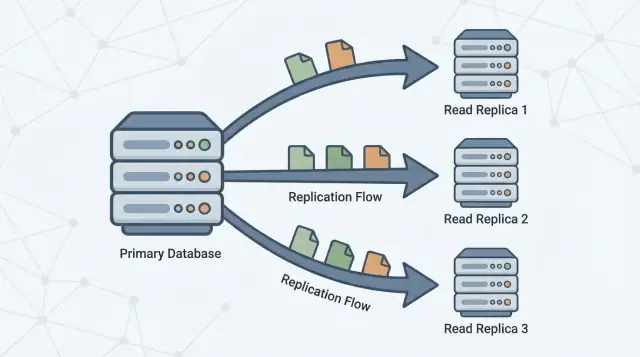
রিড রিপ্লিকা কী (এবং কী নয়)
একটি রিড রিপ্লিকা আপনার মূল ডাটাবেসের (অften প্রাইমারি বলা হয়) একটি কপি, যা ক্রমাগত পরিবর্তন গৃহীত করে আপডেট থাকে। আপনার অ্যাপ্লিকেশন রিপ্লিকায় শুধু পড়ার ক্যোয়ারিগুলো (যেমন SELECT) পাঠাতে পারে, যখন প্রাইমারি সব লেখার কাজ (যেমন INSERT, UPDATE, এবং DELETE) চালিয়ে যায়।
মৌলিক প্রতিশ্রুতি
প্রতিশ্রুতি সোজা: প্রাইমারিতে অতিরিক্ত চাপ না দিয়ে বেশি পড়ার ক্ষমতা।
আপনার অ্যাপে যদি প্রচুর “ফেচ” ট্রাফিক থাকে—হোমপেজ, প্রোডাক্ট পেজ, ইউজার প্রোফাইল, ড্যাশবোর্ড—তবে ঐ পড়ার কিছু অংশ এক বা একাধিক রিপ্লিকায় সরিয়ে দিলে প্রাইমারি লেখার কাজ ও গুরুত্বপূর্ণ রিডে ফোকাস করতে পারে। অনেক কনফিগারেশনে এটা নূন্যতম অ্যাপ পরিবর্তনেই করা যায়: একটাকে সোর্স-অফ-থ্রুথ রেখে রিপ্লিকাগুলোকে অতিরিক্ত ক্যোয়ারির জন্য যোগ করুন।
রিড রিপ্লিকা কী নয়
রিড রিপ্লিকাগুলো উপকারী, কিন্তু এগুলো যাদুকরী পারফরম্যান্স বোতাম নয়। এগুলো করবে না:
- লেখার ক্ষমতা বাড়ানো। সব লেখাই এখনও প্রাইমারিতে যায়।
- ধীর ক্যোয়ারিগুলো ফিক্স করা। যদি কোনো ক্যোয়ারি অকার্যকর (ইনডেক্স নেই, বিশাল টেবিল স্ক্যান, খারাপ জয়েন) হয়, তাহলে সেটি রিপ্লিকাতেও ধীর হবে—শুধু অন্য কোথাও ধীর হবে।
- ভাল স্কিমা ও ডেটা ডিজাইন প্রতিস্থাপন। রিপ্লিকাগুলো হটস্পট, অতিমাত্রায় বড় রো বা খুব বেশি এক “সবকিছুর টেবিল” সমাধান করে না।
- মনিটরিংয়ের প্রয়োজন কে নির্মূল করা। রিপ্লিকাগুলো আরও চলমান অংশ যোগ করে: ল্যাগ, কানেকশন সীমা, ও ফেইলওভার আচরণ।
এই গাইডের জন্য প্রত্যাশা নির্ধারণ
রিপ্লিকাগুলোকে ভাবুন একটি রিড-স্কেলিং টুল যার ট্রেড-অফ রয়েছে। নিবন্ধের বাকি অংশ ব্যাখ্যা করবে কখন এগুলো সত্যিকারের সাহায্য করে, সাধারণভাবে কোথায় ব্যাকফায়ার করে, এবং কীভাবে রেপ্লিকেশন ল্যাগ ও ইভেন্টুয়াল কনসিস্টেন্সি ব্যবহারকারীর দেখা ফলাফলে প্রভাব ফেলে যখন আপনি কপি থেকে পড়া শুরু করেন প্রাইমারির বদলে।
রিড রিপ্লিকা কেন আছে
একটি একক প্রাইমারি ডাটাবেস সার্ভার বেশিরভাগ সময় শুরুতেই “পর্যাপ্ত বড়” মনে হয়। এটি লেখাগুলো (ইনসার্ট, আপডেট, ডিলিট) হ্যান্ডেল করে এবং আপনার অ্যাপ, ড্যাশবোর্ড, অভ্যন্তরীণ টুলস থেকে প্রতিটি রিড (SELECT ক্যোয়ারি) উত্তর দেয়।
ব্যবহার বাড়ার সঙ্গে পড়াগুলো সাধারণত লেখার তুলনায় দ্রুত বাড়ে: প্রতিটি পেজ ভিউ কয়েকটি ক্যোয়ারি ট্রিগার করতে পারে, সার্চ স্ক্রিন অনেক লুকআপ করতে পারে, এবং অ্যানালিটিক্স-ধাঁচের ক্যোয়ারিগুলো অনেক সারি স্ক্যান করতে পারে। যদিও আপনার লেখার ভলিউম মাঝারি, তবুও প্রাইমারি জটিলতায় পড়ে যেতে পারে কারণ তাকে দুইটি কাজ একসাথে করতে হয়: পরিবর্তনগুলো নিরাপদে এবং দ্রুত গ্রহণ করা এবং বাড়তে থাকা পড়া ট্রাফিক কম ল্যাটেন্সিতে সার্ভ করা।
পড়া থেকে লেখা আলাদা করা
রিড রিপ্লিকাগুলো সেই কাজটি ভাগ করার জন্য আছে। প্রাইমারি লেখাগুলো প্রক্রিয়ায় ও “সত্যের উৎস” বজায় রাখতে ফোকাস করে, যখন এক বা একাধিক রিপ্লিকা পড়ার জন্য সেবা দেয়। যখন আপনার অ্যাপ কিছু ক্যোয়ারি রিপ্লিকাতে রুট করতে পারে, আপনি প্রাইমারির CPU, মেমরি, এবং I/O-তে চাপ কমাতে পারেন। সাধারণত এটি সামগ্রিক প্রতিক্রিয়াশীলতা উন্নত করে এবং লেখার দ্রুততা বা ব্রাস্টগুলোর জন্য আরো হেডরুম রাখে।
এক লাইনে রেপ্লিকেশন
রেপ্লিকেশন হল সেই প্রক্রিয়া যা প্রাইমারির পরিবর্তনগুলো কপি করে রিপ্লিকাগুলোকে আপ টু ডেট রাখে। প্রাইমারি পরিবর্তনগুলো রেকর্ড করে, এবং রিপ্লিকাগুলো সেগুলো অ্যাপ্লাই করে যাতে তারা প্রায় একই ডেটা দিয়ে ক্যোয়ারির উত্তর দিতে পারে।
এই প্যাটার্নটি বহু ডাটাবেস সিস্টেম ও ম্যানেজড সার্ভিসে সাধারণ (উদাহরণ: PostgreSQL, MySQL, এবং ক্লাউড-হোস্টেড ভ্যারিয়েন্ট)। ঠিক কিভাবে কাজ করে তা আলাদা হতে পারে, কিন্তু লক্ষ্য একটাই: প্রাইমারি অনন্তকালিকভাবে ভার্টিকালি স্কেল না করে রিড ক্যাপাসিটি বাড়ানো।
রেপ্লিকেশন কিভাবে কাজ করে (সরল মানসিক মডেল)
প্রাইমারি ডাটাবেসকে “সত্যের উৎস” মনে করুন। এটি প্রতিটি লেখা গ্রহণ করে—অর্ডার তৈরি, প্রোফাইল আপডেট, পেমেন্ট রেকর্ড—এবং সেই পরিবর্তনগুলোকে একটি নির্দিষ্ট ক্রমে অ্যাসাইন করে।
এক বা একাধিক রিড রিপ্লিকা তারপর প্রাইমারি ফলো করে, ওই পরিবর্তনগুলো কপি করে যাতে তারা পড়ার ক্যোয়ারিগুলি (যেমন “আমার অর্ডার ইতিহাস দেখাও”) প্রাইমারিতে অতিরিক্ত লোড না বাড়িয়ে সার্ভ করতে পারে।
মৌলিক ফ্লো
- প্রাইমারি লেখাগুলো গ্রহণ করে এবং সেগুলোকে একটি দায়ী লগে রেকর্ড করে (নাম ডাটাবেস অনুযায়ী ভিন্ন হতে পারে)।
- রিপ্লিকাগুলো সেই লগ এন্ট্রিগুলো স্ট্রিম বা ফেচ করে প্রাইমারির কাছ থেকে।
- রিপ্লিকাগুলো একই ক্রমে সেই পরিবর্তনগুলো রেপ্লে করে, ধীরে ধীরে ক্যাচ আপ করে।
পড়াগুলো রিপ্লিকাকে সার্ভ করা যায়, কিন্তু লেখাগুলো এখনও প্রাইমারিতে যায়।
সিঙ্ক্রোনাস বনাম অ্যাসিঙ্ক্রোনাস রেপ্লিকেশন (উচ্চ স্তরের)
রেপ্লিকেশন দুইটি প্রধান মোডে হতে পারে:
- সিঙ্ক্রোনাস: প্রাইমারি একটি রিপ্লিকা (বা কোয়ারাম) থেকে কনফার্মেশন পাওয়ার আগে লেখাকে “কমিট” হিসেবে বিবেচনা করে না। এটা স্টেল রিড কমায়, কিন্তু লেখার ল্যাটেন্সি বাড়ায় এবং রিপ্লিকা/নেটওয়ার্ক সমস্যার প্রতি সংবেদনশীল করে।
- অ্যাসিঙ্ক্রোনাস: প্রাইমারি লেখা সঙ্গে সঙ্গেই কমিট করে, এবং রিপ্লিকাগুলো পরে কcatch up করে। এটা লেখাকে ত্বরান্বিত ও রেসিলিয়েন্ট রাখে, কিন্তু রিপ্লিকাগুলো সাময়িকভাবে পিছিয়ে থাকতে পারে।
রেপ্লিকেশন ল্যাগ এবং “ইভেন্টুয়াল কনসিস্টেন্সি”
ওই বিলম্ব—রিপ্লিকাগুলো প্রাইমারির পিছনে থাকা—কেই বলা হয় রেপ্লিকেশন ল্যাগ। এটা স্বয়ংক্রিয়ভাবে ব্যর্থতা নয়; পড়া স্কেল করার জন্য প্রায়শই যে ট্রেড-অফ মেনে নেওয়া হয় তা হলো এইটা।
উপভোক্তার দৃষ্টিতে, ল্যাগ ইভেন্টুয়াল কনসিস্টেন্সি হিসেবে দেখা যায়: আপনি কিছু পরিবর্তন করলে সিস্টেম সর্বত্র সাময়িকভাবে কনসিস্টেন্ট হবে, কিন্তু তা অবিলম্বে নাও হতে পারে।
উদাহরণ: আপনি আপনার ইমেল ঠিকানা আপডেট করেন এবং প্রোফাইল পেজ রিফ্রেশ করেন। যদি পেজটি এমন একটি রিপ্লিকা থেকে সার্ভ হয় যা কয়েক সেকেন্ড পিছনে থাকে, আপনি সাময়িকভাবে পুরনো ইমেল দেখতে পারেন—যতক্ষণ না রিপ্লিকা আপডেটটি অ্যাপ্লাই করে এবং “ক্যাচ আপ” হয়।
কখন রিড রিপ্লিকা সত্যিকারের সাহায্য করে
রিড রিপ্লিকা সাহায্য করে যখন আপনার প্রাইমারি ডাটাবেস লেখার জন্য সুস্থ কিন্তু পড়ার ট্রাফিক সার্ভ করতে গিয়ে ওভারহেল্ম হচ্ছে। যখন আপনি লজিক্যালভাবে একটি অর্থবহ অংশ SELECT লোড অফলোড করতে পারেন বিনা-schema পরিবর্তন ছাড়াই, তখন রিপ্লিকাগুলো সর্বোচ্চ কার্যকারিতা দেখায়।
আপনি রিড-বাউন্ড কিনা—চিহ্নগুলো
নিচের মত প্যাটার্ন দেখুন:
- ট্র্যাফিক পিকে প্রাইমারির CPU বেশি, অথচ লেখার থ্রুপুট অস্বাভাবিকভাবে বেশি নয়
SELECT ক্যোয়ারিগুলোর অনুপাতে INSERT/UPDATE/DELETE-এর হার খুব বেশি- পিক সময়ে রিড ক্যোয়ারিগুলো ধীরে যাচ্ছে যদিও লেখাগুলো স্থিতিশীল
- রিড-হেভি এন্ডপয়েন্ট (প্রোডাক্ট পেজ, ফিড, সার্চ) দ্বারা কানেকশন পুল স্যাচুরেশন
পড়া সমস্যা নিশ্চিত করার মেট্রিকস (যেগুলো চেক করবেন)
রিপ্লিকা যোগ করার আগে কয়েকটি কনক্রিট সিগন্যাল দিয়ে যাচাই করুন:
- CPU বনাম I/O: রিড ল্যাটেন্সি বাড়লে প্রাইমারির CPU পুরো কাটা ছিল? না কি ডিস্ক রিড I/O ছিল বটলনেক?
- ক্যোয়ারী মিক্স:
SELECT স্টেটমেন্টে কাটার সময়ের শতাংশ (স্লো ক্যোয়ারী লগ/APM থেকে)।
- p95/p99 রিড ল্যাটেন্সি: রিড এন্ডপয়েন্টস এবং ডাটাবেস ক্যোয়ারী ল্যাটেন্সি আলাদাভাবে ট্র্যাক করুন।
- বাফার/ক্যাশ হিট রেট: কম হিট রেট মানে রিডগুলো ডিস্কে পড়াচ্ছে।
- টপ ক্যোয়ারিগুলো বাই টোটাল টাইম: একটা ব্যয়বহুল ক্যোয়ারিই “রিড লোড” ডমিনেট করতে পারে।
সস্তা ফিক্সগুলো এড়িয়ে যাবেন না
প্রায়ই প্রথমে বেস্ট মুভ হলো টিউনিং: সঠিক ইনডেক্স যোগ করা, একটি ক্যোয়ারি পুনরায় লেখা, N+1 কল কমানো, বা হট রিডগুলো ক্যাশ করা। এগুলো রিপ্লিকা চালানোর চেয়ে দ্রুত এবং সস্তা সমাধান হতে পারে।
দ্রুত চেকলিস্ট: রিপ্লিকা বনাম টিউনিং
রিপ্লিকা বেছে নিন যদি:
- বেশিরভাগ লোড পড়া ট্রাফিক; পড়াগুলো ইতোমধ্যে তুলনামূলকভাবে অপ্টিমাইজ করা হয়েছে
- আপনি অফলোড করা ক্যোয়ারিগুলোর জন্য মাঝে মাঝে স্টেলনেস সহ্য করতে পারেন
- আপনি ঝুঁকির ছাড়াই দ্রুত অতিরিক্ত ক্ষমতা চান
প্রথমে টিউনিং বেছে নিন যদি:
- কয়েকটি ক্যোয়ারিই মোট রিড টাইম ডমিনেট করে
- ইনডেক্স নেই বা অদক্ষ জয়েন দেখা যায়
- কম ট্র্যাফিকে পড়াগুলো ধীর (ক্যোয়ারি ডিজাইনের সমস্যা)
সবচেয়ে ভাল-ফিট ইউজ কেসগুলো
রিড রিপ্লিকা সবচেয়ে মূল্যবান যখন আপনার প্রাইমারি ডাটাবেস লেখার কাজ নিয়ে ব্যস্ত, কিন্তু ট্রাফিকের বড় অংশ পড়াহেভি। প্রাইমারি–রিপ্লিকা আর্কিটেকচারে সঠিক ক্যোয়ারিগুলো রিপ্লিকায় পাঠালে ডাটাবেস পারফরম্যান্স উন্নত হয় কোন ফিচার পরিবর্তন ছাড়াই।
1) ড্যাশবোর্ড ও অ্যানালিটিক্স যা ট্রানজ্যাকশন ধীর করবে না
ড্যাশবোর্ডগুলো প্রায়ই দীর্ঘ চলমান ক্যোয়ারি চালায়: গ্রুপিং, বড় সময়সীমায় ফিল্টারিং, বা বহু টেবিল জয়েন। ওই ক্যোয়ারিগুলো CPU, মেমরি ও ক্যাশ নিয়ে প্রতিযোগিতা করে ট্রানজ্যাকশনের সঙ্গে।
রিপ্লিকা ভাল জায়গা যখন:
- অভ্যন্তরীণ রিপোর্টিং
- অ্যাডমিন ড্যাশবোর্ড
- "দৈনিক/সাপ্তাহিক মেট্রিক্স" ভিউ
আপনি প্রাইমারিকে দ্রুত, পূর্বানুমেয় ট্রানজ্যাকশনে রাখেন আর অ্যানালিটিক্স রিডগুলো আলাদা স্কেলে সার্ভ করবেন।
2) সার্চ ও ব্রাউজ পেজ যেখানে পড়ার ভলিউম বেশি
ক্যাটালগ ব্রাউজিং, ইউজার প্রোফাইল, কনটেন্ট ফিড অনেকসময় একই ধরনের উচ্চ ভলিউম রিড ক্যোয়ারি তৈরি করে। যখন সেই রিড-স্কেলিং প্রেসার বটলনেক হয়, রিপ্লিকাগুলো লোড শোষণ করতে পারে এবং ল্যাটেন্সি স্পাইক কমায়।
এটি বিশেষত কার্যকর যখন রিডগুলো ক্যাশ-মিস ভারি (অনেক ইউনিক ক্যোয়ারি) বা পুরোপুরি অ্যাপ ক্যাশের ওপর নির্ভর করা যায় না।
3) ব্যাকগ্রাউন্ড জব যা অনেক ডেটা স্ক্যান করে
এক্সপোর্ট, ব্যাকফিল, সামারি পুনরায় গণনা, ও “X মিলে এমন সব রেকর্ড খুঁজ” ধরনের জবগুলো প্রাইমারি থ্র্যাশ করতে পারে। এই স্ক্যানগুলো রিপ্লিকায় চালানো নিরাপদ।
শুধু নিশ্চিত থাকুন জবটি ইভেন্টুয়াল কনসিস্টেন্সি সহ্য করে: রেপ্লিকেশন ল্যাগ থাকলে এটি সাম্প্রতিক আপডেটগুলো দেখতে নাও পাবে।
4) লো-ল্যাটেন্সি মাল্টি-রিজিয়ন রিড (স্টেলনেস সাবধানতা)
গ্লোবালি ইউজার সার্ভ করলে, তাদের কাছাকাছি রিড রিপ্লিকা রাখলে RTT কমে ল্যাটেন্সি কমে। ট্রেড-অফ হলো স্টেল রিডের সম্ভাবনা ল্যাগ বা নেটওয়ার্ক সমস্যায় বাড়ে, তাই এটি এমন পেজগুলোর জন্য ভালো যেখানে “প্রায়ই আপ টু ডেট” গ্রহণযোগ্য (ব্রাউজ, রিকমেন্ডেশন, পাবলিক কনটেন্ট)।
কোথায় রিপ্লিকাগুলো ব্যাকফায়ার করতে পারে
রিপোর্টিংকে ট্রানজ্যাকশন থেকে আলাদা করুন
ভিতরের রিপোর্টিং স্ক্রিন তৈরি করুন যাতে ভারী রিডগুলো ক্রিটিক্যাল লেখার পথে মিশে না যায়।
রিড রিপ্লিকাগুলো ভালো যখন “কিছুটা কাছাকাছি” পছন্দনীয়। এগুলো ব্যাকফায়ার করে যখন আপনার প্রোডাক্টটি গোপনে প্রত্যাশা করে যে প্রতিটি পড়া সর্বশেষ লেখাকে প্রতিফলিত করবে।
ক্লাসিক সিম্পটম: “আমি ঠিক এখনই আপডেট করলাম, এটা কেন পরিবর্তিত হলো না?”
একটি ইউজার তাদের প্রোফাইল এডিট করে, ফর্ম সাবমিট করে, বা অ্যাকাউন্ট সেটিংস পরিবর্তন করে—এবং পরের পেজ লোড এমনি এক রিপ্লিকা থেকে আসে যা কয়েক সেকেন্ড পিছিয়ে আছে। আপডেট সাফল্য করেছে, কিন্তু ইউজার পুরনো ডেটা দেখে পুনরায় চেষ্টা করে, ডাবল-সাবমিট করে, বা বিশ্বাস হারায়।
এই সমস্যা বিশেষভাবে খারাপ যখন ইউজার অবিলম্বে কনফার্মেশন আশা করে: ইমেল বদলানো, প্রেফারেন্স টগল, ডকুমেন্ট আপলোড, বা কমেন্ট পোস্ট করে রিডাইরেক্ট করা।
“অবশ্যই বর্তমান থাকা উচিত” স্ক্রিনগুলো (এখানে জুয়ার না করার মত)
কিছু রিড সাময়িকভাবে হলেও স্টেল সহ্য করতে পারে না:
- শপিং কার্ট ও চেকআউট টোটাল
- ওয়ালেট ব্যালান্স, লয়ালটি পয়েন্ট, ইনভেন্টরি কাউন্ট
- “আমার পেমেন্ট হয়েছে কি?” স্ট্যাটাস স্ক্রিন
রিপ্লিকা পিছিয়ে থাকলে আপনি ভুল কার্ট টোটাল দেখাতে পারেন, স্টকওভারসেল করতে পারেন, বা পুরনো ব্যালান্স দেখাতে পারেন। পরে সিস্টেম ঠিক করে দিলেও ইউজার এক্সপিরিয়েন্স ও সাপোর্ট ভলিউমে প্রভাব পড়ে।
অ্যাডমিন ও অপস টুলস-এ সর্বশেষ সত্য দরকার
অভ্যন্তরীণ ড্যাশবোর্ডগুলো প্রায়ই বাস্তব সিদ্ধান্ত নেয়: ফ্রড রিভিউ, কাস্টমার সাপোর্ট, অর্ডার ফুলফিলমেন্ট, মডারেশন, ও ইনসিডেন্ট রেসপন্স। যদি অ্যাডমিন টুল রিপ্লিকা পড়ে, আপনি অসম্পূর্ণ ডেটার ওপর কাজ করতে পারেন—যেমন আগে থেকেই রিফান্ড হওয়া অর্ডার আবার রিফান্ড করা, অথবা সর্বশেষ স্ট্যাটাস মিস করা।
ব্যবহারযোগ্য ফিক্স: “রিড-ইওর-রাইটস” প্রাইমারিতে রুট করা
একটি সাধারণ প্যাটার্ন হলো শর্তসাপেক্ষ রাউটিং:
- ইউজার লেখার পরে তাদের পরবর্তী কনফার্মেশন রিডগুলো সংক্ষিপ্ত উইন্ডোর জন্য (কয়েক সেকেন্ড থেকে মিনিট) প্রাইমারিতে পাঠান।
- ব্যাকগ্রাউন্ড, অ্যানোনিমাস, বা নন-ক্রিটিক্যাল রিডগুলো রিপ্লিকাতে রাখুন।
এটা রিপ্লিকাগুলো দ্বারা প্রাপ্ত সুবিধা ধরে রাখে কিন্তু কনসিস্টেন্সি অনুমানকে গর্বের বিষয় বানায় না।
রেপ্লিকেশন ল্যাগ এবং স্টেল রিডগুলো বোঝা
রেপ্লিকেশন ল্যাগ হচ্ছে প্রাইমারিতে লেখাটি কমিট হওয়ার এবং সেই পরিবর্তনটি রিড রিপ্লিকায় দৃশ্যমান হওয়ার মধ্যে সময়ের পার্থক্য। আপনার অ্যাপ যদি ওই বিলম্বে রিপ্লিকা থেকে পড়ে, তাহলে সেটা "স্টেল" ফলাফল দিতে পারে—যা কিছু মুহূর্ত আগের সত্য, কিন্তু আর নয়।
ল্যাগ কেন ঘটে
ল্যাগ স্বাভাবিক এবং চাপের সময় সাধারণত বাড়ে। সাধারণ কারণগুলো:
- প্রাইমারিতে লোড স্পাইক: অনেক লেখার ফলে পাঠাতে ও অ্যাপ্লাই করতে বেশি পরিবর্তন।
- রিপ্লিকা আন্ডারপাওয়ারড বা ব্যস্ত: রিপ্লিকা পরিবর্তনগুলো যত দ্রুত আসে তত দ্রুত অ্যাপ্লাই করতে পারে না (CPU, ডিস্ক I/O)।
- নেটওয়ার্ক লেটেন্সি বা জিটার: রেপ্লিকেশন স্ট্রিম সরবরাহে বিলম্ব।
- বড় ট্রানজ্যাকশন/বাল্ক আপডেট: একটি বড় পরিবর্তন সিরিয়ালাইজ, ট্রান্সফার, ও রেপ্লে করতে সময় নিচ্ছে।
প্রডাক্ট আচরণে স্টেল রিড কিভাবে দেখায়
ল্যাগ শুধু "ফ্রেশনেস"-কেই নয়—ইউজারের দৃষ্টিতে সঠিকতাকেও প্রভাবিত করে:
- ইউজার প্রোফাইল আপডেট করে, তারপর রিফ্রেশ করলে পুরনো ভ্যালু দেখতে পারে।
- "আনরিড মেসেজ" বা নোটিফিকেশন ব্যাজ গণনা একটু পিছিয়ে যেতে পারে।
- অ্যাডমিন/রিপোর্টিং স্ক্রিনগুলো সর্বশেষ অর্ডার, রিফান্ড বা স্ট্যাটাস পরিবর্তন মিস করতে পারে।
ব্যবহারিকভাবে কী করা যায়
আপনার ফিচার কতটা সহ্য করতে পারে তা নির্ধারণ করুন:
- টলারেন্স উইন্ডো যোগ করুন: "ডেটা ৩০ সেকেন্ড পর্যন্ত পুরনো হতে পারে" অনেক ড্যাশবোর্ডের জন্য গ্রহণযোগ্য।
- রাইট-আফটার-রিড প্রাইমারিতে রুট করুন: ইউজার কিছু পরিবর্তন করার পরে ওই এন্টিটি একটি সংক্ষিপ্ত সময় প্রাইমারি থেকে পড়ুন।
- UI মেসেজিং: প্রত্যাশা সেট করুন ("আপডেট হচ্ছে…", "দেখতে কয়েক সেকেন্ড লাগতে পারে")।
- রিট্রাই লজিক: যদি ক্রিটিক্যাল রিডে সদ্য-লিখিত রেকর্ড না দেখা যায়, প্রাইমারিতে রিট্রাই করুন বা সংক্ষিপ্ত বিলম্ব পরে পুনরায় চেষ্টা করুন।
কী মনিটর ও অ্যালার্ট করবেন
রিপ্লিকা ল্যাগ (টাইম/বাইটস), রিপ্লিকা অ্যাপ্লাই রেট, রেপ্লিকেশন এরর, এবং রিপ্লিকা CPU/ডিস্ক I/O ট্র্যাক করুন। যখন ল্যাগ আপনার টলারেন্স ছাড়িয়ে যায় (উদাহরণ: 5s, 30s, 2m) তখন অ্যালার্ট করুন এবং যখন ল্যাগ ধারাবাহিকভাবে বাড়তে থাকে তখনও সতর্ক থাকুন (এটি ইঙ্গিত করে যে রিপ্লিকা কখনোই ক্যাচ আপ করতে পারবে না ছাড়া হস্তক্ষেপের)।
রিড স্কেলিং বনাম রাইট স্কেলিং (মূল ট্রেড-অফ)
কোডের উপর পূর্ণ নিয়ন্ত্রণ রাখুন
যেকোনো সময় সোর্স কোড এক্সপোর্ট করুন যাতে আপনার ওয়ার্কফ্লোতে কুয়েরি, ইনডেক্স ও রুটিং টিউন করতে পারেন।
রিড রিপ্লিকা হচ্ছে রিড স্কেলিং-এর টুল: SELECT ক্যোয়ারিগুলো সার্ভ করার আরো জায়গা যোগ করা। এটা রাইট স্কেলিং-এর টুল নয়: কতগুলো INSERT/UPDATE/DELETE অপারেশন আপনার সিস্টেম নিতে পারে সেটা বাড়ায় না।
রিড স্কেলিং: রিপ্লিকাগুলো যেগুলো ভালো
রিপ্লিকা যোগ করলে আপনি রিড ক্যাপাসিটি বাড়ান। যদি আপনার অ্যাপ রিড-হেভি এন্ডপয়েন্টে বটলনেক হয় (প্রোডাক্ট পেজ, ফিড, লুকআপ), আপনি ঐ ক্যোয়ারিগুলো একাধিক মেশিনে ছড়িয়ে দিতে পারেন।
এর ফলে সাধারণত উন্নতি হয়:
- লোডের অধীনে ক্যোয়ারী ল্যাটেন্সি (প্রাইমারিতে কম কনটেনশন)
- রিডের জন্য থ্রুপুট (আরও CPU/মেমরি/I/O উপলব্ধ)
- ভারি রিড (রিপোর্টিং) আলাদা হওয়া, যাতে সেগুলো ট্রানজ্যাকশনের সাথে বিঘ্ন না করে
রাইট স্কেলিং: রিপ্লিকাগুলো কি করে না
একটি সাধারণ ভুল ধারণা হলো “আরও রিপ্লিকা = বেশি লিখন ক্ষমতা।” সাধারণ প্রাইমারি–রিপ্লিকা সেটআপে সব লেখাই প্রাইমারিতে যায়। প্রকৃতপক্ষে, আরো রিপ্লিকা প্রাইমারির কাজ একটু বাড়াতে পারে, কারণ তাকে প্রতিটি রিপ্লিকায় রেপ্লিকেশন ডেটা তৈরি ও পাঠাতে হয়।
যদি আপনার বেদনা লেখার থ্রুপুট হয়, রিপ্লিকা তা ঠিক করবে না। সাধারণত আপনি দেখতে হবে ভিন্ন পন্থা (ক্যোয়ারী/ইনডেক্স টিউনিং, ব্যাচিং, পার্টিশনিং/শার্ডিং, অথবা ডেটা মডেল পরিবর্তন)।
কানেকশন সীমা ও পুলিং: লুকানো বটলনেক
যদিও রিপ্লিকা আপনাকে আরো রিড CPU দেয়, আপনি এখনও কানেকশন সীমা-তে আঘাত খেতে পারেন। প্রতিটি ডাটাবেস নোডের সর্বোচ্চ একযোগে কানেকশন সংখ্যা আছে, এবং রিপ্লিকা যোগ করা মানে আপনার অ্যাপ কতগুলো জায়গায় কানেক্ট করতে পারে তা বাড়ে—কিন্তু মোট চাহিদা কমে না।
প্রায়োগিক নিয়ম: কানেকশন পুলিং (অথবা একটি পুলার) ব্যবহার করুন এবং সার্ভিস-বাই-সার্ভিস আপনার পার-কানেকশন সংখ্যা অনুধাবনযোগ্য রাখুন। নইলে রিপ্লিকাগুলো কেবল “অতিরিক্ত ডাটাবেস যা ওভারলোড করা যায়” হয়ে উঠবে।
খরচের ট্রেড-অফ: ক্ষমতা বিনামূল্যে নয়
রিপ্লিকাগুলো বাস্তব খরচ যোগ করে:
- আরও নোড (কম্পিউট খরচ)
- আরও স্টোরেজ (প্রতিটি রিপ্লিকা সাধারণত সম্পূর্ণ কপি স্থাপন করে)
- অপস প্রচেষ্টা (ল্যাগ মনিটরিং, ব্যাকআপ/রিস্টোর কৌশল, স্কিমা পরিবর্তন, ইনসিডেন্ট রেসপন্স)
ট্রেড-অফটি সহজ: রিপ্লিকাগুলো আপনাকে রিড হেডরুম ও আইসোলেশন কিনে দেয়, কিন্তু জটিলতা বাড়ায় এবং লেখার সিলিং বাড়ায় না।
হাই অ্যাভেইলেবিলিটি ও ফেইলওভার: রিপ্লিকাগুলো কী করতে পারে
রিড রিপ্লিকাগুলো রিড-উপলব্ধতা বাড়াতে পারে: যদি আপনার প্রাইমারি ওভারলোড বা অল্প সময়ের জন্য অনুপলব্ধ হয়, আপনি এখনও কিছু রিড-ওয়ানলি ট্র্যাফিক রিপ্লিকাগুলো থেকে সার্ভ করতে পারেন। এটা কনটেন্ট-টলারেন্ট পেজগুলোকে রেসপন্সিভ রাখে এবং প্রাইমারি ইনসিডেন্টের ব্লাস্ট রেডিয়াস কমায়।
কিন্তু রিপ্লিকাগুলো একা সম্পূর্ণ হাই-অ্যাভেইলেবিলিটি পরিকল্পনা নয়। একটি রিপ্লিকা সাধারণত স্বয়ংক্রিয়ভাবে লেখা গ্রহণের জন্য প্রস্তুত না থাকে, এবং "রিডেবল কপি আছে" মানে আলাদা থেকে "সিস্টেম নিরাপদে ও দ্রুত আবার লেখাগুলো গ্রহণ করতে পারে"।
প্রোমোশন ও ফেইলওভার (ধারণাগতভাবে)
ফেইলওভার সাধারণত মানে: প্রাইমারি ফেল ঘটলে → একটি রিপ্লিকা বেছে নিন → সেটিকে প্রোমোট করে নতুন প্রাইমারি করুন → লেখাগুলো (এবং সাধারনত রিডগুলো) নতুন প্রাইমারিতে রিডারেক্ট করুন।
কিছু ম্যানেজড ডাটাবেস এগুলো স্বয়ংক্রিয় করে, তবে মূল ধারণা একই: আপনি কাকে লেখাগুলো গ্রহণ করতে দেওয়া হবে সেটা বদলাচ্ছেন।
পরিকল্পনা করার মূল ঝুঁকি
- স্টেল রিপ্লিকা ডেটা: রিপ্লিকা পিছিয়ে থাকতে পারে। যদি আপনি সেটি প্রোমোট করেন, আপনি সাম্প্রতিক লেখাগুলো হারাতে পারেন যেগুলো কখনও রেপ্লিকেট হয়নি।
- স্প্লিট-ব্রেইন এড়ানো: একসঙ্গে দুই নোডকে লেখা গ্রহণ করা থেকে রোধ করতে হবে। এজন্য প্রোমোশন সাধারণত একটি একক অথরিটি (ম্যানেজড কন্ট্রোল প্লেন, কোয়ারাম সিস্টেম, বা কঠোর অপারেশনাল পদ্ধতি) দ্বারা গেট করা হয়।
- রাউটিং ও ক্যাশ: আপনার অ্যাপকে নির্ভরযোগ্যভাবে টার্গেট পরিবর্তন করার উপায় দরকার—কানেকশন স্ট্রিং, DNS, প্রক্সি, বা একটি ডাটাবেস রাউটার। নিশ্চিত করুন যে লেখা ট্রাফিক ভুলবশত পুরানো প্রাইমারিতে চালিয়ে না যায়।
এটাকে একটি ফিচারের মতো পরীক্ষা করুন
ফেইলওভারকে অনুশীলন করুন। স্ট্যাজিং-এ গেম-ডে টেস্ট চালান (এবং উৎপাদনে সতর্কভাবে কম-ঝুঁকির উইন্ডোতে): প্রাইমারি লস সিমুলেট করুন, টাইম-টু-রিকভার মাপুন, রাউটিং যাচাই করুন, এবং নিশ্চিত করুন আপনার অ্যাপ রিড-ওয়ানলি সময় ও পুনসংযোগ ভালভাবে হ্যান্ডেল করে।
ব্যবহারিক রাউটিং প্যাটার্ন (রিড/রাইট স্প্লিটিং)
রিড রিপ্লিকাগুলো সাহায্য করে যদি আপনার ট্রাফিক সত্যিই তাদের কাছে যায়। “রিড/রাইট স্প্লিটিং” হচ্ছে নিয়মগুলোর সেট যা লেখাগুলোকে প্রাইমারিতে পাঠায় এবং যোগ্য রিডগুলোকে রিপ্লিকায়—এবং তা সঠিকতা না ভাঙে।
প্যাটার্ন 1: অ্যাপ্লিকেশনে স্প্লিট
সর্বাধিক সরল পদ্ধতি হচ্ছে ডেটা এক্সেস লেয়ারে স্পষ্ট রাউটিং:
- সব লেখাগুলো (
INSERT/UPDATE/DELETE, স্কিমা পরিবর্তন) প্রাইমারিতে যায়।
- শুধুমাত্র নির্বাচিত রিডগুলো রিপ্লিকা ব্যবহার করতে পারে।
এটি বোঝা সহজ এবং রোলব্যাকও সহজ। এখানে আপনি ব্যবসায়িক নিয়ম এনকোড করতে পারেন—যেমন "চেকআউটের পরে অর্ডার স্ট্যাটাস কয়েকক্ষণের জন্য প্রাইমারি থেকে পড়বে"।
প্যাটার্ন 2: প্রক্সি বা ড্রাইভার দিয়ে স্প্লিট
কিছু দল ডেটাবেস প্রক্সি বা স্মার্ট ড্রাইভার পছন্দ করে যা “প্রাইমারি বনাম রিপ্লিকা” এন্ডপয়েন্ট বুঝে এবং ক্যোয়ারী টাইপ বা কানেকশন সেটিংস অনুযায়ী রাউট করে। এটি অ্যাপ কোড পরিবর্তন কমায়, কিন্তু সতর্ক থাকুন: প্রক্সি প্রোডাক্ট দৃষ্টিকোণ থেকে কোন রিড “সেফ” তা নির্ভরযোগ্যভাবে জানে না।
কোন ক্যোয়ারিগুলো রিপ্লিকায় পাঠানো যায়
ভালো প্রার্থী:
- অ্যানালিটিক্স, রিপোর্টিং ওয়ার্কলোড, ড্যাশবোর্ড
- সার্চ/ব্রাউজ পেজ যেখানে একটু স্টেল ডেটা গ্রহণযোগ্য
- ব্যাকগ্রাউন্ড জব যেগুলো রিট্রাই করে এবং সর্বশেষ মান দরকার নেই
ইউজারের লেখার সঙ্গে অবিলম্বে অনুবর্তী রিডগুলো (যেমন “প্রোফাইল আপডেট → প্রোফাইল রিলোড”) রিপ্লিকায় পাঠানো এড়িয়ে চলুন যতক্ষণ না আপনার কনসিস্টেন্সি স্ট্র্যাটেজি আছে।
ট্রানজ্যাকশন ও সেশন কনসিস্টেন্সি
একটি ট্রানজ্যাকশনের ভিতরে সব পড়া প্রাইমারিতেই রাখুন।
ট্রানজ্যাকশন ছাড়া, “রিড-ইওর-রাইটস” সেশন বিবেচনা করুন: লেখার পরে একটি ইউজার/সেশনকে সংক্ষিপ্ত TTL-র জন্য প্রাইমারিতে পিন করুন, বা নির্দিষ্ট ফলো-আপ ক্যোয়ারিগুলো প্রাইমারিতে রাউট করুন।
ছোট থেকে শুরু করুন এবং পরিমাপ করুন
একটি রিপ্লিকা যোগ করুন, নির্দিষ্ট কিছু এন্ডপয়েন্ট/ক্যোয়ারি সেখানে রাউট করুন, এবং পরিমাপ করুন:
- প্রাইমারির CPU ও রিড IOPS
- রিপ্লিকার ব্যবহার
- এরর রেট ও ল্যাটেন্সি পেরসেন্টাইল
- স্টেল রিড সম্পর্কিত ইনসিডেন্ট
ইমপ্যাক্ট স্পষ্ট ও সুরক্ষিত হলে রাউটিং বাড়ান।
মনিটরিং ও অপারেশন বেসিক
আত্মবিশ্বাসে পরিবর্তন করুন
রেপ্লিকেশন ট্রেড-অফগুলো কাজ করার সময় মাইগ্রেশন ও রোলব্যাক নিরাপদে টেস্ট করুন।
রিড রিপ্লিকাগুলো “সেট এন্ড ফোরগেট” নয়। তারা অতিরিক্ত ডাটাবেস সার্ভার—প্রতিটি তাদের নিজস্ব পারফরম্যান্স সীমা, ব্যর্থতা মোড, ও অপারেশনাল কাজ নিয়ে আসে। একটু মনিটরিং শৃঙ্খলই প্রায়শই পার্থক্য যোগায় “রিপ্লিকা সহায়ক ছিল” এবং “রিপ্লিকা বিভ্রান্তি বাড়াল” এদের মধ্যে।
কী দেখবেন (কয়েকটি গুরুত্বপূর্ণ মেট্রিক)
ইউজার-ফেসিং সিম্পটম ব্যাখ্যা করতে পারে এমন সূচকগুলোর ওপর ফোকাস করুন:
- রিপ্লিকা ল্যাগ: একটি রিপ্লিকা প্রাইমারির কতটা পিছনে আছে (সেকেন্ড, বাইট, বা WAL/LSN পজিশন)। এটি আপনার স্টেল রিডের আগাম সতর্কতা।
- রেপ্লিকেশন ত্রুটি: ব্রোকেন কানেকশন, অথ ফেইলিউর, ডিস্ক-ফুল, বা রিপ্লিকেশন স্লট সমস্যা। এগুলো কেবল “নয়েজ” না—ঘটনা হিসেবে দেখুন।
- ক্যোয়ারী ল্যাটেন্সি (p50/p95) রিপ্লিকা বনাম প্রাইমারি: রিপ্লিকাগুলোও ধীর হতে পারে এমনকি প্রাইমারি ঠিক থাকলে (বিভিন্ন ক্যাশ স্টেট, ভিন্ন হার্ডওয়্যার, দীর্ঘ রিপোর্ট)।
- ক্যাশ হিট রেট: একটি রিপ্লিকা বারবার মিস করছে মানে রিস্টার্ট বা ট্রাফিক শিফটে উচ্চ ল্যাটেন্সি হতে পারে।
ক্যাপাসিটি পরিকল্পনা: কতগুলো রিপ্লিকা?
রিড অফলোড লক্ষ্য করে এক রিপ্লিকা দিয়ে শুরু করুন। আরো যোগ করুন যখন স্পষ্ট সীমা থাকে:
- রিড থ্রুপুট: একটি রিপ্লিকা পিক QPS বা ভারী অ্যানালিটিক্স হ্যান্ডেল করতে পারবে না।
- আইসোলেশন: রিপোর্টিং ওয়ার্কলোড আলাদা রাখার জন্য একটি ডেডিকেটেড রিপ্লিকা দিন।
- জিওগ্রাফি: প্রতি রিজিয়নে একটি করে রিপ্লিকা রিড ল্যাটেন্সি কমায়, কিন্তু অপারেশনাল ওভারহেড বাড়ায়।
এক বাস্তবিক নিয়ম: রিপ্লিকা শুধুমাত্র তখন স্কেল করুন যখন আপনি যাচাই করেছেন যে পড়াই বটলনেক (ইনডেক্স, ধীর ক্যোয়ারি, অ্যাপ ক্যাশ না)।
সাধারণ অপারেশনাল কাজ
- ব্যাকআপ: ঠিক করুন কোথায় ব্যাকআপ নেবেন। রিপ্লিকা থেকে ব্যাকআপ নেওয়া প্রাইমারির ওপর লোড কমাতে পারে, কিন্তু কনসিস্টেন্সি চাহিদা ও রিপ্লিকা স্বাস্থ্য যাচাই করুন।
- স্কিমা পরিবর্তন: রেপ্লিকেশন মাথায় রেখে মাইগ্রেশন টেস্ট করুন (দীর্ঘ-চলমান DDL ল্যাগ বাড়াতে পারে)। রোলআউটগুলো কোঅর্ডিনেটেড রাখুন যাতে অ্যাপ ও স্কিমা পরিবর্তন প্রচারিত হওয়ার সময় সামঞ্জস্য থাকে।
- রক্ষণাবেক্ষণ উইন্ডো: রিপ্লিকা প্যাচিং বা রিস্টার্ট করলে রিড ক্যাপাসিটি সাময়িকভাবে কমে যায়। রোটেশন পরিকল্পনা করুন যাতে আপনি প্রয়োজনীয় রিড হেডরুমের নিচে না নামেন।
সমস্যা সমাধান চেকলিস্ট: “রিপ্লিকা ধীর”
- রিপ্লিকা ল্যাগ দেখুন: উচ্চ হলে ইউজার রিট্রাই বা স্টেল ডেটা দেখা কারণ হতে পারে।
- রিপ্লিকা বনাম প্রাইমারির স্লো ক্যোয়ারী লগ তুলনা করুন: রিপোর্টিং ক্যোয়ারি প্রায়ই এখানে উঠে আসে।
- রিপ্লিকা হোস্টে CPU, মেমরি, ডিস্ক I/O, নেটওয়ার্ক চেক করুন।
- প্রাইমারিতে লক কন্টেনশন বা দীর্ঘ ট্রানজ্যাকশন আছে কিনা দেখুন যা রেপ্লিকেশন দেরি করছে।
- নিশ্চিত করুন রিড রাউটিং একক রিপ্লিকায় ওভারলোড করছে না (অসামঞ্জস্য লোড-ব্যালান্সিং)।
- যাচাই করুন ইনডেক্সগুলো রিপ্লিকায় আছে (এগুলো প্রাইমারি দ্বারা-মিরর হওয়া উচিত) এবং স্ট্যাটিস্টিকস আপ-টু-ডেট আছে।
বিকল্প ও সহজ সিদ্ধান্ত কাঠামো
রিড রিপ্লিকা রিড স্কেলিংয়ের একটি টুল, কিন্তু সাধারণত প্রথম লিভার নয়। অপারেশনাল জটিলতা বাড়ানোর আগে পরীক্ষা করুন একটি সরল ফিক্স একই ফল দেবে কি না।
প্রথমে চেষ্টা করার বিকল্পগুলো
ক্যাশিং অনেক রিডকে ডাটাবেসের বাইরে সরিয়ে দিতে পারে। “রিড-মোস্টলি” পেজ (প্রোডাক্ট ডিটেইল, পাবলিক প্রোফাইল, কনফিগ) জন্য অ্যাপ ক্যাশ বা CDN ড্রাস্টিকভাবে লোড কমাতে পারে—রিপ্লিকেশন ল্যাগ পরিচয় করিয়ে না দিয়ে।
ইনডেক্স ও ক্যোয়ারী অপ্টিমাইজেশন সাধারণত রিপ্লিকাগুলোর চেয়ে বেশি লাভ দেয়—কিছু ব্যয়বহুল ক্যোয়ারি CPU গুলো পোড়াচ্ছে হলে সঠিক ইনডেক্স যোগ করা, SELECT কলাম কমানো, N+1 সমস্যা ঠিক করা, বা খারাপ জয়েন ঠিক করা অনেক সময় যথেষ্ট।
ম্যাটিরিয়ালাইজড ভিউ / প্রি-এগ্রিগেশন ড্যাশবোর্ডের জন্য ভালো: জটিল ক্যোয়ারিগুলো বারবার চালানোর বদলে হিসাবগুলো সংরক্ষণ করে সময়ে সময়ে রিফ্রেশ করুন।
কখন শার্ডিং/পার্টিশনিং বিবেচনা করবেন
যদি আপনার লেখাই বটলনেক হয় (হট রো, লক কন্টেনশন, লেখার I/O সীমা), রিপ্লিকা সাহায্য করবে না। তখন টেবিলগুলো সময়/টেন্যান্ট অনুসারে পার্টিশন করা বা কাস্টমার আইডি অনুযায়ী শার্ডিং করে লেখার লোড ছড়ানো প্রয়োজন। এটি বড় আর্কিটেকচারের পরিবর্তন, কিন্তু বাস্তব সমস্যার সমাধান করে।
সহজ সিদ্ধান্ত কাঠামো
চারটি প্রশ্ন করুন:
- লক্ষ্য কী? রিড ল্যাটেন্সি কমানো, রিপোর্টিং কাজ আলাদা করা, না কি হাই-অ্যাভেইলেবিলিটি বাড়ানো?
- পড়াগুলো কতটা তাজা থাকতে হবে? যদি স্টেল গ্রহণযোগ্য না হয়, রিপ্লিকা ব্যবহার করে ব্যবহারকারীর দৃশ্যমান সমস্যা হবে।
- বাজেট কত? রিপ্লিকা ইন্ফ্রা ও অপস খরচ বাড়ায়।
- কত জটিলতা আপনি সামলাতে পারবেন? রিড/রাইট স্প্লিটিং, ইভেন্টুয়াল কনসিস্টেন্সি হ্যান্ডলিং, ও ফেইলওভার টেস্টিং নন-ট্রিভিয়াল।
নতুন প্রোডাক্ট প্রোটোটাইপিং বা দ্রুত সার্ভিস চালু করার সময় এগুলো আর্কিটেকচারে আগে থেকেই বিবেচনা করে রাখা সাহায্য করে। উদাহরণস্বরূপ, Koder.ai-এ নির্মাণকারী দলগুলো প্রায়ই সহজতার জন্য প্রথমে একটি একক প্রাইমারি দিয়ে শুরু করে, তারপর ড্যাশবোর্ড, ফিড, বা অভ্যন্তরীণ রিপোর্টিং ট্রানজ্যাকশনের সাথে প্রতিযোগিতা শুরু করলে রিপ্লিকা যোগ করে। পরিকল্পনা-প্রথম কর্মপ্রবাহ সিদ্ধান্ত নেওয়া সহজ করে কোন এন্ডপয়েন্টগুলো ইভেন্টুয়াল কনসিস্টেন্সি সহ্য করবে এবং কোনগুলো অবশ্যই প্রাইমারি থেকে “রিড-ইওর-রাইটস” আকারে পড়তে হবে।
যদি পথ বেছে নিতে সাহায্য চান, দেখুন /pricing অপশনগুলো, অথবা /blog-এ সম্পর্কিত গাইডগুলো ব্রাউজ করুন।