০৭ আগ, ২০২৫·8 মিনিট
নোয়াম শাজীর এবং LLM-গুলোর পিছনের ট্রান্সফরমার আর্কিটেকচার
জানুন কিভাবে নোয়াম শাজীর ট্রান্সফরমার গঠনে অবদান রাখেন: সেলফ-অ্যাটেনশন, মাল্টি-হেড অ্যাটেনশন, এবং কেন এই ডিজাইন আধুনিক LLM-গুলোর মেরুদণ্ড হয়ে উঠেছে।
জানুন কিভাবে নোয়াম শাজীর ট্রান্সফরমার গঠনে অবদান রাখেন: সেলফ-অ্যাটেনশন, মাল্টি-হেড অ্যাটেনশন, এবং কেন এই ডিজাইন আধুনিক LLM-গুলোর মেরুদণ্ড হয়ে উঠেছে।
ট্রান্সফরমার হলো এমন একটি পদ্ধতি যা কম্পিউটারকে ক্রমগুলো—যেখানে ক্রম ও প্রসঙ্গ গুরুত্বপূর্ণ, যেমন বাক্য, কোড, বা অনুসন্ধান প্রশ্নের সিরিজ—বোঝাতে সাহায্য করে। ক্ষুদ্র-স্তরে একেকটি টোকেন পড়ে ক্রমাগত দুর্বল মেমোরি বহন করার বদলে, ট্রান্সফরমার পুরো সিকোয়েন্স জুড়ে দেখে এবং প্রতিটি অংশ ব্যাখ্যার সময় কোন অংশে মনোযোগ দেয় তা ঠিক করে।
এই সরল কাছারি বদলে দেওয়াটা বড় প্রভাব ফেলেছে। এটি আধুনিক বড় ভাষার মডেল (LLMs) কীভাবে প্রসঙ্গ ধরে রাখতে পারে, নির্দেশনার অনুবর্তিতা দেখায়, সুসংগঠিত অনুচ্ছেদ লিখে এবং পূর্বের ফাংশন ও ভেরিয়েবল রেফারেন্স করে এমন কোড জেনারেট করতে পারে—তার একটা বড় কারণ।
আপনি যদি কোনো চ্যাটবট, “এটা সারসংক্ষেপ কর” ফিচার, সেমান্টিক সার্চ, বা কোডিং সহকারী ব্যবহার করে থাকেন, তাহলে আপনি ট্রান্সফরমার-ভিত্তিক সিস্টেমের সঙ্গে যোগাযোগ করেছেন। একই মূল নকশা সমর্থন করে:
আমরা মূল অংশগুলো—সেলফ-অ্যাটেনশন, মাল্টি-হেড অ্যাটেনশন, পজিশনাল এনকোডিং, এবং বেসিক ট্রান্সফরমার ব্লক—ভাঙব এবং ব্যাখ্যা করব কেন এই নকশা মডেল বড় হওয়ার সঙ্গে কীভাবে ভালভাবে স্কেল করে।
আমরা আধুনিক ভ্যারিয়েন্টগুলোর কথাও সংক্ষেপে ছুঁয়ে দেখব, যেগুলো একই মূল ধারণা রাখে কিন্তু গতি, খরচ, বা দীর্ঘ কনটেক্সট উইন্ডোর জন্য কিছুটা পরিবর্তন আনে।
এটি একটি উচ্চ-স্তরের ভ্রমণ যার ভাষা সরল এবং গণিত কম। লক্ষ্য হলো ধারণা গড়ে তোলা: অংশগুলো কী করে, কেন তারা একসঙ্গে কাজ করে, এবং কীভাবে তা বাস্তব প্রোডাক্ট ক্ষমতায় অনুবাদ হয়।
নোয়াম শাজীর একজন AI গবেষক ও ইঞ্জিনিয়ার, যিনি ২০১৭ সালের “Attention Is All You Need” কাগজের সহ-লেখক হিসাবে সবচেয়ে বেশি পরিচিত। ওই পেপারটি ট্রান্সফরমার আর্কিটেকচারটি উপস্থাপন করেছিল, যা পরে অনেক আধুনিক LLM-এর ভিত্তি হয়ে ওঠে। শাজীরের কাজ একটি দলবদ্ধ প্রচেষ্টার অংশ: ট্রান্সফরমারটি গুগলের একদল গবেষকের দ্বারা তৈরি হয়েছিল, এবং এটাকে সেইভাবে সম্মান করা গুরুত্বপূর্ণ।
ট্রান্সফরমারের আগ পর্যন্ত অনেক NLP সিস্টেম রিকারেন্ট মডেলের ওপর নির্ভর করত, যা টেক্সটকে ধাপে ধাপে প্রক্রিয়াকরণ করত। ট্রান্সফরমারের প্রস্তাব দেখিয়েছিল কিভাবে recurrence ছাড়াই attention ব্যবহার করে সিকোয়েন্সগুলো কার্যকরভাবে মডেল করা যায়।
এই বদলটি গুরুত্বপূর্ণ ছিল কারণ এটি প্রশিক্ষণকে প্যারালালাইজ করা সহজ করে (অনেক টোকেন একসাথে প্রক্রিয়াকরণ করা যায়) এবং মডেল ও ডেটাসেট স্কেল করার দরজা খুলে দেয়—যা দ্রুত প্রোডাক্টে ব্যবহারযোগ্য হয়ে ওঠে।
শাজীরের অবদান—অন্য লেখকদের সঙ্গে—শুধু একাডেমিক বেঞ্চমার্কে সীমাবদ্ধ থাকেনি। ট্রান্সফরমার একটি পুনঃব্যবহারযোগ্য মডিউল হয়ে উঠল: উপাদান বদলানো যায়, সাইজ বাড়ানো যায়, টাস্কের জন্য টিউন করা যায়, এবং পরে বড় আকারে প্রিট্রেইন করা যায়।
অনেক ব্রেকথ্রু এভাবেই ছড়ায়: একটি কাগজ পরিষ্কার, সাধারণ রেসিপি উপস্থাপন করে; ইঞ্জিনিয়াররা এটিকে পরিশোধ করে; কোম্পানিগুলো অপারেশনালাইজ করে; এবং অবশেষে এটি ভাষা-ফিচার তৈরির জন্য ডিফল্ট পছন্দ হয়ে ওঠে।
ভুল হবে যদি কেউ বলেন শাজীর একাই আবিষ্কারক। তিনি গুরুত্বপূর্ণ সহ-লেখক ও অবদানকারী—কিন্তু আর্কিটেকচারটি একটি দলগত নকশা, এবং তার প্রভাব আসে মূল নকশা ও পরে কমিউনিটির করা অসংখ্য উন্নতির সমন্বয়ে।
ট্রান্সফরমারের আগে বেশিরভাগ সিকোয়েন্স সমস্যা (অনুবাদ, ভাষণ, টেক্সট জেনারেশন) রিকারেন্ট নিউরাল নেটওয়ার্ক (RNNs) এবং পরে LSTMs (লং শর্ট-টার্ম মেমরি) দ্বারা আধিপত্য ছিল। মূল ধারণা ছিল সহজ: টেক্সট একটুকরো করে পড়া, একটি চলমান “মেমোরি” (হিডেন স্টেট) রাখা, এবং সেটি ব্যবহার করে পরবর্তীটা পূর্বানুমান করা।
একটি RNN বাক্যকে একটি চেইনের মতো প্রক্রিয়াকরণ করে। প্রতিটি ধাপে হিডেন স্টেট আপডেট হয় বর্তমান শব্দ ও পূর্ববর্তী হিডেন স্টেটের ওপর ভিত্তি করে। LSTM গেট যোগ করে—কি রাখা হবে, কি ভুলে যাবে, কি আউটপুট হবে—যাতে দরকারী সিগন্যাল দীর্ঘক্ষণ ধরে রাখা সহজ হয়।
ধাপে ধাপে মেমোরির একটি বটলনেক আছে: বাক্য লম্বা হলে অনেক তথ্যকে একটিই স্টেটে চাপাট্টি করে রাখতে হয়। LSTM সত্ত্বেও, দূরের পূর্ববর্তী শব্দের সিগন্যাল ম্লান হয়ে যেতে পারে বা ওভাররাইট হয়ে যেতে পারে।
ফলে নির্দিষ্ট সম্পর্কগুলো নির্ভরযোগ্যভাবে শেখা কঠিন—যেমন বহু শব্দ পেছনে থাকা একটি সর্বনামকে সঠিক নামের সাথে যুক্ত করা, বা বহু ক্লজ জুড়ে একটি বিষয় ট্র্যাক করা।
RNNs ও LSTMs প্রশিক্ষণে ধীর কারণ সময় ধরে সম্পূর্ণ প্যারালালাইজ করা যায় না। এক বাক্যের ভিতরে ধাপ ৫০ ধাপ ৪৯-এ নির্ভর করে, এবং তাই ওপরের ধাপগুলো শেষ না হলে পরের ধাপ চালানো যায় না।
বড় মডেল, বেশি ডেটা, ও দ্রুত পরীক্ষা-নিরীক্ষা করতে চাইলেই এই ধাপে-ধাপে কম্পিউটেশন বড় সীমাবদ্ধতা হয়ে দাঁড়ায়।
গবেষকরা এমন একটি নকশা চেয়েছিলেন যা শব্দগুলোকে একে অপরের সঙ্গে সম্পর্কিত করতে পারে গ্রেড-রাইট-টু-লেফট ধাঁচে না গিয়ে—একটি উপায় যাতে দীর্ঘ-দূরত্বের সম্পর্ক সরাসরি মডেল করা যায় এবং আধুনিক হার্ডওয়্যারের সুবিধা নেওয়া যায়। এই চাপই Attention Is All You Need পেপারের মাধ্যমে attention-প্রথম পন্থাকে প্রস্তুত করে।
অ্যাটেনশন মডেলের প্রশ্ন: “এই মুহূর্তে এই শব্দটি বোঝার জন্য আমাকে অন্য কোন শব্দগুলো দেখতে হবে?”
ধাপে ধাপে পড়ার বদলে, attention মডেলটিকে সেই মুহূর্তে সবচেয়ে প্রাসঙ্গিক অংশগুলোতে তাকাতে দেয়।
সহজ একটি মানসিক মডেল হল বাক্যের ভেতরে একটি ছোট সার্চ ইঞ্জিন চলা:
মডেলটি প্রতিটি পজিশনের জন্য একটি কোয়ারী গঠন করে, সব পজিশনের কী-র সঙ্গে তুলনা করে, তারপর ভ্যালুগুলোর একটি ওজনযুক্ত মিশ্রণ রিটারিভ করে।
এই তুলনাগুলো প্রাসঙ্গিকতা স্কোর দেয়: কতটা সম্পর্কিত তা। মডেল এগুলোকে অ্যাটেনশন ওয়েট-এ রূপান্তর করে, যা একে অপরের যোগফল 1 করে।
যদি একটি শব্দ অত্যন্ত প্রাসঙ্গিক হয়, তা বেশি ভবনের কেন্দ্র পায়; যদি কয়েকটি শব্দই গুরুত্বপূর্ণ হয়, অ্যাটেনশন সেগুলোতে ছড়িয়ে পড়তে পারে।
নিন: “Maria told Jenna that she would call later.”
she বোঝার জন্য মডেলটি “Maria” এবং “Jenna”–এর দিকে ফিরে দেখতে হবে। অ্যাটেনশন প্রাসঙ্গিক নামটিকে উচ্চ ওজন দেয়।
অথবা: “The keys to the cabinet are missing.” এখানে অ্যাটেনশন “are”–কে “keys” (সঠিক বিষয়)–এর সাথে যুক্ত করতে সাহায্য করে, “cabinet” নয়—যদিও “cabinet” কাছাকাছি। মূল সুবিধা: অ্যাটেনশন দূরত্ব জুড়ে অর্থ-সংযোগ করে, প্রয়োজনে।
সেলফ-অ্যাটেনশন মানে প্রতিটি টোকেন একই সিকোয়েন্সের অন্য টোকেনগুলোকে দেখে সিদ্ধান্ত নেয় কী গুরুত্বপূর্ণ। পুরনো রিকারেন্ট মডেলের মতো বাঁয়ে-দিকে একটি স্টেপ করে প্রসেস করার বদলে, ট্রান্সফরমার প্রতিটি টোকেনকে যে কোনো জায়গা থেকে ইঙ্গিত সংগ্রহ করতে দেয়।
ধরা যাক বাক্য: “I poured the water into the cup because it was empty.” এখানে “it”–কে “cup”–এর সাথে যুক্ত করা উচিত, “water”–এর নয়। সেলফ-অ্যাটেনশনের মাধ্যমে “it” টোকেনটি এমনটিই করে: তার প্রাসঙ্গিক টোকেনগুলো (cup, empty)–কে উচ্চ ওজন দেয় এবং অনাবশ্যকগুলোকে কম।
সেলফ-অ্যাটেনশনের পরে প্রতিটি টোকেন আর কেবল নিজের পরিচয় বহন করে না। এটি একটি প্রসঙ্গ-জ্ঞানযুক্ত সংস্করণে রূপ নেয়—বাকি বাক্যের তথ্যের ওজনযুক্ত মিশ্রণ। প্রতিটি টোকেন যেন তার জন্য নির্দিষ্ট করা সারাংশ তৈরি করে, যা সেই টোকেনের প্রয়োজন অনুযায়ী টিউন করা।
প্রায়োগিকভাবে, “cup”–এর প্রতিনিধিত্বে “poured”, “water”, এবং “empty”–এর সিগন্যাল থাকতে পারে, আর “empty” তার বর্ণনায় কি আছে তা টেনে আনতে পারে।
প্রতিটি টোকেন একই সময়ে পুরো সিকোয়েন্সের উপর তার অ্যাটেনশন গণনা করতে পারে, তাই প্রশিক্ষণের জন্য আগের টোকেনগুলো শেষ হওয়ার অপেক্ষা করতে হয় না। এই প্যারালাল প্রক্রিয়াকরণ ট্রান্সফরমারকে বড় ডেটাসেটে দক্ষভাবে ট্রেন করতে দেয় এবং বিশাল মডেলে স্কেল করতে সাহায্য করে।
সেলফ-অ্যাটেনশন দূরবর্তী টেক্সট অংশগুলোকে সহজে সংযুক্ত করে। একটি টোকেন সরাসরি দূরে থাকা প্রাসঙ্গিক শব্দটির উপর ফোকাস করতে পারে—দীর্ঘ গুণাবলীর মধ্য দিয়ে তথ্য পাস করাতে হয় না।
এই সরাসরি পথ কোররেফারেন্স, বহু অনুচ্ছেদ জুড়ে বিষয় ট্র্যাকিং, এবং পূর্ববর্তী বিস্তারিত নির্ভর করে নির্দেশনা হ্যান্ডল করার মতো কাজগুলোতে সাহায্য করে।
একক অ্যাটেনশন মজবুত হলেও, এটি অনেকটা একটাই ক্যামেরা অ্যাঙ্গেল দিয়ে কথোপকথন বোঝার মতো। বাক্যগুলোতে সাধারণত একাধিক সম্পর্ক থাকে: কে কি করেছে, “it” কীকে নির্দেশ করছে, কোন শব্দ টোন সেট করে, এবং মোট বিষয় কী—সবকিছুই একসাথে দেখা লাগে।
“The trophy didn’t fit in the suitcase because it was too small,”—এমন বাক্যে একসঙ্গে বহু ক্লু ধরতে হয় (বাক্য রচনা, অর্থ, বাস্তব বিশ্ব কন্টেক্সট)। একটি হেড কাছে থাকা নামেই আটকে যেতে পারে; আরেকটি হেড ক্রিয়া ফ্রেজ দেখে সিদ্ধান্ত নিতে পারে।
মাল্টি-হেড অ্যাটেনশন একাধিক অ্যাটেনশন গণনা সমান্তরালে চালায়। প্রতিটি “হেড” বাক্যটিকে ভিন্ন লেন্স দিয়ে দেখতে উৎসাহিত হয়—সবচেয়ে সাধারণভাবে বলা হয় বিভিন্ন সাবস্পেসে। বাস্তবে, হেডগুলো আলাদা প্যাটার্নে বিশেষায়িত হতে পারে, যেমন:
প্রতিটি হেড তার নিজস্ব ইনসাইট দেয়। এরপর মডেল হেড আউটপুটগুলো জোড়া লাগিয়ে (কনক্যাটেনেট) তাদেরকে একটি লিয়ার দিয়ে আবার মডেলের মেইন স্পেসে প্রজেক্ট করে।
একে বলা যায়, বিভিন্ন আংশিক নোটগুলোকে এক পরিষ্কার সারাংশে মিশিয়ে পরবর্তী লেয়ার ব্যবহার করে। পরিণামে এমন একটি প্রতিনিধিত্ব তৈরি হয় যা একাধিক সম্পর্ক একসঙ্গে ধরতে পারে—ট্রান্সফরমারগুলির বড় মাপের কার্যকারিতার অন্যতম কারণ।
সেলফ-অ্যাটেনশন সম্পর্ক খুঁজে পেতে ভালো—কিন্তু নিজের মধ্যে ক্রমের ধারণা নেই। যদি আপনি শব্দগুলো ভাঁজ করেন, একটি সাধারণ সেলফ-অ্যাটেনশন লেয়ার ভাঁজ করা সংস্করণটিকেও সমান হিসেবে দেখতে পারে, কারণ এটি টোকেনগুলোকে কোনো স্থান নির্দেশ ছাড়া তুলনা করে।
পজিশনাল এনকোডিং এই সমস্যা সমাধান করে: টোকেন প্রতিনিধিত্বে “আমি সিকোয়েন্সে কোথায় আছি?”—তথ্য ঢুকিয়ে। পজিশন যোগ হলে attention এমন প্যাটার্ন শিখতে পারে যেমন “not”–এর পরের শব্দ গুরুত্বপূর্ণ” বা “সাধারণত সাবজেক্ট ক্রিয়া-র আগে আসে” ইত্যাদি।
মূল ধারণা সহজ: প্রতিটি টোকেন এম্বেডিং ট্রান্সফরমার ব্লকে প্রবেশ করার আগে একটি পজিশন সিগন্যালের সঙ্গে মিলিত হয়। সেই পজিশন সিগন্যালকে টোকেনকে 1st, 2nd, 3rd… ইত্যাদি হিসেবে ট্যাগ করা যায় এমন অতিরিক্ত ফিচার হিসেবে ভাবা যায়।
কমন পদ্ধতিগুলো:
পজিশনাল পছন্দগুলো দীর্ঘ কনটেক্সট মডেলিংয়ে লক্ষণীয় প্রভাব ফেলতে পারে—যেমন দীর্ঘ রিপোর্ট সারাংশ করা, বহু অনুচ্ছেদ জুড়ে সত্তা ট্র্যাক করা, বা হাজার টোকেনের আগের কোনো তথ্য পুনরুদ্ধার করা।
লক্ষ্য করুন: পজিশনাল এনকোডিং শুধু ভাষা শেখায় না; এটি মডেলকে ‘কোথায় দেখবে’ তাও শেখায়। রিলেটিভ ও রোটারি-স্টাইল স্কিমগুলো প্রায়শই দূর-অস্থানে টোকেন তুলনা করা সহজ করে এবং কনটেক্সট বাড়ার সঙ্গে প্যাটার্ন রক্ষা করে, যেখানে কিছু অ্যাবসোলুট স্কিম প্রশিক্ষণ উইন্ডো ছাড়িয়ে গেলে দ্রুতগতিতে অবনতি হতে পারে।
বাস্তবে, পজিশনাল এনকোডিং এমন একটা নীরব ডিজাইন সিদ্ধান্ত যা নির্ধারণ করে আপনার LLM 2,000 টোকেনে কতটা ধারাবাহিক মনে হয়—এবং 100,000 টোকেনেও কেমন ধারাবাহিক থাকে।
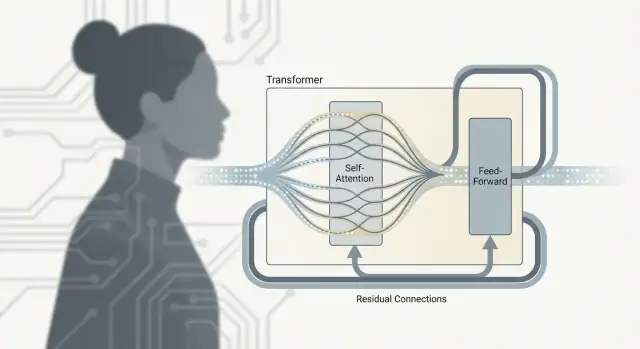
ট্রান্সফরমার কেবল “অ্যাটেনশন” নয়। প্রকৃত কাজ ঘটে একটি পুনরাবৃত্ত ইউনিটে—প্রায়শই ট্রান্সফরমার ব্লক বলা হয়—যা টোকেনগুলোর মধ্যে তথ্য মেশায় এবং তারপর তা পরিমার্জন করে। অনেকগুলো ব্লক স্ট্যাক করলে আপনি সেই গভীরতা পান যা বড় ভাষার মডেলগুলোকে সক্ষম করে তোলে।
সেলফ-অ্যাটেনশন হলো যোগাযোগ ধাপ: প্রতিটি টোকেন প্রসঙ্গ সংগ্রহ করে।
ফিড-ফরওয়ার্ড নেটওয়ার্ক (FFN), যাকে MLP ও বলা হয়, হলো চিন্তা ধাপ: এটি প্রতিটি টোকেনের আপডেট হওয়া প্রতিনিধিত্ব নিয়ে একই ছোট নিউরাল নেটওয়ার্কটি আলাদাভাবে চালায়।
সরলভাবে, FFN প্রতিটি টোকেন যা জানে সেটিকে রূপান্তরিত করে, যাতে মডেল প্রসঙ্গ সংগ্রহের পরে সমৃদ্ধ ফিচার (উদাহরণস্বরূপ সিনট্যাক্স প্যাটার্ন, তথ্য বা স্টাইল কিউ) গড়ে তুলতে পারে।
দুটো অংশের কাজ আলাদা হওয়ায় এই পর্যায়ক্রমিক বিন্যাস গুরুত্বপূর্ণ:
এই প্যাটার্ন বারবার করলে মডেল ধাপে ধাপে উচ্চ-স্তরের মানে গঠনে সক্ষম হয়: যোগাযোগ → গণনা → আবার যোগাযোগ → গণনা।
প্রতিটি সাব-লেয়ার (অ্যাটেনশন বা FFN) একটি রেসিডুয়াল সংযোগ নিয়ে মোড়ানো: ইনপুট আউটপুটে ফেরত যোগ করা হয়। এটি গভীর মডেলগুলিকে প্রশিক্ষণে সাহায্য করে কারণ গ্রেডিয়েন্টগুলো “স্কিপ লেইন” দিয়ে প্রবাহিত হতে পারে এমনকি যদি কোনো নির্দিষ্ট লেয়ার এখনও শেখা শেষ না করে। এছাড়াও একটি লেয়ারকে সবকিছু আবার শেখার বদলে ছোট পরিবর্তন করার সুযোগ দেয়।
লেয়ার নরমালাইজেশন একটি স্থিতিশীলকারী যা বহু লেয়ারের মধ্য দিয়ে অ্যাক্টিভেশনগুলো খুব বড় বা খুব ছোট হয়ে যাছাই না হয় তা নিশ্চিত করে। এটি ভলিউম লেভেল কনসিস্টেন্ট রাখে যাতে পরে লেয়ারগুলো সিগন্যাল নিয়ে অভিভূত বা অভাবগ্রস্ত না হয়—বিশেষ করে LLM স্কেলে প্রশিক্ষণকে মসৃণ ও নির্ভরযোগ্য করে তোলে।
মূল ট্রান্সফরমার Attention Is All You Need–এ মেশিন-ট্রান্সলেশনের জন্য তৈরি করা হয়েছিল—এখানে এক সিকোয়েন্স (ফরাসি) অন্য (ইংরেজি)–এ রূপান্তর করতে হয়। কাজটি স্বাভাবিকভাবেই দুইটি ভূমিকার মধ্যে ভাগ করে দেয়: ইনপুটটা ভালভাবে পড়া এবং আউটপুটটি সাবলীলভাবে লেখা।
এনে এনকোডার পুরো ইনপুট বাক্য একসাথে প্রক্রিয়াকরণ করে এবং সমৃদ্ধ প্রতিনিধিত্ব দেয়। ডিকোডার পরে ধাপে ধাপে আউটপুট তৈরি করে। গুরুত্বপূর্ণভাবে, ডিকোডার কেবল নিজের পূর্বের টোকেনের ওপর নির্ভর করে না; এটি এনকোডারের আউটপুটেও ক্রস-অ্যাটেনশন করে যাতে সোর্স টেক্সটে ভিত্তি পায়।
এই সেটআপটি এখনো ভালো যখন আপনাকে নির্দিষ্ট ইনপুট শক্তভাবে কন্ডিশন করতে হয়—অনুবাদ, সারাংশ, বা নির্দিষ্ট প্যাসেজ সহ প্রশ্নোত্তর।
আধুনিক বেশিরভাগ LLM হলো ডিকোডার-অনলি। এরা পরবর্তী টোকেন অনুমান করার সহজ কিন্তু শক্তিশালী টাস্কে প্রশিক্ষিত—এবং এজন্য কজাল (মাস্কড) সেলফ-অ্যাটেনশন ব্যবহার করে। প্রতিটি পজিশন কেবল পূর্ববর্তী টোকেনগুলোকেই দেখতে পারে যাতে জেনারেশন লেফট-টু-রাইট ধারাবাহিক থাকে।
এটি LLM-এর জন্য প্রধান কারণ: বিশাল টেক্সট কর্পাসে প্রশিক্ষণ করা সহজ, জেনারেশন ইউজকেসের সাথে মেলে, এবং ডেটা ও কম্পিউটের সঙ্গে কার্যকরভাবে স্কেল করে।
এনকোডার-অনলি ট্রান্সফরমার (যেমন BERT-স্টাইল) টেক্সট জেনারেট করে না; এগুলো ইনপুটটিকে দু-পাশে দেখে। এগুলো ক্লাসিফিকেশন, সার্চ, এম্বেডিংস—যেমন যেখানে টেক্সট বোঝাটা দীর্ঘ কন্টেক্সটের তুলনায় বেশি গুরুত্বপূর্ণ—এর জন্য দুর্দান্ত।
ট্রান্সফরমারগুলো অস্বাভাবিকভাবে স্কেল-ফ্রেন্ডলি: যদি আপনি তাদেরকে বেশি টেক্সট, বেশি কম্পিউট, এবং বড় মডেল দিন, তারা নির্ধারিতভাবে উন্নতি করে।
এক বড় কারণ হলো গঠনগত সরলতা। একটি ট্রান্সফরমার পুনরাবৃত্ত ব্লকগুলোর (সেলফ-অ্যাটেনশন + ছোট ফিড-ফরওয়ার্ড) সমষ্টি, এবং এই ব্লকগুলো একই রকম আচরণ করে আপনি মিলিয়ন শব্দ বা ট্রিলিয়ন শব্দে প্রশিক্ষণ দিলেও।
পূর্ববর্তী সিকোয়েন্স মডেলগুলো (যেমন RNNs) টোকেনগুলো ধাপে ধাপে প্রক্রিয়াকরণ করত, যা একই সঙ্গে অনেক কাজ করার সক্ষমতা সীমিত করে। ট্রান্সফরমারগুলো প্রশিক্ষণের সময় পুরো সিকোয়েন্সের টোকেনগুলো একসাথে প্রক্রিয়াকরণ করতে পারে।
এটাই GPU/TPU ও বড় ডিস্ট্রিবিউটেড সেটআপের জন্য আদর্শ—সেইগুলোই আধুনিক LLM ট্রেনিংয়ের জন্য প্রয়োজন।
কনটেক্সট উইন্ডো হলো মডেল একসাথে “দেখতে” পারে এমন টেক্সটের অংশ—আপনার প্রম্পট ও সাম্প্রতিক কথোপকথন বা ডকুমেন্ট টেক্সট। বড় উইন্ডো মডেলকে আরো বাক্য বা পৃষ্ঠা জুড়ে ধারাবাহিক ধারণা যুক্ত করতে দেয়, শর্তাবলি ধরে রাখতে সাহায্য করে, এবং পূর্বের বিবরণের ওপর নির্ভর করে প্রশ্নের উত্তর দিতে পারি।
কিন্তু কনটেক্সট বিনামূল্যের নয়।
সেলফ-অ্যাটেনশন টোকেনগুলোর মধ্যে তুলনা করে। সিকোয়েন্স লম্বা হলে তুলনাগুলোর সংখ্যা দ্রুত বাড়ে (প্রায় আদর্শভাবে সিকোয়েন্স-দৈর্ঘ্যের বর্গ অনুযায়ী)।
এই কারণেই অত্যন্ত দীর্ঘ কনটেক্সট উইন্ডো মেমরি ও কম্পিউটের দিক থেকে ব্যয়বহুল হয়ে ওঠে, এবং অনেক আধুনিক প্রচেষ্টা অ্যাটেনশনকে আরও কার্যকর করার দিকে মনোনিবেশ করে।
ট্রান্সফরমারগুলো বড় আকারে প্রশিক্ষিত হলে তারা কেবল একটি সুনির্দিষ্ট টাস্কেই ভাল হয় না। তারা প্রায়ই বিস্তৃত, নমনীয় ক্ষমতা দেখায়—সারসংক্ষেপ, অনুবাদ, লেখা, কোডিং, ও যুক্তি-প্রয়োগ—কারণ একই সাধারণ শিক্ষা যন্ত্রপাতি বিশাল, বৈচিত্র্যময় ডেটায় লাগানো হয়।
মূল ট্রান্সফরমার নকশা এখনও রেফারেন্স, কিন্তু বেশিরভাগ প্রোডাকশন LLM হলো “ট্রান্সফরমার প্লাস”: ছোট, বাস্তবসম্মত সম্পাদনা যা মূল ব্লক (অ্যাটেনশন + MLP) রাখে কিন্তু গতি, স্থিতিশীলতা, বা কনটেক্সট দৈর্ঘ্য বাড়ায়।
অনেক আপগ্রেডের মূলে আছে প্রশিক্ষণ ও রানটাইমকে উন্নত করা:
এই পরিবর্তনগুলো সাধারণত মডেলের “ট্রান্সফরমার-ness” বদলায় না—এইগুলো কেবল সেটিকে পরিমার্জন করে।
কয়েক হাজার টোকেন থেকে কয়েক ত্রিশ বা লক্ষ টোকেনে প্রসারিত করতে সাধারণত হয় স্পার্স অ্যাটেনশন (নির্বাচিত টোকেনগুলোতে শুধু মনোযোগ) অথবা কার্যকরী অ্যাটেনশন ভ্যারিয়েন্ট (অ্যাপ্রক্সিমেট বা পুনর্গঠন করে যাতে কম্পিউট কমে)।
ট্রেড-অফ সাধারণত নির্ভুলতা, মেমরি, ও প্রকৌশল জটিলতার মিশ্রণ।
MoE মডেলগুলো একাধিক “এক্সপের্ট” সাব-নেটওয়ার্ক যোগ করে এবং প্রতিটি টোকেনকে কেবল কয়েকটি এক্সপের্টের মধ্য দিয়ে রাউট করে। ধারণাতে: আপনি বড় কগনিটিভ ক্যাপাসিটি পান, কিন্তু প্রতিবার সবকিছু সক্রিয় করতে হয় না।
এটি নির্দিষ্ট পরামিতি গননা অনুযায়ী প্রতি টোকেন কম্পিউট কমাতে পারে, কিন্তু সিস্টেম জটিলতা (রাউটিং, এক্সপের্ট ব্যালান্সিং, সার্ভিং) বাড়ায়।
যখন কোনো মডেল নতুন ট্রান্সফরমার ভ্যারিয়েন্টের ঘোষণা করে, তাহলে জিজ্ঞাসা করুন:
বেশিরভাগ উন্নতি বাস্তব—কিন্তু খুব কমই বিনামূল্যে।
সেলফ-অ্যাটেনশন ও স্কেলিংয়ের ধারণাগুলো আকর্ষণীয়—কিন্তু প্রোডাক্ট টিমরা এগুলোকে বেশিরভাগ ক্ষেত্রে ট্রেড-অফ হিসেবে অনুভব করে: কতটুকু টেক্সট ইনপুট করা যায়, উত্তর কত দ্রুত মেলে, এবং প্রতি রিকোয়েস্টে খরচ কত।
কনটেক্সট দৈর্ঘ্য: বড় কনটেক্সট আপনাকে আরও ডকুমেন্ট, চ্যাট ইতিহাস এবং নির্দেশাবলী যোগ করতে দেয়। তবে এটি টোকেন খরচ বাড়ায় এবং প্রতিক্রিয়া ধীর হতে পারে। যদি আপনার ফিচার “৩০ পৃষ্ঠা পড়ে উত্তর দাও”–র মতো হয়, তাহলে কনটেক্সট দৈর্ঘ্যকে অগ্রাধিকার দিন।
ল্যাটেন্সি: ইউজার-ফেসিং চ্যাট ও কোপাইলট অভিজ্ঞতা প্রতিক্রিয়া সময়ে বেঁধে থাকে। স্ট্রিমিং আউটপুট সাহায্য করে, কিন্তু মডেল পছন্দ, অঞ্চল, ও ব্যাচিংও প্রভাব ফেলে।
খরচ: মূল্য সাধারণত টোকেন (ইনপুট + আউটপুট) অনুযায়ী। ১০% ভাল মডেল কখনো কখনো ২–৫× বেশি খরচ হতে পারে। মূল্য-স্টাইল তুলনা ব্যবহার করে নির্ধারণ করুন কোন মান পর্যায় আপনাকে মূল্য দিতে ইচ্ছুক।
গুণমান: আপনার কাজে গুণমান কী—তথ্যগত সঠিকতা, নির্দেশ-অনুসরণ, টোন, টুল-ব্যবহার, বা কোড—এগুলো স্পষ্টভাবে নির্ধারণ করুন এবং আপনার ডোমেইনের বাস্তব উদাহরণ দিয়ে মূল্যায়ন করুন।
যদি আপনার প্রধান কাজ হয় সার্চ, ডেডুপ, ক্লাস্টারিং, রিকমেন্ডেশন, বা “সদৃশ খুঁজে পাওয়া”, এম্বেডিংস (সাধারণত এনকোডার-স্টাইল মডেল) সাধারণত সস্তা, দ্রুত এবং স্থিতিশীল। জেনারেশন শুধুমাত্র শেষ ধাপে (সারাংশ, ব্যাখ্যা, খসড়া) ব্যবহার করুন।
আরও গভীর ভাঙন চাইলে দেখুন: /blog/embeddings-vs-generation
ট্রান্সফরমার ক্ষমতাগুলোকে প্রোডাক্টে রূপান্তর করার সময় কঠিন অংশ সাধারণত আর্কিটেকচারের চেয়ে বেশি ওয়ার্কফ্লো-সংক্রান্ত: প্রম্পট পরিগ্রহণ, গ্রাউন্ডিং, মূল্যায়ন, এবং নিরাপদ ডিপ্লয়মেন্ট।
একটি ব্যবহারিক পথ হল Koder.ai এর মতো একটি ভিব-কোডিং প্ল্যাটফর্ম ব্যবহার করা যাতে দ্রুত প্রোটোটাইপ ও LLM-সক্ষম ফিচার শিপ করা যায়: আপনি চ্যাটে ওয়েব অ্যাপ, ব্যাকএন্ড এন্ডপয়েন্ট, এবং ডাটা মডেল বর্ণনা করতে পারেন, প্ল্যানিং মোডে পুনরাবৃত্তি করতে পারেন, এবং তারপর সোর্স কোড এক্সপোর্ট বা হোস্টিংসহ ডিপ্লয় করতে পারেন—কাস্টম ডোমেইন ও স্ন্যাপশট-ভিত্তিক রোলব্যাক দিয়ে। এটা বিশেষভাবে উপকারী যখন আপনি রিট্রাইভাল, এম্বেডিংস, বা টুল-ককল লুপ নিয়ে পরীক্ষা-নিরীক্ষা করছেন এবং বারবার সেইই স্কেলফোল্ডিং ছাড়া দ্রুত ইটারেশন করতে চান।
একটি ট্রান্সফরমার হলো একটি নিউরাল নেটওয়ার্ক আর্কিটেকচার যা ক্রমবদ্ধ ডেটার জন্য তৈরি এবং যেখানে সেলফ-অ্যাটেনশন প্রতিটি টোকেনকে একই ইনপুটের অন্যান্য টোকেনের সঙ্গে সম্পর্ক স্থাপন করতে দেয়।
RNNs/LSTMs-এর মতো ধাপে ধাপে তথ্য বহন করার বদলে, এটি সমগ্র সিকোয়েন্স জুড়ে সিদ্ধান্ত নেয় কিসে মনোযোগ দিতে হবে, ফলে দীর্ঘ-মেয়াদী বোঝাপড়া উন্নত হয় এবং প্রশিক্ষণ প্যারালালাইজেশনের জন্য সহজ হয়।
RNNs এবং LSTMs টেক্সটকে প্রতিটি টোকেন একবারে প্রক্রিয়াকরণ করত, ফলে প্রশিক্ষণে প্যারালালাইজেশন কঠিন ছিল এবং দূরবর্তী নির্ভরশীলতা ম্যানেজ করা কঠিন হত।
ট্রান্সফরমার attention ব্যবহার করে দূরবর্তী টোকেনগুলোকে সরাসরি সংযুক্ত করে এবং প্রশিক্ষণের সময় অনেক টোকেন-টু-টোকেন ইন্টারঅ্যাকশন একসাথে গণনা করতে পারে—যা বড় ডেটা ও কম্পিউটে দ্রুত স্কেল করার সুযোগ দেয়।
অ্যাটেনশন হলো সেই পদ্ধতি যা জিজ্ঞেস করে: “এই মুহূর্তে এই টোকেনটি বুঝতে অন্য কোন টোকেনগুলো সবচেয়ে প্রাসঙ্গিক?”
মনে করুন এটা বাক্যের মধ্যে একটি ছোট সার্চ ইঞ্জিন:
আউটপুট হয় প্রাসঙ্গিক টোকেনগুলোর ওজনহীন মিশ্রণ, যা প্রতিটি পজিশনের জন্য প্রসঙ্গ-জ্ঞানযুক্ত প্রতিনিধিত্ব দেয়।
সেলফ-অ্যাটেনশন মানে একই সিকোয়েন্সের টোকেনগুলো একে অপরকে দেখে—অর্থাৎ প্রতিটি পজিশন একই ইনপুটে অন্য টোকেনগুলোর ওপর মনোযোগ দিতে পারে।
এটি কোররেফারেন্স বোঝা (যেমন কোন শব্দটি “it”-এর রেফারেন্স), সাবজেক্ট–ভিব্ সম্পর্ক, এবং টেক্সটের মধ্যে দূরবর্তী নির্ভরশীলতা সহজ করে—সবকিছুই একক পুনরাবৃত্তিমূলক ‘মেমোরির’ ওপর নির্ভর না করে।
মাল্টি-হেড অ্যাটেনশন একাধিক অ্যাটেনশন হিসাবকে সমান্তরালে চালায়, এবং প্রতিটি হেড আলাদা ধরণের প্যাটার্নে বিশেষায়িত হতে পারে।
প্রতিটি হেড ভিন্ন সম্পর্ক ধরতে পারে (সিনট্যাক্স, দূরবর্তী লিংক, সর্বনাম-রিফারেন্স, টপিক সংক্রান্ত সংকেত ইত্যাদি)। পরে এই হেডগুলোর আউটপুটগুলো কনক্যাটেনেট করে একটি একক প্রতিনিধিত্বে প্রজেক্ট করা হয়—যাতে একসময় বিভিন্ন ধরনের সম্পর্ক ধরার ক্ষমতা থাকে।
সেলফ-অ্যাটেনশনের নিজস্বভাবে টোকেন ক্রম জানার কোনো অন্তর্নিহিত উপায় নেই—শব্দগুলো যদি শাফল করা হয়, সাধারণ সেলফ-অ্যাটেনশন সেটা সমতুল্য মনে করতে পারে।
পজিশনাল এনকোডিং টোকেন এম্বেডিংয়ে ‘আমি ক্রমে কোথায় আছি’—এই তথ্য যোগ করে, যাতে মডেল যেমন “not”-এর পরের শব্দের গুরুত্ব বা সাধারণত সাবজেক্ট-বরত ক্রম ইত্যাদি ধরতে পারে।
প্রচলিত পদ্ধতিগুলো:
একটি ট্রান্সফরমার ব্লকে সাধারণত থাকে:
অ্যাটেনশন ও FFN-বিকল্পের পুনরাবৃত্তি মিলে মডেল ধীরে ধীরে উচ্চ-স্তরের মানে তৈরি করে—প্রথমে যোগাযোগ, তারপর স্থানীয় প্রক্রিয়াকরণ, এবং তা নানাভাবে পুনরাবৃত্তি হয়।
মূল কাগজে (Attention Is All You Need) ট্রান্সফরমারটি একটি এনকোডার–ডিকোডার আর্কিটেকচার হিসেবে এসেছে: ইনপুট পড়ে (এনকোডার) এবং আউটপুট ধাপে ধাপে তৈরি করে (ডিকোডার) যেখানে ডিকোডার ক্রস-অ্যাটেনশনের মাধ্যমে এনকোডারের আউটপুট দেখে।
কিন্তু আধুনিক বেশিরভাগ LLM হল ডিকোডার-অনলি মডেল, যা পরবর্তী টোকেন পূর্বাভাস করার জন্য প্রশিক্ষিত এবং কজাল (মাস্কড) সেলফ-অ্যাটেনশন ব্যবহার করে—লেফট-টু-রাইট জেনারেশনের সাথে খাপ খায় এবং বড় কর্পাসে স্কেল করা সহজ।
এনকোডার-অনলি (যেমন BERT ধাঁচ) মডেলগুলো সাধারণত ক্লাসিফিকেশন, সার্চ, এম্বেডিংস ইত্যাদির জন্য ভাল।
ট্রান্সফরমারগুলো স্কেলিং-ফ্রেন্ডলি কারণ এগুলো পুনরাবৃত্ত ব্লক (সেলফ-অ্যাটেনশন + ছোট FFN) থেকে গঠিত, এবং এই ব্লকগুলো অনস্বীকার্যভাবে বড় ডেটা ও কম্পিউটের সঙ্গে ভাল আচরণ করে।
বড় কারণ হলো প্রশিক্ষণের প্যারালালাইজেশন—প্রতিটি সিকোয়েন্সের টোকেনগুলো প্রশিক্ষণের সময় একসাথে প্রক্রিয়াকরণ করা যায়, যা GPU/TPU-ভিত্তিক ডিস্ট্রিবিউটেড ট্রেইনিংয়ের জন্য আদর্শ।
তবে কনটেক্সট উইন্ডোর খরচ বেড়ে যায়—অ্যাটেনশনের তুলনা সংখ্যা প্রায় সিকোয়েন্স লম্বার বর্গের সাথে বাড়ে, তাই দীর্ঘ কনটেক্সট মেমরি ও কম্পিউট দিক থেকে ব্যয়বহুল।
আধুনিক মডেলগুলো মূল ট্রান্সফরমার নকশাকেই ধরে রাখে, কিন্তু প্রশিক্ষণ ও inference-কে দ্রুত, স্থিতিশীল ও দীর্ঘ কনটেক্সট-সমর্থনশীল করে তোলার জন্য ছোট ছোট বদল আসে:
দীর্ঘ কনটেক্সট বাড়ানোর জন্য সাধারণ পদ্ধতিগুলো হলো স্পার্স অ্যাটেনশন, কার্যকরী অ্যাটেনশন ভ্যারিয়েন্ট, অথবা মিশ্র-এক্সপের্ট (MoE) মডেল—যেখানে প্রতিটি টোকেনকে মাত্র কিছু বিশেষজ্ঞের মধ্য দিয়ে রাউট করা হয়।
ট্রান্সফরমার ধারণা বাস্তবে গেলে প্রোডাক্ট টিমগুলো এটি ট্রেড-অফ হিসেবে অনুভব করে: কতটা টেক্সট ইনক্লুড করা যাবে, প্রতিক্রিয়া কত দ্রুত মিলবে, এবং প্রতি রিকোয়েস্টে খরচ কত।
একটি ব্যবহারিক চেকলিস্ট:
লম্বা কনটেক্সট কাজে পজিশনাল কৌশলটি ফলাফলে বড় প্রভাব ফেলতে পারে।
যদি আপনার কাজটি মূলত সার্চ, ক্লাস্টারিং, রিকমেন্ডেশন বা “সদৃশ খুঁজে পাওয়া” হয়, তাহলে এম্বেডিংস (এনকোডার-স্টাইল) প্রায়শই সস্তা, দ্রুত এবং স্থিতিশীল—জেনারেশনকে কেবল চূড়ান্ত ধাপে (সারাংশ, ব্যাখ্যা) ব্যবহার করুন।
আরও বিস্তারিত জন্য দেখুন: /blog/embeddings-vs-generation