কিভাবে NoSQL ডাটাবেসগুলো স্কেলিং এবং নমনীয়তার সমস্যাগুলো শোধরানোর জন্য উদ্ভব করল?
জানুন কেন NoSQL ডাটাবেস উঠে এলো: ওয়েবের স্কেল, নমনীয় ডেটার চাহিদা, এবং রিলেশনাল সিস্টেমের সীমাবদ্ধতা—সাথে প্রধান মডেল ও ট্রেডঅফ।
কিভাবে NoSQL ডাটাবেসগুলো স্কেলিং এবং নমনীয়তার সমস্যাগুলো শোধরানোর জন্য উদ্ভব করল? | Koder.ai
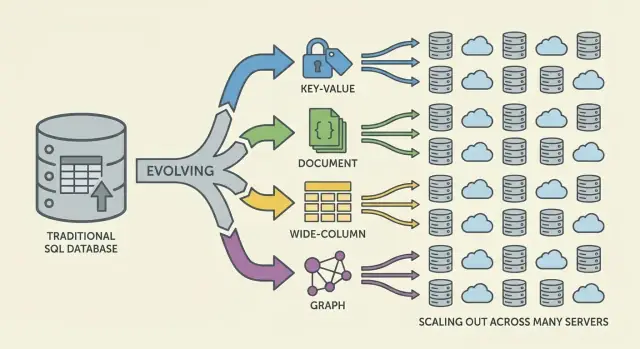
NoSQL কী সমস্যার সমাধান করতে উঠল?\n\nNoSQL তখন উঠে এলো যখন অনেক টিম দেখতে পেল তাদের অ্যাপ যা চাইছে এবং ঐতিহ্যবাহী রিলেশনাল ডাটাবেস (SQL ডাটাবেস) যা অপ্টিমাইজ করে—তার মধ্যে মেলামেশা হচ্ছে। SQL “ব্যর্থ” হয়নি—কিন্তু ওয়েব-স্কেলে কিছু দলের উদ্দেশ্য ভিন্ন হয়ে উঠল।\n\n### দুইটি চাপ: স্কেল এবং পরিবর্তন\n\nপ্রথমত, স্কেল। জনপ্রিয় কনজিউমার অ্যাপগুলো ট্রাফিক স্পাইকের, ধারাবাহিক লেখার, এবং ব্যবহারকারী-উত্পন্ন বিশাল ডেটার সম্মুখীন হতে শুরু করল। এই লোডের জন্য "বড় সার্ভার কিনুন" ধরণ ক্রমে ব্যয়বহুল, ধীর এবং সর্বোপরি সেই বড় মেশিনের সীমাবদ্ধতায় আটকে পড়ল।\n\nদ্বিতীয়ত, পরিবর্তন। প্রোডাক্ট ফিচার দ্রুত বদলায়, এবং তাদের পিছনের ডেটা সবসময় টেবিলের একটি স্থির সেটে ফিট করে না। ইউজার প্রোফাইলের নতুন অ্যাট্রিবিউট যোগ করা, বিভিন্ন ইভেন্ট টাইপ স্টোর করা, বা বিভিন্ন সোর্স থেকে সেমি-স্ট্রাকচার্ড JSON ইনজেস্ট করলে প্রায়শই বারবার স্কিমা মাইগ্রেশন এবং দলীয় সমন্বয় লাগত।\n\n### কবে রিলেশনাল ডাটাবেসগুলো নিরাশ করেছিল\n\nরিলেশনাল ডাটাবেস স্ট্রাকচার প্রয়োগ এবং নর্মালাইজ করা টেবিলের ওপর জটিল কুয়েরি চালাতে দারুণ। কিন্তু কিছু হাই-স্কেল ওয়ার্কলোডে ঐ শক্তিগুলো কাজে লাগানো কঠিন হয়ে পড়ল:\n\n- অনেকগুলো টেবিলে একসাথে কনকারেন্ট রাইট কনটেনশন তৈরি করে।\n- ভারী জয়েন-ভিত্তিক কুয়েরি ডেটা দ্রুত বাড়লে ব্যয়বহুল হয়ে যায়।\n- অনেক মেশিন জুড়ে স্কেল আউট করা সম্ভব, তবে সব জায়গায় কঠোর কনসিস্টেন্সি রাখা অপারেশনালভাবে জটিল হতে পারে।\n\nফলাফল: কিছু টিম এমন সিস্টেম খুঁজল যা নির্দিষ্ট গ্যারান্টি ও ক্ষমতা থেকে ছাড় দিয়ে সহজতর স্কেলিং আর দ্রুত iteration দেয়।\n\n### NoSQL: একক সিস্টেম নয়, এক পরিবার\n\nNoSQL কোনো একক ডাটাবেস বা ডিজাইন নয়। এটি এমন সিস্টেমগুলোর ছত্রছায়া টার্ম যা নিচের দিকগুলোর মিশ্রণকে গুরুত্ব দেয়:\n\n- হরিজন্টাল স্কেলিং (আরও মেশিন যোগ করা)\n- নমনীয় ডেটা মডেল\n- নির্দিষ্ট অ্যাপ্লিকেশন প্যাটার্নগুলোর জন্য টিউন করা এক্সেস প্যাটার্ন\n\n### প্রত্যাশায় একটি রিসেট\n\nNoSQL কখনোই সার্বজনীন SQL বিকল্প হওয়ার জন্য আসেনি। এটি ট্রেডঅফের সেট: আপনি স্কেলিং বা স্কিমা নমনীয়তা পেতে পারেন, কিন্তু হয়ত দুর্বল কনসিস্টেন্সির গ্যারান্টি, কম অ্যাড-হক কুয়েরি অপশন, অথবা অ্যাপ লেভেলে ডেটা মডেলিংয়ের বেশি দায়িত্ব গ্রহণ করতে হবে।\n\n## কেন ঐতিহ্যবাহী স্কেলিং ভেঙে যেতে শুরু করল\n\nবছরগুলোর জন্য, স্লো ডাটাবেসের সাধারণ উত্তর ছিল সহজ: বড় সার্ভার কিনুন। আরো CPU, আরো RAM, দ্রুত ডিস্ক যোগ করুন, একই স্কিমা ও অপারেশনাল মডেল রাখুন। এই "স্কেল আপ" উপায় কাজ করত—যতক্ষণ না তা অপ্রায়োগ্য হয়ে পড়ে।\n\n### ভার্টিকাল স্কেলিং কঠিন সীমায় পৌঁছালো\n\nউচ্চ-শেষ মেশিন দ্রুত ব্যয়বহুল হয়ে যায়, এবং প্রাইস/পারফর্মেন্স কার্ভ অবশেষে অনুকূল নয়। আপগ্রেডগুলো প্রায়শই বড় বাজেট অনুমোদন ও ডেটা মুভ ও কাটওভার এর জন্য বিরামচিহ্ন দরকার করে। এমনকি যদি আপনি বড় হার্ডওয়্যার afford করতে পারেন, একটি সিংগেল সার্ভারেরও সিলিং আছে: একটি মেমরি বাস, এক স্টোরেজ সাবসিস্টেম, এবং একটি প্রাইমারি নোড যা লেখার লোড শোষণ করে।\n\n### বৃদ্ধির সাথে ওয়ার্কলোডের রূপ বদলে গেল\n\nপ্রোডাক্ট বড় হওয়ার সাথে, ডাটাবেসগুলো অতিরিক্ত রিড/রাইট চাপে পড়ল—বিরতি-বিচ্ছিন্ন পিক নয়। ট্রাফিক ২৪/৭ হয়ে উঠল, এবং কিছু ফিচার অসম অ্যাকসেস প্যাটার্ন তৈরি করল। কয়েকটি অত্যন্ত অ্যাক্সেসকৃত রো বা পার্টিশন টপ-হট টেবিল (বা হট কী) তৈরি করত, যা সবকিছুকে ধীর করে দেয়।\n\nঅপারেশনাল বোতলনেক সাধারণ হল:\n\n- নতুন ফিচার চাহিদায় সেকেন্ডারি ইনডেক্স বাড়া\n- একই টেবিলে অনেক কনকারেন্ট রাইট থেকে কনটেনশন\n- লক ওয়েইট যা লোডে ল্যাটেন্সি অনিশ্চিত করে\n- রেপ্লিকেশন ল্যাগ ও ধীর ফেইলওভার ডেটাসেট বাড়লে\n\n### বড় সার্ভারগুলো বৈশ্বিক উপলব্ধি সমাধান করে না\n\nঅনেক অ্যাপ্লিকেশনই কেবল দ্রুত হওয়া নয়—বিভিন্ন অঞ্চলে উপলব্ধ থাকতে চায়। একটি একক “মেইন” ডাটাবেস একটি লোকেশনে থাকলে দূরের ব্যবহারকারীদের জন্য ল্যাটেন্সি বাড়ে এবং আউটেজ আরও ধ্বংসাত্মক হয়ে ওঠে। প্রশ্নটি বদলে গেল: "কিভাবে আমরা ডাটাবেস অনেক মেশিন ও লোকেশনে চালাবো?"\n\n## নমনীয় ডেটা মডেলের প্রয়োজন\n\nরিলেশনাল ডাটাবেস স্থির ডেটা আকারে দুর্দান্ত। কিন্তু অনেক আধুনিক প্রোডাক্ট স্থিতিশীল নয়। একটি টেবিল স্কিমা সচেতনভাবে কড়া: প্রতিটি রো একই কলাম, টাইপ, এবং কনস্ট্রেইন্ট অনুসরণ করে। ঐ পূর্বানুমানযোগ্যতা মূল্যবান—যখন পর্যন্ত আপনি দ্রুত iteration করেন।\n\n### কড়া স্কিমা ও বদলের বাস্তব খরচ\n\nপ্র্যাকটিক্যালিতে, ঘন ঘন স্কিমা পরিবর্তন ব্যয়বহুল। একটি ছোট আপডেটও মাইগ্রেশন, ব্যাকফিল, ইনডেক্স আপডেট, সমন্বিত ডিপ্লয়মেন্ট টাইমিং, এবং পুরনো কোডপাথ ভাঙা না যায় এমন কম্প্যাটিবিলিটি পরিকল্পনা দাবি করে। বড় টেবিলে, এমনকি একটি কলাম যোগ করা বা টাইপ বদলানোও সময়সাপেক্ষ অপারেশন হয়ে দাঁড়াতে পারে এবং প্রকৃত অপারেশনাল ঝুঁকি নিয়ে আসে।\n\nএই ঘর্ষণ টিমকে পরিবর্তন বিলম্ব করতে, ওয়ার্কঅ্যারাউন্ড জমা করতে, অথবা টেক্সট ফিল্ডে মেসি ব্লব স্টোর করতে ধাক্কা দেয়—যা দ্রুত iteration-এর জন্য আদর্শ নয়।\n\n### সেমি-স্ট্রাকচার্ড ডেটা প্রোডাক্টের রূপে ফিট করে\n\nঅনেক অ্যাপ্লিকেশন ডেটা প্রাকৃতিকভাবে সেমি-স্ট্রাকচার্ড: নেস্টেড অবজেক্ট, ঐচ্ছিক ফিল্ড, এবং সময়ের সঙ্গে বিবর্তিত অ্যাট্রিবিউট।\n\nউদাহরণস্বরূপ, একটি “user profile” নাম ও ইমেইল দিয়ে শুরু হতে পারে, পরে প্রেফারেন্স, লিংকড একাউন্ট, শিপিং ঠিকানা, নোটিফিকেশন সেটিংস, এবং এক্সপেরিমেন্ট ফ্ল্যাগ যোগ হতে পারে। সব ব্যবহারকারীর সব ফিল্ড থাকে না, এবং নতুন ফিল্ডগুলো ধাপে ধাপে আসে। ডকুমেন্ট-স্টাইল মডেল নেস্টেড ও অসম আকৃতিগুলো সরাসরি জমা রাখতে দেয়, প্রতিটি রেকর্ডকে একই কঠোর টেমপ্লেটে বাধ্য না করে।\n\n### দ্রুত iteration, কম জটিল জয়েন\n\nফ্লেক্সিবিলিটি কিছু ক্ষেত্রে জটিল জয়েনের প্রয়োজন কমায়। যখন একটি স্ক্রিন একটি রচনাকৃত অবজেক্ট (অর্ডার উইথ আইটেমস, শিপিং ইনফো, স্ট্যাটাস হিস্টরি) পড়ে, রিলেশনাল ডিজাইন অনেক টেবিল ও জয়েন চাইতে পারে—এবং ORM লেয়ার ঐ জটিলতা লুকাতে চেষ্টা করলেও প্রায়ই ঝামেলা বাড়ে।\n\nNoSQL অপশনগুলি ডেটা মডেল অ্যাপের পড়ার/লেখার পদ্ধতির কাছে কাছাকাছি করে তুলতে সহায়ক ছিল, ফলে টিম দ্রুত শিপ করতে পারে।\n\n## ওয়েব-স্কেল শিফট যা ডাটাবেস প্রয়োজন বদলে দিল\n\nওয়েব অ্যাপ শুধু বড় হয়নি—ওরা রূপও বদলালো। পূর্বে নির্দিষ্ট সংখ্যক অভ্যন্তরীণ ব্যবহারকারীদের সার্ভ করার বদলে, প্রোডাক্টগুলো মিলিয়ন-গণকে সার্ভ করতে লাগল ২৪/৭, লঞ্চ, নিউজ বা সোশ্যাল শেয়ারের দ্বারা হঠাৎ স্পাইক দেখা যায়।\n\nসবসময়-অন প্রত্যাশা মান বাড়াল: ডাউনটাইম শিরোনাম হতে পারে, অশান্তি নয়। একই সময়ে, টিমকে দ্রুত ফিচার শিপ করতে বলা হল—প্রায়ই ডেটা মডেল "ফাইনাল" কি হবে জানা ছাড়াই।\n\n### ডিস্ট্রিবিউটেড হওয়া বৃদ্ধি লাভের ডিফল্ট পথ হয়ে গেল\n\nটিকে ধরে রাখতে, একটি একক ডাটাবেস সার্ভার আপ করা আর যথেষ্ট ছিল না। যত বেশি ট্রাফিক, তত বেশি আপনি ধাপে ধাপে ক্যাপাসিটি বাড়াতে চান—আরো নোড যোগ করুন, লোড ছড়ান, ফেইলিউর আলাদা রাখুন।\n\nএটি আর্কিটেকচারকে একাধিক মেশিনের ফ্লিটের দিকে চাপল, এবং টিমগুলো ডাটাবেস থেকে আশা করতে শুরু করল: কেবল সঠিকতা নয়, উচ্চ কনকারেন্সিতে পূর্বানুমানযোগ্য পারফরম্যান্স এবং সিস্টেমের অংশ অসুস্থ হলে মিলিতভাবে আচরণ।\n\n### ডাটাবেস প্রস্তুত হওয়ার আগে টিমগুলো যে প্যাটার্নগুলো গ্রহণ করেছিল\n\n"NoSQL" মেইনস্ট্রিম হবার আগে অনেক টিম ইতিমধ্যেই ওয়েব-স্কেল বাস্তবতার দিকে সিস্টেমগুলোকে বেঁকিয়েছিল:\n\n- ক্যাশিং লেয়ার (প্রায়শই ইন-মেমরি) বারবার রিড কমাতে\n- ডেনর্মালাইজেশন ব্যয়বহুল জয়েন এড়াতে এবং রাউন্ড-ট্রিপ কমাতে\n- প্রিকম্পিউটেড ভিউ এবং ম্যাটেরিয়ালাইজড রোলআপস—ফিড, টাইমলাইন, ড্যাশবোর্ডের জন্য\n\nএই কৌশলগুলো কাজ করলেও, জটিলতা অ্যাপ্লিকেশন কোডে সরে গেল: ক্যাশ ইনভ্যালিডেশন, ডুপ্লিকেট ডেটা কনসিস্টেন্ট রাখা, এবং "রেডি-টু-সার্ভ" রেকর্ড তৈরির পাইপলাইন তৈরি করা।\n\n### কিভাবে এ থেকে ডাটাবেসগুলো পরিবর্তিত হল\n\nযখন এই প্যাটার্নগুলো স্ট্যান্ডার্ড হয়ে উঠল, ডাটাবেসগুলোকে ডেটা মেশিন জুড়ে ডিসট্রিবিউট করা, আংশিক ফেইলিউর সহ্য করা, উচ্চ লেখার পরিমাণ হ্যান্ডেল করা, এবং বিবর্তিত ডেটা পরিষ্কারভাবে উপস্থাপন করা সমর্থন করতে হল। NoSQL ডাটাবেসগুলোর উদ্ভব আংশিকভাবেই ঐ প্র্যাকটিসগুলোকে প্রথম শ্রেণির নাগরিক বানানোর জন্য হয়েছে—যা পূর্বে কনস্ট্যান্ট ওয়ার্কঅ্যারাউন্ড ছিল।\n\n## ডিস্ট্রিবিউটেড ট্রেডঅফ এবং CAP থিওরেম\n\nযখন ডেটা এক মেশিনে থাকে, নিয়ম সহজ মনে হয়: একটি একক সত্যের উৎস আছে, এবং প্রতিটি রিড বা রাইট তৎক্ষণাৎ চেক করা যায়। যখন ডেটা সার্ভার জুড়ে ছড়ায় (প্রায়শই অঞ্চলে), একটি নতুন বাস্তবতা আসে: মেসেজ দেরী হতে পারে, নোড ব্যর্থ হতে পারে, এবং সিস্টেমের অংশ সাময়িকভাবে যোগাযোগ বন্ধ করে দিতে পারে।\n\n### মূল বিতরণশীল ট্রেডঅফ (সহজ ভাষায়)\n\nএকটি বিতরণকৃত ডাটাবেসকে সিদ্ধান্ত নিতে হয় যখন এটি নিরাপদে সমন্বয় করতে পারে না—তবে সে কি করবে। কি- এটি রিকোয়েস্ট সার্ভ করতে থাকবে যাতে অ্যাপ "আপ" থাকে, এমনকি ফলাফল সাময়িকভাবে পুরনো হতে পারে? নাকি কিছু অপারেশন প্রত্যাখ্যান করবে যতক্ষণ না রেপ্লিকাগুলো মিলিত হতে পারে, যা ব্যবহারকারীর কাছে ডাউনটাইমের মতো দেখাতে পারে?\n\nএই পরিস্থিতিগুলো রাউটার ব্যর্থতা, ওভারলোডেড নেটওয়ার্ক, রোলিং ডিপ্লয়মেন্ট, ফায়ারওয়াল কনফিগুরেশন ত্রুটি, এবং ক্রস-রিজিওন রেপ্লিকেশন ডিলে-এর সময় ঘটে।\n\n### CAP এক ফ্রেমে: C, A, এবং P\n\nCAP থিওরেম তিনটি বৈশিষ্ট্যের সংক্ষিপ্ত রূপ:\n\n- Consistency (C): প্রতিটি রিড সর্বশেষ রাইট ফেরত দেয় (অথবা ত্রুটি)। বাস্তবে, “সবার কাছে এখনই একই উত্তর দেখা যায়।”\n- Availability (A): প্রতিটি রিকোয়েস্ট একটি রেসপন্স পায় (প্রয়োজনীয়ত অনুস্য, সর্বশেষ নয়)।\n- Partition Tolerance (P): নেটওয়ার্ক যদি বিভক্ত হয়ে যায়, সিস্টেম কাজ চালিয়ে যায়।\n\nকী পয়েন্টটি হল: নেটওয়ার্ক পার্টিশন ঘটলে, আপনাকে কনসিস্টেন্সি এবং আপটাইমের মধ্যে একটিকে বেছে নিতে হবে। ওয়েব-স্কেলে, পার্টিশনকে অনিবার্য হিসেবে ধরা হয়—বিশেষত মাল্টি-রিজিওন সেটআপে।\n\n### পার্টিশন বাস্তব আউটেজের সঙ্গে সরাসরি জড়িত\n\nধরে নিন আপনার অ্যাপ দুটি অঞ্চলে চালায়। একটি ফাইবার কাট বা রাউটিং সমস্যা সমন্বয় বন্ধ করে দেয়।\n\n- যদি আপনি অ্যাভেইলিবিটি অগ্রাধিকার দেন, দুটো অঞ্চলই রাইট গ্রহণ চালিয়ে যাবে, এবং ডেটা সাময়িকভাবে ভিন্ন হতে পারে।\n- যদি আপনি কনসিস্টেন্সি অগ্রাধিকার দেন, একটি অঞ্চল রাইট (অথবা রিড) প্রত্যাখ্যান করতে পারে যতক্ষণ না সম্মতি নিশ্চিত হয়।\n\nবিভিন্ন NoSQL সিস্টেম (এবং একই সিস্টেমের বিভিন্ন কনফিগারেশন) বিভিন্ন মানদণ্ডে কনফিগার করা থাকে—ব্যবহারকারীর অভিজ্ঞতা ব্যর্থতার সময়, সঠিকতার গ্যারান্টি, অপারেশনাল সরলতা, অথবা রিকভারি আচরণ কোনটি বেশি গুরুত্বপূর্ণ তার উপর ভিত্তি করে।\n\n## স্কেল আউট: শার্ডিং ও রিপ্লিকেশন কোর ধারনা\n\nস্কেল আউট (হরিজন্টাল স্কেলিং) মানে ক্ষমতা বাড়ানো আরো মেশিন (নোড) যোগ করে—বড় সার্ভার কেনার বদলে। অনেক টিমের জন্য এটি আর্থিক ও অপারেশনাল সিড্ডান্ত ছিল: কমদামি কমোডিটি নোড ধাপে ধাপে যোগ করা যায়, ব্যর্থতাকে প্রত্যাশিত হিসেবে ধরা হয়, এবং বৃদ্ধি ঝুঁকিপূর্ণ "বড় বক্স" মাইগ্রেশনের প্রয়োজন করে না।\n\n### শার্ডিং (পার্টিশনিং): কাজ ছড়ানো\n\nঅনেক নোডকে কাজে লাগাতে NoSQL সিস্টেম শার্ডিং (পার্টিশনিং) ব্যবহার করে। একটি ডাটাবেস সব রিকোয়েস্ট হ্যান্ডল করার বদলে, ডেটা পার্টিশনে ভাগ করে ও নোডে বিতরণ করে।\n\nসাধারণ উদাহরণ user_id দিয়ে পার্টিশন করা:\n\n- নোড A: ব্যবহারকারী 1–1,000,000\n- নোড B: ব্যবহারকারী 1,000,001–2,000,000\n\nরিড ও রাইট ছড়িয়ে পড়ে, হটস্পট কমে, এবং নোড যোগ করলে থ্রুপুট বৃদ্ধি পায়। পার্টিশন কী ডিজাইন সিদ্ধান্ত হয়ে ওঠে: কুয়েরি প্যাটার্নের সাথে সামঞ্জস্যপূর্ণ কী নিলে না হলে আপনি অনিচ্ছিতভাবে নির্দিষ্ট শার্ডে বেশি ট্রাফিক funnel করতে পারেন।\n\n### রিপ্লিকেশন: উপলব্ধি ও রিড স্কেলিং\n\nরিপ্লিকেশন মানে একই ডেটার একাধিক কপি বিভিন্ন নোডে রাখা। এটি উন্নত করে:\n\n- উপলব্ধি: একটি নোড ব্যর্থ হলে অন্য রেপ্লিকা রিকোয়েস্ট সার্ভ করতে পারে।\n- রিড সক্ষমতা: একাধিক রেপ্লিকা থেকে রিড সার্ভ করে রিড লোড ছড়ানো যায়।\n\nরিপ্লিকেশন ডেটা র্যাক বা রিজিওন জুড়ে ছড়িয়ে দিয়ে লোকাল আউটেজ টেকসই করে।\n\n### লুকানো খরচ: রিব্যালান্সিং ও অপারেশনস\n\nশার্ডিং ও রিপ্লিকেশন চলমান অপারেশনাল কাজ যোগ করে। ডেটা বাড়লে বা নোড বদলে, সিস্টেমকে রিব্যালান্স করতে হয়—পার্টিশন সরানো চলাকালীন অনলাইনে থাকা। খারাপভাবে হ্যান্ডেল করলে রিব্যালান্স ল্যাটেন্সি স্পাইক, অসম লোড, বা সাময়িক ক্যাপাসিটি কমিয়ে দিতে পারে।\n\nএটি একটি মূল ট্রেডঅফ: অনেক কমদামি নোড যোগ করে সস্তা স্কেলিং, বদলে জটিল ডিস্ট্রিবিউশন, মনিটরিং, এবং ফেইলিউর হ্যান্ডলিং বাড়ে।\n\n## কনসিস্টেন্সি মডেল: শক্ত থেকে ইভেন্টুয়াল পর্যন্ত\n\nএকবার ডেটা বিতরণ করা হলে, ডাটাবেসকে সংজ্ঞায়িত করতে হয় “সঠিক” মানে কী যখন আপডেট কনকারেন্টলি ঘটে, নেটওয়ার্ক ধীর, বা নোড যোগাযোগ করতে পারে না।\n\n### শক্ত (strong) কনসিস্টেন্সি\n\nশক্ত কনসিস্টেন্সিতে, একটি লেখার পরে যেটি অ্যাকনোলেজ করা হয়েছে প্রতিটি রিডার তা অবিলম্বে দেখতে পারে। এটি অনেক সময় সেই "একক সত্যের উৎস" অভিজ্ঞতার সাথে মেলে যা বহু মানুষ রিলেশনাল ডাটাবেসের সাথে যুক্ত করে।\n\nচ্যালেঞ্জ হল সমন্বয়: নোড জুড়ে শক্ত গ্যারান্টি রাখতে একাধিক মেসেজ, পর্যাপ্ত রেসপন্সের জন্য অপেক্ষা, এবং মাঝপথে ব্যর্থতা হ্যান্ডল করা লাগে। নোডগুলো যত দূরে বা ব্যস্ত হবে, প্রতিটি রাইটে তত বেশি ল্যাটেন্সি যোগ হতে পারে।\n\n### ইভেন্টুয়াল কনসিস্টেন্সি\n\nইভেন্টুয়াল কনসিস্টেন্সি গ্যারান্টি শিথিল করে: একটি লেখার পরে, বিভিন্ন নোড সাময়িকভাবে ভিন্ন উত্তর দিতে পারে, কিন্তু সিস্টেম সময়ের সঙ্গে মিলিত হবে।\n\nউদাহরণ:\n\n- একটি "লাইকের" কাউন্টার এক রেপ্লিকায় 101 দেখাতে পারে আর অন্যে 100 এক কয়েক সেকেন্ডের জন্য।\n- একটি নতুন পোস্ট কয়েকজন ইউজারের ফিডে আগেভাগে দেখা যেতে পারে, অন্যের কাছে দেরিতে দেখা যেতে পারে—বিশেষত বিভিন্ন অঞ্চলে।\n\nঅনেক ব্যবহারকারীর অভিজ্ঞতার জন্য সাময়িক অমিল গ্রহণযোগ্য যদি সিস্টেম দ্রুত এবং উপলব্ধ থাকে।\n\n### কনফ্লিক্ট এবং কিভাবে সমাধান করা হয়\n\nযদি দুই রেপ্লিকা প্রায় একসঙ্গে আপডেট গ্রহণ করে, ডাটাবেসকে মার্জ নিয়ম নির্ধারণ করতে হয়।\n\nসাধারণ পদ্ধতি আছে:\n\n- টাইমস্ট্যাম্প (লাস্ট-রাইট-উইন): নতুন টাইমস্ট্যাম্প বিশিষ্ট আপডেট রাখুন। সহজ, কিন্তু ক্লক ড্রিফ্ট বা "নিউএস্ট" মানে সেমান্টিকভাবে সঠিক না হলে ডেটা হারায়।\n- ভার্সন ভেক্টর (কনসেপ্টুয়ালি): কোন রেপ্লিকা কোন আপডেট দেখেছে তা ট্র্যাক করে, কনকারেন্সি সনাক্ত করে, এবং মার্জ বা কনফ্লিক্ট সারফেস করে।\n\n### কোথায় শক্ত কনসিস্টেন্সি এখনও গুরুত্বপূর্ণ\n\nমানি মুভমেন্ট, ইনভেন্টরি সীমা, ইউনিক ইউজারনেম, পারমিশন, এবং যে কোন ওয়ার্কফ্লো যেখানে "ক্ষণিক দুইটি সত্য" আঘাতজনক হতে পারে—ওগুলোর জন্য শক্ত কনসিস্টেন্সি সাধারণত মূল্যবান।\n\n## প্রধান NoSQL ডাটাবেস পরিবারগুলো (ওরা কী অপ্টিমাইজ করেছিল)\n\nNoSQL বিভিন্ন মডেলে বিভক্ত যা স্কেল, ল্যাটেন্সি, এবং ডেটা আকার নিয়ে বিভিন্ন ট্রেডঅফ করে। পরিবারগুলো বুঝলে আপনি জানতে পারবেন কী দ্রুত হবে, কী যন্ত্রণাদায়ক হবে, এবং কেন।\n\n### কি-ভ্যালু স্টোর: সরলতার মাধ্যমে গতি\n\nকি-ভ্যালু ডাটাবেস একটি ইউনিক কী-র পিছনে একটি ভ্যালু রাখে—একধরনের বড় বিতরণকৃত হ্যাশম্যাপ। অ্যাক্সেস প্যাটার্ন সাধারণত "কী দিয়ে পেতে"/"কী দিয়ে সেট করতে" হওয়ায় দ্রুত এবং হরিজন্টালি স্কেলেবল।\n\nযখন আপনি lookup key জানেন (সেশন, ক্যাশিং, ফিচার ফ্ল্যাগ) তখন এগুলো চমৎকার, কিন্তু মাল্টিফিল্ড ফিল্টার বা অ্যাড-হক কুয়েরির জন্য উপযুক্ত নয়।\n\n### ডকুমেন্ট ডাটাবেস: নমনীয় রেকর্ড, JSON-সদৃশ আকার\n\nডকুমেন্ট ডাটাবেস JSON-সদৃশ ডকুমেন্ট (প্রায়শই কালেকশন-এ গ্রুপ) সংরক্ষণ করে। প্রতিটি ডকুমেন্টের স্ট্রাকচার একটু আলাদা হতে পারে, যা প্রোডাক্ট বিকাশে স্কিমা নমনীয়তা দেয়।\n\nএগুলো পুরো ডকুমেন্ট পড়া ও লেখা এবং ডকুমেন্টের ভেতরের ফিল্ড দিয়ে কুয়েরি করার জন্য অপ্টিমাইজ করে—কঠোর টেবিল বাধ্য না করে। ট্রেডঅফ হলো: সম্পর্ক মডেল করা জটিল হতে পারে, এবং যদি জয়েন সাপোর্ট করে তবুও রিলেশনাল সিস্টেমের মতো সমৃদ্ধ নাও হতে পারে।\n\n### ওয়াইড-কলাম স্টোর: বিশাল স্কেলে উচ্চ লেখার থ্রুপুট\n\nওয়াইড-কলাম ডাটাবেস (Bigtable-অনুপ্রেরিত) রো কী দ্বারা ডেটা সংগঠিত করে, প্রতিটি রোতে বহু কলাম থাকতে পারে যা প্রতিটি রোতে ভিন্ন। এগুলো বিশাল লেখার হার ও বিতরণকৃত স্টোরেজে অসাধারণ, তাই টাইম-সিরিজ, ইভেন্ট ও লগ ওয়ার্কলোডে উপযুক্ত।\n\nএগুলো কার্যকরী কুয়েরির জন্য অ্যাক্সেস প্যাটার্ন অনুযায়ী সাবধানে ডিজাইনকে পুরস্কৃত করে: আপনি প্রাইমারি কী এবং ক্লাস্টারিং নিয়ম দিয়ে কার্যকরভাবে কুয়েরি করবেন, সর্বত্র arbitrary ফিল্টার নয়।\n\n### গ্রাফ ডাটাবেস: সম্পর্ক-ভিত্তিক কুয়েরি প্রথম-শ্রেণির\n\nগ্রাফ ডাটাবেস সম্পর্ককে প্রথম-শ্রেণীর ডেটা হিসেবে মানে। বারবার টেবিল জয়েন করার বদলে তারা নোড ও এজ ট্রাভার্স করে, যা "এই জিনিসগুলো কীভাবে সংযুক্ত?" কুয়েরিগুলো দ্রুত ও প্রাকৃতিক করে তোলে (ফ্রড রিং, রেকমেন্ডেশন, ডিপেন্ডেন্সি গ্রাফ)।\n\n### দ্রুত গাইড: প্রতিটি মডেল কখন সর্বোত্তম\n\n- কি-ভ্যালু: আইডি দ্বারা দ্রুত লুকআপ; ক্যাশিং, সেশন, কাউন্টার।
সাধারণ প্রশ্ন
What was NoSQL originally trying to solve?
NoSQL দুই ধরণের চ্যালেঞ্জকে সমাধান করতে এসেছিল:
স্কেল: উচ্চ লেখার চাপ, ট্রাফিক স্পাইক, এবং এমন ডেটাসেট যা একটি একক “বড় সার্ভার” দিয়ে ধরা যাচ্ছে না।
পরিবর্তন: দ্রুত পরিবর্তনশীল প্রোডাক্ট রিকোয়ারমেন্ট যার ফলে রিলেশনাল স্কিমা মাইগ্রেশন বারবার costly ও ঝুঁকিপূর্ণ হয়।
এটি SQL কে “খারাপ” বলে বাদ দেয়নি—বরং আলাদা ওয়র্কলোডগুলো ভিন্ন ট্রেডঅফকে অগ্রাধিকার দেয়।
Why did scaling a single relational database server start to break down?
প্র্যাকটিক্যাল সীমাবদ্ধতাগুলি কারনে “স্কেল আপ” ধীরে ধীরে কাজে লাগতে বাধা দিল:
উচ্চ-শেষ হার্ডওয়্যার দ্রুতই ব্যয়বহুল হয়ে ওঠে এবং আপগ্রেড ব্যাহত করে।
একটি মেশিন লেখার, ডিস্ক ও ফেইলওভারের জন্য একটি বোতলগল হয়ে যায়।
যদি প্রাইমারি ডাটাবেস এক অঞ্চলে থাকে, তাহলে গ্লোবাল ব্যবহারকারীরা উচ্চ ল্যাটেন্সি পায়।
NoSQL সিস্টেমগুলো স্কেল আউট-কে সমর্থন করে—বড় সার্ভার কেনার বদলে নোড যোগ করা।
Why did rigid schemas become a problem for modern applications?
রিলেশনাল স্কিমা ইরর-প্রুফ থাকার জন্য কড়া করা হয়, কিন্তু দ্রুত iteration-এর পরিবেশে তা সমস্যা তৈরি করে। বড় টেবিলে “সরল” পরিবর্তনও প্রায়শই:
মাইগ্রেশন ও ব্যাকফিল দরকার করে
ইনডেক্স আপডেট করতে হয়
দলীয় সমন্বয় লাগতে পারে
রক্ষণাবেক্ষণের ঝুঁকি বা ডাউনটাইম হতে পারে
ডকুমেন্ট-স্টাইল মডেলগুলো অনিশ্চিত ও বিকাশশীল ফিল্ডগুলোকে সহজে রাখতে দেয়, ফলে এই ঘর্ষণ কমে।
Is NoSQL only about horizontal scaling (scaling out)?
সার্বজনীনভাবে না—কিন্তু NoSQL বেশিরভাগ সময়ই ডিস্ট্রিবিউশনের সুবিধাকে সামনে রাখে। বহু SQL ডাটাবেসও আউট করা যায়, কিন্তু এটি অপারেশনালি জটিল (শার্ডিং, ক্রস-শার্ড জয়েন, বিতরণকৃত ট্রানজ্যাকশন)।
NoSQL সিস্টেম অনেক ক্ষেত্রে partitioning + replication-কে প্রাথমিক ডিজাইনের অংশ করে তোলে, বিশেষ প্রদানকারী অ্যাক্সেস প্যাটার্নগুলোর জন্য অপ্টিমাইজ করে।
Why do NoSQL designs often use denormalization and fewer joins?
ডেনর্মালাইজেশন সেই ডেটা আকারে ডেটা রাখে যা অ্যাপ পড়ে—প্রায়শই জায়গা-জায়গায় ফিল্ড অনুলিপি করে, যাতে পার্টিশন জুড়ে ব্যয়বহুল জয়েন এড়ানো যায়.
উদাহরণ: শেষ ২০টি অর্ডার দেখানোর জন্য orders রেকর্ডের মধ্যে গ্রাহকের নাম রেখে দেওয়া—তাতে একবারে দ্রুত পড়া হয়।
পক্ষ হিসেবে আসে আপডেট জটিলতা: অনুলিপি ডেটা সব জায়গায় আপডেট রাখতে অ্যাপ্লিকেশন বা পাইপলাইনের মাধ্যমে যত্ন নিতে হয়।
What does the CAP theorem mean in practical terms for NoSQL?
নেটওয়ার্ক পার্টিশন ঘটলে কী হবে—এই সিদ্ধান্তটাই বাস্তবে CAP থিওরেমের মূল বক্তব্য:
উপলব্ধতাকে অগ্রাধিকার করলে সার্ভিস চালু থাকে, কিন্তু কিছু রিড স্টেইল হতে পারে।
কনসিস্টেন্সিকে অগ্রাধিকার করলে কিছু অপারেশন বন্ধ বা প্রত্যাখ্যাত হতে পারে যতক্ষণ না রেপ্লিকা সম্মত থাকে।
CAP মূলত স্মরণ করায়: পার্টিশনের সময়ে আপনি কনসিস্টেন্সি এবং আপটাইম উভয়ই একসাথে নিশ্চিত করতে পারবেন না।
What’s the difference between strong consistency and eventual consistency?
স্ট্রং কনসিস্টেন্সি মানে—একবার একটি লেখা অ্যাকনোলেজ করা হলে সব রিডার ততোক্ষণাৎ সেটি দেখতে পারবে; সাধারণত নোডগুলোর মধ্যে সমন্বয় দরকার।
ইভেন্টুয়াল কনসিস্টেন্সি মানে—রেপ্লিকাগুলো সাময়িকভাবে ভিন্ন ফলাফল দেখাতে পারে, কিন্তু সময়ের সঙ্গে মিলিত হবে।
এসবের মধ্যে কোনটি উপযুক্ত তা নির্ভর করে: আপনি সাময়িক stale ডেটা সহ্য করতে পারবেন কি না।
How do NoSQL databases handle conflicting writes?
কনফ্লিক্ট তখন ঘটে যখন ভিন্ন রেপ্লিকা একই সময়ে আপডেট গ্রহণ করে। সাধারণ কৌশলগুলো:
লাস্ট-রাইট-উইনস (টাইমস্ট্যাম্প): সর্বশেষ টাইমস্ট্যাম্প বিশিষ্ট আপডেট রাখা হয়—সহজ, কিন্তু ডেটা হারাতে পারে।
ভার্সনিং (উদাহরণ: ভেক্টর ভেরিয়েন্ট): কোন নোড কোন আপডেট দেখেছে তা ট্র্যাক করে, সম্মিলিতভাবে মিশ্রণ বা কনফ্লিক্ট সারফেস করে।
আপনি কোন কৌশল নেবেন তা নির্ভর করে—মধ্যবর্তী আপডেট হারানো গ্রহণযোগ্য কি না।
How do I choose between key-value, document, wide-column, and graph databases?
একটি দ্রুত গাইড:
কি-ভ্যালু: আইডি দিয়ে দ্রুত লুকআপ—সেশন, ক্যাশ, ফিচার ফ্ল্যাগের জন্য উপযুক্ত।
ডকুমেন্ট: নমনীয় JSON-সদৃশ রেকর্ড—প্রোফাইল, ক্যাটালগ, কন্টেন্টের জন্য ভালো।
ওয়াইড-কলাম: বিশাল লেখা ধারা—টেলিমেট্রি, লোগ, টাইম-সিরিজে পারফেক্ট।
ওয়াইড-কলাম: বড় স্কেলে হেভি ইনজেশন; টেলিমেট্রি, লগ, টাইম-সিরিজ।
গ্রাফ: গভীর সম্পর্ক কুয়েরি; সোশ্যাল গ্রাফ, রুটিং, ফ্রড অ্যানালাইসিস।\n\n## ডেটা মডেলিং পরিবর্তন: কম জয়েন, আরও ইরাদাভিত্তিক ডিজাইন\n\nরিলেশনাল ডাটাবেস নর্মালাইজেশন উৎসাহিত করে: ডেটা বহু টেবিলে ভাগ করে কুয়েরি সময়ে জয়েন করে পুনর্গঠন করা হয়। অনেক NoSQL সিস্টেম আপনাকে সবচেয়ে গুরুত্বপূর্ণ এক্সেস প্যাটার্নগুলোর চারপাশে ডিজাইন করতে বলে—কখনও কখনও ডুপ্লিকেশন খরচ করে—যাতে নোড জুড়ে ল্যাটেন্সি পূর্বানুমানযোগ্য থাকে।\n\n### কেন ডেনর্মালাইজেশন এত সাধারণ\n\nবিতরণকৃত ডাটাবেসে, একটি জয়েনের জন্য বহু পার্টিশন বা মেশিন থেকে ডেটা টানতে হয়। এতে নেটওয়ার্ক হপ, সমন্বয়, এবং অনিশ্চিত ল্যাটেন্সি বাড়ে। ডেনর্মালাইজেশন (সম্পর্কিত ডেটা এক месте সংরক্ষণ) রাউন্ড-ট্রিপ কমায় এবং প্রায়ই রিডকে লোকাল রাখে।\n\nপ্রায়োগিক পরিণতি: আপনি একই গ্রাহকের নাম orders রেকর্ডে রাখতে পারেন যদিও তা customers-এও আছে—কারণ “শেষ 20 অর্ডার দেখাও” একটি মূল কুয়েরি।\n\n### কুয়েরি সীমাবদ্ধতা: কম জয়েন, অ্যাপে বেশি মডেলিং\n\nঅনেক NoSQL ডাটাবেস সীমিত জয়েন (বা কোনো) সাপোর্ট করে, তাই অ্যাপ্লিকেশন আরও দায়িত্ব নেয়:\n\n- কী দিয়ে একটি ডকুমেন্ট/রো ফেচ করে সরাসরি রেন্ডার করা\n- দুই dataset আলাদা পড়ে কোডে মার্জ করা\n- খরচবহুল স্ক্যান এড়াতে প্রিকম্পিউটেড "ভিউ" ডেটা রক্ষণ করা (কাউন্ট, সারাংশ)\n\nএই কারণে NoSQL মডেলিং প্রায়ই শুরু হয়: “আমাদের কোন স্ক্রিনগুলো লোড করতে হবে?” এবং “কোন টপ কুয়েরিগুলিকে দ্রুত রাখতে হবে?” দিয়ে।\n\n### সেকেন্ডারি ইনডেক্স—এবং তাদের লুকানো খরচ\n\nসেকেন্ডারি ইনডেক্স নতুন কুয়েরি সক্ষম করতে পারে ("ইমেইল দ্বারা ইউজার খুজুন"), কিন্তু এগুলো ফ্রি নয়। বিতরণকৃত সিস্টেমে, প্রতিটি লেখার সাথে একাধিক ইনডেক্স স্ট্রাকচার আপডেট হতে পারে, যার ফলে:\n\n- রাইট অ্যাম্প্লিফিকেশন: একটি লজিকাল রাইট বহু ফিজিকাল রাইটে রূপান্তরিত হয়\n- অতিরিক্ত স্টোরেজ: ইনডেক্স এন্ট্রি ডেটার আকারের কাছাকাছি হতে পারে\n- অপারেশনাল জটিলতা: ইনডেক্স ল্যাগ করতে পারে বা টিউনিং দরকার পড়ে\n\n### কর্মদক্ষতা বাড়াতে মডেলিং পছন্দের উদাহরণ\n\n- এম্বেড ওভার রেফারেন্স: একটি অর্ডারের ভিতরে অর্ডার আইটেম এম্বেড করুন যাতে অর্ডার এক অনুরোধে পড়া যায়\n- টাইম-সিরিজ ডেটা বাকেট করা: প্রতিদিন ডিভাইস অনুযায়ী ইভেন্ট রাখুন যাতে অনবরত বড় পার্টিশন এড়ানো যায়\n- রিড মডেল ম্যাটেরিয়ালাইজ করা: একটি “user_profile_summary” রেকর্ড বজায় রাখুন যাতে প্রোফাইল পেজ সার্ভ করতে পোষ্ট, লাইক, ফলো স্ক্যান না করতে হয়\n\n## টিমগুলো যে সুবিধা ও ট্রেডঅফ মেনে নিলো\n\nNoSQL গৃহীত হয়েছিল কারণ এটি সবক্ষেত্রে "উত্তম" ছিল—বলেই নয়। বরং টিমগুলো রিলেশনাল ডাটাবেসের কিছু সুবিধা ছেড়ে দিয়েই ওয়েব-স্কেল চাপে দ্রুততা, স্কেল, এবং নমনীয়তা পেতে চাইল।\n\n### টিমগুলো যে লাভ পেয়েছিল\n\nডিজাইনে স্কেল-আউট। অনেক NoSQL সিস্টেম কোষ্ঠকাঠিন্য ছাড়াই মেশিন যোগ করে স্কেল করা সহজ করে তুলেছিল। শার্ডিং ও রিপ্লিকেশন কোর ক্ষমতা হয়ে উঠল।\n\nনমনীয় স্কিমা। ডকুমেন্ট ও কি-ভ্যালু সিস্টেম ফিল্ড পরিবর্তনকে কড়া টেবিল সংজ্ঞার মধ্য দিয়ে না করে দ্রুত পরিবর্তন সম্ভব করল, বিশেষত যেখানে রিকোয়ারমেন্ট সপ্তাহে পরিবর্তিত হত।\n\nউচ্চ উপলব্ধি প্যাটার্ন। নোড ও অঞ্চলে রিপ্লিকেশন হার্ডওয়্যার ব্যর্থতা বা রখতার সময় সার্ভিস চালু রাখতে সহায়তা করে।\n\n### টিমগুলো যে মূল্য পরিশোধ করেছিল\n\nডেটা ডুপ্লিকেশন ও ডেনর্মালাইজেশন। জয়েন এড়াতে প্রায়শই ডেটা অনুলিপি করা লাগে—রিড পারফরম্যান্স বাড়ে, কিন্তু স্টোরেজ বাড়ে এবং "সবার জায়গায় আপডেট করা" জটিলতা আসে।\n\nকনসিস্টেন্সি বিস্ময়। ইভেন্টুয়াল কনসিস্টেন্সি গ্রহণযোগ্য হতে পারে—কিন্তু কখন তা নয়। ইউজার stale ডেটা বা বিভ্রান্তি দেখতে পায় যদি অ্যাপ conflict-র মোকাবিলা না করে।\n\nকঠিন অ্যানালিটিক্স (কখনো কখনো)। কিছু NoSQL স্টোর অপাৰেশনাল রিড/রাইটে চমৎকার, কিন্তু অ্যাড-হক কুয়েরি, রিপোর্টিং, অথবা জটিল অ্যাগ্রিগেশনে SQL-প্রধান সিস্টেমের মতো সুবিধা নাও দিতে পারে।\n\n### অপারেশন ও টুলিং কেন গুরুত্বপূর্ণ ছিল\n\nপ্রাথমিক NoSQL গৃহীত হলে প্রচুর ক্লিয়ার কার্যভার ইঞ্জিনিয়ারিং ডিসিপ্লিনের দিকে সরে গিয়েছিল: রেপ্লিকেশন মনিটরিং, পার্টিশন ম্যানেজমেন্ট, কম্প্যাকশন চালানো, ব্যাকআপ/রিস্টোর পরিকল্পনা, এবং ফেইলিউর সিনারিও লোড-টেস্টিং। অপারেশনে প্রভূত সক্ষমতা থাকা টিমগুলি বেশি উপকৃত হয়।\n\n### ট্রেডঅফ মূল্যায়ন কিভাবে করবেন\n\nওয়ার্কলোড বাস্তবতায় ভিত্তি করে বেছে নিন: প্রত্যাশিত ল্যাটেন্সি, পিক থ্রুপুট, প্রধান কুয়েরি প্যাটার্ন, stale রিড সহনশীলতা, এবং রিকভারি চাহিদা (RPO/RTO)। সঠিক NoSQL পছন্দ সাধারণত সেইটি যা আপনার অ্যাপ কিভাবে ব্যর্থ হয়, স্কেল করে, এবং কিভাবে কুয়েরি হবে তার সাথে মেলে—না যে কোনটি সবচেয়ে আকর্ষণীয় ফিচার তালিকায় আছে।\n\n## আজ যদি NoSQL ঠিক কিনা কিভাবে সিদ্ধান্ত নেওয়া যায়\n\nNoSQL বেছে নেওয়া ডেটাবেস ব্র্যান্ড বা হাইপ থেকে শুরু করা উচিত নয়—এটি আপনার অ্যাপ কী করবে, কিভাবে তা বৃদ্ধি পাবে, এবং ব্যবহারকারীর জন্য “সঠিক” কী মানে এটা থেকে শুরু করা উচিত।\n\n### রিকোয়ারমেন্ট ও এক্সেস প্যাটার্ন দিয়ে শুরু করুন\n\nস্টোর নির্বাচন করার আগে লিখে নিন:\n\n- আপনার টপ 5–10 কুয়েরি/অপারেশনগুলো কী (রিড, রাইট, সার্চ, অগ্রেগেশন)\n- ১২–২৪ মাসে প্রত্যাশিত ট্রাফিক এখন বনাম ভবিষ্যৎ\n- stale ডেটার সহনশীলতা (মিলিসেকেন্ড, সেকেন্ড, কখনই নয়)\n- আপনার ফেইলিউর প্রত্যাশা (নোড বা রিজিওন ডাউন হলে কি হবে?)\n\nযদি আপনি স্পষ্টভাবে এক্সেস প্যাটার্ন বর্ণনা করতে না পারেন, কোনো সিদ্ধান্তই অনুমানভিত্তিক হবে—বিশেষত NoSQL-এ, যেখানে মডেলিং প্রায়শই আপনার পড়া/লেখার চারপাশে গঠিত।\n\n### একটি সাধারণ সিদ্ধান্তচেকলিস্ট (SQL বনাম NoSQL বনাম হাইব্রিড)\n\n- SQL বেছে নিন যদি আপনি ডিফল্টরূপে শক্ত কনসিস্টেন্সি চান, জটিল অ্যাড-হক কুয়েরি প্রয়োজন, এবং অনেক সম্পর্ক আছে যা জয়েন থেকে উপকৃত হয়।\n- NoSQL বেছে নিন যদি আপনি নির্দিষ্ট অ্যাক্সেস প্যাটার্নের জন্য সহজ হরিজন্টাল স্কেল চান, সেই প্যাটার্ন অনুযায়ী ডেটা ডিজাইন করতে পারেন, এবং কিছু ওয়ার্কফ্লোতে শিথিল কনসিস্টেন্সি গ্রহণ করতে পারেন।\n- হাইব্রিড বেছে নিন যদি অ্যাপের ভিন্ন অংশের চাহিদা আলাদা হয় (বাস্তবে অনেক প্রোডাক্টেই দেখা যায়)।\n\nপ্র্যাকটিক্যাল সিগন্যাল: যদি আপনার “কোর ট্রুথ” (অর্ডার, পেমেন্ট, ইনভেন্টরি) সব সময় সঠিক হতে হবে, তা SQL বা অন্য শক্ত-কনসিস্টেন্ট স্টোরে রেখে দিন। যদি আপনি হাই-ভলিউম কন্টেন্ট, সেশন, ক্যাশ, অ্যাক্টিভিটি ফিড, বা নমনীয় ব্যবহারকারী-উত্পন্ন ডেটা সার্ভ করেন, NoSQL ভালো ফিট হতে পারে।\n\n### পলিগ্লট পেরসিস্টেন্স (উদ্দেশ্যপূর্ণভাবে) বিবেচনা করুন\n\nঅনেক টিম একাধিক স্টোর ব্যবহার করে সফল হয়: উদাহরণস্বরূপ, লেনদেনের জন্য SQL, প্রোফাইল/কনটেন্টের জন্য ডকুমেন্ট ডাটাবেস, এবং সেশনগুলির জন্য কি-ভ্যালু স্টোর। লক্ষ্য জটিলতার জন্য নয়—প্রতিটি ওয়ার্কলোডকে উপযুক্ত টুলে রাখাই উদ্দেশ্য।\n\nএখানেই ডেভেলপার ওয়ার্কফ্লো গুরুত্বপূর্ণ। যদি আপনি আর্কিটেকচারে এগোচ্ছেন (SQL বনাম NoSQL বনাম হাইব্রিড), দ্রুত প্রোটোটাইপ ঘুরিয়ে দেখা—API, ডেটা মডেল, এবং UI—ঝুঁকি কমাতে পারে। Koder.ai-এর মত প্ল্যাটফর্মগুলি চ্যাট থেকে ফুল-স্ট্যাক অ্যাপ জেনারেট করে এটা সহজ করে দেয়, সাধারণত একটি React ফ্রন্টএন্ড এবং Go + PostgreSQL ব্যাকএন্ড সহ, তারপর সোর্স কোড এক্সপোর্ট করার সুযোগ দেয়। পরবর্তীতে নির্দিষ্ট ওয়ার্কলোডের জন্য NoSQL স্টোর যোগ করলেও, একটি শক্ত SQL “সিস্টেম অব রেকর্ড” এবং দ্রুত প্রোটোটাইপিং, স্ন্যাপশট, ও রোলব্যাক থাকা এক্সপেরিমেন্টগুলোকে নিরাপদ ও দ্রুত করে।\n\n### মতামতের ওপর নয়—টেস্টিং দিয়ে যাচাই করুন\n\nআপনি যা বেছে নেন, তা প্রমাণ করুন:\n\n- বাস্তবিক কুয়েরি ও ডেটা সাইজ দিয়ে লোড টেস্ট চালান।\n- ফেইলিউর ড্রিল করুন (নোড কিল করুন, নেটওয়ার্ক সমস্যা সিমুলেট করুন, ব্যাকআপ/রিস্টোর টেস্ট করুন)।\n- একটি স্কিমা ইভোলিউশন প্ল্যান তৈরি করুন: কিভাবে ফিল্ড যোগ করবেন, রেকর্ড মাইগ্রেট করবেন, এবং রোলআউট চলাকালীন পুরানো/নতুন ভার্সনকে কাজ করাবেন।\n\nআপনি যদি এই সিনারিওগুলো টেস্ট করতে না পারেন, আপনার ডাটাবেস সিদ্ধান্ত তাত্ত্বিকই থাকবে—এবং প্রোডাকশনই আপনার বদলে পরীক্ষা করে নিবে।\n\n