০২ সেপ, ২০২৫·8 মিনিট
API-গুলিতে Protobuf বনাম JSON: গতি, আকার, এবং সামঞ্জস্য
Protobuf বনাম JSON: পে-লোড সাইজ, পারফরম্যান্স, পড়ারযোগ্যতা, টুলিং, স্কিমা বিবর্তন এবং কোন পরিস্থিতিতে কোন ফরম্যাট বেশি উপযোগী—বাস্তব পণ্যগুলোর জন্য তুলনা।
Protobuf বনাম JSON: পে-লোড সাইজ, পারফরম্যান্স, পড়ারযোগ্যতা, টুলিং, স্কিমা বিবর্তন এবং কোন পরিস্থিতিতে কোন ফরম্যাট বেশি উপযোগী—বাস্তব পণ্যগুলোর জন্য তুলনা।
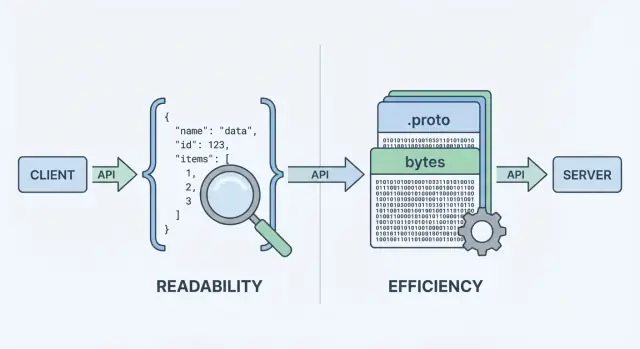
আপনার API যখন ডেটা পাঠায় বা গ্রহণ করে, তখন সেটির জন্য একটি ডেটা ফরম্যাট থাকা প্রয়োজন—রিকোয়েস্ট ও রেসপন্স বডি-তে তথ্য উপস্থাপনের একটি স্ট্যান্ডার্ড উপায়। সেই ফরম্যাট তারপর সিরিয়ালাইজ করা হয় (বাইটে রূপান্তর করা) নেটওয়ার্কে পাঠানোর জন্য, এবং ক্লায়েন্ট/সার্ভারে পুনরায় ডিসিরিয়ালাইজ করে ব্যবহারযোগ্য অবজেক্টে ফিরিয়ে আনা হয়।
দুইটি সাধারণ পছন্দ হল JSON এবং Protocol Buffers (Protobuf)। উভয়েই একই ব্যবসায়িক ডেটা (user, order, timestamps, আইটেম তালিকা) উপস্থাপন করতে পারে, কিন্তু পারফরম্যান্স, পে-লোড সাইজ ও ডেভেলপার ওয়ার্কফ্লো নিয়ে আলাদা ট্রেড-অফ করে।
JSON (JavaScript Object Notation) একটি টেক্সট-ভিত্তিক ফরম্যাট, অবজেক্ট ও অ্যারে মত সহজ কাঠামো দিয়ে গঠিত। REST API-তে এটি জনপ্রিয় কারণ পড়তে সহজ, লগ করাও সহজ, এবং curl বা ব্রাউজারের DevTools দিয়ে তৎক্ষণাৎ পরীক্ষা করা যায়।
অনেক ভাষায় দুর্দান্ত সাপোর্ট থাকায় JSON সর্বত্র—রেসপন্সটি চোখে দেখে বুঝে ফেলা যায়।
Protobuf হলো Google তৈরি একটি বাইনারি সিরিয়ালাইজেশন ফরম্যাট। টেক্সট পাঠানোর পরিবর্তে এটি .proto স্কিমা অনুযায়ী কম্প্যাক্ট বাইনারি পাঠায়। স্কিমায় ফিল্ড, টাইপ, এবং সংখ্যাসূচক ট্যাগ বর্ণিত থাকে।
বাইনারি ও স্কিমা-চালিত হওয়ার কারণে Protobuf সাধারণত ছোট পে-লোড তৈরি করে এবং পার্সিং দ্রুত হতে পারে—এটি গুরুত্বপূর্ণ যেখানে অনুরোধের পরিমাণ বেশি, মোবাইল নেটওয়ার্ক আছে, বা লেটেন্সি সংবেদনশীল সার্ভিস (gRPC-এ সাধারণত দেখা যায়) ।
কী পাঠানো হচ্ছে তা আলাদা, কিভাবে তা এনকোড করা হচ্ছে তা আলাদা। "user" যার id, name, email—উভয় ফরম্যাটেই মডেল করা যায়। মূল পার্থক্য আসে দাম যে আপনি দেবেন:
একটি একক সমাধান নেই। পাবলিক-ফেসিং API-র অনেক ক্ষেত্রেই JSON ডিফল্ট কারণ এটি অ্যাক্সেসযোগ্য ও নমনীয়। অভ্যন্তরীণ সার্ভিস-টু-সার্ভিস, পারফরম্যান্স-সংবেদনশীল সিস্টেম, বা কড়া চুক্তি দরকার হলে Protobuf ভাল হতে পারে। এই গাইডের উদ্দেশ্য হলো আপনার সীমাবদ্ধতার ওপর ভিত্তি করে পছন্দ করতে সাহায্য করা—ইডিয়োলজি নয়।
API যখন ডেটা রিটার্ন করে, সরাসরি “অবজেক্ট” পাঠানো যায় না—প্রথমে সেগুলোকে বাইটের স্ট্রিমে রূপান্তর করতে হয়। এই রূপান্তর সিরিয়ালাইজেশন—এটিকে ভাবুন ডেটা প্যাক করে শিপ করার মতো। বিপরীতে ক্লায়েন্ট ওই বাইটগুলো ডিসিরিয়ালাইজ করে পুনরায় মেমোরি অবজেক্ট পায়।
টিপিক্যাল রিকোয়েস্ট/রেসপন্স ফ্লো:
এই "এনকোডিং স্টেপ"-টিই যেখানে ফরম্যাটের চয়ন গুরুত্বপূর্ণ। JSON এনকোডিং পাঠযোগ্য টেক্সট তৈরি করে যেমন {"id":123,"name":"Ava"}। Protobuf এনকোডিং কম্প্যাক্ট বাইনারি যা টুল ছাড়া মানব-পাঠ্য নয়।
প্রতিটি রেসপন্স প্যাক ও আনপ্যাক করতে হয়—ফরম্যাট প্রভাব ফেলে:
curl টেস্ট, ও লগ/ইনস্পেকশনের সুবিধা।আপনি JSON gRPC-এ ব্যবহার করতে পারেন (transcoding এর মাধ্যমে) বা Protobuf plain HTTP-এ ব্যবহার করতে পারেন, কিন্তু স্ট্যাকের ডিফল্ট আরাম (ফ্রেমওয়ার্ক, গেটওয়ে, ক্লায়েন্ট লাইব্রেরি, ডিবাগিং অভ্যাস) প্রায়ই দৈনন্দিন অপারেশনে কী সহজ মনে হয় তা নির্ধারণ করে।
লোকেরা যখন protobuf vs json তুলনা করে, তারা সাধারণত শুরু করে দুটি মেট্রিক দিয়ে: পে-লোড কত বড় এবং encode/decode কত সময় নেয়। সারাংশ: JSON টেক্সট এবং সাধারণত verbose; Protobuf বাইনারি এবং কম্প্যাক্ট।
JSON ক্ষেত্রের প্রতিটি ফিল্ডের নাম পুনরাবৃত্তি করে এবং সংখ্যাকে টেক্সট হিসেবে পাঠায়, তাই বেশিরভাগ সময় আরও বাইট পাঠায়। Protobuf ফিল্ড নামের বদলে নম্বর ব্যবহার করে এবং ভ্যালুগুলো কার্যকরভাবে প্যাক করে—বিশেষ করে বড় অবজেক্ট, repeated ফিল্ড, এবং ডিপলি নেস্টেড ডেটার ক্ষেত্রে পার্থক্য বেশি দেখা যায়।
তবে, কমপ্রেশন পার্থক্য কমিয়ে দিতে পারে। gzip বা brotli-তে JSON-এর পুনরাবৃত্তি হওয়া কী খুব ভালোভাবে কম্প্রেস হয়, তাই বাস্তব ডিপ্লয়মেন্টে JSON ও Protobuf-র মধ্যে সাইজ পার্থক্য ছোট হতে পারে। Protobuf-ও কম্প্রেস করা যায়, তবে আপেক্ষিক লাভ সাধারণত কম।
JSON পার্সারকে টোকেনাইজ ও ভ্যালিডেট করতে হয়, স্ট্রিংকে নম্বরে রূপান্তর করতে হয়, এবং এস্কেপিং/ইউনিকোড-হ্যান্ডলিং করতে হয়। Protobuf ডিকোডিং বেশি সরাসরি: ট্যাগ পড়া → টাইপ করা ভ্যালু পড়া। অনেক সার্ভিসে Protobuf CPU সময় ও গার্বেজ তৈরি কমায়, যা লোডের নিচে টেল লেটেন্সি উন্নত করতে পারে।
মোবাইল নেটওয়ার্ক বা উচ্চ-লেটেন্সি লিঙ্কে, কম বাইট সাধারণত দ্রুত ট্রান্সফার এবং কম রেডিও সময় দেয় (ব্যাটারি-ও সাহায্য করতে পারে)। কিন্তু যদি রেসপন্স ইতিমধ্যে ছোট হয়, TLS হ্যান্ডশেক, সার্ভার প্রসেসিং ইত্যাদি ডোমিনেট করতে পারে—তাই ফরম্যাট পছন্দ কম দৃশ্যমান হতে পারে।
আপনার বাস্তব পে-লোড দিয়ে মাপুন:
এভাবে ‘API সিরিয়ালাইজেশন’ বিতর্ককে এমন ডেটায় রূপান্তর করবেন যা আপনার API-র জন্য বিশ্বাসযোগ্য।
ডেভেলপার এক্সপেরিয়েন্সে JSON সাধারণত ডিফল্ট জয়ী। JSON রিকোয়েস্ট বা রেসপন্স প্রায় যেকোন জায়গায় ইন্সপেক্ট করা যায়: ব্রাউজারের DevTools, curl আউটপুট, Postman, রিভার্স প্রক্সি, এবং প্লেন-টেক্সট লগে। যখন কিছু ভেঙে যায়, "আমরা আসলে কী পাঠিয়েছি?" সাধারণত একটি কপি-পেস্ট দূরত্বেই থাকে।
Protobuf ভিন্ন: কম্প্যাক্ট ও কড়া, কিন্তু মানুষ-পাঠযোগ্য নয়। র-লগ করলে base64 ব্লব বা অনবোঝা বাইনারি দেখায়। পে-লোড বুঝতে .proto স্কিমা ও decoder দরকার (যেমন protoc, ভাষা-নির্দিষ্ট টুলিং, বা সার্ভিসের জেনারেটেড টাইপ)।
JSON-এ সমস্যা পুনরুত্পাদন সহজ: লগ করা পে-লোড নিয়ে সিকিউরিটি রিড্যাক্ট করে curl দিয়ে পুনরায় চালাও—এটাই একটি ন্যূনতম টেস্ট কেস।
Protobuf-এ সাধারণত ডিবাগ করবেন:
এই অতিরিক্ত ধাপগুলো ম্যানেজযোগ্য—শুধু দলের কাছে একটি রেপিটেবল ওয়ার্কফ্লো থাকতে হবে।
স্ট্রাকচার্ড লগিং দুই ফরম্যাটেই সাহায্য করে। রিকোয়েস্ট আইডি, মেথড নাম, ইউজার/অ্যাকাউন্ট আইডি এবং গুরুত্বপূর্ণ ফিল্ডগুলো লগ করুন পুরো বডি নয়।
Protobuf-এর জন্য:
.proto ব্যবহার করা হয়েছিল।JSON-এর জন্য:
API কেবল ডেটা নেয় না—এগুলো অর্থ বহন করে। JSON এবং Protobuf-এর মধ্যে সবচেয়ে বড় পার্থক্য হলো সেই অর্থ কত স্পষ্টভাবে নির্ধারিত ও শক্তভাবে প্রয়োগ করা হয়।
ডিফল্টভাবে JSON "স্কিমা-হীন": আপনি যেকোন অবজেক্ট পাঠাতে পারেন এবং অনেক ক্লায়েন্ট সেটি গ্রহণ করবে যতক্ষণ তা যুক্তিসঙ্গত দেখায়।
এই নমনীয়তা সুবিধাজনক শুরুর দিকে, কিন্তু ত্রুটি লুকিয়ে দিতে পারে। সাধারণ সমস্যা:
userId এক রেসপন্সে, user_id অন্য রেসপন্সে, বা কিছু কোডপাথে অনুপস্থিত।null মানে "অজানা", "সেট করা হয়নি", বা "ইচ্ছাকৃতভাবে ফাঁকি"—বিভিন্ন ক্লায়েন্ট ভিন্নভাবে ব্যাখ্যা করতে পারে।আপনি JSON Schema বা OpenAPI যোগ করতে পারেন, কিন্তু JSON নিজেই তা বাধ্যতামূলক করে না।
.proto দ্বারা স্পষ্ট চুক্তিProtobuf একটি .proto ফাইলের মাধ্যমে স্কিমা অনিবার্য করে। স্কিমা নির্দিষ্ট করে:
এটি দুর্ঘটনাজনক পরিবর্তন (যেমন সংখ্যা থেকে স্ট্রিং করা) প্রতিরোধ করতে সাহায্য করে কারণ জেনারেটেড কোড নির্দিষ্ট টাইপ আশা করে।
Protobuf-এ নম্বরগুলোই নম্বর থাকে, enum নির্দিষ্ট মানেই সীমাবদ্ধ, এবং timestamp সাধারণত well-known types ব্যবহার করে মডেল করা হয় (আডহক স্ট্রিং ফরম্যাট না করে)। proto3-এ অনুপস্থিতি এবং ডিফল্ট মান পার্থক্য optional ফিল্ড বা wrapper টাইপ ব্যবহার করলে স্পষ্ট হয়।
যদি আপনার API-র নির্ভরতা নির্দিষ্ট টাইপ ও পূর্বাভাসযোগ্য পার্সিংয়ের উপর, Protobuf সেই গার্ডরেইলগুলো প্রদান করে যা JSON-এ কনভেনশনভিত্তিকভাবে সম্পাদন করা হয়।
API বিকশিত হয়: আপনি ফিল্ড যোগ করবেন, আচরণ সামান্য বদলাবেন, পুরানো অংশ অবলুপ্ত করবেন। লক্ষ্য হলো ক্লায়েন্টদের অবাক না করে কন্ট্রাক্ট পরিবর্তন করা।
ভাল বিবর্তন কৌশল সাধারণত উভয়কে লক্ষ্য করে, কিন্তু backward compatibility সাধারণত মিনিমাম হিসেবে ধরা হয়।
Protobuf-এ প্রতিটি ফিল্ডের একটি নম্বর থাকে (যেমন email = 3)—ওয়্যারে সেই নম্বরই ব্যবহার হয়। নাম মূলত মানুষের এবং জেনারেটেড কোডের জন্য।
এর কারণে:
নিরাপদ পরিবর্তন (সাধারণত)
ঝুঁকিপূর্ণ পরিবর্তন (প্রায়ই ব্রেকিং)
সেরা অনুশীলন: পুরানো নাম/নম্বর reserved করুন এবং চেঞ্জলগ রাখুন।
JSON-এ বিল্ট-ইন স্কিমা না থাকায় সামঞ্জস্য আপনার প্যাটার্নের ওপর নির্ভর করে:
ডিপ্রিকেশন আগেই ডকুমেন্ট করুন: কোনো ফিল্ড কখন ডিপ্রিকেট করা হবে, কত দিন সমর্থিত থাকবে, এবং প্রতিস্থাপন কী। একটি সহজ versioning policy (যেমন "অ্যাডিটিভ পরিবর্তন non-breaking; রিমুভালের জন্য নতুন মেজর ভার্সন") প্রকাশ করুন এবং তা মেনে চলুন।
JSON বনাম Protobuf বেছে নেয়ার সময় প্রায়ই নির্ধারণ করে কোথায় আপনার API চলবে—এবং আপনার দল কী বজায় রাখতে চায়।
JSON কার্যত ইউনিভার্সাল: প্রতিটি ব্রাউজার ও ব্যাকএন্ড রানটাইম এটি পার্স করতে পারে অতিরিক্ত ডিপেন্ডেন্সি ছাড়াই। ওয়েব অ্যাপে fetch() + JSON.parse() হল সাধারণ পথ, এবং প্রোক্সি/গেটওয়ে/অবজার্ভেবিলিটি টুলগুলো সাধারণত JSON বুঝে।
Protobuf ব্রাউজারে চালানো যায়, কিন্তু শূন্য-খরচ নয়—সাধারণত Protobuf লাইব্রেরি বা জেনারেটেড JS/TS কোড যোগ করতে হবে, বান্ডলিং সাইজ ও ইন্সপেকশন কিভাবে হবে তা সিদ্ধান্ত নিতে হবে।
iOS/Android এবং ব্যাকএন্ড ভাষাগুলোতে (Go, Java, Kotlin, C#, Python ইত্যাদি) Protobuf সাপোর্ট পরিপক্ব। Protobuf-এ সাধারণত আপনি প্ল্যাটফর্ম-নির্দিষ্ট লাইব্রেরি ব্যবহার করে .proto থেকে কোড জেনারেট করবেন।
কোড জেনারেশন নিয়ে সুবিধা:
কস্টও আছে:
.proto প্যাকেজ প্রকাশ, ভার্সন পিনিং)Protobuf gRPC-র সঙ্গে ঘনিষ্ঠভাবে আন্তঃসংযুক্ত—আপনি পেয়ে যান সার্ভিস ডেফিনিশন, ক্লায়েন্ট স্টাব, স্ট্রিমিং, এবং ইন্টারসেপ্টর। gRPC বিবেচনা করলে Protobuf প্রাকৃতিক চয়ন।
যদি আপনি ঐতিহ্যগত JSON REST API তৈরি করেন, JSON টুলিং ইকোসিস্টেম (ব্রাউজার DevTools, curl- ফ্রেন্ডলি ডিবাগিং, জেনেরিক গেটওয়ে) সাধারণত সহজ—বিশেষত পাবলিক API ও দ্রুত ইন্টিগ্রেশনের জন্য।
যদি আপনি এখনও API স্যাফেস এক্সপ্লোরিং করছেন, উভয় স্টাইলে দ্রুত প্রোটোটাইপ করা সাহায্য করে। উদাহরণস্বরূপ Koder.ai-র মতো প্ল্যাটফর্মে দলগুলো প্রায়ই একটি JSON REST API স্পিন আপ করে broad compatibility-র জন্য এবং অভ্যন্তরীণ gRPC/Protobuf সার্ভিস করে efficiency-র জন্য, তারপর বাস্তব পে-লোড বেঞ্চমার্ক করে কোনটা "ডিফল্ট" হবে তা নির্ধারণ করে। Koder.ai পূর্ণ-স্ট্যাক অ্যাপ জেনারেট করতে পারে (React ওয়েব, Go + PostgreSQL ব্যাকএন্ড, Flutter মোবাইল) এবং প্ল্যানিং মোড, স্ন্যাপশট/রোলব্যাক সাপোর্ট করে—কেন এমনভাবে কন্ট্রাক্ট ইটারেট করা যায় তা ব্যবহারিকভাবে দেখায়।
JSON বনাম Protobuf পছন্দ কেবল পে-লোড সাইজ বা স্পিড নয়—এটি কিভাবে আপনার API ক্যাশিং স্তর, গেটওয়ে এবং দল যে টুলগুলোতে নির্ভর করে তাদের সাথে খাপ খায় তা প্রভাবিত করে।
অধিকাংশ HTTP ক্যাশিং ইনফ্রা (ব্রাউজার ক্যাশ, রিভার্স প্রক্সি, CDN) HTTP সেমান্টিক্স-এ অপটিমাইজড—কোন নির্দিষ্ট বডি ফরম্যাট নয়। CDN যে কোনো বাইট ক্যাচ করতে পারে যতক্ষণ রেসপন্স cacheable।
তবে অনেক দল edge-এ HTTP/JSON আশা করে কারণ ইন্সপেকশন ও ট্রাবলশুটিং সহজ। Protobuf-এ ক্যাশিং কাজ করবে, কিন্তু আপনাকে সচেতন হতে হবে:
Vary)Cache-Control, ETag, Last-Modified) সেট করাযদি আপনি JSON ও Protobuf উভয় সাপোর্ট করেন, কনটেন্ট নেগোটিয়েশন ব্যবহার করুন:
Accept: application/json বা Accept: application/x-protobufContent-Type দিয়ে রেসপন্ড করেক্যাশগুলো যাতে বুঝতে পারে, Vary: Accept যোগ করুন। না হলে ক্যাশ হয়তো JSON রেসপন্স স্টোর করবে এবং Protobuf ক্লায়েন্টকে তা সার্ভ করে (বা উল্টো)।
API গেটওয়ে, WAF, রিকোয়েস্ট/রেসপন্স ট্রান্সফর্মার, এবং অবজার্ভেবিলিটি টুলগুলো প্রায়ই JSON বডি ধরে নিচ্ছে—for:
বাইনারি Protobuf এই বৈশিষ্ট্যগুলো সীমিত করতে পারে যদি আপনার টুলিং Protobuf-সচেতন না হয় (অথবা আপনি ডিকোডিং ধাপ যোগ না করেন)।
একটি সাধারণ প্যাটার্ন হল edge-এ JSON, ভিতরে Protobuf:
এভাবে বাইরের ইন্টিগ্রেশন সহজ থাকে এবং অভ্যন্তরীণভাবে Protobuf-এর পারফরম্যান্স সুবিধা পাওয়া যায়।
JSON বা Protobuf বেছে নেওয়া কেবল কিভাবে ডেটা এনকোড/পার্স করা হয় তা পরিবর্তন করে—কিন্তু এটি authentication, encryption, authorization, এবং সার্ভার-সাইড ভ্যালিডেশন এর মতো মৌলিক নিরাপত্তা চাহিদাগুলোর জায়গা নিতে পারে না। দ্রুত সিরিয়ালাইজারই যদি অনট্রাস্টেড ইনপুট সীমা ছাড়িয়ে যায় তাহলে API নিরাপদ থাকবে না।
কখনও কখনও মনে হতে পারে Protobuf "আরো নিরাপদ" কারণ তা বাইনারি—কিন্তু এটা নিরাপত্তা কৌশল নয়। আক্রমণকারীরা মানুষের পাঠযোগ্যতা ছাড়াই API-তে আক্রমণ করতে পারে। TLS, authz চেক, ইনপুট ভ্যালিডেশন, এবং নিরাপদ লগিং উভয় ফরম্যাটেই প্রয়োজন।
দুই ফরম্যাটেই সাধারণ ঝুঁকি আছে:
API-কে নির্ভরযোগ্য রাখতে একই গার্ডরেইল প্রয়োগ করুন:
সারমর্ম: “বাইনারি বনাম টেক্সট” মূলত পারফরম্যান্স ও ইউজার-অ্যারগনমিক্স প্রভাবিত করে। নিরাপত্তা ও নির্ভরযোগ্যতা আসে সীমা, আপডেটেড ডিপেনডেন্সি, ও স্পষ্ট ভ্যালিডেশন থেকে—যে ফরম্যাটই ব্যবহার করুন না কেন।
JSON বনাম Protobuf বেছে নেওয়া সাধারণত কোনটি “ভাল” সেটির প্রশ্ন নয়—এটা নির্ভর করে আপনার API কী জন্য অপটিমাইজ করা দরকার: মানুষের জন্য সুবিধা ও বিস্তৃতি, নাকি উন্নত দক্ষতা ও কড়া কন্ট্রাক্ট।
JSON সাধারণত নিরাপদ ডিফল্ট যখন আপনাকে বিস্তৃত কম্প্যাটিবিলিটি ও দ্রুত ট্রাবলশুটিং দরকার।
টিপিক্যাল পরিস্থিতি:
curl টেস্ট)Protobuf সাধারণত জিতে যখন পারফরম্যান্স ও কনসিস্টেন্সি মানুষের পাঠযোগ্যতার চেয়ে বেশি গুরুত্ব পায়।
টিপিক্যাল পরিস্থিতি:
যদি আপনি এখনও দ্বিধায় থাকেন, “edge-এ JSON, ভিতরে Protobuf” কার্যকরী সমঝোতা।
ফরম্যাট পরিবর্তন করা মানে সবকিছু রিরাইট করা নয়—এটা গ্রাহকদের ঝুঁকি কমিয়ে ধাপে ধাপে বদলানো। নিরাপদ পদক্ষেপগুলো সাধারণতঃ API-এর ব্যবহার যোগ্যতা বজায় রাখে এবং রোলব্যাক সহজ করে।
কম-ঝুঁকির সাটলেট বেছে নিন—অন্তর্ভূক্ত সার্ভিস-টু-সার্ভিস কল বা একটি রিড-ওনলি এন্ডপয়েন্ট। এতে আপনি Protobuf স্কিমা, জেনারেটেড ক্লায়েন্ট, এবং অবজার্ভেবিলিটি পরিবর্তনগুলো যাচাই করতে পারবেন বড় রিফ্যাক্টরের ঝুঁকি ছাড়াই।
একটি বাস্তব প্রথম ধাপ: একটি বিদ্যমান রিসোর্সের জন্য Protobuf প্রতিনিধিত্ব যোগ করা, কিন্তু JSON শেপ একই রেখে দিন। এতে আপনি দ্রুতই দেখতে পাবেন কোথায় আপনার ডেটা মডেল অস্পষ্ট (null বনাম missing, সংখ্যা বনাম স্ট্রিং, তারিখ ফরম্যাট) এবং সেগুলো স্কিমায় ঠিক করতে পারবেন।
বহিরাগত API-র জন্য দ্বৈত সমর্থন সাধারণত সোজা পথ:
Content-Type ও Accept হেডার ব্যবহার করুন।/v2/...) স্থাপন করতে পারেন অস্থায়ীভাবে।এই সময়ে নিশ্চিত করুন উভয় ফরম্যাট একই সোর্স-অফ-থ্রথ মডেল থেকে উৎপন্ন হচ্ছে যাতে ধীর-গতিতে বিচ্যুতি না ঘটে।
পরিকল্পনা করুন:
.proto ফাইল, ফিল্ড মন্তব্য, এবং বাস্তব রিকোয়েস্ট/রেসপন্স উদাহরণ (JSON ও Protobuf উভয়) প্রকাশ করুন যাতে গ্রাহকরা সঠিকভাবে ডেটা বুঝতে পারে। একটি সংক্ষেপিত “migration guide” ও চেঞ্জলগ সহায়ক—সমর্থন লোড ও গ্রহণকাল কমায়।
JSON বা Protobuf বেছে নেওয়া প্রায়ই আইডিয়োলজি নয়—আপনার ট্র্যাফিক, ক্লায়েন্ট, ও অপারেশনাল সীমাবদ্ধতার বাস্তবতার ব্যাপার। সবচেয়ে নির্ভরযোগ্য পথ হল মাপা, সিদ্ধান্ত ডকুমেন্ট করা, এবং আপনার API পরিবর্তনকে ‘‘বোরিং’’ রাখা।
প্রতিনিধিত্বশীল এন্ডপয়েন্টে একটি ছোট পরীক্ষা চালান।
ট্র্যাক করুন:
স্টেজিং-এ প্রোডাকশন-মত ডেটা দিয়ে করুন, তারপর প্রোডাকশনে ছোট ট্র্যাফিক স্লাইসে যাচাই করুন।
JSON Schema/OpenAPI বা .proto ফাইল যাই ব্যবহার করুন:
Protobuf বেছে নেওয়ার পরও আপনার ডকস বন্ধুত্বপূর্ণ রাখুন:
যদি আপনি ডকস বা SDK গাইড বজায় রাখেন, তাদের লিঙ্কগুলি স্পষ্ট করুন (উদাহরণস্বরূপ: /docs এবং /blog)। যদি মূল্যবোধ বা ব্যবহার সীমা ফরম্যাট-নির্ভর হয়, তা স্পষ্ট করুন (/pricing)।
উপসংহার: আপনার ট্রেড-অফগুলো মাপুন, সিদ্ধান্ত ডকুমেন্ট করুন, এবং API পরিবর্তনকে ধীরে ধীরে নেওয়ার কৌশল রাখুন—তাহলেই ফরম্যাট পরিবর্তন বড় ঝামেলা হবে না।
JSON হল একটি টেক্সট-ভিত্তিক ফরম্যাট যা পড়া, লগ করা এবং সাধারণ টুলগুলো দিয়ে টেস্ট করা সহজ। Protobuf হল .proto স্কিমা দ্বারা সংজ্ঞায়িত একটি কম্প্যাক্ট বাইনারি ফরম্যাট, যা সাধারণত ছোট পে-লোড এবং দ্রুত পার্সিং দেয়।
চয়ন করুন আপনার সীমাবদ্ধতাগুলোর ওপর ভিত্তি করে: সম্প্রচারযোগ্যতা ও ডিবাগযোগ্যতা (JSON) বনাম দক্ষতা ও কড়া কন্ট্রাক্ট (Protobuf)।
API গুলো বাইট পাঠায়—মেমোরি অবজেক্ট পাঠায় না। Serialization হলো আপনার সার্ভারের অবজেক্টগুলোকে নেটওয়ার্কের জন্য পে-লোডে (JSON টেক্সট বা Protobuf বাইনারি) রূপান্তর করা; deserialization সেই বাইটগুলোকে ক্লায়েন্ট/সার্ভারের অবজেক্টে ফিরিয়ে আনা।
আপনার ফরম্যাটের পছন্দ ব্যান্ডউইথ, লেটেন্সি, এবং (ডি)সিরিয়ালাইজেশনে ব্যয় হওয়া CPU-কে প্রভাবিত করে।
সাধারণতঃ হ্যাঁ—বিশেষ করে বড় বা নেস্টেড অবজেক্ট ও repeated ফিল্ডগুলোর ক্ষেত্রে, Protobuf-এর ট্যাগ-বেজড বাইনারি এনকোডিং JSON-এর চেয়ে কম বাইট পাঠায়।
তবে gzip বা brotli অন করলে JSON-এর পুনরাবৃত্তি করা কী ইত্যাদি ভালোভাবে কম্প্রেস হয়, ফলে বাস্তব পরিবেশে সাইজের পার্থক্য অনেকক্ষেত্রে কমে যেতে পারে। সবসময় র ক্ ও এবং কমপ্রেসড উভয় অবস্থায় মাপুন।
শর্টকাটে বলতে গেলে: হতে পারে। JSON পার্সিং-এ টোকেনাইজেশন, এস্কেপিং/ইউটিএফ-হ্যান্ডলিং, স্ট্রিং→নাম্বর রূপান্তর ইত্যাদি জড়িত; Protobuf ডিকোডিং সাধারণত ট্যাগ → টাইপ করা ভ্যালু পড়া, তাই CPU ও অলোকেশন কম হতে পারে।
তবুও যদি পে-লোড খুব ক্ষুদ্র হয়, TLS/RTT/অ্যাপ্লিকেশন কাজ লেটেন্সিকে আধিপত্য করাতে পারে—সুতরাং মাপাই সঠিক নির্দেশক।
প্রাথমিকভাবে: কারণ Protobuf বাইনারি এবং দৃঢ়, কাঁচা বাইট লগ করলে তা base64 বা অনবুাঝ্য বাইনারি দেখায়। JSON মানব-পাঠ্য এবং DevTools, লগ, curl, Postman-এ সহজে দেখা যায়। Protobuf ডিকোড করতে .proto স্কিমা এবং নির্দিষ্ট টুলিং প্রয়োজন।
একটি ভাল প্র্যাকটিস হচ্ছে নিরাপদভাবে ডিকোড করে একটি redacted JSON ‘debug view’ লগ করা যাতে অন-কল/ইনসিডেন্ট সময় দ্রুত ত্রুটি বিশ্লেষণ করা যায়।
JSON মূলত স্কিমা-হীন: যেকোন অবজেক্ট পাঠানো যায় যদি সেটা যৌক্তিক দেখায়। সুবিধা আছে দ্রুত বিকাশে, কিন্তু ঝুঁকিও আছে: অনিয়মিত field নাম, ‘stringly-typed’ মান (সংখ্যা/বুলিয়ান/তারিখ স্ট্রিং হিসেবে পাঠানো) এবং null-এর বিভিন্ন ব্যাখ্যা।
Protobuf .proto ফাইলে স্পষ্ট কন্ট্রাক্ট দেয়: কোন ফিল্ড আছে, টাইপ কী, এবং ওয়্যারে কোন নম্বর দিয়ে পাঠানো হবে—এগুলো টাইপ-ভিত্তিক ভুল কমায়।
Protobuf-এ প্রতিটি ফিল্ডের একটি নম্বর (ট্যাগ) থাকে—ওয়্যারে সেটাই পরিচিতি। সেজন্য নিরাপদ পরিবর্তনগুলি সাধারণতঃ নতুন optional ফিল্ড যোগ করা (নতুন নম্বর), enum-এ নতুন ভ্যালু যোগ করা ইত্যাদি।
ভাঙন ঘটায় এমন পরিবর্তনগুলি হল: একটি ব্যবহৃত ফিল্ড নম্বর অন্য মান/টাইপে পুনরায় ব্যবহার করা, টাইপ অসঙ্গতভাবে পরিবর্তন, বা একটি ফিল্ড বাদ দিয়ে তার নম্বর পুনরায় ব্যবহার করা। reserved ব্যবহার করে পুরানো নাম/নম্বর সংরক্ষণ করা সর্বোত্তম।
JSON-এ স্কিমা অনুশাসন ও নিয়মের ওপর নির্ভর করে—নতুন ফিল্ড অ্যাডিটিভভাবে যোগ করা, টাইপ বদল না করা এবং অনচেনা ফিল্ডগুলোকে নির্দ্বিধায় উপেক্ষা করার পরামর্শ থাকে।
JSON সর্বত্র চলে—ব্রাউজার, ব্যাকএন্ড, প্রক্সি ও অবজার্ভেবিলিটি টুলগুলো সাধারণত JSON সমর্থন করে। ব্রাউজারে Protobuf চালানো যায়, কিন্তু সাধারণত লাইব্রেরি/জেনারেটেড কোড, বান্ডলিং এবং টুলিং যোগ করতে হয়।
ব্যাকএন্ড/মোবাইলে Protobuf-এর লাইব্রেরি পরিপক্ব এবং .proto থেকে জেনারেটেড টাইপগুলো দ্রুত সিরিয়ালাইজ করে। gRPC-এ Protobuf-এর ইকোসিস্টেম শক্ত—সার্ভিস ডেফিনিশন, ক্লায়েন্ট স্টাব, স্ট্রিমিং সব মিলে।
ফরম্যাট বদল নিরাপত্তা প্রদান করে না। Protobuf বাইনারি হওয়ায় সেটা ‘অল্প পাঠযোগ্য’ হতে পারে, কিন্তু আক্রমণকারীকে পাঠযোগ্যতা দরকার নেই—তারা API-তে আক্রমণ করবে যদি auth/validation দুর্বল থাকে।
দুই ফরম্যাটের জন্য সাধারণ রক্ষা ব্যবস্থা:
লাইব্রেরি/পার্সার আপডেট রাখাও গুরুত্বপূর্ণ—পার্সার বাগগুলো ঝুঁকি বাড়ায়।
নিয়মিত সিদ্ধান্ত — মানুষ বান্ধবতা ও বিস্তৃতি বনাম দক্ষতা ও কড়া কন্ট্রাক্ট।
JSON-ই ডিফল্ট যখন: পাবলিক API, ব্রাউজার ক্লায়েন্ট, দ্রুত প্রোটোটাইপিং, সহজ ডিবাগিং ও REST-শৈলী ইত্যাদি।
Protobuf-ই ভালো যখন: উচ্চ থ্রুপুট, অনেক ছোট কল, অভ্যন্তরীন মাইক্রোসার্ভিস যেখানে আপনি উভয় প্রান্ত নিয়মিত, gRPC সিস্টেম, মোবাইল/এজ যেখানে পে-লোড ছোট থাকা দরকার।
একটি সাধারণ মাঝামাঝি প্যাটার্ন: "edge-এ JSON, ভিতরে Protobuf"—বহিরাগত ইন্টিগ্রেশন সহজ থাকে, অভ্যন্তরীণ কল দ্রুত হয়।
ধাপে ধাপে ঝুঁকি কমিয়ে নিন:
.proto ফাইল, উদাহরণ রিকোয়েস্ট/রেসপন্স, এবং মাইগ্রেশন গাইড প্রকাশ করুন।সব সময়ই উত্পাদনের মতো ডেটা দিয়ে বেঞ্চমার্ক করুন এবং ছোট ট্র্যাফিক স্লাইসে প্রয়োগ করে দেখুন।