কেন MySQL প্রথম ওয়েবের জন্য একটি ভিত্তি হয়ে উঠল
MySQL প্রথমকের ওয়েবের ডাটাবেস হিসেবে জনপ্রিয় হয়েছিল এক সহজ কারণের জন্য: এটি তখনকার ওয়েবসাইটগুলোর চাহিদার সঙ্গে মানিয়ে গেল—সংরক্ষণ এবং দ্রুত স্ট্রাকচার্ড ডেটা পুনরুদ্ধার, সামান্য হার্ডওয়্যারে চলা, এবং ছোট টিমের জন্য পরিচালনা করা সহজ।
এটি অধিগম্য ছিল। দ্রুত ইনস্টল করা যেত, সাধারণ প্রোগ্রামিং ভাষা থেকে কানেক্ট করা যেত, এবং ডেডিকেটেড ডাটাবেস অ্যাডমিন নিয়োগ না করেই সাইট চালু করা সম্ভব ছিল। “পর্যাপ্ত পারফরম্যান্স” এবং কম অপারেশনাল ওভারহেডের এই মিশ্রণ স্টার্টআপ, হবি প্রজেক্ট এবং বেড়ে ওঠা ব্যবসায়ের জন্য এটিকে ডিফল্ট করে দিল।
এখানে “স্কেল” আসলে কি বোঝায়
লোকেরা যখন বলে MySQL “স্কেল করেছে,” তারা সাধারণত একটি মিশ্রণ বোঝায়:
- ট্র্যাফিক বৃদ্ধিঃ বেশি কনকারেন্ট ইউজার এবং প্রতি সেকেন্ডে বেশি কুয়েরি।
- ডেটা বৃদ্ধিঃ টেবিল হাজার থেকে মিলিয়ন বা বিলিয়ন সারিতে পরিণত হওয়া।
- নির্ভরযোগ্যতার প্রত্যাশাঃ ক্র্যাশ, ডিপ্লয় এবং হার্ডওয়্যার ফেইল্যারের মধ্যেও অনলাইনে থাকা।
- খরচ সীমাবদ্ধতাঃ এ সব কিছু এন্টারপ্রাইজ-মাত্রার বাজেট ছাড়াই অর্জন করা।
প্রাথমিক ওয়েব কোম্পানিগুলো শুধু গতি চাননি; তারা পূর্বাবস্থায় পারফরম্যান্স ও আপটাইম চান যা খরচের মধ্যে সম্ভব।
আমরা কোন মূল লিভারগুলো পুনর্বিবেচনা করব
MySQL-এর স্কেলিং গল্প আসলে ব্যবহারযোগ্য ট্রেডঅফ এবং পুনরাবৃত্ত প্যাটার্নের গল্প:
- স্কিমা ও কুয়েরি ডিজাইন (কি সংরক্ষণ করবেন, কিভাবে JOIN করবেন, কী এড়াবেন)
- ইনডেক্স ("ডেভে কাজ করে" vs "প্রোডে কাজ করে")
- ক্যাশিং (প্রতি পেজ ভিউয়ে ডাটাবেস না থ্রোট করা)
- রেপ্লিকেশন ও রিড রেপ্লিকা (রিড ট্র্যাফিক ভাগ করা)
- শার্ডিং/পার্টিশনিং (একটি ডাটাবেস যদি চাপ সামলাতে না পারে তাহলে ডেটা ভাগ করা)
এই আর্টিকলের স্কোপ
এটি একটি ভ্রমণ-দলিল যেখানে দলগুলো কিভাবে বাস্তব ওয়েব ট্র্যাফিকের অধীনে MySQL কে performant রাখত—এটি সম্পূর্ণ MySQL ম্যানুয়াল নয়। লক্ষ্য হলো ব্যাখ্যা করা যে ডাটাবেস কীভাবে ওয়েবের চাহিদার সাথে মেলে এবং কেন একই ধারণাগুলো আজও বিশাল প্রোডাকশনে দেখা যায়।
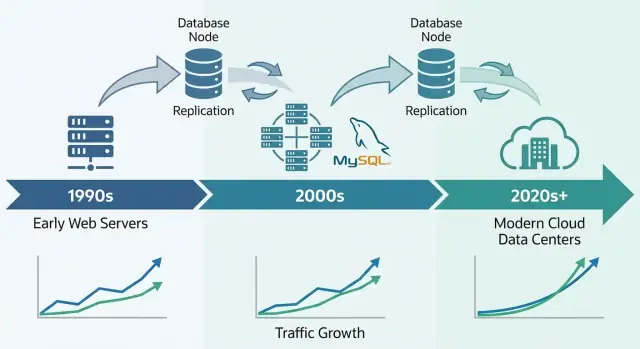
LAMP যুগ: সরলতা MySQL বিস্তারে কিভাবে সাহায্য করল
MySQL-এর ব্রেকআউট মুহূর্তটি ঘনিষ্ঠভাবে জড়িত ছিল শেয়ার্ড হোস্টিং ও ছোট টিম দ্রুত ওয়েব অ্যাপ বানানোর উত্থানের সঙ্গে। এটা কেবল তাই যে MySQL “পর্যাপ্ত ছিল”—এটি প্রথম ওয়েব কিভাবে ডিপ্লয়, ম্যানেজ ও পে করা হত তার সঙ্গে মানিয়ে চলতে পারত।
কেন LAMP প্রথম হোস্টিংয়ের সাথে মিলেছিল
LAMP (Linux, Apache, MySQL, PHP/Perl/Python) কাজ করেছে কারণ এটি সেই ডিফল্ট সার্ভারের সাথে চাটখার মত মিলে যেটি অধিকাংশ মানুষই নিতে পারত: একটি একক লিনাক্স বক্সে ওয়েব সার্ভার ও ডাটাবেস পাশাপাশিভাবে চলছে।
হোস্টিং প্রদানকারী এই সেটআপগুলো টেমপ্লেট করতে পারত, ইনস্টল অটোমেট করতে পারত, এবং সস্তায় প্রস্তাব করতে পারত। ডেভেলপাররা প্রায় সব জায়গায় একই বেসলাইন পরিবেশ ধরে নিতে পারত, যে কারণে লোকাল ডেভ থেকে প্রোডাকশনে যাওয়ার সময় আশ্চর্যের ঘটনা কমে যেত।
বিতরণ কৌশল হিসেবে সরলতা
MySQL ইনস্টল, স্টার্ট ও কানেক্ট করা সহজ ছিল। এটি পরিচিত SQL কথা বলত, একটি সরল কমান্ড-লাইন ক্লায়েন্ট ছিল, এবং সেই সময়কার জনপ্রিয় ভাষা ও ফ্রেমওয়ার্কগুলোর সাথে চমৎকারভাবে ইন্টিগ্রেট হত।
পরিচালনাগত মডেলও গ্রহনযোগ্য ছিল: একটি প্রধান প্রক্রিয়া, কয়েকটি কনফিগারেশন ফাইল, এবং পরিষ্কার ফল ফেল। ফলে সাধারণ sysadmin বা প্রায়শই ডেভেলপাররাই বিশেষ প্রশিক্ষণ ছাড়াই ডাটাবেস চালাতে পেরেছিল।
খরচ, প্রবেশগম্যতা ও কমিউনিটি গতি
ওপেন-সোর্স হওয়ায় প্রারম্ভিক লাইসেন্সিং ফ্রিকশন বন্ধ হয়ে গেল। একজন ছাত্র প্রকল্প, একটি হবি ফোরাম, ও একটি ছোট ব্যবসার সাইট—তিনটাই একই ডাটাবেস ইঞ্জিন ব্যবহার করতে পারত বড় কোম্পানির মতোই।
ডকুমেন্টেশন, মেইলিং লিস্ট ও পরে অনলাইন টিউটোরিয়ালগুলো গতিবেগ সৃষ্টি করল: বেশি ব্যবহারকারী মানে বেশি উদাহরণ, বেশি টুল ও দ্রুত ট্রাবলশুটিং।
প্রাথমিক ওয়ার্কলোড যা MySQL ভালভাবে সেবা করত
অধিকাংশ প্রাথমিক সাইট ছিল রিড-হেভি ও তুলনামূলক সরল: ফোরাম, ব্লগ, CMS-চালিত পেজ, ছোট ই-কমার্স ক্যাটালগ। এই অ্যাপগুলো সাধারনত আইডি দ্বারা দ্রুত লুকআপ, সাম্প্রতিক পোস্ট, ইউজার অাকাউন্ট, এবং বেসিক সার্চ/ফিল্টারিং চাইত—ঠিক সেই ধরণের ওয়ার্কলোড যা MySQL সামান্য হার্ডওয়্যারে দক্ষভাবে সাম্ভালতে পারত।
প্রাথমিক স্কেলিং চাপ: বেশি ইউজার, বেশি রিড, বেশি রাইট
প্রাথমিক MySQL ডিপ্লয়মেন্ট প্রায়ই শুরু করত “এক সার্ভার, এক ডাটাবেস, এক অ্যাপ” দিয়ে। একটি হবি ফোরাম বা ছোট কোম্পানি সাইটের জন্য এটা ঠিক থাকত—যতক্ষণ না অ্যাপটি জনপ্রিয় হয়ে ওঠে। পেজ ভিউ সেশন হয়ে যায়, সেশনগুলো কনস্ট্যান্ট ট্র্যাফিকে পরিণত হয়, এবং ডাটাবেস চুপচাপ ব্যাকরুম কম্পোনেন্ট থাকা বন্ধ করে দেয়।
কেন রিড সাধারণত জয়ী হত
অধিকাংশ ওয়েব অ্যাপ (আজও) রিড-হেভি। একটি হোমপেজ, প্রোডাক্ট লিস্ট, বা প্রোফাইল পেজ প্রতি এক আপডেটের জন্য হাজারবার দেখা হতে পারে। এই অসমতা প্রাথমিক স্কেলিং সিদ্ধান্তগুলোকে প্রভাবিত করল: যদি আপনি রিডগুলিকে দ্রুততর করতে পারেন—অথবা পুরোপুরি ডাটাবেসে না পাঠাতে পারেন—তাহলে আপনি পুনর্লিখন ছাড়াই অনেক বেশি ব্যবহারকারী সার্ভ করতে পারতেন।
ক্যাচ: রিড-হেভি অ্যাপেও গুরুত্বপূর্ণ রাইট থাকে। সাইন-আপ, পারচেজ, কমেন্ট এবং অ্যাডমিন আপডেটগুলো ছেড়ে দেয়া যায় না। ট্র্যাফিক বাড়ার সাথে সাথে সিস্টেমকে একই সঙ্গে রিড ও “মাস্ট-সাকসিড” রাইট হ্যান্ডল করতে হবে।
প্রথম যন্ত্রণা পয়েন্টগুলো দলগুলো অনুভব করল
উচ্চ ট্র্যাফিকে সমস্যাগুলো সাধারণ ভাষায় দৃশ্যমান হল:
- ধীর কুয়েরি: রিপোর্ট-স্টাইল কুয়েরি বেশি সারি স্ক্যান করলে পেজ ‘হ্যাং’ করত।
- টেবিল লক: কিছু প্রাথমিক সেটআপে রাইট পড়াকে ব্লক করতে পারত (এবং উল্টো)।
- সীমিত RAM: ইনডেক্স এবং হট ডেটা মেমরিতে ফিট না করলে সার্ভার বেশি ডিস্ক টাচ করত—মেমরির থেকে অনেক ধীর।
প্রথমে সম্পর্ক-বিচ্ছিন্ন করা
দলগুলো শিখল কিভাবে দায়িত্ব ভাগ করতে হয়: অ্যাপ ব্যবসায়িক লজিক হ্যান্ডল করে, একটি ক্যাশ পুনরাবৃত্তি রিড শোষণ করে, এবং ডাটাবেস নির্ভুল সংরক্ষণ ও জরুরি কুয়েরি ফোকাস করে। এই মানসিক মডেল পরে কুয়েরি টিউনিং, ভাল ইনডেক্সিং, ও রেপ্লিকাসহ আউট-স্কেলিং ধাপগুলোর পথ তৈরি করল।
স্টোরেজ ইঞ্জিন: নির্ভরযোগ্যতার বড় মোড়
MySQL-এর একটি অনন্য বিষয় হল এটি “উপরে একটি সার্ভার” না—এটি বিভিন্ন স্টোরেজ ইঞ্জিন ব্যবহার করে ডেটা সংরক্ষণ ও পুনরুদ্ধার করে।
স্টোরেজ ইঞ্জিন আসলে কী
উপরে বাড়তি ভাষায়, স্টোরেজ ইঞ্জিন নির্ধারণ করে কিভাবে সারি ডিস্কে লেখা হয়, ইনডেক্স কিভাবে বজায় থাকে, লক কিভাবে কাজ করে, এবং ক্র্যাশের পরে কী হয়। আপনার SQL একই থাকতে পারে, কিন্তু ইঞ্জিন নির্ধারণ করে ডাটাবেস কি একটি দ্রুত নোটবুকের মতো আচরণ করবে, না একটি ব্যাংক লেজারের মতো।
MyISAM বনাম InnoDB (সোজা বাংলায় পার্থক্য)
অনেক MySQL সেটআপ দীর্ঘদিন MyISAM ব্যবহার করত। এটা সরল ও রিড-হেভি সিচুয়েশনে দ্রুত হতে পারে, কিন্তু এর কিছু ট্রেডঅফ ছিল:
- লকিং: MyISAM সাধারণত টেবিল-লেভেল লক ব্যবহার করে। একটি রাইট অনেক পড়া/রাইট ব্লক করতে পারে যতটা আপনি আশা করবেন না।
- ক্র্যাশ: আনক্লিন শাটডাউনের পরে MyISAM টেবিল মেরামত করতে হতে পারে এবং সাম্প্রতিক পরিবর্তন হারাতে পারে।
- ট্রানজেকশন: MyISAM ট্রানজেকশন সাপোর্ট করে না, তাই বহু-ধাপ আপডেটকে “সব সফল অথবা সব ব্যর্থ”ভাবে চালানো কঠিন।
InnoDB এগুলো উল্টে দিল:
- লকিং: রো-লেভেল লকিং অনেক ব্যবহারকারী ভিন্ন সারি আপডেট করলে ব্লক কমায়।
- ক্র্যাশ রিকভারি: ব্যাকআপ ও অটোমেটিক রিকভারি ভালো।
- ট্রানজেকশন: পূর্ণ ট্রানজেকশন সাপোর্ট, অ্যাপ আচরণকে অনেক বেশি পূর্বানুমানযোগ্য করে।
কেন InnoDB প্রোডাকশনের ডিফল্ট হলো
ওয়েব অ্যাপগুলোর প্রাধান্য রিড থেকে লিক করে যখন তারা লগইন, কার্ট, পেমেন্ট এবং মেসেজিং হ্যান্ডল করতে শুরু করল, তখন সঠিকতা ও রিকভারি গতি-র সমান গুরুত্ব পেল। InnoDB-র সাহায্যে রিস্টার্ট বা ট্র্যাফিক স্পাইক ডেটা করাপশনে পরিণত হবে না এমন আশ্বাস নিয়ে স্কেল করা বাস্তবসম্মত হয়।
বাস্তব শিক্ষা: ইঞ্জিন পছন্দ পারফরম্যান্স ও নিরাপত্তা—উভয়ের উপর প্রভাব ফেলে। এটা কেবল চেকবক্স নয়—আপনার লকিং মডেল, ফেলিয়ার আচরণ, এবং অ্যাপ গ্যারান্টি এটির উপর নির্ভর করে।
ইনডেক্স ও কুয়েরি ডিজাইন: প্রথম স্কেলিং গুণক
শার্ডিং, রিড রেপ্লিকা বা জটিল ক্যাশ ছাড়াও, অনেক প্রাথমিক MySQL সাফল্য এসেছে একটি ধ্রুবপন্থার বদলে: কুয়েরিগুলোকে পূর্বানুমানযোগ্য করা। ইনডেক্স ও কুয়েরি ডিজাইন ছিল প্রথম “গুণক” কারণ তারা প্রতি রিকুয়েস্টে MySQL-কে কত ডেটা টাচ করতে হবে তা কমিয়েছে।
B-tree ইনডেক্স: দ্রুত লুকআপ বনাম ফুল-টেবিল স্ক্যান
অধিকাংশ MySQL ইনডেক্স B-tree ভিত্তিক। এগুলোকে একটি অ্যারেড ডিরেক্টর মনে করুন: MySQL সঠিক জায়গায় ঝাঁপিয়ে ছোট، সংলগ্ন ডেটার স্লাইস পড়তে পারে। সঠিক ইনডেক্স না থাকলে সার্ভার প্রায়শই সারি এক এক করে স্ক্যান করে। কম ট্র্যাফিকে এটি ধীর হওয়া মাত্র; স্কেলে এটি ট্র্যাফিককে বাড়িয়ে তোলে—আরও CPU, ডিস্ক I/O, লক সময় ও সবকিছুর জন্য উচ্চ ল্যাটেন্সি।
কুয়েরি অ্যান্টি-প্যাটার্ন যা স্কেলে ক্ষতি করে
কিছু প্যাটার্ন বারবার "স্টেজিংয়ে কাজ করত" কিন্তু প্রোডাকশনে ফেল হতো:
SELECT *: অপ্রয়োজনীয় কলাম টেনে আনে, I/O বাড়ায় এবং কভারিং-ইনডেক্স সুবিধা নষ্ট করে।- লিডিং-ওয়াইল্ডকার্ড:
WHERE name LIKE '%shoe' সাধারণ B-tree ইনডেক্স কার্যকরভাবে ব্যবহার করতে পারে না।
- ইনডেক্সড কলামে ফাংশন:
WHERE DATE(created_at) = '2025-01-01' প্রায়শই ইনডেক্স ব্যবহার বাধা দেয়; বদলে রেঞ্জ ফিল্টার ব্যবহার করুন যেমন created_at >= ... AND created_at < ....
EXPLAIN ও স্লো লগকে দৈনন্দিন টুল বানান
দুই অভ্যাস যে কোনো একক কৌশলের চেয়ে ভালো স্কেল করে:
EXPLAIN চালান যাতে নিশ্চিত হওয়া যায় আপনি কাঙ্ক্ষিত ইনডেক্স ব্যবহার করছেন এবং স্ক্যান করছেন না।- স্লো কুয়েরি লগ দেখুন যাতে ফিচার শিপ করার সময় নয়, দ্রুত রিগ্রেশন ধরতে পারেন।
ইনডেক্সগুলো প্রকৃত ফিচারের সাথে মানানসই হওয়া উচিত
ইনডেক্স ডিজাইন করুন প্রোডাক্ট কিভাবে আচরণ করে তার চারপাশে:
- সার্চ: ফুল-টেক্সট বা প্রিফিক্স কৌশল বিবেচনা করুন উইল্ডকার্ড স্ক্যানের পরিবর্তে।
- ফিড:
(user_id, created_at) রকম কম্পোজিট ইনডেক্স “সর্বশেষ আইটেম” দ্রুত করে।
- চেকআউট ফ্লো: order/payment আইডেন্টিফায়ারে ইউনিক ইনডেক্স ডুপ্লিকেট প্রতিরোধ ও লুকআপ দ্রুত করে।
ভাল ইনডেক্সিং হল “আরও ইনডেক্স” করা নয়—বরং সেই কয়েকটি ইনডেক্স যা গুরুত্বপূর্ণ রিড/রাইট পথগুলোর সাথে মিলে।
উল্লম্ব বনাম অনুভূমিক স্কেলিং: কি বদলে যায় এবং কেন
ডাটাবেস পরিবর্তন নিরাপদে রিলিজ করুন
স্ন্যাপশট নিন, মাইগ্রেশন টেস্ট করুন, এবং রিলিজ ভুল গেলে দ্রুত রোলব্যাক করুন.
যখন একটি MySQL-চালিত প্রোডাক্ট ধীর হয়ে যায়, প্রধান সিদ্ধান্ত হয় উপরের দিকে স্কেল (উল্লম্ব) না বহু সার্ভারের দিকে (অনুভূমিক)। এরা আলাদা সমস্যার সমাধান করে—এবং অপারেশনাল জীবন অনেকটি আলাদা করে দেয়।
উল্লম্ব স্কেলিং: “বড় বক্স” কৌশল
উল্লম্ব মানে MySQL-কে একটি মেশিনে আরও সম্পদ দেওয়া: দ্রুত CPU, বেশি RAM, ভালো স্টোরেজ।
এটি প্রায়শই অবিশ্বাস্যভাবে ভাল কাজ করে কারণ অনেক বটলনেক লোকাল হয়:
- CPU: জটিল কুয়েরি, সর্ট, JOIN, ও অকার্যকর WHERE কন্ডিশন কোরগুলো ম্যাক্স করে দিতে পারে।
- I/O: ধীর ডিস্ক ও র্যান্ডম রিড/রাইট ডেটা মেমরিতে না থাকলে প্রাধান্য পায়।
- বাফার পুল/মেমরি: InnoDB-তে বেশি RAM হট ডেটা ও ইনডেক্স ক্যাশ করে, ডিস্ক হিট কমায়।
- কানেকশন সীমা: অতিরিক্ত কনকারেন্ট কানেকশন থ্রেড, মেমরি এবং কন্টেক্সট সুইচিংকে মাত করতে পারে।
উল্লম্ব স্কেলিং সাধারণত দ্রুত শীর্ষ ফল দেয়: কম চলমান অংশ, সরল ফেলিয়ার মোড, এবং কম অ্যাপ পরিবর্তন। কন্স: সর্বদা একটি ছাদ আছে (এবং আপগ্রেডে ডাউনটাইম বা ঝুঁকিপূর্ণ মাইগ্রেশন লাগতে পারে)।
অনুভূমিক স্কেলিং: “আরও বক্স”, আরো সমন্বয়
অনুভূমিক স্কেলিং মেশিনগুলো যোগ করে। MySQL-এ সাধারণত মানে:
- রিডগুলো রেপ্লিকাগুলোতে ভাগ করা
- ডেটা ভাগ করে লেখা বিভক্ত করা (শার্ডিং) বা কর্মপ্রবাহ পুনর্গঠন
এটি কঠিন কারণ আপনাকে সমন্বয়ের সমস্যাগুলো মোকাবিলা করতে হয়: রেপ্লিকেশন ল্যাগ, ফেইলোভার আচরণ, কনসিস্টেন্সি ট্রেডঅফ, ও আরো অপারেশনাল টুলিং। আপনার অ্যাপকেও জানতে হবে কোন সার্ভারে কথা বলতে হবে (অথবা একটি প্রক্সি লেয়ার লাগবে)।
প্রত্যাশা নির্ধারণ: শার্ডিং-এ ঝাঁপ মারবেন না
অধিকাংশ টিম শার্ডিংকে প্রথম স্কেলিং ধাপ হিসেবে প্রয়োজন করে না। প্রথমে নিশ্চিত করুন সময় কোথায় খাচ্ছে (CPU বনাম I/O বনাম লক কনটেনশন), ধীর কুয়েরি ও ইনডেক্স ঠিক করুন, এবং মেমরি/স্টোরেজ রাইট-সাইজ করুন। অনুভূমিক স্কেলিং তখনই ফলদায়ক যখন একটি একক মেশিন আপনার রাইট রেট, স্টোরেজ সাইজ, বা অ্যাভেইলেবিলিটি চাহিদা পূরণ করতে পারে না—ভাল টিউনিংয়ের পরে থাকা সত্ত্বেও।
রেপ্লিকেশন ও রিড রেপ্লিকা: রিড স্কেল করার বাস্তব উপায়
রেপ্লিকেশন ছিল এমন এক পথ যার মাধ্যমে MySQL সিস্টেমগুলো গ্রোথ হ্যান্ডেল করত: একটি ডাটাবেসকে সব কাজ করতে না দিয়ে, আপনি তার ডেটা কপি করে অন্যান্য সার্ভারে ছড়িয়ে দিতেন এবং কাজ ভাগ করতেন।
সাধারণ ভাষায় রেপ্লিকেশন: একটি প্রাইমারি ও রেপ্লিকা
একটি প্রাইমারি (কখনো কখনো “মাস্টার”) পরিবর্তন গ্রহণ করে—INSERT, UPDATE, DELETE। এক বা একাধিক রেপ্লিকা ধারাবাহিকভাবে সেই পরিবর্তনগুলো টেনে নিয়ে প্রয়োগ করে, নিকট-রিয়েল-টাইম কপি রাখে।
আপনার অ্যাপ তখন করতে পারে:
- রাইট প্রাইমারিতে পাঠানো
- বহু রিড রেপ্লিকাগুলোতে পাঠানো
ওয়েব ট্র্যাফিক প্রায়শই রিড-হেভি দ্রুত বাড়ে—এ কারণেই প্যাটার্নটি জনপ্রিয় হয়।
মানুষ রিড রেপ্লিকাকে কোথায় ব্যবহার করত
রিড রেপ্লিকা কেবল পেজ ভিউ দ্রুত করার জন্য নয়। এগুলো এমন কাজগুলোকে পৃথক করত যা মূল ডাটাবেস ধীর করে দিত:
- রিড স্কেলিং: প্রোডাক্ট পেজ, ফিড, সার্চ রেজাল্ট ইত্যাদি
- অ্যানালিটিকস ও রিপোর্টিং: দীর্ঘ কুয়েরি রেপ্লিকায় চালানো যাতে প্রাইমারি ব্লক না হয়
- ব্যাকআপ: লজিক্যাল ডাম্প বা ব্যাকআপ টুলিং একটি রেপ্লিকায় চালিয়ে প্রোডাকশনে প্রভাব কমানো
আপনাকে কোন ট্রেডঅফগুলি মেনে নিতে হয়
রেপ্লিকেশন বিনামূল্যের নয়। সবচেয়ে সাধারণ সমস্যা হল রেপ্লিকেশন ল্যাগ—স্পাইক চলাকালে রেপ্লিকাগুলো সেকেন্ড (বা বেশি) পিছিয়ে থাকতে পারে।
এটি একটি মূল অ্যাপ-লেভেল প্রশ্ন তৈরি করে: read-your-writes consistency। যদি একজন ব্যবহারকারী প্রোফাইল আপডেট করে এবং আপনি সঙ্গে সঙ্গেই রেপ্লিকা থেকে পড়েন, তারা পুরোনো ডেটা দেখতে পেতে পারে। অনেক টিম সমাধান করে লেখার পরে “প্রাইমারি থেকে পড়ুন” নীতি বা ছোট একটি উইন্ডো তৈরি করে।
রেপ্লিকেশন মানেই ফেইলোভার নয়
রেপ্লিকেশন ডেটা কপি করে; এটি স্বয়ংক্রিয়ভাবে আপনাকে ফেইল-ওভার দেয় না। ফেইলোভার—একটি রেপ্লিকাকে প্রোমোট করা, ট্রাফিক রিডাইরেক্ট করা, এবং অ্যাপ রি-কানেক্ট করা—একটি আলাদা সক্ষমতা যা টুলিং, টেস্টিং ও নির্দিষ্ট অপারেশনাল প্রসিডিউর চায়।
উচ্চ উপলব্ধতা মৌলিক বিষয়: ফেলিয়ারগুলোর মধ্যেও অনলাইনে থাকা
স্কেল পরিস্থিতি আগে থেকেই টেস্ট করুন
লঞ্চের আগে ট্রাফিক, কনসিস্টেন্সি চাহিদা ও ব্যর্থতার আচরণ মডেল করতে Koder.ai-কে বলুন.
উচ্চ উপলব্ধতা (HA) হলো সেই অনুশীলনগুলোর সেট যা ডাটাবেস সার্ভার ক্র্যাশ, নেটওয়ার্ক ড্রপ বা রক্ষণাবেক্ষণের সময় আপনার অ্যাপ চালু রাখে। লক্ষ্যগুলো সহজ: ডাউনটাইম কমানো, রক্ষণাবেক্ষণ নিরাপদ করা, এবং পুনরুদ্ধার পূর্বনির্ধারিত হওয়া—অলিতে অস্তিত্বেই improvisation নয়।
সবচেয়ে সাধারণ HA প্যাটার্নগুলো
প্রাথমিক MySQL ডিপ্লয়মেন্ট প্রায়ই "একটি প্রধান ডাটাবেস" দিয়ে শুরু করে। HA সাধারণত একটি দ্বিতীয় মেশিন যোগ করে যাতে ফেলিয়ার মানে দীর্ঘ আউটেজ না হয়।
- প্রাইমারি–স্ট্যান্ডবাই (একটিভ–প্যাসিভ): একটি সার্ভার ট্রাফিক হ্যান্ডল করে; একটি স্ট্যান্ডবাই নেওয়া থাকে চূড়ান্ত গ্রহণের জন্য প্রস্তুত।
- মাল্টি-নোড ক্লাস্টার: একাধিক ডেটাবেস নোড সহযোগীভাবে সার্ভিস চালিয়ে রাখে, সাধারণত লেখার ক্ষেত্রে কঠোর নিয়ম থাকে।
- স্বয়ংক্রিয় ফেইলোভার: মনিটরিং প্রাইমারি ফেলিউর শনাক্ত করে ও স্ট্যান্ডবাইকে প্রোমোট করে, অ্যাপের কানেকশন টার্গেট আপডেট করে।
অটোমেশন সাহায্য করে, কিন্তু এটি বার বাড়ায়: আপনার টিমকে ডিটেকশন লজিকে বিশ্বাস করতে হবে এবং “স্প্লিট ব্রেন” (দুইটি সার্ভারই প্রাইমারি মনে করা) প্রতিরোধ করতে হবে।
RPO এবং RTO, সরল ভাষায়
দুটি মেট্রিক HA সিদ্ধান্তকে কম আবেগপ্রবণ ও বেশি পরিমাপযোগ্য করে:
- RPO (Recovery Point Objective): আপনি কতটা ডেটা হারাতে পারবেন। যদি একটি রেপ্লিকা 10 সেকেন্ড পিছিয়ে থাকে, আপনার RPO প্রায় ~10 সেকেন্ড।
- RTO (Recovery Time Objective): আপনি কতক্ষণ ডাউন থাকতে পারবেন। এতে ডিটেকশন, প্রোমোশন, এবং অ্যাপ রি-কানেক্ট টাইম সমানভাবে অন্তর্ভুক্ত।
HA বাস্তব করার অপারেশনাল মৌলিক বিষয়গুলো
HA শুধু টপোলজি নয়—এটি অনুশীলন।
বাকআপ নিয়মিত হতে হবে, কিন্তু মূল ব্যাপার হল রিস্টোর টেস্ট: আপনি কি দ্রুত ও চাপের মধ্যে নতুন সার্ভারে সফলভাবে রিকভার করতে পারেন?
স্কিমা চেঞ্জও গুরুত্বপূর্ণ। বড় টেবিল আলটরেশন লেখাকে লক বা কুয়েরি ধীর করে দিতে পারে। নিরাপদ পদ্ধতি হিসেবে লো-ট্র্যাফিক উইন্ডো, অনলাইন স্কিমা চেঞ্জ টুল, এবং সবসময় রোলব্যাক প্ল্যান রাখা ভালো।
ভালভাবে করলে, HA ফেলিয়ারগুলোকে জরুরি ঘটনায় না রেখে পরিকল্পিত, অনুশীলিত ইভেন্টে পরিণত করে।
ক্যাশিং কৌশল যা MySQL কে ওয়েব ট্র্যাফিকের মধ্যে দ্রুত রেখেছিল
ক্যাশিং ছিল প্রাথমিক ওয়েব টিমগুলোকে MySQL রেসপনসিভ রাখার সবচেয়ে সরল উপায়গুলোর মধ্যে। ধারণা সরল: পুনরাবৃত্ত অনুরোধগুলোকে ডাটাবেসের চেয়ে দ্রুত কিছুর কাছ থেকে সার্ভ করুন, এবং কেবল তখনই MySQL-এ পাঠান যখন প্রয়োজন। ভালোভাবে করা হলে ক্যাশিং রিড লোয় ব্যাপকভাবে কমায় এবং আকস্মিক স্পাইকগুলোকে ধাক্কা না দিয়ে শান্তভাবে সামলায়।
সাধারণ ক্যাশ লেয়ারগুলো
অ্যাপ্লিকেশন/অবজেক্ট ক্যাশ সেই “টুকরো” ডেটা সরবরাহ করে যা কোড বারংবার চায়—ইউজার প্রোফাইল, প্রোডাক্ট বিস্তারিত, পারমিশন চেক। একই SELECT শতবার চালানোর বদলে অ্যাপ একটি কী দিয়ে প্রি-কনপিউটেড অবজেক্ট পড়ে।
পেজ বা ফ্র্যাগমেন্ট ক্যাশ রেন্ডার করা HTML স্টোর করে (পূর্ণ পেজ বা অংশ)। কন্টেন্ট-হেভি সাইটগুলোর জন্য এটা বিশেষভাবে কার্যকর যেখানে অনেক ভিজিটর একই পেজ দেখে।
কুয়েরি রেজাল্ট ক্যাশিং একটি নির্দিষ্ট কুয়েরির ফল রাখতে পারে। SQL স্তরে ক্যাশ না থাকলেও, আপনি “এই এন্ডপয়েন্টের ফল” একটি কী দিয়ে ক্যাশ করতে পারেন।
ধারণাগতভাবে, টিমগুলো ইন-মেমরি কী/ভ্যালু স্টোর, HTTP কেশ, বা অ্যাপ ফ্রেমওয়ার্কের বিল্ট-ইন ক্যাশ ব্যবহার করে। সঠিক টুল কম গুরুত্বপূর্ণ—কিন্তু ধারাবাহিক কী, TTL (মেয়াদ) ও পরিষ্কার মালিকানা অপরিহার্য।
কঠিন অংশ: ক্যাশ ইনভ্যালিডেশন
ক্যাশিং সততা (freshness) বনাম গতি বিনিময় করে। কিছু ডেটা হালকা জীর্ণ হতে পারে (নিউজ, ভিউ কাউন্ট); অন্য ডেটা ঠিক থাকতে হবে (চেকআউট টোটাল, পারমিশন)। সাধারণত আপনি বিপরীত পছন্দ করেন:
- সময়-ভিত্তিক মেয়াদ (TTL) (সরল, সংক্ষিপ্ত স্ট্যালনেস দেয়)
- ইভেন্ট-ভিত্তিক ইনভ্যালিডেশন (আরও সঠিক, কিন্তু ভুল করা সহজ)
ইনভ্যালিডেশন ব্যর্থ হলে ব্যবহারকারী পুরোনো কন্টেন্ট দেখতে পারে। অতিরিক্ত আগ্রাসী হলে লাভ নষ্ট হয়ে যায় এবং MySQL আবার হিট হয়।
কেন এটা স্পাইক মসৃণ করে
ট্র্যাফিক বেড়ে গেলে, ক্যাশ বারবারের রিড শোষণ করে এবং MySQL কেবল “বাস্তব কাজ” (রাইট, ক্যাশ মিস, জটিল কুয়েরি) করে। এতে কিউয়িং কমে, স্লোডাউন কেসকেড হওয়া থমকে যায়, এবং নিরাপদভাবে স্কেল করার সময় কেনাকাটা করা যায়।
শার্ডিং ও পার্টিশনিং: যখন এক ডাটাবেস যথেষ্ট নয়
একটি সীমা আছে যেখানে “বড় হার্ডওয়্যার” এবং সুক্ষ্ম কুয়েরি টিউনিং আর কাজ দেয় না। যদি একটি একক MySQL সার্ভার রাইট ভলিউম, ডেটাসেট সাইজ বা রক্ষণাবেক্ষণ উইন্ডো হ্যান্ডেল করতে না পারে, আপনি ডেটা ভাগ করার কথা ভাবতে শুরু করবেন।
পার্টিশনিং বনাম শার্ডিং (কেন তারা আলাদা)
পার্টিশনিং এক টেবিলকে ছোট ছোট অংশে ভাঙে একই MySQL ইনস্ট্যান্সের ভিতরে (উদাহরণস্বরূপ, তারিখ অনুযায়ী)। এটি ডিলিট, আর্কাইভ ও কিছু কুয়েরি দ্রুত করতে পারে, কিন্তু এটি সেই এক সার্ভারের CPU, RAM ও I/O সীমা ছাড়িয়ে যেতে সাহায্য করে না।
শার্ডিং ডেটা কয়েকটি MySQL সার্ভারের মধ্যে ভাগ করে দেয়। প্রতিটি শার্ড সারির একটি সাবসেট ধরে রাখে, এবং আপনার অ্যাপ (বা একটি রাউটিং লেয়ার) নির্ধারণ করে কোন অনুরোধ কোন শার্ডে যাবে।
কখন শার্ডিং দরকারি হয়
শার্ডিং সাধারণত তখন আসে যখন:
- ইনডেক্সিং, কুয়েরি ফিক্স ও ক্যাশিং করার পরও একটি প্রাইমারি রাইট স্যাচুরেট হয়ে যায়
- স্টোরেজ বৃদ্ধি ব্যাকআপ, রিস্টোর ও স্কিমা চেঞ্জকে ধীর করে তোলে
- “নইজি নেবার” ওয়ার্কলোড অনিয়মিত ল্যাটেন্সি সৃষ্টি করে
সাধারণ শার্ড কী
একটি ভাল শার্ড কী ট্র্যাফিক সমানভাবে ছড়ায় এবং বেশিরভাগ অনুরোধকে একটি শার্ডেই রাখে:
- user_id: কনজিউমার অ্যাপগুলোর জন্য সাধারণ; একটি ইউজারের ডেটা একসাথে থাকে
- tenant_id: SaaS-এর জন্য আদর্শ; কাস্টমার অনুসারে শক্ত বিচ্ছিন্নতা
- জিওগ্রাফি: ল্যাটেন্সি ও ডেটা রেসিডেন্সির জন্য ভালো, কিন্তু বড় অঞ্চলে হটস্পট তৈরি করতে পারে
বাস্তব খরচগুলো
শার্ডিং সরলতাকে বিনিময় করে স্কেলে:
- ক্রস-শার্ড কুয়েরি কঠিন হয় (সাধারণত ফ্যান-আউট + অ্যাগ্রেগেশন দিয়ে হ্যান্ডল করা হয়)
- ক্রস-শার্ড ট্রানজেকশন সীমিত; অনেক দল “ইভেন্টুয়াল কনসিস্টেন্সি” প্যাটার্নে চলে যায়
- মাইগ্রেশন ও রিব্যালেন্সিং অপারেশনালি ভারী (রেঞ্জ সরানো, রাউটিং আপডেট)
প্রতিশ্রুতিপূর্ণ ধাপ (কমিট করার আগে)
প্রথমে ক্যাশিং ও রিড রেপ্লিকা দিয়ে চাপ কমান। পরবর্তীতে সবচেয়ে ভারী টেবিল বা ওয়ার্কলোড আলাদা করুন (কখনও কখনও ফিচার বা সার্ভিস অনুযায়ী)। তারপর ধীরে ধীরে শার্ডিং-এ যান—শুরুতে এমনভাবে সেট করুন যাতে নতুন শার্ড যোগ করা যায় অকপটে, পুরো ডিজাইন একবারে বদলাতে না হয়।
স্কেলে অপারেশন: মনিটরিং, রক্ষণাবেক্ষণ, ও ইনসিডেন্ট
রিপোর্টিং-ফ্রেন্ডলি API তৈরি করুন
এমন এন্ডপয়েন্ট তৈরি করুন যা ভারী কুয়ারিগুলো প্রধান থেকে দূরে রাখে এবং পরে সহজে সামঞ্জস্য করা যায়.
ব্যস্ত প্রোডাকশনের জন্য MySQL চালানো কেবল ফিচার নয়—এটি শৃঙ্খলাবদ্ধ অপারেশন। অধিকাংশ আউটেজ নাটকীয় ব্যর্থতা থেকে শুরু হয় না—তারা ছোট সংকেত থেকে শুরু হয় যা কেউ সময়মতো জোড়ে দেয়নি।
দলগুলো বাস্তবে কি মনিটর করে
স্কেলে “বড় চার” সিগন্যালগুলো প্রাথমিকত ঝামেলা পূর্বাভাস দেয়:
- কুয়েরি ল্যাটেন্সি (p50/p95/p99): টেইল ল্যাটেন্সি গড়ের থেকে অনেক বেশি গুরুত্বপূর্ণ।
- লক ও লক ওয়েটস: স্পাইকগুলো হট রো, অনুপস্থিত ইনডেক্স বা দীর্ঘ ট্রানজেকশন নির্দেশ করে।
- রেপ্লিকেশন ল্যাগ: ল্যাগ রিড-স্কেলিংকে স্টেল read করে ফেলে এবং ফেইলোভার ভাঙতে পারে।
- ডিস্ক বৃদ্ধি ও I/O চাপ: ডিস্ক ভর্তি হওয়া, কিন্তু প্রথমে IO স্যাচুরেশন আঘাত করে।
ভালো ড্যাশবোর্ডে ট্র্যাফিক, এরর রেট, কানেকশন কনট, বাফার পুল হিট রেট ও টপ কুয়েরি কনটেক্সট দেখায়। লক্ষ্য হলো পরিবর্তন শনাক্ত করা—"নরমাল" মনে রাখার চেয়ে।
কেন স্লো কুয়েরি কেবল প্রকৃত লোডে দেখা যায়
অনেক কুয়েরি স্টেজিং-এ বা নীরব প্রোডাকশনে ভালো দেখায়। লোডে ডাটাবেস ভিন্ন আচরণ করে: ক্যাশ কাজ করা বন্ধ করে, কনকারেন্ট অনুরোধ লক কনটেনশন বাড়ায়, এবং একটু অকার্যকর কুয়েরি বেশি রিড, টেম্পোরারি টেবিল বা বিশাল সর্ট কাজ ট্রিগার করতে পারে।
এ কারণেই টিমরা স্লো কুয়েরি লগ, কুয়েরি ডাইজেস্ট এবং প্রকৃত প্রোডাকশনের হিস্টোগ্রামকে ভরসা করে—একক বেঞ্চমার্ক নয়।
সাসামান্য রক্ষণাবেক্ষণ ছাড়া বিস্ময় ছাড়া
নিরাপদ চেঞ্জ অনুশীলন লক্ষ্যমাত্রায় বোধগম্য: মাইগ্রেশন ছোট ব্যাচে চালান, সম্ভব হলে ন্যূনতম লকিং দিয়ে ইনডেক্স যোগ করুন, explain প্ল্যান যাচাই করুন, এবং রোলব্যাক বাস্তবসম্ভব রাখা (কখনও কখনও রোলব্যাক মানে "রোলআউট বন্ধ করা ও ফেইলোভার" হয়)। পরিবর্তনগুলো পরিমাপযোগ্য হওয়া উচিত: আগে/পর ল্যাটেন্সি, লক ওয়েটস, ও রেপ্লিকেশন ল্যাগ।
ইনসিডেন্ট মৌলিক: ডায়াগনোজ, মিটিগেট, প্রতিরোধ
ইনসিডেন্ট চলাকালে: প্রভাব নিশ্চিত করুন, প্রধান অপরাধী শনাক্ত করুন (একটি কুয়েরি, হোস্ট, টেবিল), তারপর মিটিগেট—ট্রাফিক থ্রটল করুন, রানঅ্যাওয়ে কুয়েরি কিল করুন, অস্থায়ী ইনডেক্স যোগ করুন, বা রিড/রাইট স্থানান্তর করুন।
পরে, যা ঘটল তা লিখে রাখুন, প্রারম্ভিক সিগন্যাল জন্য অ্যালার্ট যোগ করুন, এবং ফিক্সটিকে রিপিটেবল বানান যাতে একই ফেলিউর পরের সপ্তাহে ফিরে না আসে।
কেন আজও MySQL বিশাল সিস্টেমগুলো চালায়
MySQL অনেক আধুনিক উৎপাদন ব্যবস্থার জন্য ডিফল্ট নির্বাচন থাকার কারণ হচ্ছে এটি দৈনন্দিন অ্যাপ্লিকেশন ডেটার আকারের সঙ্গে মেলে: অনেক ছোট রিড ও রাইট, স্পষ্ট ট্রানজেকশনাল সীমানা, এবং পূর্বানুমানযোগ্য কুয়েরি। এজন্য এটি আজও OLTP-ভিত্তিক প্রোডাক্টগুলো (SaaS অ্যাপ, ই-কমার্স, মার্কেটপ্লেস, মাল্টি-টেন্যান্ট প্ল্যাটফর্ম) চালাতে উপযুক্ত—বিশেষ করে যখন আপনি ডেটা বাস্তব ব্যবসায়িক সত্তার চারপাশে মডেল করেন এবং ট্রানজেকশনগুলো ফোকাসড রাখেন।
আধুনিক MySQL “পুরনো MySQL”-এর থেকে অনেক আলাদা দেখায়
আজকের MySQL ইকোসিস্টেমে বছরের কঠিন পাঠসমূহ ভালো ডিফল্ট ও নিরাপদ অপারেশনে বেক করা আছে। বাস্তবে, টিমগুলো নির্ভর করে:
- InnoDB স্ট্যান্ডার্ড স্টোরেজ ইঞ্জিন হিসেবে, শক্তিশালী ক্র্যাশ রিকভারি ও ট্রানজেকশন গ্যারান্টি সহ
- উন্নত পারফরম্যান্স ফিচার (ভাল অপ্টিমাইজার, দ্রুত রেপ্লিকেশন অপশন, পূর্বানুমানযোগ্য কনকারেন্সি)
- অবজার্ভেবিলিটি অন করা সহজ: স্লো কুয়েরি লগ, পারফরম্যান্স স্কিমা, মেট্রিক্স এক্সপোর্টার, এবং বোতান যা আসল বটলনেক হাইলাইট করে
- স্কিমা চেঞ্জ, ব্যাকআপ, ও ফেইলোভারের চারপাশে অটোমেশন—তাই স্কেল করা নায়কের উপর নির্ভর করে না
ম্যানেজড MySQL অপারেশনাল ট্যাক্স কমায়
আজকাল অনেক কোম্পানি MySQL ম্যানেজ করা সার্ভিসে চালায়, যেখানে প্রভাইডার রুটিন কাজগুলি (প্যাচিং, অটোমেটেড ব্যাকআপ, এনক্রিপশন, পয়েন্ট-ইন-টাইম রিকভারি, এবং সাধারণ স্কেলিং ধাপ) হ্যান্ডেল করে। আপনি এখনও আপনার স্কিমা, কুয়েরি ও ডেটা অ্যাক্সেস প্যাটার্ন নিয়ন্ত্রণ করেন—কিন্তু রক্ষণাবেক্ষণ উইন্ডো ও রিকভারি ড্রিলের উপর কম সময় ব্যয় করতে হয়।
আধুনিক অ্যাপ ডেলিভারিতে এই প্যাটার্নগুলো আনা
MySQL স্কেলিং প্লেবুক এখনও প্রাসঙ্গিক থাকার একটি কারণ হলো—এটি প্রায়ই কেবল ডাটাবেস সমস্যা নয়, তা অ্যাপ আর্কিটেকচারের সমস্যা। রিড/রাইট বিভাজন, ক্যাশ কীগুলো ও ইনভ্যালিডেশন, নিরাপদ মাইগ্রেশন, এবং রোলব্যাক প্ল্যানগুলো যখন প্রোডাক্টের সাথে একসঙ্গে ডিজাইন করা হয়, তারা ইনসিডেন্টে পরে বসন্তে লাগানো নয়।
নতুন সার্ভিস বিল্ড করলে এবং এই সিদ্ধান্তগুলো আগেই এনকোড করতে চান, একটি vibe-coding ওয়ার্কফ্লো সহায়ক হতে পারে। উদাহরণস্বরূপ, Koder.ai একটি সাধারণ ভাষার স্পেস (সত্তা, ট্র্যাফিক প্রত্যাশা, কনসিস্টেন্সি চাহিদা) নিয়ে একটি অ্যাপ স্ক্যাফোল্ড জেনারেট করতে সাহায্য করতে পারে—সাধারণত React ও Go সার্ভিসের সঙ্গে—এবং ডাটা লেয়ার ডিজাইনের উপরে আপনাকে নিয়ন্ত্রণ দেয়। এর Planning Mode, স্ন্যাপশট, ও রোলব্যাক বিশেষভাবে উপকারী যখন স্কিমা ও ডিপ্লয়মেন্ট চেঞ্জে ঝুঁকি কমাতে চান।
আপনি যদি Koder.ai-এর টিয়ার (Free, Pro, Business, Enterprise) অনুসন্ধান করতে চান, দেখুন /pricing.
আজ MySQL বেছে নেবেন কবে (চাহিদা-প্রথম চেকলিস্ট)
MySQL বেছে নিন যখন আপনি চান: শক্ত ট্রানজেকশন, রিলেশনাল মডেল, পরিণত টুলিং, পূর্বানুমানযোগ্য পারফরম্যান্স, এবং বড় হায়ারিং পুল।
বিকল্প বিবেচনা করুন যখন আপনি চান: ব্যাপক রাইট ফ্যান-আউট ও নমনীয় স্কিমা (কিছু NoSQL সিস্টেম), গ্লোবালি কনসিস্টেন্ট মাল্টি-রিজিয়ন রাইট (বিশেষ ডিস্ট্রিবিউটেড ডাটাবেস), অথবা অ্যানালিটিক্স-ফার্স্ট ওয়ার্কলোড (কলামনার ওয়্যারহাউস)।
বাস্তব পাঠ: প্রয়োজন থেকে শুরু করুন (ল্যাটেন্সি, কনসিস্টেন্সি, ডেটা মডেল, বৃদ্ধির হার, টিম স্কিল), তারপর সবচেয়ে সরল সিস্টেমটি বেছে নিন যা সেগুলো পূরণ করে—এবং MySQL অনেক সময় সেটা করে।