০২ ডিসে, ২০২৫·8 মিনিট
গুগলের দীর্ঘকালের কৌশলের পেছনে ল্যারি পেজের মূল এআই ভিশন
ল্যারি পেজের প্রাথমিক এআই ধারণা এবং জ্ঞান সম্পর্কিত ভাবনা কিভাবে গুগলের দীর্ঘমেয়াদি কৌশল গঠন করেছে—সার্চ কোয়ালিটি থেকে মুনশট ও এআই-প্রথম পিভট পর্যন্ত জানুন।
এই পোস্টে 'ল্যারি পেজের এআই ভিশন' বলতে কি বোঝানো হয়েছে
এটা কোনো একক বিপ্লবী মুহূর্ত নিয়ে উত্সাহজনক বর্ণনা নয়। এটি দীর্ঘমেয়াদি চিন্তার গল্প: কিভাবে কোনো প্রতিষ্ঠান সময়ের শুরুতেই একটি দিশা বেছে নেয়, বহু প্রযুক্তিগত পরিবর্তনের মধ্যেই বিনিয়োগ চালিয়ে যায়, এবং ধীরে ধীরে একটি বড় আইডিয়াকে প্রতিদিনের প্রোডাক্টে পরিণত করে।
যখন এই পোস্টে বলা হচ্ছে 'ল্যারি পেজের এআই ভিশন', তখন তার মানে হলো 'গুগল আজকের চ্যাটবটগুলি আগেই ভবিষ্যদ্বাণী করেছিল'—এটা সেইরকম কোনো দৃষ্টিভঙ্গি নয়। বরং সহজ ও টেকসই একটি ধারণা: অভিজ্ঞতা থেকে শিখতে পারে এমন সিস্টেম বানানো।
সাধারণ ভাষায় সংজ্ঞা
এই পোস্টে 'এআই ভিশন' কয়েকটি সংযুক্ত বিশ্বাসকে বোঝায়:
- কম্পিউটারগুলো শুধুমাত্র হাতে-লিখিত নিয়ম মেনে চলার বদলে ডেটা থেকে শেখার মাধ্যমে তাদের কর্মদক্ষতা বাড়ানো উচিত।
- সবচেয়ে ভালো সিস্টেমগুলো সময়ের সঙ্গে উন্নতি করে, কারণ বাস্তব-ব্যবহার থেকে প্রতিক্রিয়া আসে (মানুষ কী ক্লিক করে, কী উপেক্ষা করে, কীভাবে শব্দ পরিবর্তন করে)।
- শেখাকে ব্যবহারিক করতে হলে অবকাঠামো দরকার: দ্রুত কম্পিউটিং, নির্ভরযোগ্য স্টোরেজ, এবং বিশাল স্কেলে নিরাপদভাবে পরীক্ষা চালানোর উপায়।
অর্থাৎ, 'ভিশন' কোনো একক মডেলের চেয়ে বেশি একটি ইঞ্জিনের কথা—সিগন্যাল সংগ্রহ করা, প্যাটার্ন শেখা, উন্নতি রিলিজ করা, পুনরাবৃত্তি করা।
আমরা যে আর্কটি অনুসরণ করব
এই ধারণাকে বাস্তব রূপ দিতে পোস্টের বাকিটা একটি সরল প্রগতি দেখায়:
- সার্চ: একটি স্পষ্ট সমস্যা দিয়ে শুরু—মানুষকে ভালো উত্তর খুঁজে দিতে সাহায্য করা।
- ডেটা + অবকাঠামো: বাস্তব ব্যবহার থেকে জানা কী 'ভালো', এবং সেটা প্রসেস করার যন্ত্রপাতি গড়া।
- এআই-প্রথম প্রোডাক্ট: শেখার সিস্টেমকে ডিফল্ট হিসেবে দেখা, যাতে ভয়েস, ছবি এবং নতুন ইন্টারফেসগুলো বড় করে লিখতে না গিয়ে ভালো কাজ করে।
শেষ পর্যন্ত, 'ল্যারি পেজের এআই ভিশন' একটি স্লোগানের চেয়ে বেশি কৌশলবোধ হওয়া উচিত: শেখার সিস্টেমে আগাম বিনিয়োগ করা, সেগুলো খাওয়ানোর পাইপলাইন বানানো, এবং বছরের পর বছর ধৈর্য ধরে উন্নতি সংগৃহীত করা।
গুগল যে শুরুর সমস্যাটি সমাধান করতে চেয়েছিল: ভালো উত্তর খুঁজে পাওয়া
শুরুর ওয়েবে একটি সরল কিন্তু জটিল সমীকরণ ছিল: সেখানে এত বেশি তথ্য হয়ে গিয়েছিল যে কোনো মানুষ তা খতিয়ে দেখতে পারছিল না, আর বেশির ভাগ সার্চ টুল মূলত অনুমান করছিল কী গুরুত্বপূর্ণ।
আপনি যখন কোনো কুয়েরি টাইপ করতেন, অনেক ইঞ্জিন চোখে পড়া সিগন্যালের উপর নির্ভর করত—কোন শব্দটি পেজে কতবার এসেছে, শিরোনামে আছে কি না, বা সাইট মালিক কতবার এটিকে অদৃশ্য টেক্সটে ভরিয়ে দিয়েছে। তা হলে ফলাফল সহজে গেম করা যেত এবং বিশ্বাসযোগ্য হওয়া কঠিন ছিল। ওয়েব সেই টুলগুলোর তুলনায় দ্রুত বাড়ছিল।
পেজর্যাঙ্ক, একটি রিকমেন্ডেশনের মতো ব্যাখ্যা
ল্যারি পেজ ও সার্গে ব্রিনের মূল অন্তর্দৃষ্টি ছিল—ওয়েবে নিজেই একটি ভোটিং সিস্টেম আছে: লিঙ্ক।
এক পেজ থেকে অন্য পেজে লিঙ্ক একটা কাগজে উদ্ধৃতি বা বন্ধুর সুপারিশের মতো। কিন্তু সব সুপারিশ একরকম নয়। যেই পেজটি অনেকের কাছেই মূল্যবান মনে হয়, সেখান থেকে আসা লিঙ্ক অজানা পেজ থেকে আসা লিঙ্কের চেয়ে বেশি গণ্য হওয়া উচিত। পেজর্যাঙ্ক সেই ধারণাকে গাণিতিক রূপ দেয়: পেজগুলোকে কেবল নিজেদের কথার দ্বারা নয়, বরং ওয়েবের বাকি অংশ কী বলছে তার মাধ্যমে র্যাংক করা।
এটা একই সময়ে দুটো গুরুত্বপূর্ণ কাজ করে:
- এটি কর্তৃত্বপ্রাপ্ত পেজগুলোকে সামনে আনে এমনকি তারা সঠিক কুয়েরি শব্দগুলো বারবার না বললেও।
- এটি র্যাংকিংকে ম্যানিপুলেট করা কঠিন করে তোলে, কারণ বিশ্বাসযোগ্যতা পুরো সাইট নেটওয়ার্ক জুড়ে অর্জন করতে হয়।
প্রথম দিন থেকেই পরিমাপ ও পুনরাবৃত্তি কেন জরুরি ছিল
শুধু একটি চতুর র্যাংকিং আইডিয়া থাকলেই কাজ হয় না। সার্চ কোয়ালিটি একটি চলমান লক্ষ্য: নতুন পেজ আসে, স্প্যাম অভিযোজিত হয়, এবং কুয়েরির মানে বদলে যায়।
অত:পর সিস্টেমটিকে পরিমাপযোগ্য এবং আপডেটযোগ্য হতে হয়। গুগল ধারাবাহিক টেস্টিংয়ের উপর ভর করত—পরিবর্তনগুলো চেষ্টা করা, ফলাফল উন্নত হয়েছে কিনা মাপা, এবং পুনরাবৃত্তি করা। এই পুনরাবৃত্তির অভ্যাস কোম্পানির দীর্ঘমেয়াদি 'শেখার' সিস্টেম সম্পর্কে মনোভাব গঠন করে: সার্চকে একবারের প্রকৌশল প্রকল্প হিসেবে না দেখে, নিরবচ্ছিন্ন মূল্যায়নের জিনিস হিসেবে দেখা।
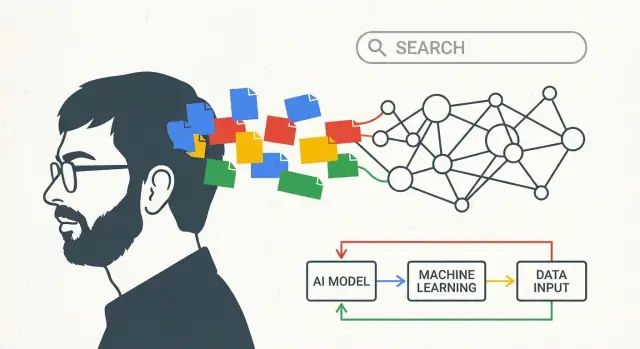
ডেটাকে ফ্লাইহুইল হিসেবে দেখা: বাস্তব-ব্যবহার থেকে শেখা
দারুণ সার্চ শুধু চতুর অ্যালগরিদম নয়—এটি সেই সিগন্যালগুলোর মান ও পরিমাণের ওপর নির্ভর করে যাতে অ্যালগরিদমগুলো শেখে।
প্রাথমিক গুগলের একটি রূপান্তরমূলক সুবিধা ছিল: ওয়েব নিজেই 'ভোট' ভর্তি। পেজগুলোর মধ্যে লিঙ্ক (পেজর্যাঙ্কের ভিত্তি) উদ্ধৃতির মতো কাজ করে, আর অ্যাঙ্কর টেক্সট ('click here' বনাম 'best hiking boots') অর্থ যোগ করে। উপরে, পৃষ্ঠাগুলোর ভাষাগত প্যাটার্ন সমার্থক শব্দ, বানান ভিন্নতা, এবং একে-ই প্রশ্ন ভিন্ন ভিন্নভাবে জিজ্ঞেস করা হয়—এসব বোঝাতে সাহায্য করে।
সংঘবদ্ধ প্রতিক্রিয়ার লুপ যা যৌগিক উন্নতি করে
একবার মানুষ বড় পরিসরে কোনো সার্চ ইঞ্জিন ব্যবহার করা শুরু করলে, ব্যবহার অতিরিক্ত সিগন্যাল তৈরি করে:
- ক্লিকগুলি দেখায় কোন ফলাফলগুলো নির্দিষ্ট কুয়েরির জন্য বাস্তবে প্রাসঙ্গিক মনে হচ্ছে।
- 'লম্বা ক্লিক' বনাম দ্রুত ফেরত-ফেরির সময় সন্তুষ্টির ইঙ্গিত দেয়।
- কুয়েরি পুনর্গঠন (ভিন্ন শব্দ নিয়ে আবার সার্চ করা) অভিপ্রায় ও ফলাফলের মধ্যে অসঙ্গতি প্রকাশ করতে পারে।
এটাই ফ্লাইহুইল: ভাল ফলাফল বেশি ব্যবহার আকর্ষণ করে; বেশি ব্যবহার সমৃদ্ধ সিগন্যাল তৈরি করে; সমৃদ্ধ সিগন্যাল র্যাংকিং ও বোঝাপড়া উন্নত করে; সেই উন্নতি আরও বেশি ব্যবহার টানে। সময়ের সঙ্গে সার্চ কেবল নিয়মের একটি সেট না হয়ে, ব্যবহারকারীরা কী কাজে লাগছে তা অনুযায়ী অভিযোজিত একটি শেখার সিস্টেমে পরিণত হয়।
কেন ডেটার বৈচিত্র্য গুরুত্বপূর্ণ
বিভিন্ন ধরনের ডেটা একে অপরকে পূরণ করে। লিঙ্ক স্ট্রাকচার কর্তৃত্ব তুলে ধরতে পারে, ক্লিক আচরণ বর্তমান পছন্দকে প্রতিফলিত করে, আর ভাষা ডেটা অস্পষ্ট কুয়েরি ('জাগুয়ার' পশু না গাড়ি) বোঝার কাজে সাহায্য করে। একসাথে, এগুলো শুধুমাত্র 'কোন পেজে এই শব্দগুলো আছে' জবাব দেয় না, বরং 'এই অভিপ্রায়ের জন্য সেরা উত্তর কী' সেটাই নির্ধারণ করে।
গোপনীয়তা সম্বন্ধে একটি নোট
এই ফ্লাইহুইল স্পষ্টতই গোপনীয়তার প্রশ্ন তোলে। পাবলিক রিপোর্টিং থেকে জানা যায় বড় কনজিউমার প্রোডাক্টগুলো বিশাল ইন্টারঅ্যাকশন ডেটা তৈরি করে, এবং কোম্পানিগুলো সঙ্গ্রহকৃত সিগন্যাল ব্যবহার করে মান বাড়ায়। গুগল সময়ের সাথে গোপনীয়তা ও সুরক্ষা নিয়ন্ত্রণে বিনিয়োগ করেছে, যদিও বিস্তারিত ও কার্যকারিতা নিয়ে বিতর্ক আছে।
টেকঅ্যাওয়ে সহজ: বাস্তব-ব্যবহার থেকে শেখা শক্তিশালী—এবং বিশ্বাস নির্ভর করে সেই শেখাকে দায়িত্বশীলভাবে কিভাবে পরিচালনা করা হয় তার ওপর।
'মেশিন' বানানো: যে অবকাঠামো এআইকে ব্যবহারিক করে তুলল
গুগল শুধু কারণ ট্রেন্ডি ছিল বলে ডিস্ট্রিবিউটেড কম্পিউটিংয়ে আগাম বিনিয়োগ করেনি—ওয়েবের বিশৃঙ্খল স্কেলের সাথে তাল মিলিয়ে চলার একমাত্র উপায় ছিল। যদি আপনি কোটি কোটি পেজ ক্রল করতে চান, র্যাংকিং বারবার আপডেট করতে চান, এবং কয়েকশত মিলিসেকেন্ডে প্রশ্নের উত্তর দিতে চান, একক বড় কম্পিউটারে নির্ভর করা যাবে না। আপনাকে হাজার হাজার সস্তা মেশিন একসঙ্গে চালাতে হবে, এমন সফটওয়্যার সহ যা ব্যর্থতাকে স্বাভাবিক হিসেবে দেখে।
কেন ডিস্ট্রিবিউটেড কম্পিউটিং এত তাড়াতাড়ি গুরুত্বপূর্ণ ছিল
সার্চ গুগলকে এমন সিস্টেম তৈরি করতে বাধ্য করে যা বিশাল পরিমাণ ডেটা নির্ভরযোগ্যভাবে সংরক্ষণ ও প্রসেস করতে পারে। সেই একই 'একাধিক কম্পিউটার, এক সিস্টেম' ধারণা পরবর্তীতে ইনডেক্সিং, অ্যানালিটিক্স, এক্সপেরিমেন্টেশন, এবং শেষ পর্যন্ত মেশিন লার্নিংয়ের ভিত্তি হয়ে ওঠে।
কী গুরুত্বপূর্ন তা হলো: অবকাঠামো আলাদা কিছু নয়—এটাই নির্ধারণ করে কোন ধরনের মডেলগুলো সম্ভব।
কিভাবে অবকাঠামো এআইকে ডেমো থেকে প্রোডাক্টে পরিণত করে
একটি ব্যবহারযোগ্য মডেল ট্রেন করতে মানে হল এটাকে প্রচুর বাস্তব উদাহরণ দেখানো। সেটি সার্ভ করতে মানে হল লক্ষ লক্ষ মানুষের জন্য তা দ্রুতভাবে চালানো, আউটেজ ছাড়া। উভয়ই 'স্কেল সমস্যা':
- ট্রেনিং-এ প্রচুর কম্পিউট দরকার ডেটা বারবার প্রক্রিয়া করার জন্য।
- সার্ভিং-এ লো-ল্যাটেন্সি সিস্টেম দরকার পূর্বানুমান দ্রুত (অften মিলিসেকেন্ডে) দেবে, এমনকি ট্রাফিক স্পাইকেও।
একবার আপনি ডেটা সংরক্ষণ, গণনা বিতরণ, পারফরম্যান্স মনিটরিং এবং নিরাপদভাবে আপডেট রোলআউট করার পাইপলাইন গড়ে তুললে, শেখাভিত্তিক সিস্টেমগুলো ধারাবাহিকভাবে উন্নতি করতে পারে; এগুলো রেয়ার, ঝুঁকিপূর্ণ রিভাইটিং নয়।
দৈনন্দিন 'প্লাম্বিং'-এ চালিত এআই-এর সহজ উদাহরণ
কয়েকটি পরিচিত ফিচার দেখায় কেন মেশিনারির গুরুত্ব ছিল:
- বানান সংশোধন: 'restarant' → 'restaurant'-এর মত প্যাটার্নগুলো লক্ষ করার জন্য বহু সার্চ ও ক্লিক থেকে শেখা দরকার, তারপর কুয়েরি সময়ে তা দ্রুত প্রয়োগ করতে হয়।
- অটোকমপ্লিট: আপনি যা টাইপ করতে যাচ্ছেন তা পূর্বানুমান করতে সমন্বিত আচরণ ও দ্রুত ইনফারেন্স প্রয়োজন—না হলে সাজেস্টশন ল্যাগ করে এবং বাজে মনে হয়।
- অনুবাদ: ভালো অনুবাদ প্রাপ্তির জন্য বড় ডেটাসেটে ট্রেনিং ও দ্রুত রান করা মডেল দরকার বিশ্বের বিভিন্ন প্রান্তে ব্যবহারকারীর জন্য।
গুগলের দীর্ঘমেয়াদি সুবিধা ছিল কেবল চতুর অ্যালগরিদম না—অপারেশনাল ইঞ্জিন গড়ে তোলা যা অ্যালগরিদমগুলোকে ইন্টারনেট স্কেলে শেখার, শিপ করার, এবং উন্নত করার সুযোগ দেয়।
নিয়ম থেকে শেখায়: কিভাবে সার্চ ধীরে ধীরে আরও 'এআই-সদৃশ' হয়ে উঠল
আপনার আউটপুটের মালিকানা নিন
পুরো পাইপলাইন নিজে নিতে প্রস্তুত হলে সোর্স কোড এক্সপোর্ট করে নিয়ন্ত্রণ রাখুন।
প্রাথমিক গুগলটা ইতিমধ্যে 'বুদ্ধিমান' লাগত, কিন্তু সেই বুদ্ধিমত্তার অনেকটা ছিল হস্তনির্মিত: লিঙ্ক বিশ্লেষণ (পেজর্যাঙ্ক), হাত-টিউন করা র্যাংকিং সিগন্যাল, এবং স্প্যামের বিরুদ্ধে অনেক হিউরিস্টিক। সময়ের সাথে মাধ্যাকর্ষ্য কেন্দ্র বদলে গেল—একদিকে স্পষ্টভাবে লেখা নিয়ম থেকে সরে এসে এমন সিস্টেমগুলোর দিকে যা ডেটা থেকে প্যাটার্ন শিখত—বিশেষত যে ব্যবহারকারীরা কী বোঝায় তা সম্পর্কে।
এমএল কিভাবে সার্চের অনুভূতি বদলে দেয়
মেশিন লার্নিং ধীরে ধীরে তিনটি বিষয় উন্নত করেছে যা প্রতিদিনের ব্যবহারকারীরা লক্ষ্য করে:
- র্যাংকিং মান: নির্দিষ্ট সূত্র দিয়ে সিগন্যাল ওজন করার বদলে, মডেলগুলো শেখে কোন সিগন্যালগুলোর সংমিশ্রণ ব্যবহারকারীদের সন্তুষ্ট করে (অ্যানোনিমাইজড এগ্রিগেট আচরণ ও মানব কুয়ালিটি রেটার ফিডব্যাক দিয়ে মাপা)।
- অভিপ্রায় বোঝা: 'jaguar speed' বা 'apple support' মতো কুয়েরিগুলোতে মডেলগুলো মানে, প্রসঙ্গ, এবং অস্পষ্টতা অনুমান করতে বাধ্য হয়। শেখাভিত্তিক সিস্টেমগুলো শব্দকে ধারণা ও সম্ভাব্য লক্ষ্যগুলোর সাথে ভালোভাবে মানচিত্রে আনতে পারে।
- স্প্যাম ও ট্রাস্ট: কন্টেন্ট ফার্ম ও ম্যালিশিয়াস এসইও যেভাবে বাড়ল, এমএল অনৈচ্ছিক লিঙ্ক প্যাটার্ন, পাতলা কন্টেন্ট, এবং অন্যান্য কৌশল চিহ্নিত করতে সাহায্য করে—উচ্চ-গুণমান ফলাফলের দিকে বৃহত্তর চাপকে সমর্থন করে।
পাঠকের জন্য একটি মাইলফলক টাইমলাইন
- 1998: পেজর্যাঙ্ক ও মূল গুগল পেপার প্রাসঙ্গিকতার ভিত্তি স্থাপন করে।
- ২০০০-এর শুরু: স্ট্যাটিস্টিক্যাল বানান সংশোধন ও কুয়েরি সাজেশন 'ডিড ইউ মীন' ও পুনর্গঠনে উন্নতি আনে।
- ২০১1: প্যান্ডা নিম্ন-মানের কন্টেন্টকে লক্ষ করে; কুয়ালিটি সিগন্যালগুলো আরও সিস্টেম্যাটিক হয়।
- 2012: পেঙ্গুইন লিঙ্ক ম্যানিপুলেশনের বিরুদ্ধে দুস্কৃত্য নিষ্প্রাণ করে, ম্যানুয়াল নিয়ম ছাড়িয়ে অ্যান্টি-স্প্যাম কাজ করে।
- 2015: র্যাঙ্কব্রেইন (learning-based ranking component) অচেনা বা অস্পষ্ট কুয়েরিগুলোর ক্ষেত্রে সহায়তা করে।
- 2018–2019: নিউরাল ম্যাচিং ও BERT ভাষা বোঝাপড়ায় শক্তিশালী উন্নতি আনে, বিশেষ করে দীর্ঘ কুয়েরি ও প্রিপজিশন-জাত সমস্যায়।
- 2021+: MUM-যুগের মাল্টি-টাস্ক মডেল ও 'হেল্পফুল কন্টেন্ট' প্রচেষ্টা অভিপ্রায় এবং উপযোগিতার দিকে আরও গভীর সংকেত টেনে আনে।
উল্লেখযোগ্য সূত্র
বিশ্বাসযোগ্যতার জন্য প্রাথমিক গবেষণা ও পাবলিক প্রোডাক্ট ব্যাখ্যার মিশ্রণ উদ্ধৃত করুন:
- গবেষণা পেপার: Brin & Page (PageRank, 1998), BERT (Devlin et al., 2018).
- অফিশিয়াল সার্চ ঘোষণা: গুগল সার্চ ব্লগ পোস্টগুলো—RankBrain, BERT, MUM, Panda/Penguin আপডেটগুলোর বিষয়ে।
- টALK/ইন্টারভিউ/ইভেন্ট: র্যাংকিং ইভলিউশনের ওপর Amit Singhal-এর ইন্টারভিউ; Sundar Pichai-এর কনফারেন্স (Google I/O); আধুনিক মাইলফলকগুলোর জন্য 'Search On' ইভেন্ট।
গবেষণা সংস্কৃতি: দীর্ঘশিগ্যা আইডিয়াকে ব্যবহারযোগ্য সিস্টেমে পরিণত করা
গুগলের দীর্ঘ কৌশল কেবল বড় আইডিয়া থাকা নয়—এটা এমন গবেষণা সংস্কৃতি দরকার যাতে একাডেমিক ধরনের কাগজগুলোকে এমন জিনিসে রূপান্তর করা যায় যা মিলিয়ন-প্রচুর মানুষ ব্যবহার করতে পারে। এর মানে কৌতূহলকে পুরস্কৃত করা, এবং প্রোটোটাইপ থেকে নির্ভরযোগ্য প্রোডাক্টে যাওয়ার পথ তৈরি করা।
'পাবলিশ' থেকে 'শিপ' পর্যন্ত
অনেকে গবেষণাকে আলাদা দ্বীপ হিসেবে দেখে। গুগল tighter লুপের জন্য চাপ দিয়েছিল: গবেষকরা সাহসী দিশা পরীক্ষা করত, ফল প্রকাশ করত, এবং প্রোডাক্ট টিমের সাথে কাজ করত যারা ল্যাটেন্সি, নির্ভরযোগ্যতা, এবং ব্যবহারকারীর বিশ্বাস নিয়ে চিন্তা করত। সেই লুপ কাজে লাগলে, একটি পেপার শেষ লাইন নয়—বরং দ্রুত ও ভাল সিস্টেম তৈরির শুরু।
এইটা প্রায়ই 'ছোট' ফিচারগুলোতে দেখা যায়: উন্নত বানান সংশোধন, স্মার্ট র্যাংকিং, উন্নত রেকমেন্ডেশন, বা অনুবাদ যা অতি-শব্দগত নয়। প্রতিটি ধাপ আলাদা মনে হতে পারে, কিন্তু একসাথে এগুলো সার্চের অনুভূতিটাই বদলে দেয়।
ছন্দকেবল প্রচেষ্টাগুলো যা পথ গড়ে দিল
কয়েকটি প্রচেষ্টা পেপার-টু-প্রোডাক্ট পাইপলাইনের প্রতীক হয়ে উঠেছে। Google Brain ডিপ লার্নিংকে প্রতিষ্ঠানের ভিতরে ঠেলে দিয়েছিল, এটা প্রমাণ করে যে পর্যাপ্ত ডেটা ও কম্পিউট থাকলে পুরানো উপায়গুলোকে ছাড়িয়ে যাওয়া যায়। পরে TensorFlow অনেক টিমকে মডেল ট্রেন ও ডিপ্লয় করতে সহজতর করে—এটি অনুপ্রাণক কিন্তু অত্যাবশ্যকীয় উপাদান ছিল মেশিন লার্নিং স্কেলে নেওয়ার জন্য।
নিউরাল মেশিন ট্রান্সলেশন, স্পিচ রিকগনিশন, এবং ভিশন সিস্টেমের উপর গবেষণাও ল্যাবের ফলাফল থেকে দৈনন্দিন অভিজ্ঞতায় এসেছিল, প্রায়ই বহু পুনরাবৃত্তির পরে মান উন্নত ও খরচ কমে।
কেন ধৈর্য গুরুত্বপূর্ণ
পারফরম্যান্সের ফলাফল সাধারণত সঙ্গে সঙ্গে আসে না। প্রাথমিক ভার্সনগুলো ব্যয়বহুল, ভুলপ্রবণ, বা ইন্টিগ্রেট করতে কঠিন হতে পারে। সুবিধা আসে তখন যখন আপনি আইডিয়ার সঙ্গে যথেষ্ট দীর্ঘ সময় তৎপর থাকেন—অবকাঠামো গড়ে তুলতে, ফিডব্যাক সংগ্রহ করতে, এবং মডেল পরিমার্জন করে নির্ভরযোগ্য করা পর্যন্ত অপেক্ষা করেন।
এই ধৈৰ্য—দীর্ঘ শটগুলিতে অর্থায়ন, বিচ্যুতি মেনে নেওয়া, এবং বছরের পর বছর পুনরাবৃত্তি—অ্যাম্বিশিয়াস এআই ধারণাগুলোকে গুগল স্কেলে মানুষের اعتمادযোগ্য ব্যবস্থায় পরিণত করতে সাহায্য করেছে।
নতুন ইনপুট: ভয়েস, ছবি, ভিডিও—এসব মডেলকে আরও বুদ্ধিমান করতে বাধ্য করে
টেক্সট সার্চে চতুর র্যাংকিং ট্রিকগুলো কাজ করত। কিন্তু গুগল যখন ভয়েস, ফটো, ও ভিডিও গ্রহণ করতে শুরু করে, পুরনো পদ্ধতি ঝুঁকিতে পড়ে। এই ইনপুটগুলো এলোমেলো: উচ্চারণ, ব্যাকগ্রাউন্ড শব্দ, ঝাপসা ছবি, কাঁপানো ফুটেজ, রীতিমত ভাষা ও প্রসঙ্গ যা লিখিত নেই। এগুলোকে কাজে লাগাতে গুগলকে ডেটা থেকে প্যাটার্ন শিখতে পারে এমন সিস্টেম দরকার পড়ল, হাতে-লিখিত নিয়ম নয়।
ভয়েস: শব্দকে অভিপ্রায়ে বদলানো
ভয়েস সার্চ ও অ্যান্ড্রয়েড ডিক্টেশনের সঙ্গে লক্ষ্য ছিল কেবল 'শব্দ ট্রান্সক্রাইব' করা নয়। এটা দ্রুত, ডিভাইসে বা দুর্বল কানেকশনে, কী বোঝানো হয়েছে তা বুঝা।
স্পিচ রিকগনিশন গুগলকে বড় স্কেল মেশিন লার্নিংয়ের দিকে ঠেলে দেয় কারণ পারফর্ম্যান্স সর্বাধিক বাড়ে যখন মডেলগুলো বিশাল, বৈচিত্র্যময় অডিও ডেটাসেটে ট্রেন হয়। সেই প্রোডাক্ট প্রতিরোধী চাপ ট্রেনিংয়ের জন্য বড় লেভেলের কম্পিউট, বিশেষাইজড টুলিং (ডেটা পাইপলাইন, ইভ্যালুয়েশন সেট), এবং এমন দক্ষ লোক নিয়োগের যৌক্তিকতা দেয় যারা মডেলগুলোকে জীবন্ত প্রোডাক্ট হিসেবে পুনরাবৃত্তি করতে পারে।
ফটো: মেটাডেটার চেয়ে অর্থ
ফটোর সাথে কীওয়ার্ড আসে না। ব্যবহারকারী প্রত্যাশা করে গুগল ফটো 'কুকুর', 'বিচ', বা 'আমার প্যারিস ভ্রমণ' খুঁজে পাবে, যদিও তারা কিছুই ট্যাগ দেয়নি।
সেই প্রত্যাশা জোরালো ইমেজ বোঝাপড়া চেয়েছে: অবজেক্ট ডিটেকশন, ফেস গ্রুপিং, এবং সাদৃশ্য অনুসন্ধান। আবারও, নিয়মগুলো বাস্তবে ঘটে যাওয়া বৈচিত্র্যকে আচ্ছাদন করতে পারে না, তাই শেখার সিস্টেমই ব্যবহারিক পথ। নির্ভুলতা বাড়াতে লেবেলড ডেটা, উন্নত ট্রেনিং অবকাঠামো, এবং দ্রুত এক্সপেরিমেন্ট সাইকেল দরকার।
ভিডিও ও রেকমেন্ডেশন: স্কেল দুর্বলতা সামনে নিয়ে আসে
ভিডিও একটি দ্বিগুণ চ্যালেঞ্জ যোগ করে: এটা সময়ের সঙ্গে ছবি এবং অডিও। ইউটিউব ব্যবহারকারীদের সাহায্য করা—সার্চ, ক্যাপশন, 'আপ নেক্সট', এবং সেফটি ফিল্টার—মডেল চায় যা বিষয় এবং ভাষা জুড়ে সাধারণকরণ করতে পারে।
রেকমেন্ডেশন মেশিন লার্নিংয়ের প্রয়োজনীয়তা আরও স্পষ্ট করল। কোটি কোটি ব্যবহারকারী ক্লিক করে, দেখে, স্কিপ করে, ফিরে আসে—সিস্টেমটিকে ধারাবাহিকভাবে অভিযোজিত হতে হবে। এমন প্রতিক্রিয়া-লুপ স্কেলে ট্রেনিং, মেট্রিক্স, এবং ট্যালেন্টে বিনিয়োগকে স্বাভাবিকভাবে পুরস্কৃত করে যাতে মডেলগুলো ভাঙ্গা ছাড়াই উন্নতি করতে পারে।
এআই-প্রথম পিভট: এআইকে একটি ফিচার না দেখে ডিফল্ট করা
টুকরো করে রিলিজ করুন
একটি ছোট রিলিজ ও দ্রুত আপডেট দিয়ে একটি স্পষ্ট ব্যবহারকারীর প্রতিশ্রুতি যাচাই করুন।
'এআই-প্রথম' ধারণা বোঝা সহজ: কোনো ফিচার হিসেবে এআই যোগ করার বদলে শিখে এমন সিস্টেমকে প্রতিটি জিনিসের ভেতরে ডিফল্ট ধরা—অর্থাৎ মানুষ ইতিমধ্যেই যেসব জিনিস ব্যবহার করে তাদের ইঞ্জিন হিসেবে।
গুগল ২০১৬–২০১৭ সময়ে এই দিকটি প্রকাশ্যে বর্ণনা করে, মোবাইল-ফার্স্ট থেকে 'এআই-ফার্স্ট' শিফট হিসেবে। ধারণা ছিল সব ফিচার হঠাৎ করে 'স্মার্ট' হবে না, বরং প্রোডাক্টগুলো উন্নতির জন্য ডিফল্টভাবে শেখার সিস্টেমকে ব্যবহার করবে—র্যাংকিং, রেকমেন্ডেশন, স্পিচ রিকগনিশন, অনুবাদ, এবং স্প্যাম ডিটেকশন—হতে হবে, হাতে তোলা নিয়ম নয়।
মূল লুপের ভিতরে এআই
প্রায়োগিকভাবে, এআই-প্রথমের উপস্থিতি তখন বোঝা যায় যখন প্রোডাক্টের 'কোর লুপ' নীরবে বদলে যায়:
- সার্চ রেজাল্ট ভালো হয় কারণ সিস্টেম কুয়েরি ও ক্লিকের প্যাটার্ন শিখে, হাজার হাজার নতুন ইফ-থেন নিয়ম কোড করার বদলে।
- ফটো গুলো তাদের ভিতরের বিষয় অনুসারে সংগঠিত হয়, কেবল ফাইলনাম বা ফোল্ডারের উপর নয়।
- জিমেইল আরও বেশি অনিচ্ছিত বার্তা ধরা দেয় বিবর্তিত আচরণ থেকে শেখে, কেবল পরিচিত কীওয়ার্ড মিল করার চেয়ে।
ব্যবহারকারী হয়তো কোথাও 'এআই' নামে কোনো বোতাম দেখবে না। তারা কেবল কম ভুল ফলাফল, কম ঘর্ষণ, এবং দ্রুত উত্তর লক্ষ্য করবে।
অ্যাসিস্ট্যান্টগুলো প্রাকৃতিক ভাষার মান বাড়িয়ে দেয়
ভয়েস অ্যাসিস্ট্যান্ট ও কথোপকথনমূলক ইন্টারফেস প্রত্যাশাকে রূপান্তর করে। যখন মানুষ বলে, 'Remind me to call Mom when I get home', তারা সফটওয়্যারকে অভিপ্রায়, প্রসঙ্গ, এবং দৈনন্দিন ভাষা বুঝতে আশা করে।
এটা প্রোডাক্টগুলোকে প্রাকৃতিক ভাষা বোঝার একটি বেসলাইন দক্ষতা হিসেবে ঠেলে দেয়—ভয়েস, টাইপিং, এমনকি ক্যামেরা ইনপুট (কিছু নির্দেশ করে ফোন ধরে এটা কি?) জুড়ে। পিভটটি মূলত নতুন ব্যবহারকারীর অভ্যাস মেটাতে এবং গবেষণা আকাঙ্ক্ষাকে চালিত করতে।
গুরুত্বপূর্ণভাবে, 'এআই-প্রথম'কে একটি দিক হিসেবে পড়া ভালো—একটি ধারনা যা বহুবারের পাবলিক বিবৃতি ও প্রোডাক্ট মুভ দ্বারা সমর্থিত—না যে এআই একেবারে অন্য সব পন্থাকে বদলে দিয়েছে একরাতে।
অ্যালফাবেট ও দীর্ঘ খেলা: সার্চের বাইরে বাজি ধরার জায়গা
২০১5 সালে অ্যালফাবেটের সৃজন ছিল কেবল রিব্র্যান্ড নয়, বরং অপারেটিং সিদ্ধান্ত: পরিণত, রাজস্ব-উত্পাদনকারী কোর (গুগল) কে ঝুঁকিভিত্তিক, দীর্ঘকালীন প্রচেষ্টাগুলো (প্রায়শই 'অথার বেটস') থেকে আলাদা করা। যদি আপনি ল্যারি পেজের এআই ভিশনকে একটি বহু-দশকীয় প্রকল্প হিসেবে দেখেন, এই গঠন গুরুত্বপূর্ণ।
কেন 'কোর' ও 'বেটস' আলাদা করা
গুগল সার্চ, অ্যাডস, ইউটিউব, এবং অ্যান্ড্রয়েডকে নিরবচ্ছিন্ন এক্সিকিউশনের দরকার ছিল: নির্ভরযোগ্যতা, খরচ নিয়ন্ত্রণ, এবং ধারাবাহিক পুনরাবৃত্তি। মুনশট—সেল্ফ-ড্রাইভিং কার, লাইফ সায়েন্স, কানেক্টিভিটি প্রকল্প—অন্য কিছুর প্রয়োজন করে: অনিশ্চয়তার সহনশীলতা, ব্যয়বহুল পরীক্ষা চালানোর জায়গা, এবং ভুল হওয়ার অনুমতি।
অ্যালফাবেটের অধীনে কোরকে পরিষ্কার কর্মদক্ষতার প্রত্যাশায় পরিচালনা করা যায়, আর বেটগুলিকে শেখার মাইলফলক অনুযায়ী মূল্যায়ন করা যায়: 'আমরা কি একটি মূল প্রযুক্তিগত অনুমান প্রমাণ করলাম?' 'বাস্তব-জগতের ডেটা থেকে মডেল কি যথেষ্ট উন্নতি পেল?' 'সমস্যাটি নিরাপদভাবে গ্রহণযোগ্য স্তরে সমাধ্যযোগ্য কি না?'
মুনশট লজিক: পরীক্ষামূলক কাজকে কৌশল হিসেবে দেখা
এই 'দীর্ঘ খেলা' মানে সব প্রকল্প সফল হবে না। এটি ধরে যে ধারাবাহিক পরীক্ষা-নিরীক্ষা জানে কী ভবিষ্যতে গুরুত্বপূর্ণ হবে।
X-এর মতো একটি মুনশট ফ্যাক্টরি একটি ভালো উদাহরণ: টিমগুলো সাহসী হাইপোথেসিস ট্রাই করে, ফলগুলো ইনস্ট্রুমেন্ট করে, এবং প্রমাণ দুর্বল হলে দ্রুত আইডিয়া বন্ধ করে দেয়। এই শৃঙ্খলা বিশেষভাবে প্রাসঙ্গিক এআই-কে নিতে—যেখানে অগ্রগতি প্রায়ই পুনরাবৃত্তির ওপর নির্ভর করে—ভাল ডেটা, উন্নত ট্রেনিং সেটআপ, এবং মূল্যায়ন নয় কেবল একক ব্রেকথ্রুর ওপর নয়।
কী নেওয়া উচিত (বচন ছাড়া)
অ্যালফাবেট ভবিষ্যতের জয়-পরাজয়ের নিশ্চয়তা ছিল না। এটি দুই ধরনের কাজের ছন্দকে আলাদা করার উপায় ছিল:
- কোর ব্যবসাকে ফোকাসড ও জবাবদিহিমূলক রাখা।
- এক্সপ্লোরেটরি কাজের জন্য স্পষ্ট বাড়ি তৈরি করা।
টিমগুলোর জন্য পাঠ হলো গঠনগত: আপনি যদি দীর্ঘমেয়াদি এআই ফলাফল চান, সেগুলোর জন্য ডিজাইন করুন। নিকট-মেয়াদি ডেলিভারিকে এক্সপ্লোরেটরি কাজ থেকে আলাদা করুন, পরীক্ষাগুলোকে শেখার যান হিসেবে তহবিল দিন, এবং অগ্রগতি মাপুন যাচাইযোগ্য অন্তর্দৃষ্টিতে—শিরোনাম নয়।
কঠিন দিকগুলো: স্কেলে গুণমান, সুরক্ষা, এবং বিশ্বাস
AI ধারণাগুলোকে মোবাইলে আনুন
চ্যাট থেকে একটি Flutter মোবাইল অ্যাপ তৈরি করুন এবং বাস্তব প্রতিক্রিয়ার ভিত্তিতে পুনরাবৃত্তি করুন।
যখন এআই সিস্টেম বিলিয়ন কুয়েরি সার্ভ করে, ছোট ভুলের হারও দৈনিক শিরোনামে পরিণত হয়। একটি মডেল যেটা 'অধিকাংশ সময় ঠিক' বলতে পারে, তবুও কোটি কোটি মানুষকে ভুল পথে নিয়ে যেতে পারে—বিশেষত স্বাস্থ্য, অর্থ, নির্বাচন বা ব্রেকিং নিউজ ক্ষেত্রে। গুগল-স্কেলে গুণমান শুধুই সুন্দর হওয়ার ব্যাপার নয়; এটি একটি যৌগিক দায়িত্ব।
মূল ট্রেডঅফগুলো
পক্ষপাত ও প্রতিনিধিত্ব। মডেলগুলো ডেটা থেকে প্যাটার্ন শেখে, যার মধ্যে সামাজিক ও ঐতিহাসিক পক্ষপাত থাকে। 'তটস্থ' র্যাংকিংও প্রধান দৃষ্টিভঙ্গিগুলোকেই শক্তিশালী করতে পারে বা সংখ্যালঘু ভাষা ও অঞ্চলে ঠিক পরিষেবা দিতে ব্যর্থ হতে পারে।
ভুল ও আত্মবিশ্বাসীতা। এআই প্রায়ই এমনভাবে ব্যর্থ হয় যা বিশ্বাসপ্রদ শোনায়। সবচেয়ে ক্ষতিকর ভুলগুলো স্পষ্ট বাগ নয়; বরং বিশ্বাসযোগ্য শোনানো উত্তরগুলো যা ব্যবহারকারীরা বিশ্বাস করে।
নিরাপত্তা বনাম উপযোগিতা। শক্তিশালী ফিল্টার ক্ষতি কমায় কিন্তু বৈধ অনুসন্ধানও ব্লক করতে পারে। দুর্বল ফিল্টার কভারেজ বাড়ায় কিন্তু স্ক্যাম, আত্মহত্যা উত্তেজনা, বা ভুল তথ্য ছড়ানোর ঝুঁকি বাড়ায়।
দায়বদ্ধতা। সিস্টেমগুলো যতটা স্বয়ংক্রিয় হয় ততই এটি জবাব দেওয়া কঠিন: কে এই আচরণ অনুমোদন করেছে? কিভাবে পরীক্ষা করা হয়েছে? ব্যবহারকারী কীভাবে আপিল বা সংশোধন করতে পারবে?
কেন স্কেল বাড়লে গার্ডরেইল প্রয়োজন বেড়ে যায়
স্কেল ক্ষমতা বাড়ায়, কিন্তু এক্ষেত্রে:
- এজ কেসগুলোর সংখ্যা বাড়ে (ভাষা, সংস্কৃতি, সংবেদনশীল প্রসঙ্গ)
- অপব্যবহারের প্রণোদনা বেড়ে যায় (স্প্যাম, প্রম্পট ইনজেকশন, প্রতিহিংসাপূর্ণ এসইও)
- একবার প্রোডাক্টগুলোর মধ্যে সম্পৃক্ত হলে ব্যর্থতা ফেরানো কঠিন হয়
এইজন্য গার্ডরেইলও স্কেলে বাড়াতে হয়: ইভ্যালুয়েশন স্যুট, রেড-টিমিং, নীতি বাস্তবায়ন, সূত্রের provenance, এবং অস্পষ্টতা নির্দেশ করে এমন ইউআই।
এআই দাবির মূল্যায়নের জন্য একটি ব্যবহারিক চেকলিস্ট
জানুন যেকোন 'এআই-পাওয়ারড' ফিচার মূল্যায়ন করতে:
- বিফলতার মোড কী? তারা কি দেখায় কোথায় এটি ভেঙে যায়, শুধু ডেমো নয়?
- কিভাবে তা মাপা হয়? বাস্তব মেট্রিক্স (সঠিকতা, টক্সিসিটি হার, হ্যালুসিনেশন হার) দেখুন, অস্পষ্ট 'উন্নতি' নয়।
- কোন ডেটায় ট্রেন করা? অন্তত: বিস্তৃত ক্যাটাগরি, সাম্প্রতিকতা, এবং বাদ দেওয়ার নীতি।
- গার্ডরেইলগুলো কী? সেফটি নিয়ম, মানব পর্যালোচনা পথ, এবং অপব্যবহার মনিটরিং।
- ব্যবহারকারী যাচাই করতে পারে? উত্স, লিঙ্ক, বা ব্যাখ্যা যা আপনাকে দাবিগুলো পরীক্ষা করতে দেয়।
- কিভাবে সংশোধন হয়? স্পষ্ট রিপোর্টিং, দ্রুত আপডেট, এবং অডিটযোগ্যতা।
বিশ্বাস পুনরাবৃত্তিপূর্ণ প্রক্রিয়ার দ্বারা অর্জিত হয়—কোনো একক ব্রেকথ্রু মডেল দ্বারা নয়।
টিমদের জন্য পাঠ: এআই সম্পর্কে দীর্ঘমেয়াদি কিভাবে চিন্তা করবেন
গুগলের দীর্ঘ আর্কের সবচেয়ে স্থানান্তরযোগ্য প্যাটার্নটি সরল: স্পষ্ট লক্ষ্য → ডেটা → অবকাঠামো → পুনরাবৃত্তি। গুগলের স্কেল না থাকলেই এই লুপটি ব্যবহার করা যায়—আপনাকে দরকার শৃঙ্খলাবদ্ধতা: আপনি কী অপ্টিমাইজ করছেন তা পরিষ্কার করা, এবং বাস্তব ব্যবহারে থেকে শেখার উপায় রাখা।
আপনি অনুকরণ করতে পারেন এমন মূল প্যাটার্ন
একটি পরিমাপযোগ্য ব্যবহারকারী প্রতিশ্রুতি (গতি, কম ভুল, ভাল মিল) দিয়ে শুরু করুন। সেটিকে ইনস্ট্রুমেন্ট করুন যাতে আপনি ফলাফল পর্যবেক্ষণ করতে পারেন। সেই ন্যূনতম 'মেশিন' তৈরি করুন যা আপনাকে ডেটা সংগ্রহ, লেবেল, এবং নিরাপদভাবে উন্নতি শিপ করতে দেয়। তারপর ছোট, ঘন পদক্ষেপে পুনরাবৃত্তি করুন—প্রতিটি রিলিজকে শেখার একটি সুযোগ হিসেবে দেখুন।
যদি আপনার জটিলতা শুধু 'আইডিয়া' থেকে 'ইনস্ট্রুমেন্টেড প্রোডাক্ট' দ্রুত তৈরির ক্ষেত্রে হয়, আধুনিক বিল্ড কর্মপ্রবাহ সহায়ক হতে পারে। উদাহরণস্বরূপ, Koder.ai একটি ভাইব-কোডিং প্ল্যাটফর্ম যেখানে টিমরা চ্যাট ইন্টারফেস থেকে ওয়েব, ব্যাকেন্ড, বা মোবাইল অ্যাপস তৈরি করতে পারে—এমভিপি দ্রুত বানাতে সহায়ক এবং প্রতিক্রিয়া লুপ (থাম্বস আপ/ডাউন, রিপোর্ট-এ-প্রবলেম, দ্রুত সার্ভে) অন্তর্ভুক্ত করে, সপ্তাহের বদলে দ্রুত। প্ল্যানিং মোড, স্ন্যাপশট/রোলব্যাকের মতো সুবিধা 'নিরাপদে পরীক্ষা করুন, মাপুন, পুনরাবৃত্তি করুন' নীতির সঙ্গে খাঁটিভাবে মানায়।
নেতারা যে ৬টি পাঠ অবলম্বন করতে পারেন (গুগল না হওয়াও চলবে)
- একটি উত্তর-পূর্ব নর্থ স্টার পছন্দ করুন। 'সার্চ অভিজ্ঞতা উন্নত করা' বলাটা 'এআই গ্রহণ করা' বলার চেয়ে স্পষ্ট। সফলতা মানুষের অনুভবে সংজ্ঞায়িত করুন।
- আপনার প্রোডাক্টটিকে শেখার ডেটা তৈরির দিকে ডিজাইন করুন। ফিডব্যাক লুপ যোগ করুন (থাম্বস আপ/ডাউন, সংশোধন, 'এটি কি সাহায্য করেছে?') যা কেবল ক্লিক নয়, অভিপ্রায় ধরবে।
- শুরুতেই প্লাম্বিংয়ে বিনিয়োগ করুন, শুধু মডেলে নয়। ডেটা কোয়ালিটি চেক, ইভ্যালুয়েশন ড্যাশবোর্ড, এবং ডিপ্লয়মেন্ট ওয়ার্কফ্লো ওয়ান-অফ প্রোটাইপের চেয়ে অধিক কার্যকর।
- ইভ্যালুয়েশনকে একটি প্রোডাক্ট ফিচার হিসেবে বিবেচনা করুন। একটি পুনরাবৃত্ত স্কোরকার্ড (কোয়ালিটি, ল্যাটেন্সি, খরচ, সেফটি) তৈরি করুন যাতে পুনরাবৃত্তি অনুমান নয়।
- স্লাইসে শিপ করুন। সংকীর্ণ ইউজ কেস দিয়ে শুরু করুন, ছোট অডিয়েন্সে রোলআউট করুন, মাপুন, তারপর প্রসারিত করুন। গতি বড়-বেংচ লঞ্চকে হারায়।
- দীর্ঘ-বাজি টিকিয়ে রাখুন। পরীক্ষার জন্য সামান্য সক্ষমতা সংরক্ষণ করুন, কিন্তু স্পষ্ট শেখার মাইলফলক চান যাতে কার্যকারি রাখা যায়।
সম্পর্কিত পড়া
প্রযোজ্য পরবর্তী ধাপগুলোর জন্য টিমের রিডিং লিস্টে এইগুলো লিঙ্ক করুন:
- /blog/ai-strategy-basics
- /blog/data-flywheels-for-product-teams
- /blog/evaluating-ml-models-without-a-phd
- /blog/ai-governance-lightweight