২২ সেপ, ২০২৫·8 মিনিট
Kafka কী এবং আধুনিক সিস্টেমে এটি কীভাবে ব্যবহৃত হয়?
জানুন Apache Kafka কী, টপিক ও পার্টিশন কীভাবে কাজ করে, এবং রিয়েল‑টাইম ইভেন্ট, লগ ও ডাটা পাইপলাইনে Kafka আধুনিক সিস্টেমে কোথায় উপযোগী।
জানুন Apache Kafka কী, টপিক ও পার্টিশন কীভাবে কাজ করে, এবং রিয়েল‑টাইম ইভেন্ট, লগ ও ডাটা পাইপলাইনে Kafka আধুনিক সিস্টেমে কোথায় উপযোগী।
Apache Kafka হলো একটি বিতরণকৃত ইভেন্ট স্ট্রিমিং প্ল্যাটফর্ম। সহজভাবে বললে, এটি একটি শেয়ার করা, স্থায়ী “নলিকা” যা অনেক সিস্টেমকে ঘটে যাওয়া বিষয়গুলি প্রকাশ করতে দেয় এবং অন্য সিস্টেমগুলো সেই বিষয়গুলো দ্রুত, স্কেলে এবং ধারাবাহিকভাবে পড়তে পারে।
টিমগুলো Kafka ব্যবহার করে যখন ডেটা বিশ্বস্তভাবে সিস্টেমগুলোর মধ্যে সরাতে হয় এবং কঠোর ভাবে কাপল করা ঠিক না। একটি অ্যাপ সরাসরি অন্যটিকে কল করার বদলে (যা ডাউন বা ধীর হলে সমস্যা হবে), প্রোডিউসাররা ইভেন্টগুলো Kafka-তে লেখে। কনসিউমাররা যখন প্রস্তুত তখন সেগুলো পড়ে। Kafka ইভেন্টগুলো একটি কনফিগারেবল সময় পর্যন্ত সংরক্ষণ করে, তাই সিস্টেমগুলো আউটেজ থেকে পুনরুদ্ধার করতে পারে এবং ইতিহাস পুনঃপ্রক্রিয়া করতেও পারে।
এই গাইডটি প্রোডাক্ট-মাইন্ডেড ইঞ্জিনিয়ার, ডাটা পেশাজীবী এবং প্রযুক্তিগত নেতা যারা Kafka‑এর একটি ব্যবহারিক মানসিক মডেল চান তাদের জন্য।
আপনি শিখবেন মূল উপাদানগুলো (প্রোডিউসার, কনসিউমার, টপিক, ব্রোকার), পার্টিশনের মাধ্যমে Kafka কিভাবে স্কেল করে, এটি কিভাবে ইভেন্ট সংরক্ষণ ও রি‑প্লে করে, এবং ইভেন্ট-ড্রিভেন আর্কিটেকচারে কোথায় ফিট করে। আমরা সাধারণ ইউজকেস, ডেলিভারি গ্যারান্টি, নিরাপত্তার মূল বিষয়, অপারেশন পসরা পরিকল্পনা, এবং কখন Kafka ঠিক টুল নয়—সেগুলোও কভার করব।
Kafka‑কে বুঝতে সহজ হলে তা হলো একটি শেয়ার করা ইভেন্ট লগ: অ্যাপগুলো এতে ইভেন্ট লিখে, আর অন্য অ্যাপগুলো পরে সেগুলো পড়ে—প্রায়শই রিয়েল‑টাইমে, কখনো কখনো ঘন্টার বা দিনের পরেও।
প্রোডিউসার হলো লেখক। এক প্রোডিউসার “order placed”, “payment confirmed”, বা “temperature reading” মতো ইভেন্ট পাবলিশ করতে পারে। প্রোডিউসাররা ইভেন্টগুলো নির্দিষ্ট অ্যাপে পাঠায় না—তারা Kafka-তে পাঠায়।
কনসিউমার হলো পাঠক। একটি কনসিউমার ড্যাশবোর্ড চালাতে পারে, শিপমেন্ট ওয়ার্কফ্লো ট্রিগার করতে পারে, অথবা অ্যানালিটিক্সে ডেটা লোড করতে পারে। কনসিউমাররা সিদ্ধান্ত নেয় যে ইভেন্টগুলোর সাথে কী করা হবে, এবং তারা নিজেদের গতি অনুযায়ী পড়ে।
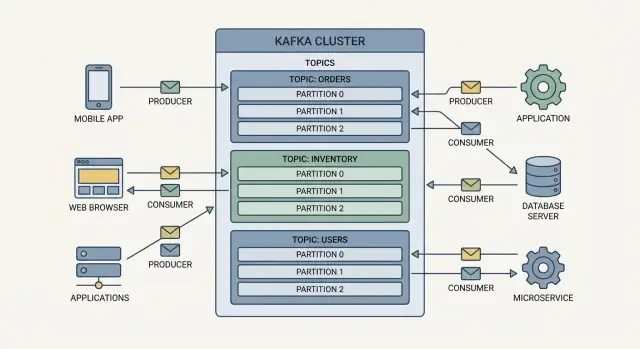
Kafka‑র ইভেন্টগুলো টপিক এ গ্রুপ করা হয়—প্রায়ই নামকৃত ক্যাটেগরি। উদাহরণ:
orders — অর্ডার সম্পর্কিত ইভেন্টpayments — পেমেন্ট ইভেন্টinventory — স্টক পরিবর্তনএকটি টপিক ঐ ধরনের ইভেন্টের “সোর্স অফ ট্রুথ” স্ট্রিমে পরিণত হয়, যা একাধিক টিমকে একই ডেটা পুনরায় ব্যবহার করতে সহজ করে তোলে—এক-অফ ইন্টিগ্রেশন না বানিয়েই।
ব্রোকার হলো একটি Kafka সার্ভার যা ইভেন্টগুলো সংরক্ষণ করে এবং কনসিউমারদের সেগুলো পরিবেশন করে। বাস্তবে, Kafka একটি ক্লাস্টার (একাধিক ব্রোকার একসাথে কাজ করে) হিসেবে চালানো হয় যাতে এটি বেশি ট্রাফিক হ্যান্ডেল করতে পারে এবং একটি মেশিন ফেল হলে চালু রাখতে পারে।
কনসিউমাররা প্রায়ই একটি কনসিউমার গ্রুপ এ চলে। Kafka গ্রুপের মধ্যে পড়া কাজ ভাগ করে দেয়, তাই আপনি প্রসেসিং স্কেল আউট করতে পারেন—প্রতিটি ইনস্ট্যান্স একই কাজ করে না।
Kafka স্কেল করে কাজকে ভাগ করে নিয়ে: প্রথমে বিষয়ভিত্তিক স্ট্রিমগুলিকে টপিক এ বিভাজন করে এবং প্রতিটি টপিককে ছোট, স্বাধীন ফালি হিসেবে পার্টিশন এ ভাগ করে।
একটি টপিক যার একটি পার্টিশন আছে সেটি একই গ্রুপের এক কনসিউমার দ্বারা একবারে পড়া যাবে। পার্টিশন বাড়ালে আপনি আরও কনসিউমার যোগ করে ইভেন্টসমূহ সমান্তরালে প্রক্রিয়াকরণ করতে পারেন। এভাবেই Kafka উচ্চ-ভলিউম ইভেন্ট স্ট্রিমিং এবং রিয়েল‑টাইম ডাটা পাইপলাইন সমর্থন করে।
পার্টিশন ব্রোকার জুড়ে লোড ছড়িয়ে দিতে সাহায্য করে—একটি টপিকের সব রাইট/রিড এক মেশিনে না পড়ে, বিভিন্ন ব্রোকার আলাদা পার্টিশন হোস্ট করে ট্রাফিক ভাগ করে নেয়।
Kafka একটি একক পার্টিশনের ভেতরে অর্ডারিং গ্যারান্টি দেয়। যদি ইভেন্ট A, B, C একই পার্টিশনে সেই ক্রমে লেখা হয়, কনসিউমাররা তাদের A → B → C ক্রমে পড়বে।
পার্টিশনগুলোর মধ্যেকার অর্ডারিং গ্যারান্টি নেই। যদি নির্দিষ্ট এন্টিটির জন্য কঠোর ক্রমানুশাসন দরকার হয় (যেমন একটি কাস্টমার বা অর্ডার), সাধারণত সেই এন্টিটির সব ইভেন্ট একই পার্টিশনে পাঠানো হয়।
প্রোডিউসাররা ইভেন্ট পাঠানোর সময় একটি কী (যেমন order_id) দিতে পারে। Kafka কী ব্যবহার করে সংশ্লিষ্ট ইভেন্টগুলোকে একই পার্টিশনে ধারাবাহিকভাবে রুট করে। এতে ঐ কী‑এর জন্য ভবিষ্যদ্বাণীমূলক অর্ডারিং পাওয়া যায়, তবু পুরো টপিক বহু পার্টিশনে স্কেল করতে পারে।
প্রতিটি পার্টিশন অন্যান্য ব্রোকারে রিপ্লিকেট করা যায়। যদি একটি ব্রোকার ব্যর্থ হয়, অন্য রিপ্লিকা থাকার কারণে সেটি দায়িত্ব নেবে। রেপ্লিকেশনই Kafka‑কে মিশন‑ক্রিটিক্যাল পাব‑সাব মেসেজিং ও ইভেন্ট‑ড্রিভেন সিস্টেমে বিশ্বাসযোগ্য করে তোলে: এটি উপলব্ধতা বাড়ায় এবং ফল্ট টলারেন্স দেয়।
Apache Kafka‑র একটি মূল ধারণা হলো ইভেন্টগুলো কেবল হ্যান্ড‑অফ করা হয় না—তারা ডিস্কে লেখা হয় একটি সাজানো লগে, তাই কনসিউমাররা এখন বা পরে সেগুলো পড়তে পারে। এ কারণে Kafka কেবল ডেটা সরানোর জন্য নয়, ঘটনার স্থায়ী ইতিহাস রাখার জন্যও শক্তিশালী।
প্রোডিউসার যখন একটি ইভেন্ট টপিকে পাঠায়, Kafka সেটি ব্রোকারে স্টোরেজে যোগ করে। কনসিউমাররা তারপর সেই সংরক্ষিত লগ থেকে নিজেদের গতি অনুসারে পড়ে। যদি একটি কনসিউমার এক ঘণ্টা ডাউন থাকে, ইভেন্টগুলো তখনও থাকবে এবং পুনরায় ক্যাচ‑আপ করা যাবে।
Kafka টপিক অনুযায়ী ইভেন্ট রাখে:
প্রতি টপিকে রিটেনশন কনফিগার করা যায়, তাই আপনি অডিট‑ট্রেইল টপিকগুলোকে হাই‑ভ্যালু হিসেবে দীর্ঘ সময় ধরে রাখতে পারেন কিন্তু হাই‑ভলিউম টেলিমেট্রি দ্রুত ঘুরিয়ে দিতে পারেন।
কিছু টপিক পুরো ইতিহাসের চাইতে চেঞ্জলগের মতো—উদাহরণ: “বর্তমান কাস্টমার সেটিংস।” লগ কমপ্যাকশন প্রতিটি কী‑এর অন্তত সর্বশেষ ইভেন্টটি রাখে, পুরনো প্রতিস্থাপিত রেকর্ডগুলো মুছে দেয়। এতে সীমাহীন বৃদ্ধির পরিবর্তে সর্বশেষ স্টেটের একটি স্থায়ী সোর্স থাকে।
ইভেন্টগুলো স্টোর হওয়ায় আপনি সেগুলো রি‑প্লে করে স্টেট পুনর্নির্মাণ করতে পারেন:
প্রায়োগিকভাবে, রি‑প্লে নির্ধারিত হয় কনসিউমারের “কোথা থেকে পড়া শুরু করছে” (অফসেট) দ্বারা, যা টিমগুলিকে একটি শক্তিশালী সেফটি নেট দেয়।
Kafka এমনভাবে নির্মিত যাতে সিস্টেমের অংশগুলো বিফলে গেলেও ডেটা প্রবাহ অব্যাহত থাকে। এটি করে রেপ্লিকেশন, প্রতিটি পার্টিশনের “কে লিডার” সে সম্পর্কে স্পষ্ট নিয়ম, এবং কনফিগারেবল রাইট অ্যাকনলেজমেন্ট দিয়ে।
প্রতিটি টপিক পার্টিশনের একটি লিডার ব্রোকার এবং এক বা একাধিক ফলোয়ার রিপ্লিকা থাকে। প্রোডিউসার ও কনসিউমাররা ঐ পার্টিশনের জন্য লিডারের সাথে যোগাযোগ করে।
ফলোয়াররা লিডারের ডেটা কপি করে রাখে। যদি লিডার ডাউন হয়, Kafka আপ‑টু‑ডেট থাকা ফলোয়ারদের মধ্যে থেকে একজনকে প্রমোট করে নতুন লিডার বানাতে পারে, যাতে পার্টিশন উপলব্ধ থাকে।
যদি একটি ব্রোকার ফেল করে, যে পার্টিশনগুলো তা লিড করছিল তা সাময়িকভাবে অনুপলব্ধ হতে পারে। Kafka‑র কন্ট্রোলার এই ফেল খুঁজে বের করে এবং ঐ পার্টিশনগুলোর জন্য লিডার ইলেকশন ট্রিগার করে।
যদি কমপক্ষে একটি ফলোয়ার ইন‑সিঙ্ক থাকে, তা লিডার হিসেবে উঠতে পারে এবং ক্লায়েন্টরা আবার প্রোডিউস/কনসিউম করতে পারে। যদি কোনো ইন‑সিঙ্ক রিপ্লিকা না থাকে, Kafka কনফিগারেশন অনুযায়ী রাইট থামাতে পারে যাতে অ্যাকনলেজড ডেটা হারিয়ে না যায়।
দুইটি প্রধান কনফিগারেশন ডিউরেবিলিটি নির্ধারণ করে:
কনসেপ্টুয়ালি:
রিট্রাই‑এর সময় ডুপ্লিকেট কমাতে টিমরা প্রায়ই নিরাপদ acks সেটিংসের সঙ্গে idempotent প্রোডিউসার এবং শক্ত কনজিউমার হ্যান্ডলিং ব্যবহার করে।
উচ্চতর নিরাপত্তা সাধারণত বেশি কনফার্মেশনের জন্য অপেক্ষা করা এবং আরো রিপ্লিকা সিঙ্ক রাখার প্রয়োজন হয়, যা ল্যাটেন্সি বাড়াতে এবং পিক থ্রুপুট কমাতে পারে।
কম ল্যাটেন্সি সেটিংস টেলিমেট্রি বা ক্লিকস্ট্রিমের মতো ক্ষেত্রে গ্রহণযোগ্য যেখানে মাঝে মাঝে ডেটা লস মানা যায়; কিন্তু পেমেন্ট, ইনভেন্টরি এবং অডিট লগ সাধারণত অতিরিক্ত নিরাপত্তা সাধিত করে।
ইভেন্ট‑ড্রিভেন আর্কিটেকচার (EDA) হলো এমন একটি উপায়ে সিস্টেম গঠন যেখানে ব্যবসার ঘটনা—একটি অর্ডার প্লেস করা, পেমেন্ট কনফার্ম হওয়া, প্যাকেজ শিপ হওয়া—কোকে ইভেন্ট হিসেবে উপস্থাপন করা হয় যাতে অন্য অংশগুলো সেগুলোর উপর প্রতিক্রিয়া জানাতে পারে।
Kafka প্রায়শই EDA‑র কেন্দ্র হিসেবে কাজ করে—একটি শেয়ার করা “ইভেন্ট স্ট্রিম”। সার্ভিস A সরাসরি সার্ভিস B‑কে কল না করে, সার্ভিস A একটি Kafka টপিকে OrderCreated ইভেন্ট পাবলিশ করে। যে কোনও সংখ্যক সার্ভিস ঐ ইভেন্ট কনসিউম করে এবং কাজ করে—ইমেল পাঠানো, ইনভেন্টরি রিজার্ভ, ফ্রড চেক শুরু—বিনা সার্ভিস A‑কে জানা প্রয়োজন।
সার্ভিসগুলো ইভেন্টের মাধ্যমে যোগাযোগ করলে তাদের প্রত্যেকটি ইন্টারঅ্যাকশনের জন্য রিকোয়েস্ট/রেসপন্স এপিআই সমন্বয় করতে হয় না। এতে টিমের মধ্যে শক্ত কাপলিং কমে যায় এবং নতুন ফিচার যোগ করা সহজ হয়: আপনি একটি নতুন কনসিউমার পরিচয় করালেই চলবে, প্রোডিউসার পরিবর্তন করা লাগবে না।
EDA স্বভাবতই অ্যাসিনক্রোনাস: প্রোডিউসার দ্রুত ইভেন্ট লিখে, কনসিউমাররা নিজেদের গতি অনুযায়ী প্রসেস করে। ট্রাফিক স্পাইক হলে Kafka সেই স্রোতকে বাফার করে যাতে ডাউনস্ট্রিম সিস্টেমগুলো একসাথে ভেঙে না পড়ে। কনসিউমাররা স্কেল‑আউট করে ক্যাচ‑আপ করতে পারে, এবং যদি একটি কনসিউমার সাময়িকভাবে ডাউন হয়, তা পুনরায় শুরু করে যেখানে থেমেছিল।
Kafka‑কে ভাবুন সিস্টেমের “অ্যাক্টিভিটি ফিড” হিসেবে। প্রোডিউসাররা স্থিতি প্রকাশ করে; কনসিউমাররা তাদের যা যা দরকার তা সাবস্ক্রাইব করে। এই প্যাটার্নটি রিয়েল‑টাইম ডাটা পাইপলাইন ও ইভেন্ট‑ড্রিভেন ওয়ার্কফ্লো সক্রিয় করে এবং সার্ভিসগুলোকে সহজ ও স্বাধীন রাখে।
Kafka সাধারণত সেখানে ব্যবহৃত হয় যেখানে টিমগুলোকে প্রচুর ছোট "ঘটা ঘটেছে" (ইভেন্ট) বারান্দা দ্রুত, বিশ্বাসযোগ্যভাবে এবং একাধিক কনসিউমারদের পুনরায় ব্যবহারযোগ্যভাবে পাঠাতে হয়।
অ্যাপগুলো প্রায়ই একটি_APPEND‑অনলি ইতিহাস রাখে: ইউজার সাইন‑ইন, পারমিশন পরিবর্তন, রেকর্ড আপডেট, বা অ্যাডমিন অ্যাকশন। Kafka কেন্দ্রিয় স্ট্রিম হিসেবে কাজ করে যাতে সিকিউরিটি টুল, রিপোর্টিং ও কমপ্লায়েন্স এক্সপোর্ট একই সোর্স পড়তে পারে—প্রোডাকশন DB‑তে অতিরিক্ত লোড ছাড়াই। ইভেন্টগুলো একটি সময় ধরে রাখা হলে বাগ বা স্কিমা পরিবর্তনের পরেও অডিট ভিউ পুনঃনির্মাণ করা যায়।
সার্ভিসগুলো সরাসরি একে অপরকে কল না করে ইভেন্টগুলো পাবলিশ করে, যেমন “order created” বা “payment received।” অন্য সার্ভিসগুলো সাবস্ক্রাইব করে এবং নিজেদের সময়ে প্রতিক্রিয়া জানায়। এতে কড়াকড়ি কাপলিং কমে, আংশিক আউটেজেও সিস্টেম কাজ চালিয়ে যেতে পারে, এবং কেবল বিদ্যমান ইভেন্ট স্ট্রিম খেয়েই নতুন ক্ষমতা যোগ করা সহজ হয় (যেমন ফ্রড চেক)।
Kafka অপারেশনাল সিস্টেম থেকে অ্যানালিটিক্স প্ল্যাটফর্মে ডেটা সরানোর একটি সাধারণ ব্যাকবোন। টিমগুলো ডাটাবেস পরিবর্তন স্ট্রিম করে কম দেরিতে ওয়্যারহাউস বা লেকে পৌঁছে দিতে পারে, প্রোডাকশন অ্যাপকে ভারী অ্যানালিটিক্যাল কুয়েরি থেকে আলাদা রেখে।
সেন্সর, ডিভাইস, ও অ্যাপ টেলিমেট্রি প্রায়ই স্পাইকে আসে। Kafka সেই বাম্পগুলো শোষণ করতে পারে, নিরাপদে বাফার করে, এবং ডাউনস্ট্রিম প্রসেসিংকে ক্যাচ‑আপ করাতে দেয়—মনিটরিং, অ্যালার্টিং, ও দীর্ঘমেয়াদী বিশ্লেষণের জন্য উপযোগী।
Kafka শুধু ব্রোকার ও টপিক নয়। বেশিরভাগ টিম সহায়ক টুলগুলোর ওপর নির্ভর করে যা দৈনন্দিন ডেটা মুভমেন্ট, স্ট্রিম প্রসেসিং, ও অপারেশনকে বাস্তবসম্মত করে তোলে।
Kafka Connect হলো Kafka‑এর ইন্টিগ্রেশন ফ্রেমওয়ার্ক যা ডেটা Kafka‑তে আনা (sources) এবং Kafka থেকে পাঠানো (sinks) সহজ করে। এক‑অফ পাইপলাইন তৈরি না করে আপনি Connect চালিয়ে কনফিগারেশন দিয়ে সংযোগ স্থাপন করেন।
সাধারণ উদাহরণগুলোর মধ্যে রয়েছে ডাটাবেস থেকে পরিবর্তন টেনে আনা, SaaS ইভেন্ট ইনজেস্ট করা, বা Kafka ডেটা একটি ডেটা ওয়্যারহাউস/অবজেক্ট স্টোরেজে ডেলিভার করা। Connect রিট্রাই, অফসেট, এবং প্যারালালিজমের মতো অপারেশনাল উদ্বেগও স্ট্যান্ডার্ড করে।
যদি Connect ইন্টিগ্রেশনের জন্য হয়, Kafka Streams হলো কম্পিউটেশনের জন্য। এটি একটি লাইব্রেরি যা আপনার অ্যাপে যোগ করে স্ট্রিমগুলো বাস্তবে ট্রান্সফর্ম করতে পারে—ফিল্টার, এনরিচ, স্ট্রীম জয়েন, এবং এগ্রিগেট (যেমন “orders per minute”)।
Streams অ্যাপগুলো টপিক থেকে পড়ে এবং টপিকে লিখে, তাই ইভেন্ট‑ড্রিভেন সিস্টেমে সুপ্রকৃতি ভাবে ফিট করে এবং আরও ইনস্ট্যান্স যোগ করলে স্কেল করে।
একাধিক টিম ইভেন্ট পাবলিশ করলে কনসিস্টেন্সি জরুরি। স্কিমা ম্যানেজমেন্ট (প্রায়ই একটি স্কিমা রেজিস্ট্রি দ্বারা) নির্ধারণ করে ইভেন্টে কী ফিল্ড থাকা উচিত এবং কীভাবে এগুলো সময়ের সঙ্গে বিকশিত হবে। এতে প্রোডিউসার কোনো ফিল্ড রিনেম করলে কনসিউমার ভেঙে না যায়।
Kafka অপারেশনালি সংবেদনশীল, তাই বেসিক মনিটরিং অপরিহার্য:
বেশি টিম ম্যানেজমেন্ট UI এবং ডেপ্লয়মেন্ট, টপিক কনফিগারেশন, এবং অ্যাক্সেস কন্ট্রোল নীতির অটোমেশনও ব্যবহার করে (দেখুন /blog/kafka-security-governance)।
Kafka কেবল “টেকসই লগ + কনসিউমার” না—বেশিরভাগ টিম আসলে জানতে চায়: ওকে, আমি কি প্রতিটি ইভেন্ট একবারই প্রসেস করব, আর ব্যর্থ হলে কী হবে? Kafka আপনাকে বিল্ডিং ব্লক দেয়, এবং আপনিই ট্রেড‑অফগুলো বাছবেন।
At-most-once: আপনি ইভেন্ট হারাতে পারেন, কিন্তু ডুপ্লিকেট হবে না। উদাহরণ: কনসিউমার অফসেট আগে কমিট করে এবং তারপর ক্র্যাশ করে।
At-least-once: ইভেন্ট হারাবে না, কিন্তু ডুপ্লিকেট হতে পারে (উদাহরণ: কনসিউমার একটি ইভেন্ট প্রসেস করে, ক্র্যাশ করে, এবং আবার রি‑প্রসেস করে)। এটি সাধারণ ডিফল্ট প্যাটার্ন।
Exactly-once: উভয়ই—না হারানো, না ডুপ্লিকেট—লক্ষ্য করে। Kafka-তে এটি সাধারণত ট্রানজেকশনাল প্রোডিউসার ও সামঞ্জস্যপূর্ণ প্রসেসিং (প্রায়ই Kafka Streams) দিয়ে অর্জিত হয়। শক্তিশালী কিন্তু বেশি সীমাবদ্ধ এবং সাবধানে সেটআপ প্রয়োজন।
প্র্যাকটিসে অনেক সিস্টেম at-least-once গ্রহণ করে এবং সুরক্ষা যোগ করে:
কনসিউমার অফসেট হলো একটি পার্টিশনে সর্বশেষ প্রসেস করা রেকর্ডের অবস্থান। আপনি যখন অফসেট কমিট করেন, বলছেন, “আমি এখান পর্যন্ত শেষ করেছি।” খুব আগেই কমিট করলে লোকসান, খুব দেরিতে করলে ডুপ্লিকেট থাকার সম্ভাবনা বাড়ে।
রিট্রাই সীমাবদ্ধ ও দৃশ্যমান হওয়া উচিত। একটি সাধারণ প্যাটার্ন:
এটি একটি “পয়জন মেসেজ” পুরো গ্রুপকে ব্লক করা থেকে রক্ষা করে, একই সাথে ডেটা পরবর্তী ফিক্সের জন্য সংরক্ষণ করে।
Kafka প্রায়ই ব্যবসায়িকভাবে গুরুত্বপূর্ণ ইভেন্ট বহন করে (অর্ডার, পেমেন্ট, ইউজার অ্যাক্টিভিটি)। তাই নিরাপত্তা ও গভর্ন্যান্স ডিজাইনের অংশ হওয়া উচিত, পরে যোগ করার মতো না।
প্রমাণীকরণ বলে “আপনি কে?”; অনুমোদন বলে “আপনি কী করতে পারেন?” Kafka‑তে সাধারণত SASL (উদা: SCRAM বা Kerberos) দিয়ে প্রমাণীকরণ করা হয়, আর অনুমোদন ACLs (টপিক, কনসিউমার গ্রুপ, ক্লাস্টার স্তরে) দিয়ে প্রয়োগ করা হয়।
একটি বাস্তবিক প্যাটার্ন হলো লিস্ট‑প্রিভিলেজ: প্রোডিউসার শুধু তাদের টপিকে লিখতে পারে, কনসিউমার শুধু তাদের দরকারি টপিক পড়তে পারে। এতে ভ্রান্ত ডেটা‑এক্সপোজার কমে এবং যদি ক্রেডেনশিয়াল লিক হয় তাতে ক্ষতি সীমিত হয়।
TLS ক্লায়েন্ট, ব্রোকার এবং টুলিংয়ের মধ্যকার ডেটা এনক্রিপ্ট করে। TLS ছাড়া ইভেন্টগুলো ইন্টারনাল নেটওয়ার্কে ইন্টারসেপ্ট করা যেতে পারে—শুধু পাবলিক ইন্টারনেট নয়। TLS ব্রোকারের পরিচয় যাচাই করে MAN‑IN‑THE‑MIDDLE আক্রমণও রুখে দেয়।
যখন একাধিক টিম একটি ক্লাস্টার শেয়ার করে, গার্ডরেইল প্রয়োজন। স্পষ্ট টপিক নেমিং কনভেনশন (উদাহরণ: \u003cteam\u003e.\u003cdomain\u003e.\u003cevent\u003e.\u003cversion\u003e) মালিকানা স্পষ্ট করে এবং টুলিংকে কনসিস্টেন্ট নীতি প্রয়োগে সাহায্য করে।
নেমিংয়ের সঙ্গে কোটা ও ACL টেমপ্লেট জোড়া লাগান যাতে একটি জোরালো ওয়ার্কলোড অন্যদের অপুষ্ট না করে, এবং নতুন সার্ভিসগুলো নিরাপদ ডিফল্ট নিয়ে শুরু করে।
Kafka‑কে ইভেন্ট ইতিহাসের সিস্টেম অফ রেকর্ড হিসাবে বিবেচনা করুন কেবল তখনই যখন তা প্রত্যাশিত। ইভেন্টে PII থাকলে ডেটা মিনিমাইজেশন করুন (পূর্ণ প্রোফাইল না পাঠিয়ে আইডি পাঠান), ফিল্ড‑লেভেল এনক্রিপশন বিবেচনা করুন, এবং কোন টপিক সংবেদনশীল তা ডকুমেন্ট করুন।
রিটেনশন সেটিংস আইনি ও ব্যবসায়িক চাহিদার সাথে মিলিয়ে রাখুন। যদি নীতি বলে “30 দিনের পরে মুছে ফেল”, তাহলে 6 মাস ধরে রাখা ঠিক নয়। নিয়মিত পর্যালোচনা ও অডিট কনফিগারেশনগুলো সিস্টেম বিবর্তনের সাথে সামঞ্জস্য রাখে।
Apache Kafka চালানো মানে শুধু ইনস্টল করে ছেড়ে দেয়া নয়। এটি একটি শেয়ার করা ইউটিলিটির মত আচরণ করে: অনেক টিম এর উপর নির্ভরশীল এবং ছোট ভুলও নীচের অ্যাপগুলোতে ছড়িয়ে পড়তে পারে।
Kafka ক্যাপাসিটি মূলত একটি গণিত সমস্যা যেটা নিয়মিত পুনর্বিবেচনা করা দরকার। বড় লিভারগুলো হলো পার্টিশন (প্যারালালিজম), থ্রুপুট (MB/s ইন ও আউট), এবং স্টোরেজ বৃদ্ধি (রিটেনশন কতো লম্বা)।
যদি ট্রাফিক দ্বিগুণ হয়, আপনাকে লোড ছড়ানোর জন্য বেশি পার্টিশন, রিটেনশনের জন্য বেশি ডিস্ক, এবং রেপ্লিকেশনের জন্য বেশি নেটওয়ার্ক হেডরুম দরকার হতে পারে। একটি বাস্তবিক অভ্যাস হলো পিক রাইট রেটকে পূর্বাভাস দিন এবং রিটেনশন দিয়ে ডিস্ক বৃদ্ধি হিসাব করুন, তারপর রেপ্লিকেশন ও অনির্বাচিত সাফল্যের জন্য বাফার যোগ করুন।
সার্ভার চালু রাখার বাইরে রুটিন কাজ আশা করুন:
খরচ আসে মূলত ডিস্ক, নেটওয়ার্ক আউটগোয়িং, এবং ব্রোকারের সংখ্যা/আকার থেকে। ম্যানেজড Kafka স্ট্যাফিং ও আপগ্রেড সহজ করতে পারে, যেখানে সেলফ‑হোস্ট করা স্কেলে সস্তা হতে পারে যদি আপনার কাছে দক্ষ অপারেটর থাকে। ট্রেড‑অফটি টাইম‑টু‑রিকভারি ও অন‑কল বোঝা।
টিমগুলো সাধারণত মনিটর করে:
ভালো ড্যাশবোর্ড ও অ্যালার্ট Kafka‑কে একটি ‘রহস্য বাক্স’ থেকে একটি বোঝা‑যাই service‑এ পরিণত করে।
Kafka ভাল মানায় যখন আপনাকে প্রচুর ইভেন্ট বিশ্বাসযোগ্যভাবে সরাতে হবে, সেগুলো কিছু সময় ধরে রাখতে হবে, এবং একাধিক সিস্টেম একই ডেটা স্ট্রিমে নিজ নিজ সময়ে প্রতিক্রিয়া জানাবে। রি‑প্লে দরকার হলে (ব্যাকফিল, অডিট, বা নতুন সার্ভিস পুনর্নির্মাণের জন্য) এবং যখন অধিক প্রোডিউসার/কনসিউমার যোগ হওয়ার সম্ভাবনা থাকে—তখন Kafka বিশেষভাবে উপকারী।
Kafka সাধারণত ভাল কাজ করে যখন:
যদি আপনার চাহিদা সরল হয়, Kafka বেশি জটিল হতে পারে:
এই ক্ষেত্রে অপারেশনাল ওভারহেড (ক্লাস্টার সাইজিং, আপগ্রেড, মনিটরিং, অন‑কল) সুবিধার চেয়ে বেশি হতে পারে।
Kafka ডাটাবেস (সিস্টেম অফ রেকর্ড), ক্যাশ (দ্রুত রিড), এবং ব্যাচ ETL টুলগুলোর (বড় পিরিয়ডিক ট্রান্সফর্মেশন) সাথে পরিপূরক—প্রতিস্থাপন নয়।
প্রশ্ন করুন:
আপনি বেশিরভাগ প্রশ্নে “হ্যাঁ” বললে, Kafka সাধারণত যুক্তিযুক্ত পছন্দ।
Kafka সবচেয়ে ভালো মানে যখন একটি শেয়ার করা “রিয়েল‑টাইম সোর্স অফ ট্রুথ” দরকার: বহু সিস্টেম যা ফ্যাক্ট প্রোডিউস করে (অর্ডার তৈরি, পেমেন্ট অনুমোদন, ইনভেন্টরি পরিবর্তন) এবং বহু সিস্টেম সেগুলো খেয়ে পাইপলাইন, অ্যানালিটিক্স, ও প্রতিক্রিয়াশীল ফিচার চালায়।
একটি সংকীর্ণ, উচ্চ‑মূল্য প্রবাহ দিয়ে শুরু করুন—যেমন downstream সার্ভিসগুলোর (ইমেল, ফ্রড চেক, ফুলফিলমেন্ট) জন্য “OrderPlaced” ইভেন্ট পাবলিশ করা। প্রথম দিনেই Kafka‑কে catch‑all কিউ বানাবেন না।
লিখে রাখুন:
প্রাথমিক স্কিমাগুলো সাদামাটা রাখুন (টাইমস্ট্যাম্প, আইডি, স্পষ্ট ইভেন্ট নাম)। সিদ্ধান্ত নিন আপনি স্কিমা আগে‑থেকে প্রয়োগ করবেন না কি সময়ের সঙ্গে সাবধানে বিকাশ করবেন।
Kafka সফল হয় যখন কারো মালিকানা থাকে:
শুরুতেই মনিটরিং যোগ করুন (কনসিউমার লাগ, ব্রোকার হেলথ, থ্রুপুট, এরর রেট)। যদি এখনো প্ল্যাটফর্ম টিম না থাকে, managed অপশন দিয়ে শুরু করুন এবং স্পষ্ট সীমা নির্ধারণ করুন।
একটি সিস্টেম থেকে ইভেন্ট প্রোডিউস করুন, একটি জায়গায় কনসিউম করুন, এবং এন্ড‑টু‑এন্ড লুপটি প্রমান করুন। তারপর ধীরে ধীরে কনসিউমার, পার্টিশন, ও ইন্টিগ্রেশন বাড়ান।
ফাস্ট‑ট্র্যাক প্রোটোটাইপে Koder.ai‑র মতো টুলগুলো সাহায্য করতে পারে (React UI, Go ব্যাকএন্ড, PostgreSQL) এবং চার্ট‑চালিত ওয়ার্কফ্লো দিয়ে দ্রুত Kafka প্রোডিউসার/কনসিউমার যোগ করতে দেয়। এটি অভ্যন্তরীণ ড্যাশবোর্ড ও হালকা সার্ভিস তৈরিতে সহায়ক, প্ল্যানিং মোড, সোর্স‑কোড এক্সপোর্ট, ডিপ্লয়/হোস্টিং, এবং স্ন্যাপশট‑রোলব্যাকের মতো ফিচার সহ।
আপনি যদি এটি ইভেন্ট‑ড্রাইভেনভাবে ম্যাপ করতে চান দেখুন /blog/event-driven-architecture. কস্ট ও এনভায়রনমেন্ট পরিকল্পনার জন্য দেখুন /pricing.
Kafka একটি বিতরণকৃত ইভেন্ট স্ট্রিমিং প্ল্যাটফর্ম যা ইভেন্টগুলোকে স্থায়ী, append-only লগ হিসেবে সংরক্ষণ করে।
প্রোডিউসাররা ইভেন্টগুলো টপিকে লিখে, এবং কনসিউমাররা সেগুলো স্বাধীনভাবে (অনেক সময় রিয়েল-টাইমে, কিন্তু পরে থেকেও) পড়ে নেয়।
যদি একাধিক সিস্টেম একই ইভেন্ট স্ট্রিম শেয়ার করে, আপনি ডিকাপলিং চান, বা ইতিহাস রি‑প্লে করার প্রয়োজন থাকে—তখন Kafka ব্যবহার করুন।
বিশেষভাবে উপযোগী:
টপিক হলো একটি নামকৃত ইভেন্ট ক্যাটাগরি (যেমন orders বা payments)।
পার্টিশন হল একটি টপিকের ভগ্নাংশ যা সুবিধা দেয়:
Kafka কেবলমাত্র একটি পার্টিশনের ভেতরেই অর্ডারিং নিশ্চিত করে।
Kafka রেকর্ডের কী (যেমন order_id) ব্যবহার করে সংশ্লিষ্ট ইভেন্টগুলোকে একই পার্টিশনে ধারাবাহিকভাবে রুট করে।
প্রায়োগিক নিয়ম: যদি আপনি প্রতিটি এন্টিটির জন্য ক্রমাগত অর্ডার চান (যেমন একটি অর্ডার/কাস্টমার), তাহলে সেই এন্টিটি প্রতিনিধিত্বকারী কী ব্যবহার করুন যাতে সব ইভেন্ট একই পার্টিশনে যায়।
কনসিউমার গ্রুপ হলো কনসিউমার ইনস্ট্যান্সগুলোর একটি সেট যা একটি টপিকের কাজ ভাগ করে নেয়।
গ্রুপের মধ্যে:
যদি দুটি আলাদা অ্যাপ প্রতিটি ইভেন্টই পেতে চায়, তাদের আলাদা কনসিউমার গ্রুপ থাকা উচিত।
Kafka টপিক-ভিত্তিক নীতির ওপর ডিস্কে ইভেন্ট রাখে যাতে কনসিউমার ডাউন থাকলেও পরে ক্যাচ আপ করা যায় বা ইতিহাস পুনঃপ্রক্রিয়াকরণ করা সম্ভব হয়।
সাধারণ রিটেনশন ধরণগুলো:
প্রতি টপিকে আলাদা রিটেনশন কনফিগার করা যায়, তাই অডিট ট্রেইলগুলোকে উচ্চ কিছুক্ষণের জন্য আলাদা রাখা যায়।
লগ কমপ্যাকশন প্রতিটি কীয়ের জন্য অন্তত সর্বশেষ রেকর্ডটি রাখে এবং পুরোনো superseded রেকর্ডগুলো মুছে দেয়।
এটি “বর্তমান স্টেট” স্ট্রীমগুলোর জন্য উপযোগী (যেমন কনফিগ বা প্রোফাইল) যেখানে প্রতিটি কী‑এর সর্বশেষ ভ্যালু প্রয়োজন, সম্পূর্ণ ইতিহাস নয়।
Kafka-র সাধারণ এন্ড‑টু‑এন্ড প্যাটার্ন হলো at-least-once: আপনি ইভেন্ট হারাবেন না, কিন্তু ডুপ্লিকেট হতে পারে।
নিরাপদ ভাবে কাজ করার জন্য:
অফসেট হলো প্রতিটি পার্টিশনের জন্য কনসিউমারের ‘বুকমার্ক’।
অফসেট খুব আগে কমিট করলে ক্র্যাশে কাজ হারাতে পারেন; অনেক পরে কমিট করলে রিস্টার্টের পর ডুপ্লিকেট তৈরি হবে।
সাধারণ অপারেশনাল প্যাটার্ন: সীমিত রিট্রাই ব্যাকঅফসহ, তারপর ব্যর্থ রেকর্ডগুলোকে একটি dead-letter টপিকে পাঠান যাতে একটি পয়জন মেসেজ পুরো গ্রুপকে ব্লক না করে এবং পরবর্তী তদন্ত/রিপ্লেতে সুবিধা থাকে।
Kafka Connect ডেটা সোর্স/সিংক কনেক্টর দিয়ে Kafka-তে ডেটা আনা/নেওয়ার জন্য ব্যবহৃত ফ্রেমওয়ার্ক—একেকটি কাজের জন্য কাস্টম পাইপলাইন লিখতে হয় না।
Kafka Streams একটি লাইব্রেরি যা আপনার অ্যাপে রিয়েল‑টাইম স্ট্রিম ট্রান্সফর্মেশন করে (ফিল্টার, জয়েন, এগ্রিগেট)।
সারাংশ: Connect হলো ইন্টিগ্রেশন, Streams হলো কম্পিউটেশন।