জখন জার্গন ছাড়া বলা যায়: সেম্যান্টিক সার্চ কী
সেম্যান্টিক সার্চ এমন এক ধরনের অনুসন্ধান যা শুধুমাত্র আপনি যে শব্দগুলো টাইপ করছেন তা নয়—আপনি কী বলতে চাচ্ছেন তা বোঝার ওপর গুরুত্ব দেয়।
যদি কখনও সার্চ করে ভেবে থাকেন, “উত্তর তো স্পষ্টভাবে আছে—কেন এটা খুঁজে পাচ্ছে না?”, তাহলে আপনি কিওয়ার্ড সার্চের সীমা অনুভব করেছেন। প্রচলিত সার্চ টার্ম মিলায়; এটা তখন কাজ করে যখন আপনার কুয়েরি ও কন্টেন্টের শব্দগুলো ওভারল্যাপ করে।
কেন কিওয়ার্ড সার্চ প্রায়ই কাজে ব্যর্থ হয়
কিওয়ার্ড সার্চ লড়াই করে:
- সমার্থক শব্দ ও ভঙ্গি: “cancel” বনাম “close” বনাম “terminate” (অ্যাকাউন্ট)।
- ইনটেন্ট: “how do I stop being billed?” আসলে সাবস্ক্রিপশন বাতিল করার কথাই জানতে চায়।
- প্রসঙ্গ: “apple charger” (ব্র্যান্ড) বনাম “apple tree charger” (অযৌক্তিক, কিন্তু ধারণা পাওয়া যায়)।
এটা বারবার ব্যবহৃত শব্দগুলোকে বেশি ওজন দিতে পারে, ফলে সারফেসে প্রাসঙ্গিক দেখলেও এমন পেজগুলি পিছিয়ে পড়ে যা ভিন্ন ভাষায় সঠিক উত্তর দেয়।
একটি সহজ উদাহরণ
ধরুন একটি হেল্প সেন্টারে একটি আর্টিকেল শিরোনাম “Pause or cancel your subscription.” ব্যবহারকারী সার্চ করে:
“stop my payments next month”
কিওয়ার্ড সিস্টেম যদি “stop” বা “payments” শব্দটা না পায়, সেই আর্টিকেলকে উঁচুতে র্যাঙ্ক নাও করতে পারে। সেম্যান্টিক সার্চ বুঝতে পারে যে “stop my payments” এবং “cancel subscription” প্রায় একই মানে রাখে—তাই ঐ আর্টিকেলকে টপ-এ নিয়ে আসে।
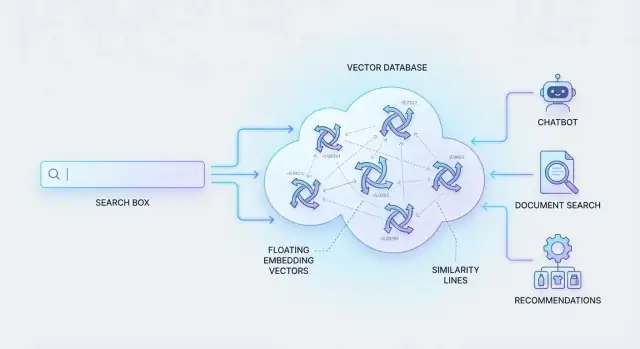
ভেক্টর ডেটাবেসের ভূমিকা
এই কাজ করার জন্য সিস্টেম কনটেন্ট ও কুয়েরিকে “অর্থের ফিঙ্গারপ্রিন্ট” (সংখ্যা যা সাদৃশ্য ব্যাখ্যা করে) হিসেবে উপস্থাপন করে। তারপর মিলিয়ন মিলিয়ন এই ফিঙ্গারপ্রিন্ট দ্রুত সার্চ করতে হয়।
ঠিক তাই ভেক্টর ডেটাবেস তৈরি করা হয়েছে: এসব সংখ্যাগত উপস্থাপনা সংরক্ষণ করা এবং সবচেয়ে মিলযুক্ত ম্যাচগুলো দ্রুত রিট্রিভ করা যাতে বড় আকারেও সেম্যান্টিক সার্চ তাৎক্ষণিক মনে হয়।
এম্বেডিং: কনটেন্টকে অর্থপূর্ণ ভেক্টরে রূপান্তর
এম্বেডিং হলো একটি সংখ্যাগত উপস্থাপনা যা অর্থ ধারণ করে। ডকুমেন্টকে কিওয়ার্ড দিয়ে বর্ণনা করার বদলে, আপনি এটিকে সংখ্যার একটি তালিকা (একটি “ভেক্টর”) হিসেবে উপস্থাপন করেন যা কনটেন্টের বিষয়বস্তু ধরতে পারে। দুইটা কনটেন্ট যার অর্থ একই রকম, তাদের ভেক্টরগুলো ঐ সংখ্যাগত স্থানে একে অপরের কাছে থাকে।
এম্বেডিং আসলে কেমন দেখায়
এম্বেডিংকে উচ্চ-ডাইমেনশনাল ম্যাপের একটি কোঅর্ডিনেট হিসেবে ভাবুন। সাধারণত আপনি সংখ্যাগুলো সরাসরি পড়েন না—এগুলো মানুষের পঠিত হওয়ার জন্য নয়। এর মূল্য এই যে তারা কিভাবে আচরণ করে: যদি “cancel my subscription” এবং “how do I stop my plan?” কাছাকাছি ভেক্টর দেয়, সিস্টেম এইগুলোকে সম্পর্কিত হিসেবে গ্রহণ করবে—যদি শব্দ শেয়ার কমই বা শূন্যই থাকে।
টেক্সট, ছবি, এবং অডিও—সবকিছু ভেক্টরে রূপান্তর করা যায়
এম্বেডিং কেবল টেক্সটে সীমাবদ্ধ নয়।
- টেক্সট এম্বেডিং বাক্য, অনুচ্ছেদ, সাপোর্ট টিকেট, প্রোডাক্ট বর্ণনা ইত্যাদি উপস্থাপন করে।
- ইমেজ এম্বেডিং ভিজ্যুয়াল সাদৃশ্য ও ধারণা (যেমন “লাল রঙের রানিং শু”) উপস্থাপন করে।
- অডিও এম্বেডিং স্পিকার, টোন, বা কথোপকথনের অর্থ প্রতিনিধিত্ব করতে পারে (স্পিচ মডেলের সাথে জোড়া দিলে)।
এভাবেই একক ভেক্টর ডেটাবেস “ইমেজ দিয়ে সার্চ করুন”, “মিলের মতো গান খুঁজুন” বা “এমন প্রোডাক্ট রিকমেন্ড করুন”—এসব সমর্থন করতে পারে।
মডেল দ্বারা জেনারেটেড, হাতে ট্যাগ করা নয়
ভেক্টর ম্যানুয়ালি ট্যাগ করে তৈরি করা হয় না। এগুলো মেশিন লার্নিং মডেল দ্বারা উৎপন্ন হয় যেগুলো অর্থকে সংখ্যায় কড়ে তোলে। আপনি কনটেন্টটি এম্বেডিং মডেলে পাঠান (নিজে হোস্ট করা বা প্রোভাইডারের), এবং এটি একটি ভেক্টর রিটার্ন করে। আপনার অ্যাপ সেই ভেক্টরকে মূল কনটেন্ট ও মেটাডেটার সাথে সংরক্ষণ করে।
এম্বেডিং নির্বাচন মান এবং খরচে প্রভাব ফেলে
আপনি যে এম্বেডিং মডেল বেছে নেবেন তা ফলাফলেও বেশ প্রভাব ফেলে। বড় বা বিশেষায়িত মডেল প্রাসঙ্গিকতা বাড়াতে পারে কিন্তু খরচও বেশি এবং ধীর হতে পারে। ছোট মডেল সস্তা ও দ্রুত হতে পারে, তবে ডোমেইন-নির্দিষ্ট ভাষা, বহু ভাষা, বা সংক্ষিপ্ত কুয়েরির সূক্ষ্মতা মিস করতে পারে। অনেক দল প্রথমে কয়েকটি মডেল টেস্ট করে সেরা ট্রেড-অফ খুঁজে নেয়।
ভেক্টর ডেটাবেস কীভাবে ডাটা সংরক্ষণ করে
ভেক্টর ডেটাবেসটি একটি সহজ ধারণার উপর গড়া: “অর্থ” (ভেক্টর) সেই তথ্যের সাথে সংরক্ষণ করুন যা আপনি আইটেম চিহ্নিত, ফিল্টার ও প্রদর্শনের জন্য প্রয়োজন।
বেসিক ডাটা মডেল
বেশিরভাগ রেকর্ড এইরকম দেখা যায়:
- ID: একটি ইউনিক আইডেন্টিফায়ার আপনি নিয়ন্ত্রণ করেন (যেমন
doc_18492 বা একটি UUID)
- Vector (embedding): কনটেন্টের অর্থ উপস্থাপনকারী সংখ্যার অ্যারে
- Metadata: কী–ভ্যালু ফিল্ড যেমন title, URL, tags, author, language, created_at, বা tenant_id
উদাহরণস্বরূপ, একটি হেল্প-সেন্টার আর্টিকেল সংরক্ষণ করতে পারে:
- ID:
kb_123
- Vector: 768টি ফ্লোটিং-পয়েন্ট সংখ্যা (একটি সাধারণ এম্বেডিং মডেলের জন্য)
- Metadata:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
ভেক্টর সেম্যান্টিক সাদৃশ্য চালায়। ID এবং মেটাডেটা ফলাফলকে ব্যবহারযোগ্য করে তোলে।
মেটাডেটা কেন প্রত্যাশার থেকে বেশি গুরুত্বপূর্ণ
মেটাডেটা দুইটি কাজ করে:
- ভেক্টর সার্চের আগে/পরে ফিল্টারিং: “শুধু প্রোডাক্ট X-এর থেকে দেখাও”, “শুধু ইংরেজি”, “শুধু যেগুলো ইউজার দেখার যোগ্য” বা “শুধু ৯০ দিনের মধ্যে জেনারেট হওয়া আইটেম”। relevance ও access control-এর জন্য এটি অপরিহার্য।
- প্রদর্শন ও অ্যাকশন: ব্যবহারকারীরা একটি ভেক্টর চাই না—তারা শিরোনাম, স্নিপেট, এবং একটি লিংক দেখতে চায়। মেটাডেটা UI-কে প্রয়োজনীয় বিবরণ দেয়।
ভাল মেটাডেটা না থাকলে, আপনি সঠিক অর্থ রিট্রিভ করতে পারেন, তবু ভুল প্রসঙ্গ দেখাতে পারেন।
সাধারণ ভেক্টর সাইজ ও স্টোরেজ প্রভাব
এম্বেডিং সাইজ মডেলের উপর নির্ভর করে: 384, 768, 1024, এবং 1536 ডাইমেনশন সাধারণ। বেশি ডাইমেনশন সূক্ষ্মতা ধরে রাখতে পারে, কিন্তু এসব বাড়ায়:
- স্টোরেজ (প্রতি রেকর্ডে বেশি সংখ্যা সংরক্ষণ করতে হয়)
- মেমরি চাপ দ্রুত সার্চের জন্য
- ইনডেক্স বিল্ড টাইম (বিশেষ করে ANN ইনডেক্সিং সহ)
একটি সহজ ইন্টুইশন: ডাইমেনশন ডবল করলে সাধারণত খরচ ও লেটেন্সি বাড়ে যদি না আপনি ইনডেক্সিং বা কম্প্রেশন দিয়ে সামঞ্জস্য করেন।
আপডেট প্যাটার্ন: ইনসার্ট, চেঞ্জ, ডিলিট
রিয়েল ডাটাসেট পরিবর্তনশীল, তাই ভেক্টর ডেটাবেস সাধারণত সমর্থন করে:
- Insert: নতুন কনটেন্ট এম্বেডিং ও মেটাডেটা সহ যোগ করা
- Update: মেটাডেটা পরিবর্তন (যেমন ট্যাগ) বা কনটেন্ট বদলে ভেক্টর প্রতিস্থাপন
- Delete: পুরানো বা প্রত্যাহৃত কনটেন্ট মুছা
- Re-embed: আপনি যখন এম্বেডিং মডেল বদলান, chunking বদলান, বা টেক্সট বড়ভাবে এডিট করেন তখন ভেক্টর পুনরায় গণনা করা
প্রথম থেকেই আপডেট প্ল্যান করলে “স্টেল নলেজ” সমস্যা (যেখানে সার্চ এমন কনটেন্ট ফিরিয়ে দেয় যা আর সঠিক নেই) এড়ানো যায়।
সাদৃশ্য অনুসন্ধান: দ্রুত "সবচেয়ে কাছের অর্থ" খুঁজে পাওয়া
যখন আপনার টেক্সট, ইমেজ, বা প্রোডাক্টগুলিকে এম্বেডিংয়ে রূপান্তর করা হয়েছে, সার্চ একটি জ্যামিতিক সমস্যা হয়ে যায়: “এই কুয়েরি ভেক্টরের জন্য কোন ভেক্টরগুলো সবচেয়ে কাছের?” এটিই nearest-neighbor search। কিওয়ার্ড মিল নয়; সিস্টেম দুইটি ভেক্টরের কাছাকাছিতা পরিমাপ করে অর্থ তুলনা করে।
সহজ ভাষায় nearest neighbors
প্রতিটি কনটেন্টকে একটি বিশাল মাল্টি-ডাইমেনশনাল স্পেসে একটি পয়েন্ট হিসেবে কল্পনা করুন। ব্যবহারকারী যখন সার্চ করে, তাদের কুয়েরি আরেকটি পয়েন্টে রূপান্তর হয়। সাদৃশ্য সার্চ সেই আইটেমগুলো ফিরিয়ে দেয় যাদের পয়েন্টগুলো সবচেয়ে কাছাকাছি—আপনার “nearest neighbors”। এই প্রতিবেশীরা সম্ভবত ইনটেন্ট, টপিক, বা প্রসঙ্গে মিল রাখে, এমনকি যদি তারা একই শব্দ শেয়ার না করুক।
সাধারণ সাদৃশ্য মেট্রিক
ভেক্টর ডেটাবেস সাধারণত কয়েকটি স্ট্যান্ডার্ড উপায় সমর্থন করে “কাছের” স্কোর করার জন্য:
- Cosine similarity: ভেক্টরের মধ্যে কোণ তুলনা করে (দিক/অর্থকে মাপতে ভালো)
- Dot product: কোসাইনের সাথে সম্পর্কিত, কিন্তু ভেক্টর দৈর্ঘ্যেও প্রভাবিত; নিয়ারমাইজড এম্বেডিংসের সাথে প্রায়ই ব্যবহৃত
- Euclidean distance: পয়েন্টগুলোর সরল-রৈখিক দূরত্ব
বিভিন্ন এম্বেডিং মডেল একটি নির্দিষ্ট মেট্রিক মেনে ট্রেন করা থাকে, তাই মডেল প্রোভাইডার যেটা সুপারিশ করে সেটাই ব্যবহার করা গুরুত্বপূর্ণ।
এক্স্যাক্ট সার্চ বনাম আনুমানিক (ANN)
Exact সার্চ প্রতিটি ভেক্টর পরীক্ষা করে প্রকৃত nearest neighbors খুঁজে পায়—তবে এটি ধীরে ও ব্যয়বহুল হয়ে যায় যখন আপনি মিলিয়ন আইটেমে পৌঁছান।
অধিকাংশ সিস্টেম ANN (approximate nearest neighbor) সার্চ ব্যবহার করে। ANN স্মার্ট ইনডেক্সিং স্ট্রাকচার ব্যবহার করে সবচেয়ে সম্ভাব্য প্রার্থীদের দিকে সার্চ সীমিত করে। সাধারণত আপনি সত্যিকারের সেরা ম্যাচগুলোর কাছাকাছি ফলাফল পাবেন—অনেক দ্রুত।
লেটেন্সি বনাম রিকল ট্রেড-অফ
ANN জনপ্রিয় কারণ এটি আপনার প্রয়োজন অনুযায়ী টিউন করার সুযোগ দেয়:
- কম প্রার্থীতে সার্চ করে লেটেন্সি (দ্রুত রেসপন্স) কমান
- বেশি প্রার্থীতে সার্চ করে রিকল বাড়ান (সত্যিকারের টপ ম্যাচগুলো খুঁজে পাওয়ার সম্ভাবনা বাড়ে)
এই টিউনিং-ই ভেক্টর সার্চকে বাস্তব অ্যাপে ভালোভাবে কাজ করায়: রেসপন্স দ্রুত রাখার সময়ও প্রাসঙ্গিক ফলাফল ফেরত দেয়া যায়।
শুরু থেকে শেষ: সেম্যান্টিক সার্চ ওয়ার্কফ্লো
সেম্যান্টিক সার্চকে সহজে বোঝার জন্য এটিকে একটি পাইপলাইন হিসেবে দেখুন: টেক্সটকে অর্থে রূপান্তর করুন, মিলযুক্ত অর্থ রিট্রিভ করুন, তারপর সবচেয়ে উপযোগী ম্যাচগুলো উপস্থাপন করুন।
1) কুয়েরি এম্বেড করুন
ব্যবহারকারী একটি প্রশ্ন টাইপ করে (উদাহরণ: “How do I cancel my plan without losing data?”). সিস্টেম ঐ টেক্সটটিকে এম্বেডিং মডেলে চালায় এবং একটি ভেক্টর উৎপন্ন করে—একটি সংখ্যার অ্যারে যা কুয়েরির অর্থ ধারণ করে, না যে শব্দগুলো সুনির্দিষ্টভাবে ব্যবহৃত হয়েছে।
2) ভেক্টর ডেটাবেস সার্চ
কুয়েরি ভেক্টরটি ভেক্টর ডেটাবেসে পাঠানো হয়, যা আপনার সংরক্ষিত কনটেন্টের মধ্য থেকে সবচেয়ে “কাছের” ভেক্টরগুলো খুঁজে বের করে।
বেশিরভাগ সিস্টেম top-K ম্যাচ রিটার্ন করে: K সবচেয়ে মিলযুক্ত চাঙ্ক/ডকুমেন্ট।
- K কনফিগারেবল কেন: ছোট K দ্রুত এবং প্রায়ই যথেষ্ট (যেমন, K=5)।
- বড় K রিকল বাড়ায় (আপনি সঠিক উত্তর মিস করার সম্ভাবনা কমান), কিন্তু এতে বেশি “প্রায়-প্রাসঙ্গিক” ফলাফল আসতে পারে (উদাহরণ K=50)।
3) (ঐচ্ছিক) রির্যাঙ্কিং দিয়ে সুক্ষ্ম করা
সাদৃশ্য সার্চ গতি-অপ্টিমাইজ করা হয়, তাই প্রাথমিক top-K-এ নিকট-মিস থাকতে পারে। একটি reranker দ্বিতীয় মডেল হিসেবে কুয়েরি এবং প্রতিটি প্রার্থী ফলাফল একসঙ্গে দেখে relevance অনুসারে আবার সাজায়।
চিন্তা করুন: ভেক্টর সার্চ আপনাকে একটি শক্ত শর্টলিস্ট দেয়; reranking শ্রেষ্ঠ অর্ডার বাছাই করে।
4) ফলাফল রিটার্ন করা (বা ডাউনস্ট্রিমে পাঠানো)
অবশেষে, আপনি সেরা ম্যাচগুলো ব্যবহারকারীকে রিটার্ন করবেন (সার্চ ফলাফল হিসেবে), অথবা সেগুলো একটি AI অ্যাসিস্ট্যান্টকে পাঠাবেন (উদাহরণ: একটি RAG সিস্টেম) “গ্রাউন্ডিং” কনটেক্সট হিসেবে।
আপনি যদি এই ধরনের ওয়ার্কফ্লো কোনো অ্যাপে গঠন করেন, তাহলে প্ল্যাটফর্মগুলো (যেমন Koder.ai) দ্রুত প্রোটোটাইপ করতে সাহায্য করতে পারে: আপনি চ্যাট ইন্টারফেসে সেম্যান্টিক সার্চ বা RAG এক্সপেরিয়েন্স বর্ণনা করেন, তারপর React ফ্রন্টএন্ড ও Go/PostgreSQL ব্যাকএন্ড নিয়ে ইটারেট করেন—এবং রিট্রাইভাল পাইপলাইন (embed → vector search → optional rerank → answer) প্রোডাক্টের প্রথম-শ্রেণির অংশ হিসেবে রাখেন।
দ্রুত একটি "কিওয়ার্ড বনাম সেম্যান্টিক" উদাহরণ
আপনার হেল্প সেন্টার আর্টিকেলে লেখা আছে “terminate subscription” এবং ব্যবহারকারী সার্চ করে “cancel my plan”—কিওয়ার্ড সার্চ হয়তো তা মিস করবে কারণ “cancel” আর “terminate” ম্যাচ করে না।
সেম্যান্টিক সার্চ সাধারণত তা রিকট্রিভ করবে কারণ এম্বেডিং উভয় বাক্যই একই ইনটেন্ট বহন করে। রির্যাঙ্কিং যোগ করলে শীর্ষ ফলাফলগুলো কেবল “সাদৃশ্য” নয়, ব্যবহারকারীর প্রশ্নের জন্য সরাসরি কার্যকর হয়ে ওঠে।
হাইব্রিড সার্চ ও মেটাডেটা ফিল্টার দিয়ে ভাল ফলাফল
আপনার ডোমেনে শেয়ার করুন
স্টেকহোল্ডাররা পরীক্ষা করে দেখতে পারবে এমন কাস্টম ডোমেনে আপনার সেম্যান্টিক সার্চ বা চ্যাটবট রাখুন।
শুধু ভেক্টর সার্চ “অর্থ” নিয়ে দারুণ, তবে ব্যবহারকারীরা সবসময় অর্থ অনুযায়ী সার্চ করে না। মাঝে মাঝে তারা নির্দিষ্ট মিল চায়: পুরো নাম, SKU, ইনভয়েস আইডি, বা লগ থেকে কপি করা একটা এরর কোড। হাইব্রিড সার্চ সেম্যান্টিক সিগন্যাল (ভেক্টর) এবং লেক্সিক্যাল সিগন্যাল (রক্ষণশীল কিওয়ার্ড সার্চ যেমন BM25) মিলিয়ে দেয়।
হাইব্রিড সার্চ আসলে কী করে
একটি হাইব্রিড কুয়েরি সাধারণত দুইটি রিট্রিভাল পথ সমান্তরালে চালায়:
- ভেক্টর সার্চ: কনসেপ্ট অনুযায়ী মিল খুঁজে বের করে, এমনকি ভঙিতে ভিন্ন হলে তবু
- কিওয়ার্ড/BM25 সার্চ: একই টোকেন শেয়ার করা কনটেন্ট খুঁজে বের করে, বিরল শব্দগুলোকে পুরস্কৃত করে
সিস্টেম তারপর ঐ প্রার্থীদের একত্র করে একটি র্যাঙ্কড লিস্ট তৈরি করে।
কখন হাইব্রিড ডিফল্ট হওয়া উচিৎ
যখন আপনার ডাটায় “মাস্ট-ম্যাচ” স্ট্রিং থাকে, হাইব্রিড ভালো কাজ করে:
- বিশেষ মডিফায়ারসহ প্রোডাক্ট নাম (যেমন “Pro Max”, “Gen 2”)
- আইডি (অর্ডার নম্বর, টিকেট আইডি, পার্ট নম্বর)
- এরর কোড (“E0421”, “ORA-00933”) এবং কমান্ড ফ্ল্যাগ
- বিরল ডোমেইন টার্ম যেখানে সমার্থক ব্যবহার ঝুঁকিপূর্ণ
শুধু সেম্যান্টিক সার্চ বিস্তৃতভাবে সম্পর্কিত পেজ আনতে পারে; কিওয়ার্ড সার্চ আলাদা ভাষায় থাকা প্রাসঙ্গিক উত্তর মিস করতে পারে। হাইব্রিড উভয় ব্যর্থ-কেস ঢেকে দেয়।
সার্চ স্পেস সংকুচিত করতে মেটাডেটা ফিল্টার
মেটাডেটা ফিল্টার র্যাঙ্কিংয়ের আগে (বা পাশাপাশি) রিট্রাইভাল সীমানা সীমাবদ্ধ করে, relevance ও গতি বাড়ায়। সাধারণ ফিল্টারগুলো:
- Language (শুধু ইংরেজি ডকুমেন্ট ফেরত দিন)
- Date range (সর্বশেষ পলিসি, লেটেস্ট রিলিজ নোট)
- Category or source (ডক্স বনাম টিকেট; “billing” বনাম “security”)
- Access control tags (শুধু ব্যবহারকারী যে দেখার যোগ্য সেগুলো)
স্কোরিং কিভাবে কাজ করে (উচ্চ-স্তরে)
অধিকাংশ সিস্টেম ব্যবহারিকভাবে মিশ্রণ ব্যবহার করে: উভয় সার্চ চালান, স্কোরগুলো নর্মালাইজ করুন যাতে তুলনীয় হয়, তারপর ওজন প্রয়োগ করুন (উদাহরণ: “IDs-এর জন্য কিওয়ার্ডকে বেশি ওজন দিন”)। কিছু প্রোডাক্ট একত্রিত শর্টলিস্টকে একটি লাইটওয়েট মডেল বা নিয়ম দিয়ে পুনরায় র্যাঙ্ক করে, আর ফিল্টারগুলো নিশ্চিত করে যে আপনি সঠিক সাবসেটকে র্যাঙ্ক করছেন।
RAG: ভেক্টর ডেটাবেসকে LLM-র উত্তর গ্রাউন্ড করতে ব্যবহার করা
RAG (Retrieval-Augmented Generation) একটি ব্যবহারিক প্যাটার্ন যা LLM-কে বেশি নির্ভরযোগ্য উত্তর দেয়: প্রথমে প্রাসঙ্গিক তথ্য রিট্রিভ করুন, তারপর জেনারেট করুন—এবং উত্তরটিকে রিট্রিভ করা কনটেক্সটের সঙ্গে বেঁধে রাখুন।
এক লাইনে RAG আইডিয়া
মডেলকে আপনার কোম্পানির ডকস "মনে রাখার" উপর নির্ভর না করে, আপনি সেই ডকসগুলোকে এম্বেডিং হিসেবে স্টোর করেন ভেক্টর ডেটাবেসে, প্রশ্ন সময়ে সবচেয়ে প্রাসঙ্গিক চাঙ্কগুলো রিট্রিভ করেন, এবং সেগুলোকে LLM-কে সাপোর্টিং কনটেক্সট হিসেবে পাঠান।
ভেক্টর ডেটাবেস কেন হ্যালুসিনেশন কমায়
LLM গুলো লেখায় চমৎকার, কিন্তু যখন দরকারি তথ্য না থাকে তারা আত্মবিশ্বাসের সঙ্গে কিছুই উদ্ভাবন করে ফেলতে পারে। ভেক্টর ডেটাবেস কাছাকাছি মানের প্যাসেজগুলো দ্রুত এনে দেয় এবং সেগুলোকে প্রম্পটে দিয়ে মডেলকে “উৎসগুলোর সারাংশ/ব্যাখ্যা করতে” বলে।
এভাবে মডেল উদ্ভাবনের বদলে সূত্রভিত্তিক উত্তর দেয়। এছাড়া কোন চাঙ্কগুলো রিট্রিভ করা হয়েছে তা ট্র্যাক করা সহজ হয় ফলে আপনি উত্স দেখাতে পারেন।
চাঙ্কিং বেসিক (রিট্রিভাল কাজ করুক)
RAG কুয়ালিটি প্রায়ই মডেল থেকে বেশি চাঙ্কিং-এ নির্ভর করে।
- চাঙ্ক সাইজ: পুরো ভাব ধারণকারী ছোট সেকশন লক্ষ্য করুন। খুব ছোট হলে অর্থ হারায়; খুব বড় হলে নয়েজ আসে।
- ওভারল্যাপ: বর্ডারগুলোতে গুরুত্বপূর্ণ বিবরণ আলাদা না পড়ে যাতে একটু ওভারল্যাপ রাখুন।
- কনটেক্সট রাখুন: টাইটেল, হেডিং, এবং আইডেন্টিফায়ার (ডক নাম, সেকশন, তারিখ) মেটাডেটা হিসেবে রাখুন যাতে ফলাফলগুলি বোঝা যায় ও ফিল্টার করা যায়।
সরল RAG পাইপলাইন (বর্ণনা)
এই ফ্লোটা কল্পনা করুন:
User question → Embed question → Vector DB retrieve top-k chunks (+ optional metadata filters) → Build prompt with retrieved chunks → LLM generates answer → Return answer (and sources).
ভেক্টর ডেটাবেস মাঝামাঝি ‘ফাস্ট মেমরি’ হিসেবে থাকে যা প্রতিটি রিকোয়েস্টে সবচেয়ে প্রাসঙ্গিক সাক্ষ্য সরবরাহ করে।
ভেক্টর ডেটাবেস চালিত সাধারণ AI ইউজকেস
RAG প্রোটোটাইপ পরীক্ষা করুন
একটি সহজ RAG অ্যাপ দ্রুত চালু করুন এবং এমবেডিংস, চাঙ্কিং এবং রিট্রিভাল উন্নত করুন।
ভেক্টর ডেটাবেস কেবল সার্চকে “বুদ্ধিমান” করেই থেমে থাকে না—এগুলো এমন পণ্য অভিজ্ঞতা সম্ভব করে যেখানে ব্যবহারকারী স্বাভাবিক ভাষায় যা চায় তা বললে প্রাসঙ্গিক ফলাফল আসে। নিচে কয়েকটি ব্যবহারিক কেস আছে যা বারবার দেখা যায়।
কাস্টমার সাপোর্ট: কিওয়ার্ডের বাইরে উত্তর খুঁজে পাওয়া
সাপোর্ট টিমের কাছে প্রায়ই কনটেন্ট থাকে: নলেজ বেস, পুরনো টিকেট, চ্যাট ট্রান্সক্রিপ্ট, রিলিজ নোট—কিন্তু কিওয়ার্ড সার্চ সমার্থক, প্যারাফ্রেজ, এবং অস্পষ্ট সমস্যা বর্ণনায় হেরে যায়।
সেম্যান্টিক সার্চ ব্যবহার করে একজন এজেন্ট (বা চ্যাটবট) অতীত টিকেট রিট্রিভ করতে পারে যেগুলো একই অর্থ বহন করে, এমনকি ভাষা ভিন্ন থাকলেও। এতে রেজল্যুশন দ্রুত হয়, ডুপ্লিকেশন কমে, এবং নতুন এজেন্ট তাড়াতাড়ি র্যাম্পআপ পায়। ভেক্টর সার্চকে মেটাডেটা ফিল্টার (প্রোডাক্ট লাইন, ভাষা, ইস্যু টাইপ, তারিখ রেঞ্জ) দিয়ে জোরালাভ করালে ফলাফল ফোকাসড থাকে।
প্রোডাক্ট ডিসকভারি: মানুষ যে ভাষায় কথা বলে সেটাই অনুসন্ধান
শপাররা সাধারণত নির্দিষ্ট প্রোডাক্ট নাম জানে না। তারা ইচ্ছা প্রকাশ করে যেমন “small backpack that fits a laptop and looks professional.” এম্বেডিংগুলো পছন্দগুলো—স্টাইল, ফাংশন, সীমাবদ্ধতা—ক্যাপচার করে, ফলে ফলাফল মানুষের সেলস অ্যাসিস্ট্যান্টের মতো লাগে।
এটি রিটেইল ক্যাটালগ, ট্রাভেল লিস্টিং, রিয়েল এস্টেট, জব বোর্ড, এবং মার্কেটপ্লেসে কাজ করে। আপনি সেম্যান্টিক রিলেভ্যান্সকে মূল্য, সাইজ, অ্যাভেইলেবিলিটি, বা লোকেশন মতো স্ট্রাকচার্ড কনস্ট্রেইন্টের সাথে ব্লেন্ড করতেও পারেন।
রিকমেন্ডেশন্স: “এটার মতো” এবং কনটেন্ট ডিসকভারি
একটি ক্লাসিক ভেক্টর-ডেটাবেস ফিচার হলো “এটার মতো আইটেম খুঁজুন।” ব্যবহারকারী যদি কোনো আইটেম দেখেন, আরেকটি আর্টিকেল পড়েন, বা ভিডিও দেখেন, আপনি সম্পর্কিত অন্য কনটেন্ট রিট্রিভ করতে পারেন—এমনকি ক্যাটাগরি মিল না থাকলেও।
এটি কাজে লাগে:
- “More like this” মডিউল
- সম্পর্কিত আর্টিকেল ও নলেজ বেস সাজেশন
- ডুপ্লিকেট বা নিকট-ডুপ্লিকেট শনাক্তকরণ (কনটেন্ট মডারেশন বা ক্লিনআপের জন্য)
অভ্যন্তরীণ সার্চ ও পারমিশন: পলিসি, ডকস, মিটিং নোট
কোম্পানির ভিতরে তথ্য ছড়িয়ে থাকে ডকস, উইকি, পিডিএফ, মিটিং নোটে। সেম্যান্টিক সার্চ কর্মচারীদের স্বাভাবিক ভাষায় প্রশ্ন করে সঠিক সোর্স খুঁজে পেতে সাহায্য করে (“What’s our reimbursement policy for conferences?”) এবং সঠিক সোর্স ফিরিয়ে দেয়।
অনিচ্ছনীয় অংশ হলো এক্সেস কন্ট্রোল—রেজাল্টগুলো অবশ্যই পারমিশন মেনে চলবে। সাধারণত টিম, ডক মালিক, কনফিডেনশিয়ালিটি লেভেল, বা ACL লিস্ট দ্বারা ফিল্টার করে নিশ্চিত করা হয় যে ব্যবহারকারী কেবলযা দেখার অধিকার পেয়েছে তাই দেখতে পায়।
আপনি যদি এটাকে আরও এগিয়ে নিয়ে যেতে চান, একই রিট্রেইভাল লেয়ার grounded Q&A সিস্টেমও চালায় (RAG অংশে কভার করা হয়েছে)।
ডাটা পাইপলাইন: ইনজেশন, চাঙ্কিং, এবং আপডেট
একটি সেম্যান্টিক সার্চ সিস্টেম কেবল সেই পাইপলাইন যতটাই ভালো ততটাই ভালো। যদি ডকুমেন্টগুলো অনিয়মিতভাবে আসছে, খারাপভাবে চাঙ্ক করা হচ্ছে, অথবা এডিট হলে কখনোই রি-এম্বেড না করা হয়, তখন ফলাফল ইউজারের প্রত্যাশার থেকে সরিয়ে যায়।
একটি সহজ ইনজেশন ফ্লো (যা কাজ করে)
অধিকাংশ দল একটি পুনরাবৃত্তিযোগ্য সিকোয়েন্স অনুসরণ করে:
- ডাটা সংগ্রহ (ডকস, PDFs, টিকেট, চ্যাট লগ, উইকি পেজ, প্রোডাক্ট ডাটা)
- পরিষ্কার করা (বয়লারপ্লেট অপসারণ, এনকোডিং ঠিক করা, হোয়াইটস্পেস নরমালাইজ করা, প্রধান টেক্সট এক্সট্র্যাক্ট করা)
- চাঙ্ক করা (বাইট-সাইজ প্যাসেজে ভাগ করা—যেগুলো ব্যবহারকারী আসলে রিট্রিভ করতে চাইবে)
- এম্বেড করা (আপনার নির্বাচিত এম্বেডিং মডেল দিয়ে ভেক্টর জেনারেট করা)
- আপসার্ট করা (ভেক্টর + মেটাডেটা ভেক্টর ডেটাবেসে লিখুন, দরকার হলে প্রতিস্থাপন করে)
“চাঙ্ক” ধাপেই অনেক পাইপলাইন জয় বা পরাজয় পায়। খুব বড় চাঙ্ক অর্থ হ্রাস করে; খুব ছোট হলে প্রসঙ্গ হারায়। বাস্তবসম্মত উপায় হ'ল স্বাভাবিক স্ট্রাকচার (হেডিং, প্যারাগ্রাফ, Q&A জোড়া) অনুযায়ী চাঙ্ক করা এবং ধারাবাহিকতার জন্য সামান্য ওভারল্যাপ রাখা।
এম্বেডিং আপ-টু-ডেট রাখার উপায়
কনটেন্ট নিয়মিত বদলে যায়—পলিসি আপডেট হয়, মূল্য পরিবর্তন হয়, আর্টিকেল রিরাইট হয়। এম্বেডিংকে ডেরাইভড ডেটা হিসেবে বিবেচনা করে পুনঃউৎপন্ন করা উচিত।
সাধারণ কৌশল:
- সোর্স ডকুমেন্ট আইডি, চাঙ্ক ID, এবং কনটেন্ট হ্যাশ সংরক্ষণ করুন। যদি হ্যাশ বদলে যায়, সেই চাঙ্কটি re-embed করুন।
- সফট ডিলিট ব্যবহার করুন (পুরানো চাঙ্কগুলো ইনঅ্যাকটিভ করুন) যাতে ভূতপ্রেত রেজাল্ট এড়ানো যায়।
- সবকিছু পুনরায় করার বদলে নির্বাচনীভাবে পুনর্নির্মাণ করুন।
ব্যাচ বনাম স্ট্রিমিং আপডেট
- ব্যাচ: বড় ব্যাকফিল, নৈতৃক সিঙ্ক, এবং ভবিষ্যদ্বাণিমূলক কন্টেন্টের জন্য উপযুক্ত।
- স্ট্রিমিং: দ্রুত বদল প্রাপ্ত সোর্স (সাপোর্ট টিকেট, ইউজার জেনারেটেড কন্টেন্ট, ইনভেন্টরি)। এটি স্টেলনেস কমায় তবে মনিটরিং ও খরচ নিয়ন্ত্রণে বেশি চ্যালেঞ্জ আনে।
বহু ভাষা ও বহু মডেল
যদি আপনি বহু ভাষা সার্ভ করেন, আপনি একটি মাল্টিলিঙ্গুয়াল এম্বেডিং মডেল ব্যবহার করতে পারেন (সহজ) বা প্রতি-ভাষার মডেল (কখনো বেশি কুয়ালিটি)। মডেল নিয়ে পরীক্ষা করলে আপনার এম্বেডিংগুলো ভার্সন করুন (উদাহরণ: embedding_model=v3) যাতে A/B টেস্ট এবং রোলব্যাক করা যায় ছাড়া সার্চ ভেঙে না যায়।
কিভাবে কুয়ালিটি ও পারফরম্যান্স মূল্যায়ন করবেন
সেম্যান্টিক সার্চ ডেমোতে “ভালো” মনে হতে পারে এবং প্রোডাকশনে ব্যর্থ হতে পারে। পার্থক্য পরিমাপ—আপনাকে স্পষ্ট রিলেভ্যান্স মেট্রিক এবং স্পিড লক্ষ্যমাত্রা দরকার, যা বাস্তব ব্যবহারকারীর কুয়েরির মতো দেখায়।
রিলেভ্যান্স মেট্রিক যা ব্যবহারকারীর সন্তুষ্টি প্রকাশ করে
ছোট সেট মেট্রিক দিয়ে শুরু করুন এবং সময় ধরে সেগুলি বজায় রাখুন:
- Precision / Recall: Precision কয়টি রিটার্নকৃত ফলাফল প্রকৃতপক্ষে প্রাসঙ্গিক; recall কতগুলি প্রাসঙ্গিক আইটেম আপনি রিট্রিভ করতে পেরেছেন। স্পষ্ট “রিলেভেন্ট” সংজ্ঞা থাকলে এগুলো ব্যবহার করুন।
- MRR (Mean Reciprocal Rank): তখন ভালো যখন ব্যবহারকারী এক “সেরা” উত্তর আশা করে। শীর্ষে সঠিক ডকুমেন্ট রাখলে পুরস্কৃত করে।
- nDCG: তখন উপযোগী যখন একাধিক ফলাফল বিভিন্ন স্তরে রিলেভ্যান্স পেতে পারে (খুব প্রাসঙ্গিক বনাম কিছুটা প্রাসঙ্গিক)।
- Latency (p50/p95): গড় তথা টেইল লেটেন্সি উভয়ই ট্র্যাক করুন। দ্রুত p50 থাকলেও ধীর p95 থাকলে ব্যবহারকারীরা এখনও স্লuggish অনুভব করবে।
বিশ্বাসযোগ্য টেস্ট সেট বানান
একটি মূল্যায়ন সেট তৈরি করুন:
- রিয়েল কুয়েরি সার্চ লগ বা সাপোর্ট টিকেট থেকে (অ্যানোনিমাইজড)
- এবং প্রত্যাশিত ডকুমেন্ট (গোল্ড লেবেল) ডোমেইন বিশেষজ্ঞরা সম্মত হয়
- এজ কেইস: সংক্ষিপ্ত কুয়েরি (“refund”), লম্বা প্রশ্ন, অস্পষ্ট টার্ম, বিরল প্রোডাক্ট নাম, এবং "no-result" কুয়েরি যেখানে সঠিক আচরণ হলো “কিছুই পাওয়া যায়নি” বলা
টেস্ট সেট ভার্সন করে রাখুন যাতে রিলিজ পারস্পরিক তুলনা করা যায়।
A/B টেস্টিং ও ফিডব্যাক লুপ
অফলাইন মেট্রিক সবকিছু ক্যাপচার করে না। A/B টেস্ট চালান এবং হালকা সিগন্যাল সংগ্রহ করুন:
- রেজাল্টে থাম্বস আপ/ডাউন
- ক্লিক-থ্রু ও ডওয়েল টাইম
- “Refine search” ইভেন্ট
এই ফিডব্যাক রিলেভেন্স জাজমেন্ট আপডেট করতে এবং ব্যর্থ প্যাটার্ন শনাক্ত করতে সহায়ক।
সময়ের সাথে ড্রিফট মনিটর করা
পারফরম্যান্স পরিবর্তিত হতে পারে যখন:
- আপনি এম্বেডিং মডেল বদলান বা চাঙ্কিং কৌশল পরিবর্তন করেন
- আপনার কর্পাস সরে যায় (নতুন প্রোডাক্ট, পলিসি পরিবর্তন, মৌসুমি টার্ম)
কোন পরিবর্তন হলে আপনার টেস্ট স্যুট পুনরায় চালান, সাপ্তাহিকভাবে মেট্রিক ট্রেন্ড মনিটর করুন, এবং MRR/nDCG-এ হঠাৎ পতন বা p95 ল্যাটেন্সিতে স্পাইকের জন্য অ্যালার্ট সেট করুন।
সিকিউরিটি, প্রাইভেসি, এবং এক্সেস কন্ট্রোল বিবেচনা
আপনার ক্রেডিট বাড়ান
Koder.ai সম্পর্কে কনটেন্ট তৈরি করুন অথবা সহকর্মীদের রেফার করে আপনার বিল্ড সময় বাড়ান।
ভেক্টর সার্চ কিভাবে ডাটা রিট্রিভ করে তা বদলে দেয়, কিন্তু কারা তা দেখতে পারবে তা বদলে দেওয়া উচিত নয়। যদি আপনার সেম্যান্টিক সার্চ বা RAG সিস্টেম সঠিক চাঙ্ক খুঁজে পায়, তা ব্যবহারকারী অনুমোদিত না হলে ভুল করে তিনি তা পেয়ে যেতে পারেন—অতএব রিট্রাইভালে পারমিশন ও প্রাইভেসি ডিজাইন করা জরুরি।
রিট্রাইভাল সময়ে এক্সেস কন্ট্রোল প্রয়োগ করুন
সবচেয়ে নিরাপদ নিয়ম: একজন ব্যবহারকারী কেবল সেই কনটেন্ট রিট্রিভ করতে পারবে যা সে পড়তে পারার অনুমতি পেয়েছে। ভেক্টর ডেটাবেস রিটার্ন করার পরে অ্যাপ দিয়ে লুকোয়ো না—কারণ তখন কন্টেন্ট আপনার স্টোরেজ বাউন্ডারি ছেড়ে গেছে।
প্রায়োগিক পন্থা:
- প্রতি-ডকুমেন্ট (বা প্রতি-চাঙ্ক) ACL: প্রতিটি ভেক্টরের পাশে পারমিশন ফিল্ড সংরক্ষণ করুন যাতে প্রতিটি কুয়েরি সময়েই এগুলো enforce করা যায়।
- টেন্যান্ট আইসোলেশন: মাল্টি-টেন্যান্ট অ্যাপে ডাটা আলাদা করুন (লজিক্যাল পার্টিশন, নেমস্পেস, অথবা আলাদা ইনডেক্স) যাতে ক্রস-টেন্যান্ট লিক এড়ানো যায়।
পারমিশন ফিল্টারের জন্য মেটাডেটা ব্যবহার
অনেক ভেক্টর ডেটাবেস মেটাডেটা-ভিত্তিক ফিল্টার (যেমন tenant_id, department, project_id, visibility) সমর্থন করে যা সাদৃশ্য সার্চের সঙ্গে চলতে পারে। সঠিকভাবে ব্যবহার করলে এটি রিট্রাইভালে পারমিশন প্রয়োগ করার ক্লিন উপায়।
একটি গুরুত্বপূর্ণ দিক: ফিল্টারটি অনিবার্য ও সার্ভার-সাইড করা উচিত, ক্লায়েন্ট-লজিক নয়। "রোল এক্সপ্লোশন" (অনেক বেশি কম্বিনেশন) এ সতর্ক থাকুন। যদি আপনার পারমিশন মডেল জটিল হয়, প্রি-ক্যালকুলেটেড “এফেক্টিভ অ্যাক্সেস গ্রুপ” বা কুয়েরি-টাইম ফিল্টার টোকেন জেনারেট করার জন্য আলাদা অথরাইজেশন সার্ভিস বিবেচনা করুন।
PII ও সংবেদনশীল ডাটা: কি কখনই এম্বেডিংয়ে যাবে না
এম্বেডিং মূল টেক্সট থেকে অর্থ এনকোড করতে পারে। এটা সরাসরি কাঁচা PII প্রকাশ করে না, তবে ঝুঁকি বাড়ায় (যেমন সংবেদনশীল তথ্য পুনরুদ্ধারের সহজতা)।
কাজের নিয়ম:
- যতটা সম্ভব অত্যন্ত সংবেদনশীল ফিল্ড এম্বেডিংয়ে পাঠাবেন না (SSN, পেমেন্ট ডিটেইল, মেডিক্যাল আইডেন্টিফায়ার)
- এম্বেডিং করার আগে রিড্যাকশন করুন যদি টেক্সট সার্চযোগ্য হতে হবে (সঠিক মানগুলো প্লেসহোল্ডার দিয়ে প্রতিস্থাপন)
- অরিজিনালগুলো আলাদাভাবে সংরক্ষণ করুন এবং পারমিশন চেক করার পরে সেগুলোই রিট্রিভ করুন
অপারেশনাল দরকারি বিষয়: ব্যাকআপ, রিটেনশন, অডিট
আপনার ভেক্টর ইনডেক্সকে প্রোডাকশন ডেটা হিসেবে বিবেচনা করুন:
- ব্যাকআপ ও রিকোভারি: ইনডেক্সগুলি পুনর্নির্মাণ ব্যয়বহুল; স্ন্যাপশট বা সোর্স-থেকে রিবিল্ড পাথ পরিকল্পনা করুন
- রিটেনশন পলিসি: সোর্স ডকুমেন্টস মেয়াদ পূর্ণ হলে ভেক্টর ডিলিট করুন
- অডিটেবিলিটি: কে কী কুয়েরি করেছে (কুয়েরি কনটেক্সট ও রিটার্নকৃত ডকুমেন্ট ID লোগ) লগ করুন যাতে তদন্ত ও কমপ্লায়েন্স করা যায়
ভালভাবে করা গেলে, এসব অনুশীলন সেম্যান্টিক সার্চকে ব্যবহারকারীদের কাছে জাদুকরী মনে করিয়ে দেয়—কিন্তু পরে সিকিউরিটি চমক না তৈরি করে।
ভুল, খরচ, এবং একটি ব্যবহারিক নির্বাচন চেকলিস্ট
ভেক্টর ডেটাবেসগুলো “প্লাগ-এন্ড-প্লে” মনে হতে পারে, কিন্তু বেশিরভাগ হতাশা আসে চারপাশের পছন্দগুলো থেকে: কিভাবে চাঙ্কিং করবেন, কোন এম্বেডিং মডেল বাছবেন, এবং কিভাবে আপ-টু-ডেট রাখবেন।
সাধারণ ব্যর্থ মোড (কীভাবে শনাক্ত করবেন)
খারাপ চাঙ্কিং হলো অপ্রাসঙ্গিক রেজাল্টের #1 কারণ। খুব বড় চাঙ্ক অর্থ dilute করে; খুব ছোট হলে প্রসঙ্গ হারায়। যদি ব্যবহারকারীরা প্রায়ই বলেন “ঠিক ডকুমেন্টটাই মিলেছে, কিন্তু ভুল প্যাসেজ দেখাচ্ছে”, আপনার চাঙ্কিং স্ট্র্যাটেজি সম্ভবত উন্নত দরকার।
ভুল এম্বেডিং মডেল নিরবচ্ছিন্ন সেম্যান্টিক মিসম্যাচ হিসেবে দেখা যায়—ফলাফল সাবলীল কিন্তু টপিক-বন্ধ হয় না। এটা তখন হয় যখন মডেল আপনার ডোমেইনের জন্য উপযুক্ত নয় (লিগ্যাল, মেডিকেল, সাপোর্ট টিকেট) বা আপনার কন্টেন্ট টাইপের জন্য (টেবিল, কোড, বহু-ভাষা) নয়।
স্টেল ডাটা দ্রুত বিশ্বাসযোগ্যতা ভেঙে দেয়: ব্যবহারকারী সর্বশেষ পলিসি খুঁজে চান কিন্তু তারা পুরোনো সংস্করণ পায়। সোর্স ডাটা পরিবর্তন হলে এম্বেডিং ও মেটাডেটা আপডেট করা অনিবার্য।
কোল্ড-স্টার্ট এবং empty-results হ্যান্ডলিং
প্রাথমিক পর্যায়ে আপনার কাছে খুব কম কন্টেন্ট, খুব কম কুয়েরি, বা পর্যাপ্ত ফিডব্যাক নাও থাকতে পারে। পরিকল্পনা রাখুন:
- ফলব্যাক: কিওয়ার্ড সার্চ বা কিউরেটেড “টপ উত্তর” যখন সেম্যান্টিক ফলাফল দুর্বল
- Empty-result UX: সম্পর্কিত ক্যাটাগরি দেখান, একটি বোধগম্য প্রশ্ন জিজ্ঞেস করুন, বা ফিল্টারগুলো প্রশস্ত করুন
- ওরম-আপ কুয়েরি: লঞ্চের আগে কিছু প্রতিনিধিত্বমূলক প্রশ্ন দিয়ে টেস্ট করুন
খরচ চালক যে জিনিসগুলো থাকে
খরচ সাধারণত চার জায়গা থেকে আসে:
- এম্বেডিং কম্পিউট (একবারের ব্যাকফিল + চলমান আপডেট)
- স্টোরেজ (ভেক্টর, মেটাডেটা, এবং ইনডেক্স)
- কুয়েরি ভলিউম (রিড, নেটওয়ার্ক এগ্রেস, কনকারেন্টি)
- রির্যাঙ্কিং (ঐচ্ছিক কিন্তু শক্তিশালী; প্রতি-কুয়েরি মডেল খরচ বাড়ায়)
ভেন্ডর তুলনা করলে আপনার প্রত্যাশিত ডকুমেন্ট কাউন্ট, গড় চাঙ্ক সাইজ, এবং পীক QPS ব্যবহার করে একটি মাসিক আনুমানিক চান। অনেক অপ্রত্যাশিত ব্যয় ইনডেক্সিং শেষে ও ট্রাফিক spike-এ ঘটে।
ব্যবহারিক নির্বাচন চেকলিস্ট
এই ছোট চেকলিস্টটি ব্যবহার করে এমন একটি ভেক্টর ডেটাবেস বেছে নিন যা আপনার চাহিদা পূরণ করবে:
- Search quality: কি এটি হাইব্রিড সার্চ (কিওয়ার্ড + ভেক্টর) ও মেটাডেটা ফিল্টার সমর্থন করে? আপনি রির্যাঙ্কার যোগ করতে পারেন কি?
- Performance: ANN ইনডেক্সিং অপশন, পীক ট্রাফিকে পূর্বানুমানযোগ্য লেটেন্সি, এবং সহজ স্কেলিং
- Data operations: আপসার্ট, ডিলিট, রি-ইনডেক্স, ভার্সনিং, ও ব্যাকফিল ডাউনটাইন ছাড়াই
- Observability: কুয়েরি লগ, recall/latency মেট্রিকস, এবং “কেন এই ফলাফল” ডিবাগিং টুল
- Security: এনক্রিপশন, টেন্যান্ট আইসোলেশন, রোল-ভিত্তিক অ্যাক্সেস, এবং পারমিশন-ফিল্টার প্যাটার্ন
- Integration: SDKs, সমর্থিত ভাষা, এবং আপনার স্টোরেজ (S3, DBs, ডক্স) জন্য কানেক্টর
- Total cost: স্টোরেজ, রাইট, রিড, এবং কোনো ম্যানেজড কম্পিউটের জন্য পরিষ্কার মূল্য নির্ধারণ
সঠিক নির্বাচন একটি নতুন ইনডেক্স টাইপ ছাড়াও নির্ভর করে স্থায়িত্বের ওপরে: আপনি কি ডেটা তাজা রাখতে পারেন, এক্সেস নিয়ন্ত্রণ করতে পারেন, এবং কন্টেন্ট ও ট্রাফিক বাড়ার সঙ্গে মান বজায় রাখতে পারেন?