১৮ ডিসে, ২০২৫·7 মিনিট
Postgres স্কিমা ডিজাইন পরিকল্পনা মোড: ধাপে ধাপে পদ্ধতি
Postgres স্কিমা পরিকল্পনা মোড আপনাকে এনটিটি, কনস্ট্রেইন্ট, ইনডেক্স এবং মাইগ্রেশন কোড জেনারেশনের আগে নির্ধারণ করতে সাহায্য করে—পরে রি-রাইট কমায়।
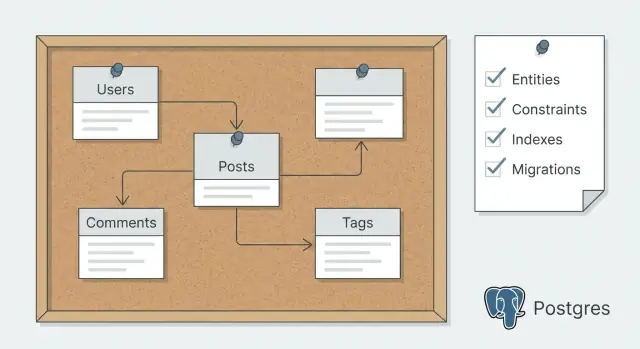
Postgres স্কিমা পরিকল্পনা মোড আপনাকে এনটিটি, কনস্ট্রেইন্ট, ইনডেক্স এবং মাইগ্রেশন কোড জেনারেশনের আগে নির্ধারণ করতে সাহায্য করে—পরে রি-রাইট কমায়।
যদি আপনি ডাটাবেসের কাঠামো পরিষ্কার না থাকা অবস্থায় এন্ডপয়েন্ট ও মডেল তৈরি করেন, বেশিরভাগ সময় একই ফিচার দুইবার রি-রাইট করতে হয়। ডেমোর জন্য অ্যাপ কাজ করলেও বাস্তব ডেটা ও এজ-কেস আসলে সবকিছু ভঙ্গুর মনে হতে শুরু করে।
বেশিরভাগ রি-রাইট তিনটি পূর্বানুমেয় সমস্যার কারণে ঘটে:
প্রতিটি পরিবর্তন কোড, টেস্ট, এবং ক্লায়েন্ট অ্যাপে ছড়িয়ে দেয়।
Postgres স্কিমা পরিকল্পনা করার মানে হলো প্রথমে ডেটা কন্ট্রাক্ট নির্ধারণ করা, তারপর সেই অনুযায়ী কোড জেনারেট করা। বাস্তবে এর অর্থ হলো এনটিটি, সম্পর্ক, এবং কয়েকটি গুরুত্বপুর্ন কুয়েরি লিখে নেওয়া, তারপর কনস্ট্রেইন্ট, ইনডেক্স, এবং মাইগ্রেশন পদ্ধতি বেছে নেওয়া—যখনও টুল টেবিল বা CRUD স্ক্যাফোল্ড না করে।
এইটা আরো গুরুত্বপূর্ণ যখন আপনি Koder.ai মতো দ্রুত-জেনারেশন প্ল্যাটফর্ম ব্যবহার করেন। দ্রুত জেনারেশন ভালো, কিন্তু স্কিমা স্থির হলে তা অনেক বেশি নির্ভরযোগ্য হয়। আপনার জেনারেট করা মডেল ও এন্ডপয়েন্ট পরে কম পরিবর্তন চায়।
পরিকল্পনা না করলে সাধারণত এগুলোই ভুল হয়:
ভাল স্কিমা প্ল্যান সহজ: আপনার এনটিটিগুলোর সাধারণ ভাষায় বর্ণনা, টেবিল ও কলামের খসড়া, মূল কনস্ট্রেইন্ট ও ইনডেক্স, এবং একটি মাইগ্রেশন স্ট্র্যাটেজি যা প্রোডাক্ট বাড়ার সঙ্গে নিরাপদে বদল করতে দেয়।
স্কিমা পরিকল্পনা সবচেয়ে ভালো কাজ করে যখন আপনি অ্যাপকে কী মনে রাখতে হবে এবং ব্যবহারকারীরা ডেটা দিয়ে কী করতে পারবে তা দিয়ে শুরু করেন। লক্ষ্যটি 2–3 সহজ বাক্যে লিখুন। যদি সহজে ব্যাখ্যা না করতে পারেন, সম্ভবত অপ্রয়োজনীয় অতিরিক্ত টেবিল তৈরি করবেন।
এরপর, এমন অ্যাকশনগুলোর দিকে মনোযোগ দিন যেগুলো ডেটা তৈরি বা পরিবর্তন করে। এই অ্যাকশনগুলোই আসলে আপনার সারির উৎস এবং এরা বলে দেয় কী যাচাই করা দরকার। নিউনবাচক নয়—ক্রিয়াপদের দিকে চিন্তা করুন।
উদাহরণস্বরূপ, একটি বুকিং অ্যাপ বুকিং তৈরি করা, রিস্কেজিউল করা, বাতিল করা, রিফান্ড করা, এবং কাস্টমারকে মেসেজ করা লাগতে পারে। এই ক্রিয়াপদগুলো দ্রুত বলে দেয় কী সংরক্ষণ করা দরকার (টাইম স্লট, স্ট্যাটাস পরিবর্তন, টাকার পরিমাণ) টেবিলের নাম দেয়ার আগে।
আপনার রিড পাথগুলিও নোট করুন, কারণ রিড কাঠামো এবং ইনডেক্সিং চালায়। ব্যবহারকারীরা কোন স্ক্রিন বা রিপোর্ট আসলে ব্যবহার করবে এবং তারা কিভাবে ডেটাকে স্লাইস করবে তা তালিকা করুন: “My bookings” তারিখ অনুযায়ী সাজানো এবং স্ট্যাটাস দিয়ে ফিল্টার, অ্যাডমিন সার্চ কাস্টমার নাম বা বুকিং রেফারেন্স দিয়ে, লোকেশান অনুযায়ী দৈনিক আয়, এবং কার কখন কী বদলিয়েছে সেই অডিট ভিউ।
সবশেষে, নন-ফাংশনাল চাহিদাগুলো নোট করুন যা স্কিমা পছন্দ বদলে দেয়—যেমন অডিট ইতিহাস, সফট ডিলিট, মাল্টি-টেন্যান্সি, বা প্রাইভেসি নিয়ম (উদাহরণ: কাকে কন্ট্যাক্ট ডিটেইল দেখার অনুমতি আছে)।
যদি আপনি পরে কোড জেনারেট করতে যান, এই নোটগুলো শক্তিশালী প্রম্পট হয়ে যায়। এটা বলে দেয় কী লাগবে, কী পরিবর্তনশীল, এবং কী সার্চেবল হতে হবে। Koder.ai ব্যবহার করলে, জেনারেট করার আগে এগুলো লিখলে Planning Mode অনেক বেশি কার্যকর হয় কারণ প্ল্যাটফর্ম অনুমানের বদলে বাস্তব চাহিদা থেকে কাজ করে।
টেবিল ছোঁয়ার আগে আপনার অ্যাপ কী সংরক্ষণ করে তা সাধারণ ভাষায় লিখুন। প্রায়ই বারবার যেসব নাম আসে সেগুলো তালিকাভুক্ত করুন: user, project, message, invoice, subscription, file, comment। প্রতিটি নাম একটি সম্ভাব্য এনটিটি।
তারপর প্রতিটি এনটিটির জন্য একটি বাক্য যোগ করুন: এটা কী এবং কেন আছে? উদাহরণ: “A Project is a workspace a user creates to group work and invite others.” এটা অস্পষ্ট টেবিল যেমন data, items, বা misc এড়াতে সাহায্য করবে।
অধিকার (ownership) পরবর্তী বড় সিদ্ধান্ত এবং এটি প্রায় প্রতিটি কুয়েরিকে প্রভাবিত করে। প্রতিটি এনটিটির জন্য সিদ্ধান্ত নিন:
এখন সিদ্ধান্ত নিন কীভাবে রেকর্ড সনাক্ত করবেন। UUID ভাল যখন রেকর্ড বহু জায়গা থেকে তৈরি হতে পারে (ওয়েব, মোবাইল, ব্যাকগ্রাউন্ড জব) অথবা অনুমেয় আইডি চান না। Bigint ছোট ও দ্রুত। যদি মানুষ-মুখী আইডেন্টিফায়ার দরকার হয়, আলাদা রাখুন (যেমন একটি সংক্ষিপ্ত project_code যা অ্যাকাউন্টের মধ্যে ইউনিক) প্রাইমারি কী হিসেবে জোর না করে।
শেষে, সম্পর্কগুলো শব্দে লিখুন আগে ডায়াগ্রাম করার: a user has many projects, a project has many messages, এবং users অনেক projects-এ থাকতে পারে। প্রতিটি লিংককে required বা optional হিসাবে মার্ক করুন, যেমন “a message must belong to a project” বনাম “an invoice may belong to a project।” এই বাক্যগুলো পরে কোড জেনারেশনের জন্য সূত্র হবে।
যখন এনটিটিগুলো সাধারণ ভাষায় পরিষ্কার পড়ে, প্রতিটিকে একটি টেবিল হিসেবে রূপান্তর করুন এবং বাস্তব তথ্য ধরে রাখার জন্য কলামগুলো দিন।
নাম ও টাইপ নিয়ে এমন প্যাটার্ন বেছে নিন যা আপনি ধরে রাখতে পারবেন। অনুশাসন: snake_case কলাম নাম, একই ধারণার জন্য একই টাইপ, এবং পূর্বানুমেয় প্রাইমারি কী। টাইমস্ট্যাম্পের জন্য timestamptz ব্যবহার করুন যাতে টাইমজোন পরে সমস্যা না তৈরি করে। অর্থের জন্য numeric(12,2) (অথবা সেন্ট হিসেবে একটি integer) ব্যবহার করুন, float নয়।
স্ট্যাটাস ফিল্ডের জন্য Postgres enum বা text কলাম + CHECK কনস্ট্রেইন্ট বেছে নিন যাতে অনুমোদিত মানগুলো নিয়ন্ত্রিত হয়।
কোনটা required বা optional হবে তা NOT NULL এ অনুবাদ করে সিদ্ধান্ত নিন। যদি একটি মান না থাকলে সারি অর্থহীন হয়, তাহলে তা required করুন; যদি আসলেই অজানা বা প্রযোজ্য না হয়, null অনুমতি দিন।
একটি ব্যবহারিক ডিফল্ট কলাম সেট:
id (uuid বা bigint, এক পদ্ধতি বেছে নিন এবং লেগে থাকুন)created_at এবং updated_atdeleted_at কেবল যদি আপনি সত্যিই সফট ডিলিট চান এবং রিস্টোর করার দরকার থাকেcreated_by যখন আপনাকে স্পষ্ট অডিট ট্রেইল দরকারMany-to-many সম্পর্ক সাধারণত join টেবিলে রূপ নেয়। উদাহরণস্বরূপ, যদি একাধিক ব্যবহারকারী একটি অ্যাপে সহযোগীতা করতে পারে, তৈরি করুন app_members যাতে app_id এবং user_id আছে, তারপর জোড়ায় ইউনিকনেস জোর দিন যাতে ডুপ্লিকেট না ঘটে।
ইতিহ্য পরিকল্পনা সম্পর্কে ভাবুন। যদি আপনি জানেন ভার্সনিং লাগবে, একটি ইমিউটেবল টেবিল পরিকল্পনা করুন যেমন app_snapshots, যেখানে প্রতিটি সারি একটি সেভড ভার্সন এবং app_id দ্বারা লিঙ্কড এবং created_at দ্বারা স্ট্যাম্প করা থাকে।
কনস্ট্রেইন্ট আপনার স্কিমার গার্ডরেইল। সিদ্ধান্ত নিন কোন নিয়মগুলো সত্য হতে হবে যেকোন সার্ভিস, স্ক্রিপ্ট, বা অ্যাডমিন টুল ডাটাবেসে লিখুক।
পরিচয় ও সম্পর্ক থেকে শুরু করুন। প্রতিটি টেবিলে একটি প্রাইমারি কী দরকার, এবং কোন “belongs to” ফিল্ড হলে তা আসল foreign key হওয়া উচিত, শুধুমাত্র একটি integer নয়।
তারপর ইউনিকনেস যোগ করুন যেখানে ডুপ্লিকেট বাস্তব ক্ষতি করবে, যেমন একই ইমেইল সহ দুইটি অ্যাকাউন্ট বা একই (order_id, product_id) সহ দুইটি লাইন আইটেম।
উচ্চ-মানের কনস্ট্রেইন্ট যা আগে পরিকল্পনা করা উচিত:
amount >= 0, status IN ('draft','paid','canceled'), বা rating BETWEEN 1 AND 5।ক্যাসকেড আচরণ এমন জায়গা যেখানে পরিকল্পনা পরে আপনাকে বাঁচায়। ভাবুন ব্যবহারকারীরা আসলে কী প্রত্যাশা করবে। যদি একটি কাস্টমার মুছে যায়, তাদের অর্ডার সাধারণত অদক্ষী হওয়া উচিত না—এতে ইতিহাস রাখা উচিত। এই ক্ষেত্রে RESTRICT ভাল। অন্যদিকে নির্ভরশীল ডেটার জন্য যেমন order line items, প্যারেন্ট মুছলে CASCADE বুঝদার হতে পারে কারণ আইটেমগুলির কোন স্বাধীন মানে নেই।
যখন পরে আপনি মডেল ও এন্ডপয়েন্ট জেনারেট করবেন, এই কনস্ট্রেইন্টগুলো পরিষ্কার আইটেম হয়ে যাবে: কোন ত্রুটি ধরতে হবে, কোন ফিল্ড বাধ্যতামূলক, এবং কোন এজ-কেস ডিজাইন দ্বারা অসম্ভব।
ইনডেক্সগুলো একটাই প্রশ্নের উত্তর দেয়: বাস্তব ব্যবহারকারীদের জন্য কি দ্রুত হতে হবে।
শুরু করুন সেই স্ক্রিন ও API কলগুলির সাথে যেগুলো আপনি প্রথমে পাঠাবেন। একটি তালিকা পেজ যা স্ট্যাটাস দিয়ে ফিল্টার করে এবং নতুনতম অনুসারে সাজায় তার চাহিদা আলাদা হবে একটি ডিটেইল পেজ থেকে যা সম্পর্কিত রেকর্ড লোড করে।
কোনো ইনডেক্স বেছে নেওয়ার আগে ৫–১০টি কুয়েরি প্যাটার্ন সাদারন ভাষায় লিখে নিন। উদাহরণ: “Show my invoices for the last 30 days, filter by paid/unpaid, sort by created_at,” বা “Open a project and list its tasks by due_date.” এটা ইনডেক্স সিদ্ধান্তগুলোকে বাস্তব ব্যবহার অনুযায়ী রাখে।
ভাল প্রথম সেট সাধারণত foreign key কলামগুলো (joins-এ ব্যবহৃত), সাধারণ ফিল্টার কলাম (যেমন status, user_id, created_at), এবং একটি-দুটি কম্পোজিট ইনডেক্স যা স্থিতিশীল মルটিফিল্টার কেসগুলোর জন্য—যেমন (account_id, created_at) যখন আপনি সবসময় account_id দিয়ে ফিল্টার করে সময় অনুসারে সাজান।
কম্পোজিট ইনডেক্সের কলাম ক্রম গুরুত্বপূর্ণ। প্রথমে সেই কলামটি রাখুন যা আপনি সবচেয়ে বেশি ফিল্টার করেন এবং যেটা সবচেয়ে বেশি সিলেকটিভ। যদি আপনি প্রতিটি রিকোয়েস্টে tenant_id দিয়ে ফিল্টার করেন, সেটাই অনেক ইনডেক্সের সামনে থাকা উচিত।
প্রতি সম্ভাব্য ক্ষেত্রে ইনডেক্স যোগ করবেন না। প্রতিটি ইনডেক্স INSERT ও UPDATE-এ ওভারহেড বাড়ায় এবং বিরল কিন্তু খারাপ কুয়েরির চেয়ে তা বেশি ক্ষতিকর হতে পারে।
টেক্সট সার্চ আলাদা পরিকল্পনা করুন। যদি শুধু সরল “contains” ম্যাচিং দরকার, প্রথমে ILIKE যথেষ্ট হতে পারে। যদি সার্চ কোর ফিচার হয়, তখন আগে থেকেই full-text search (tsvector) পরিকল্পনা করুন যাতে পরে পুনরায় ডিজাইন করতে না হয়।
একবার প্রথম টেবিল তৈরি হলে স্কিমা “শেষ” হয় না। এটি প্রতিটি ফিচার যোগ করা, ভুল ঠিক করা, বা ডেটা সম্পর্কে আরও জানার সাথে বদলে যায়। যদি আপনি শুরুতেই আপনার মাইগ্রেশন কৌশল ঠিক করেন, তাহলে কোড জেনারেশনের পরে কষ্টকর রি-রাইট এড়ানো যায়।
সরল নিয়ম রাখুন: ডাটাবেস ছোট ধাপে বদলে ফেলুন, প্রতিটি ফিচার আলাদা মাইগ্রেশন হিসেবে। প্রতিটি মাইগ্রেশন রিভিউ করা সহজ এবং প্রতিটি পরিবেশে নিরাপদভাবে চালানোর মতো হওয়া উচিত।
বেশিরভাগ ব্রেকিং চেঞ্জ কলাম রিনেম বা রিমুভ করা, অথবা টাইপ পরিবর্তন থেকে আসে। সবকিছু একবারে করার বদলে একটি নিরাপদ পথ পরিকল্পনা করুন:
এটি ধাপে ধাপে হলেও বাস্তবে দ্রুত কাজ করে কারণ এটি আউটেজ ও জরুরী প্যাচ কমায়।
সিড ডেটাও মাইগ্রেশনের অংশ। সিদ্ধান্ত নিন কোন রেফারেন্স টেবিলগুলো “সবসময় আছে” (roles, statuses, countries, plan types) এবং সেগুলো পূর্বানুমেয় রাখুন। এই টেবিলের জন্য ইনসার্ট ও আপডেট আলাদা মাইগ্রেশনে রাখুন যাতে প্রতিটি ডেভেলপার ও প্রতিটি ডিপ্লয় একরকম ফল পায়।
শুরুতেই প্রত্যাশা সেট করুন:
রোলব্যাক সবসময় নিখুঁত “down migration” নাও হতে পারে। কখনও কখনও সবচেয়ে ভালো রোলব্যাক হলো ব্যাকআপ রিস্টোর। যদি আপনি Koder.ai ব্যবহার করেন, ঝুঁকিপূর্ণ পরিবর্তনের আগে স্ন্যাপশট ও রোলব্যাকের উপর নির্ভর করা সুবিধাজনক হতে পারে।
ধরা যাক একটি ছোট SaaS অ্যাপ যেখানে মানুষ টিমে যোগ দেয়, প্রজেক্ট তৈরি করে, এবং টাস্ক ট্র্যাক করে।
শুরু করুন এনটিটিগুলো ও প্রথম দিনের জন্য দরকারি শুধুমাত্র ফিল্ডগুলো তালিকা করে:
সম্পর্কগুলো সরল: একটি team-এর অনেক projects আছে, একটি project-এ অনেক tasks আছে, এবং users team_members মারফত টিমে যোগ দেয়। টাস্ক একটি project-এ থাকে এবং কোনো ব্যবহারকারীকে নিয়োগ করা থাকতে পারে।
এখন কয়েকটি কনস্ট্রেইন্ট যোগ করুন যা সাধারণত পরে বাগ দেয়:
citext ব্যবহার করুন)।ইনডেক্সগুলো বাস্তব স্ক্রিনের সাথে মিলিয়ে পরিকল্পনা করুন। উদাহরণ: যদি টাস্ক তালিকা project এবং state দিয়ে ফিল্টার করে এবং newest অনুযায়ী সাজায়, তাহলে একটি ইনডেক্স রাখতে পারেন tasks (project_id, state, created_at DESC)। যদি “My tasks” গুরুত্বপূর্ণ ভিউ হয়, তাহলে tasks (assignee_user_id, state, due_date) মতো ইনডেক্স সাহায্য করবে।
মাইগ্রেশনের জন্য প্রথম সেট নিরাপদ ও সরল রাখুন: টেবিল তৈরি, প্রাইমারি কী, ফরেন কী, এবং মূল ইউনিক কনস্ট্রেইন্ট। পরে ব্যবহার প্রমাণ করলে যোগ করুন—উদাহরণস্বরূপ টাস্কে সফট ডিলিট (deleted_at) যোগ করে “active tasks” ইনডেক্স সামঞ্জস্য করা।
বেশিরভাগ রি-রাইট হয় কারণ প্রথম স্কিমায় নিয়ম ও বাস্তব ব্যবহার বিবরণ অনুপস্থিত ছিল। একটি ভালো পরিকল্পনা পারফেকশন নয়—এটা জাল ছিদ্র আগে চিহ্নিত করার কাজ।
একটি সাধারণ ভুল হলো গুরুত্বপূর্ণ নিয়ম শুধুমাত্র অ্যাপলিকেশন কোডে রাখা। যদি একটি মান ইউনিক বা বাধ্যতামূলক হওয়া উচিত, ডাটাবেসেও তা Enforce করুন; নতুবা ব্যাকগ্রাউন্ড জব, নতুন এন্ডপয়েন্ট, বা ম্যানুয়াল ইমপোর্ট আপনার লজিক বাইপাস করতে পারে।
আরেকটি সাধারণ ত্রুটি হলো ইনডেক্সকে পরে দেখার অনুমান করা। লঞ্চের পরে ইনডেক্স যোগ করা প্রায়শই আন্দাজভিত্তিক হয়ে যায়, এবং আপনি ভুল জিনিস ইনডেক্স করতে পারেন, যখন আসল ধীর কুয়েরি হতে পারে একটি join বা status ফিল্টার।
Many-to-many টেবিলও নীরবে বাগের উৎস। যদি আপনার join টেবিল ডুপ্লিকেট প্রতিরোধ না করে, একই সম্পর্ক বারবার সংরক্ষিত হতে পারে এবং আপনি ঘণ্টার পর ঘণ্টা ডিবাগ করতে থাকতে পারেন যে “কেন এই ব্যবহারকারী দ্বিগুণ রো?”
এছাড়া সহজে টেবিল তৈরি করার পরে আপনি বুঝতে পারেন অডিট লগ, সফট ডিলিট, বা ইভেন্ট ইতিহাস দরকার। এসব পরিবর্তন এন্ডপয়েন্ট ও রিপোর্টে প্রভাব ফেলে।
শেষে, JSON কলাম লোভনীয় কারণ “ফ্লেক্সিবল” বলে মনে হয়, কিন্তু তারা যাচাই ও ইনডেক্সিং কঠিন করে দেয়। JSON ঠিক আছে যদি সত্যিই ভ্যারিয়েবল পে-লোড থাকে—কোর ব্যবসায়িক ফিল্ডগুলোতে নয়।
জেনারেট করার আগে এই দ্রুত চেকলিস্টটি চালান:
এখানে একটি দ্রুত প্রি-ফ্লাইট চেক যা নিশ্চিত করবে প্ল্যান এতটাই সম্পূর্ণ যাতে কোড জেনারেট করে আপনি বারবার সমস্যা না খুঁজে থাকেন। লক্ষ্য পারফেকশন নয়—এটি সেই গ্যাপগুলো ধরা যা পরে রি-রাইটের কারণ হয়ে দাঁড়ায়: অনুপস্থিত সম্পর্ক, অস্পষ্ট নিয়ম, এবং ইনডেক্স যা অ্যাপের ব্যবহার মেলায় না।
amount >= 0 বা অনুমোদিত স্ট্যাটাস)।একটি দ্রুত স্বাভাবিকতা পরীক্ষা: কল্পনা করুন একজন সহকর্মী আগামীকাল যোগ দিল। তারা কি প্রথম এন্ডপয়েন্ট তৈরি করতে পারবে প্রতিঅর্ধেক ঘণ্টায় প্রতিটি ক্ষেত্রে “এটি null হতে পারে?” অথবা “ডিলিট হলে কী হয়?” জিজ্ঞাসা করে না? যদি না পারে, আপনার পরিকল্পনা আরো স্পষ্ট করা দরকার।
একবার প্ল্যান পরিষ্কার পড়ে এবং মূল ফ্লো কাগজে অর্থবহ মনে হলে, এটিকে কার্যকরী কিছুতে রূপান্তর করুন: একটি বাস্তব স্কিমা ও মাইগ্রেশন।
একটি প্রাথমিক মাইগ্রেশন দিয়ে শুরু করুন যা টেবিল, টাইপ (যদি আপনি enum ব্যবহার করেন), এবং must-have কনস্ট্রেইন্ট তৈরি করে। প্রথম উত্তোলন ছোট কিন্তু সঠিক রাখুন। একটু সিড ডেটা লোড করুন এবং আপনার অ্যাপের যে কুয়েরিগুলো বাস্তবে প্রয়োজন সেগুলো চালান। যদি কোনো ফ্লো অদ্ভুত লাগে, মাইগ্রেশন ইতিহাস এখনও ছোট থাকা অবস্থায় স্কিমা ঠিক করুন।
টেবিল, কী, এবং নামকরণ এতটাই স্থির হলে কেবল তখনই মডেল ও এন্ডপয়েন্ট জেনারেট করুন যাতে পরেরদিন আপনি সবকিছু রিনেম না করছেন।
একটি কার্যকরী লুপ যা রি-রাইট কম রাখে:
শুরুতেই ঠিক করুন আপনি কোনটা ডাটাবেসে যাচাই করবেন বনাম API লেয়ারে। স্থায়ী নিয়মগুলো ডাটাবেসে রাখুন (ফরেন কী, ইউনিক কনস্ট্রেইন্ট, চেক কনস্ট্রেইন্ট)। নরম নিয়মগুলো API-তে রাখুন (ফিচার ফ্ল্যাগ, অস্থায়ী সীমা, এবং জটিল ক্রস-টেবিল লজিক যা প্রায়ই পরিবর্তিত হয়)।
যদি আপনি Koder.ai ব্যবহার করেন, একটি বুদ্ধিমান পদ্ধতি হলো প্রথমে Planning Mode-এ এনটিটি ও মাইগ্রেশন নিয়ে একমত হওয়া, তারপর Go প্লাস PostgreSQL ব্যাকএন্ড জেনারেট করা। যখন কোনো পরিবর্তন সমস্যা করে, স্ন্যাপশট ও রোলব্যাক দ্রুত পরিচিত-ভাল ভার্সনে ফিরতে সাহায্য করতে পারে যতক্ষণ আপনি স্কিমা প্ল্যান সামঞ্জস্য করেন।
Plan the schema first. It sets a stable data contract (tables, keys, constraints) so generated models and endpoints don’t need constant renames and rewrites later.
In practice: write your entities, relationships, and top queries, then lock in constraints, indexes, and migrations before you generate code.
Write 2–3 sentences describing what the app must remember and what users must be able to do.
Then list:
This gives you enough clarity to design tables without overbuilding.
Start by listing the nouns you keep repeating (user, project, invoice, task). For each one, add one sentence: what it is and why it exists.
If you can’t describe it clearly, you’ll likely end up with vague tables like items or misc and regret it later.
Default to a single consistent ID strategy across your schema.
UUIDs: great when records can be created from many places (web/mobile/jobs) or you don’t want predictable IDsbigint: smaller, a bit faster, and simpler when everything is server-createdIf you need a human-friendly identifier, add a separate unique column (like project_code) instead of using it as the primary key.
Decide it per relationship based on what users expect and what must be preserved.
Common defaults:
RESTRICT/NO ACTION when deleting a parent would erase important records (like customers → orders)CASCADE when child rows have no meaning without the parent (like order → line items)Make this decision early because it affects API behavior and edge cases.
Put permanent rules in the database so every writer (API, scripts, imports, admin tools) is forced to behave.
Prioritize:
Start from real query patterns, not guesses.
Write 5–10 plain-English queries (filters + sort), then index for those:
status, user_id, created_atCreate a join table with two foreign keys and a composite unique constraint.
Example pattern:
team_members(team_id, user_id, role, joined_at)UNIQUE (team_id, user_id) to prevent duplicatesThis prevents subtle bugs like “why does this user appear twice?” and keeps your queries clean.
Default to:
timestamptz for timestamps (fewer time zone surprises)numeric(12,2) or integer cents for money (avoid floats)CHECK constraintsKeep types consistent across tables (same type for the same concept) so joins and validations stay predictable.
Use small, reviewable migrations and avoid breaking changes in one step.
A safe path:
Also decide upfront how you’ll handle seed/reference data so every environment matches.
PRIMARY KEY on every tableFOREIGN KEY for every “belongs to” columnUNIQUE where duplicates cause real harm (email, (team_id, user_id) in join tables)CHECK for simple rules (non-negative amounts, allowed statuses)NOT NULL for fields required for the row to make sense(account_id, created_at)Avoid indexing everything; each index slows inserts and updates.