২৬ নভে, ২০২৫·7 মিনিট
গ্রাফ ডেটাবেস সম্পর্কের ক্ষেত্রে কেন শ্রেষ্ঠ—সবকিছুর জন্য নয়
যেখানে সংযোগই প্রশ্ন চালায়, সেখানে গ্রাফ ডেটাবেস আলোকিত হয়। সেরা ব্যবহার‑কেস, ট্রেড‑অফ এবং কখন রিলেশনাল বা ডকুমেন্ট ডেটাবেস উপযুক্ত—সবই শিখুন।
যেখানে সংযোগই প্রশ্ন চালায়, সেখানে গ্রাফ ডেটাবেস আলোকিত হয়। সেরা ব্যবহার‑কেস, ট্রেড‑অফ এবং কখন রিলেশনাল বা ডকুমেন্ট ডেটাবেস উপযুক্ত—সবই শিখুন।
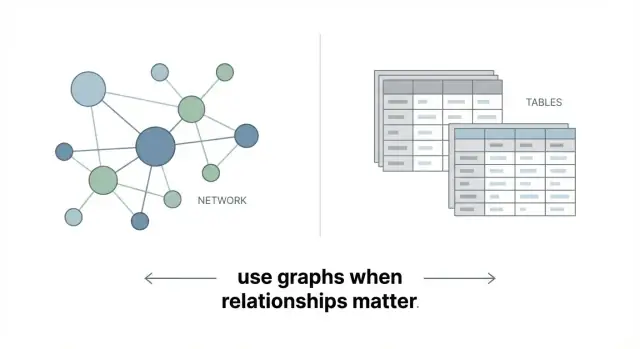
গ্রাফ ডেটাবেস ডেটাকে টেবিলের বদলে একটি নেটওয়ার্ক হিসেবে সংরক্ষণ করে। মূল ধারণাটি সহজ:
এটুকুই: গ্রাফ ডেটাবেস সংযুক্ত ডেটাকে সরাসরি উপস্থাপন করার জন্য তৈরি।
গ্রাফ ডেটাবেসে রিলেশনশিপগুলো কোনো সাইড‑নোট নয়—এগুলো বাস্তব, কুয়েরি‑যোগ্য অবজেক্ট হিসেবে স্টোর করা হয়। একটি রিলেশনশিপের নিজস্ব প্রোপার্টি থাকতে পারে (উদাহরণ: একটি PURCHASED রিলেশনশিপে date, channel, discount রাখা যেতে পারে), এবং আপনি এক নোড থেকে অন্য নোড পর্যন্ত দক্ষতার সাথে ট্রাভার্স করতে পারবেন।
এটা গুরুত্বপূর্ণ কারণ অনেক ব্যবসায়িক প্রশ্ন প্রকৃতপক্ষে পথ ও সংযোগ নিয়েই থাকে: “কে কার সঙ্গে সংযুক্ত?”, “এই এন্টিটি কত ধাপ দূরে?”, অথবা “এই দুইটির মধ্যে সাধারণ লিঙ্কগুলো কী?”
রিলেশনাল ডেটাবেসগুলো স্ট্রাকচার্ড রেকর্ডে (customers, orders, invoices) দুর্দান্ত। ওইখানে সম্পর্কও থাকে, কিন্তু সাধারণত foreign keys হিসেবে পরোক্ষভাবে প্রতিনিধিত্ব করে, এবং একাধিক হপ সংযুক্ত করতে সাধারণত অনেক টেবিলে JOIN লিখতে হয়।
গ্রাফে সংযোগগুলো ডেটার পাশেই থাকে, তাই মাল্টি‑স্টেপ সম্পর্ক অন্বেষণ মডেল ও কুয়েরি করা সহজ হয়ে যায়।
যদি রিলেশনশিপই মূল বিষয় হয়—রেকমেন্ডেশন, প্রতারণার রিং, ডিপেন্ডেন্সি ম্যাপিং, জ্ঞান গ্রাফ—তখন গ্রাফ ডেটাবেস চমৎকার। এটা স্বয়ংক্রিয়ভাবে সব কাজের জন্য ভাল বলে ধরে নেওয়া ঠিক নয়; সাধারণ রিপোর্টিং, মোট, বা খুব টেবুলার ওয়ার্কলোডের জন্য relational বা document ডেটাবেসই ভালো হতে পারে। লক্ষ্য হচ্ছে সবকিছুকে প্রতিস্থাপন নয়, বরং যেখানে কানেক্টিভিটি মান তৈরি করে সেখানে গ্রাফ ব্যবহার করা।
অধিকাংশ ব্যবসায়িক প্রশ্ন একক রেকর্ড নিয়ে নয়—বরং কীভাবে জিনিসগুলো সংযুক্ত তার উপর ভিত্তি করে।
একজন কাস্টমার কেবল একটি সারি নয়; তিনি অর্ডার, ডিভাইস, ঠিকানা, সাপোর্ট টিকিট, রেফারাল এবং কখনো কখনো অন্য কাস্টমারের সাথেও জড়িত। একটি ট্রানজেকশন কেবল একটি ইভেন্ট নয়; এটি একটি মার্চেন্ট, পেমেন্ট মেথড, লোকেশন, টাইম উইন্ডো, এবং সম্পর্কিত ক্রিয়াকলাপের একটি চেইনের সাথে সংযুক্ত। যখন প্রশ্ন হয় “কে/কী কার সঙ্গে সংযুক্ত, এবং কিভাবে?”, তখন সম্পর্কভিত্তিক ডেটাই মূল চরিত্র।
গ্রাফ ডেটাবেস ট্রাভার্সালের জন্য ডিজাইন করা: আপনি এক নোড থেকে শুরু করে এজ ফলো করে নেটওয়ার্ক “চলবেন”।
টেবিলগুলোকে বারবার JOIN করার বদলে আপনি যে পথটি চান সেটিই প্রকাশ করেন: Customer → Device → Login → IP Address → Other Customers. এই ধাপে‑ধাপে ফ্রেমিং মিলছে কিভাবে মানুষ সাধারণত প্রতারণা তদন্ত করে, ডিপেন্ডেন্সি ট্রেস করে, বা রেকমেন্ডেশন ব্যাখ্যা করে।
বৈশিষ্ট্যগত পার্থক্যটা স্পষ্ট যখন আপনাকে অনেক হপ (দুই, তিন, পাঁচ) অনুসরণ করতে হয় এবং আগেই জানা থাকে না কোথায় আগ্রহজনক সংযোগগুলো হবে।
রিলেশনাল মডেলে মাল্টি‑হপ প্রশ্নগুলো প্রায়শই দীর্ঘ JOIN চেইন ও অতিরিক্ত লজিকে রূপ নেয়—ডুপ্লিকেট এড়ানো ও পাথ লেন্থ কন্ট্রোল করতে। গ্রাফে “N হপ পর্যন্ত সব পথ খুঁজো” একটি স্বাভাবিক, পাঠযোগ্য প্যাটার্ন—বিশেষত প্রপার্টি গ্রাফ মডেলে।
এজগুলো কেবল লাইন নয়; এগুলো ডেটা বহন করতে পারে:
এসব প্রোপার্টি দিয়ে আপনি ভাল প্রশ্ন করেতে পারেন: “গত ৩০ দিনে সংযুক্ত,” “সবচেয়ে শক্তিশালী টাই,” অথবা “উচ্চ‑রিস্ক ট্রানজেকশনসহ পথ”—বাইরের লুকআপ টেবিলে সবকিছু ঢোকাতে বাধ্য না হয়ে।
যখন আপনার প্রশ্নগুলো সংযুক্ততার ওপর নির্ভর করে: “কে কার সঙ্গে যুক্ত, কিভাবে, এবং কত ধাপ দূরে?”—তখন গ্রাফ ডেটাবেস উজ্জ্বল হয়। যদি আপনার ডেটার মূল্য সম্পর্কভিত্তিক হয় (শুধু অ্যাট্রিবিউট নয়), গ্রাফ মডেলিং ও কুয়েরি করা অনেক স্বাভাবিক মনে হবে।
বন্ধু, অনুসরণকারী, সহকর্মী, টিম, রেফারাল—যেকোনো নেটওয়ার্কের মতো বিষয় নোড এবং রিলেশনশিপ‑এ সোজা করে মানচিত্র হয়। সাধারণ প্রশ্নগুলো: “মিউচুয়াল কানেকশন,” “এক ব্যক্তির কাছে সবচেয়ে সংক্ষিপ্ত পথ কী?” বা “কে এই দুই গ্রুপকে সংযুক্ত করে?”—এইগুলো অনেক JOIN টেবিলের মধ্যে জটিল বা ধীর হতে পারে।
রেকমেন্ডেশন ইঞ্জিন প্রায়শই মাল্টি‑স্টেপ কনেকশনের ওপর নির্ভর করে: user → item → category → similar items → other users। গ্রাফ ডেটাবেস “যারা X পছন্দ করেছিল তারা Y ও পছন্দ করেছে” বা “অবজেক্টগুলো শেয়ার করা অ্যাট্রিবিউট/বিহেভিয়ারের মাধ্যমে কীভাবে যুক্ত” ধরতে ভাল। সিগন্যালগুলো যদি বহুমুখী হয় এবং আপনি নতুন রিলেশনশিপ টাইপ যোগ করে যাচ্ছেন, তখন গ্রাফের সুবিধা বড় হয়।
প্রতারণা সাধারণত বিচ্ছিন্ন নয়। অ্যাকাউন্ট, ডিভাইস, ট্রানজেকশন, ফোন নম্বর, ইমেল, ঠিকানার জাল একে‑অপরকে জোড়ে দেয়। গ্রাফে রিং, পুনরাবৃত্ত প্যাটার্ন, অপ্রত্যাশিত ইন্ডাইরেক্ট লিঙ্ক (যেমন দুই “অন্যথায় অসংশ্লিষ্ট” অ্যাকাউন্ট একই ডিভাইস ব্যবহার করছে এমন একটি চেইন) খুঁজে পাওয়া সহজ।
সার্ভিস, হোস্ট, API, কল, মালিকানার ক্ষেত্রে প্রধান প্রশ্ন: “এটা বদলে গেলে কী ভেঙে যাবে?” গ্রাফ ইমপ্যাক্ট অ্যানালাইসিস, রুট‑কারণ অনুসন্ধান, এবং “ব্লাস্ট রেডিয়াস” কুয়েরি সমর্থন করে যখন সিস্টেমগুলো আন্তঃসংযুক্ত থাকে।
জ্ঞান গ্রাফ এন্টিটি (লোক, কোম্পানি, প্রোডাক্ট, ডকুমেন্ট)‑কে ফ্যাক্ট ও রেফারেন্সের সাথে যুক্ত করে। এটি সার্চ, এন্টিটি রেজল্যুশন, এবং কিভাবে একটি ফ্যাক্ট জানা গেছে (প্রোভেন্যান্স) ট্রেস করতে সাহায্য করে।
গ্রাফ ডেটাবেস জোর দিয়ে থাকে যখন প্রশ্নটি প্রকৃতই কানেকশনের ওপর: কে কার সঙ্গে যুক্ত, কোন চেইন দিয়ে, এবং কোন প্যাটার্নগুলো বারবার দেখা যায়। বারবার টেবিলে JOIN করার বদলে আপনি সরাসরি রিলেশনশিপ প্রশ্নটি জিজ্ঞাসা করেন এবং নেটওয়ার্ক বাড়লেও কুয়েরি পাঠযোগ্য থাকে।
সাধারণ প্রশ্নসমূহ:
কাস্টমার সাপোর্ট, কমপ্লায়েন্স, এবং তদন্তে এইগুলো খুব কাজে লাগে।
গ্রাফ আপনাকে প্রাকৃতিক গোষ্ঠী চিনতে দেয়:
এটি ব্যবহার করে আপনি ইউজার সেগমেন্ট করতে, প্রতারণা দলের সন্ধান করতে, বা কোন পণ্যগুলো একসাথে কেনা হয় তা বুঝতে পারেন। গ্রুপটি কিভাবে সংজ্ঞায়িত হবে তা নির্ধারণ করে—কেবল একটি কলামের ওপর নয়, কিভাবে জড়িত তা দিয়ে।
কখনো কখনো প্রশ্নটি এমন হয়: “কে সবচেয়ে গুরুত্বপূর্ণ?”—
এসব সেন্ট্রাল নোড প্রায়ই ইনফ্লুয়েন্সার, সমালোচনামূলক ইনফ্রাস্ট্রাকচার, বা মনিটর করার মতো বোটলনেক ইঙ্গিত করে।
গ্রাফ পুনরাবৃত্ত আকার‑আকৃতি খুঁজতে ভাল:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
আপনি যদি কখনো নিজে Cypher না লিখেন, এটাই দেখায় কেন গ্রাফগুলো বোঝা সহজ: কুয়েরি আপনার মাথায় থাকা ছবিটাকেই মিমিক করে।
রিলেশনাল ডেটাবেস তাদের নকশার জন্য দুর্দান্ত: ট্রানজেকশন এবং সুসংগঠিত রেকর্ড। যদি আপনার ডেটা টেবিলের মতো ফিট করে (customers, orders, invoices) এবং অধিকাংশ পুনরাবৃত্তি আইডি, ফিল্টার, অ্যাগ্রিগেট দিয়ে হয়, relational সিস্টেম সাধারণত সহজ ও নিরাপদ পছন্দ।
JOINগুলো ঠিক আছে যখন তা অল্প ও অগভীর। সমস্যা শুরু হয় যখন আপনার প্রধান প্রশ্নগুলো প্রায়ই এবং বহু JOIN চায়।
উদাহরণ:
SQL‑এ এগুলো দীর্ঘ কুয়েরি, বারবার self‑join এবং জটিল লজিকে রূপ নেয়। গভীরতা বাড়লে টিউনিং কঠিন হয়ে ওঠে।
গ্রাফ ডেটাবেস রিলেশনশিপগুলো স্পষ্টভাবে স্টোর করে, তাই বহু‑ধাপ ট্রাভার্সালই একটি স্বাভাবিক অপারেশন। টেবিলগুলোকে কুয়েরি‑টাইমে জোড়া লাগানোর বদলে আপনি কনেক্টেড নোড ও এজ ট্রাভার্স করেন।
ফলাফলতঃ:
যদি আপনার দল প্রায়ই মাল্টি‑হপ প্রশ্ন করে—“connected to,” “through,” “in the same network as,” “within N steps”—তাহলে গ্রাফ ডেটাবেস বিবেচনা করা উচিত।
আপনার মূল ওয়ার্কলোড যদি উচ্চ‑ভলিউম ট্রানজেকশন, কঠোর স্কিমা, রিপোর্টিং ও সরল JOINs নিয়ে থাকে, relational সাধারণত ডিফল্ট। অনেক বাস্তব সিস্টেম দুটোই ব্যবহার করে; দেখুন /blog/practical-architecture-graph-alongside-other-databases।
গ্রাফ ডেটাবেস তখনই উজ্জ্বল যখন রিলেশনশিপই “মেইন ইভেন্ট”। যদি আপনার অ্যাপের মূল্য ট্রাভার্সিং‑এ না থাকে (who‑knows‑who, item‑relations, paths, neighborhoods), গ্রাফ জটিলতা বাড়িয়ে খুব বেশি লাভ না দিতে পারে।
যদি অধিকাংশ অনুরোধ হয় “get user by ID,” “update profile,” “create order,” এবং প্রয়োজনীয় ডেটা এক রেকর্ডে বা কয়েকটি টেবিলে সীমাবদ্ধ থাকে, গ্রাফ প্রায়শই অপ্রয়োজনীয়। আপনি নোড ও এজ মডেল করতে, ট্রাভার্সাল টিউন করতে, এবং নতুন কুয়েরি স্টাইল শিখতে সময় ব্যয় করবেন—যেখানে রিলেশনাল পরিচিত টুলিং‑এর মাধ্যমে কাজ দ্রুত হবে।
মাসভিত্তিক রাজস্ব, অঞ্চলভিত্তিক অর্ডার, চ্যানেল অনুসারে কনভারশন রেট—এসব ধরনের ড্যাশবোর্ড সাধারণত SQL ও কলামিয়ার অ্যানালিটিক্সে ভাল মেলে। গ্রাফ ইঞ্জিন কিছু অ্যাগ্রিগেট প্রশ্ন করতে পারে, কিন্তু OLAP‑স্টাইল ওয়ার্কলোডে সেগুলো সাধারণত সবচেয়ে সহজ বা দ্রুত পথ নয়।
জটিল JOIN‑সহ কড়াকড়ি কনস্ট্রেন্ট, উন্নত ইনডেক্সিং, স্টোরড প্রোসিজার, বা স্থাপিত ACID প্যাটার্নে নির্ভরশীল হলে relational সিস্টেম প্রাকৃতিক বান্ধব। অনেক গ্রাফ ডেটাবেস ট্রানজেকশন সাপোর্ট করে, কিন্তু অপারেশনাল পরিবেশ ও ecosystem আপনার দলের পরিচিত SQL কাজের সাথে মিল নাও করতে পারে।
ডেটা যদি স্বাধীন এন্টিটিগুলোর সেট (টিকিট, ইনভয়েস, সেন্সর রিডিং) এবং কয়েকটি লিঙ্ক/সম্বন্ধ থাকে, গ্রাফ মডেল জোর করে তোলা লাগতে পারে। এই ক্ষেত্রে পরিষ্কার রিলেশনাল স্কিমা (বা ডকুমেন্ট মডেল) ফোকাস করুন, এবং ভবিষ্যতে রিলেশনশিপ‑ভিত্তিক প্রশ্ন গুরত্ব পেলে গ্রাফ বিবেচনা করুন।
একটি সহজ নিয়ম: যদি আপনার শীর্ষ কুয়েরিগুলোতে “connected,” “path,” “neighborhood,” বা “recommend” মত শব্দ থাকে না, গ্রাফ সম্ভবত প্রথম পছন্দ হওয়ার দরকার নেই।
গ্রাফ ডেটাবেস দ্রুত কানেকশন ফলো করার জন্য দুর্দান্ত—কিন্তু এই শক্তির মূল্য আছে। কমিট করার আগে বোঝা দরকার কোথায় গ্রাফ কম দক্ষ, বেশি খরচী, বা দৈনন্দিন অপারেশনে কিভাবে ভিন্ন।
গ্রাফ ডেটাবেস অনেকে ট্রাভার্সাল দ্রুত রাখতে সম্পর্কগুলো স্টোর ও ইনডেক্স করে; পরিবর্তে মেমরি ও স্টোরেজ বেশি লাগে—বিশেষ করে সাধারণ লুকআপের জন্য ইনডেক্স যোগ করলে এবং রিলেশনশিপ ডেটা সবসময় অ্যাক্সেসযোগ্য রাখলে।
আপনার ওয়ার্কলোড যদি একটি স্প্রেডশিটের মত—বড় টেবিল‑স্ক্যান, মিলিয়ন রেকর্ডে রিপোর্টিং কুয়েরি, বা ভারি অ্যাগ্রিগেট—তবে গ্রাফ ডেটাবেস একই ফল পেতে ধীর বা খরচসাপেক্ষ হতে পারে। গ্রাফ ট্রাভার্সালের জন্য অপ্টিমাইজ করা; বড় ব্যাচ‑ক্রাঞ্চিং‑এর জন্য নয়।
ব্যাকআপ, স্কেলিং, মনিটরিং অনেক সময় রিলেশনাল সিস্টেমের চেয়ে ভিন্ন। কিছু গ্রাফ প্ল্যাটফর্ম বড় মেশিনে স্কেল‑আপ করে ভালো চলে, আবার কিছু আর্কিটেকচারে স্কেল‑আউট সমর্থন করে কিন্তু কনসিস্টেন্সি, রিপ্লিকেশন ও কুয়েরি প্যাটার্ন নিয়ে সাবধানতা লাগে।
আপনার দল নতুন মডেলিং ধরন ও কুয়েরি পদ্ধতি (প্রপার্টি গ্রাফ, Cypher ইত্যাদি) শিখতে সময় লাগবে। শেখার বরাবর খরচ আছে—বিশেষত যদি mature SQL‑ভিত্তিক রিপোর্টিং ওয়ার্কফ্লো প্রতিস্থাপন করার চেষ্টা করা হয়।
ব্যবহারিক পন্থা: যেখানে সম্পর্কই প্রোডাক্ট, সেখানে গ্রাফ ব্যবহার করুন এবং রিপোর্টিং/অ্যাগ্রিগেশনের জন্য বিদ্যমান সিস্টেম রাখুন।
গ্রাফ মডেলিং ভাবার সহজ উপায়: নোড হল জিনিস, এবং এজ হল জিনিসগুলোর মধ্যে সম্পর্ক। মানুষ, অ্যাকাউন্ট, ডিভাইস, অর্ডার, প্রোডাক্ট, লোকেশন—এসব নোড। “Bought”, “logged_in_from”, “works_with”, “is_parent_of”—এসব এজ।
অনেক প্রোডাক্ট‑ফোকাসড গ্রাফ ডেটাবেস প্রপার্টি গ্রাফ মডেল ব্যবহার করে: নোড ও এজ—উভয়েই প্রোপার্টি (কী‑ভ্যালু) রাখতে পারে। উদাহরণ: একটি PURCHASED এজ‑এ date, amount, channel থাকতে পারে। এটি “বিবরণসহ সম্পর্ক” মডেল করতে স্বাভাবিক করে।
RDF জ্ঞানকে ট্রিপল হিসাবে উপস্থাপন করে: subject – predicate – object। ইন্টারঅপেরেবল ভোকাবুলারির জন্য এটি ভাল, কিন্তু প্রায়শই “রিলেশনশিপ‑বিবরণ” অতিরিক্ত নোড/ট্রিপলে ঠেলে দেয়। ব্যবহারিকভাবে, RDF আপনাকে স্ট্যান্ডার্ড ontology ও SPARQL প্যাটার্নের দিকে ঠেলে দেয়, যেখানে প্রপার্টি গ্রাফ অ্যাপ‑সেন্ট্রিক মডেলিংয়ের কাছে লাগে।
শুরুতে সিনট্যাক্স মুখস্ত করা জরুরি নয়—গুরুত্বপূর্ণ হলো গ্রাফ কুয়েরি সাধারণত পাথ ও প্যাটার্ন হিসেবে প্রকাশ পায়, টেবিল JOIN নয়।
গ্রাফগুলো সাধারণত স্কিমা‑ফ্লেক্সিবল: নতুন নোড লেবেল বা প্রোপার্টি যোগ করা মাইগ্রেশন না করেই করা যায়। কিন্তু নমনীয়তার সাথে ডিসিপ্লিন দরকার: নামকরণ কনভেনশন, বাধ্যতামূলক প্রোপার্টি (যেমন id), এবং রিলেশনশিপ টাইপের নিয়ম নির্ধারণ করুন।
অর্থবহ নাম দিন (“FRIEND_OF” বনাম “CONNECTED”)। ডিরেকশন ব্যবহারে সেমান্টিক্স স্পষ্ট করুন (উদাহরণ: FOLLOWS follower থেকে creator দিকে), এবং যখন রিলেশনশিপের নিজস্ব সত্য/ফ্যাক্ট থাকে তখন এজ‑প্রোপার্টি যোগ করুন (time, confidence, role, weight)।
একটি সমস্যা “সম্পর্ক‑চালিত” যখন কঠিন অংশ রেকর্ড সংরক্ষণ নয়—বরং কীভাবে জিনিসগুলো সংযুক্ত তা বোঝা এবং কোন পথ অনুসরণ করলে তা মান বদলে যায়।
শুরু করুন আপনার শীর্ষ ৫–১০টি প্রশ্ন সোজা ভাষায় লিখে—যেগুলো স্টেকহোল্ডার বারবার জিজ্ঞাসা করে এবং আপনার বর্তমান সিস্টেম ধীর বা অনিশ্চিতভাবে উত্তর দেয়। ভালো গ্রাফ প্রার্থী সাধারণত “connected,” “through,” “similar to,” “within N steps,” বা “who else” মত বাক্যাংশ রয়েছে।
উদাহরণ:
প্রশ্নগুলা থাকলে, বস্তুগুলো ও ক্রিয়াগুলো ম্যাপ করুন:
তারপর নির্ধারণ করুন কীকে রিলেশনশিপ হিসেবে রাখবেন এবং কীকে নোড। একটি ব্যবহারিক নীতিঃ যদি কিছুর নিজের অ্যাট্রিবিউট দরকার এবং একাধিক পক্ষের সাথে এটি যুক্ত হবে, তাকে নোড করুন (যেমন Order বা Login ইভেন্ট)।
প্রোপার্টি যোগ করুন যেগুলো ফলাফল সীমিত ও র্যাঙ্ক করতে সাহায্য করে যেন অতিরিক্ত JOIN বা পোস্ট‑প্রসেসিং না লাগাতে হয়। উচ্চমানের প্রোপার্টি: time, amount, status, channel, confidence score।
যদি আপনার প্রধান প্রশ্নগুলো মাল্টি‑স্টেপ কানেকশন এবং সেই প্রোপার্টিগুলো দ্বারা ফিল্টারিং/র্যাঙ্কিং করে, তাহলে সম্পর্ক‑চালিত সমস্যা বলে ধরে গ্রাফ উদ্দেশ্যমূলক।
অধিকাংশ দল সবকিছুই গ্রাফে বদলায় না। বাস্তবপক্ষে, আপনার সিস্টেম‑অফ‑রেকর্ড যেখানে কাজ করে সেখানে রাখুন (অften SQL), এবং সম্পর্ক‑কঠোর প্রশ্নের জন্য গ্রাফকে বিশেষ ইঞ্জিন হিসেবে ব্যবহার করুন।
রিলেশনাল ডেটাবেসে ট্রানজেকশন, কনস্ট্রেইন্ট এবং canonical entities রাখুন। তারপর প্রয়োজনে গ্রাফে একটি সম্পর্কভিত্তিক ভিউ প্রজেক্ট করুন—শুধু সেই নোড ও এজগুলো যেগুলো ট্রাভার্সাল কুয়েরির জন্য দরকার।
এটি অডিটিং ও ডেটা‑গভর্ন্যান্স সহজ রাখে এবং দ্রুত ট্রাভার্সাল কুয়েরি আনলক করে।
স্পষ্ট স্কোপড ফিচারের সাথে শুরু করুন, যেমন:\n\n- রেকমেন্ডেশন (“people who bought X also bought Y”)\n- রিস্ক স্কোরিং (ফ্রড রিং, শেয়ার করা ডিভাইস)\n- আইডেন্টিটি রেজল্যুশন (সিস্টেমগুলোর মধ্যে প্রোফাইল লিঙ্ক করা)
একটি ফিচার, একটি দল, এবং একটি পরিমিত লক্ষ্যমাত্রা নিয়ে শুরু করুন। পরে প্রমাণিত হলে প্রসারিত করুন।
যদি আপনার বোতল‑নেক প্রটোটাইপ শিপ করা হয় (মডেল নিয়ে বিতর্ক নয়), তাহলে একটি vibe‑coding প্ল্যাটফর্ম যেমন Koder.ai দ্রুত একটি গ্রাফ‑পাওয়ার্ড অ্যাপ খাড়া করতে সাহায্য করতে পারে: আপনি চ্যাটে ফিচার বর্ণনা করে React UI ও Go/PostgreSQL ব্যাকেন্ড জেনারেট করে দ্রুত ইটারেট করতে পারেন, আর আপনার ডেটা টিম গ্রাফ স্কিমা ও কুয়েরি যাচাই করে।
গ্রাফকে কতটা সতত করতে হবে?
সাধারণ প্যাটার্ন: ট্রানজেকশন SQL‑এ লিখুন → পরিবর্তন ইভেন্ট পাবলিশ করুন → গ্রাফ আপডেট করুন।
আইডি ভাসমান হলে গ্রাফ ঝামেলার মুখোমুখি হয়।\n\nস্টেবল আইডি (উদাহরণ: customer_id, account_id) সংজ্ঞায়িত করুন যা সিস্টেমগুলোর মধ্যে মিলবে, এবং কে কোন ফিল্ড/রিলেশনশিপের “মালিক” তা ডকুমেন্ট করুন। যদি দুই সিস্টেম একই এজ তৈরি করতে পারে, ঠিক করুন কোনটি জয়ী হবে।
পাইলট পরিকল্পনা দেখতে /blog/getting-started-a-low-risk-pilot-plan।
একটি গ্রাফ পাইলটকে পরীক্ষার মতো ভাবা উচিত, রিরাইট নয়। লক্ষ্য: সম্পর্ক‑ভিত্তিক কুয়েরি সহজ ও দ্রুত হচ্ছে কি না প্রমাণ করা—সার্বিক ডেটা স্ট্যাকে বড় বাজি না ধরে।
একটি সীমিত ডেটাসেট নিয়ে শুরু করুন যেটা ইতিমধ্যেই যন্ত্রণা দেয়: বেশি JOIN, ভাঙ্গা SQL, বা ধীর “কে কার সঙ্গে সংযুক্ত?” প্রশ্ন। একটিমাত্র ওয়ার্কফ্লো সীমাবদ্ধ রাখুন (উদাহরণ: customer ↔ account ↔ device অথবা user ↔ product ↔ interaction) এবং কয়েকটি কুয়েরি নির্ধারণ করুন end‑to‑end উত্তর দেওয়ার জন্য।
স্রেফ গতি নয় মাপুন:\n\n- কুয়েরি জটিলতা: এখন কতো লাইন/JOIN/ইন্টারমিডিয়েট টেবিল লাগে বনাম গ্রাফে?\n- লেটেন্সি: বাস্তব ডেটাভলিউমে রেজাল্ট ফেরত দেওয়ার সময়।\n- ডেভেলপার টাইম: প্রয়োজন পরিবর্তন হলে কুয়েরি বানাতে ও পরিবর্তন করতে কত সময় লাগে?
“আগে” সংখ্যাগুলো না থাকলে “পরে” বিশ্বাস করা মুশকিল।
সবকিছু নোড/এজ করে ফেলার ইচ্ছা আসবে—প্রতিরোধ করুন। “গ্রাফ স্প্রল”: অনেক নোড/এজ টাইপ যা কোনো স্পষ্ট কুয়েরি ছাড়া তৈরি হয়েছে—বশিষ্ট রাখুন না। প্রতিটি নতুন লেবেল বা রিলেশনশিপকে বাস্তব প্রশ্নের মাধ্যমে এর প্রয়োজন প্রমাণ করতে বলুন।
প্রাইভাসি, অ্যাক্সেস কন্ট্রোল, ডেটা রিটেনশন আগে থেকেই প্ল্যান করুন। সম্পর্ক‑ডেটা একক রেকর্ডের চাইতে বেশি প্রকাশ করতে পারে (উদাহরণ: সংযোগ এমন আচরণ নির্দেশ করে)। নির্ধারণ করুন কে কী কুয়েরি চালাতে পারবে, কীভাবে ফলাফল অডিট হবে, এবং প্রয়োজন হলে ডেটা কিভাবে মুছে ফেলা হবে।
সহজ সিঙ্ক (ব্যাচ বা স্ট্রীমিং) ব্যবহার করে গ্রাফে ফিড করুন যখন আপনার বিদ্যমান সিস্টেম সোর্স‑অফ‑ট্রুথ থাকে। পাইলট মূল্য প্রমাণ করলে ধীরে ধীরে স্কোপ বাড়ান—একটি ইউজ‑কেসে করে।
ডাটাবেস চয়েস করার সময় প্রযুক্তি দিয়ে শুরু করবেন না—প্রথমে প্রশ্নগুলো লিখুন। গ্রাফ ডেটাবেস তখনই উজ্জ্বল যখন আপনার সবচেয়ে কঠিন সমস্যা কানেকশন ও পাথ নিয়ে।
নিয়োগ করার আগে এই চেকলিস্টটি ব্যবহার করুন:
আপনি এসব প্রশ্নে অধিকাংশে “হ্যাঁ” বললে গ্রাফ ভাল ফিট—বিশেষত যখন মাল্টি‑হপ প্যাটার্ন ম্যাচিং দরকার: “দুই এন্টিটির মধ্যে সংক্ষিপ্ত পথ খুঁজো,” “কোন অ্যাকাউন্ট এই ডিভাইসের সাথে ৩ ধাপে সংযুক্ত,” “শেয়ার করা নেয়বারসের ওপর ভিত্তি করে প্রোডাক্ট সুপারিশ।”
আপনার কাজ যদি মূলত সিম্পল লুকআপ (ID/ইমেইল দ্বারা) বা অ্যাগ্রিগেট (“মাসভিত্তিক মোট বিক্রয়”) হয়, তবে রিলেশনাল বা কী‑ভ্যালু/ডকুমেন্ট স্টোর সাধারণত সহজ ও সস্তা।
আপনার শীর্ষ ১০টি ব্যবসায়িক প্রশ্ন সোজা বাক্যে লিখুন, তারপর সেগুলোকে বাস্তব ডেটায় ছোট পাইলট‑এ টেস্ট করুন। কুয়েরির সময় নিন, কোন কথা প্রকাশ করা কঠিন ছিল লিপিবদ্ধ করুন, এবং মডেলে যে পরিবর্তনগুলো লাগল তা সংক্ষিপ্ত লগ রাখুন। যদি পাইলট মূলত “আরও JOIN” বা “আরও ক্যাশিং” হয়ে যায়, তা হলে গ্রাফ সম্ভবত ব্যয়সাধ্য হবে। যদি তা সংখ্যা ও ফিল্টারের কথা হয়ে যায়, গ্রাফ দরকার নাও হতে পারে।
একটি গ্রাফ ডেটাবেস ডেটা সংরক্ষণ করে নোড (অবজেক্ট) এবং রিলেশনশিপ (সংযোগ) হিসেবে, এবং উভয়ের উপরই থাকতে পারে বিভিন্ন প্রোপার্টি। এটি এমন প্রশ্নগুলোর জন্য অপটিমাইজড—“A এবং B কীভাবে সংযুক্ত?” অথবা “কে N ধাপে পৌঁছায়?”—যার উত্তর ট্যাবুলার রিপোর্টিংয়ের চেয়ে সম্পর্ক‑অনুসন্ধানেই থাকে।
কারণ রিলেশনশিপগুলো বাস্তব, কুয়েরি‑যোগ্য অবজেক্ট হিসেবে স্টোর করা থাকে (শুধু foreign‑key নয়)। আপনি অনেক ধাপ ধরে ট্রাভার্স করতেই পারেন, এবং রিলেশনশিপের উপর আপনি প্রোপার্টি (date, amount, risk_score ইত্যাদি) রাখতে পারবেন—যা সম্পর্কভিত্তিক প্রশ্নগুলোকে সহজ করে তোলে।
রিলেশনাল ডেটাবেসে সম্পর্কগুলো সাধারণত আইডি/ফোরেন‑কি হিসেবে থাকে এবং মাল্টি‑হপ প্রশ্নগুলোতে অনেক JOIN প্রয়োজন হয়। গ্রাফ ডেটাবেসে কানেকশনগুলো ডেটার পাশে রাখে, তাই ২–৬ হপের মতো পরিবর্তনশীল‑গভীরতার ট্রাভার্সালগুলো তুলনামূলকভাবে সহজে প্রকাশ এবং রক্ষণাবেক্ষণ করা যায়।
যখন আপনার মূল প্রশ্নগুলো পাথ, নেবারহুড, এবং প্যাটার্ন নিয়ে—তখন গ্রাফ ভাল কাজ করে:
গ্রাফ‑ফ্রেন্ডলি প্রশ্নগুলোর উদাহরণ:
প্রধানত তখনই যখন আপনার ওয়ার্কলোড থাকে:
এই ক্ষেত্রে রিলেশনাল বা অ্যানালিটিক্স সিস্টেম সাধারণত সস্তা ও সহজ।
যখন সেটা দুটি এন্টিটির মধ্যে প্রধানত দুইটি বিষয়কে সংযুক্ত করে এবং রিলেশনশিপের নিজস্ব প্রোপার্টি থাকে (সময়, ভূমিকা, ওজন), তখন এটাকে edge হিসেবে মডেল করুন। কিন্তু যদি সেটা একটি ইভেন্ট বা অবজেক্ট যেটার বহুগুণ অ্যাট্রিবিউট থাকে এবং বহু পক্ষের সঙ্গে জড়িত (উদাহরণ: Order বা Login ইভেন্ট), তখন সেটিকে নোড করা ভালো।
সাধারণ ট্রেড‑অফগুলো:
প্রপার্টি‑গ্রাফে নোড ও রিলেশনশিপ—উভয়েরই প্রোপার্টি থাকে (key–value)। RDF‑এ সবকিছু ট্রিপল (subject–predicate–object) হিসেবে হয়। যদি আপনি অ্যাপ‑সেন্ট্রিক রিলেশনশিপ প্রোপার্টি চান, প্রপার্টি গ্রাফ সুবিধাজনক। যদি ইন্টারঅপেরেবল ভোকাবুলারি ও সেম্যান্টিক মডেলিং জরুরি, RDF/ SPARQL উপযুক্ত।
আপনার বিদ্যমান সিস্টেম (প্রায়শই SQL) কে source of truth হিসেবে রেখে, একটি নির্দিষ্ট ফিচারের জন্য গ্রাফ ব্যবহার করুন—উদাহরণ: রেকমেন্ডেশন, রিস্ক স্কোরিং, আইডেন্টিটি রেজল্যুশন। ব্যাচ বা স্ট্রীমিং দিয়ে সিঙ্ক করুন, স্থায়ী আইডি ব্যবহার করুন, এবং শুরুতে মাত্র একটি পরিমিত ইউজ‑কেসে মনোযোগী থাকুন। দেখুন /blog/practical-architecture-graph-alongside-other-databases এবং /blog/getting-started-a-low-risk-pilot-plan।