১৪ মে, ২০২৫·8 মিনিট
কেন OLTP এবং OLAP ওয়ার্কলোডগুলো সাধারণত একই ডাটাবেসে থাকে না
একই ডাটাবেসে ট্রানজেকশনাল (OLTP) ও অ্যানালিটিক্যাল (OLAP) কাজ একসঙ্গে রাখলে কেন অ্যাপ ধীর হয়, খরচ বেড়ে, অপারেশন জটিল হয়—এবং বিকল্প কি তা জানুন।
একই ডাটাবেসে ট্রানজেকশনাল (OLTP) ও অ্যানালিটিক্যাল (OLAP) কাজ একসঙ্গে রাখলে কেন অ্যাপ ধীর হয়, খরচ বেড়ে, অপারেশন জটিল হয়—এবং বিকল্প কি তা জানুন।
যখন মানুষ “OLTP” এবং “OLAP” বলে, তারা ডাটাবেস ব্যবহারের দুইটি ভিন্ন রকমের বরাত দেয়।
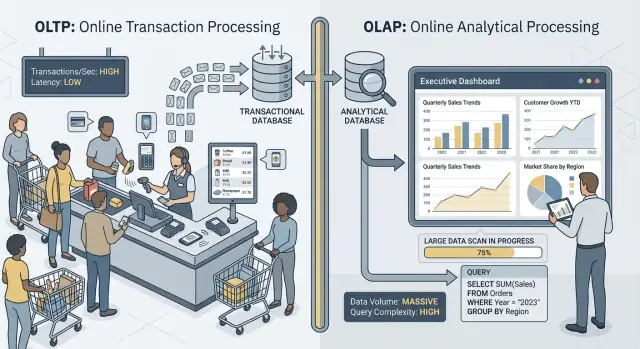
OLTP (Online Transaction Processing) হলো সেই ওয়ার্কলোড যা দৈনন্দিন কার্যক্রম দ্রুত এবং সঠিকভাবে সম্পন্ন করে—ভাবুন: “এই পরিবর্তনটি এখনই সংরক্ষণ কর।”
সাধারণ OLTP কাজের উদাহরণ: অর্ডার তৈরি করা, স্টক আপডেট করা, পেমেন্ট রেকর্ড করা, গ্রাহকের ঠিকানা বদলানো। এগুলো সাধারণত ছোট (কয়েকটি সারি), ঘনঘন, এবং মিলিসেকেন্ডে সাড়া দেওয়া দরকার কারণ একজন ব্যবহারকারী বা অন্য কোনো সিস্টেম অপেক্ষা করছে।
OLAP (Online Analytical Processing) হলো সেই ওয়ার্কলোড যা বোঝার কাজে লাগে—কী ঘটেছে এবং কেন তা ঘটল। ভাবুন: “বেশি ডেটা স্ক্যান করে সংক্ষেপ কর। ”
সাধারণ OLAP কাজের উদাহরণ: ড্যাশবোর্ড, ট্রেন্ড রিপোর্ট, কোহর্ট বিশ্লেষণ, পূর্বাভাস, এবং “slice-and-dice” প্রশ্নগুলি যেমন: “গত ১৮ মাসে অঞ্চল ও পণ্যের শ্রেণি অনুযায়ী রাজস্ব কিভাবে পরিবর্তিত হয়েছে?” এই কুয়েরিগুলো সাধারণত বহু সারি পড়ে, ভারী অ্যাগ্রিগেশন করে, এবং সেকেন্ড (বা মিনিট) ধরে চললেও ভুল বলা হয় না।
মুখ্য ধারণা সহজ: OLTP দ্রুত, কনসিসটেন্ট রাইট ও ছোট রিডের জন্য অপ্টিমাইজ করে, যেখানে OLAP বড় রিড ও জটিল গণনার জন্য অপ্টিমাইজ করে। লক্ষ্যগুলো আলাদা হওয়ায় সেরা ডাটাবেস সেটিং, ইনডেক্স, স্টোরেজ লেআউট, এবং স্কেলিং পন্থাও প্রায়শই আলাদা হয়।
এখানেই লক্ষ্য থাকা দরকার: প্রায়ই নয়, কখনও নয় নয়। কিছু ছোট দলের জন্য একটি ডাটাবেস শেয়ার করা সাময়িকভাবে সম্ভব হতে পারে, বিশেষত যখন ডেটা পরিমাণ কম এবং কুয়েরি শৃঙ্খলাবদ্ধ থাকে। পরে কোনটুকু আগে ভেঙে পড়ে, বিভক্ত করার প্রচলিত প্যাটার্ন, এবং কীভাবে রিপোর্টিং প্রোডাকশনের বাইরে সরানো যায়—এইসব পরের অংশগুলোতে আলোচনা করা হয়েছে।
OLTP এবং OLAP উভয়ই "SQL ব্যবহার করে"—তবুও এগুলো ভিন্ন কাজের জন্য অপ্টিমাইজ করা হয়—এবং সেটাই সফলতা পরিমাপের ধরণে প্রকাশ পায়।
OLTP (ট্রানজেকশনাল) সিস্টেমগুলি দৈনন্দিন অপারেশন চালায়: চেকআউট ফ্লো, অ্যাকাউন্ট আপডেট, রিজার্ভেশন, সাপোর্ট টুল। অগ্রাধিক্যগুলো সরল:
সাফল্য প্রায়ই ল্যাটেন্সি মেট্রিক দিয়ে মাপা হয়—যেমন p95/p99 রিকোয়েস্ট টাইম, এরর রেট, এবং পিক কনকারেন্সির সময় সিস্টেম কেমন আচরণ করে।
OLAP (অ্যানালিটিক্স) সিস্টেমগুলো জিজ্ঞাসা করে "এই ত্রৈমাসিকে কী বদলেছে?" বা "নতুন প্রাইসিং পরে কোন সেগমেন্ট চর্ন করল?" এই কুয়েরিগুলো সাধারণত:
এখানে সফলতা দেখতে পাওয়া যায় কুয়েরি থ্রুপুট, ইনসাইট পেতে সময়, এবং জটিল কুয়েরি চালানোর ক্ষমতা ছাড়া প্রতিটি রিপোর্ট ম্যানুয়ালি টিউন না করা।
যখন আপনি দুই ওয়ার্কলোডকে এক ডাটাবেসে চাপ দেন, আপনি সেটিকে একই সময়ে ছোট, উচ্চ-ভলিউম ট্রানজেকশন এবং বড়, এক্সপ্লোরেটরি স্ক্যান উভয়ের জন্য শ্রেষ্ঠ হতে বলছেন। ফলাফল সাধারণত আপোষ: OLTP অনিশ্চিত লেটেন্সি পায়, OLAP-কে প্রোডাকশন রক্ষা করতে থ্রটল করা হয়, এবং দলগুলো মারামারি শুরু করে কার কুয়েরি "চালানো যাবে"। ভিন্ন লক্ষ্যগুলো আলাদা সফলতার মেট্রিক দাবি করে—আর সাধারণত আলাদা সিস্টেম।
যখন OLTP (আপনার অ্যাপের দৈনন্দিক ট্রানজেকশন) এবং OLAP (রিপোর্টিং ও বিশ্লেষণ) একই ডাটাবেসে চলে, তারা একই সীমিত রিসোর্স নিয়ে লড়াই করে। ফলাফল কেবল "রিপোর্ট ধীর" নয়—এটি প্রায়ই ধীর চেকআউট, আটকে থাকা লগইন, এবং অনিশ্চিত অ্যাপ হিকে।
অ্যানালিটিক্যাল কুয়েরিগুলো দীর্ঘ-চলমান এবং ভারী হয়: বড় টেবিল জয়েন, অ্যাগ্রিগেশন, সাজানো এবং গ্রুপিং। এগুলো CPU কোর ও মেমরি (হ্যাশ জয়েন, সর্ট বাফার) দখল করে রাখতে পারে।
অন্যদিকে, ট্রানজেকশনাল কুয়েরি সাধারণত ছোট কিন্তু লেটেন্সি-সংবেদনশীল। যদি CPU স্যাচুরেটেড হয় বা মেমরি প্রেসার ফায়ার করায় ফ্রিকোয়েন্ট ইভিকশন ঘটে, তখন ছোট কুয়েরিগুলোরও বড় কুয়েরিগুলোর পিছনে অপেক্ষা করতে হয়—ভিত্তি হিসেবে যেখানে প্রতিটি ট্রানজেকশন মাত্র কয়েক মিলিসেকেন্ড কাজ চায়।
অ্যানালিটিক্স প্রায়ই বড় টেবিল স্ক্যান করে এবং অনেক পেজ ধারাবাহিকভাবে পড়ে। OLTP কর্মভারটি সাধারণত বিপরীত: বহু ছোট, র্যান্ডম রিড এবং ইনডেক্স ও লগে ধারাবাহিক রাইট।
দুটি মিলিয়ে দিলে ডাটাবেস স্টোরেজ সাবসিস্টেমকে মিশ্র অ্যাকসেস প্যাটার্নের সাথে সামঞ্জস্য রাখতে হয়। OLTP-তে সাহায্য করা ক্যাশগুলো অ্যানালিটিক্স স্ক্যান দ্বারা "ওয়াশ আউট" হয়ে যেতে পারে, এবং রিপোর্টিংয়ের জন্য ডিস্ক স্ট্রিমিং ব্যস্ত হলে রাইট লেটেন্সি বাড়তে পারে।
কিছু বিশ্লেষক বড় কুয়েরি চালালে কয়েক মিনিট পর্যন্ত কানেকশন দখল করতে পারে। যদি আপনার অ্যাপ একটি নির্দিষ্ট সাইজের পুল ব্যবহার করে, অনুরোধগুলো ফ্রি কানেকশনের জন্য কিউতেই দাঁড়ায়। সেই কিউয়িং ইফেক্ট একটি সুস্থ সিস্টেমকেও ভাঙা মনে করায়: গড় লেটেন্সি ঠিক থাকতে পারে, কিন্তু টেইল লেটেন্সি (p95/p99) অস্বস্তিকর হয়ে ওঠে।
বাইরোয়, এটি টাইমআউট, ধীর চেকআউট ফ্লো, বিলম্বিত সার্চ রেজাল্ট, এবং সাধারণত ফ্লাকী আচরণ হিসাবে প্রকাশ পায়—প্রায়ই "শুধু রিপোর্ট চালালে" বা "পূজির মাসে" ঘটে। অ্যাপ টিম ত্রুটি দেখে; অ্যানালিটিক্স টিম ধীর কুয়েরি দেখে; কিন্তু সমস্যার আসল কারণ হল শেয়ার্ড কনটেনশন।
OLTP এবং OLAP কেবল ডাটাবেস "ভিন্নভাবে ব্যবহার করে" না—তারা শারীরিক ডিজাইনের বিপরীত পুরস্কৃত করে। এক জায়গায় উভয়কে সন্তুষ্ট করার চেষ্টা করলে সাধারণত এমন একটি আপোষ দাঁড়ায় যা খরচবহুল এবং তবুও পারফরম্যান্সে পিছিয়ে।
ট্রানজেকশনাল ওয়ার্কলোড ছোট প্রশ্ন দ্বারা আধিপত্য বিস্তার করে: একটি অর্ডার আনা, একটি স্টক সারি আপডেট, এক নির্দিষ্ট ব্যবহারকারীকে ২০টি ইভেন্ট দেখানো।
এটি OLTP স্কিমাগুলোকে রো-অরিয়েন্টেড স্টোরেজ এবং পয়েন্ট লুকআপ/ছোট রেঞ্জ স্ক্যান সমর্থনকারী ইনডেক্সের দিকে ঠেলে (প্রাইমারি কী, ফরেন কী, এবং কয়েকটি উচ্চ-মূল্যের সেকেন্ডারি ইনডেক্স)। লক্ষ্য হচ্ছে পূর্বানুমেয়, নিম্ন ল্যাটেন্সি—বিশেষত রাইটের জন্য।
অ্যানালিটিক্স প্রায়ই অনেক সারি পড়ে এবং কেবল কয়েকটি কলাম ব্যবহার করে: “সপ্তাহ অনুযায়ী অঞ্চলভিত্তিক রাজস্ব,” “ক্যাম্পেইন অনুযায়ী কনভার্সন রেট,” “মার্জিন অনুযায়ী শীর্ষ পণ্য।”
OLAP সিস্টেমগুলো কলাম-ভিত্তিক স্টোরেজ (শুধু প্রয়োজনীয় কলাম পড়তে), পার্টিশনিং (পুরনো বা অনাগ্রহী ডেটা দ্রুত বাদ দেয়া), এবং প্রি-অ্যাগ্রিগেশন (materialized views, rollups, summary tables) থেকে সুবিধা পায় যাতে রিপোর্টগুলোর বারবার একই মোট গণনা না করতে হয়।
একটি সাধারণ প্রতিক্রিয়া হলো প্রতিটি ড্যাশবোর্ড দ্রুত করতে ইনডেক্স বাড়ানো। কিন্তু প্রতিটি অতিরিক্ত ইনডেক্স লিখনের খরচ বাড়ায়: ইনসার্ট/আপডেট/ডিলিটে আরও স্ট্রাকচার আপডেট করতে হয়। এটি স্টোরেজ বাড়ায় এবং মেইনটেন্যান্স টাস্ক (vacuuming, reindexing, backup) ধীর করে।
ডাটাবেস কুয়েরি প্ল্যানগুলো স্ট্যাটিস্টিক্সের ওপর ভিত্তি করে চয়েস করে—কত সারি একটি ফিল্টার ম্যাচ করবে, একটি ইনডেক্স কতটা সিলেকটিভ, ডেটা কীভাবে বিতরণ। OLTP ডেটা ক্রমাগত বদলে যায়। বিতরণ বদলালে স্ট্যাটিস্টিক্স ড্রিফট হয়, এবং প্ল্যানার এমন পরিকল্পনা বেছে নেবে যা গতকালের ডেটার জন্য উপযুক্ত ছিল কিন্তু আজ ধীর।
ভারী OLAP কুয়েরি মেশালে পরিবর্তনশীলতা আরও বাড়ে: “সেরা প্ল্যান” পূর্বাভাস করা কঠিন হয়, এবং একটি ওয়ার্কলোড জন্য টিউন করলে অন্যটি খারাপ হতে পারে।
যদি আপনার ডাটাবেস "কনকারেন্সি সাপোর্ট করে" বলে থাকলেও, ভারী রিপোর্টিং ও জীবন্ত ট্রানজেকশন মিশালে সূক্ষ্ম মন্থরতা তৈরি হয় যা ভবিষ্যদ্বাণী করা কঠিন—আর গ্রাহককে একটি স্পিনিং চেকআউট দেখালে বোঝানো কঠিন।
OLAP-শৈলীর কুয়েরিগুলো সাধারণত বহু সারি স্ক্যান করে, একাধিক টেবিল জয়েন করে, এবং সেকেন্ড বা মিনিট ধরে চলতে পারে। সে সময় তারা লক ধরে রাখতে পারে (উদাহরণ: স্কিমা অবজেক্টে লক, বা টেম্প স্ট্রাকচারে সাজানো/অ্যাগ্রিগেট করার সময়), এবং অনেক সময় তারা পরোক্ষভাবে লক কনটেনশন বাড়ায় কারণ বহু সারি “ইন প্লে” রাখে।
MVCC থাকলেও, ডাটাবেসকে একাধিক row-version ট্র্যাক করতে হয় যাতে রিডার ও রাইটার ব্লক না করে। তা সাহায্য করে, কিন্তু কনটেনশন পুরোপুরি দূর করে না—বিশেষত যখন কুয়েরিগুলো এমন হট টেবিলগুলো স্পর্শ করে যেগুলো ট্রানজেকশন দ্বারা ক্রমাগত আপডেট হয়।
MVCC মানে পুরনো row-versionগুলো সুরক্ষিতভাবে অপসারণের আগে লেগে থাকে। একটি দীর্ঘ-চলমান রিপোর্ট একটি পুরনো স্ন্যাপশট ওপেন রেখে দিতে পারে, ফলে ক্লিনআপ সেই স্পেস আদায় করতে পারে না।
এটি প্রভাব ফেলে:
ফলাফল হলো দ্বৈত আঘাত: রিপোর্টিং ডাটাবেসকে বেশি কাজ করায় এবং সময়ের সাথে সিস্টেমকে ধীর করে দেয়।
রিপোর্টিং টুল প্রায়ই শক্ততর আইসোলেশন চায় (বা ভুলবশত দীর্ঘ ট্রানজেকশনে চলে)। উচ্চ আইসোলেশন লক অপেক্ষা বাড়ায় এবং ইঞ্জিনকে আরও বেশি ভার্সনিং পরিচালনা করতে বাধ্য করে। OLTP দিক থেকে আপনি এটি অনিয়মিত স্পাইক হিসেবে দেখেন: বেশিরভাগ অর্ডার দ্রুত লেখেন, তারপর কয়েকটি আচমকা আটকে যায়।
মাস শেষে, ফাইন্যান্স "পণ্যের নিরিখে রাজস্ব" কুয়েরি চালায় যা পুরো মাসের অর্ডার ও লাইন আইটেম স্ক্যান করে। যখন এটি চলে, নতুন অর্ডার রাইট এখনও গ্রহণ করা হয়, কিন্তু vacuum পুরনো ভার্সনগুলি মুছে ফেলতে পারে না এবং ইনডেক্স ঘষা পড়ে। অর্ডার API মাঝে মাঝে টাইমআউট দেখতে পায়—কেননা এটি "ডাউন" নয়, বরং কনটেনশন ও ক্লিনআপ ওভারহেড চুপচাপ আপনার ল্যাটেন্সিকে আপনার সীমার ওপরে ঠেলে দেয়।
OLTP সিস্টেম পূর্বানুমেয়তার ওপর বাঁচে। একটি চেকআউট, সাপোর্ট টিকিট, বা ব্যালান্স আপডেট "মোটামুটি ঠিক আছে" হলে যদি 95% সময় দ্রুত হয়, ব্যবহারকারী ধীর মুহূর্তগুলো নজরে রাখে। OLAP-ই সাধারণত ব্রাস্টি: কয়েকটি ভারী কুয়েরি ঘণ্টাখানিক নিঃশব্দ থাকতে পারে এবং হঠাৎ অনেক CPU, মেমরি, ও I/O নেয়।
অ্যানালিটিক্স ট্র্যাফিকগুলো সাধারণত রুটিন ঘিরে বেঁধে যায়:
অন্যদিকে OLTP ট্র্যাফিক সাধারণত ধীর বা ধারাবাহিক থাকে। যখন উভয়ই একই ডাটাবেস শেয়ার করে, সেই অ্যানালিটিক্স স্পাইকগুলো ট্রানজেকশনের জন্য অনিয়ন্ত্রিত লেটেন্সি হয়ে ফিরে আসে—টাইমআউট, ধীর পেজ লোড, এবং রিট্রাই যা আরও লোড বাড়ায়।
আপনি ক্ষতি কমাতে পারেন রিপোর্টগুলো রাতের বেলা চালিয়ে, কনকারেন্সি সীমা বসিয়ে, স্টেটমেন্ট টাইমআউট জারি করে, বা কুয়েরি কস্ট ক্যাপ সেট করে। এগুলো রিপোর্টিং অন প্রোডাকশনের জন্য ভালো গার্ডরেইল।
কিন্তু এগুলো মৌলিক টেনশন দূর করে না: OLAP কুয়েরি বড় রিসোর্স ব্যবহার করার জন্য ডিজাইন করা, আর OLTP সারাদিন ছোট, দ্রুত রিসোর্স টুকরা চায়। কোন অপ্রত্যাশিত ড্যাশবোর্ড রিফ্রেশ, অ্যাড-হক কুয়েরি, বা ব্যাকফিল স্লিপ করলে শেয়ার্ড ডাটাবেস আবারও বিপজ্জনক হয়ে ওঠে।
শেয়ার্ড ইনফ্রাস্ট্রাকচারে একটি “নয়সি” অ্যানালিটিক্স ইউজার বা জব ক্যাশ একচেটিয়া করতে পারে, ডিস্ক স্যাচুরেট করতে পারে, বা CPU শিডিউলিং চাপাতে পারে—কর্ম করার কোন ভুল না করেই। OLTP ওয়ার্কলোড কল্যাটারাল ক্ষতিগ্রস্ত হয়, এবং সবচেয়ে কঠিন ব্যাপার হলো ব্যর্থতাগুলো র্যান্ডম স্পাইক হিসেবে দেখা যায়: পরিষ্কার, পুনরাবৃত্তি ত্রুটি নয়।
OLTP (ট্রানজেকশন) ও OLAP (অ্যানালিটিক্স) একসাথে রাখা কেবল পারফরম্যান্সের মাথাব্যথা নয়—এটি দৈনন্দিন অপারেশনকেও জটিল করে। ডাটাবেসটি হয়ে ওঠে একটি একক “সবকিছু বাক্স”, এবং প্রতিটি অপারেশনাল টাস্ক উভয় ওয়ার্কলোডের ঝুঁকি পায়।
অ্যানালিটিক্স টেবিলগুলো সাধারণত দ্রুত বড় হয় (আরও ইতিহাস, আরও কলাম, আরও অ্যাগ্রিগেট)। সেই অতিরিক্ত ভলিউম আপনার রিকভারি গল্প বদলে দেয়।
পূর্ণ ব্যাকআপ বেশি সময় নেয়, বেশি স্টোরেজ নেয়, এবং ব্যাকআপ উইন্ডো মিস করার সম্ভাবনা বাড়ায়। রিস্টোর আরও খারাপ: দ্রুত রিকভার করতে গেলে আপনি কেবল ট্রানজেকশনাল ডেটাই নয় বরং বড় অ্যানালিটিকাল ডেটাসেটও রিস্টোর করছেন—যা ব্যবসাকে দ্রুত চালু রাখার জন্য প্রয়োজনীয় নয়। ডিজাস্টার রিকভারি টেস্টও লম্বা হয়, তাই কম হয়—ঠিক তার বিপরীত যা দরকার।
ট্রানজেকশনাল গ্রোথ সাধারণত পূর্বানুমেয়: আরও গ্রাহক, আরও অর্ডার, আরও সারি। অ্যানালিটিক্স গ্রোথ প্রায়ই লাম্পি: নতুন ড্যাশবোর্ড, নতুন রিটেনশন পলিসি, বা একটি টিম কাঁচা ইভেন্ট “আরেক বছর” রাখতে সিদ্ধান্ত নেওয়া।
যখন উভয় একসাথে থাকে, আপনি সহজে উত্তর দিতে পারবেন না:
অপ্রত্যাশ্যতা ওভারপ্রোভিশনিং (অপ্রয়োজনীয় হেডরুমের জন্য অর্থ দেয়া) বা আন্ডারপ্রোভিশনিং (হঠাৎ আউটেজ) নিয়ে যায়।
একটি শেয়ার্ড ডাটাবেসে একটি “নির্দোষ” কুয়েরিই একটি ইনসিডেন্ট হয়ে উঠতে পারে। আপনি স্টেটমেন্ট টাইমআউট, ওয়ার্কলোড কোটা, নির্ধারিত রিপোর্টিং উইন্ডো, বা ওয়ার্কলোড ম্যানেজমেন্ট রুল যুক্ত করবেন। এগুলো সাহায্য করে, কিন্তু ভঙ্গুর: অ্যাপ ও বিশ্লেষকরা একই সীমার জন্য প্রতিযোগিতা করে, এবং একটি গ্রুপের নীতির পরিবর্তন অন্যটিকে ভাঙতে পারে।
অ্যাপ্লিকেশনগুলো সাধারণত সঙ্কীর্ণ, উদ্দেশ্যমূলক পারমিশন চায়। বিশ্লেষকরা প্রায়ই বহুভাগ টেবিল জুড়ে বিস্তৃত রিড এক্সেস চায়, যাচাই ও এক্সপ্লোর করার জন্য। দুটোই এক ডাটাবেসে রাখলে রিপোর্ট কাজ করতে "প্রায়শই" বেশি বিস্তৃত অনুমতি দিতে চাপ পড়ে, যা ভুলের বিস্তারকে বাড়ায় এবং সংবেদনশীল অপারেশনাল ডেটা দেখার সুযোগ বাড়ায়।
একই ডাটাবেসে OLTP ও OLAP চালানোর চেষ্টা করা প্রাথমিকভাবে সস্তা মনে হতে পারে—কিন্তু স্কেলিং শুরু হলে তা বদলে যায়। সমস্যা কেবল পারফরম্যান্স নয়। প্রতিটি ওয়ার্কলোডকে সঠিকভাবে স্কেল করার পথ আলাদা ইনফ্রা দিকেই ঠেলে, এবং একসাথে চালালে আপনাকে ব্যয়বহুল আপোষ করতে হবে।
ট্রানজেকশনাল সিস্টেমগুলো লিখনের দ্বারা সীমিত: বহু ছোট আপডেট, কঠোর ল্যাটেন্সি, এবং সেজন্য হওয়া বুর্সগুলি অবিলম্বে হজম করতে হবে। OLTP স্কেল করা সাধারণত ভার্টিকাল স্কেলিং (বড় CPU, দ্রুত ডিস্ক, বেশি মেমরি) দ্বারা হয় কারণ রাইট-হেভি ওয়ার্কলোড সহজে ফ্যান আউট করা যায় না।
যখন ভার্টিক্যাল সীমা পৌঁছে যায়, আপনি শার্ডিং বা অন্য রাইট-স্কেলিং প্যাটার্ন দেখতে পাবেন—যা ইঞ্জিনিয়ারিং ওভারহেড বাড়ায় এবং অ্যাপ পরিবর্তন প্রয়োজন করে।
অ্যানালিটিক্স ওয়ার্কলোড আলাদা ভাবে স্কেল করে: দীর্ঘ স্ক্যান, ভারী অ্যাগ্রিগেশন, এবং বেশি রিড থ্রুপুট। OLAP সিস্টেমগুলো সাধারণত ডিসট্রিবিউটেড কম্পিউট যোগ করে এবং অনেক আধুনিক সেটআপে কম্পিউট ও স্টোরেজ আলাদা করে যাতে আপনি কুয়েরি হর্সপাওয়ার বাড়াতে পারেন স্টোরেজ নকল না করে।
যদি OLAP OLTP ডাটাবেস শেয়ার করে, আপনি অ্যানালিটিক্স আলাদাভাবে স্কেল করতে পারবেন না। তখন পুরো ডাটাবেসই স্কেল করতে হয়—যদিও ট্রানজেকশনগুলো ঠিক আছে।
ট্রানজেকশনগুলো দ্রুত রাখতে রিপোর্ট চালাতে গেলে দলগুলো প্রোডাকশন ডাটাবেস ওভার-প্রোভিশন করে: অতিরিক্ত CPU হেডরুম, হাই-এন্ড স্টোরেজ, ও বড় ইনস্ট্যান্স। অর্থাৎ আপনি OLTP-দর দামেই OLAP ব্যবস্থার ব্যয় বহন করছেন।
বিভাগ করলে প্রতিটি সিস্টেমকে তার কাজ অনুযায়ী সাইজ করা যায়: OLTP-কে পূর্বানুমেয় লো-ল্যাটেন্সি রাইটের জন্য, OLAP-কে ব্রাস্টি হেভি রিডের জন্য। ফলাফল প্রায়ই মোটামুটি সস্তা হয়—যদিও এটি "দুই সিস্টেম", কারণ আপনি প্রোডাকশনের প্রিমিয়াম ট্রানজেকশনাল সক্ষমতা আরোপ করে রিপোর্ট চালানোর খরচ বন্ধ করে দেন।
বেশিরভাগ টিম OLTP (ট্রানজেকশনাল ওয়ার্কলোড) ও OLAP (অ্যানালিটিক্স) আলাদা রাখে একটি দ্বিতীয় "রিড-অরিয়েন্টেড" সিস্টেম যোগ করে, পরিবর্তে একটি ডাটাবেসকে উভয় করাতে বাধ্য করার।
প্রথম ধাপে সাধারণভাবে একটি রিড রেপ্লিকা (বা follower) থাকে OLTP ডাটাবেসের, যেখানে BI টুলগুলো কুয়েরি চালায়।
Pros: অ্যাপ পরিবর্তনে অল্প কাজ, পরিচিত SQL, দ্রুত সেটআপ।
Cons: এটি এখনও একই ইঞ্জিন ও স্কিমা, তাই ভারী রিপোর্টগুলো রেপ্লিকা CPU/I/O স্যাচুরেট করতে পারে; কিছু রিপোর্ট রেপ্লিকায় লাগতে থাকা ফিচার না পেতে পারে; এবং রেপ্লিকেশন ল্যাগ মানগুলিকে মিনিট (বা বেশি) পিছিয়ে দিতে পারে। ল্যাগ ইনসিডেন্টে বিভ্রান্তি সৃষ্টি করে।
Best fit: ছোট দল, সীমিত ডেটা পরিমাণ, "নিয়ার-রিয়েল-টাইম" ভালো কিন্তু অপরিহার্য না, এবং রিপোর্টিং কুয়েরিগুলো নিয়ন্ত্রিত থাকে।
এখানে OLTP রাইট ও পয়েন্ট রিডের জন্য অপ্টিমাইজ রাখা হয়, আর অ্যানালিটিক্স চলে একটি ডেটা ওয়ারহাউসে (বা কলামার এনালিটিক্স DB) যা স্ক্যান, কম্প্রেশন, এবং বড় অ্যাগ্রিগেশনের জন্য ডিজাইন করা।
Pros: OLTP পারফরম্যান্স পূর্বানুমেয় থাকে, ড্যাশবোর্ড দ্রুত, বিশ্লেষকদের জন্য ভালো কনকারেন্সি, এবং কষ্টসমাধান/কস্ট টিউনিং স্পষ্ট।
Cons: এখন আরেকটি সিস্টেম অপারেট করতে হয় এবং একটি এনালিটিক্স-ফ্রেন্ডলি ডেটা মডেল (প্রায়ই স্টার স্কিমা) দরকার হয়।
Best fit: ডেটা বৃদ্ধি, বহু স্টেকহোল্ডার, জটিল রিপোর্টিং, অথবা কঠোর OLTP ল্যাটেন্সি প্রয়োজন হলে।
পর্বিক ETL-এর বদলে আপনি OLTP লগ থেকে CDC (চেঞ্জ ডেটা ক্যাপচার) ব্যবহার করে ওয়ারহাউসে স্ট্রিম করতে পারেন (প্রায়ই ELT সহ)।
Pros: পরীক্ষার মতো ডেটা আরো তাজা হয়, OLTP-তে কম লোড, ইনक्रিমেন্টাল প্রসেসিং সহজ, এবং অডিটযোগ্যতা ভালো হয়।
Cons: আরও বেশি চলন্ত অংশ এবং স্কিমা চেঞ্জ সাবধানে হ্যান্ডেল করতে হয়।
Best fit: বড় ভলিউম, উচ্চ ফ্রেশনেস চাহিদা, এবং ডেটা পাইপলাইন পরিচালনার প্রস্তুতি থাকা টিম।
আপনার ট্রানজেকশনাল ডাটাবেস থেকে অ্যানালিটিক্স সিস্টেমে ডেটা সরানো হল "টেবিল কপি করা"-র বেশি—এটা নির্ভরযোগ্য, কম-প্রভাবশালী পাইপলাইন তৈরি করা। লক্ষ্য সহজ: অ্যানালিটিক্স পায় যা প্রয়োজন, প্রোডাকশন ট্রাফিকে ঝুঁকি না নিয়ে।
ETL (Extract, Transform, Load) মানে আপনি ডেটা লোড করার আগে পরিষ্কার ও রিশেপ করেন। এটা তখন উপযোগী যখন ওয়ারহাউসের কম্পিউট ব্যয় বেশি বা আপনি সংরক্ষণে কড়া নিয়ন্ত্রণ চান।
ELT (Extract, Load, Transform) প্রথমে কাঁচা-রূপ ডেটা লোড করে, পরে ওয়ারহাউসে পরিবর্তন করেন। এটি সাধারণত দ্রুত সেটআপ হয় এবং সহজে বিবর্তনশীল: আপনি সুত্র-তথ্যের ইতিহাস রাখেন এবং প্রয়োজন বদলে গেলে ট্রান্সফর্ম সমন্বয় করতে পারেন।
একটি ব্যবহারিক নিয়ম: ব্যবসায়িক লজিক ঘনঘন বদলে গেলে ELT পুনরায় কাজ কমায়; যদি প্রশাসনিকভাবে কেবল কিউরেটেড ডেটা রাখতে চান, ETL ভাল হতে পারে।
Change Data Capture (CDC) OLTP-এ হওয়া ইনসার্ট/আপডেট/ডিলিটকে স্ট্রিম করে (প্রায়ই DB লগ থেকে) আপনার অ্যানালিটিক্স সিস্টেমে। বড় টেবিল বারবার স্ক্যান করার বদলে CDC দিয়ে শুধু বদলে যাওয়া অংশটুকুই নেয়া যায়।
এটি যা সক্ষম করে:
ফ্রেশনেস একটি ব্যবসায়িক সিদ্ধান্ত এবং এর কারিগরি খরচ আছে।
স্পষ্ট SLA লিখে রাখুন (উদাহরণ: "ডেটা 15 মিনিটের মধ্যে আপডেট থাকে") যাতে স্টেকহোল্ডাররা জানে "ফ্রেশ" মানে কী।
পাইপলাইনগুলো সাধারণত নীরবে ভেঙে—যতক্ষণ না কেউ সংখ্যার তফাৎ দেখে। হালকা চেক যোগ করুন:
এই নিরাপত্তা ব্যবস্থা OLAP-কে বিশ্বাসযোগ্য রাখে এবং OLTP-কে সুরক্ষিত রাখে।
OLTP ও OLAP একসাথে রাখা স্বয়ংক্রিয় ভাবে ভুল নয়। এটি যুক্তিযুক্ত অস্থায়ী পছন্দ হতে পারে যখন অ্যাপ ছোট, রিপোর্টিং সীমিত, এবং আপনি কঠোর সীমা আরোপ করতে পারেন যাতে অ্যানালিটিক্স আপনার গ্রাহকদের ধীর চেকআউট বা টাইমআউটে না ফেলেই ক্রিয়াশীল থাকে।
ছোট অ্যাপ যেখানে হালকা অ্যানালিটিক্স ও কঠোর কুয়েরি সীমা আছে সাধারণত একটি ডাটাবেসেই ভালো চলে—বিশেষত আরম্ভে। কীভাবে "হালকা" সংজ্ঞায়িত করবেন তা স্পষ্ট রাখা দরকার: কয়েকটি ড্যাশবোর্ড, সীমিত সারি সংখ্যা, এবং কুয়েরি রানটাইম ও কনকারেন্সির পরিষ্কার ছাদের উপরে।
নির্দিষ্ট পুনরাবৃত্তি রিপোর্টের জন্য materialized views বা summary tables ব্যবহার করলে অ্যানালিটিক্সের ব্যয় কমে। কাঁচা ট্রানজেকশন স্ক্যান না করে আপনি দৈনিক মোট, টপ ক্যাটাগরি, বা কাস্টমার-ভিত্তিক রোলআপ আগে থেকে গণনা করে রাখুন—এতে বেশিরভাগ কুয়েরি ছোট ও পূর্বানুমেয় থাকে।
ডিলেইড নম্বর মানতে পারলে, অফ-পিক রিপোর্টিং উইন্ডো কাজে লাগে। রাত বা কম-ট্রাফিক সময়ে ভারী জব স্কেজিউল করুন, এবং স্পষ্ট পারমিশন ও রিসোর্স সীমা থাকা একটি ডেডিকেটেড রিপোর্টিং রোল বিবেচনা করুন।
যদি আপনি দেখেন ট্রানজেকশন লেটেন্সি বাড়ছে, রিপোর্ট চালানোর সময় পুনরায় ইনসিডেন্ট, কানেকশন পুল এক্সহস্টশন, বা "একটি কুয়েরি প্রোডাকশন ডাউন করে দিয়েছে" গল্প — আপনি নিরাপদ অঞ্চলের বাইরে চলে এসেছেন। সেই মুহূর্তে ডাটাবেস আলাদা করা কেবল অপ্টিমাইজেশন নয় বরং বেসিক অপারেশনাল হাইজিন হয়ে যায়।
অ্যানালিটিক্স প্রোডাকশন ডাটাবেস থেকে সরানো একটি বড় রিরাইট নয়—এটি কাজকে দৃশ্যমান করা, লক্ষ্য স্থির করা, এবং নিয়ন্ত্রিত ধাপে মাইগ্রেট করার ব্যাপার।
অনুমান নয়, প্রমাণ দিয়ে শুরু করুন। তালিকা বানান:
লুক-হোটেন অ্যানালিটিক্সও অন্তর্ভুক্ত করুন: BI টুলের অ্যাড-হক SQL, নির্ধারিত এক্সপোর্ট, এবং CSV ডাউনলোড।
আপনি কী জন্য অপ্টিমাইজ করবেন তা লিখে রাখুন:
এটা বিতর্ক এড়ায় "এটা ধীর" বনাম "এটা ঠিক আছে" এবং সঠিক আর্কিটেকচার বেছে নিতে সাহায্য করে।
টার্গেট পূরণ করার জন্য সহজতম অপশন বেছে নিন:
রেপ্লিকা ল্যাগ/পাইপলাইন ডিলেই/ড্যাশবোর্ড রানটাইম/ওয়ারহাউস খরচ মনিটর করুন। কুয়েরি বাজেট (টাইমআউট, কনকারেন্সি লিমিট), এবং ইনসিডেন্ট প্লেবুক রাখুন: ফ্রেশনেস স্লিপ করলে, লোড spike হলে, বা কী-মেট্রিক বিচ্যুত হলে কী করবেন।
প্রোডাক্টের শুরুতে দ্রুত গড়ানোর সময় সবচেয়ে বড় ঝুঁকি হচ্ছে ভাসমানভাবে অ্যানালিটিক্সকে একই ডাটাবেস পথের মধ্যে বানানো (উদাহরণ: ড্যাশবোর্ড কুয়েরি যা নীরবে “প্রোডাকশন-ক্রিটিকাল” হয়ে যায়)। একরকম এড়ানোর উপায় হল আলাদা করার পরিকল্পনা শুরু থেকেই করা—যদিও আপনি একটি সামান্য রিড রেপ্লিকা দিয়ে শুরু করেন—এবং এটিকে আর্কিটেকচার চেকলিস্টে ঢুকিয়ে রাখা।
কিছু প্ল্যাটফর্ম যেমন Koder.ai এখানে সাহায্য করতে পারে কারণ আপনি OLTP পাশে প্রোটোটাইপ করতে (React অ্যাপ + Go সার্ভিস + PostgreSQL) এবং রিপোর্টিং/ওয়ারহাউস সীমানা প্ল্যানিং মোডে স্কেচ করতে পারেন শিপ করার আগে। প্রোডাক্ট বাড়লে আপনি সোর্স কোড এক্সপোর্ট করতে, স্কিমা বিবর্তন করতে, এবং CDC/ELT উপাদান যোগ করতে পারবেন যাতে "প্রোডাকশনে রিপোর্টিং" প্রকৃত অভ্যাসে কামড় না বসায়।
OLTP (Online Transaction Processing) দৈনন্দিন অপারেশন যেমন অর্ডার তৈরি করা, স্টক আপডেট এবং পেমেন্ট রেকর্ড করার কাজ করে। এটি কম লেটেন্সি, উচ্চ কনকারেন্সি, এবং সঠিকতার ওপর গুরুত্ব দেয়।
OLAP (Online Analytical Processing) বড় স্ক্যান ও অ্যাগ্রিগেশন ব্যবহার করে ব্যবসায়িক প্রশ্নের উত্তর দেয় (ড্যাশবোর্ড, ট্রেন্ড, কোহর্ট বিশ্লেষণ)। এটি থ্রুপুট, নমনীয় কুয়েরি, এবং দ্রুত সংক্ষিপ্তসারকে প্রাধান্য দেয়—মিলিসেকেন্ড রেসপন্স টাইম নয়।
কারণ দুটো ওয়ার্কলোড একই রিসোর্সের জন্য প্রতিদ্বন্দ্বিতা করে:
ফলাফল হিসেবে প্রায়ই আপনার কোর ইউজার অ্যাকশনগুলোর p95/p99 লেটেন্সি অনিয়মিত হয়ে পড়ে।
সাধারণত নয়। ড্যাশবোর্ডগুলোকে দ্রুত করতে ইনডেক্স বাড়ালে অনেক সময় বিপর্যয় ঘটে কারণ:
অ্যানালিটিক্সের জন্য সাধারণত ভালো ফল মেলে (materialized views, rollups) ব্যবহার করলে।
MVCC পাঠক ও লেখককে ব্লক না করাতে সহায়তা করে, কিন্তু মিশ্র ওয়ার্কলোডকে বিনামূল্যে করে না। বাস্তব সমস্যা:
অতএব, দৃশ্যমান ব্লকিং না থাকলেও ভারী অ্যানালিটিক্স ধীরে ধীরে পারফরম্যান্স নষ্ট করে।
সাধারণ সংকেতগুলো:
যদি ড্যাশবোর্ড রিফ্রেশ করার সময় সিস্টেম 'র্যান্ডমলি স্লো' মনে হয়, সেটাই মিশ্র-ওয়ার্কলোডের ক্লাসিক লক্ষণ।
রিড রেপ্লিকা সাধারণত প্রথম ধাপ হিসেবে উপযোগী:
ডেটা ভলিউম সামান্য এবং "মিনিটদের পিছনে" থাকা গ্রহণযোগ্য হলে এটি ভাল ব্রিজ।
ওয়্যারহাউস ভালো যখন আপনি চান:
এটি সাধারণত একটি এনালিটিক্স-ফ্রেন্ডলি মডেল (স্টার/স্নোফ্লেক) এবং ডেটা লোড করার জন্য একটি পাইপলাইন দরকার করে।
CDC (Change Data Capture) OLTP ডাটাবেস থেকে ইনসার্ট/আপডেট/ডিলিটগুলো (প্রায়ই লগ থেকে) স্ট্রিম করে analytics-এ পাঠায়।
এটি উপকার করে কারণ:
Trade-off হলো আরও বেশি মোভিং পার্টস এবং স্কিমা চেঞ্জ ও অর্ডারিং সাবধানে হ্যান্ডেল করার প্রয়োজন।
নিচের ভিত্তিতে পছন্দ করুন:
বাস্তব প্রয়োগে ELT দিয়ে শুরু করা দ্রুত হয়; পরে গভার্নেন্স (টেস্ট, কিউরেটেড মডেল) যোগ করুন যখন ক্রিটিক্যাল মেট্রিক স্থির হয়ে যায়।
হ্যাঁ—অস্থায়ীভাবে—যদি আপনি অ্যানালিটিক্সকে সত্যিই হালকা রাখেন এবং কঠোর গার্ডরেইল যোগ করেন:
এই নিয়মগুলো প্রয়োগ করা হয়েই এটাকে কার্যকর রাখা যায়, কিন্তু যখন রিপোর্টিং নিয়মিত লেটেন্সি স্পাইক বা প্রোডাকশন ইনসিডেন্ট তৈরি করে, তখন আলাদা করা অপরিহার্য।