদের মেসেজের মাধ্যমে যোগাযোগ করতে দিতে পারেন। যদি আপনি ‘প্রসেসরা মেসেজ পাঠায়’ ধারণা বুঝে থাকেন, ডিসট্রিবিউশন একই ধারনার এক্সটেনশন—কয়েকটি প্রসেস কিছু কারণে অন্য নোডে থাকলে তাই।
BEAM কাঁচা গতি প্রতিশ্রুতি দেওয়ার জন্য নয়; বরং কনকারেন্সি, ত্রুটি ধারণ এবং পুনরুদ্ধার ডিফল্ট করে তোলার জন্য। তাই নির্ভরযোগ্যতার গল্পটি তত্ত্বীয় নয়, ব্যবহারিক।
সিস্টেম বন্ধ না করে আপগ্রেড (হট কোড, সাবধানে)
Erlang-এর একটি সবচেয়ে আলোচিত কৌশল হল হট কোড সোয়াপিং: চালু থাকা সিস্টেমের অংশ আপডেট করা যাতে ডাউনটাইম কম হয় (যেখানে রানটাইম ও টুলিং এটাকে সমর্থন করে)। ব্যবহারিক প্রতিশ্রুতি হচ্ছে না “কখনও রিস্টার্ট করব না”, বরং “একটি ছোট বাগকে দীর্ঘ আউটেজে রূপান্তর না করে দ্রুত প্যাচ পাঠাতে পারা।”
“হট কোড” বাস্তবে কী বোঝায়
Erlang/OTP-তে রানটাইম একই সময়ে দুইটি মডিউলের সংস্করণ ধরে রাখতে পারে। বিদ্যমান প্রসেসগুলো পুরানো সংস্করণ ব্যবহার করে কাজ শেষ করতে পারে যখন নতুন কলগুলো নতুন সংস্করণ ব্যবহার শুরু করে। এতে আপনি একটি বাগ প্যাচ, ফিচার রোলআউট বা আচরণ সমন্বয় করতে পারেন সবাইকে সিস্টেম থেকে বের করে না দিয়ে।
ভালভাবে করলে, এটি সরাসরি নির্ভরযোগ্যতা লক্ষ্যগুলোকে সমর্থন করে: কম ফুলি রিস্টার্ট, ছোট মেইনটেন্যান্স উইন্ডো, এবং প্রোডাকশনে কিছু লপে গেলে দ্রুত সংশোধন।
যে সীমাবদ্ধতাগুলো কাউকে উপেক্ষা করা উচিত নয়
প্রতি পরিবর্তনই লাইভে নিরাপদ নয়। যা অতিরিক্ত যত্ন প্রয়োজন এমন কিছু উদাহরণ:
- স্টেট আকার-পরিবর্তন (এক প্রসেস এক ফরম্যাটে ডেটা আশা করে, নতুন কোড অন্য ফরম্যাটে)
- সার্ভিসদের মধ্যে প্রোটোকল বা মেসেজ-ফরম্যাট পরিবর্তন যা মিল থাকা আবশ্যক
- সময়সাপেক্ষ স্কিমা মাইগ্রেশন যা সমন্বয় দাবি করে
Erlang নিয়ন্ত্রিত ট্রানজিশনের উপায় দেয়, কিন্তু আপগ্রেড পথ আপনাকে পরিকল্পনা করতেই হবে।
মানসিকতা: আপগ্রেড এবং রোলব্যাক স্বাভাবিক
হট আপগ্রেড সবচেয়ে ভালো কাজ করে যখন আপগ্রেড ও রোলব্যাক রুটিন অপারেশন হিসেবে দেখা হয়, বিরল জরুরি হিসেবে নয়। এর মানে ভার্সনিং, সামঞ্জস্য এবং স্পষ্ট “আনডু” পথ শুরু থেকে প্ল্যান করা। প্রকটিক ভাবে, দলগুলো লাইভ-আপগ্রেড কৌশলগুলো স্টেজড রোলআউট, হেলথ চেক, এবং সুপারভিশন-ভিত্তিক পুনরুদ্ধারের সাথে জোড়া দেয়।
আপনি যদি কখনও Erlang না ব্যবহার করেনও, শিক্ষা স্থানান্তরযোগ্য: সিস্টেমগুলো এমনভাবে ডিজাইন করুন যাতে সেগুলোকে নিরাপদে বদলানো প্রথম-শ্রেণির দাবী হয়, পরের কথা নয়।
রিয়েল-টাইম প্ল্যাটফর্মে Erlang-এর ধারণাগুলো কোথায় উজ্জ্বলভাবে কাজ করে
রিয়েল-টাইম প্ল্যাটফর্মগুলো নিখুঁত টাইমিংয়ের তুলনায় বেশি এমন কিছু: পরিস্থিতি যেখানে সিস্টেম প্রতিক্রিয়াশীল থাকে যদিও জিনিসপত্র ক্রমাগত ভগ্ন হচ্ছে—নেটওয়ার্ক দুলছে, ডিপেনডেন্সি ধীর হচ্ছে, ইউজার ট্রাফিক স্পাইক করে। জো আর্মস্ট্রং দ্বারা প্রচারিত Erlang ডিজাইন এই বাস্তবতাকে মানে কারণ এটি ব্যর্থতাকে ধরে নেয় এবং কনকারেন্সিকে সাধারণ বানায়, ব্যতিক্রম নয়।
সাধারণ “রিয়েল-টাইম” ব্যবহারকেস
আপনি Erlang-স্টাইল চিন্তাভাবনা দেখতে পাবেন যেখানে অনেক স্বাধীন কার্য একই সময়ে ঘটে:
- মেসেজিং ও চ্যাট: লক্ষ লক্ষ ছোট কথোপকথন, প্রতিটির নিজস্ব স্টেট ও রেট্রাই সহ।
- রিয়েল-টাইম কমিউনিকেশন: ভয়েস/ভিডিও সিগনালিং, প্রেসেন্স আপডেট, এবং সেশন কোঅর্ডিনেশন।
- IoT কোঅর্ডিনেশন: ডিভাইসের বহর যা অনিয়মিতভাবে চেক-ইন করে, অনুপস্থিত হয় এবং আবার উপস্থিত হয়।
- পেমেন্টস ওয়ার্কফ্লো: বহু-ধাপ প্রক্রিয়া যেখানে কিছু ধাপ ধীর বা অনুপলব্ধ হতে পারে এবং ক্ষতিপূরণমূলক কাজ প্রয়োজন হতে পারে।
“সফট রিয়েল-টাইম” সাধারণত কী বোঝায়
অধিকাংশ প্রোডাক্টের হার্ড গ্যারান্টি লাগে না যেমন “প্রতি অ্যাকশন ১০ ms-এ শেষ হবে।” তারা চায় সফট রিয়েল-টাইম: সাধারণ অনুরোধগুলোর জন্য ধারাবাহিকভাবে কম লেটেন্সি, অংশ ব্যর্থ হলে দ্রুত পুনরুদ্ধার, এবং উচ্চ উপলব্ধতা যাতে ব্যবহারকারীরা খুব কমই ইনসিডেন্ট অনুভব করে।
ব্যর্থতা স্বাভাবিক: তাই ডিজাইনও তাই
বাস্তব সিস্টেমগুলো সমস্যায় পড়ে যেমন:
- ড্রপড কানেকশন (মোবাইল নেটওয়ার্ক, Wi‑Fi হ্যান্ডঅফ)
- টাইমআউট যখন ডাউনস্ট্রিম সার্ভিস ধীর
- আংশিক আউটেজ যেখানে একটি রিজন বা ডিপেনডেন্সি খারাপ থাকে
Erlang-এর মডেল প্রতিটি কার্য (একটি ইউজার সেশন, একটি ডিভাইস, একটি পেমেন্ট অ্যাটেম্পট) আলাদা করে ডিজাইন করতে উৎসাহ দেয় যাতে একটি ব্যর্থতা ছড়ায় না। এক বিশাল “সবকিছু চেষ্টা করতে হবে” কম্পোনেন্টের বদলে দলগুলো ছোট ইউনিটে চিন্তা করতে পারে: প্রতিটি ওয়ার্কার এক কাজ করে, মেসেজ পাঠায়, এবং ভেঙে গেলে সাভারভিশার সেইটাকে পরিষ্কারভাবে রিস্টার্ট করে।
এই পরিবর্তন—“প্রতি ব্যর্থতা প্রতিরোধ করা” থেকে “বাড়ি করে দ্রুত সীমাবদ্ধ ও পুনরুদ্ধার কর” পর্যন্ত—ই প্রায়শই রিয়েল-টাইম প্ল্যাটফর্মকে চাপের সময়ে স্থিতিশীল অনুভব করায়।
সাধারণ ভুল বোঝাবুঝি এবং বাস্তব সীমাবদ্ধতা
Erlang-এর খ্যাতি এমন একটা প্রতিশ্রুতি শোনায়: সিস্টেমগুলো কখনও ডাউন হবে না কারণ শুধু রিস্টার্ট করলে হয়। বাস্তবতা বেশি ব্যবহারিক এবং বেশি উপকারী। “লেট ইট ক্র্যাশ” নির্ভরযোগ্য সার্ভিস তৈরির একটি টুল—গভীর সমস্যাগুলো উপেক্ষা করার লাইসেন্স নয়।
রিস্টার্টগুলো ব্যান্ড-এড নয়
একটি সাধারণ ভুল হলো সুপারভিশনকে একটি গভীর বাগ লুকানোর উপায় হিসেবে দেখা। যদি একটি প্রসেস শুরু হতেই তাত্ক্ষণিকভাবে ক্র্যাশ করে, সুপারভাইজার তা রিস্টার্ট করে যতক্ষণ না আপনার CPU পুড়িয়ে দেয়, লগ স্প্যাম করে, এবং সম্ভবত মূল বাগের চেয়েও বড় আউটেজ তৈরি করে।
ভাল সিস্টেম ব্যাকঅফ, রিস্টার্ট ইনটেনসিটি সীমা, এবং স্পষ্ট “দেখো ও এসক্যালেট কর” আচরণ যোগ করে। রিস্টার্টগুলো সিস্টেমকে সুস্থ অবস্থায় ফিরিয়ে আনার জন্য হওয়া উচিত, ভাঙা ইনভারিয়েন্ট লুকোয়ানোর জন্য নয়।
স্টেটই কঠিন অংশ
একটি প্রসেস রিস্টার্ট করা প্রায়ই সহজ; সঠিক স্টেট পুনরুদ্ধার কঠিন। যদি স্টেট শুধুই মেমরিতে থাকে, তাহলে ক্র্যাশের পর “সঠিক” কী তা নির্ধারণ করতে হবে:
- আপনি কি টেকসই স্টোরেজ থেকে পুনর্নির্মাণ করবেন?
- আপনি কি ইভেন্ট পুনরায় বাজাতে পারেন (আইডেমপটেন্ট)?
- ইন-ফ্লাইট কাজ বা আংশিক আপডেট কী হবে?
ত্রুটি সহনশীলতা যতটা না প্রযুক্তিগত কৌশল, ততটাই স্পষ্ট ডেটা ডিজাইনের দাবি করে।
আপনাকে এখনও অবজারভেবিলিটিতে বিনিয়োগ করতে হবে
ক্র্যাশগুলো তখনই সাহায্য করে যখন আপনি সেগুলো দ্রুত দেখতে এবং বুঝতে পারেন। এর মানে হলো লগিং, মেট্রিক্স, এবং ট্রেসিং-এ বিনিয়োগ—শুধু “এটা রিস্টার্ট হয়েছে, তাই ঠিক আছে” নয়। আপনাকে বাড়তে থাকা রিস্টার্ট রেট, বাড়তে থাকা কিউ, এবং ধীর ডিপেনডেন্সিগুলো আগে থেকেই দেখতে হতে হবে।
বাস্তব অপারেশনাল সীমাবদ্ধতা আছে
BEAM-এর শক্তির পরেও, সিস্টেমগুলো খুব সাধারণ উপায়ে ব্যর্থ হতে পারে:
- মেমরি বৃদ্ধি লিক, ক্যাশ, বা বড় হিপ থেকে
- মেইলবক্স ব্যাকলগ যখন প্রডিউসার কনসিউমারকে ছাড়িয়ে যায় (লেটেন্সি স্পাইক ও টাইমআউট)
- ডিপেনডেন্সি ফেইলিউর (ডাটাবেস, তৃতীয় পক্ষের APIs, DNS) যেখানে আপনার কোড রিস্টার্ট করলে রুট কারণ ঠিক হয় না
Erlang-এর মডেল ত্রুটি সীমাবদ্ধ ও পুনরুদ্ধারে সাহায্য করে—কিন্তু এটি ত্রুটিগুলো দূর করে না।
আজ কীভাবে এই পাঠগুলো প্রয়োগ করবেন (যদি আপনি Erlang ব্যবহার না করেন)
Erlang-এর সবচেয়ে বড় উপহার সিনট্যাক্স নয়—এটি এমন অভ্যাসের সেট যা সিস্টেমগুলোকে চলতে রাখে যখন অংশগুলো অবশ্যই ব্যর্থ হবে। আপনি প্রায় যেকোন স্ট্যাকে এই অভ্যাসগুলো প্রয়োগ করতে পারবেন।
ধারনাগুলোকে বাস্তব কাজগুলোতে অনুবাদ করুন
প্রথমে ব্যর্থতা সীমানা স্পষ্ট করুন। আপনার সিস্টেমকে এমন কম্পোনেন্টে ভেঙে ফেলুন যা স্বাধীনভাবে ব্যর্থ হতে পারে, এবং প্রতিটি অংশের স্পষ্ট কনট্রাক্ট রাখুন (ইনপুট, আউটপুট এবং “খারাপ” কী)।
তারপর প্রতিরোধের বদলে পুনরুদ্ধার অটোমেট করুন:
- কম্পোনেন্ট আলাদা করা: ঝুঁকিপূর্ণ কাজ আলাদা প্রসেস/কন্টেইনার/থ্রেডে চালান যাতে একটি ক্র্যাশ সবকিছু নষ্ট না করে।
- সীমা নির্ধারণ: টাইমআউট, ব্যাকঅফ সহ রিট্রাই, সার্কিট ব্রেকার, এবং বাল্কহেড ব্যবহার করুন।
- পুনরুদ্ধার রুটিন করা: হেলথ চেক, অটো-রিস্টার্ট, এবং নিরাপদ ডিফল্ট যাতে সিস্টেম দ্রুত জানা-ভাল অবস্থায় ফিরতে পারে।
একটি বাস্তব উপায় হলো এই অভ্যাসগুলো টুলিং ও লাইফসাইকলে বেক করা। উদাহরণস্বরূপ, যখন দলগুলো Koder.ai ব্যবহার করে চ্যাটের মাধ্যমে ওয়েব, ব্যাকএন্ড, বা মোবাইল অ্যাপ কোড করে, ওয়ার্কফ্লোটি স্বাভাবিকভাবেই স্পষ্ট পরিকল্পনা (Planning Mode), পুনরাবৃত্ত ডিপ্লয়মেন্ট, এবং স্ন্যাপশট ও রোলব্যাকের সাথে নিরাপদ iteration উৎসাহিত করে—এইগুলোই Erlang যে অপারেশনাল মানসিকতা জনপ্রিয় করেছে তার সঙ্গে ঠিক মিলে যায়: পরিবর্তন ও ব্যর্থতা হবে, এবং পুনরুদ্ধারকে বিরক্তিকর করা।
Erlang ছাড়া শুরু করার পয়েন্টসমূহ
আপনি ব্যবহার করা টুলগুলোর মাধ্যমে “সুপারভিশন” প্যাটার্নগুলো অনুকরণ করতে পারেন:
- সুপারভাইজার: systemd, Kubernetes Deployments, বা কোনো প্রসেস ম্যানেজার (restart-on-failure, readiness probes)
- প্রসেস আইসোলেশন: CPU-হেভি বা অট্রাস্টেড টাস্কের জন্য আলাদা ওয়ার্কার সার্ভিস
- মেসেজ পাসিং: কিউ/স্ট্রিম (RabbitMQ, SQS, Kafka) প্রোডিউসার ও কনজিউমার আলাদা করতে এবং স্পাইক মসৃণ করতে
দ্রুত সিদ্ধান্ত নেয়ার চেকলিস্ট
প্যাটার্নগুলো কপি করার আগে সিদ্ধান্ত নিন আপনি আসলে কী প্রয়োজন:
- প্রত্যাশিত ত্রুটি মোড: ওভারলোড, আংশিক আউটেজ, ধীর ডিপেনডেন্সি, খারাপ ইনপুট, মেমরি লিক
- লেটেন্সি চাহিদা: আপনি কি রিয়েল-টাইম প্রতিক্রিয়া চাইছেন, না কি ইভেন্টুয়াল প্রসেসিং চলবে?
- পুনরুদ্ধার উদ্দেশ্য: দ্রুত রিস্টার্ট, গ্রেসফুল ডিগ্রেডেশন, নাকি ম্যানুয়াল হস্তক্ষেপ?
- টিম স্কিল ও টুলিং: কে অন‑কল, অবজারভেবিলিটি, এবং ইনসিডেন্ট রেসপন্স দেখবে?
যদি আপনি অনুশীলনগত পরবর্তী পদক্ষেপ চান, /blog-এ আরও গাইড দেখুন, অথবা /docs-এ ইমপ্লিমেন্টেশন ডিটেইলস ব্রাউজ করুন (আর যদি টুলিং মূল্যায়ন করেন, /pricing দেখে নেবেন)।
সাধারণ প্রশ্ন
কেন জো আর্মস্ট্রং এর Erlang মানসিকতা আজও প্রাসঙ্গিক?
Erlang একটি বাস্তবসম্মত নির্ভরযোগ্যতা মানসিকতা জনপ্রিয় করে তুলেছে: অংশগুলো ব্যর্থ হবে বলে ধরুন এবং ঠিক তখন কী হবে তা ডিজাইন করুন.
প্রতিটি ক্র্যাশ প্রতিরোধের চেষ্টা করার বদলে এটি জোর দেয় ত্রুটি আলাদা রাখা, দ্রুত সনাক্তকরণ, এবং স্বয়ংক্রিয় পুনরুদ্ধার-এর উপর, যা চ্যাট, কল রাউটিং, নোটিফিকেশন এবং কোঅর্ডিনেশন সার্ভিসগুলোর মতো রিয়েল-টাইম প্ল্যাটফর্মের সঙ্গে ভালোভাবে মিলে যায়।
পোস্টে “রিয়েল-টাইম” সাধারণ কথায় কী বোঝায়?
এখানে “রিয়েল-টাইম” সাধারণ ভাষায় সাধারণত সফট রিয়েল-টাইম বোঝায়:
- উত্তরগুলো দ্রুত এবং ধারাবাহিকভাবে অনুভূত হয়
- লোডের সময় আচরণ পূর্বনির্ধারিত থাকে
- আংশিক ব্যর্থতার মাঝেও সিস্টেম কাজ চালিয়ে যায়
এটা মাইক্রোসেকেন্ড গ্যারান্টির ব্যাপার নয়; বরং স্টল, স্ফিয়াল বা ক্যাসকেডিং আউটেজ এড়ানোই মূল সমস্যা।
Erlang-স্টাইল ডিজাইনে “কনকারেন্সি বাই ডিফল্ট” মানে কী?
কনকারেন্সি-উইথ-ডিফল্ট মানে সিস্টেমকে অনেক ছোট, বিচ্ছিন্ন ওয়ার্কার হিসেবে গঠন করা, বড় ও টাইটলি-কাপলড কম্পোনেন্টের বদলে।
প্রতিটি ওয়ার্কার একটি সংকীর্ণ দায়িত্ব অনুসরণ করে (একটি সেশন, ডিভাইস, কল, retry লুপ), ফলে স্কেল করা এবং ত্রুটি সীমিত রাখা সহজ হয়।
Erlang-এ “লাইটওয়েট প্রসেস” কী, এবং কেন তা গুরুত্বপূর্ণ?
লাইটওয়েট প্রসেসগুলো ছোট, স্বাধীন ওয়ার্কার যেগুলো আপনি অনেক সংখ্যায় তৈরি করতে পারেন।
প্রায়োগিকভাবে এর সুবিধাগুলো:
- আপনি প্রতিটি “বস্তুর” জন্য একটি প্রসেস মডেল করতে পারেন (ব্যবহারকারী/সেশন/ডিভাইস)
- ত্রুটিগুলো একক ওয়ার্কারে সীমাবদ্ধ থাকে
- একটি মনোলিথ রিবুট করার চাইতে কাজ পুনরায় শুরু করা সস্তা
Erlang কেন শেয়ার্ড স্টেটের বদলে মেসেজ পাসিংকে প্রাধান্য দেয়?
মেসেজ পাসিং মানে সমন্বয় ঘটে মেসেজ পাঠানোর মাধ্যমে, ভাগ করা মিউটেবল স্টেটের বদলে।
এটি অনেক ধরণের কনকারেন্সি বাগ (যেমন রেস কন্ডিশন) কমায় কারণ প্রতিটি ওয়ার্কার তার অভ্যন্তরীণ স্টেটের মালিক; অপর ওয়ার্কাররা শুধুমাত্র মেসেজ পাঠিয়ে অনুরোধ করতে পারে।
অ্যাক্টর/মেসেজ সিস্টেমে ব্যাক-প্রেশার কী, এবং কীভাবে এটি মোকাবিলা করবেন?
ব্যাক-প্রেশার তখনই ঘটে যখন একটি ওয়ার্কার মেসেজ প্রক্রিয়াকরণের চেয়ে দ্রুত মেসেজ পাচ্ছে, ফলে তার মেইলবক্স বড় হয়।
প্রায়োগিকভাবে মোকাবেলার উপায়গুলো:
- মেইলবক্স/কিউ সাইজ মনিটর করা
- সীমা আরোপ (ড্রপ, স্যাম্পল, বা ক্যাপ) করা
- লোড আরও বেশি ওয়ার্কারের মাঝে ছড়িয়ে দেওয়া
- নরমভাবে дег্রেড করা (উদাহরণ: অ-সমালোচনীয় নোটিফিকেশনগুলোর জন্য ডাইজেস্ট মোড)
“লেট ইট ক্র্যাশ” বাস্তবে কী বোঝায় (এবং কী বোঝায় না)?
“লেট ইট ক্র্যাশ” মানে: যদি কোনো ওয়ার্কার অনিয়ন্ত্রিত বা অপ্রত্যাশিত অবস্থায় পৌঁছে যায়, তবে তা দ্রুত ব্যর্থ হোক ঠিক করার চেষ্টা না করে।
পুনরুদ্ধার কাঠামোগতভাবে (সুপারভিশন-দ্বারা) হ্যান্ডেল করা হয়, যা সহজ ওর্য়াক ফ্লো এবং পূর্বনির্ধারিত পুনরুদ্ধার দেয়—শর্ত হলো রিস্টার্ট দ্রুত এবং নিরাপদ হতে হবে।
সুপারভিশন ট্রি কী, এবং কেন তা ত্রুটি সহনশীলতার জন্য কেন্দ্রীয়?
সুপারভিশন ট্রি হল এমন একটি হায়ারার্কি যেখানে সুপারভাইজাররা ওয়ার্কারদের মনিটর করে এবং নির্ধারিত নিয়ম অনুসারে সেগুলো রিস্টার্ট করে।
এটি অ্যাড-হক রিকভারি ছড়িয়ে দেওয়ার বদলে কেন্দ্রীভূত করে:
- কোনো কিছু ব্যর্থ হলে কী রিস্টার্ট হবে তা নির্ধারণ করে
- অনন্ত ক্র্যাশ লুপ রোধ করতে ব্যাকঅফ/লিমিট প্রয়োগ করে
- যখন উপাদানগুলোকে সিঙ্কে রাখার প্রয়োজন হয় তখন গ্রুপ রিস্টার্ট করে
OTP কী, এবং এটি কীভাবে নির্ভরযোগ্য সার্ভিস গড়তে সাহায্য করে?
OTP হল মানদণ্ডসম্বলিত প্যাটার্ন (behaviours) ও রীতিনীতি সেট যা Erlang সিস্টেমকে দীর্ঘমেয়াদে পরিচালনাযোগ্য করে তোলে।
সাধারণ বিল্ডিং ব্লকগুলো:
gen_server— স্টেটফুল লং‑রানিং ওয়ার্কারsupervisor— ফেইল হলে অটোমেটিক রিস্টার্ট নীতিapplication— সার্ভিস কিভাবে স্টার্ট/স্টপ করে এবং রিলিজে ফিট হয়
সাধারণ লাইফসাইকেল ও অভিহিত প্যাটার্নগুলো দলগুলোর জন্য ঝুঁকি কমায়।
যদি আমি Erlang ব্যবহার না করি, তাহলে কীভাবে এর শিক্ষা প্রয়োগ করব?
কাছাকাছি ধারণাগুলোকে বাস্তবে লাগাতে:
- ঝুঁকিপূর্ণ কাজ আলাদা প্রসেস/কন্টেইনার/থ্রেডে চালান
- টাইমআউট, ব্যাকঅফ সহ রিটার্ন, সার্কিট ব্রেকার এবং বাল্কহেড ব্যবহার করুন
- হেলথ চেক, অটো-রিস্টার্ট এবং নিরাপদ ডিফল্ট দিয়ে পুনরুদ্ধার স্বয়ংক্রিয় করুন
- প্রোডিউসার ও কনজিউমার আলাদা করতে কিউ/স্ট্রিম (RabbitMQ, SQS, Kafka) ব্যবহার করুন
আরো গাইড পেতে /blog দেখুন, ইমপ্লিমেন্টেশন-ডিটেইলসের জন্য /docs, এবং টুলিং মূল্যায়নের জন্য /pricing ব্রাউজ করুন।