৩০ অক্টো, ২০২৫·8 মিনিট
প্রোডাক্ট অনুযায়ী পরীক্ষার ফলাফল ট্র্যাক করার ওয়েব অ্যাপ কীভাবে তৈরি করবেন
কিভাবে প্রোডাক্ট অনুযায়ী পরীক্ষার ফলাফল ট্র্যাক করার একটি ওয়েব অ্যাপ বানাবেন: ডেটা মডেল, মেট্রিক, পারমিশন, ইন্টিগ্রেশন, ড্যাশবোর্ড, এবং নির্ভরযোগ্য রিপোর্টিং।
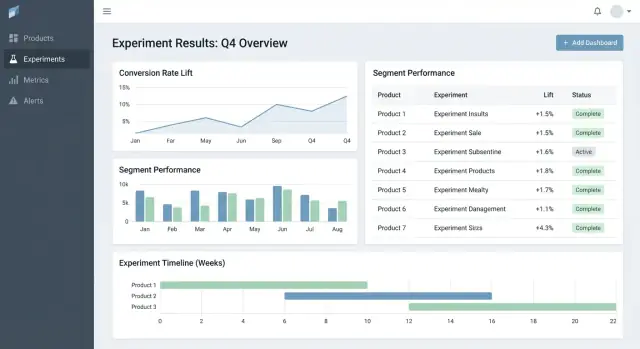
এই ওয়েব অ্যাপটি কী সমস্যা সমাধান করা উচিত
বেশিরভাগ টিম আইডিয়ার অভাবে পরীক্ষায় ব্যর্থ হয় না—তারা ব্যর্থ হয় কারণ ফলাফল বিচ্ছিন্ন। একটি প্রোডাক্টে চার্ট থাকে অ্যানালিটিক্স টুলে, অন্যটিতে স্প্রেডশীট, আরেকটিতে স্লাইড ডেকে স্ক্রিনশট। কয়েক মাস পরে, কেউ সহজ প্রশ্নের উত্তর দিতে পারে না যেমন “আমরা কি এটা আগেই টেস্ট করেছি?” বা “কোন ভার্সন জিতেছে, কোন মেট্রিক সংজ্ঞা ব্যবহার করে?”
মূল সমস্যা: বিচ্ছিন্ন ফলাফল ও অসংগত সত্য
একটি এক্সপেরিমেন্ট ট্র্যাকিং ওয়েব অ্যাপকে কেন্দ্রীভূত করতে হবে কি টেস্ট করা হয়েছে, কেন, কিভাবে মাপা হয়েছে, এবং কী হল—একাধিক প্রোডাক্ট ও টিম জুড়ে। এর বাইরে থাকলে টিমগুলো রিপোর্ট পুনর্নির্মাণে সময় নষ্ট করে, সংখ্যাকে নিয়ে তর্ক করে, এবং পুরোনো টেস্টগুলি পুনরায় চালায় কারণ শিখনগুলো সার্চযোগ্য নয়।
কাদের জন্য (এবং প্রতিটি গ্রুপের দরকার কী)
এটা কেবল বিশ্লেষকের টুল নয়।
- প্রোডাক্ট ম্যানেজাররা ফলাফল, কনফিডেন্স, এবং সিদ্ধান্তের স্থিতি দ্রুত দেখতে চান।
- অ্যানালিস্টরা অনুমান, মেট্রিক সংজ্ঞা, এবং সাভধানতার নথি রাখতে একটি নির্ভরযোগ্য জায়গা চান।
- ইঞ্জিনিয়াররা জানতে চান কোন ফিচার ফ্ল্যাগ, ভ্যারিয়েন্ট, এবং রোলআউট শর্ত প্রাসঙ্গিক ছিল।
- লিডারশিপ প্রোডাক্ট জুড়ে প্রভাবের একটি সঙ্গত দৃষ্টি চান, বিশেষ ডেক ছাড়া।
অপ্টিমাইজ করার জন্য আউটকাম
একটি ভালো ট্র্যাকার ব্যবসায় মূল্য তৈরি করে যা সক্ষম করে:
- দ্রুত সিদ্ধান্ত (কম লিংক খোঁজা ও অনুমোদন সময়)
- কম রিপোর্টিং ত্রুটি ("চূড়ান্ত সংখ্যার" এক উৎস)
- শেয়ার্ড শিখন (খোঁজযোগ্য ইতিহাস—জয়, পরাজয়, এবং নিরপেক্ষ টেস্ট)
স্পষ্ট স্কোপ সীমা
স্পষ্টভাবে বলুন: এই অ্যাপ মূলত ট্র্যাকিং ও রিপোর্টিং এর জন্য—এটি এক্সপেরিমেন্ট সম্পূর্ণ চালানোর জন্য নয়। এটি বিদ্যমান টুল (ফিচার ফ্ল্যাগিং, অ্যানালিটিক্স, ডেটা ওয়্যারহাউস) গুলোতে লিংক করতে পারে, কিন্তু এক্সপেরিমেন্ট এবং তার চূড়ান্ত, সম্মত ব্যাখ্যার কাঠামোবদ্ধ রেকর্ড নিজের দায়িত্বে নেবে।
Requirements: সর্বনিম্ন কার্যকর এক্সপেরিমেন্ট ট্র্যাকার
একটি MVP ট্র্যাকারকে দুইটি প্রশ্নের উত্তর দিতে হবে কষ্ট ছাড়া: আমরা কী পরীক্ষা করছি এবং আমরা কী শিখেছি। প্রোডাক্ট জুড়ে কাজ করবে এমন একটি ছোট সেট এন্টিটি এবং ফিল্ড দিয়ে শুরু করুন, তারপর কেবল তখনই বাড়ান যখন টিমগুলো বাস্তবে কষ্ট অনুভব করে।
সমর্থন করার জন্য মূল এন্টিটি
ডেটা মডেলটি এতটাই সহজ রাখুন যাতে প্রতিটি টিম একইভাবে এটি ব্যবহার করে:
- Product: যেখানে চেঞ্জ দিন (অ্যাপ/সাইট/API)
- Experiment: একটি হাইপোথিসিস এবং একটি সিদ্ধান্ত
- Variant: কন্ট্রোল ও এক বা একাধিক ট্রিটমেন্ট
- Metric: নামকৃত পরিমাপ যার একটি মালিক ও সংজ্ঞা আছে
- Segment: ঐচ্ছিক দর্শক স্লাইস (নতুন ব্যবহারকারী, পেইড ব্যবহারকারী, অঞ্চল) রিপোর্টিংয়ের জন্য
এক্সপেরিমেন্ট টাইপ (ছোট থেকে শুরু করুন, নমনীয় থাকুন)
প্রথম দিন থেকেই সবচেয়ে সাধারণ প্যাটার্নগুলো সমর্থন করুন:
- A/B টেস্ট (কন্ট্রোল বনাম ট্রিটমেন্ট)
- মাল্টিভ্যারিয়েট টেস্ট (একাধিক ভ্যারিয়েন্ট)
- ফিচার ফ্ল্যাগ রোলআউট (পার্সেন্টেজ-বেসড এক্সপোজার)
রোলআউটগুলো প্রথমে رسمی পরিসংখ্যান ব্যবহার না করলেও, এগুলোকে এক্সপেরিমেন্টের পাশে ট্র্যাক করলে টিমগুলো একই “টেস্ট” বারবার না চালায়।
প্রতিটি পরীক্ষার জন্য ন্যূনতম ফিল্ড
তৈরির সময়, কেবল যা প্রয়োজন তাই বাধ্যতামূলক করুন যাতে পরে টেস্টটি চালানো ও ব্যাখ্যা করা যায়:
- Hypothesis (কি পরিবর্তন, কার জন্য, এবং কেন)
- Owner (একজন দায়িত্বপ্রাপ্ত ব্যক্তি)
- Start/end dates (পরিকল্পিত ও বাস্তব)
- Targeting (যোগ্যতা নিয়ম) এবং allocation (ট্রাফিক ভাগ)
- Links রোলআউট/ফ্ল্যাগ, টিকিট, বা স্পেসিফিকেশনের (সম্পর্কিত URL-গুলো যেমন /projects/123)
সাফল্য মানদণ্ড ও সিদ্ধান্ত স্ট্যাটাস
ফলাফল তুলনীয় করতে কাঠামো জোরদার করুন:
- Primary metric (মূল সাফল্য পরিমাপক)
- Guardrails (যে মেট্রিকগুলো খারাপ হওয়া উচিত নয়)
- Decision status: proposed → running → analyzed → shipped/rolled back → archived
এইটুকু বানালে টিমগুলো সহজে পরীক্ষাগুলো খুঁজে পাবে, সেটআপ বুঝবে, এবং আউটকাম রেকর্ড করতে পারবে—এখনও আগেই আপনি উন্নত অ্যানালিটিক্স বা অটোমেশন যোগ করেননি।
ক্রস-প্রোডাক্টে কাজ করে এমন ডেটা মডেল
একটি ক্রস‑প্রোডাক্ট ট্র্যাকার তার ডেটা মডেলের উপরই সফলতা বা ব্যর্থতা নির্ভর করে। যদি আইডি গুলি টকদিক করে, মেট্রিক ভাসমান হয়, বা সেগমেন্ট অসংগত থাকে, তাহলে আপনার ড্যাশবোর্ড "ঠিক" দেখলেও ভুল গল্প বলবে।
স্থিতিশীল আইডেন্টিফায়ার বেছে নিন (এবং তাতে অটল থাকুন)
স্পষ্ট আইডেন্টিফায়ার কৌশল দিয়ে শুরু করুন:
- product_id: নাম পরিবর্তন হলেও স্থায়ী রাখুন (ডিসপ্লে নাম কী হিসেবে ব্যবহার করবেন না)
- experiment_key: মানুষ-বান্ধব স্লাগ (উদাহরণ:
checkout_free_shipping_banner) এবং একটি অপরিবর্তনীয় experiment_id - variant_key: স্থিতিশীল লেবেল যেমন
control,treatment_a
এতে আপনি অনুমান না করে প্রোডাক্ট জুড়ে ফলাফল তুলনা করতে পারবেন (যেমন “Web Checkout” এবং “Checkout Web” একই কি না)।
মূল কলেকশন/টেবিল
কোর এন্টিটিগুলো ছোট ও স্পষ্ট রাখুন:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (বা anonymous_id), variant_key, assigned_at
- metric_defs: metric name, numerator/denominator logic, unit (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
প্রতিগণিত কোথাও ঘটে, আউটপুটগুলো (results) সংরক্ষণ করলে দ্রুত ড্যাশবোর্ড ও নির্ভরযোগ্য ইতিহাস পাওয়া যায়।
টাইম উইন্ডো ও ভার্সনিং
মেট্রিক ও এক্সপেরিমেন্ট স্থির নয়—এগুলো মডেল করুন:
- time windows (যেমন “অ্যাসাইনমেন্টের পরে প্রথম 7 দিন”, “ক্যালেন্ডার সপ্তাহ”)
- ভার্সনকৃত মেট্রিক সংজ্ঞা: যখন একটি মেট্রিকের গণনা বদলে, পুরোনোটি এডিট না করে নতুন ভার্সন বানান
এতে গত মাসের পরীক্ষাগুলি পরিবর্তিত হবে না যখন কেউ KPI লজিক আপডেট করে।
সেগমেন্ট এবং অডিট ট্রেইল
দেশ, ডিভাইস, প্ল্যান টিয়ার, নতুন বনাম রিটার্নিং—প্রোডাক্ট জুড়ে সঙ্গত সেগমেন্ট পরিকল্পনা করুন।
শেষে, একটি অডিট ট্রেইল যোগ করুন যা কে কখন কী পরিবর্তন করেছে (স্ট্যাটাস পরিবর্তন, ট্রাফিক স্প্লিট, মেট্রিক সংজ্ঞা আপডেট) ধারন করে। এটি বিশ্বাস, রিভিউ, ও গভর্ন্যান্সের জন্য অপরিহার্য।
মেট্রিক সংজ্ঞা ও সঙ্গত গণনা
আপনার ট্র্যাকার যদি মেট্রিকের গাণিতিক ভুল করে (বা প্রোডাক্ট জুড়ে অসঙ্গত করে), তবে “ফলাফল” কেবল একটি মতামত সহ চার্ট হবে। দ্রুত প্রতিরোধের পথ হল মেট্রিকগুলোকে শেয়ার্ড প্রোডাক্ট অ্যাসেট হিসেবে ব্যবহার করা—নট এলোমেলো কুয়েরি স্নিপেট।
একটি ক্যানোনিকাল মেট্রিক ক্যাটালগ তৈরি করুন
একটি মেট্রিক এন্ট্রি হওয়া উচিত:
- সাধারণ ভাষায় সংজ্ঞা (কোন সিদ্ধান্তে সাহায্য করে)
- মালিক (পরিবর্তনের দায়িত্ব কে নেবে)
- সঠিক সূত্র ও প্রয়োজনীয় ইভেন্ট/ফিল্ড
- অন্তর্ভুক্তি/বর্জন বিধি (উপস্থিতি: ইনটার্নাল ইউজার, বট, রিফান্ড)\
- বৈধ অ্যাগ্রিগেশন লেভেল এবং সমর্থিত প্রোডাক্ট
ক্যাটালগটিকে এমন জায়গায় রাখুন যেখানে মানুষ কাজ করে (উদাহরণ: আপনার experiment creation flow-এ লিংক) এবং ভার্সন রাখুন যাতে ঐতিহাসিক ফলাফল ব্যাখ্যা করতে পারেন।
অ্যাগ্রিগেশন লেভেল স্ট্যান্ডার্ডাইজ করুন
প্রতিটি মেট্রিক কোন "ইউনিট অব অ্যানালিসিস" ব্যবহার করে তা আগে থেকেই নির্ধারণ করুন: per user, per session, per account, অথবা per order। একটি conversion rate "per user" এবং "per session" কখনোই একেবারে মিলবে না।
কনফিউশন কমানোর জন্য মেট্রিক ডেফিনিশনে অ্যাগ্রিগেশন পছন্দ রাখুন এবং পরীক্ষার সেটআপে এটি বাধ্যতামূলক করুন। প্রতিটি টিমকে এলোমেলোভাবে ইউনিট বেছে নিতে দেবেন না।
দেরী কনভার্শন ও এট্রিবিউশন হ্যান্ডল করা
অনেক প্রোডাক্টে কনভার্শন উইন্ডো থাকে (যেমন আজ সাইনআপ, 14 দিনের মধ্যে পার্চেজ)। এট্রিবিউশন নিয়ম গুলো ধারাবাহিকভাবে সংজ্ঞায়িত করুন:
- ঘড়ি কখন শুরু করে (এক্সপোজার টাইম, প্রথম ভিজিট, অ্যাসাইনমেন্ট টাইম)?
- যদি ইউজার একাধিকবার এক্সপোজড হয় তাহলে কী কভার করা হবে?
- ক্রস‑ডিভাইস বা ক্রস‑প্রোডাক্ট জার্নি কিভাবে হ্যান্ডল করবেন?
এই নিয়মগুলো ড্যাশবোর্ডে দৃশ্যমান রাখুন যাতে পাঠকরা জানে তারা কি দেখছে।
র কস গন্য সংখ্যা ও গণিত সংরক্ষণ করুন
দ্রুত ড্যাশবোর্ড ও অডিটেবিলিটির জন্য উভয় সংরক্ষণ করুন:
- কাঁচা গণনা (exposures, converters, revenue sums, variance inputs)
- গণিত-ফলাফল (lift, confidence intervals, p-values)
এতে দ্রুত রেন্ডারিং সম্ভব হয় এবং সংজ্ঞা বদলে গেলে পুনর্গণনা করা যায়।
নামকরণ কনভেনশন মেট্রিক স্প্রল প্রতিরোধ করে
একটি নামকরণ স্ট্যান্ডার্ড গ্রহণ করুন যা অর্থ এনকোড করে (উদাহরণ: activation_rate_user_7d, revenue_per_account_30d)। ইউনিক আইডি বাধ্যতামূলক করুন, অলিয়াস কার্যকর করুন, এবং মেট্রিক তৈরি করার সময় কাছাকাছি-ডুপ্লিকেটগুলো ফ্ল্যাগ করুন যাতে ক্যাটালগ পরিষ্কার থাকে।
ডেটা সংগ্রহ: ইভেন্ট, পাইপলাইন, ও কোয়ালিটি চেক
আপনার এক্সপেরিমেন্ট ট্র্যাকার এমনই নির্ভরযোগ্য হওয়া উচিত যেন প্রতিটি প্রোডাক্টের জন্য দুটো প্রশ্নের উত্তর দেয়: কে কোন ভ্যারিয়েন্টে এক্সপোজড ছিল এবং তারা পরে কী করেছে? সব কিছু—মেট্রিক, স্ট্যাটিস্টিক্স, ড্যাশবোর্ড—ওই ভিত্তির উপর দাঁড়ায়।
ইনজেশন পদ্ধতি বেছে নিন
অধিকাংশ টিম এই প্যাটার্নগুলোর একটিকে বেছে নেয়:
- ইভেন্ট স্ট্রিম (নীয়র-রিয়েলটাইম): দ্রুত পড়ার জন্য এবং দ্রুত ডিবাগিংয়ের জন্য ভালো। স্থিতিশীল রাখতে বেশি ইঞ্জিনিয়ারিং প্রয়োজন।
- ডেইলি ব্যাচ: পরিচালনা সহজ এবং সস্তা। যখন সিদ্ধান্তগুলি ঘণ্টা-ঘণ্টা প্রয়োজন নেই তখন শ্রেষ্ঠ।
- হাইব্রীড: এক্সপোজার ও ক্রিটিকাল ইভেন্ট স্ট্রিম করুন (অ্যাসাইনমেন্ট দ্রুত ভ্যালিডেট করতে), বাকিটা ব্যাচ করে সম্পূর্ণতা ও কস্ট কন্ট্রোলের জন্য।
আপনি যা নির্বাচন করুন না কেন, প্রোডাক্ট জুড়ে ন্যূনতম ইভেন্ট সেট স্ট্যান্ডার্ডাইজ করুন: exposure/assignment, মূল conversion events, এবং যোগযুক্ত করার মতো পর্যাপ্ত কনটেক্সট (user ID/device ID, timestamp, experiment ID, variant)।
প্রোডাক্ট ইভেন্টকে মেট্রিকের সাথে ম্যাপ করুন (এবং পরিপূর্ণতা ভ্যালিডেট করুন)
রా ইভেন্ট থেকে ট্র্যাকার যে মেট্রিক রিপোর্ট করবে সেগুলোর স্পষ্ট ম্যাপ সংজ্ঞায়িত করুন (উদাহরণ: purchase_completed → Revenue, signup_completed → Activation)। এটি প্রতিটি প্রোডাক্টের জন্য আলাদা রাখতে পারেন, তবে নাম রাখা সঙ্গত রাখুন যাতে A/B টেস্ট ড্যাশবোর্ডে তুলনা ভালভাবে হয়।
শুরুতেই পরিপূর্ণতা যাচাই করুন:
- নিশ্চিত করুন প্রতিটি এক্সপোজার-এ experiment ID ও variant আছে
- কনভার্শন ইভেন্টে সেই একই আইডেন্টিটি ফিল্ড আছে যা এক্সপোজারের যোগ করতে ব্যবহৃত হয়
- ক্লায়েন্ট, সার্ভার, ও ওয়্যারহাউসের মাঝে ইভেন্ট ড্রপ‑অফ লক্ষ্য করুন (মোবাইল SDK গুলো সাধারণত সমস্যার উৎস)
ডেটা কোয়ালিটি চেক যেগুলো অটোমেট করা উচিত
প্রতিটি লোডে চালানোর চেক তৈরি করুন ও তারা জোরালোভাবে ফেল করলে সতর্ক করুন:
- নির্দিষ্ট এক্সপোজার ইভেন্ট অনুপস্থিত: কনভার্শন আছে কিন্তু পূর্বের এক্সপোজার নেই (প্রায়ই ইনস্ট্রুমেন্টেশন গ্যাপ বা আইডেন্টিটি মিসম্যাচ)
- বন্টন বিভ্রাট: প্রত্যাশিত 50/50 এর বদলে 70/30 (টার্গেটিং বাগ সংকেত)
- টাইমস্ট্যাম্প স্যানিটি: এক্সপোজার পরে কনভার্শন, বা বড় বিলম্ব যা ক্লক সমস্যা বোঝায়
এসব ওয়ার্নিংগুলো পরীক্ষা পেজে সংযুক্ত করুন, লোগে লুকিয়ে রাখবেন না।
ব্যাকফিল এবং পুনরায় প্রসেসিং
পাইপলাইন বদলায়। ইনস্ট্রুমেন্টেশন বাগ বা ডুপ্লিকেশন লজিক ঠিক করলে, ঐতিহাসিক ডেটা পুনরায় প্রসেস করতে হবে যাতে মেট্রিক ও KPI সঙ্গত থাকে।
পরিকল্পনা করুন:
- ভার্সনকৃত ট্রান্সফর্মেশন (কে জানেন কোন লজিক কোন আউটপুট তৈরি করেছে)
- নিরাপদ ব্যাকফিল (তারিখ/প্রোডাক্ট/এক্সপেরিমেন্ট দ্বারা স্কোপ সীমাবদ্ধ)
- পুনর্গণনার অডিট ট্রেইল
ইন্টিগ্রেশন ডকুমেন্ট করুন
ইন্টিগ্রেশানগুলোকে প্রোডাক্ট ফিচার হিসেবে বিবেচনা করুন: সমর্থিত SDK, ইভেন্ট স্কিমা, ও ট্রাবলশুটিং স্টেপ নথিভুক্ত করুন। যদি আপনার ডক্স এলাকায় থাকে, লিংক দিন যেমন /docs/integrations।
স্ট্যাটিস্টিক্স ও ফলাফল গণনা যা বিশ্বাসযোগ্য
সিদ্ধান্ত নেওয়ার উপযোগী ড্যাশবোর্ড তৈরি করুন
পরীক্ষার তালিকা, বিস্তারিত এবং পণ্য ওভারভিউ পেজ তৈরি করুন—কোনো ম্যানুয়াল বয়লারপ্লেট ছাড়া।
মানুষ যদি সংখ্যাগুলো বিশ্বাস না করে, তারা ট্র্যাকার ব্যবহার করবে না। লক্ষ্যটি জটিল গণিতে প্রভাব ফেলা নয়—বরং সিদ্ধান্তগুলো পুনরাবৃত্য এবং প্রতিরক্ষাযোগ্য করা।
একটি স্ট্যাটিস্টিক্যাল “ডায়ালেক্ট” বেছে নিন এবং তাতে স্থির থাকুন
আগে নির্ধারণ করুন আপনি কি রিপোর্ট করবেন: Frequentist (p-values, confidence intervals) না Bayesian (probability of improvement, credible intervals)। দুটোই কাজ করে, কিন্তু প্রোডাক্ট জুড়ে মিশিয়ে দিলে বিভ্রান্তি তৈরি হয়।
একটি বাস্তববুদ্ধি নিয়ম: যে পদ্ধতিটা আপনার অর্গানাইজেশন ইতিমধ্যেই বোঝে সেটাই বেছে নিন, তারপর শব্দাবলি, ডিফল্ট, ও থ্রেশহোল্ড স্ট্যান্ডার্ডাইজ করুন।
UI ঠিক কী দেখাবে তা স্পষ্টভাবে সংজ্ঞায়িত করুন
কমপক্ষে, ফলাফল ভিউতে নিম্নলিখিতগুলি অস্পষ্ট হতে হবে না:
- Lift (কন্ট্রোলের চেয়ে absolute বা relative)
- Interval (confidence interval বা credible interval) একটি পরিসর হিসেবে দেখান, কেবল পয়েন্ট নয়
- প্রমাণের শক্তি (frequentist-এর জন্য p-value, Bayesian-এর জন্য কন্ট্রোলকে টপ করার সম্ভাবনা)
এছাড়া দেখান analysis window, গণনা ইউনিট (users, sessions, orders), এবং ব্যবহৃত মেট্রিক ডেফিনিশন ভার্সন। এই ছোট “বিস্তারিতগুলো”ই সঙ্গত রিপোর্টিং ও বিতর্কের মধ্যে পার্থক্য গঠন করে।
মাল্টিপল তুলনা ও “পীকিং” নীতি
যদি টিমগুলো বহু ভ্যারিয়েন্ট, বহু মেট্রিক, বা দৈনিক ফলাফল পরীক্ষা করে, তাহলে false positive বাড়ে। আপনার অ্যাপটিতে নীতিটি এঙ্কোড করুন:
- Multiple comparisons: আপনি কি অ্যাডজাস্ট করবেন (উদাহরণ: false discovery rate) না কি স্পষ্টভাবে ফলাফলকে “unadjusted exploratory” লেবেল দেবেন
- Repeated peeking: হয় (1) কড়াভাবে নির্ধারিত শেষ তারিখ + finalized স্ট্যাটাস দিয়ে এড়ানো, অথবা (2) sequential পদ্ধতি সমর্থন করে “safe-to-stop” নির্দেশিকা দেখানো
সাধারণ ব্যর্থতা ধরার গার্ডরেল
ফলাফলগুলোর পাশে স্বয়ংক্রিয় ফ্ল্যাগ যোগ করুন, লোগে লুকিয়ে রাখবেন না:
- Sample Ratio Mismatch (SRM): প্রত্যাশিত বন্টন থেকে বিচ্যুত হলে ওয়ার্নিং
- অ্যানোমালি ডিটেকশন: ট্রাফিক, কনভার্শন, বা রেভিনিউতে হঠাৎ ড্রপ/স্পাইক—ট্র্যাকিং ব্রেক বা আউটেজের সংকেত
সাধারণ ভাষার ব্যাখ্যা
সংখ্যার পাশে সংক্ষিপ্ত ব্যাখ্যা দিন যাতে নন‑টেকনিক্যাল পাঠকও বিশ্বাস করতে পারে, উদাহরণ: “সেরা অনুমান +2.1% লিফট, কিন্তু প্রকৃত প্রভাব সম্ভবত -0.4% থেকে +4.6% এর মধ্যে। এখনো জেতা বলার মতো শক্ত প্রমাণ নেই।”
UX ও ড্যাশবোর্ড দ্রুত সিদ্ধান্তের জন্য
ভালো এক্সপেরিমেন্ট টুলিং মানুষকে দুইটি প্রশ্ন দ্রুত উত্তর করতে সহায় করে: পরের কী দেখা উচিত? এবং আমরা কী করতে পারি? UI-টি প্রাসঙ্গিক প্রসঙ্গ খোঁজার সময় কমাতে হবে এবং “সিদ্ধান্তের অবস্থা” স্পষ্ট করতে হবে।
ওয়ার্কফ্লো অ্যাঞ্চর করার জন্য কীগুলি পেজ
শুরু করুন তিনটি পেজ দিয়ে যা বেশিরভাগ ব্যবহারের কভার করে:
- Experiments list: সারাবর্ণের (অথবা প্রোডাক্ট অনুযায়ী) সাজানো কিউ
- Experiment detail: সেটআপ, ফলাফল, ও সিদ্ধান্তের একমাত্র উৎস
- Product overview: একটি প্রোডাক্টের সক্রিয় টেস্ট, সাম্প্রতিক সিদ্ধান্ত, এবং মেট্রিক হেলথের রোলআপ
লিস্ট ও প্রোডাক্ট পেজগুলোতে ফিল্টারগুলো দ্রুত ও স্থায়ী রাখুন: product, owner, date range, status, primary metric, এবং segment। মানুষকে সেকেন্ডেই “Checkout experiments, owned by Maya, running this month, primary metric = conversion, segment = new users” মতো ফিল্টার করতে দিন।
বিশ্বাসযোগ্য সিদ্ধান্ত স্টেট
স্ট্যাটাসকে একটি নিয়ন্ত্রিত ভোকাবুলারি হিসেবে বর্ণনা করুন, ফ্রি‑টেক্সট নয়:
Draft → Running → Stopped → Shipped / Rolled back
স্ট্যাটাস সব জায়গায় দেখান (লিস্ট রো, ডিটেইল হেডার, শেয়ার লিংক) এবং দেখান কে কখন কেন পরিবর্তন করেছে। এতে "নীরব লঞ্চ" ও অস্পষ্ট আউটকাম রোধ হয়।
ফলাফলের টেবিল যা সিদ্ধান্ত স্পষ্ট করে
এক্সপেরিমেন্ট ডিটেইল ভিউতে নেতৃত্ব দিন একটি সংক্ষিপ্ত ফলাফল টেবিল দিয়ে প্রতিটি মেট্রিকের জন্য:
- Baseline
- Variant
- Lift
- Uncertainty (confidence/credible interval)
- Notes (উদাহরণ: ইনস্ট্রুমেন্টেশন কেভেটস, সেগমেন্ট কিউরকস)
অ্যাডভান্সড চার্টগুলো "More details" সেকশনের পিছনে রাখুন যাতে সিদ্ধান্ত-নির্ধারকরা অতিরিক্তভাবে অভিভূত না হন।
শেয়ার ও এক্সপোর্টগুলি কন্ট্রোল রেখে
অ্যানালিস্টদের জন্য CSV এক্সপোর্ট এবং স্টেকহোল্ডারদের জন্য শেয়ারেবল লিংক যোগ করুন, কিন্তু এক্সেস বজায় রাখুন: লিংকগুলো ভূমিকা ও প্রোডাক্ট পারমিশন মেনে চলবে। একটি সাধারণ “Copy link” বোতাম এবং একটি “Export CSV” অ্যাকশন বেশিরভাগ সহযোগিতার চাহিদা মেটায়।
পারমিশন, প্রাইভেসি, ও গভর্ন্যান্স
মেট্রিক ক্যাটালগ সেট আপ করুন
ভার্সন-সহ মেট্রিক সংজ্ঞা তৈরি করুন যাতে ফলাফল সময়ের সঙ্গে তুলনাযোগ্য থাকে।
আপনার ট্র্যাকার যদি বহু প্রোডাক্ট জুড়ে হয়, তখন অ্যাক্সেস কন্ট্রোল ও অডিটিবিলিটি ঐচ্ছিক নয়—এগুলোই টুল গ্রহণযোগ্য করে তোলে।
রোল‑ভিত্তিক অ্যাক্সেস কন্ট্রোল (RBAC)
সহজ রোল সেট দিয়ে শুরু করুন এবং অ্যাপ জুড়ে সামঞ্জস্য রাখুন:
- Viewer: পরীক্ষাগুলি, ফলাফল, ও ড্যাশবোর্ড পড়ার অনুমতি
- Editor: পরীক্ষা তৈরি/এডিট, সহায়ক ডক আপলোড, স্ট্যাটাস সেট করা (draft → running → concluded)
- Admin: ইউজার, পারমিশন, মেট্রিক সংজ্ঞা, রিটেনশন নিয়ম, ও ইন্টিগ্রেশন ম্যানেজ
RBAC সিদ্ধান্তগুলো কেন্দ্রীভূত রাখুন (একটি পলিসি লেয়ার) যাতে UI ও API একই নিয়ম মানে।
প্রোডাক্ট স্তরের ও রো স্তরের পারমিশন
অনেক অর্গে product-scoped access লাগে: টিম A শুধুমাত্র Product A দেখতে পায়। এটি স্পষ্টভাবে মডেল করুন (উদাহরণ: user ↔ product memberships) এবং নিশ্চিত করুন প্রতিটি কুয়েরি প্রোডাক্ট দ্বারা ফিল্টার হয়।
সংবেদনশীল ক্ষেত্রে (পার্টনার ডেটা, নিয়ন্ত্রিত সেগমেন্ট) রো‑লেভেল রেস্ট্রিকশন যোগ করুন—প্রতিটি পরীক্ষায় বা ফলাফল স্লাইসে সংবেদনশীলতা ট্যাগ করে অতিরিক্ত পারমিশন প্রয়োজন করুন।
অডিট ট্রেইল: অ্যাক্সেস + চেঞ্জ ইতিহাস
দুটি জিনিস আলাদাভাবে লগ করুন:
- Change logs: কে কোন পরীক্ষা/মেট্রিক/ডিসিশন সম্পাদন করেছে—কি বদলিয়েছে এবং কখন
- Access logs: কে ফলাফল দেখে বা এক্সপোর্ট করেছে (বিশেষত সংবেদনশীল কেস)
UI-তে চেঞ্জ ইতিহাস প্রকাশ করুন স্বচ্ছতার জন্য, এবং তদন্তের জন্য গভীর লগও সংরক্ষণ করুন।
রিটেনশন ও ডিলিশন নিয়ম
রিটেনশন সংজ্ঞায়িত করুন:
- Experiment metadata (hypothesis, owners, dates, decision notes)
- Computed results (effect sizes, confidence intervals, significance flags)
রিটেনশন প্রোডাক্ট ও সংবেদনশীলতা অনুযায়ী কনফিগারেবল রাখুন। ডেটা মুছে ফেলতে হলে একটি মিনিমাল টম্বস্টোন রেকর্ড রাখুন (ID, ডিলিশন সময়, কারণ) যাতে রিপোর্টিং ইন্টিগ্রিটি বজায় থাকে কিন্তু সংবেদনশীল বিষয় Retain না হয়।
ওয়ার্কফ্লো ফিচার্স: আইডিয়া থেকে লার্নিং লাইব্রেরি
ট্র্যাকার সত্যিই উপকারী হয় যখন এটি পুরো এক্সপেরিমেন্ট লাইফসাইকেলকে কভার করে, কেবল চূড়ান্ত p‑value নয়। ওয়ার্কফ্লো ফিচার্স বিক্ষিপ্ত ডক, টিকিট, ও চার্টগুলোকে পুনরাবৃত্ত প্রক্রিয়ায় পরিণত করে যা মান বাড়ায় ও শিখনগুলো পুনরায় ব্যবহার করা সহজ করে।
লাইফসাইকেল ওয়ার্কফ্লো: idea → review → run → post‑mortem
এক্সপেরিমেন্টগুলোকে স্টেটসের সিরিজ হিসেবে মডেল করুন (Draft, In Review, Approved, Running, Ended, Readout Published, Archived)। প্রতিটি স্টেটে স্পষ্ট "exit criteria" থাকা উচিত যাতে পরীক্ষা অপরিহার্য উপাদান ছাড়া লাইভ না যায়—যেমন hypothesis, primary metric, এবং guardrails।
অ্যাপ্রুভাল ভারী হওয়ার দরকার নেই। একটি সহজ রিভিউ স্টেপ (উদাহরণ: product + data) এবং কে কখন অনুমোদন করেছিল তার অডিট ট্রেইল অনিবার্য ভুল প্রতিরোধ করতে পারে। সম্পন্ন হলে একটি সংক্ষিপ্ত post‑mortem বাধ্যতামূলক করুন যাতে ফলাফল ও প্রসঙ্গ কিলিক্যাললি ক্যাপচার করা যায় আগে পরীক্ষাটি “Published” বলা যায়।
টেমপ্লেটগুলো চিন্তা মানক করে
টেমপ্লেট যোগ করুন:
- Experiment brief (লক্ষ্য, hypothesis, টার্গেট অডিয়েন্স, সাফল্য মেট্রিক, guardrails, রোলআউট পরিকল্পনা)
- Analysis notes (ডেটা সোর্স, বর্জন, স্যানিটি চেক, ব্যাখ্যা, ঝুঁকি)
টেমপ্লেটগুলো "ব্ল্যাঙ্ক পাতা" ঘিরে ঘন্টা কাটানো কমায় এবং রিভিউ দ্রুত করে কারণ সবাই জানে কোথায় দেখতে হবে। এগুলো প্রতিটি প্রোডাক্ট অনুযায়ী এডিটেবল রাখুন কিন্তু একটি সাধারণ কোর বজায় রাখুন।
শেখা: সবকিছু লিংক করুন, সার্চেবল রাখুন
এক্সপেরিমেন্টগুলো বেশিরভাগ সময় একা থাকে না—মানুষকে আশে পাশে প্রসঙ্গ দরকার হয়। ব্যবহারকারীরা টিকিট/স্পেক/লেখার সাথে লিংক যোগ করতে পারুক (উদাহরণ: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist)। "Learning" নামে কাঠামোবদ্ধ ফিল্ড রাখুন, যেমন:
- কি বদলানো হলো (সিদ্ধান্ত)
- আমরা কী শিখলাম (ইনসাইট)
- পরবর্তী পদক্ষেপ (ফলো‑আপ)
গার্ডরেল ও ফলাফলের পরিবর্তনের জন্য সতর্কতা
গার্ডরেল ব্যর্থ হলে (উদাহরণ: error rate, cancellations) বা পরে ডেটা/মেট্রিক পুনর্গণনার ফলে ফলাফল বদলালে নোটিফিকেশন সমর্থন করুন। সতর্কতাগুলো অ্যাকশনযোগ্য রাখুন: মেট্রিক, থ্রেশহোল্ড, সময়সীমা, এবং একজন মালিক দেখান যে acknowledge বা escalate করতে পারে।
আগের কাজ পুনরায় ব্যাবহার করার জন্য লাইব্রেরি ভিউ
একটি লাইব্রেরি দিন যা প্রোডাক্ট, ফিচার এলাকা, অডিয়েন্স, মেট্রিক, আউটকাম, এবং ট্যাগ (যেমন “pricing,” “onboarding,” “mobile”) দিয়ে ফিল্টার করে। "সদৃশ পরীক্ষার" সুপারিশ যোগ করুন ট্যাগ/মেট্রিক ভাগ করে যাতে টিমগুলো একই পরীক্ষা পুনরায় চালানোর বদলে পূর্বের শিখন ব্যবহার করতে পারে।
আর্কিটেকচার ও টেক স্ট্যাক অপশন
একটি "পারফেক্ট" স্ট্যাক দরকার নেই—কিন্তু স্পষ্ট সীমা দরকার: ডেটা কোথায় থাকে, গণনা কোথায় চলে, এবং টিমগুলো কীভাবে ফলাফল অ্যাক্সেস করে সেগুলো পরিষ্কার করা।
একটি ব্যবহারিক বেসলাইন স্ট্যাক
অনেক টিমের জন্য একটি সহজ ও স্কেলেবল সেটআপ:
- Frontend: React (বা Vue) ড্যাশবোর্ড ও ওয়ার্কফ্লো
- Backend API: Node.js/Express, Python/FastAPI, বা Java/Spring—যেটা টিম রক্ষণাবেক্ষণ করতে পারে
- Database: Postgres (অ্যাপ ডেটার জন্য: experiments, metric definitions, permissions)
- Analytics warehouse: BigQuery/Snowflake/Redshift (ইভেন্ট ডেটা ও ভারী অগ্রিগেশন)
এই ভাগ ট্রানজেকশনাল ওয়ার্কফ্লোকে দ্রুত রাখে এবং ওয়্যারহাউস বড়-স্কেল গণনার দায় নেয়।
প্রোটোটাইপ দ্রুত তৈরি করতে আপনি UI ও ওয়ার্কফ্লো (experiments list → detail → readout) তাড়াতাড়ি দেখতে চাইলে, একটি ভিব‑কোডিং প্ল্যাটফর্ম যেমন Koder.ai আপনাকে chat spec থেকে কাজ করা React + ব্যাকএন্ড ফাউন্ডেশন জেনারেট করতে সাহায্য করতে পারে। এটি বিশেষ করে উপযোগী όταν আপনি entities, forms, RBAC scaffolding, এবং audit-friendly CRUD দ্রুত স্থাপন করে পরে ডেটা কনট্রাক্ট নিয়ে ইটারেট করবেন।
মেট্রিক.calculations কোথায় থাকা উচিত?
তিনটি সাধারণ অপশন থাকে:
- Warehouse-first: SQL মডেল মেট্রিক ও এক্সপেরিমেন্ট রেজাল্ট টেবিল তৈরি করে। অ্যাপ কেবল পড়ে।
- Backend jobs: ওয়ার্কার নির্ধারিত সময়ে বা পরীক্ষার পরিবর্তনে ফলাফল গণনা করে।
- হাইব্রিড: ক্যানোনিকাল অগ্রিগেশন ওয়্যারহাউসে, ব্যাকএন্ডে পোস্ট‑প্রসেসিং (ফরম্যাটিং, গার্ডরেল, ক্যাশিং)
যদি ডেটা টিম ইতিমধ্যেই নির্ভরযোগ্য SQL-অভিজ্ঞ হয় তবে warehouse-first সাধারণত সহজ। ব্যাকএন্ড-হেভি যখন দরকার হয় দ্রুত-লেটেন্সি আপডেট বা কাস্টম লজিকের জন্য, কিন্তু এটি অ্যাপ জটিলতা বাড়ায়।
পারফরম্যান্স: ক্যাশ ও প্রি‑কম্পিউট
এক্সপেরিমেন্ট ড্যাশবোর্ড সাধারণত একই কুয়েরি বারবার চালায় (টপ-লাইন KPI, টাইম সিরিজ, সেগমেন্ট কাটি)। পরিকল্পনা করুন:
- প্রি‑কম্পিউট রোলআপ (প্রতিদিনের মেট্রিক অগ্রিগেট per experiment/variant/segment)
- API লেয়ারে ক্যাশ (উদাহরণ: Redis) স্পষ্ট ইনভ্যালিডেশন রুলসহ
- ওয়্যারহাউসে সাধারণ ড্যাশবোর্ডের জন্য materialized views বা নির্ধারিত টেবিল ব্যবহার
মাল্টি-টেন্যান্ট বনাম সিঙ্গল-টেন্যান্ট
যদি আপনি অনেক প্রোডাক্ট বা বিজনেস ইউনিট সাপোর্ট করেন, আগে সিদ্ধান্ত নিন:
- Single-tenant (shared schema): পরিচালনা সহজ, কিন্তু কঠোর পারমিশন ফিল্টারিং প্রয়োজন
- Multi-tenant: শক্তিশালী isolation, বেশি অপারেশনাল ওভারহেড
একটি সাধারণ সমঝোতা হলো শেয়ার্ড ইन्फ্রা কিন্তু শক্ত tenant_id মডেল ও এনফোর্সড রো‑লেভেল এক্সেস।
কোর API সংজ্ঞায়িত করুন
API সারফেস ছোট ও স্পষ্ট রাখুন। অধিকাংশ সিস্টেমের জন্য দরকার: experiments, metrics, results, segments, এবং permissions (অডিট‑ফ্রেন্ডলি রিড সহ)। এতে নতুন প্রোডাক্ট যোগ করা সহজ হয়।
টেস্টিং, মনিটরিং, ও নির্ভরযোগ্য অপারেশন
আরও বিল্ড সময় পান
আপনি যা বানান তা শেয়ার করে বা টিমমেটদের Koder.ai-তে রেফার করে ক্রেডিট অর্জন করুন।
এক্সপেরিমেন্ট ট্র্যাকার তখনই কাজে লাগে যখন মানুষ এটি বিশ্বাস করে। সেই বিশ্বাস আসে নিয়মিত টেস্টিং, পরিষ্কার মনিটরিং, এবং পূর্বনির্ধারিত অপারেশন থেকে—বিশেষ করে যখন একাধিক প্রোডাক্ট ও পাইপলাইন একই ড্যাশবোর্ডে ডেটা পাঠায়।
অবজারভেবিলিটি যে ভাবে মানুষ অ্যাপ ব্যবহার করে তা মেলে
প্রতি গুরুত্বপূর্ণ ধাপে স্ট্রাকচার্ড লগিং থেকে শুরু করুন: ইভেন্ট ইনজেশন, অ্যাসাইনমেন্ট, মেট্রিক রোলআপ, ও ফলাফল গণনা। product, experiment_id, metric_id, pipeline run_id মতো আইডেন্টিফায়ার রাখুন যাতে সাপোর্ট একটি ফলাফলকে তার ইনপুট পর্যন্ত ট্রেস করতে পারে।
সিস্টেম মেট্রিক্স (API latency, job runtimes, queue depth) এবং ডেটা মেট্রিক্স (ইভেন্ট প্রোসেসড, % late events, % dropped by validation) যুক্ত করুন। ট্রেসিং সার্ভিস জুড়ে add করুন যাতে উত্তর দিতে পারেন: “কেন এই পরীক্ষায় গতকালের ডেটা অনুপস্থিত?”
ডেটা ফ্রেশনেস চেক দ্রুততম উপায় সাইলেন্ট ফেইল প্রতিরোধ করার। যদি SLA হয় “প্রতিদিন 9am-এ”, প্রতিটি প্রোডাক্ট ও সোর্সের জন্য freshness মনিটর করুন এবং সতর্ক করুন যখন:
- সর্বশেষ পার্টিশন অনুপস্থিত
- ইভেন্ট ভলিউম বেসলাইনের থেকে উল্লেখযোগ্যভাবে বিচ্যুত
- রোলআপ জব শেষ হয়েছে কিন্তু শূন্য রো উৎপাদন করেছে
অটোমেটেড টেস্ট: ডেটা ও গণিত রক্ষা করুন
তিন স্তরে টেস্ট রাখুন:
- Schema ও কনস্ট্রেইন্ট: বাধ্যতামূলক ফিল্ড, ইউনিকনেস (উদাহরণ: প্রতিটি ব্যবহারকারী প্রতি পরীক্ষায় একটি অ্যাসাইনমেন্ট), ফরেন কি, বৈধ তারিখ পরিসর
- Permissions: RBAC টেস্ট (viewer/editor/admin), এবং প্রোডাক্ট স্কোপিং যাতে টিম শুধু তাদের প্রোডাক্ট দেখুক
- Result math: লিফট, confidence intervals, significance flags, এবং এজ কেস (ছোট স্যাম্পল, জিরো ডিনোমিনেটর, বহু ভ্যারিয়েন্ট)
একটি ছোট “golden dataset” রাখুন যাতে রিগ্রেশন আগে ধরা পড়ে।
ডিপ্লয়মেন্ট, মাইগ্রেশন, ও ঐতিহাসিক সুরক্ষা
মাইগ্রেশনগুলো অপারেশনের অংশ হিসেবেই বিবেচনা করুন: মেট্রিক ডেফিনিশন ও ফলাফলের গণনা ভার্সন করুন, এবং ঐতিহাসিক পরীক্ষা পুনরায় লেখার থেকে বিরত থাকুন যতক্ষণ পর্যন্ত স্পষ্টভাবে চাওয়া না হয়। যখন পরিবর্তন প্রয়োজন, নিয়ন্ত্রিত ব্যাকফিল পথ প্রদান করুন এবং কী বদলেছে তা অডিট ট্রেইলে নথিভুক্ত করুন।
ইনসিডেন্ট ও পুনরায় প্রসেসিংয়ের জন্য অ্যাডমিন টুল
একটি অ্যাডমিন ভিউ দিন যা নির্দিষ্ট পরীক্ষা/তারিখ-রেঞ্জের জন্য পাইপলাইন পুনরায় চালাতে পারে, ভ্যালিডেশন ত্রুটি পরীক্ষা করতে পারে, এবং ইনসিডেন্টগুলো স্ট্যাটাস আপডেটের সাথে চিহ্নিত করতে পারে। ইনসিডেন্ট নোটগুলো প্রভাবিত পরীক্ষাগুলোর সাথে লিংক করুন যাতে ব্যবহারকারীরা বিলম্ব বুঝতে পারে এবং অসম্পূর্ণ ডেটার উপর সিদ্ধান্ত না নেয়।
রোলআউট প্ল্যান ও সাধারণ ফাঁদ
এক্সপেরিমেন্ট ট্র্যাকিং ওয়েব অ্যাপ বহু প্রোডাক্ট জুড়ে রোলআউট করা মানে "লঞ্চ ডে" নয়—এটা একে একে অনিশ্চয়তা কমানো: কী ট্র্যাক করা হচ্ছে, কে মালিক, এবং সংখ্যাগুলো বাস্তবে মেলে কি না।
একটি ব্যবহারিক রোলআউট ক্রম
প্রথমে এক প্রোডাক্ট এবং একটি নির্ভরযোগ্য মেট্রিক সেট (উদাহরণ: conversion, activation, revenue) দিয়ে শুরু করুন। লক্ষ্যটি হলো end-to-end ওয়ার্কফ্লো যাচাই করা—এক্সপেরিমেন্ট তৈরি করা, এক্সপোজার ও আউটকাম ক্যাপচার, ফলাফল গণনা, এবং সিদ্ধান্ত রেকর্ড করা—তারপর জটিলতা বাড়ান।
প্রথম প্রোডাক্ট স্থিতিশীল হলে প্রোডাক্ট-বাই-প্রোডাক্ট প্রসার করুন একটি পূর্বনির্ধারিত অনবোর্ডিং কেডেন্স নিয়ে। প্রতিটি নতুন প্রোডাক্টকে পুনরাবৃত্তিযোগ্য সেটআপের মতো মনে করান, কাস্টম প্রজেক্ট নয়।
যদি আপনার অর্গ দীর্ঘ "প্ল্যাটফর্ম বিল্ড" সাইকেলে আটকে যায়, একটি দুই‑ট্র্যাক পদ্ধতি বিবেচনা করুন: স্থায়ী ডেটা কনট্রাক্ট (ইভেন্ট, আইডি, মেট্রিক) একই সময়ে পাতলা অ্যাপ লেয়ার তৈরি করুন। টিমগুলো প্রায়ই Koder.ai ব্যবহার করে সেই পাতলা লেয়ার দ্রুত স্থাপন করে—ফর্ম, ড্যাশবোর্ড, পারমিশন, এবং এক্সপোর্ট—তারপর গ্রহণ বাড়লে এটিকে হার্ডেন করে (সোর্স কোড এক্সপোর্ট ও স্ন্যাপশট দ্বারা ইটারেটিভ রোলব্যাক) ।
প্রতিটি নতুন প্রোডাক্টের জন্য রোলআউট চেকলিস্ট
একটি লাইটওয়েট চেকলিস্ট ব্যবহার করে প্রোডাক্টগুলো অনবোর্ড করুন এবং ইভেন্ট স্কিমা ধারাবাহিক রাখুন:
- ইভেন্ট ট্যাক্সোনমি ও নামকরণ কনভেনশন নিশ্চিত করুন (এবং কে এটি পরিবর্তন করতে পারে)
- নিশ্চিত করুন exposure events আছে এবং একটি ব্যবহারকারীর সাথে অনন্যভাবে অ্যাট্রিবিউটেবল
- মেট্রিকগুলোকে প্রোডাক্টের ইভেন্ট স্কিমার সঙ্গে ম্যাপ করুন (রিফান্ড, ক্যানসেলেশনের মতো এজ-কেস সহ)
- ব্যাকফিল বা প্যরালাল‑রান পিরিয়ড চালিয়ে বিদ্যমান অ্যানালিটিক্সের সাথে তুলনা করুন
- এক্সপেরিমেন্ট সেটআপ, ডেটা ভ্যালিডেশন, এবং চূড়ান্ত সিদ্ধান্ত নোটের জন্য মালিক নির্ধারণ করুন
গ্রহণ সহজ করতে, পরীক্ষার ফলাফল থেকে "next steps" লিংক দিন প্রাসঙ্গিক প্রোডাক্ট এরিয়ায় (উদাহরণ: pricing‑related experiments → /pricing)। লিংকগুলো তথ্যবহুল ও নিরপেক্ষ রাখুন—কোন ফলাফল নেই তা ইঙ্গিত করবেন না।
গ্রহণ পরিমাপ করুন যাতে ঘর্ষণ দ্রুত ঠিক করতে পারেন
পরিমাপ করুন টুলটা নির্ধারিত স্থানে সিদ্ধান্ত গ্রহণ হচ্ছে কি না:
- রোল স্তরে সাপ্তাহিক সক্রিয় ব্যবহারকারী (PM, অ্যানালিস্ট, ইঞ্জিনিয়ার)
- পরীক্ষাগুলি তৈরি ও সম্পন্ন হয়েছে কি পরিমাণ
- সিদ্ধান্ত নোট ভরা আছে এমন পরীক্ষার শতাংশ (শুধু ফলাফল দেখা নয়)
- পরীক্ষা শেষ → সিদ্ধান্ত রেকর্ড সময়
সাধারণ ফাঁদগুলো থেকে সাবধান থাকুন
অ্যাকচুয়াল রোলআউটগুলো সাধারণত কয়েকটি সমস্যায় ভেঙে পড়ে:
- অসংগত মেট্রিক সংজ্ঞা (একই নাম, ভিন্ন গণিত)
- এক্সপোজার ট্র্যাকিং অনুপস্থিত বা ত্রুটিপূর্ণ, ফলে পক্ষপাতি ফলাফল
- অস্পষ্ট মালিকানা যা zombie experiments সৃষ্টি করে
- চুপিচুপি স্কিমা পরিবর্তনগুলো যা ট্রেন্ড ভেঙে ফেলে
- কোর ওয়ার্কফ্লো বিশ্বাসযোগ্য হওয়ার আগে অনেক মেট্রিক নিয়ে স্কেল করা
সাধারণ প্রশ্ন
What problem is an experiment tracking web app actually solving?
প্রত্যেক পরীক্ষার অবশেষে সম্মত রেকর্ড কেন্দ্রীভূত করা দিয়ে শুরু করুন:
- কী পরীক্ষা করা হয়েছিল (পরিকল্পনা, ভ্যারিয়েন্ট)
- কোথায় চলেছিল (প্রোডাক্ট)
- কীভাবে পরিমাপ করা হয়েছে (মেট্রিক সংজ্ঞা + ভার্সন)
- কী হয়েছে (ফলাফল, অনিশ্চয়তা, সিদ্ধান্ত)
আপনি ফিচার-ফ্ল্যাগ টুল বা অ্যানালিটিক্স সিস্টেমে লিংক করতে পারেন, কিন্তু ট্র্যাকারটি কাঠামোবদ্ধ ইতিহাসের মালিক হওয়া উচিত যাতে সময়ের সাথে ফলাফল সার্চযোগ্য ও তুলনীয় থাকে।
Does an experiment tracker need to run experiments end-to-end?
না—স্কোপটি ফলাফল ট্র্যাকিং ও রিপোর্টিং-এ রাখুন।
একটি ব্যবহারিক MVP:
- পরীক্ষা মেটাডেটা সংরক্ষণ করে (owner, তারিখ, টার্গেটিং, ট্রাফিক স্প্লিট)
- মেট্রিক সংজ্ঞা ভার্সন সহ সংরক্ষণ করে
- গণিত আউটপুট সংরক্ষণ করে (লিফট + অনিশ্চয়তা) এবং সিদ্ধান্ত নোট রাখে
- বহির্গত সিস্টেম (ফ্ল্যাগ, টিকিট, ড্যাশবোর্ড) এ লিংক করে
এতে পুরো এক্সপেরিমেন্ট প্ল্যাটফর্ম পুনর্নির্মাণ করা ছাড়াই “বিক্ষিপ্ত ফলাফল” সমস্যার সমাধান হয়।
What core entities should the MVP data model include?
যে মিনিমাম মডেল দলগুলোর জন্য কাজ করে:
How should we design identifiers so results stay consistent across products?
স্থায়ী আইডি ব্যবহার করুন এবং ডিসপ্লে নামকে এডিটেবল লেবেল হিসেবে বিবেচনা করুন:
product_id: পরিবর্তন না করে রাখুন, এমনকি প্রোডাক্ট নাম বদলালে ওexperiment_id: অভ্যন্তরীণ অপরিবর্তনীয় আইডি- : পড়তে সহজ স্লাগ (প্রোডাক্ট অনুযায়ী ইউনিক করতে পারেন)
What fields should be required when creating an experiment?
সেটআপের সময় "সাকসেস ক্রাইটেরিয়া" স্পষ্ট করুন:
- একটি প্রাইমারি মেট্রিক বাধ্যতামূলক করুন (সিদ্ধান্ত চালক)
- গার্ডরেল সংজ্ঞায়িত করুন (যেগুলো খারাপ হওয়া চলবে না)
- একটি নিয়ন্ত্রিত ডিসিশন স্ট্যাটাস স্টোর করুন (যেমন Draft → Running → Analyzed → Shipped/Rolled back → Archived)
এই কাঠামো পরে বিতর্ক কমিয়ে দেয়, কারণ পাঠকরা পরীক্ষা চালু হওয়ার আগে কী মানেই “জিতা” তা দেখতে পায়।
How do we prevent inconsistent metric definitions across teams?
একটি ক্যানোনিকাল মেট্রিক ক্যাটালগ তৈরি করুন যাতে থাকে:
- সোজা-সাপਟੀ সংজ্ঞা + কোন সিদ্ধান্তে সাহায্য করে
- সঠিক সূত্র এবং প্রয়োজনীয় ইভেন্ট/ফিল্ড
- অন্তর্ভুক্তি/বর্জন বিধি (বটস, ইনটার্নাল ইউজার, রিফান্ড ইত্যাদি)
- বিশ্লেষণের ইউনিট (user/session/order/account)
- মালিকানা এবং ভার্সনিং
যখন লজিক বদলে, একটি নতুন মেট্রিক ভার্সন প্রকাশ করুন—ইতিহাস সংশোধন করবেন না; এবং প্রতিটি পরীক্ষা কোন ভার্সন ব্যবহার করেছে সেটা স্টোর করুন।
What’s the minimum instrumentation and data quality checks we need?
সর্বনিম্নে, এক্সপোজার এবং আউটকামগুলোর নির্ভরযোগ্য যোগসূত্র থাকা প্রয়োজন:
- একটি assignment/exposure ইভেন্ট যাতে experiment ID এবং variant থাকে
- মূল কনভার্শন ইভেন্টে মিলমান আইডেন্টিটি ফিল্ড (user/device/account)
- এট্রিবিউশন উইন্ডো জন্য নির্ভরযোগ্য টাইমস্ট্যাম্প
তারপর স্বয়ংক্রিয় পরীক্ষা চালান, যেমন:
Should we use frequentist or Bayesian stats in the tracker?
একটি “ডায়ালেক্ট” নির্ধারণ করুন এবং তাতে ব্যাপক নিয়মাবলি বজায় রাখুন:
- Frequentist: p-value + confidence intervals
- Bayesian: improvement probability + credible intervals
যেটা আপনি বেছে নেবেন, UI-তে অবশ্যই দেখান:
- কন্ট্রোলের তুলনায় লিফট
- একটি ইন্টারভাল রেঞ্জ (শুধু পয়েন্ট অনুমান নয়)
What permissions and governance features are essential for a cross-product tracker?
অ্যাক্সেস কন্ট্রোলকে ইনফ্রাস্ট্রাকচারের অংশ হিসেবে শুরু থেকেই বিবেচনা করুন:
- RBAC: Viewer / Editor / Admin
- Product-scoped access: ইউজার শুধুমাত্র তাদের প্রোডাক্টগুলোই দেখতে পায়
- সংবেদনশীল কেসে ঐচ্ছিক row-level restrictions প্রয়োগ করুন
এছাড়া দুটি অডিট ট্রেইল রাখুন:
How should we roll out the tracker, and what pitfalls should we watch for?
একটি পুনরাবৃত্তিমূলক সিরিজে রোলআউট করুন:
- প্রথমে একটা প্রোডাক্ট ও একটি ছোট মেট্রিক সেট (যেমন conversion, activation, revenue) দিয়ে শুরু করুন
- end-to-end যাচাই করুন: assignment → joins → metrics → results → decision notes
- প্রতিটি প্রোডাক্টে একই অনবোর্ডিং চেকলিস্ট দিয়ে বাড়ান
সাধারণ ভুলগুলো এড়ান: