০৯ আগ, ২০২৫·8 মিনিট
কিভাবে ফ্রেমওয়ার্ক অ্যাবস্ট্র্যাকশন স্কেলে বাড়লে লিক করে
বিষয় বুঝুন: কেন উচ্চ-স্তরের ফ্রেমওয়ার্কগুলো স্কেলে ভেঙে পড়ে, সাধারণ লিক প্যাটার্নগুলো কী, কোন লক্ষণগুলো সতর্ক করে, এবং ডিজাইন ও অপস প্র্যাকটিসে বাস্তবসম্মত সমাধান।
বিষয় বুঝুন: কেন উচ্চ-স্তরের ফ্রেমওয়ার্কগুলো স্কেলে ভেঙে পড়ে, সাধারণ লিক প্যাটার্নগুলো কী, কোন লক্ষণগুলো সতর্ক করে, এবং ডিজাইন ও অপস প্র্যাকটিসে বাস্তবসম্মত সমাধান।
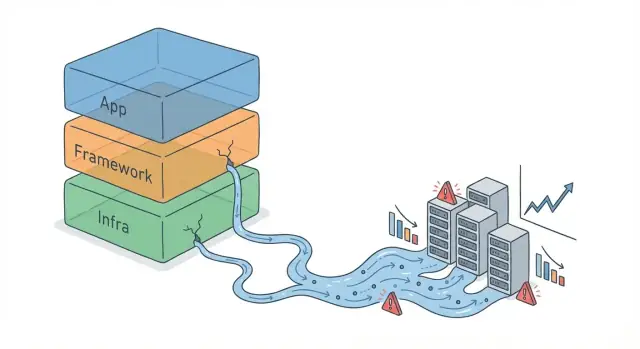
একটি অ্যাবস্ট্র্যাকশন হলো সরলীকরণ স্তর: একটি ফ্রেমওয়ার্ক API, একটি ORM, একটি মেসেজ কিউ ক্লায়েন্ট, এমনকি একটি “এক-লাইন” ক্যাশিং হেলপার। এটি আপনাকে উচ্চ-স্তরের ধারণায় ভাবতে দেয় (“এই অবজেক্ট সংরক্ষণ কর”, “এই ইভেন্ট পাঠাও”) בלי নীচের-স্তরের মেকানিক্স প্রতিনিয়ত সামলাতে।
একটি অ্যাবস্ট্র্যাকশন লিক ঘটে যখন ওই লুকানো বিবরণগুলো বাস্তবে প্রভাব ফেলা শুরু করে—ফলে আপনাকে বাধ্য করা হয় সেইসব বিষয়ে বুঝতে ও পরিচালনা করতে যা অ্যাবস্ট্র্যাকশন ঢেকে রেখেছিল। কোড এখনও “চালু” থাকে, কিন্তু সরল মডেলটা আর বাস্তব আচরণ পূর্বাভাস দিতে পারে না।
শুরুতে বৃদ্ধিই নমনীয়। কম ট্রাফিক ও ছোট ডেটাসেটে অকার্যকরতা গুলো ফাঁকা CPU, ওয়ার্ম ক্যাশ ও দ্রুত কুয়েরির আড়ালে লুকিয়ে থাকে। লেটেন্সি স্পাইক বিরল, রিট্রাই জমে না, এবং হালকা অপচয়কারী লগ লাইন তেমন সমস্যা করে না।
ভলিউম বাড়লে একই শর্টকাটগুলো তীব্রতর হয়ে ওঠে:
লিকিং অ্যাবস্ট্র্যাকশন সাধারণত তিনটি ক্ষেত্রে দেখা দেয়:
পরবর্তী অংশে আমরা ফোকাস করব প্র্যাকটিক্যাল সিগন্যালগুলোর ওপর—কোনগুলো প্রকাশ করে যে একটি অ্যাবস্ট্র্যাকশন লিক করছে, কীভাবে মূল কারণ ডায়াগনোজ করতে হবে (শুধু লক্ষণ নয়), এবং মিটিগেশন অপশনগুলো—কনফিগারেশন টুইক থেকে শুরু করে সেই সময়ে “নিচে নামা” (drop down a level) পর্যন্ত যেখানে অ্যাবস্ট্র্যাকশন আর আপনার স্কেলের সাথে মেলে না।
অনেক সফটওয়্যার একই চক্র অনুসরণ করে: একটি প্রোটোটাইপ আইডিয়া প্রমাণ করে, একটি প্রোডাক্ট শিপ হয়, তারপর ব্যবহার মূল আর্কিটেকচারের চেয়েও দ্রুত বাড়ে। শুরুতে ফ্রেমওয়ার্কগুলো জাদুময় লাগে কারণ তাদের ডিফল্ট সেটিংস আপনাকে দ্রুত এগোতে দেয়—রাউটিং, ডাটাবেস অ্যাক্সেস, লগিং, রিট্রাই ও ব্যাকগ্রাউন্ড জব “বিনা খরচে”।
স্কেলে আপনি ওই সুবিধা চাইবেন—কিন্তু ডিফল্ট ও সুবিধাজনক API গুলো অভ্যাসে ধারণা হয়ে যায়।
ফ্রেমওয়ার্ক ডিফল্টগুলো সাধারণত নিচের অনুমানগুলো করে:
শুরুতে এই অনুমানগুলো ঠিক থাকে, তাই অ্যাবস্ট্র্যাকশনটি পরিষ্কার মনে হয়। কিন্তু স্কেল বদলে দেয় “নরমাল” কী। 10,000 রোতে ঠিক থাকা একটি কুয়েরি 100 মিলিয়ন রোতে ধীর হয়ে উঠতে পারে। একটি সিংক্রোনাস হ্যান্ডলার, যা সহজ মনে হচ্ছিল, ট্রাফিক স্পাইক হলে টাইমআউট হতে পারে। একটা রিট্রাই পলিসি যেটা বিরল ব্যর্থতা মসৃণ করেছিল, হাজার হাজার ক্লায়েন্ট একসাথে রিট্রাই করলে আউটেজ বাড়াতে পারে।
স্কেল মানে শুধু “আরও ইউজার” নয়। এটা বেশি ডেটা ভলিউম, বুর্সি ট্রাফিক, এবং একই সময়ে আরও কনকারেন্ট কাজ ঘটা। এগুলো যে অংশগুলোকে চাপ দেয় যেগুলো অ্যাবস্ট্র্যাকশন লুকিয়ে রাখে: কানেকশন পুল, থ্রেড শিডিউলিং, কিউ ডেপ্থ, মেমরি প্রেসার, I/O সীমা, ও ডিপেন্ডেন্সি থেকে আসা রেট লিমিট।
ফ্রেমওয়ার্কগুলো সাধারণত সেফ, জেনেরিক সেটিংস (পুল সাইজ, টাইমআউট, ব্যাচিং আচরণ) বেছে নেয়। লোডে, ঐ সেটিংগুলো কনটেনশন, লং-টেইল লেটেন্সি ও ক্যাসকেডিং ফেলিওর-এ রূপ নেয়—সেই সমস্যা যা তখনো দৃশ্যমান ছিল না যখন সবকিছু মার্জিনের মধ্যে মেলে।
স্টেজিং পরিবেশগুলো বিরলই প্রোডাকশনকে অনুকরণ করে: ছোট ডেটাসেট, কম সার্ভিস, ভিন্ন ক্যাশিং আচরণ, এবং কম “মেসি” ইউজার অ্যাকটিভিটি। প্রোডাকশনে আপনার সামনে বাস্তব নেটওয়ার্ক ভ্যারিয়েবিলিটি, নইজি নেবার্স, রোলিং ডিপ্লয় এবং পার্শিয়াল ফেইল আছে। এজন্য টেস্টে অবিকল থাকা অ্যাবস্ট্র্যাকশনগুলো প্রোডাকশনে লিক করে।
যখন একটি ফ্রেমওয়ার্ক অ্যাবস্ট্র্যাকশন লিক করে, লক্ষণগুলো পরিষ্কার এরর মেসেজের মতো আসে না। বরং আপনি প্যাটার্ন দেখবেন: কম ট্রাফিকে ঠিক থাকা আচরণ উচ্চ ভলিউামে অনিশ্চিত বা ব্যয়বহুল হয়ে ওঠে।
একটি লিকিং অ্যাবস্ট্র্যাকশন প্রায়ই ব্যবহারকারীর কাছে দৃশ্যমান লেটেন্সির মাধ্যমে ঘোষণা করে:
এসব ক্লাসিক চিহ্ন যে অ্যাবস্ট্র্যাকশন একটি বটলনেক লুকিয়ে রেখেছে যা আপনি নীচে নামেই (কুয়েরি/কানেকশন/আইও পর্যবেক্ষণ করে) মুক্ত করতে পারবেন।
কিছু লিক প্রথমে ইনভয়েসে দেখে না ড্যাশবোর্ডে:
ইনফ্রা বাড়িয়েও পারফরম্যান্স প্রপোরশনালভাবে ফিরে না এলে, প্রায়শই সেটা কাঁচা ক্যাপাসিটি নয়—এটি আপনার অজান্তে দিতে হচ্ছে এমন ওভারহেড।
লিকগুলো রিট্রাই ও ডিপেন্ডেন্সি চেইনের সঙ্গে ইন্টারঅ্যাক্ট করলে রিলায়াবিলিটি সমস্যায় পরিণত হয়:
বড়জোর কেনাকাটা করার আগে স্যানিটি-চেক হিসেবে:
যদি লক্ষণগুলো একটি নির্দিষ্ট ডিপেন্ডেন্সিতে কেন্দ্রীভূত হয় এবং “আরও সার্ভার” দিয়ে predictableভাবে সাড়া না দেয়, তাহলে এটা শক্ত সংকেত যে আপনাকে অ্যাবস্ট্র্যাকশনের নিচে নামতে হবে।
ORM খুবই সুবিধাজনক বটলনেক রিমুভ করতে, কিন্তু শেষ কথাটা হলো: প্রতিটি অবজেক্ট শেষ পর্যন্ত একটি SQL কুয়েরি হয়ে ওঠে। ছোট স্কেলে এই ট্রেড-অফ অদৃশ্য মনে হয়। বড় ভলিউমে ডাটাবেস প্রায়শই প্রথম জায়গা যেখানে “পরিষ্কার” অ্যাবস্ট্র্যাকশন সুদের দাম চায়।
N+1 ঘটে যখন আপনি প্যারেন্ট রেকর্ডগুলোর একটি লিস্ট লোড করেন (1 কুয়েরি) এবং তারপর একটি লুপের ভিতর প্রতিটি প্যারেন্টের সম্পর্কিত রেকর্ড লোড করেন (আর N কুয়েরি)। লোকাল টেস্টে ঠিক থাকে—হয়তো N ২০। প্রোডাকশনে N হয়ে যায় ২,০০০, এবং আপনার অ্যাপ এক অনুরোধকে হাজার হাজার রাউন্ড-ট্রিপে বদলে দেয়।
কষ্টকর বিষয় হল কিছুই অবিলম্বে “ভঙ্গ” করে না; লেটেন্সি ক্রিপ করে, কানেকশন পুল ভর্তি হয়, এবং রিট্রাই লোড বাড়ায়।
অ্যাবস্ট্র্যাকশনগুলো প্রায়শই ডিফল্টে সম্পূর্ণ অবজেক্ট ফেচ করতে উৎসাহ দেয়, এমনকি যখন আপনাকে কেবল দুইটা ফিল্ডই লাগে। এটি I/O, মেমরি ও নেটওয়ার্ক বাড়ায়।
একই সঙ্গে, ORM-জেনারেটেড কুয়েরিগুলো বানায় যা আপনার অনুমানকৃত ইনডেক্সগুলো ব্যবহার করে না (বা ইনডেক্সই ছিল না)। একটি একক মিসিং ইনডেক্স একটি সিলেক্টিভ লুকআপকে টেবিল-স্ক্যানে পরিণত করতে পারে।
জয়েন একটি অন্য লুকানো খরচ: “শুধু রিলেশন ইনক্লুড কর” বললে তা বড় ইন্টারমিডিয়েট রেজাল্টসহ একাধিক জয়েন কুয়েরি করতে পারে।
লোডে ডাটাবেস কানেকশন সরবরাহ সীমিত। যদি প্রতিটি রিকুয়েস্ট বহু কুয়েরিতে ফ্যান-আউট করে, পুল দ্রুত সীমায় পৌঁছায় এবং আপনার অ্যাপ কিউ হতে শুরু করে।
কখনও কখনও দুর্ঘটনাজনিত দীর্ঘ ট্রানজাকশন কনটেনশন বাড়ায়—লক বেশি সময় ধরে থাকে এবং কনকারেন্সি ধসে পড়ে।
EXPLAIN দিয়ে ভ্যালিডেট করুন, এবং ইনডেক্সকে অ্যাপ ডিজাইনের অংশ হিসেবে গণ্য করুন—কেবল DBA’র পরে-চিন্তা নয়।কনকারেন্সি এমন জায়গা যেখানে ফ্রেমওয়ার্কগুলো ডেভেলপমেন্টে “সেফ” মনে হয় এবং লোডে জোরে ফেল করে। একটি ফ্রেমওয়ার্কের ডিফল্ট মডেল প্রায়শই প্রকৃত সীমা লুকিয়ে রাখে: আপনি শুধু রিকোয়েস্ট সার্ভ করছেন না—আপনি CPU, থ্রেড, সকেট ও ডাউনস্ট্রিম ক্যাপাসিটির জন্য প্রতিযোগিতা করছেন।
থ্রেড-প্রতি-রিকোয়েস্ট (ক্লাসিক ওয়েব স্ট্যাকে সাধারণ) সোজা: প্রতিটি রিকোয়েস্টকে একটি ওয়ার্কার থ্রেড দেওয়া হয়। যখন স্লো I/O (ডিবি, API কল) আসে তখন থ্রেড জমা হয়। পুল এক্সস্ট হয়, নতুন অনুরোধ কিউ হয়, লেটেন্সি স্পাইক করে, তারপর টাইমআউট—যখন সার্ভার আসলে শুধু অপেক্ষায় থাকে।
অ্যাসিঙ্ক/ইভেন্ট-লুপ মডেল অনেক ইন-ফ্লাইট রিকোয়েস্ট কম থ্রেড দিয়ে হ্যান্ডেল করে, তাই উচ্চ কনকারেন্সিতে ভালো। তারা ভিন্নভাবে ভেঙে: একটি ব্লকিং কল (সিংক লাইব্রেরি, ধীর JSON পার্সিং, ভারী লগিং) ইভেন্ট লুপকে আটকে দিতে পারে, “একটি ধীর রিকোয়েস্ট” কে “সবকিছু ধীর” এ পরিণত করে। অ্যাসিঙ্ক এছাড়াও সহজ করে অতিরিক্ত কনকারেন্সি তৈরি করা, ফলে ডিপেন্ডেন্সিকে থ্রটল করা কঠিন হয়।
ব্যাকপ্রেশার সিস্টেমটিকে বলে দেয় “আমি এখন আরো গ্রহণ করতে পারি না”—বিনা ব্যাকপ্রেশারের, একটি স্লো ডিপেন্ডেন্সি কেবল রেসপন্স ধীর করে না, এটি ইন-ফ্লাইট কাজ, মেমরি ব্যবহার এবং কিউ লেন বাড়ায়। অতিরিক্ত কাজ ডিপেন্ডেন্সিকে আরও ধীর করে, একটি প্রতিক্রিয়া লুপ গঠন হয়।
টাইমআউটগুলো উচিত স্পষ্ট ও স্তরভিত্তিক: ক্লায়েন্ট, সার্ভিস, এবং ডিপেন্ডেন্সি। টাইমআউট যদি খুব লম্বা হয়, কিউ গড়ে ওঠে এবং পুনরুদ্ধার ধীর হয়। রিট্রাই যদি স্বয়ংক্রিয় ও আগ্রাসিভ হয়, আপনি একটি রিট্রাই স্টর্ম ট্রিগার করতে পারেন: ডিপেন্ডেন্সি ধীর হয়, কল টাইমআউট হয়, কলাররা রিট্রাই করে, লোড বৃদ্ধি পায়, এবং ডিপেন্ডেন্সি ধস হয়।
ফ্রেমওয়ার্কগুলো নেটওয়ার্কিংকে “শুধু একটি এন্ডপয়েন্ট কল করা” মনে করায়। লোডে, অ্যাবস্ট্র্যাকশনটি প্রায়শই মধ্য়ের মিহি কাজ—মিডলওয়্যার স্ট্যাক, সিরিয়ালাইজেশন ও পে-লোড হ্যান্ডলিং—দিয়ে লিক করে।
প্রতিটি স্তর—API গেটওয়ে, অথ মিডলওয়্যার, রেট লিমিট, রিকোয়েস্ট ভ্যালিডেশন, অবজার্ভেবিলিটি হুক, রিট্রাই—একটু সময় যোগ করে। ডেভে এক মিলিসেকেন্ড কম প্রশ্নহীন; স্কেলে কয়েকটা মধ্য়-হপ ২০ ms-কে ৬০–১০০ ms-এ পরিণত করতে পারে, বিশেষত যখন কিউ গঠন হয়।
লেটেন্সি শুধু যোগ হয় না—এটি বাড়ায়। ছোট দেরি বেশি ইন-ফ্লাইট রিকোয়েস্ট তৈরি করে, যা কনটেনশন বাড়ায়, এবং দেরি আরও বাড়ে।
JSON সুবিধাজনক, কিন্তু বড় পে-লোড এনকোড/ডিকোড CPU ডোমিনেট করতে পারে। লিকটি “নেটওয়ার্ক” ধীরতা হিসেবে দেখায় যদিও এটা অ্যাপ CPU-টাইম, এবং আলাদা বাফার আলোকচিত্রে অতিরিক্ত মেমরি চাপ তোলে।
বড় পে-লোড সবকিছু ধীর করে:
হেডার অনুপস্থিতভাবে অনুরোধকে ফুলে তোলে (কুকি, অথ টোকেন, ট্রেসিং হেডার)। ওই ফুলে যাওয়া প্রতিটি কল ও প্রতিটি হপে গুণিত হয়।
কমপ্রেশনেও ট্রেড-অফ আছে: ব্যান্ডউইথ বাঁচায়, কিন্তু CPU লাগে এবং লেটেন্সি বাড়ায়—বিশেষত ছোট পে-লোডে বা বহু প্রক্সির মাধ্যমে একাধিকবার কমপ্রেস করলে।
স্ট্রিমিং বনাম বাফারিং শেষ পর্যন্ত গুরুত্বপূর্ণ। অনেক ফ্রেমওয়ার্ক ডিফল্টে পুরো রিকোয়েস্ট/রেসপন্স বডি বাফার করে (রিট্রাই, লগিং বা কনটেন্ট-লেন্থ গণনার সুবিধার জন্য)। এটি সুবিধাজনক, কিন্তু উচ্চ ভলিউমে মেমরি ব্যবহার বাড়ায় এবং হেড-অফ-লাইনে ব্লকিং তৈরি করে। স্ট্রিমিং মেমরি পূর্বানুমানযোগ্য রাখে এবং টাইম-টু-ফার্স্ট-বাইট কমায়, কিন্তু এর জন্য ত্রুটির হ্যান্ডলিং আরও সাবধানে করতে হয়।
পে-লোড সাইজ ও মিডলওয়্যার ডেপ্থকে বাজেট হিসেবে গণ্য করুন:
যখন স্কেল নেটওয়ার্ক ওভারহেড প্রকাশ করে, সমাধান প্রায়ই “নেটওয়ার্ক অপ্টিমাইজ করুন” নয়—বরং “প্রতিটি অনুরোধে লুকানো কাজ বন্ধ করুন”।
ক্যাশিংকে প্রায়ই একটি সহজ সুইচ মনে করা হয়: Redis (বা CDN) যোগ করুন, লেটেন্সি কমে যাবে—অনেক দল এগুলোর পেছনে আর যায় না। বাস্তব লোডে, ক্যাশিং এমন একটি অ্যাবস্ট্র্যাকশন যা মারাত্মকভাবে লিক করতে পারে—কারণ এটি কাজ হচ্ছে কোথায়, কখন, এবং কিভাবে ব্যর্থতা ছড়ায় তা বদলে দেয়।
একটি ক্যাশ যোগ করলে অতিরিক্ত নেটওয়ার্ক হপ, সিরিয়ালাইজেশন এবং অপারেশনাল জটিলতা আসে। এছাড়া এটা দ্বিতীয় “সোর্স অফ ট্রুথ” তৈরি করে যা স্ট্যাল, আংশিক-ফিল বা অনুপলব্ধ হতে পারে। সমস্যা হলে সিস্টেম শুধু ধীর হয় না—এটি আলাদা আচরণও করতে পারে (পুরোনো ডেটা সার্ভ করা, রিট্রাই বাড়ানো, অথবা ডাটাবেস ওভারলোড)।
ক্যাশ স্ট্যাম্পিড ঘটে যখন অনেক অনুরোধ একসাথে ক্যাশ মিস করে (সাধারণত মেয়াদ সমাপ্তির পরে) এবং সবাই একই মূল মান পুনর্নির্মাণ করতে দৌড়ায়। স্কেলে এটি একটি ছোট মিস রেটকে ডাটাবেস স্পাইকে পরিণত করতে পারে।
খারাপ কী ডিজাইন আরেকটি নীরব সমস্যা। কী যদি খুব ব্যাপক হয় (উদাহরণ: user:feed প্যারামিটার ছাড়া), আপনি ভুল ডেটা সার্ভ করবেন। যদি কী খুব স্পেসিফিক হয় (টাইমস্ট্যাম্প, র্যান্ডম আইডি, অর্ডারড না করা কুয়েরি প্যারাম), হিট রেট প্রায় শূন্য এবং আপনি শূন্যে খরচের মূল্য পরিশোধ করেন।
ইনভ্যালিডেশন ক্লাসিক ট্র্যাপ: ডাটাবেস আপডেট করা সহজ; সমস্ত সম্পর্কিত ক্যাশেড ভিউ রিফ্রেশ করা কঠিন। আংশিক ইনভ্যালিডেশন বিভ্রান্ত “আমার কাছে ঠিক আছে” বাগ ও inconsistent রিড সৃষ্টি করে।
বাস্তব ট্রাফিক সমানভাবে বিতরণ হয় না। একটি সেলিব্রিটি প্রোফাইল, জনপ্রিয় প্রোডাক্ট, বা শেয়ার করা কনফিগ এন্ডপয়েন্ট হট কী হয়ে উঠতে পারে—একক ক্যাশ এন্ট্রিতে ও তার ব্যাকিং স্টোরে লোড ঘন করে দেয়। গড় পারফরম্যান্স ঠিক থাকলেও টেইল লেটেন্সি ও নোড-স্তরের চাপ বিস্ফোরিত হতে পারে।
ফ্রেমওয়ার্কগুলো প্রায়ই মেমরিকে “ম্যানেজড” মনে করায়—যা প্রফুল্লকর; কিন্তু ট্রাফিক বাড়লে লেটেন্সি এমনভাবে স্পাইক করা শুরু করে যা CPU গ্রাফের সাথে মেলে না। অনেক ডিফল্ট ডেভেলপার কমফোর্টের জন্য টিউন করা থাকে, না যে এটি দীর্ঘ-গড়তি প্রসেসে টেকসই।
হাই-লেভেল ফ্রেমওয়ার্কগুলো প্রতি রিকোয়েস্টে শর্ট-লিভড অবজেক্ট আলোকায়: রিকোয়েস্ট/রেসপন্স র্যাপার, মিডলওয়্যার কনটেক্সট অবজেক্ট, JSON ট্রি, টেম্পোরারি স্ট্রিং ইত্যাদি। একেকটি ছোট—কিন্তু স্কেলে এগুলো ধারাবাহিক অ্যালোকেশন প্রেসার তৈরি করে যা runtime-কে আরও ঘন ঘন গার্বেজ কালেক্ট করতে বাধ্য করে।
GC পজেস ছোট কিন্তু বারবার লেটেন্সি স্পাইক হিসেবে দৃশ্যমান হতে পারে। হিপ বাড়লে পজগুলো প্রায়ই লম্বা হয়—প্রতিশোধ নয় যে আপনি লিক করেছেন, বরং runtime-কে মেমরি স্ক্যান ও কম্প্যাক্ট করতে বেশি সময় লাগে।
লোডে একটি সার্ভিস কিছু অবজেক্টকে ‘ওল্ড জেনারেশন’-এ প্রোমোট করতে পারে (বা অনুরূপ দীর্ঘ-জীবিত এলাকা) শুধু কারণ তারা কয়েকটি GC সাইকেলের মাধ্যমে বেঁচে গেছে—কিউ, বাফার, কানেকশন পুল বা ইন-ফ্লাইট রিকোয়েস্টের সময়। এটি হিপ ফুলিয়ে দিতে পারে যদিও অ্যাপ্লিকেশন “ঠিক” আছে।
ফ্র্যাগমেন্টেশন আরেকটি লুকানো খরচ: মেমরি ফ্রি থাকলেও প্রতিটি আকৃতির জন্য পুনরায় ব্যবহারযোগ্য না হলে প্রসেস OS-কে বেশি মেমরি চায়।
একটি সত্য লিক হচ্ছে অসীম বৃদ্ধি: মেমরি সময়ের সাথে বাড়ে, ফিরে আসে না, এবং অবশেষে OOM কিল বা অতিরিক্ত GC থ্র্যাশ সৃষ্টি করে।
উচ্চ-কিন্তু-স্থিতিশীল ব্যবহার ভিন্ন: ওয়ার্মআপের পরে মেমরি একটি প্ল্যাটফর্মে উঠেএবং প্রায় সমান থাকে।
প্রোফাইলিং (হিপ স্ন্যাপশট, অ্যালোকেশন ফ্লেম গ্রাফ) দিয়ে হট অ্যালোকেশন পাথ ও রিটেইন্ড অবজেক্ট চিহ্নিত করুন।
পুলিংতে সাবধানতা করুন: পুলিং অ্যালোকেশন কমাতে পারে, কিন্তু খারাপভাবে সাইজ করা পুল মেমরি পিন করে ফেলে এবং ফ্র্যাগমেন্টেশন বাড়ায়। প্রথমে অ্যালোকেশন কমান (স্ট্রিমিং বনাম বাফারিং, অপ্রয়োজনীয় অবজেক্ট ক্রিয়েশন এড়ান, প্রতি-রিকোয়েস্ট ক্যাশ সীমাবদ্ধ), তারপর মাপা ফলাফল না দেখলে পুলিং যোগ করুন।
অবজার্ভেবিলিটি টুলস প্রায়ই “বিনা খরচ” মনে হয় কারণ ফ্রেমওয়ার্ক আপনাকে সুবিধাজনক ডিফল্ট দেয়: রিকোয়েস্ট লগ, অটো-ইনস্ট্রুমেন্টেড মেট্রিক্স, এক-লাইন ট্রেসিং। বাস্তব ট্রাফিকে ঐ ডিফল্টগুলোই কখনও-কখনও ওয়ার্কলোডের অংশ হয়ে ওঠে যা আপনি পর্যবেক্ষণ করতে চান।
প্রতি-রিকোয়েস্ট লগিং ক্লাসিক উদাহরণ। প্রতি রিকোয়েস্ট একটা লাইন ক্ষুদ্র মনে হলেও—হাজার হাজার RPS এ CPU, স্ট্র্রিং ফরম্যাটিং, JSON এনকোডিং, ডিস্ক বা নেটওয়ার্ক লিখা ও ডাউনস্ট্রিম ইনজেকশন সবই মূল্য নেয়। লিকটি CPU/লেটেন্সি স্পাইক, লগ পাইপলাইন পিছিয়ে পড়া, এবং কখনো সিঙ্ক্রোনাস লগ ফ্লাশিং-এর কারণে রিকোয়েস্ট টাইমআউট হিসেবে প্রকাশ পায়।
মেট্রিক্স নীরবে সিস্টেমে অতিরিক্ত লোড সৃষ্টি করে। কাউন্টার ও হিস্টোগ্রাম ছোট টাইম সিরিজে সস্তা; কিন্তু ফ্রেমওয়ার্ক প্রায়ই user_id, email, path, অথবা order_id মতো ট্যাগ/লেবেল যোগ করতে উৎসাহ দেয়। এর ফলে কার্ডিনালিটি বিস্ফোরিত হয়: একাধিক ইউনিক সিরিজ তৈরি হয়। ফলাফল: ক্লায়েন্ট ও ব্যাকএন্ডে মেমরি ভর্তি, ড্যাশবোর্ড প্রশ্ন ধীর, স্যাম্পল ড্রপ এবং অপ্রত্যাশিত বিল।
ট্রেসিং ভিসিবিলিটি দেয় কিন্তু খরচও বাড়ায়—ট্রাফিক ও প্রতিটি রিকোয়েস্টের স্প্যান সংখ্যা বাড়ার সাথে সাথে স্টোরেজ ও কম্পিউট খরচও বাড়ে। যদি আপনি সবকিছু ডিফল্টে ট্রেস করেন, আপনি দুইবারই দিচ্ছেন: অ্যাপ ওভারহেড (স্প্যান তৈরি ও প্রসার করা) এবং ট্রেসিং ব্যাকএন্ড ইনজেকশন/ইন্ডেক্সিং/রিটেনশন খরচ।
স্যাম্পলিং হলো কন্ট্রোল ফেরত আনার উপায়—কিন্তু ভুল করলে বিরল ত্রুটি হারিয়ে যায় বা কম স্যাম্পল করলে খরচ অপরিবর্তিত থাকতে পারে। প্র্যাকটিক্যাল উপায়: এরর ও উচ্চ-লেটেন্সি রিকোয়েস্টগুলোর জন্য বেশি স্যাম্পলিং, স্বাস্থ্যকর দ্রুত পথের জন্য কম।
যদি আপনি কি সংগ্রহ করবেন তার একটি বেসলাইন চান, দেখুন /blog/observability-basics।
অবজার্ভেবিলিটিকে প্রোডাকশন ট্রাফিক হিসেবে ট্রিট করুন: বাজেট নির্ধারণ করুন (লগ ভলিউম, মেট্রিক সিরিজ কাউন্ট, ট্রেস ইনজেকশন), ট্যাগগুলোর কার্ডিনালিটি ঝুঁকি রিভিউ করুন, এবং ইন্সট্রুমেন্টেশন চালু রেখে লোড-টেস্ট করুন। লক্ষ্য “কম অবজার্ভেবিলিটি” নয়—বরং এমন পর্যবেক্ষণযোগ্যতা যা সিস্টেম চাপের সময়ও কাজ করে।
ফ্রেমওয়ার্কগুলো প্রায়ই অন্য সার্ভিস কল করা লোকাল ফাংশন কলের মতো অনুভব করায়: userService.getUser(id) দ্রুত রিটার্ন করে, এররগুলো “শুধু এক্সসেপশন”, এবং রিট্রাই অদেখা ক্ষতি মনে হয়। ছোট স্কেলে এই মায়া চলে যায়। বড় স্কেলে অ্যাবস্ট্র্যাকশন লিক করে—কারণ প্রতিটি “সহজ” কল লুকানো coupling বহন করে: লেটেন্সি, ক্যাপাসিটি সীমা, পার্শিয়াল ফেইল এবং ভার্শন মিসম্যাচ।
একটি রিমোট কল দুই টিমের রিলিজ সাইকেল, ডেটা মডেল, ও আপটাইমকে কাপল করে। সার্ভিস A যদি ধরে নেয় সার্ভিস B সবসময় উপলব্ধ ও দ্রুত, তাহলে A-র আচরণ আর নিজের কোড দ্বারা সংজ্ঞায়িত থাকে না—এটি B-র খারাপ দিনের দ্বারা সংজ্ঞায়িত হয়। এভাবেই সিস্টেমগুলো কঠিনভাবে বাঁধা পড়ে যায় যদিও কোড মডুলার দেখায়।
বণ্টিত ট্রানজাকশন একটি সাধারণ ফাঁদ: যা মনে হয়েছিল “ইউজার সেভ করো, তারপর কার্ড চার্জ করো” সেটা বহু ধাপের ওয়ার্কফ্লো হয়ে ওঠে ডাটাবেস ও সার্ভিস জুড়ে। টু-ফেজ কমিট বাস্তবে প্রোডাকশনে সহজ থাকে না, তাই অনেক সিস্টেম eventual consistency-তে স্যুইচ করে (উদাহরণ: “পেমেন্ট শীঘ্রই নিশ্চিত হবে”)। সেই পরিবর্তন আপনাকে রিট্রাই, ডুপ্লিকেট ও আউট-অফ-অর্ডার ইভেন্টের জন্য ডিজাইন করতে বাধ্য করে।
আইডেমপটেন্সি অপরিহার্য হয়ে ওঠে: একটি রিকোয়েস্ট রিট্রাই হলে দ্বিতীয় চার্জ বা দ্বিতীয় শিপমেন্ট হওয়া উচিত নয়। ফ্রেমওয়ার্ক-স্তরের রিট্রাই হেল্পারসমূহ সমস্যা বাড়িয়ে দিতে পারে যদি আপনার এন্ডপয়েন্টগুলি রিপিট করা নিরাপদ না।
একটি স্লো ডিপেন্ডেন্সি থ্রেডপুল/কানেকশন পুল/কিউ খেয়ে ফেলতে পারে, একটি ঢেউ তৈরি করে: টাইমআউট রিট্রাই ট্রিগার করে, রিট্রাই লোড বাড়ায়, এবং দ্রুতই অপ্রাসঙ্গিক এন্ডপয়েন্টগুলো degrade করে। “শুধু আরও ইনস্ট্যান্স যোগ করুন” না কখনো সময় খারাপ অবস্থাকে আরও খারাপ করে যদি সবাই একসাথে রিট্রাই করে।
পরিষ্কার কনট্রাক্ট নির্ধারণ করুন (স্কিমা, এরর কোড, ভার্শনিং), প্রতি কলের জন্য টাইমআউট ও বাজেট সেট করুন, এবং প্রয়োজনীয় জায়গায় ফলব্যাক (ক্যাশড রিড, ডিগ্রেডেড রেসপন্স) বাস্তবায়ন করুন।
সবশেষে, প্রতি ডিপেন্ডেন্সির জন্য SLO সেট করুন ও তা কার্যকর করুন: যদি সার্ভিস B তার SLO পূরণ করতে না পারে, সার্ভিস A-কে দ্রুত ব্যর্থ করা বা মার্জিতভাবে degrate করা উচিত, যাতে পুরো সিস্টেমকে চুপিচুপি টেনে নামানো না হয়।
যখন একটি অ্যাবস্ট্র্যাকশন স্কেলে লিক করে, এটি প্রায়শই একটি অস্পষ্ট লক্ষণ (টাইমআউট, CPU স্পাইক, স্লো কুয়েরি) হিসেবে দেখা দেয় যা দলগুলোর প্রিম্যাচার রিরাইট-এ প্রলুব্ধ করে। একটি ভালো উপায় হল অনুমানকে প্রমাণে পরিণত করা।
1) Reproduce (সমস্যা অন-ডিমান্ড ঘটান).
সমস্যাটি ট্রিগার করা সবচেয়ে ছোট দৃশ্যপট ধরুন: এন্ডপয়েন্ট, ব্যাকগ্রাউন্ড জব বা ইউজার ফ্লো। লোকাল বা স্টেজিং-এ প্রোডাকশন-সদৃশ কনফিগ (ফিচার ফ্ল্যাগ, টাইমআউট, কানেকশন পুল) নিয়ে পুনরুত্পাদন করুন।
2) Measure (২–৩ সিগন্যাল বাছুন).
কয়েকটি মেট্রিক বেছে নিন যা বলে দেয় সময় ও রিসোর্স কোথায় যাচ্ছে: p95/p99 লেটেন্সি, এরর রেট, CPU, মেমরি, GC সময়, DB কুয়েরি সময়, কিউ গভীরতা। ঘটনার মাঝেমধ্যে ডজনগুলো গ্রাফ যোগ করার থেকে বিরত থাকুন।
3) Isolate (সন্দেহভাজন সংকুচিত করুন).
টুলিং ব্যবহার করে “ফ্রেমওয়ার্ক ওভারহেড” কে “আপনার কোড” থেকে আলাদা করুন:
EXPLAIN ORM-জেনারেটেড SQL ও ইনডেক্স ব্যবহার যাচাই করতে4) Confirm (কারণ ও প্রভাব প্রমাণ করুন).
একবারে একটি পরিবর্তন করুন: একটি কুয়েরির জন্য ORM বাইপাস, একটি মিডলওয়্যার ডিসেবল, লগ ভলিউম কমানো, কনকারেন্সি ক্যাপ ইত্যাদি। লক্ষণ যদি পূর্বাভাস মতো সরে যায়, আপনি লিক প্রমাণ করেছেন।
বাস্তবগত ডেটা সাইজ (রো কাউন্ট, পে-লোড সাইজ) এবং বাস্তব কনকারেন্সি (বুর্স, লং টেইল, ধীর ক্লায়েন্ট) ব্যবহার করুন। অনেক লিক কেবল ক্যাশ কোল্ড, বড় টেবিল বা রিট্রাই অ্যামপ্লিফিকেশনের সময়ই দেখা দেয়।
EXPLAIN দিয়ে পরীক্ষা করেছেন?অ্যাবস্ট্র্যাকশন লিক ফ্রেমওয়ার্কের নৈতিক ব্যর্থতা নয়—এটা একটি সংকেত যে আপনার সিস্টেমের চাহিদা “ডিফল্ট পাথ” ছাড়িয়ে গেছে। লক্ষ্য ফ্রেমওয়ার্ক ছেড়ে দেওয়া নয়, বরং সচেতনভাবে কখন টিউন করা উচিত এবং কখন বাইপাস করা উচিত তা নির্ধারণ করা।
ফ্রেমওয়ার্কে থাকুন যদি সমস্যাটি কনফিগারেশন বা ব্যবহারজনিত এবং মৌলিক অসঙ্গতি না হয়। ভালো প্রার্থীরা:
যদি আপনি সেটিং দিয়ে ঠিক করতে পারেন, আপনি সহজভাবে আপগ্রেড রাখতে পারবেন এবং “স্পেশাল কেস” কম রাখবেন।
অধিকাংশ পরিণত ফ্রেমওয়ার্ক অ্যাবস্ট্র্যাকশন ছাড়ার উপায় দেয়। সাধারণ প্যাটার্নগুলো:
এটি ফ্রেমওয়ার্ককে একটি টুল হিসেবে রাখে, যে আর্কিটেকচারের ধারক নয়।
সংক্রান্ত রিলিজ অনুশীলনের জন্য দেখুন /blog/canary-releases।
নিচে নামুন যখন (1) সমস্যা একটি ক্রিটিক্যাল পাথকে আঘাত করে, (2) আপনি বিজয় পরিমাপ করতে পারেন, এবং (3) পরিবর্তনটি দীর্ঘমেয়াদি মেইনটেন্যান্স ট্যাক্স না বাড়ায় যা আপনার টিম বহন করতে পারে না। যদি শুধু একজন ব্যক্তি সেই বাইপাস বুঝে, তাহলে সেটা “ফিক্স” নয়—এটি ভঙ্গুর।
লিক খোঁজার সময় দ্রুততা গুরুত্বপূর্ণ—কিন্তু পরিবর্তন রিভার্সিবলও হতে হবে। দলগুলো প্রায়ই Koder.ai ব্যবহার করে প্রোডাকশনের সমস্যাগুলোর ছোট, আইসোলেটেড রিপ্রো তৈরি করতে (একটি ন্যূনতম React UI, একটি Go সার্ভিস, PostgreSQL স্কিমা, এবং লোড-টেস্ট হারনেস) বড় স্ক্যাফোল্ডিং ছাড়াই।
এর planning mode আপনি কী পরিবর্তন করছেন এবং কেন তা ডকুমেন্ট করতে সাহায্য করে, আর snapshots ও rollback “নিচে নামা” পরীক্ষা (উদাহরণ: একটি ORM কুয়েরিকে raw SQL-এ বদলে দেখা) নিরাপদ করে এবং ফলাফল না মিলে সহজে ফিরিয়ে আনা যায়।
আপনি যদি পরিবেশ জুড়ে এই কাজটি করছেন, Koder.ai-র বিল্ট-ইন ডিপ্লয়/হোস্টিং ও এক্সপোর্টেবল সোর্স কোড ডায়াগনোসিস আর্টিফ্যাক্টগুলো (বেনচমার্ক, রিপ্রো অ্যাপ, ইন্টারনাল ড্যাশবোর্ড) ভার্সনড, শেয়ারেবল এবং লোকালের ফোল্ডারে আটকে না রেখে বাস্তব সফটওয়্যার হিসেবে রাখতে সাহায্য করে।
একটি লিকিং অ্যাবস্ট্র্যাকশন এমন একটি স্তর যা জটিলতা ঢেকে দেয় (ORM, retry হেলপার, ক্যাশিং র্যাপার, মিডলওয়্যার), কিন্তু লোড বেড়ে গেলে ওই লুকানো বিবরণগুলো ফলাফল বদলে দেয়।
প্র্যাক্টিক্যালভাবে, আপনার “সহজ মনস্তত্ত্ব” আর বাস্তব আচরণ ভবিষ্যদ্বাণী করতে পারে না, এবং আপনাকে কুয়েরি প্ল্যান, কানেকশন পুল, কিউ গভীরতা, GC, টাইমআউট ও রিট্রাই ইত্যাদি বুঝতে বাধ্য করে।
শুরুতে সিস্টেমগুলোর কাছে অতিরিক্ত ক্ষমতা থাকে: ছোট টেবিল, কম কনকারেন্সি, ওয়ার্ম ক্যাশ, এবং কম ফেইলার ইন্টারঅ্যাকশন।
ভলিউম বেড়ে গেলে, ক্ষুদ্র ওভারহেডগুলো স্থায়ী বটলনেকে রূপ নেয় এবং বিরল এজ-কেস (টাইমআউট, পার্শিয়াল ফেইল) স্বাভাবিক হয়ে যায়। তখনই অ্যাবস্ট্র্যাকশনের লুকানো খরচ ও সীমা প্রোডাকশনে দেখা দেয়।
নিচের প্যাটার্নগুলো লক্ষ্য করুন—যেগুলো রিসোর্স বাড়ালে সহজে ঠিক হয় না:
এই লক্ষণগুলো অনেকে “অধূপুরি প্রোভিশনিং” হিসেবে ভুল করে। যদি ডবল করা রিসোর্স লিনিয়ারভাবে উন্নতি না করে, লিক সন্দেহ করুন।
ORM গুলো শেষ পর্যায়ে প্রতিটি অবজেক্ট অপারেশন SQL-এ রূপান্তর করে—এটা ছোট স্কেলে অদৃশ্য মনে হয়। সাধারণ লিকগুলো:
প্রথমে করণীয়: ইগার লোডিং ব্যবহার করুন যত টীকা করে প্রয়োজন, নির্দিষ্ট কলাম সিলেক্ট করুন, পেজিনেশন যোগ করুন, ব্যাচ অপারেশন নিন এবং জেনারেটেড SQL EXPLAIN দিয়ে ভ্যালিডেট করুন।
কানেকশন পুলগুলো কনকারেন্সি সীমাবদ্ধ করে ডিবিকে রক্ষা করে, কিন্তু গোপন কুয়েরি বিস্তার পুলকে দ্রুত খেয়ে ফেলে।
পুল ফুরিয়ে গেলে অ্যাপ অধিরহে অনুরোধগুলো কিউ করে, লেটেন্সি বাড়ে এবং রিসোর্স আরও দীর্ঘ সময় ধরে ধরে রাখে। দীর্ঘ ট্রানজাকশন লক ধরে রাখে এবং কনকারেন্সি কমিয়ে দেয়।
প্রায়োগিক সমাধান:
থ্রেড-প্রতি-রিকোয়েস্ট এবং অ্যাসিঙ্ক মডেল দুটির ভিন্ন ভাঙন আছে:
সুতরাং_framework concurrency হ্যান্ডল করে_—এই ধারণা লিক করে; আপনাকে explicit limits, timeouts, এবং backpressure দিতে হয়।
ব্যাকপ্রেশার হল সেই মেকানিজম যা বলে “ধীর করো” যখন কম্পোনেন্ট আরও কাজ নিরাপদে নিতে পারে না।
বিনা ব্যাকপ্রেশারের ক্ষেত্রে, স্লো ডিপেন্ডেন্সি ইন-ফ্লাইট রিকোয়েস্ট, মেমরি ব্যবহার এবং কিউ লেন বাড়ায়—এটি একটি ফিডব্যাক লুপ তৈরি করে এবং ডিপেন্ডেন্সিকে আরও ধীর করে তোলে।
সাধারণ টুল:
অটোমেটিক রিট্রাই ধীরে ধীরে অসক্ষমতাকে আউটেজে রূপান্তর করতে পারে:
মিটিগেশন:
ইনস্ট্রুমেন্টেশন ট্র্যাফিক তৈরি করে:
প্র্যাকটিক্যাল নিয়ামক:
ক্লিয়ার কনট্রাক্ট (স্কিমা, এরর কোড, ভার্জনিং) নির্ধারণ করুন, প্রত্যেক কলের জন্য টাইমআউট ও বাজেট সেট করুন, এবং যেখানে প্রয়োজন ফলব্যাক (ক্যাশড রিড, degrated রেসপন্স) বাস্তবায়ন করুন।
SLO গুলো ডিপেন্ডেন্সি অনুযায়ী সেট করুন এবং প্রয়োগ করুন: যদি সার্ভিস B তার SLO পূরণ করতে না পারে, সার্ভিস A-কে দ্রুত ব্যর্থ করা বা মার্জিতভাবে degrate করা উচিত—নিরবভাবে পুরো সিস্টেমকে টেনে নেবার চেয়ে।
একটি প্র্যাকটিক্যাল ওয়ার্কফ্লো:
ফ্রেমওয়ার্ক ত্যাগ করা নয়—বরং সচেতনভাবে কখন টিউন করবেন এবং কখন বাইপাস করবেন।
টিউনিং প্রথমেই (যদি সমস্যাটি কনফিগ/ব্যবহারে হয়):
এস্কেপ হ্যাচেস (নির্দিষ্ট প্রিসিশন দরকার হলে):
Koder.ai ব্যবহার করে ছোট, আইসোলেটেড রেপ্রোডাকশন স্পিন-আপ করা যায়—React UI, Go সার্ভিস, PostgreSQL স্কিমা, লোড-টেস্ট হারনেস—বিনা বড় স্ক্যাফোল্ডিংয়ের।
এর planning mode পরিবর্তনগুলো ডকুমেন্ট করে, snapshots ও rollback-এপর্যন্ত রিভার্সিবিলিটি বাড়ায়—যেমন একটি ORM কুয়েরি raw SQL-এ বদলে পরীক্ষার পরে সহজে revert করা যায়।
এছাড়াও, Koder.ai-র ডিপ্লয়/হোস্টিং ও এক্সপোর্টেবল সোর্স কোড ডায়াগনোসিস আর্টিফ্যাক্টগুলো (বেনচমার্ক, রিপ্রো অ্যাপ, ইন্টারনাল ড্যাশবোর্ড) ভার্সনড ও শেয়ারেবল রাখে।
EXPLAINঅপারেশনাল অনুশীলন: