১৪ জুল, ২০২৫·8 মিনিট
মেমরি ব্যবস্থাপনার কৌশল: পারফরম্যান্স বনাম নিরাপত্তা
জানুন গার্বেজ কালেকশন, মালিকানা ও রেফারেন্স কাউন্টিং কীভাবে গতি, লেটেন্সি ও সুরক্ষাকে প্রভাবিত করে—এবং কিভাবে আপনার লক্ষ্য অনুযায়ী ভাষা বেছে নিবেন।
জানুন গার্বেজ কালেকশন, মালিকানা ও রেফারেন্স কাউন্টিং কীভাবে গতি, লেটেন্সি ও সুরক্ষাকে প্রভাবিত করে—এবং কিভাবে আপনার লক্ষ্য অনুযায়ী ভাষা বেছে নিবেন।
মেমরি ব্যবস্থাপনা হল সেই নিয়ম ও যন্ত্রপাতি যেগুলো একটি প্রোগ্রাম মেমরি চায়, ব্যবহার করে এবং ফিরিয়ে দেয়ার জন্য ব্যবহার করে। প্রতিটি রানিং প্রোগ্রামের ভ্যারিয়েবল, ইউজার ডেটা, নেটওয়ার্ক বাফার, ইমেজ এবং মধ্যবর্তী রেজাল্টের মতো জিনিসগুলোর জন্য মেমরি দরকার। মেমরি সীমিত এবং অপারেটিং সিস্টেম ও অন্যান্য অ্যাপ্লিকেশনের সাথে শেয়ার করা হওয়ায় ভাষাগুলোকে সিদ্ধান্ত নিতে হয় কে মেমরিটি মুক্ত করবে এবং কখন তা হবে।
এই সিদ্ধান্তগুলো দুইটি ফলাফল গঠন করে যেগুলো অধিকাংশ মানুষকে গুরুত্ব দেয়: প্রোগ্রামটি কত দ্রুত মনে হবে, এবং চাপের মধ্যে এটি কত নির্ভরযোগ্যভাবে আচরণ করবে।
পারফরম্যান্স একটি একক সংখ্যা নয়। মেমরি ব্যবস্থাপনা প্রভাবিত করতে পারে:
একটি ভাষা যা দ্রুত বরাদ্দ করে কিন্তু মাঝে মাঝে ক্লিনআপের জন্য বিরতি দেয় তা বেঞ্চমার্কে ভাল দেখাতে পারে কিন্তু ইন্টারঅ্যাক্টিভ অ্যাপে জিটারিং তৈরি করতে পারে। অন্য একটি মডেল যা বিরতি এড়ায় তা লিক ও লাইফটাইম ভুল প্রতিরোধে আরও সতর্ক ডিজাইন দাবি করতে পারে।
নিরাপত্তা মানে মেমরি-সংক্রান্ত ব্যর্থতা প্রতিরোধ করা, যেমন:
অনেক উচ্চ-প্রোফাইল সিকিউরিটি সমস্যা মেমরি ভুল থেকে উদ্ভূত হয়েছে, যেমন use-after-free বা বাফার ওভারফ্লো।
এই গাইডটি জনপ্রিয় ভাষাগুলোর প্রধান মেমরি মডেলগুলোর একটি অ-প্রযুক্তিগত ট্যুর — তারা কী অপ্টিমাইজ করে এবং আপনি একটি ভাষা বেছে নিলে কী ট্রেডঅফ নিচ্ছেন।
মেমরি হল যেখানে আপনার প্রোগ্রাম রান করার সময় ডেটা রাখা হয়। বেশিরভাগ ভাষা এটিকে দুইটি প্রধান অংশের উপর সাজায়: স্ট্যাক এবং হিপ।
স্ট্যাককে ভাবুন যেন চলমান কাজের জন্য ছোট নোটপ্যাড। যখন একটি ফাংশন শুরু হয়, এটি স্ট্যাকে একটি ছোট “ফ্রেম” পায় তার লোকাল ভ্যারিয়েবলগুলোর জন্য। ফাংশন শেষ হলে পুরো ফ্রেম একসাথে সরিয়ে ফেলা হয়।
এটি দ্রুত ও পূর্বানুমানযোগ্য — কিন্তু কেবল তখনই কাজ করে যখন মানগুলোর সাইজ জানা থাকে এবং লাইফটাইম ফাংশন কলের সাথে শেষ হয়।
হিপটা বেশি ট্রাঞ্জিশনাল, যেখানে আপনি অবজেক্টগুলো যতক্ষণ চান ততক্ষণ রাখতে পারেন। ডাইনামিক সাইজযুক্ত লিস্ট, স্ট্রিং বা প্রোগ্রামের বিভিন্ন অংশে শেয়ার হওয়া অবজেক্টের জন্য এটি উপযুক্ত।
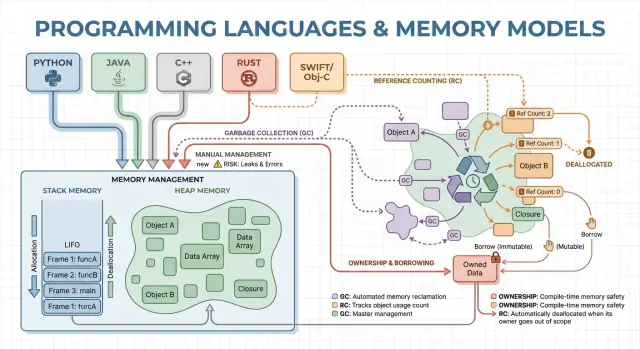
কারণ হিপ অবজেক্টগুলো একটি ফাংশনের জীবনকাল ছাড়িয়ে থাকতে পারে, প্রধান প্রশ্ন হয়ে ওঠে: কে এবং কখন তাদের মুক্ত করবে? এটাই একটি ভাষার “মেমরি ম্যানেজমেন্ট মডেল”।
একটি পয়েন্টার বা রেফারেন্স হল অবজেক্টকে অপরোক্ষভাবে অ্যাক্সেস করার উপায় — যেমন স্টোররুমে একটি বাক্সের শেলফ নম্বর। যদি বাক্সটি ফেলার পরে আপনার কাছে এখনও শেলফ নম্বর থাকে, আপনি গারবেজ পড়তে পারেন বা ক্র্যাশ করতে পারেন (use-after-free এর ক্লাসিক উদাহরণ)।
ধরা যাক একটি লুপ যা একটি কাস্টমার রেকর্ড তৈরি করে, একটি বার্তা ফরম্যাট করে এবং তা discard করে:
কখনো কখনো ভাষাগুলো এই বিস্তারিতগুলো লুকায় (স্বয়ংক্রিয় ক্লিনআপ), আবার কিছু ভাষা এগুলো উন্মুক্ত করে (আপনি স্পষ্টভাবে মেমরি মুক্ত করবেন, বা অবজেক্টের মালিকানা সম্পর্কে নিয়ম মানতে হবে)। পরবর্তী অংশগুলো নিয়ে আলোচনা করবে কীভাবে সেই পছন্দগুলো গতি, বিরতি এবং নিরাপত্তায় প্রভাব ফেলে।
ম্যানুয়াল মেমরি ম্যানেজমেন্ট মানে প্রোগ্রাম (অর্থাৎ ডেভেলপার) স্পষ্টভাবে মেমরি চয়েস করে এবং পরে মুক্ত করে। বাস্তবে এটা malloc/free (C) বা new/delete (C++) রূপে দেখা যায়। সিস্টেম প্রোগ্রামিং-এ এটি এখনও সাধারণ, যেখানে আপনাকে নির্দিষ্টভাবে জানতে হয় কখন মেমরি নেওয়া ও ফেরত দেওয়া হচ্ছে।
আপনি সাধারণত মেমরি বরাদ্দ করেন যখন কোনো অবজেক্ট বর্তমান ফাংশন কল থেকেও বেশি বাঁচবে, ডাইনামিকভাবে বাড়বে (যেমন একটি resizable বাফার) বা হার্ডওয়্যার/OS/নেটওয়ার্ক প্রোটোকলের সাথে ইন্টারঅপের জন্য নির্দিষ্ট লেআউট দরকার।
ব্যাকগ্রাউন্ডে কোন গার্বেজ কালেক্টর না থাকায় হঠাৎ বিরতি কম থাকে। কাস্টম আলোকেটর, পুল বা ফিক্সড-সাইজ বাফারের সঙ্গে জোড়া লাগালে বরাদ্দ ও বিমুক্তি অনেকটাই পূর্বানুমানযোগ্য করা যায়।
ম্যানুয়াল কন্ট্রোলও ওভারহেড কমাতে পারে: ট্রেসিং নেই, রাইট ব্যারিয়ার নেই, এবং প্রায়ই অবজেক্ট প্রতি কম মেটাডাটা থাকে। যতক্ষণ কোড সতর্কভাবে নকশা করা হয়, ততক্ষণ আপনি কঠিন লেটেন্সি টার্গেট পূরণ করতে এবং মেমরি ব্যবহারে কড়া সীমা বজায় রাখতে পারবেন।
ট্রেডঅফ হলো যে রানটাইম স্বয়ংক্রিয়ভাবে বাধা দেয় না এমন ভুল প্রোগ্রাম করতে পারে:
এই বাগগুলো ক্র্যাশ, ডেটা কোরাপশন এবং সিকিউরিটি ভান্ন করতে পারে।
টিমগুলি ঝুঁকি কমায় কাঁচা বরাদ্দ কোথায় অনুমোদিত তা সীমাবদ্ধ করে এবং রোজকার প্যাটার্নগুলো ব্যবহার করে:
std::unique_ptr) মালিকানা এনকোড করতেএম্বেডেড সফটওয়্যার, রিয়েল-টাইম সিস্টেম, OS অংশ এবং পারফরম্যান্স-ক্রিটিক্যাল লাইব্রেরিগুলোর জন্য ম্যানুয়াল মেমরি ম্যানেজমেন্ট ভালো পছন্দ—যেখানে কড়া নিয়ন্ত্রণ ও পূর্বানুমানযোগ্য লেটেন্সি ডেভেলপার স্বাচ্ছন্দ্যের চেয়ে গুরুত্বপূর্ণ।
গার্বেজ কালেকশন (GC) হলো স্বয়ংক্রিয় মেমরি ক্লিনআপ: আপনি নিজে free না করলেও রানটাইম অবজেক্টগুলো ট্র্যাক করে এবং পৌছনো না যেসব অবজেক্ট সেগুলো পুনরুদ্ধার করে। এতে আপনি আচরণ ও ডেটা ফ্লোতে মনোযোগ রাখতে পারেন, আর সিস্টেম বেশিরভাগ বরাদ্দ/বিমুক্তি সিদ্ধান্ত সামলায়।
অধিকাংশ কালেক্টর প্রথমে লাইভ অবজেক্টগুলো শনাক্ত করে, তারপর অবশিষ্টগুলো পুনরুদ্ধার করে।
ট্রেসিং GC সাধারণত “রুট” (স্ট্যাক ভ্যারিয়েবল, গ্লোবাল রেফারেন্স, রেজিস্টার) থেকে শুরু করে রেফারেন্সগুলো অনুসরণ করে যে সব অবজেক্ট পৌঁছনো যায় সেগুলো চিহ্নিত করে, তারপর হিপকে সুইপ করে অচিহ্নিতগুলো মুক্ত করে। যদি কেহ কোনো অবজেক্টকে পয়েন্ট না করে, সেটি কালেকশনের সুযোগ পায়।
Generational GC ধরে যে অনেক অবজেক্ট তরুণ অবস্থায় মরে। হিপকে জেনারেশনগুলোতে ভাগ করে তরুণ এলাকা ঘন ঘন কালেক্ট করে, যা সাধারণত কম খরচে হয়ে থাকে এবং সামগ্রিক দক্ষতা বাড়ায়।
Concurrent GC অ্যাপ্লিকেশন থ্রেডের পাশাপাশি কালেকশনের অংশ চালায়, লম্বা বিরতি কমাতে চায়। এটি যখন প্রোগ্রাম চলমান থাকে তখন মেমরির দৃশ্যমানতা স্থিত রাখতে বেশি বুককিপিং করতে পারে।
GC সাধারণত ম্যানুয়াল কন্ট্রোল বিনিময়ে রানটাইম কাজ নেয়। কিছু সিস্টেম steady throughput প্রাধান্য দেয় (প্রতি সেকেন্ড অনেক কাজ) কিন্তু stop-the-world বিরতি থাকতে পারে। অন্যরা লেটেন্সি সংবেদনশীল অ্যাপের জন্য বিরতিগুলো কমায়, কিন্তু এটি স্বাভাবিক এক্সিকিউশনে অতিরিক্ত ওভারহেড যোগ করতে পারে।
GC লাইফটাইমের একটি সম্পূর্ণ ক্লাস বাগ মুছে দেয় (বিশেষত use-after-free) কারণ অবজেক্টগুলি তখনই পুনরুদ্ধার হয় না যতক্ষণ ওগুলো পৌঁছনো থাকে। এটি মিসড ডিঅলোকেশনের ফলে হওয়া লিকও কমায় (যদিও রেফারেন্স দীর্ঘ সময় ধরে ধরলে আপনি এখনও “লিক” প্রাপ্ত করতে পারেন)। বড় কোডবেসে যেখানে মালিকানা ট্র্যাক করা কঠিন, এটি iteration দ্রুত করতে সহায়ক।
গার্বেজ-কলেক্টেড রUNTIME সাধারণত JVM (Java, Kotlin), .NET (C#, F#), Go, এবং ব্রাউজার ও Node.js-এর জাভাস্ক্রিপ্ট ইঞ্জিনে দেখা যায়।
রেফারেন্স কাউন্টিং এমন একটি কৌশল যেখানে প্রতিটি অবজেক্ট কতগুলো “মালিক” (রেফারেন্স) আছে তা ট্র্যাক করে। যখন কাউন্ট শূন্যে নেমে আসে, অবজেক্ট তৎক্ষণাৎ মুক্ত হয়। সেই তাৎক্ষণিকতা বোধগম্য লাগে: আর কেউ ওই অবজেক্টে পৌঁছাতে না পারলে মেমরি অবিলম্বে ফিরে যায়।
প্রতিবার আপনি একটি রেফারেন্স কপি বা স্টোর করেন, রানটাইম তার কাউন্টার বাড়ায়; যখন রেফারেন্স চলে যায়, সেটা কমায়। শূন্যে গেলে তাৎক্ষণিক ক্লিনআপ ট্রিগার হয়।
এতে রিসোর্স ম্যানেজমেন্ট সহজ মনে হয়: অবজেক্টগুলো সাধারণত আপনি ব্যবহার শেষ করার কাছাকাছি সময়েই মুক্তি দেয়, যা পিক মেমরি ব্যবহার কমাতে পারে এবং বিলম্বিত পুনরুদ্ধার এড়াতে সাহায্য করে।
রেফারেন্স কাউন্টিং সাধারণত স্থিত, ধ্রুব ওভারহেড থাকে: ইনক্রিমেন্ট/ডিক্রিমেন্ট অপারেশন অনেক অ্যাসাইনমেন্ট ও ফাংশন কলেই ঘটে। ওভারহেড সাধারণত ছোট, কিন্তু প্রতিটি জায়গায় ঘটছে।
উল্টো দিকটি হলো প্রায়ই আপনি বড় stop-the-world বিরতি পাবেন না যেগুলো ট্রেসিং GC-তে দেখা যায়। লেটেন্সি সাধারণত মসৃণ থাকে, যদিও বড় অবজেক্ট গ্রাফ একবারে ডি-অলক হলে ডিক্লাস্টার ডিলেটগুলো ঘটতে পারে।
রেফারেন্স কাউন্টিং সাইকেলগুলো পুনরুদ্ধার করতে পারে না। যদি A B-কে রেফার করে এবং B A-কে রেফার করে, উভয়ের কাউন্ট শূন্য হয় না এমনকি যদি আর কেউ পৌঁছায় না—ফলস্বরূপ মেমরি লিক হয়।
ইকোসিস্টেমগুলো এটা মোকাবেলা করে:
মালিকানা ও ধার নীতিটি সবচেয়ে বেশি পরিচিত রাস্টের সঙ্গে। ধারণাটি সহজ: কম্পাইলার এমন নিয়ম আরোপ করে যাতে dangling পয়েন্টার, ডাবল-ফ্রি এবং অনেক ডেটা-রেস তৈরি করাটা কঠিন হয় — রানটাইম GC ছাড়াই।
প্রতিটি মানের একবারে একটিই “মালিক” থাকে। মালিক স্কোপ থেকে বের হলে মানটি তৎক্ষণাৎ এবং পূর্বানুমানযোগ্যভাবে ক্লিনআপ হয়। এটা আপনাকে মেমরি, ফাইল হ্যান্ডল, সকেটের মতো রিসোর্সগুলোর জন্য নির্ধারিত ম্যানেজমেন্ট দেয়, ম্যানুয়াল ক্লিনআপের মতোই কিন্তু অনেক কম ভুল করার উপায় আছে।
মালিকানা মুভও করতে পারে: একটি ভ্যালুকে নতুন ভ্যারিয়েবলে অ্যাসাইন করলে বা একটি ফাংশনে পাস করলে দায়িত্ব স্থানান্তরিত হতে পারে। মুভের পর পুরানো বাইন্ডিং ব্যবহার করা যায় না, ফলে use-after-free কম্পাইল টাইমেই আটকানো যায়।
ধার আপনাকে মালিক না হয়ে কোনো মান ব্যবহার করতে দেয়।
একটি শেয়ার্ড বরা পাঠ্য-শক্তির অ্যাক্সেস দেয় এবং সহজে কপি করা যায়।
একটি মিউটেবল বরা পরিবর্তনের অনুমতি দেয়, কিন্তু তা একচেটিয়াভাবে হতে হবে: যখন এটি আছে, তখন অন্য কেউ একই মান পড়তে বা লিখতে পারবে না। "একজন লেখক বা অনেক পাঠক" নিয়ম কম্পাইল টাইমে যাচাই করা হয়।
লাইফটাইম ট্র্যাক করার কারণে কম্পাইলার এমন কোড رد করতে পারে যেটা ডেটা লাইফটাইম অতিক্রম করবে, ফলে dangling-reference অনেকটাই মুছে যায়। একই নিয়ম কনকারেন্সি কোডে অনেক রেস কন্ডিশনকেও প্রতিরোধ করে।
টারেডঅফ হিসেবে শেখার বাঁক এবং কিছু ডিজাইন সীমা আছে। আপনাকে ডাটা ফ্লো বদলাতে হতে পারে, মালিকানা সীমানা পরিষ্কার করতে হতে পারে বা শেয়ার্ড মিউটেবল স্টেটের জন্য বিশেষ ধরনের টাইপ ব্যবহার করতে হতে পারে।
সিস্টেম কোড—সার্ভিস, এমবেডেড, নেটওয়ার্কিং এবং পারফরম্যান্স-সেনসিটিভ কম্পোনেন্ট—এ এটি ভাল ফিট, যেখানে আপনি GC বিরতিবিহীন পূর্বানুমানযোগ্য ক্লিনআপ চান।
আপনি যদি অনেক স্বল্পজীবী অবজেক্ট তৈরি করেন—কম্পাইলারের AST নোড, গেমিং-ফ্রেমের এন্টিটি, বা ওয়েব রিকোয়েস্টের সময় অস্থায়ী ডেটা—তবে প্রতিটি অবজেক্ট আলাদাভাবে বরাদ্দ ও মুক্তির ওভারহেড রানটাইমে বাড়তে পারে। অ্যারিনা (রিজিয়ন) ও পুল এমন প্যাটার্ন যা সূক্ষ্ম-মাপে মুক্তি প্রতিস্থাপনে দ্রুত ব্যাচ ম্যানেজমেন্ট দেয়।
একটি অ্যারিনা হল একটি মেমরি “জোন” যেখানে আপনি অনেক অবজেক্ট বরাদ্দ করেন এবং পরে সবকে একসাথে রিলিজ করেন অ্যারিনাটি রিসেট করে বা ড্রপ করে।
আপনি প্রতিটি অবজেক্টের লাইফটাইম আলাদাভাবে ট্র্যাক না করে লাইফটাইমকে একটি স্পষ্ট সীমানার সঙ্গে বেঁধে দেন: “এই অনুরোধের জন্য সব কিছু” বা “এই ফাংশন কম্পাইলিংয়ের সময় সব কিছু”।
অ্যারিনা প্রায়ই দ্রুত কারণ:
এটি থ্রুপুট বাড়ায় এবং বারবার ফ্রি বা আলোকেটর কনটেনশনের কারণে হওয়া লেটেন্সি স্পাইক কমাতে পারে।
অ্যারিনা ও পুল দেখা যায়:
মুখ্য নিয়ম: রিজিয়ন যে মেমরির মালিক সেটার বাইরেও রেফারেন্স পাস করবেন না। যদি অ্যারিনায় বরাদ্দকৃত কিছু গ্লোবালভাবে সংরক্ষিত হয় বা অ্যারিনার লাইফটাইম অতিক্রম করে রিটার্ন করা হয়, তাহলে use-after-free ঝুঁকি থাকে।
ভাষা ও লাইব্রেরি এটা ভিন্নভাবে হ্যান্ডল করে: কিছু শৃঙ্খলা ও API-র ওপর নির্ভর করে, অন্যরা টাইপে রিজিয়ন বাউন্ডারি এনকোড করে।
অ্যারিনা ও পুল GC বা মালিকানা-ভিত্তিক পন্থার বিকল্প নয়—এগুলো প্রায়ই সংযোজক হিসেবে কাজ করে। GC-ভিত্তিক ভাষাগুলো হট-পাথে অবজেক্ট পুল ব্যবহার করতে পারে; মালিকানা-ভিত্তিক ভাষাগুলো অ্যারিনা ব্যবহার করে বরাদ্দগুলো গ্রুপ করে লাইফটাইম স্পষ্ট করে। সাবধানে ব্যবহৃত হলে এগুলো ক্লিয়ারিটি অক্ষুণ্ণ রেখে "ডিফল্টে দ্রুত" বরাদ্দ দেয়।
একটি ভাষার মেমরি মডেল কেবল কাহিনীর একটি অংশ। আধুনিক কম্পাইলার ও রUNTIME আপনার প্রোগ্রামকে পুনলিখন করে কম বরাদ্দ করা, দ্রুত মুক্তি এবং অপ্রয়োজনীয় বুককিপিং এড়িয়ে দেয়। এ কারণেই "GC ধীর" বা "ম্যানুয়াল মেমরি সবসময় দ্রুত" ধরণের ধরণপোষ্য বাস্তবে ভাঙে।
অনেক বরাদ্দ কেবল ফাংশনের মধ্যে ডাটা পাস করতে থাকে। Escape analysis কম্পাইলার প্রমাণ করতে পারে যে একটি অবজেক্ট বর্তমান স্কোপ ছাড়ে না এবং সেটিকে হিপের বদলে স্ট্যাকে রাখতে পারে।
এতে একটি হিপ বরাদ্দই পুরোপুরি মুছে যেতে পারে, সঙ্গে GC ট্র্যাকিং, রেফ কাউন্ট আপডেট বা আলোকেটর লকও মাইনাস হয়ে যায়। ম্যানেজড ভাষাগুলোতে এই অপ্টিমাইজেশন ছোট অবজেক্টকে খুব সস্তা করে তুলতে পারে।
যখন একটি কম্পাইলার একটি ফাংশন ইনলাইন করে, এটি কলের পরিবর্তে ফাংশন বডি দেখে নেয়; সেই দৃশ্যমানতা অপ্টিমাইজেশন সক্ষম করে যেমন:
ভাল ডিজাইনকৃত API অপ্টিমাইজেশনের পরে “জিরো-কস্ট” হয়ে উঠতে পারে, যদিও সোর্স কোডে অনেক বরাদ্দ আছে বলে মনে হতে পারে।
JIT রানটাইম বাস্তব উৎপাদন তথ্য (কোন কোড হট, সাধারণ অবজেক্ট সাইজ, বরাদ্দ প্যাটার্ন) ব্যবহার করে অপ্টিমাইজ করতে পারে; এতে প্রায়ই থ্রুপুট বাড়ে, কিন্তু ওয়ার্ম-আপ টাইম ও কখনো কখনো রিপিশন বা GC-এর জন্য বিরতিও যোগ হতে পারে।
AOT কম্পাইলার আগেভাগেই অনুমান করে অপ্টিমাইজ করে, কিন্তু তারা নির্ভরযোগ্য স্টার্টআপ ও স্থির লেটেন্সি দেয়।
GC-ভিত্তিক রানটাইমে হিপ সাইজিং, পজ-টাইম টার্গেট এবং জেনারেশন থ্রেশহোল্ডের মত সেটিং থাকে। এগুলো পরিবর্তন করুন তখনই যখন আপনার মাপা প্রমাণ থাকে (যেমন লেটেন্সি স্পাইক বা মেমরি চাপ)।
একই অ্যালগরিদমের দুটি ইমপ্লিমেন্টেশন লুকান আলোকেশন গণনা, অস্থায়ী অবজেক্ট এবং পয়েন্টার চেজিং-এ ভিন্ন হতে পারে। সেই সব পার্থক্য অপ্টিমাইজার, আলোকেটর এবং ক্যাশ আচরণের সঙ্গে মিশে যায়—অতএব পারফরম্যান্স তুলনা প্রফাইলিং ছাড়া ধারণার উপর ভিত্তি করে করবেন না।
মেমরি ব্যবস্থাপনা পছন্দগুলো কেবল কিভাবে কোড লিখবেন তা পরিবর্তন করে না—এগুলো নির্ধারণ করে কখন কাজ হয়, কত মেমরি رزার্ভ করতে হবে, এবং ব্যবহারকারীর কাছে পারফরম্যান্স কেমন অনুভূত হবে।
থ্রুপুট হল “একক সময়ে কত কাজ।” ধরুন একটি রাতভর ব্যাচ জব 10 মিলিয়ন রেকর্ড প্রসেস করে: যদি GC বা রেফ কাউন্টিং ছোট ওভারহেড যোগ করলেও ডেভেলপার ভেলোসিটি বজায় থাকে, মোটামুটি আপনি মোটেই দ্রুত শেষ করতে পারেন।
লেটেন্সি হল “একটি অপারেশন সম্পূর্ণ হতে কত সময় লাগে।” একটি ওয়েব রিকোয়েস্টের জন্য এক এক ধীর রেসপন্স ইউজার এক্সপেরিয়েন্সকে ক্ষতিগ্রস্ত করে এমনকি গড় থ্রুপুট যদি বেশি থাকে। একটি runtime যা মাঝে মাঝে মেমরি পুনরুদ্ধারের জন্য বিরতি দেয় তা ব্যাচ প্রসেসিং-এ ঠিকঠাক হতে পারে, কিন্তু ইন্টারঅ্যাক্টিভ অ্যাপে তা লক্ষণীয় হবে।
বড় মেমরি ফুটপ্রিন্ট ক্লাউড খরচ বাড়ায় এবং প্রোগ্রামকে ধীর করে দিতে পারে। যখন আপনার ওয়ার্কিং সেট CPU ক্যাশে ফিট না করে, CPU বেশি সময় RAM থেকে ডেটা আনার জন্য অপেক্ষা করে। কিছু কৌশল গতি বাড়াতে অতিরিক্ত মেমরি ব্যবহার করে (যেমন ফ্রি করা অবজেক্টগুলো পুলে রাখা), অন্যগুলো মেমরি কমায় কিন্তু বুককিপিং ওভারহেড বাড়ায়।
ফ্র্যাগমেন্টেশন ঘটে যখন ফ্রি মেমরি বহু ছোট ফাঁক হয়ে যায়—যেন স্টিয়ারিং লট-এ ছড়িয়ে ছিটিয়ে ছোট জায়গা। আলোকেটর স্পেস খুঁজতে বেশি সময় নেবে, এবং মেমরি বাড়তে পারে এমনকি পর্যাপ্ত ফ্রি থাকলেও।
ক্যাশ লোকালিটি মানে সম্পর্কিত ডেটা কাছাকাছি থাকে। পুল/অ্যারিনা বরাদ্দ প্রায়ই লোকালিটি উন্নত করে, যখন দীর্ঘজীবী হিপে মিশ্র সাইজের অবজেক্ট দূরবর্তী অবস্থানে চলে যেতে পারে এবং ক্যাশ-মইন্দা কমে যায়।
যদি আপনি ধারাবাহিক প্রতিক্রিয়া সময় চান—গেমস, অডিও অ্যাপ, ট্রেডিং সিস্টেম, এমবেডেড বা রিয়েল-টাইম কন্ট্রোলার—তখন “অনেক সময় দ্রুত কিন্তু মাঝে মাঝে ধীর” হওয়া “থোড়াই ধীর কিন্তু ধারাবাহিক” হওয়ার চাইতে খারাপ হতে পারে। এখানে পূর্বানুমানযোগ্য ডিঅলোকেশন প্যাটার্ন ও বরাদ্দের উপর কড়া নিয়ন্ত্রণ জরুরি।
মেমরি ত্রুটিগুলো কেবল "প্রোগ্রামারের ভুল" নয়—অনেক বাস্তব সিস্টেমে এগুলো সিকিউরিটি সমস্যায় পরিণত হয়: হঠাৎ ক্র্যাশ (ডিনায়াল অফ সার্ভিস), দুর্ঘটনাক্রমে ডেটা প্রকাশ (ফ্রি করা বা আনইনিশিয়ালাইজড মেমরি পড়া), বা এমন শর্ত যেখানে আক্রমণকারী প্রোগ্রামকে অনির্ধারিত কোড চালাতে দেবে।
বিভিন্ন মেমরি-ম্যানেজমেন্ট স্ট্র্যাটেজি ভিন্নভাবে ভেঙে পড়ে:
কনকারেন্সি থ্রেট মডেল বদলে দেয়: একটি থ্রেডে “ঠিক” থাকা মেমরিটি অন্য থ্রেড যখন মুক্ত বা পরিবর্তন করে তখন বিপজ্জনক হয়ে ওঠে। শেয়ারিং-এর চারপাশে নিয়ম আরোপ করে এমন মডেল বা স্পষ্ট সিনক্রোনাইজেশন বাধ্যতামূলক করে দিলে রেস কন্ডিশন ও তার ফলে হওয়া কোরাপশন, ডেটা লিক এবং ইন্টারমিটেন্ট ক্র্যাশ কমে।
কোনো মেমরি মডেল সব ঝুঁকি দূর করে না—লজিক বাগ (authentication ভুল, অনিরাপদ ডিফল্ট, দুর্বল ভ্যালিডেশন) সবসময়ই থাকে। শক্তিশালী টিমগুলো একাধিক স্তরের সুরক্ষা দেয়: টেস্টিং-এ স্যানিটাইজার, নিরাপদ স্ট্যান্ডার্ড লাইব্রেরি, কড়া কোড রিভিউ, ফাজিং এবং unsafe/FFI কোডের চারপাশে দৃঢ় সীমা। মেমরি সেফটি আক্রমণ-পৃষ্ঠাকে বড় অংকে কমায়, কিন্তু সম্পূর্ণ নিশ্চয়তা নয়।
মেমরি সমস্যা যখন পরিবর্তনের কাছাকাছি পর্যায়েই ধরা পড়ে তখন ঠিক করা সহজ। মাপা শুরু করুন, তারপর সঠিক টুল দিয়ে সমস্যা সংকুচিত করুন।
আপনি কি স্পিড খুঁজছেন নাকি মেমরি গ্রোথ তা নির্ধারণ করে শুরু করুন।
পারফরম্যান্সের জন্য wall-clock time, CPU time, বরাদ্দ হার (bytes/sec) এবং GC বা আলোকেটরের সময় মাপুন। মেমরির জন্য peak RSS, steady-state RSS এবং সময় ভেঙে অবজেক্ট গণনা ট্র্যাক করুন। একই ওয়ার্কलोड নিয়ে চালান; ছোট পরিবর্তনগুলো বরাদ্দ চর্চা লুকিয়ে দিতে পারে।
সাধারণ লক্ষণ: একটি রিকোয়েস্ট অপ্রত্যাশিতভাবে অনেক বরাদ্দ করে, বা ট্র্যাফিক বাড়ার সঙ্গে মেমরি বাড়ে যদিও থ্রুপুট স্থির। সমাধান প্রায়ই বাফার পুনব্যবহার, শর্ট-লাইভ অবজেক্টের জন্য অ্যারিনা/পুল ব্যবহার, এবং অবজেক্ট গ্রাফ সরলীকরণ যাতে কম অবজেক্ট সার্কিট করে থাকে।
ন্যূনতম ইনপুট দিয়ে পুনরুত্পাদন করুন, কঠোরতম রানটাইম চেক (স্যানিটাইজার/GC verification) চালান, তারপর ধরুন:
প্রথম ফিক্সটিকে একটি পরীক্ষা হিসেবে দেখুন; পরিবর্তনের পরে পুনরায় মাপুন নিশ্চিত করতে যে বরাদ্দ কমেছে বা মেমরি স্থির হয়েছে—এবং সমস্যা অন্য জায়গায় সরে যায়নি। আরও ব্যাখ্যার জন্য দেখুন /blog/performance-trade-offs-throughput-latency-memory-use।
ভাষা নির্বাচন কেবল সিনট্যাক্স বা ইকোসিস্টেম নয়—এর মেমরি মডেল দৈনন্দিন ডেভেলপমেন্ট গতি, অপারেশনাল ঝুঁকি এবং বাস্তব ট্র্যাফিকের অধীনে পারফরম্যান্স কতটা পূর্বানুমানযোগ্য হবে তা নির্ধারণ করে।
আপনার প্রোডাক্ট চাহিদাকে একটি মেমরি স্ট্রাটেজির সঙ্গে মানানসই করুন নিম্নলিখিত প্রশ্নগুলোর মাধ্যমে:
আপনি যদি মডেল বদলান, ফ Ajax: FFI লাইব্রেরি কল, মিশ্র মেমরি কনভেনশন, টুলিং ও হায়ারিং মার্কেট—সবকিছু ঘরোয়ার কষ্ট করবে। প্রোটোটাইপ তৈরি করে লুকানো খরচ (বিরতি, মেমরি বৃদ্ধি, CPU ওভারহেড) আগে আবিষ্কার করুন।
একটি ব্যবহারিক উপায় হল একই ফিচারের দুটি পরিবেশে প্রোটোটাইপ করা এবং প্রতিনিধিত্বশীল লোডে বরাদ্দ হার, টেইল লেটেন্সি ও পিক মেমরি তুলনা করা। অনেক টিম এমন “আপেল-টু-আপেল” ইভালুয়েশন করে।
শীর্ষ 3–5 সীমাবদ্ধতা নির্ধারণ করুন, ত Thin prototype বানান, এবং মাপুন মেমরি ব্যবহার, টেইল লেটেন্সি, এবং ব্যর্থতার মোড।
| Model | Safety by default | Latency predictability | Developer speed | Typical pitfalls |
|---|---|---|---|---|
| Manual | Low–Medium | High | Medium | leaks, use-after-free |
| GC | High | Medium | High | pauses, heap growth |
| RC | Medium–High | High | Medium | cycles, overhead |
| Ownership | High | High | Medium | learning curve |
মেমরি ব্যবস্থাপনা হল কিভাবে একটা প্রোগ্রাম ডেটার জন্য মেমরি বরাদ্দ করে (যেমন অবজেক্ট, স্ট্রিং, বাফার) এবং যখন আর প্রয়োজন নেই তখন তা কীভাবে মুক্ত করে।
এটি প্রভাব ফেলে:
স্ট্যাক দ্রুত, স্বয়ংক্রিয় এবং ফাংশন কলের সঙ্গে যুক্ত: একটি ফাংশন রিটার্ন করলে তার স্ট্যাক ফ্রেম একসাথে সরিয়ে ফেলা হয়।
হিপ ডায়নামিক এবং দীর্ঘস্থায়ী ডেটার জন্য; তবে এতে সিদ্ধান্ত নেওয়া লাগে কে ও কখন তা মুক্ত করবে।
সাধারণ নিয়ম: স্ট্যাক ছোটস্থায়ী, নির্দিষ্ট আকারের লোক্যালের জন্য চমৎকার; হিপ তখন ব্যবহৃত হয় যখন লাইফটাইম বা সাইজ অনিশ্চিত।
রেফারেন্স বা পয়েন্টার কোডকে কোনো অবজেক্টকে অপরোক্ষভাবে অ্যাক্সেস করার পথ দেয়। বিপদ তখন আসে যখন অবজেক্টের মেমরি মুক্ত করা হয়েছে কিন্তু সেই রেফারেন্সটি এখনও ব্যবহার করা হয়।
ফলস্বরূপ:
আপনি স্পষ্টভাবে মেমরি বরাদ্দ এবং মুক্ত করেন (উদাহরণ: malloc/free, new/delete)।
এটি ব্যবহারী যখন লাগবে:
মূল্য: যদি মালিকানা ও লাইফটাইম ভালভাবে না ম্যানেজ করা হয় তবে বাগের ঝুঁকি বাড়ে।
যদি ভালভাবে ডিজাইন করা হয়, ম্যানুয়াল মেমরি ম্যানেজমেন্ট খুব পূর্বানুমানযোগ্য লেটেন্সি দিতে পারে, কারণ ব্যাকগ্রাউন্ড GC নেই।
আপনি আরও অপ্টিমাইজ করতে পারেন:
কিন্তু সহজেই খারাপ প্যাটার্ন তৈরি করা যায় (ফ্র্যাগমেন্টেশন, অনেক ছোট alloc/free, আলোকেটর কনটেনশন)।
গার্বেজ কালেকশন স্বয়ংক্রিয়ভাবে এমন অবজেক্টগুলো খুঁজে বের করে এবং মুক্ত করে যেগুলো আর প্রোগ্রাম দ্বারা পৌঁছনো যায় না।
সাধারণত ট্রেসিং GC এর ধাপগুলো হল:
এটি সাধারণত use-after-free-এর মতো লাইফটাইম বাগ কমায়, তবে রানটাইম ওভারহেড যোগ করে এবং কালেকটরের ডিজাইনের উপর নির্ভর করে বিরতি ঘটাতে পারে।
রেফারেন্স কাউন্টিং একটি অবজেক্টে কতগুলো “মালিক” (রেফারেন্স) আছে তা ট্র্যাক করে; কাউন্ট শূন্য হলে অবজেক্ট তৎক্ষণাৎ মুক্ত হয়।
সুবিধা:
সামস্যা:
মালিকানা ও ঋণ (ownership এবং borrowing) মডেল—বিশেষত রাস্টে—কোম্পাইল টাইমে নিয়ম আরোপ করে যাতে dangling পয়েন্টার, ডাবল-ফ্রি এবং অনেক ডেটা-রেস ক্লাস বাধা দেয়া যায়, রানটাইম GC ছাড়াই।
মূল ধারণা:
ফলপ্রসূ—নির্দিষ্ট_cleanup ও GC-বিহীন লেটেন্সি; তবে শেখার বাঁক এবং ডিজাইন সামঞ্জস্য প্রয়োজন হতে পারে।
অ্যারিনা/রিজিয়ন/পুলগুলো তখন কার্যকর যখন আপনি অনেক স্বল্পকালীন অবজেক্ট তৈরি করেন—তারপর প্রতিটি অবজেক্ট আলাদা করে মুক্ত করার বদলে একটি ইউনিট হিসাবে সবকে একসাথে রিসেট বা ড্রপ করতে পারেন।
উদাহরণ: “প্রতি অনুরোধ” বরাদ্দ, “প্রতি ফ্রেম” গেম অবজেক্ট, কম্পাইলারের AST নোড ইত্যাদি।
কী নিয়ম: অ্যারিনায় বরাদ্দকৃত রেফারেন্সগুলো আরিনা লাইফটাইম পার হয়ে গেলে বাইরে পাঠাবেন না—অন্যথায় use-after-free ঘটবে।
এগুলো প্রায়ই GC বা মালিকানা মডেলের সঙ্গে একসাথে ব্যবহার করা হয় হট-পাথে দ্রুত বরাদ্দের জন্য।
প্রথমে একটা রিয়েলিস্টিক লোডে মাপুন:
তারপর টুলগুলো ব্যবহার করুন:
অনেক ইকোসিস্টেম সাইকেল ভাঙার জন্য ওয়েক রেফারেন্স ব্যবহার করে বা রেফারেন্স কাউন্টিং-এর উপর অতিরিক্ত সাইকেল ডিটেকশন চালায়।
GC প্যারামিটার টিউন করুন কেবলমাত্র মাপার পরে এবং স্পষ্ট সমস্যার কাছে পৌঁছালে।