২১ সেপ, ২০২৫·8 মিনিট
Meilisearch: আপনার অ্যাপে তাত্ক্ষণিক সার্ভার-সাইড সার্চ
আপনার ব্যাকএন্ডে Meilisearch যোগ করে দ্রুত, টাইপো-টলারেন্ট সার্চ কিভাবে করবেন শিখুন: সেটআপ, ইনডেক্সিং, র্যাঙ্কিং, ফিল্টার, সিকিউরিটি এবং স্কেলিং-এর বেসিক।
আপনার ব্যাকএন্ডে Meilisearch যোগ করে দ্রুত, টাইপো-টলারেন্ট সার্চ কিভাবে করবেন শিখুন: সেটআপ, ইনডেক্সিং, র্যাঙ্কিং, ফিল্টার, সিকিউরিটি এবং স্কেলিং-এর বেসিক।
সার্ভার-সাইড সার্চ মানে কিওয়ারি আপনার সার্ভারে (বা একটি নিবেদিত সার্চ সার্ভিসে) প্রক্রিয়াকৃত হয়, ব্রাউজারের ভিতরে নয়। আপনার অ্যাপ একটি সার্চ অনুরোধ পাঠায়, সার্ভার সেটি একটি ইনডেক্সের বিরুদ্ধে চালায়, এবং র্যাঙ্ক করা ফলাফল ফিরিয়ে দেয়।
এটি তখনই গুরুত্বপূর্ণ যখন আপনার ডেটাসেট ক্লায়েন্টে পাঠানোর জন্য খুব বড়, যখন আপনাকে প্ল্যাটফর্ম জুড়ে সামঞ্জস্যপূর্ণ রিলেভ্যান্স চান, অথবা যখন অ্যাক্সেস কন্ট্রোল অপরিহার্য (উদাহরণ: অভ্যন্তরীণ টুল যেখানে ব্যবহারকারীরা কেবল তাদের অনুমোদিত রেকর্ডই দেখতে পারবে)। এটি সেই সময়ও ডিফল্ট পছন্দ যখন আপনি অ্যানালিটিক্স, লগিং এবং পূর্বানুমানযোগ্য পারফর্ম্যান্স চান।
মানুষ সার্চ ইঞ্জিন নিয়ে ভাবেন না—তারা অভিজ্ঞতাকে বিচার করে। একটি ভাল “তাত্ক্ষণিক” সার্চ ফ্লো সাধারণত মানে:
যদি এগুলোর কোনোটি অনুপস্থিত হয়, ব্যবহারকারীরা বিভিন্ন কিওয়ার্ড চেষ্টা করে, বেশি স্ক্রল করে, কিংবা সার্চ ছেড়ে দেয়।
এই আর্টিকেলটি Meilisearch ব্যবহার করে সেই অভিজ্ঞতা তৈরির জন্য একটি প্রায়োগিক ওয়াকথ্রু। আমরা কিভাবে এটি নিরাপদে সেটআপ করবেন, কিভাবে ইনডেক্সড ডেটা গঠন ও সিঙ্ক করবেন, কিভাবে রিলেভ্যান্স ও র্যাঙ্কিং টিউন করবেন, কিভাবে ফিল্টার/সাজানো/ফ্যাসেট যোগ করবেন, এবং কিভাবে সিকিউরিটি ও স্কেলিং নিয়ে ভাববেন যাতে আপনার অ্যাপ বাড়লেও সার্চ দ্রুত থাকে—এসব কভার করব।
Meilisearch ভাল ফিট এরকম ক্ষেত্রে:
লক্ষ্য সারাজীবন জুড়ে হল: ফলাফল যা তাত্ক্ষণিক, সঠিক এবং বিশ্বাসযোগ্য লাগে—বেশিরভাগ ক্ষেত্রে সার্চকে বড় ইঞ্জিনিয়ারিং প্রজেক্টে পরিণত না করে।
Meilisearch একটি সার্চ ইঞ্জিন যা আপনি আপনার অ্যাপের পাশে চালান। আপনি এটাকে ডকুমেন্ট পাঠান (যেমন প্রোডাক্ট, আর্টিকেল, ইউজার, বা সাপোর্ট টিকিট), এবং এটি দ্রুত সার্চের জন্য অপ্টিমাইজ করা একটি ইনডেক্স গড়ে তোলে। আপনার ব্যাকএন্ড (বা ফ্রন্টএন্ড) সহজ HTTP API মারফত Meilisearch-কে কুয়েরি করে মিলিসেকেন্ডে র্যাঙ্ক করা ফলাফল পায়।
Meilisearch আধুনিক সার্চ থেকে প্রত্যাশিত ফিচারগুলোর উপর মনোযোগ দেয়:
এটি এমন অনুভূতি দেওয়ার জন্য ডিজাইন করা হয়েছে যাতে এটি প্রতিক্রিয়াশীল ও সহনশীল লাগে, এমনকি যখন কিওয়ারি ছোট, সামান্য ভুল, বা অস্পষ্ট হয়।
Meilisearch আপনার প্রধান ডেটাবেসের বিকল্প নয়। লেখার, ট্রাঞ্জ্যাকশন এবং কনস্ট্রেইন্টের জন্য আপনার ডেটাবেসই সোর্স-অফ-ট্রুথ থাকে। Meilisearch আপনি যে ফিল্ডগুলো সার্চেবল, ফিল্টারেবল বা ডিসপ্লেয়েবল করতে চান সেগুলোর একটি কপি রাখে।
একটি ভাল মানসিক মডেল হল: ডেটাবেস ডেটা সংরক্ষণ ও আপডেট করে, Meilisearch তা দ্রুত খুঁজে দিতে সাহায্য করে।
Meilisearch অত্যন্ত দ্রুত হতে পারে, কিন্তু ফলাফল কয়েকটি বাস্তবগত ফ্যাক্টরের ওপর নির্ভর করে:
ছোট-থেকে-মাঝারি ডেটাসেটের জন্য, প্রায়ই এটি একটি একক মেশিনেই চালানো যায়। আপনার ইনডেক্স বাড়লে, আপনি কী ইনডেক্স করবেন এবং কীভাবে আপডেট রাখবেন সে সম্পর্কে আরও সাবধানে ভাববেন—এসব বিষয় পরবর্তী সেকশনে কভার করা হবে।
কিছুই ইনস্টল করার আগে, ঠিক করুন আপনি আসলে কী সার্চ করবেন। Meilisearch তখনই “তাত্ক্ষণিক” মনে হবে যখন আপনার ইনডেক্স ও ডকুমেন্টগুলি মিলবে যে ভাবে মানুষ আপনার অ্যাপ ব্রাউজ করে।
শুরুর দিকে আপনার সার্চেবল এন্টিটিগুলোর তালিকা করুন—সাধারণত products, articles, users, help docs, locations ইত্যাদি। অনেক অ্যাপে, পরিষ্কারতর পদ্ধতি হল প্রতি এন্টিটি টাইপে একটি ইনডেক্স (যেমন products, articles)। এটি র্যাঙ্কিং নিয়ম ও ফিল্টারগুলোকে ভবিষ্যদ্বাণীময় রাখে।
আপনার UX যদি এক কৌভাবে একাধিক টাইপ সার্চ করে ("সবকিছু সার্চ"), আপনি এখনও আলাদা ইনডেক্স রাখতে পারেন এবং ব্যাকএন্ডে ফলাফল মিশাতে পারেন, অথবা পরে একটি ডেডিকেটেড “গ্লোবাল” ইনডেক্স তৈরি করতে পারেন। সবকিছু এক ইনডেক্সে জোর করে ভরাট করবেন না যদি না ফিল্ডগুলো ও ফিল্টার প্রকৃতপক্ষে সামঞ্জস্যপূর্ণ।
প্রতিটি ডকুমেন্টের একটি স্থায়ী আইডেন্টিফায়ার (প্রাইমারি কী) থাকা দরকার। এমনটি নিন যা:\n\n- কখনই বা খুব কমই পরিবর্তিত হয়\n- ইনডেক্স জুড়ে অনন্য\n- ইতিমধ্যে আপনার ডেটাবেসে বিদ্যমান (যেমন id, sku, slug)\n
ডকুমেন্ট শেপের জন্য, যেখানে সম্ভব ফ্ল্যাট ফিল্ড পছন্দ করুন। ফ্ল্যাট স্ট্রাকচারগুলি ফিল্টার ও সাজানোর জন্য সহজ। নেস্টেড ফিল্ডগুলি তখনই ঠিক থাকে যখন সেগুলো একটি ঘন, অচল বাণ্ডেল উপস্থাপন করে (উদাহরণ: একটি author অবজেক্ট), কিন্তু আপনার পুরো রিলেশনাল স্কিমার অনুকরণ করে গভীর নেস্টিং এড়িয়ে চলুন—সার্চ ডকুমেন্টগুলো হওয়া উচিত রিড-অপ্টিমাইজড, না ডেটাবেস-আকৃতির।
ডকুমেন্ট ডিজাইন করার একটি ব্যবহারিক পথ হল প্রতিটি ফিল্ডকে একটি ভূমিকা দিয়ে চিহ্নিত করা:\n\n- Searchable: ব্যবহারকারীরা যে টেক্সট টাইপ করে (title, name, description)\n- Filterable: কনস্ট্রেইন্ট হিসেবে ব্যবহার করা হয় (category, price range, status, tags)\n- Displayed: UI-তে যা ফেরত দেয়া হবে (title, thumbnail URL, short snippet)\n এটি একটি সাধারণ ভুল ঠেকায়: একটি ফিল্ড “সম্ভবত লাগতে পারে” বলে ইনডেক্স করা এবং পরে আশ্চর্য হয়ে ভাবা কেন ফলাফল শব্দজিৎ বা ফিল্টারগুলো ধীর হচ্ছে।
“ভাষা” আপনার ডেটায় বিভিন্ন অর্থ বহন করতে পারে:\n\n- ডকুমেন্টের ভাষা (lang: "en" প্রতিটি আর্টিকেলে)\n- ব্যবহারকারীর লোকেল (UI ভাষা)\n- মিশ্র-ভাষিক ফিল্ড (প্রোডাক্টের নাম একাধিক ভাষায়)\n
শুরুর দিকে সিদ্ধান্ত নিন আপনি কি প্রতি ভাষায় আলাদা ইনডেক্স ব্যবহার করবেন (সরল এবং পূর্বনির্দেশযোগ্য) বা একক ইনডেক্সে ভাষা ফিল্ড রাখবেন (কম ইনডেক্স, বেশি লজিক)। সঠিক উত্তর নির্ভর করে ব্যবহারকারী সাধারণত এক ভাষায় সার্চ করে কিনা এবং আপনি কীভাবে অনুবাদ সংরক্ষণ করেন তার ওপর।
Meilisearch চালানো সরল, কিন্তু “ডিফল্টভাবে নিরাপদ” করার জন্য কয়েকটি বিবেচনা দরকার: কোথায় ডেপ্লয় করবেন, কীভাবে ডেটা প্রিজার্ভ করবেন, এবং মাস্টার কী কীভাবে হ্যান্ডেল করবেন।
স্টোরেজ: Meilisearch তার ইনডেক্স ডিস্কে লেখে। ডেটা ডিরেক্টরিটি নির্ভরযোগ্য, স্থায়ী স্টোরেজে রাখুন (এফেমেরাল কনটেইনার স্টোরেজ নয়)। বৃদ্ধির জন্য সক্ষমতা পরিকল্পনা করুন: বড় টেক্সট ফিল্ড ও বহু অ্যাট্রিবিউট থাকতে ইনডেক্স দ্রুত বাড়তে পারে।
মেমরি: লোডের অধীনে সার্চ প্রতিক্রিয়াশীল রাখতে পর্যাপ্ত RAM বরাদ্দ করুন। যদি সোয়াপ দেখা যায়, পারফর্ম্যান্স ক্ষতিগ্রস্ত হবে।
ব্যাকআপ: Meilisearch ডেটা ডিরেক্টরির ব্যাকআপ নিন (অথবা স্টোরেজ লেয়ারে স্ন্যাপশট ব্যবহার করুন)। অন্তত একবার রিস্টোর টেস্ট করুন; একটি ব্যাকআপ যা আপনি রিস্টোর করতে পারেন না তবেই শুধু একটা ফাইল।
মনিটরিং: CPU, RAM, ডিস্ক ব্যবহার এবং ডিস্ক I/O ট্র্যাক করুন। প্রক্রিয়া হেলথ এবং লগ এরর মনিটর করুন। ন্যূনতম: সার্ভিস বন্ধ হওয়া বা ডিস্ক স্পেস কমে গেলে অ্যালার্ট রাখুন।
লোকাল ডেভেলপমেন্ট ছাড়া সবকিছুর জন্য সর্বদা Meilisearch মাস্টার কী ব্যবহার করুন। এটিকে সিক্রেট ম্যানেজার বা এনক্রিপ্টেড পরিবেশ ভ্যারিয়েবল স্টোরে রাখুন (Git-এ নয়, plain-text .env-এ কমিট করবেন না)।
উদাহরণ (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
নেটওয়ার্ক নিয়মও বিবেচনা করুন: একটি প্রাইভেট ইন্টারফেসে বান্ড করুন বা ইনবাউন্ড অ্যাক্সেস সীমাবদ্ধ করুন যাতে কেবল আপনার ব্যাকএন্ড Meilisearch-এ পৌঁছাতে পারে।
curl -s http://localhost:7700/version
Meilisearch ইনডেক্সিং অ্যাসিঙ্ক্রোনাস: আপনি ডকুমেন্ট পাঠান, Meilisearch একটি টাস্ক কিউ করে, এবং টাস্ক সফল হওয়ার পরে ডকুমেন্টগুলো সার্চযোগ্য হয়। ইনডেক্সিংকে একটি জব সিস্টেম হিসাবে বিবেচনা করুন, একক অনুরোধ হিসেবে নয়।
id)।curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
taskUid থাকে। এটি succeeded (অথবা failed) না হওয়া পর্যন্ত পোল করুন।curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
যদি কাউন্ট মিল না করে, অনুমান করবেন না—প্রথমে টাস্ক এরর ডিটেইল দেখুন।
ব্যাচিং এমনভাবে করা উচিত যাতে টাস্কগুলো পূর্বানুমানযোগ্য ও রিকভারে সহজ হয়।
addDocuments একটি আপসার্ট হিসেবে কাজ করে: একই প্রাইমারি কী সহ ডকুমেন্টগুলো আপডেট হয়, নতুনগুলো ইনসার্ট হয়। এটা সাধারণ আপডেটে ব্যবহার করুন।
নিচেরগুলি হলে পূর্ণ রিইনডেক্স করুন:\n\n- ডকুমেন্টের শেপ উল্লেখযোগ্যভাবে বদলে গেলে,\n- আপনাকে ডেরাইভড ফিল্ডগুলো পুনঃনির্মাণ করতে হবে,\n- আপনার সিঙ্ক ড্রিফট হয়েছে এবং আপনি একটি ক্লিন রিসেট চান।
রিমুভালের জন্য, স্পষ্টভাবে deleteDocument(s) কল করুন; অন্যথায় পুরনো রেকর্ডগুলো লিঙ্গার করতে পারে।
ইন্ডেক্সিং রিট্রায়েবল হওয়া উচিত। কী জিনিস গুরুত্বপূর্ণ তা হলো স্থিতিশীল ডকুমেন্ট আইডি।
taskUid আপনার ব্যাচ/জব আইডির সাথে সংরক্ষণ করুন, এবং টাস্ক স্ট্যাটাসের উপর ভিত্তি করে রিট্রাই করুন।প্রোডাকশনের আগে, একটি ছোট ডেটাসেট (২০০–৫০০ আইটেম) ইনডেক্স করুন যা আপনার বাস্তব ফিল্ডগুলোর সাথে মেলে। উদাহরণ: একটি products সেট id, name, description, category, brand, price, inStock, createdAt ফিল্ড সহ। এটি টাস্ক ফ্লো, কাউন্ট, এবং আপডেট/ডিলিট আচরণ যাচাই করার জন্য যথেষ্ট—ভারি ইম্পোর্টের অপেক্ষা না করেই।
সার্চ “রিলেভ্যান্স” শুধু: কি আগে দেখায়, এবং কেন। Meilisearch এটাকে অ্যাডজাস্টেবল করে তোলে যাতে আপনাকে নিজে থেকে একটি স্কোরিং সিস্টেম বানাতে না হয়।
দুটি সেটিংস নির্ধারণ করে Meilisearch কী করতে পারে:
searchableAttributes: কোন ফিল্ডে Meilisearch কুয়েরি খোঁজে (উদাহরণ: title, summary, tags)। অর্ডার গুরুত্বপূর্ণ: আগে থাকা ফিল্ডগুলোকে বেশি গুরুত্ব দেয়া হয়।displayedAttributes: রেসপন্সে কোন ফিল্ডগুলো ফেরত দেয়া হবে। এটি প্রাইভেসি ও পে-লোড সাইজের জন্য গুরুত্বপূর্ণ—যদি একটি ফিল্ড ডিসপ্লেয়েবল না থাকে, তা ফেরত পাঠানো হবে না।একটি প্রায়োগিক বেসলাইন হল কয়েকটি হাই-সিগন্যাল ফিল্ড সার্চেবল করা (title, key text), এবং ডিসপ্লেয়েবল ফিল্ডগুলো UI-র প্রয়োজনীয়তায় সীমাবদ্ধ রাখা।
Meilisearch মিলিং ডকুমেন্টগুলিকে র্যাঙ্কিং নিয়ম দিয়ে সাজায়—এগুলো “টাই-ব্রেকার” পাইলাইন। ধারণাগতভাবে, এটি পছন্দ করে:\n\n1) কিউয়ারির সাথে ভালভাবে মেলানো রেজাল্ট (টাইপো টলার্যান্স সহ), তারপর\n2) যেখানে ম্যাচগুলো শক্ত—নীকট শব্দ, গুরুত্বপূর্ণ অ্যাট্রিবিউটে ম্যাচ—এগুলোকে উপরের দিকে রাখে, তারপর\n3) আপনার ব্যবসায়িক লজিক (রিসেন্সি বা জনপ্রিয়তার মতো কাস্টম সাজানো) ফিট করে এমন রেজাল্ট।
আপনাকে অন্তরঙ্গভাবে মেমোরাইজ করতে হবে না টিউন করতে; আপনি প্রধানত নির্ধারণ করবেন কোন ফিল্ডগুলো বেশি গুরুত্বপূর্ণ এবং কখন কাস্টম সাজানো প্রয়োগ করবেন।
লক্ষ্য: “টাইটেল ম্যাচগুলোকে প্রাধান্য দিন।” title-কে প্রথমে রাখুন:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
লক্ষ্য: “নতুন কনটেন্ট আগে দেখুক।” একটি সার্ট রুল যোগ করুন এবং কিওয়ারি টাইমে সাজান (অথবা কাস্টম র্যাঙ্কিং সেট করুন):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
তখন অনুরোধ করুন:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
লক্ষ্য: “জনপ্রিয় আইটেমগুলোকে বাড়াও।” popularity-কে sortable করে রাখুন এবং প্রয়োজনে সেটি দিয়ে সাজান।
ব্যবহারকারীরা যেসব কিওয়ার্ড টাইপ করে সেগুলো থেকে 5–10টি নিন। পরিবর্তনের আগে টপ ফলাফলগুলো সংরক্ষণ করুন, তারপর পরে তুলনা করুন।
উদাহরণ:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerযদি “পরে” তালিকা ব্যবহারকারীর ইরাদার সাথে বেশি মেলে, সেটিংস রাখুন। যদি এর্জ কেসে খারাপ হয়, একসময় একটিমাত্র পরিবর্তন করুন (প্রথমে অ্যাট্রিবিউট অর্ডার, পরে সাজানোর নিয়ম) যাতে আপনি জানেন কোন পরিবর্তন উন্নতি আনছে।
একটি ভাল সার্চ বক্স কেবল “শব্দ টাইপ করুন, মিল পেয়েছেন” নয়। মানুষ ফলাফল সংকুচিত করতে চায় (“কেবল প্রাপ্য আইটেম”), এবং সাজাতে চায় (“সবচেয়ে সস্তা প্রথম”)। Meilisearch-এ আপনি এটা করেন ফিল্টার, সাজানো, এবং ফ্যাসেট দিয়ে।
ফিল্টার হল একটি নিয়ম যা আপনি রেজাল্ট সেটে প্রয়োগ করেন। ফ্যাসেট হল UI-তে যা দেখান যাতে ব্যবহারকারীরা সেই নিয়মগুলো গঠন করতে পারে (প্রায়শই চেকবক্স বা কাউন্ট হিসেবে)।
অ-টেকনিক্যাল উদাহরণ:
তাই একজন ব্যবহারকারী “running” সার্চ করতে পারেন এবং তারপর category = Shoes এবং status = in_stock দিয়ে ফিল্টার করতে পারেন। ফ্যাসেটগুলো কাউন্ট দেখাতে পারে যেমন “Shoes (128)” এবং “Jackets (42)” যাতে ব্যবহারকারীরা উপলব্ধতা বুঝতে পারেন।
Meilisearch-এ যে ফিল্ডগুলো ফিল্টার বা সাজানোর জন্য ব্যবহার হবে সেগুলো আপনি স্পষ্টভাবে অনুমতি দিতে হবে।
category, status, brand, price, created_at (যদি আপনি সময় দিয়ে ফিল্টার করেন), tenant_id (যদি আপনি গ্রাহক আলাদা করেন)।price, rating, created_at, popularity।এই তালিকাটি সংকীর্ণ রাখুন। সবকিছু ফিল্টারেবল/সোর্টেবল করে দিলে ইনডেক্স সাইজ বাড়ে এবং আপডেট ধীর হতে পারে।
আপনি যদি 50,000 ম্যাচ পেয়ে থাকেন, ব্যবহারকারী কেবল প্রথম পেজই দেখেন। ছোট পেজ ব্যবহার করুন (প্রায়ই 20–50 রেজাল্ট), limit-এ যুক্তিসঙ্গত মান সেট করুন, এবং offset দিয়ে পেজিনেট করুন (অথবা আপনি নতুন পেজিনেশন ফিচার ব্যবহার করতে পারেন)। আপনার অ্যাপে সর্বোচ্চ পেজ গভীরতা ক্যাপ দিন যাতে খরচী “পেজ 400” অনুরোধ এড়ানো যায়।
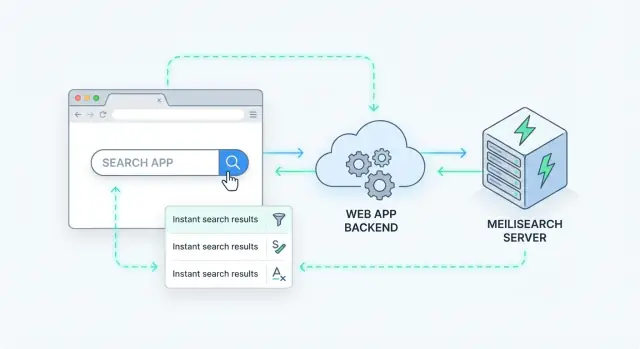
সার্ভার-সাইড সার্চ যোগ করার একটি পরিষ্কার উপায় হল Meilisearch-কে একটি বিশেষায়িত ডাটা সার্ভিস হিসাবে ট্রিট করা যা আপনার API পেছনে থাকে। আপনার অ্যাপ একটি সার্চ অনুরোধ পায়, Meilisearch-কে কল করে, তারপর ক্লায়েন্টকে কিউরেট করা রেসপন্স ফিরিয়ে দেয়।
অধিকাংশ টিম নিচের মতো ফ্লো পায়:
GET /api/search?q=wireless+headphones&limit=20).এই প্যাটার্নটি Meilisearch-কে প্রতিস্থাপনযোগ্য রাখে এবং ফ্রন্টএন্ড কোডকে ইনডেক্স ইন্টার্নাল-এ নির্ভরশীল হওয়া থেকে রোধ করে।
যদি আপনি একটি নতুন অ্যাপ বানান (অথবা একজন অভ্যন্তরীণ টুল পুনর্নির্মাণ করছেন) এবং দ্রুত এই প্যাটার্নটি ইমপ্লিমেন্ট করতে চান, একটি ভিব-কোডিং প্ল্যাটফর্ম যেমন Koder.ai দ্রুত রিয়্যাক্ট UI, একটি Go ব্যাকএন্ড, এবং PostgreSQL সহ পুরো ফ্লো স্ক্যাফোল্ড করতে সাহায্য করতে পারে—তারপর Meilisearch-কে একটি একক /api/search এন্ডপয়েন্টের পেছনে ইন্টিগ্রেট করে ক্লায়েন্টকে সরল রাখা এবং পারমিশন সার্ভার-সাইডে রাখা যায়।
Meilisearch ক্লায়েন্ট-সাইড কুয়েরিকে সমর্থন করে, কিন্তু ব্যাকএন্ড কুয়েরি সাধারণত নিরাপদ কারণ:\n\n- সিক্রেট গোপন থাকে: আপনি রক্ষা পান উচ্চ-অধিকার API কী ফাঁস হওয়ার ঝুঁকি থেকে।\n- অথরাইজেশন অক্ষণীয়: আপনার ব্যাকএন্ড নিশ্চিত করতে পারে “এই ব্যবহারকারী কি দেখতে পারবে” সেটা রিটার্নের আগে প্রয়োগ করে।\n- আপনি কুয়েরির জটিলতা নিয়ন্ত্রণ করেন: সীমাবদ্ধ ফিল্টার, সাজানো অপশন, এবং পেজিনেশন রাখুন যাতে পারফর্ম্যান্স সুরক্ষিত থাকে।
পাবলিক ডেটার জন্য সীমিত কী দিয়ে ক্লায়েন্ট-সাইড কুয়েরি কাজ করতে পারে, কিন্তু যদি আপনার কাছে কোনো ব্যবহারকারী-নির্দিষ্ট ভিজিবিলিটি নিয়ম থাকে, সার্চ অবশ্যই আপনার সার্ভারের মধ্য দিয়ে রুট করুন।
সার্চ ট্র্যাফিক প্রায়ই পুনরাবৃত্তি হয় (“iphone case”, “return policy”)। আপনার API লেয়ারে ক্যাশিং যোগ করুন:\n\n- অ্যানোনিমাস ট্রাফিকের জন্য ছোট সময়ের জন্য (উদাহরণ: 10–60 সেকেন্ড) সম্পূর্ণ রেসপন্স ক্যাশ করুন।\n- ক্যাশ কী নরমালাইজ করুন (স্পেস ট্রিম করুন, ছোট হাতের বানান, ফিল্টার/সাজানো অন্তর্ভুক্ত করুন)।\n- ইনভ্যালিডেট সাবধানে: দ্রুত পরিবর্তনশীল ইনডেক্সের জন্য TTL ছোট রাখুন, বদলে পুড়ে-অপ্স করার চেয়ে।
সার্চকে পাবলিক-ফেসিং এন্ডপয়েন্ট হিসেবে বিবেচনা করুন:\n\n- প্রতি-IP বা প্রতি-ইউজার রেট লিমিট প্রয়োগ করুন।\n- সর্বোচ্চ limit এবং সর্বোচ্চ কিওয়ারি দৈর্ঘ্য সেট করুন।\n- বাস্তব ব্যবহারকারীদের জন্য অনুমতি রেখে স্পষ্ট বটগুলোকে সফট-ব্লক বিবেচনা করুন।
Meilisearch প্রায়ই আপনার অ্যাপের "পিছনে" রাখা হয় কারণ এটি ব্যবসায়িক সংবেদনশীল ডেটা দ্রুত ফেরত দিতে পারে। এটিকে একটি ডেটাবেসের মতো লক করুন, এবং কেবল প্রত্যেক কলারের দেখার অধিকার অনুযায়ী যা ফেরত দেওয়া উচিত তা খুলে দিন।
Meilisearch-এর একটি মাস্টার কী আছে যা সবকিছু করতে পারে: ইনডেক্স তৈরি/মুছা, সেটিংস আপডেট করা, এবং ডকুমেন্ট পড়া/লেখা। এটাকে সার্ভার-ওনলি রাখুন।
অ্যাপ্লিকেশনের জন্য সীমিত কার্য এবং সীমিত ইনডেক্স সহ API কী জেনারেট করুন। একটি সাধারণ প্যাটার্ন:\n\n- ব্যাকএন্ড জবস: এমন একটি কী যা ডকুমেন্ট লিখতে ও সেটিংস আপডেট করতে পারে, কিন্তু নির্দিষ্ট ইনডেক্সগুলোর মধ্যে সীমাবদ্ধ।\n- অ্যাপ সার্ভার: সার্চ জন্য রিড-অনলি কী।\n- ক্লায়েন্ট (যদি আবশ্যক): একটি অত্যন্ত স্কোপড সার্চ-ওনলি কী কড়া ফিল্টার সহ।\n\nন্যূনতম অধিকার মানে একটি ফাঁস হওয়া কী ডিলেট করা বা অনান্য ইনডেক্স পড়ার ক্ষমতা না রাখে।
আপনি যদি একাধিক কাস্টমার (টেন্যান্ট) সার্ভ করুন, আপনার কাছে দুটি প্রধান অপশন আছে:\n\n1) প্রতিটি টেন্যান্টের জন্য একটি ইনডেক্স।\n\nবুঝতে সহজ এবং ক্রস-টেন্যান্ট অ্যাক্সেসের ঝুঁকি কমায়। কনস: আরও ইনডেক্স পরিচালনা করতে হবে, এবং সেটিংস আপডেট কনসিস্টেন্টভাবে প্রয়োগ করতে হবে।\n\n2) শেয়ার্ড ইনডেক্স + tenant filter।\n\nপ্রতিটি ডকুমেন্টে একটি tenantId ফিল্ড রাখুন এবং সমস্ত সার্চে tenantId = "t_123" ফিল্টার প্রয়োগ করুন। এটি ভালভাবে স্কেল করতে পারে, কিন্তু নিশ্চিত করতে হবে যে প্রতিটি অনুরোধে সবসময় ফিল্টার প্রয়োগ হয় (আদর্শভাবে একটি স্কোপড কী এর মাধ্যমে যাতে কলার সেটি সরাতে না পারে)।
যদিও সার্চ সঠিক, ফলাফলগুলি এমন ফিল্ড লিক করতে পারে যা আপনি দেখাতে চাননি (ইমেইল, অন্তর্নিহিত নোট, কস্ট প্রাইস)। কী ফেরত দেওয়া যাবে তা কনফিগার করুন:\n\n- displayed/retrievable attributes কে নিরাপদ আলাউলিস্টে সীমাবদ্ধ করুন।\n- সংবেদনশীল ফিল্ডগুলি কেবলমাত্র ইনডেক্স করা থাকলে খুব জরুরি হলে রাখুন—এবং সেগুলো কখনই রিটার্ন করবেন না।
একটি দ্রুত “ওয়্যার্স্ট-কেস” টেস্ট করুন: একটি সাধারণ টার্ম সার্চ করে নিশ্চিত করুন কোনও প্রাইভেট ফিল্ড দেখা যায় না।
আপনি যদি নিশ্চিত না হন কোন কী ক্লায়েন্ট-সাইড হওয়া উচিত, ধরে নিন “না” এবং সার্চ সার্ভার-সাইডে রাখুন।
Meilisearch দ্রুত থাকে যখন আপনি দুইটি ওয়ার্কলোড মাথায় রাখেন: ইন্ডেক্সিং (লিখন) এবং সার্চ কিওয়ারিজ (রিড)। বেশিরভাগ “অজানা ধীরতা” হল এইগুলোর কোনো একটি CPU, RAM, বা ডিস্ক ভাগ করে নিচ্ছে।
ইন্ডেক্সিং লোড বাড়ে যখন আপনি বড় ব্যাচ ইম্পোর্ট করেন, ঘন ঘন আপডেট চালান, বা অনেক সার্চেবল ফিল্ড যোগ করেন। ইন্ডেক্সিং ব্যাকগ্রাউন্ড টাস্ক হলেও এটি CPU ও ডিস্ক ব্যান্ডউইথ ব্যবহার করে। যদি আপনার টাস্ক কিউ বাড়ে, সার্চ ধীর হওয়া শুরু করতে পারে এমনকি কিউয়ারি ভলিউম অপরিবর্তিত থাকলেও।
কিউয়ারি লোড ট্রাফিক বাড়ার সঙ্গে বাড়ে, কিন্তু ফিচারগুলোর কারণে (বেশি ফিল্টার, ফ্যাসেট, বড় রেজাল্ট সেট, টাইপো টলার্যান্স) প্রতি অনুরোধে কাজ বাড়লে ক্লিয়ার বেড়ে যায়।
ডিস্ক I/O বহু সময় চুপচাপ ভিলেন। ধীর ডিস্ক (অথবা শেয়ার্ড ভলিউমে নয়েজি নেবর্স) “তাত্ক্ষণিক” কে “অবশেষে” বানিয়ে দিতে পারে। NVMe/SSD স্টোরেজ প্রোডাকশনের সাধারণ বেসলাইন।
সহজ সাইজিং দিয়ে শুরু করুন: Meilisearch-কে যথেষ্ট RAM দিন যাতে ইনডেক্স হট থাকে এবং যথেষ্ট CPU দিন চূড়ান্ত QPS হ্যান্ডেল করতে। তারপর বিষয়গুলো আলাদা করুন:\n\n- যদি ইনডেক্সিং পড়ার সাথে হস্তক্ষেপ করে, বড় ইম্পোর্টগুলো অফ-পিক সময়ে চালান এবং অনেক ছোট আপডেটের বদলে বড় ব্যাচ পছন্দ করুন।\n- উচ্চ উপলব্ধতা ও পড়ার ক্ষমতার জন্য রেপ্লিকা যোগ করুন (আপনার অ্যাপ রেপ্লিকার মধ্যে সার্চ অনুরোধ লোড-ব্যালান্স করতে পারে)।\n- শার্ডিং: Meilisearch স্বয়ংক্রিয়ভাবে ডিস্ট্রিবিউটেড শার্ডিং করে না। যদি একটি নোড অতিক্রম করে, আপনি অ্যাপ লেয়ারে ডেটা পার্টিশন করতে পারেন (উদাহরণ: প্রতিটি টেন্যান্ট, রিজিয়ন, বা টাইম রেঞ্জ অনুযায়ী) একাধিক ইনডেক্স বা ক্লাস্টারে বিভাজন করে।
একটি ছোট সেট সিগন্যাল ট্র্যাক করুন:\n\n- সার্চ লেটেন্সি (p50/p95) এবং থ্রুপুট\n- টাস্ক কিউ লেন্থ / টাস্ক প্রসেসিং টাইম (একটা বাড়তে থাকা কিউ মানে ইনডেক্সিং সাথে রাখছে না)\n- CPU, RAM, ডিস্ক ব্যবহার এবং ডিস্ক I/O ওয়েট\n- এরর রেট (টাইমআউট, 4xx/5xx, ব্যর্থ টাস্ক)
ব্যাকআপ রুটিন হওয়া উচিত, ন্যূনতম নয়। Meilisearch-এর snapshot ফিচার ব্যবহার করে শিডিউল করুন, স্ন্যাপশটগুলো অফ-বক্সে স্টোর করুন, এবং মাঝে মাঝে রিস্টোর টেস্ট করুন। আপগ্রেডের ক্ষেত্রে রিলিজ নোট পড়ুন, একটি নন-প্রোড এনভারনমেন্টে স্টেজ করুন, এবং যদি ভার্সন পরিবর্তন ইন্ডেক্সিং আচরণ প্রভাবিত করে তাহলে রিইনডেক্সিং সময় পরিকল্পনা করুন।
যদি আপনি ইতিমধ্যেই পরিবেশ স্ন্যাপশট ও রোলব্যাক ব্যবহার করে থাকেন (উদাহরণ: Koder.ai-এর স্ন্যাপশট/রোলব্যাক ওয়ার্কফ্লো), আপনার সার্চ রোলআউট একই শৃঙ্খলে লাগান: পরিবর্তনের আগে স্ন্যাপশট নিন, হেলথ চেক যাচাই করুন, এবং দ্রুতভাবে_known-good_ অবস্থায় ফিরে যাওয়ার পথ রাখুন।
পরিষ্কার ইন্টিগ্রেশন থাকা সত্ত্বেও, সার্চ সমস্যাগুলো সাধারণত কয়েকটি রিপিটেবল বাকেটে পড়ে। ভাল খবর: Meilisearch আপনাকে পর্যাপ্ত ভিজিবিলিটি দেয় (টাস্ক, লগ, ডিটারমিনিস্টিক সেটিংস) দ্রুত ডিবাগ করার জন্য—প্রকৃতপক্ষে যদি আপনি সিস্টেম্যাটিকভাবে এগোেন।
filterableAttributes-এ যোগ করা হয়নি, অথবা ডকুমেন্টে সেটি অপ্রত্যাশিত শেপে সংরক্ষিত আছে (স্ট্রিং বনাম অ্যারে বনাম নেস্টেড অবজেক্ট)।sortableAttributes/rankingRules টুইক ভুল আইটেমকে উপরে নিয়ে আসছে।শুরুতেই চেক করুন Meilisearch আপনার শেষ পরিবর্তন সফলভাবে প্রয়োগ করেছে কিনা।
filter, তারপর sort, তারপর facets।আপনি যদি একটি ফলাফল ব্যাখ্যা করতে না পারেন, সাময়িকভাবে আপনার কনফিগারেশন সরল করে ফেলুন: সাইনোনিম সরান, র্যাঙ্কিং টুইক কমান, এবং একটি ছোট ডেটাসেটে পরীক্ষা করুন। জটিল রিলেভ্যান্স ইস্যুগুলো 50 ডকুমেন্টে দেখা সহজ, 5 মিলিয়ন-এ নয়।
your_index_v2 পারালালে তৈরি করুন, সেটিংস প্রয়োগ করুন, এবং প্রোডাকশনের কিউয়ারির একটি নমুনা রেপ্লে করুন।filterableAttributes ও sortableAttributes আপনার UI প্রয়োজনের সাথে মিলছে।Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
সার্ভার-সাইড সার্চ মানে প্রশ্নটি ব্রাউজারের ভিতরে নয় আপনার ব্যাকএন্ডে (বা একটি নিবেদিত সার্চ সার্ভিসে) চলবে। এটি সঠিক যখন:
ব্যবহারকারীরা চারটি বিষয়ই তাত্ক্ষণিকভাবে টের পায়:
যদি এগুলোর একটি নেই, ব্যবহারকারীরা পুনরায় কিওয়ার্ড টাইপ করেন, অতিরিক্ত স্ক্রল করেন, বা সার্চ ছেড়ে দেন।
এটিকে সার্চ ইনডেক্স হিসেবে বিবেচনা করুন, আপনার মূল ডেটাবেসের বিকল্প নয়। আপনার ডেটাবেস লেখাগুলো, ট্রাঞ্জ্যাকশন এবং কনস্ট্রেইন্টের জন্য সোর্স-অফ-ট্রুথ থাকবে; Meilisearch হলো খুঁজে পাওয়ার জন্য নির্বাচিত ফিল্ডগুলোর কপি।
একটি সহজ মনস্তত্ব:
সাধারণ ডিফল্ট হলো প্রতি এন্টিটি টাইপে একটি ইনডেক্স (যেমন products, articles)। এটি রাখে:
আপনি যদি “সবকিছু খুঁজুন” চান, তাহলে একাধিক ইনডেক্স কে কুয়েরি করে ব্যাকএন্ডে ফলাফলগুলি মিশ্রিত করতে পারেন, অথবা পরে একটি ডেডিকেটেড গ্লোবাল ইনডেক্স তৈরি করতে পারেন।
একটি প্রাথমিক কী এমন কিছু হওয়া উচিত যা:
id, sku, slug)স্থিতিশীল আইডি ইন্ডেক্সিংকে আইডেমপটেন্ট করে: আপনি যদি আবার আপলোড করেন, তাহলে ডুপ্লিকেট তৈরি হবে না কারণ আপডেটগুলো সেফ আপসার্ট হিসেবে কাজ করে।
প্রতিটি ফিল্ডকে তার উদ্দেশ্য অনুযায়ী শ্রেণীবদ্ধ করুন যাতে আপনাকে অতিরিক্ত ইনডেক্সিং না করতে হয়:
এই ভূমিকা স্পষ্ট রাখলে শব্দজিৎ ফলাফল কমে এবং ইনডেক্স ফোল্ডিং ও ধীর আপডেট এড়ানো যায়।
ইন্ডেক্সিং অ্যাসিঙ্ক্রোনাস: ডকুমেন্ট পাঠালেই Meilisearch একটি টাস্ক তৈরি করে, এবং টাস্ক সফল হওয়ার পরে সেই ডকুমেন্টগুলো সার্চযোগ্য হয়।
একটি নির্ভরযোগ্য ফ্লো:
taskUid পোল করুন যতক্ষণ না এটি succeeded বা failed হয়যদি ফলাফল পুরোনো লাগে, ডিবাগ করার আগে টাস্ক স্ট্যাটাস চেক করুন।
সার্ভিসে বহুল-ডকুমেন্ট ইম্পোর্ট বা ঘন ঘন আপডেট থাকলে ইনডেক্সিং লোড বাড়ে। আইডিয়াল শুরু বিন্দু:
ছোট ব্যাচ অনেক সুবিধা দেয়: রিট্রাই করা সহজ, ভুল রেকর্ড শনাক্ত করা সহজ, টাইমআউট এর সম্ভাবনা কম।
দুইটি দ্রুত প্রভাবশালী নিয়ন্ত্রণ আছে:
searchableAttributes: কোন ফিল্ডগুলো সার্চ করা হবে এবং কোন অগ্রাধিকার (অগ্রগণ্য ফিল্ডগুলোকে বেশি গুরুত্ব দেয়)publishedAt, price, বা popularity মতো ফিল্ড দিয়ে সাজাবেনপ্রায়োগিক কৌশল: 5–10টি বাস্তব ইউজার কিওয়ার্ড নিন, পরে-আগে শীর্ষ ফলাফল রেকর্ড করুন, এক সেটিং পরিবর্তন করে আবার তুলনা করুন।
সাধারণত ফিল্টার/সাজানোর সমস্যা কনফিগারেশনের অভাবে হয়:
filterableAttributes এ থাকতে হবেsortableAttributes এ থাকতে হবেএছাড়া ডকুমেন্টে ফিল্ডের ধরন ও গঠন (স্ট্রিং বনাম অ্যারে বনাম নেস্টেড অবজেক্ট) যাচাই করুন। যদি ফিল্টার ব্যর্থ হয়, সর্বশেষ সেটিংস/টাস্ক স্ট্যাটাস দেখুন এবং নিশ্চিত করুন যে ইনডেক্সে প্রত্যাশিত ফিল্ড মানগুলো আছে।