০৫ অক্টো, ২০২৫·8 মিনিট
রিয়েল-টাইম ওয়েব অ্যাপ তৈরি করে SLA লঙ্ঘন মনিটর ও প্রতিরোধ করুন
SLA টাইমার ট্র্যাক করা, ব্রিচ তৎক্ষণাৎ শনাক্ত করা, টিমকে সতর্ক করা এবং রিয়েল-টাইমে কমপ্লায়েন্স ভিজ্যুয়ালাইজ করার জন্য একটি ব্যবহারিক ব্লুপ্রিন্ট শিখুন।
SLA টাইমার ট্র্যাক করা, ব্রিচ তৎক্ষণাৎ শনাক্ত করা, টিমকে সতর্ক করা এবং রিয়েল-টাইমে কমপ্লায়েন্স ভিজ্যুয়ালাইজ করার জন্য একটি ব্যবহারিক ব্লুপ্রিন্ট শিখুন।
স্ক্রিন ডিজাইন বা ডিটেকশন লজিক লেখার আগে, পরিষ্কারভাবে ঠিক করুন আপনার অ্যাপটি কী প্রতিরোধ করতে চাইছে। “SLA মনিটরিং” বলতে দৈনিক রিপোর্ট থেকে প্রতি সেকেন্ডের ব্রিচ প্রেডিকশন—সবই বুঝানো যেতে পারে—এগুলো সম্পূর্ণ আলাদা প্রোডাক্ট এবং আলাদা আর্কিটেকচারের প্রয়োজন।
শুরুতেই সম্মত হন সেই রিয়েকশন উইন্ডোতে যা আপনার টিম বাস্তবে পারবেন।
যদি আপনার সাপোর্ট সংস্থা 5–10 মিনিট চক্রে কাজ করে (ট্রায়াজ কিউ, পেজিং রোটেশন), তাহলে “রিয়েল-টাইম” মানে হতে পারে প্রতি মিনিটে ড্যাশবোর্ড আপডেট এবং 2 মিনিটের মধ্যে অ্যালার্ট। যদি উচ্চ-সেভারিটি ইনসিডেন্ট যেখানে মিনিটগুলোই গুরুত্বপূর্ণ সেখানে কাজ করেন, আপনি 10–30 সেকেন্ডের ডিটেকশন-এবং-অ্যালার্ট লুপ চাইতে পারেন।
এটাকে একটি পরিমাপযোগ্য লক্ষ্য হিসেবে লিখে রাখুন, যেমন: “সম্ভাব্য ব্রিচ 60 সেকেন্ডের মধ্যে সনাক্ত এবং অন-কলকে 2 মিনিটের মধ্যে জানানো।” পরে আর্কিটেকচারের এবং খরচের ট্রেডঅফ নির্ধারণে এটি একটি গার্ডরেইল হবে।
আপনি যে প্রতিশ্রুতিগুলো ট্র্যাক করবেন সেগুলো তালিকাভুক্ত করুন এবং প্রতিটিকে সরল ভাষায় সংজ্ঞায়িত করুন:
এছাড়া লক্ষ্য করুন এগুলো কিভাবে আপনার সংস্থার SLO এবং SLA সংজ্ঞার সাথে সম্পর্কিত। যদি অভ্যন্তরীণ SLO গ্রাহক-সম্মুখীন SLA থেকে আলাদা হয়, তাহলে আপনার অ্যাপকে হয়ত উভয় ট্র্যাক করতে হবে: অপারেশনাল উন্নতির জন্য একটী, চুক্তিগত ঝুঁকির জন্য আরেকটি।
সিস্টেমটি যারা ব্যবহার করবে বা এর উপর নির্ভর করবে তাদের দলগুলো নাম করুন: সাপোর্ট, ইঞ্জিনিয়ারিং, কাস্টমার সাকসেস, টিম লিড/ম্যানেজার, এবং ইনসিডেন্ট রেসপন্স/অন-কল।
প্রতিটি দলের জন্য ধরুন তারা কোন বিষয়ে মুহূর্তের মধ্যে সিদ্ধান্ত নেওবে: “এই টিকেট কি ঝুঁকিতে?”, “এর মালিক কে?”, “এস্কালেশন দরকার কি?”—এসাগুলো আপনার ড্যাশবোর্ড, অ্যালার্ট রাউটিং এবং পারমিশনের ডিজাইন নির্ধারণ করবে।
আপনার লক্ষ্য শুধু ভিজিবিলিটি নয়—এটি সময়োপযোগী অ্যাকশন। সিদ্ধান্ত নিন ঝুঁকি বাড়লে বা ব্রিচ ঘটলে কী হওয়া উচিত:
একটি ভাল আউটকাম স্টেটমেন্ট: “আমাদের সমঝোতা করা রিয়েকশন উইন্ডোর মধ্যে ব্রিচ ডিটেকশন ও ইনসিডেন্ট রেসপন্স সক্রিয় করে SLA লঙ্ঘন কমানো।”
ডিটেকশন লজিক বানানোর আগে, ঠিক লিখে রাখুন কী ‘ভাল’ আর কী ‘খারাপ’ আপনার সার্ভিসের জন্য। বেশিরভাগ SLA মনিটরিং সমস্যাই প্রযুক্তিগত নয়—এগুলো সংজ্ঞার সমস্যা।
একটি SLA (Service Level Agreement) গ্রাহকদের দেওয়া একটি প্রতিশ্রুতি, সাধারণত ফলাফল/শাস্তি থাকে। একটি SLO (Service Level Objective) অভ্যন্তরীণ লক্ষ্য যেটি SLA-এর উপরে নিরাপদ থাকতে সাহায্য করে। একটি KPI (Key Performance Indicator) হলো যে কোনো মেট্রিক আপনি ট্র্যাক করেন (সাহায্যকারী, তবে সবসময় একটি প্রতিশ্রুতির সাথে বাঁধা নয়)।
উদাহরণ: SLA = “1 ঘন্টার মধ্যে রেসপন্ড করুন।” SLO = “30 মিনিটের মধ্যে রেসপন্ড করুন।” KPI = “গড় প্রথম রেসপন্স সময়।”
প্রতিটি ব্রিচ টাইপ তালিকাভুক্ত করুন এবং টাইমার শুরু করে এমন ইভেন্ট নির্ধারণ করুন।
সাধারণ ব্রিচ ক্যাটাগরি:
পরিষ্কার করে লিখুন “রেসপন্স” বলতে পাবলিক রিপ্লাই নাকি ইনটের্নাল নোট বোঝায় এবং “রেজলিউশন” বলতে রিজল্ভড না কী ক্লোজড, এবং রিইওপেনিং কি টাইমার রিসেট করে নাকি না।
অনেক SLA কেবল ব্যবসায়িক ঘণ্টায় সময় গণনা করে। ক্যালেন্ডার নির্ধারণ করুন: কাজের দিন, ছুটি, শুরু/শেষ সময়, এবং গণনার জন্য কোন টাইমজোন ব্যবহার হবে (কাস্টমারের, কনট্র্যাক্টের, না টিমের)। এছাড়া সিদ্ধান্ত নিন যখন কাজ সীমানা ক্রস করে তখন কী হবে (যেমন 16:55-এ টিকেট আসে এবং 30-মিনিট রেসপন্স SLA রয়েছে)।
কখন SLA ঘড়ি থামবে তা ডকুমেন্ট করুন, যেমন:
এসব নিয়ম এমনভাবে লেখুন যাতে আপনার অ্যাপ কনসিসটেন্টলি প্রয়োগ করতে পারে, এবং জটিল কেসগুলোর উদাহরণ পরীক্ষার জন্য রাখুন।
আপনার SLA মনিটর আপনার খাওয়ার ডেটার উপর নির্ভর করে। প্রতিটি SLA ঘড়ির “সিস্টেম অফ রেকর্ড” চিহ্নিত করা দিয়ে শুরু করুন। অনেক টিমের জন্য টিকেটিং টুল লাইফসাইকেল টাইমস্ট্যাম্পের সোর্স অফ ট্রুথ; মনিটরিং ও লগ টুলগুলো ঘটনার কারণ ব্যাখ্যা করে।
বেশিরভাগ রিয়েল-টাইম SLA সেটআপ কয়েকটি কোর সিস্টেম থেকে টানে:
যদি দুই সিস্টেম অমতে থাকে, প্রতিটি ফিল্ডের জন্য আগে থেকেই সিদ্ধান্ত নিন কোনটি জয়ী (উদাহরণ: “টিকেট স্ট্যাটাস ServiceNow থেকে, কাস্টমার টিয়ার CRM থেকে”)।
কমপক্ষে সেই ইভেন্টগুলো ট্র্যাক করুন যা SLA টাইমার শুরু, থাম বা বদলায়:
আরও বিবেচনা করুন অপারেশনাল ইভেন্টগুলো: বিজনেস আওয়ার ক্যালেন্ডার পরিবর্তন, কাস্টমার টাইমজোন আপডেট, এবং হলিডে শিডিউল পরিবর্তন।
নিয়মিতভাবে webhooks পছন্দ করুন নিকটে-রিয়েল-টাইম আপডেটের জন্য। যেখানে webhooks নেই বা নির্ভরযোগ্য নয় সেখানে polling ব্যবহার করুন। রিকনসিলিয়েশনের জন্য API এক্সপোর্ট/ব্যাকফিল রাখুন (উদাহরণ: রাতে চলে এমন জব যা গ্যাপ পূরণ করে)। অনেক টিম হাইব্রিড ব্যবহার করে: দ্রুততার জন্য webhook, নিরাপত্তার জন্য সময়-বিলম্বিত polling।
বাস্তব সিস্টেমগুলো বিশৃঙ্খল। আশা রাখুন:
এসবকে এজ-কেস নয় বলে দেখবেন না—আপনার ব্রিচ ডিটেকশনের উপর এগুলো নির্ভর করে।
একটা ভাল SLA মনিটরিং অ্যাপ স্পষ্ট ও ইন্টারেশনালি সহজ হলে তৈরির ও মেইনটেন করা সহজ হয়। সারমর্মে, আপনি একটি পাইপলাইন বানাচ্ছেন যা কাঁচা অপারেশনাল সংকেতকে “SLA স্টেট”-এ রূপান্তর করে, তারপর সেই স্টেট ব্যবহার করে মানুষকে সতর্ক করে এবং ড্যাশবোর্ড চালায়।
পাঁচটি ব্লকে চিন্তা করুন:
এই বিভাজন দায়িত্ব পরিষ্কার রাখে: ইনজেস্টে SLA লজিক থাকা উচিত নয়, এবং ড্যাশবোর্ড ভারি ক্যালকুলেশন চালালে ভালো হয় না।
শুরুতেই সিদ্ধান্ত নিন আপনি প্রকৃতপক্ষে কতটা “রিয়েল-টাইম” চান।
ব্যবহারিক পদ্ধতি: প্রথমে এক-দুই SLA রুলের জন্য ঘন রিক্যালকুলেশন দিয়ে শুরু করুন, তারপর উচ্চ-ইমপ্যাক্ট রুলগুলো স্ট্রিমিংয়ে নিয়ে যান।
শুরুতে মাল্টি-রিজিয়ন ও মাল্টি-এনভায়রনমেন্ট জটিলতা এড়িয়ে চলুন। একটি একক রিজিয়ন, এক প্রোডাকশন এনভায়রনমেন্ট, এবং মিনিমাল স্টেজিং সাধারণত যথেষ্ট যতক্ষণ না আপনি ডেটা কোয়ালিটি ও অ্যালার্ট ইউজফুলনেস যাচাই করে ফেলেন। “বড় হতে পরে” এমন নকশা করুন, কিন্তু প্রথমে না।
দ্রুত প্রথম কার্যকর ভার্সন তৈরি করতে যদি চান, কিচ্ছু প্ল্যাটফর্ম যেমন Koder.ai আপনাকে React-ভিত্তিক UI এবং Go + PostgreSQL ব্যাকএন্ড দ্রুত scaffold করতে সাহায্য করতে পারে—তারপর আপনি স্ক্রিন ও ফিল্টার ইটারেট করুন।
বাস্তবে যাওয়ার আগেই এগুলো লিখে রাখুন:
ইভেন্ট ইনজেশনই সেই জায়গা যেখানে আপনার SLA মনিটর নির্ভরযোগ্য হবে অথবা রূক্ষ ও বিভ্রান্তিকর হবে। লক্ষ্য: বহু টুল থেকে ইভেন্ট গ্রহণ করে একটি একক “ট্রুথি” ফরম্যাটে কনভার্ট করা এবং পর্যাপ্ত কনটেক্সট রাখা যাতে প্রতিটি SLA সিদ্ধান্ত পরে ব্যাখ্যা করা যায়।
প্রারম্ভে স্ট্যান্ডার্ড করুন একটি “SLA-রিলেভেন্ট ইভেন্ট” কেমন দেখাবে, যদিও আপস্ট্রিম সিস্টেমগুলো ভিন্ন হতে পারে। একটি ব্যবহারিক বেসলাইন স্কিমায় থাকতে পারে:
ticket_id (বা কেস/ওয়ার্ক আইটেম আইডি)timestamp (কখন পরিবর্তনটা ঘটেছে, না কখন আপনি পেয়েছেন)status (opened, assigned, waiting_on_customer, resolved ইত্যাদি)priority (P1–P4 বা সমতুল্য)customer (অ্যাকাউন্ট/টেন্যান্ট আইডি)sla_plan (কোন SLA রুল প্রযোজ্য)স্কিমা ভার্সনিং (উদাহরণ: schema_version) রাখুন যাতে ফিল্ড বাড়লে পুরনো প্রডিউসার ভেঙ্গে না যায়।
বিভিন্ন সিস্টেম একই জিনিস ভিন্নভাবে নামায়: “Solved” বনাম “Resolved”, “Urgent” বনাম “P1”, টাইমজোন পার্থক্য, বা মিসিং প্রায়োরিটি। ছোট একটি নর্মালাইজেশন লেয়ার বানান যা:
is_customer_wait বা is_pause) যাতে পরে ব্রিচ লজিক সহজ হয়ইনটিগ্রেশনগুলো রিট্রাই করে। আপনার ইনজেশন ইডেম্পটেন্ট হতে হবে যাতে রিপিটেড ইভেন্ট ডুপ্লিকেট না তৈরি করে। সাধারণ পদ্ধতি:
event_id চাইুন এবং ডুপ্লিকেট প্রত্যাখ্যান করুনticket_id + timestamp + status) এবং আপসার্ট করুনযখন কেউ জিজ্ঞেস করে “কেন আমরা অ্যালার্ট করেছি?”—আপনাকে একটি কাগজ-ট্রেইল দেখাতে হবে। প্রতিটি গ্রহণ করা রো ইভেন্ট এবং প্রতিটি নর্মালাইজড ইভেন্ট সংরক্ষণ করুন, সঙ্গে যে/কি তা পরিবর্তন করেছে তার তথ্য। এই অডিট ইতিহাস কাস্টমার কথোপকথন ও অভ্যন্তরীণ রিভিউয়ের জন্য অপরিহার্য।
কিছু ইভেন্ট পারসিং বা ভ্যালিডেশন ফেইল করবে। সেগুলো চুপচাপ ড্রপ করবেন না। একটি ডেড-লেটার কিউ/টেবিলে পাঠান যার সঙ্গে এরর রিজন, মূল পেইলোড এবং রিট্রাই কাউন্ট থাকবে, যাতে ম্যাপিং ঠিক করে রেপ্লে করা যায়।
আপনার SLA অ্যাপে দুই ধরনের মেমোরি লাগে: এখন কী সত্য (অ্যালার্ট ট্রিগারের জন্য) এবং স্মৃতি হিসেবে কী ঘটেছে (বর্ণনা ও প্রমাণ করার জন্য)।
বর্তমান স্টেট হলো প্রতিটি ওয়ার্ক আইটেমের সর্বশেষ জানাজানো স্ট্যাটাস এবং তার সক্রিয় SLA টাইমার (স্টার্ট সময়, পজড সময়, ডিউ সময়, অবশিষ্ট মিনিট, বর্তমান মালিক)।
ID দ্বারা দ্রুত রিড/রাইট এবং সহজ ফিল্টারিং-এ অপ্টিমাইজ করা স্টোর বেছে নিন। সাধারণ অপশন: রিলেশনাল DB (Postgres/MySQL) বা কী-ভ্যালু স্টোর (Redis/DynamoDB)। অনেক টিমের জন্য Postgres যথেষ্ট এবং রিপোর্টিংও সহজ রাখে।
স্টেট মডেলকে ছোট ও কুয়েরি-বন্ধুভাবেই রাখুন। আপনি এটা বারবার পড়বেন যেমন “সিগন্যালিং ব্রিচিং সুন” ভিউতে।
ইতিবাচক ইতিহাসে প্রতিটি পরিবর্তনকে অপরিবর্তনীয় রেকর্ড হিসেবে ধরে রাখুন: created, assigned, priority changed, status updated, customer replied, on-hold started/ended ইত্যাদি।
একটি অ্যাপেন্ড-ওনলি ইভেন্ট টেবিল (বা ইভেন্ট স্টোর) অডিট ও রেপ্লের জন্য উপযুক্ত করে তোলে। পরবর্তীতে যদি ব্রিচ লজিকে বাগ পাওয়া যায়, ইভেন্টগুলো পুনরায় প্রসেস করে স্টেট রিকনস্ট্রাক্ট করে ফলাফল তুলনা করা যাবে।
বাস্তবিক প্যাটার্ন: প্রথমে একই ডাটাবেজে state table + events table রাখা; ভলিউম বাড়লে আলাদা অ্যানালিটিক্স স্টোরে মাইগ্রেট করুন।
উদ্দেশ্য অনুযায়ী রিটেনশন নির্ধারণ করুন:
পার্টিশন (মাস/কোয়ার্টার) ব্যবহার করুন যাতে আর্কাইভ ও ডিলিট predictable হয়।
আপনার ড্যাশবোর্ড যে প্রশ্নগুলো সবচেয়ে বেশি করবে সেগুলোর জন্য পরিকল্পনা করুন:
due_at ও status-এ ইনডেক্স (এবং সম্ভব হলে queue/team)।breached_at (বা কম্পিউটেড ব্রিচ ফ্ল্যাগ) ও তারিখে ইনডেক্স।(customer_id, due_at) মত কম্পোজিট ইনডেক্স।পারফরম্যান্স জিতবেন আপনার টপ 3–5 ভিউ-কে ঘিরে স্টোরেজ গঠন করে, সব রিপোর্ট নয়।
রিয়েল-টাইম ব্রিচ ডিটেকশন মূলত একটি জিনিস: মানুষের অনিয়মিত ওয়ার্কফ্লো (assigned, waiting on customer, reopened, transferred) কে পরিষ্কার SLA টাইমারে রূপান্তর করা যাতে আপনি ভরসাযোগ্যভাবে কাজ করতে পারেন।
প্রতিটি টিকেট বা অনুরোধ টাইপের জন্য কোন ইভেন্টগুলো SLA ক্লক নিয়ন্ত্রণ করে তা সংজ্ঞায়িত করে শুরু করুন। সাধারণ প্যাটার্ন:
এই ইভেন্টগুলো থেকে একটি due time ক্যালকুলেট করুন। কঠোর SLA-এর জন্য এটি হতে পারে “created_at + 2 hours।” ব্যবসায়িক-ঘণ্টার SLA-র জন্য এটি হবে “2 ব্যবসায়িক ঘন্টা,” যা একটি ক্যালেন্ডার দরকার।
একটি ছোট ক্যালেন্ডার মডিউল বানান যা ধারাবাহিকভাবে দুইটি প্রশ্নের উত্তর দেয়:
ছুটিসমূহ, কার্যঘণ্টা ও টাইমজোন এক জায়গায় রাখুন যাতে প্রতিটি SLA রুল একই লজিক ব্যবহার করে।
একবার আপনার কাছে একটি due time থাকলে, time remaining হিসাব করা সহজ: due_time - now (যদি প্রযোজ্য হয় তাহলে বিজনেস মিনিটে)। তারপর ব্রিচ রিস্ক থ্রেশহোল্ড নির্ধারণ করুন যেমন “15 মিনিটের মধ্যে ডিউ” বা “SLA-র মাত্র 10% বাকি”—এইগুলিই জরুরিত্ব ব্যাজ ও অ্যালার্ট রাউটিং চালাবে।
আপনি করতে পারেন:
প্রায়োগিক হাইব্রিড: নির্ভুলতার জন্য ইভেন্ট-ড্রিভেন আপডেট এবং মিনিট-লেভেল টিক যাতে কোনও নতুন ইভেন্ট না এলে হলেও টাইম-ভিত্তিক থ্রেশহোল্ড ক্রস ধরা পড়ে।
অ্যালার্টই হলো যেখানে আপনার SLA মনিটরিং অপারেশনাল হয়। লক্ষ্য হচ্ছে “আরও নোটিফিকেশন” নয়—সঠিক মানুষকে সঠিক অ্যাকশন নিতে পারানো, ডেডলাইন মিস হওয়ার আগে।
কয়েকটি ছোট অ্যালার্ট টাইপ ব্যবহার করুন স্পষ্ট অপচেন্ট্স সহ:
প্রতিটি টাইপকে আলাদা জরুরিত্ব ও ডেলিভারি চ্যানেলে ম্যাপ করুন (চ্যাট ওয়ার্নিং জন্য, পেজিং ব্রিচ কনফার্মড এর জন্য ইত্যাদি)।
রাউটিং ডেটা-চালিত হওয়া উচিত, হার্ড-কোড নয়। একটি সিম্পল রুলস টেবিল রাখুন যেমন: service → owning team, তারপর মডিফায়ার প্রয়োগ করুন:
এটি “সবকে ব্রডকাস্ট” করা এড়ায় এবং মালিকানা দৃশ্যমান করে।
ইনসিডেন্ট রেসপন্স চলাকালে SLA স্ট্যাটাস দ্রুত ফ্লিপ করতে পারে। একটি স্থির কী দিয়ে ডেডুপ্লিকেট করুন যেমন (ticket_id, sla_rule_id, alert_type) এবং প্রয়োগ করুন:
একাধিক ওয়ার্নিংকে একক পিরিয়ডিক সারাংশে বান্ডেল করাও বিবেচনা করুন।
প্রতিটি নোটিফিকেশনকে “কি, কখন, কে, এখন কী” উত্তর দিতে হবে:
যদি কেউ 30 সেকেন্ডের মধ্যে কার্য করতে না পারে, অ্যালার্টে আরও ভাল কনটেক্সট দিতে হবে।
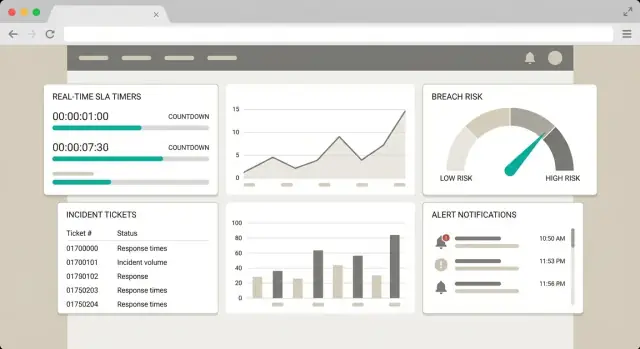
একটি ভাল SLA ড্যাশবোর্ড চার্টের চেয়ে কম এবং কাউকে এক মিনিটের মধ্যে সিদ্ধান্ত নিতে সাহায্য করা বেশি। UI তিনটি প্রশ্নের চারপাশে ডিজাইন করুন: কি ঝুঁকিতে আছে? কেন? আমি কী করব?
চারটি সহজ ভিউ দিয়ে শুরু করুন, প্রতিটির একটি পরিষ্কার উদ্দেশ্য থাকবে:
ডিফল্ট ভিউ “breaching soon” এ ফোকাস রাখুন, কারণ সেখানেই প্রতিরোধ ঘটে।
ব্যবহারকারীদের এমন এক সেট ফিল্টার দিন যা বাস্তব মালিকানা ও ট্রায়াজ সিদ্ধান্তের সঙ্গে মানানসই:
ফিল্টারগুলো প্রতি ব্যবহারকারীর জন্য sticky রাখুন যাতে প্রতিদর্শনে বারবার কনফিগার না করতে হয়।
“Breaching soon” ভিউতে প্রতিটি সারিতে সংক্ষিপ্ত, সাধারণ ভাষায় ব্যাখ্যা থাকতে হবে, উদাহরণ:
একটি “Details” drawer যোগ করুন যা SLA স্টেট পরিবর্তনের টাইমলাইন দেখায় (start, pause, resume, breached), যাতে ব্যবহারকারী ক্যালকুলেশন বিশ্বাস করতে পারে বাইনারি গণনা না করে।
ডিফল্ট ওয়ার্কফ্লো ডিজাইন করুন: review → open → act → confirm।
প্রতিটি আইটেমে এমন অ্যাকশন বাটন থাকা উচিত যা সোর্স অভ ট্রুথে ঝাঁপিয়ে যাবে:
যদি দ্রুত অ্যাকশন (assign, change priority, add note) সমর্থন করেন, সেগুলো এমন জায়গায় দেখান যেখানে কনসিস্টেন্টলি প্রয়োগ করা যায় এবং পরিবর্তনগুলো অডিট করা যায়।
রিয়েল-টাইম SLA মনিটরিং অ্যাপ দ্রুত পারফরম্যান্স, ইনসিডেন্ট ও কাস্টমার ইমপ্যাক্টের রেকর্ড হয়ে যায়। প্রোডাকশন-গ্রেড সফটওয়্যারের মতো আচরণ করুন: কে কী করতে পারবে সীমাবদ্ধ করুন, কাস্টমার ডেটা সুরক্ষিত করুন, এবং ডেটা কীভাবে সংরক্ষণ ও মুছে ফেলা হবে তা ডকুমেন্ট রাখুন।
শুরুতে ছোট, স্পষ্ট পারমিশন মডেল রাখুন এবং প্রয়োজনে বাড়ান। সাধারণ সেটআপ:
পারমিশনগুলো ওয়ার্কফ্লো অনুযায়ী রেখে দিন; উদাহরণ: অপারেটর ইনসিডেন্ট স্ট্যাটাস আপডেট করতে পারে, কিন্তু শুধুমাত্র অ্যাডমিন SLA টাইমার বা এস্কালেশন রুল পরিবর্তন করতে পারবে।
SLA মনিটরিং প্রায়ই কাস্টমার আইডেন্টিফায়ার, কনট্র্যাক্ট টিয়ার, ও টিকেট বিষয়বস্তু রাখে। এক্সপোজার কমান:
ইন্টিগ্রেশনগুলো প্রায়শই দুর্বল স্থান:
আপনি মাসের পর মাস ইতিহাস জমা করার আগে নীতি নির্ধারণ করুন:
এই নিয়মগুলো লেখা রাখুন এবং UI তে প্রতিফলিত করুন যাতে টিম জানে সিস্টেম কি রাখে—এবং কতদিন।
SLA মনিটরিং অ্যাপ টেস্ট করা কেবল “UI লোড করে কি না” নয়, বরং “টাইমার, পজ, ও থ্রেশহোল্ড ঠিকভাবে আপনার কনট্র্যাক্ট চায় সেইভাবে প্রতিবারই গণনা করছে কি না”—এটা জরুরি। একটি ছোট ভুল (টাইমজোন, বিজনেস আওয়ার, মিসিং ইভেন্ট) গোলমাল অ্যালার্ট বা মিসড ব্রিচ সৃষ্টি করতে পারে।
আপনার SLA রুলগুলোকে কনক্রিট সিনারিওতে রূপান্তর করুন এবং এন্ড-টু-এন্ড সিমুলেট করুন। সাধারণ ও এজ-কেস দুইটাই রাখুন:
প্রুফ করুন আপনার ব্রিচ ডিটেকশন লজিক বাস্তব অপারেশনাল বিশৃঙ্খলার মধ্যে স্থিতিশীল।
রেপ্লেয়েবল ইভেন্ট ফিক্সচারের একটি ছোট লাইব্রেরি তৈরি করুন: “ইনসিডেন্ট টাইমলাইন”গুলো যা ইনজেশন ও ক্যালকুলেশনে প্রতিবার চালানো যায় যখন আপনি লজিক বদলান। এটি পরিবর্তন পরে রিগ্রেশন প্রতিরোধ করে।
ফিক্সচারগুলো Git-এ ভার্সন করুন এবং প্রত্যাশিত আউটপুট রাখুন: গণিতকৃত অবশিষ্ট সময়, ব্রিচ মুহূর্ত, পজ উইন্ডো, এবং অ্যালার্ট ট্রিগার।
SLA মনিটরকে নিজেই প্রোডuction সিস্টেম হিসেবে বিবেচনা করুন এবং এর স্বাস্থ্য সংকেত যোগ করুন:
যদি আপনার ড্যাশবোর্ড সবুজ দেখালো কিন্তু ইভেন্ট আটকে আছে, আস্থা দ্রুত হারিয়ে যাবে।
কমন ফেইলিওর মোডের জন্য সংক্ষিপ্ত, পরিষ্কার রনবুক লিখুন: স্থগিত কনজিউমার, স্কিমা চেঞ্জ, আপস্ট্রিম আউটেজ, ব্যাকফিল। ইভেন্ট নিরাপদে রেপ্লে ও টাইমার পুনর্গণনার ধাপগুলো অন্তর্ভুক্ত করুন (কোন পিরিয়ড, কোন টেন্যান্ট, কিভাবে ডাবল-অ্যালার্ট এড়াবেন)। এটাকে আপনার অভ্যন্তরীণ ডক্স হাব বা একটি সরল পেজে লিঙ্ক করুন যেমন /runbooks/sla-monitoring।
SLA মনিটরিং অ্যাপকে প্রোডাক্ট হিসেবে ট্রিট করুন, এক-টাইম প্রকল্প হিসেবে নয়। একটি MVP দিয়ে শুরু করুন যা এন্ড-টু-এন্ড লুপ প্রমাণ করবে: ingest → evaluate → alert → act করে কেউ উপকার পেয়েছে কি না নিশ্চিত করা।
একটি ডেটা সোর্স, একটি SLA টাইপ, এবং বেসিক অ্যালার্ট বেছে নিন। উদাহরণ: “প্রথম রেসপন্স টাইম” মনিটর করুন একটি একক টিকেটিং সিস্টেম ফিড ব্যবহার করে, এবং যখন ক্লক প্রায় মেয়াদ পেরোয় তখন অ্যালার্ট পাঠান (শুধু ব্রিচ হলে নয়)। এভাবে স্কোপ টাইট থাকে এবং টিম_timestamp, টাইম উইন্ডো, ও মালিকানা যাচাই করতে পারবেন।
MVP স্থিতিশীল হলে ছোট ধাপে বাড়ান: দ্বিতীয় SLA টাইপ যোগ করুন (উদাহরণ: রেজলিউশন), তারপর দ্বিতীয় ডেটা সোর্স, তারপর সমৃদ্ধ ওয়ার্কফ্লো।
শুরুতেই dev, staging, production সেটআপ করুন। স্টেজিং কনফিগারেশনগুলো প্রোডাকশন কনফিগারেশন মিরর করা উচিত (ইন্টিগ্রেশন, শিডিউল, এস্কালেশন) কিন্তু বাস্তব রেসপন্ডারদের নোটিফাই না করে।
ফিচার ফ্ল্যাগ ব্যবহার করুন রোলআউটের জন্য:
যদি আপনি দ্রুত Koder.ai-এর মতো প্ল্যাটফর্ম দিয়ে তৈরি করেন, স্ন্যাপশট ও রোলব্যাক এখানে উপকারী: পাইলটে UI ও রুল শিপ করে দ্রুত সমস্যা এলে revert করতে পারবেন।
সংক্ষিপ্ত, ব্যবহারিক সেটআপ ডকস লিখুন: “ডেটা সোর্স কানেক্ট করুন”, “SLA তৈরি করুন”, “একটি অ্যালার্ট টেস্ট করুন”, “নোটিফাই হলে কী করবেন।” এগুলো প্রোডাক্টের কাছে রাখুন, যেমন /docs/sla-monitoring।
প্রাথমিক গ্রহণের পরে এমন উন্নয়ন অগ্রাধিকার দিন যা আস্থা বাড়ায় ও শব্দ কমায়:
ইটারেট করুন বাস্তব ইনসিডেন্টের ওপর ভিত্তি করে: প্রতিটি অ্যালার্ট আপনাকে শেখাবে কী স্বয়ংক্রিয় করা যায়, কী পরিষ্কার করা উচিত, বা কী সরিয়ে ফেলা উচিত।
একটি SLA মনিটরিং লক্ষ্য একটি পরিমাপযোগ্য বিবৃতি যা নির্ধারণ করে:
এটিকে এমন একটি উদ্দেশ্য হিসেবে লিখুন যেটি পরীক্ষা করা যায়: “X সেকেন্ডের মধ্যে সম্ভাব্য ব্রিচ সনাক্ত করুন এবং Y মিনিটের মধ্যে অন-কলকে নোটিফাই করুন.”
“রিয়েল-টাইম” কী হওয়া উচিত তা আপনার টিমের প্রতিক্রিয়া ক্ষমতার ওপর ভিত্তি করে নির্ধারণ করুন, যা প্রযুক্তিগতভাবে সম্ভব তার ওপর নয়।
কী গুরুত্বপূর্ণ: একটি (ইভেন্ট → ক্যালকুলেশন → অ্যালার্ট/ড্যাশবোর্ড) নির্ধারণ করুন এবং তার আশেপাশেই ডিজাইন করুন।
প্রথমে সেই কাস্টমার-ফেসিং প্রতিশ্রুতি গুলো দেখুন যেগুলো আপনি বাস্তবে ব্রিচ করতে পারেন (এবং যেগুলোর জন্য ক্রেডিট দিতে হতে পারে)। সাধারণতঃ:
অনেক টিমই একটি অভ্যন্তরীণ ট্র্যাক করে যা SLA-এর চেয়ে কঠোর। যদি দুটোই থাকে, উভয়ই সংরক্ষণ ও প্রদর্শন করুন যাতে অপারেটররা সময়মতো কাজ করতে পারে এবং কনট্র্যাকচুয়াল কমপ্লায়েন্সও সঠিকভাবে রিপোর্ট করা যায়।
SLA ব্যর্থতার মূল কারণ প্রায়ই সংজ্ঞার অস্পষ্টতা। স্পষ্ট করুন:
পরে এইগুলিকে ডিটারমিনিস্টিক রুল হিসেবে এনকোড করুন এবং পরীক্ষার জন্য টাইমলাইন উদাহরণগুলোর একটি লাইব্রেরি রাখুন।
একটি সঙ্গতিপূর্ণ ক্যালেন্ডার রুল সেট নির্ধারণ করুন:
একটি পুনঃব্যবহারযোগ্য ক্যালেন্ডার মডিউল বাস্তবায়ন করুন যা উত্তর দিতে পারবে:
প্রতিটি ফিল্ডের জন্য একটি “সিস্টেম অফ রেকর্ড” বাছাই করে dokument করুন কোনটা কোন ক্ষেত্রে জয়ী হবে যখন সিস্টেমগুলো মতবিরোধ করবে।
সাধারণ সোর্সগুলো:
নিয়মিতভাবে পছন্দ করুন দ্রুততার জন্য; মিস হওয়া ইভেন্ট পূরণের জন্য যোগ করুন।
সর্বনিম্নে, সেইসব ইভেন্টগুলো সংগ্রহ করুন যেগুলো SLA ঘড়ি শুরু, থাম বা পরিবর্তন করে:
এছাড়াও সেই ইভেন্টগুলো পরিকল্পনা করুন যেগুলো মানুষ প্রায় ভুলে যায়, যেমন বিজনেস ক্যালেন্ডার আপডেট, টাইমজোন পরিবর্তন, এবং ছুটির শিডিউল—এইগুলো কোনও টিকেট অ্যাক্টিভিটি ছাড়াও ডিউ টাইম পরিবর্তন করতে পারে।
একটি সহজ পাঁচ-ব্লক পাইপলাইন ব্যবহার করুন:
প্রয়োজনীয়তা অনুযায়ী উভয় ব্যবহার করুন:
একটি কার্যকর হাইব্রিড: সঠিকতার জন্য ইভেন্ট-ড্রিভেন আপডেট এবং মিনিট-লেভেল টিক যাতে কোনও থ্রেশহোল্ড ক্রসিং ইভেন্ট ছাড়াও ধরা পড়ে।
অ্যালার্টিংকে কেবল নোটিফিকেশন নয় বরং একটি ওয়ার্কফ্লো হিসেবে বিবেচনা করুন:
ইনজেস্টশনে SLA লজিক রাখবেন না এবং ড্যাশবোর্ডে ভারি ক্যালকুলেশন করবেন না। ডেটা কোয়ালিটি ও অ্যালার্ট ইউজফুলনেস যাচাই না হওয়া পর্যন্ত সহজ ডিপ্লয়মেন্টেই শুরু করুন।
(work_item_id, sla_rule_id, alert_type) দিয়েই ডেডুপ করুন এবং স্টেট ট্রানজিশনে বা কুলডাউন উইন্ডোতে (৫–১৫ মিনিট) পাঠান।প্রতিটি অ্যালার্টে: মালিক/অন-কল, ডিউ টাইম ও বাকি সময়, পরবর্তী অ্যাকশন, এবং লিংক (যেমন /tickets/{id}, /sla/tickets/{id}) থাকা উচিত।