কেন রয় ফিল্ডিং-এর REST আজও গুরুত্বপূর্ণ
রয় ফিল্ডিং শুধু একটি API-বাজওয়ার্ডের সাথে জড়িত নাম নয়। তিনি HTTP ও URI স্পেসিফিকেশনের মূল লেখকদের একজন ছিলেন এবং তার পিএইচডি থিসিসে তিনি REST (Representational State Transfer) নামের একটি আর্কিটেকচারাল স্টাইল বর্ণনা করেছেন, যা বোঝায় কেন ওয়েব এত ভালোভাবে কাজ করে।
এই উত্স গুরুত্বপূর্ণ কারণ REST “সুন্দর দেখানোর এন্ডপয়েন্ট” করতে আবিষ্কৃত হয়নি। এটি এমন বাধ্যতাগুলো ব্যাখ্যা করার উপায় ছিল যা একটি বৈশ্বিক, বিশৃঙ্খল নেটওয়ার্ককে স্কেল করতে দেয়: অনেক ক্লায়েন্ট, অনেক সার্ভার, মধ্যস্থকারি, ক্যাশিং, আংশিক ব্যর্থতা, এবং ক্রমাগত পরিবর্তন।
এই পোস্ট থেকে আপনি কী পাবেন
আপনি যদি কখনও wondered হন কেন দুইটি “REST API” একেবারে আলাদা অনুভূত হয়—অথবা কেন একটি ছোট ডিজাইন পছন্দ পরে পেজিনেশন সমস্যা, ক্যাশিং বিভ্রান্তি, বা ব্রেকিং চেঞ্জে পরিণত হয়—এই গাইডটি সেই চমক কমাতে তৈরি।
আপনি প্রতিবেদনের শেষে পাবেন:
- API ডিজাইন বা মূল্যায়ন করার সময় স্পষ্ট সিদ্ধান্ত-নেওয়ার ক্ষমতা
- টিমের সঙ্গে ট্রেড-অফ নিয়ে আলোচনা করার ভাল ভোকাবুলারী
- কোন REST ধারণাগুলো প্রকল্পে সবচেয়ে বেশি কাজে দেয় তার ব্যবহারিক উপলব্ধি
এক পৃষ্ঠায় REST: স্টাইল, স্ট্যান্ডার্ড নয়
REST কোনো চেকলিস্ট, কোনো প্রটোকল, বা কোনো সার্টিফিকেশন নয়। ফিল্ডিং এটাকে একটি আর্কিটেকচারাল স্টাইল হিসেবে বর্ণনা করেছেন: কিছু বাধ্যতা যা একসঙ্গে প্রয়োগ করলে ওয়েবের মতো স্কেল করা যায়—ব্যবহার সহজ, সময়ের সাথে বিবর্তন যোগ্য, এবং মধ্যস্থকারদের (প্রক্সি, ক্যাশ, গেটওয়ে) সঙ্গে সামঞ্জস্যপূর্ণ।
REST যে সমস্যা সমাধান করছিল
প্রারম্ভিক ওয়েবকে বহু প্রতিষ্ঠান, সার্ভার, নেটওয়ার্ক, এবং ক্লায়েন্ট টাইপ জুড়ে কাজ করতে হয়েছিল। এতে কেন্দ্রীয় নিয়ন্ত্রণ ছাড়াই বাড়তে হয়েছিল, আংশিক ব্যর্থতা সহ্য করতে হয়েছিল, এবং নতুন ফিচার যোগ করা হয়েও পুরোনোগুলো ভাঙতে না দেওয়ার ব্যবস্থা থাকতে হয়েছিল। REST সেই সমস্যাগুলো মোকাবিলা করে কারণ এটি বেশ কয়েকটি বিস্তৃত ধারণা (আইডেন্টিফায়ার, রেপ্রেজেন্টেশন, স্ট্যান্ডার্ড অপারেশন) কে অগ্রাধিকার দেয় কাস্টম, সন্নিবিষ্ট কনট্রাক্টের উপরে।
সাধারণ কথায় “আর্কিটেকচারাল বাধ্যতা”
একটি বাধ্যতা হল এমন নিয়ম যা ডিজাইনের স্বাধীনতা সীমাবদ্ধ করে বিনিময়ে সুফল দেয়। উদাহরণস্বরূপ, আপনি সার্ভার-সাইড সেশন স্টেট ত্যাগ করতে পারেন যাতে অনুরোধ কোন সার্ভার নোড দ্বারা হ্যান্ডেল করা হোক সেটা গুরুত্বপূর্ণ না হয়—যা নির্ভরযোগ্যতা ও স্কেলিং উন্নত করে। প্রতিটি REST বাধ্যতা একই রকম ট্রেড অফ করে: কম বিশেষীকৃত নমনীয়তা, বেশি পূর্বানুমেয়তা ও বিবর্তনশীলতা।
REST বনাম “REST-সদৃশ” API
অনেক HTTP API REST ধারণার কিছু অংশ নেয় (HTTP-এ JSON, URL এন্ডপয়েন্ট, সম্ভবত স্ট্যাটাস কোড) কিন্তু পুরো বাধ্যতাগুলো প্রয়োগ করে না। এটা “ভুল” নয়—প্রায়ই এটা প্রোডাক্ট ডেডলাইন বা কেবল অভ্যন্তরীণ ব্যবহারের দরকারের প্রতিফলন। শুধু পার্থক্যটি নামকরণ করা সুবিধাজনক: একটি API হতে পারে রিসোর্স-অরিয়েন্টেড কিন্তু পুরোপুরি REST নাও হতে পারে।
এক-অনুচ্ছেদ মানসিক মডেল
REST সিস্টেমকে ভাবুন যেমন রিসোর্স (URL দিয়ে নামকরণ করা জিনিস) যেগুলোর সঙ্গে ক্লায়েন্ট রেপ্রেজেন্টেশন (JSON বা HTML-এর মত) দিয়ে ইন্টারঅ্যাক্ট করে, এবং লিঙ্ক (পরবর্তী অ্যাকশন ও সম্পর্কিত রিসোর্স) দ্বারা নির্দেশিত। ক্লায়েন্টকে কোনো গোপন বাই-অফ-ব্যান্ড নিয়ম জানার প্রয়োজন পড়ে না; এটি স্ট্যান্ডার্ড সেমান্টিক্স অনুসরণ করে এবং লিঙ্ক ফলো করে—একইভাবে একটি ব্রাউজার ওয়েব ঘুরে বেড়ায়।
রিসোর্স এবং রেপ্রেজেন্টেশন: মূল ভোকাবুলারি
বাধ্যতা ও HTTP বিবরণে হারিয়ে যাওয়ার আগেই, REST একটি সহজ ভোকাবুলারি পরিবর্তন থেকে শুরু হয়: রিসোর্স হিসেবে ভাবুন, অ্যাকশন হিসেবে নয়।
রিসোর্স = একটি নামধারী সবিশেষ (noun)
একটি রিসোর্স আপনার সিস্টেমের একটি ঠিকানাযোগ্য “বস্তু”: একটি ব্যবহারকারী, একটি চালান, একটি পণ্য ক্যাটাগরি, একটি শপিং কার্ট। গুরুত্বপূর্ণ অংশ হলো এটি একটি নামপদ—একটি আইডেন্টিটি।
এজন্যই /users/123 প্রাকৃতিকভাবে পড়ে: এটা ID 123 থাকা ব্যবহারকারীকে শনাক্ত করে। তুলনা করুন action-shaped URL গুলোর সাথে যেমন /getUser বা /updateUserPassword—এসব ক্রিয়া বর্ণনা করে, বস্তু নয়।
REST বলে না আপনি অ্যাকশন করতে পারবেন না। এটা বলে অ্যাকশনগুলো ইউনিফর্ম ইন্টারফেস-এর মাধ্যমে প্রকাশ করা উচিত (HTTP API-র ক্ষেত্রে সাধারণত GET/POST/PUT/PATCH/DELETE ইত্যাদি) যা রিসোর্স আইডেন্টিফায়ারের ওপর কাজ করে।
রেপ্রেজেন্টেশন = রিসোর্সের একটি ভিউ
একটি রেপ্রেজেন্টেশন হল আপনি ওয়্যার-এ যা পাঠান—কোনো সময়ের পয়েন্টে সেই রিসোর্সের স্ন্যাপশট বা ভিউ। একই রিসোর্সের একাধিক রেপ্রেজেন্টেশন থাকতে পারে।
উদাহরণস্বরূপ, রিসোর্স /users/123 একটি অ্যাপের জন্য JSON হিসেবে, বা একটি браузারের জন্য HTML হিসেবে উপস্থাপিত হতে পারে।
GET /users/123
Accept: application/json
শুধু উদাহরণস্বরূপ এটি হতে পারে:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
আর:
GET /users/123
Accept: text/html
হবে এমন একটি HTML পেজ যা একই ব্যবহারকারীর বিবরণ রেন্ডার করে।
মূল ধারণা: রিসোর্সই JSON নয় এবং HTML ও নয়—এসব শুধুই রেপ্রেজেন্টেশন।
কেন এই ফ্রেমিং API ডিজাইন বদলে দেয়
রিসোর্স ও রেপ্রেজেন্টেশনকে কেন্দ্র করে API মডেল করলে বেশ কয়েকটি ব্যবহারিক সিদ্ধান্ত সহজ হয়ে যায়:
- নেমিং স্থিতিশীল থাকে।
/users/123 মানেই বৈধ থাকে এমনকি আপনার UI, ওয়ার্কফ্লো, বা ডেটা মডেল বিকশিত হলেও।
- এন্ডপয়েন্টগুলো সরল হয়। প্রতিটি অপারেশনের জন্য নতুন URL বানানোর বদলে রিসোর্স URL পুনরায় ব্যবহার করা হয় এবং মেথড বা রেপ্রেজেন্টেশন ভ্যারিয়েবল করা হয়।
- ক্লায়েন্ট কোড কম কাপলড হয়। ক্লায়েন্টরা “ব্যবহারকারী পেয়ে আনি” বা “ব্যবহারকারীর ফিল্ড আপডেট করি”-তে ফোকাস করে, একাডেমিক অপারেশন ক্যালাটলগ মুখস্থ করার বদলে।
এই রিসোর্স-ফার্স্ট মানসিকতা REST বাধ্যতাগুলোর ভিত্তি। এর সুবাদে না হলে “REST” প্রায়ই “HTTP-এ JSON এবং কিছু সুন্দর URL” হয়ে পড়ে।
বাধ্যতা ১: ক্লায়েন্ট–সার্ভার বিভাজন
ক্লায়েন্ট–সার্ভার বিভাজন REST-এর সেই উপায় যাতে দায়িত্বগুলো পরিষ্কারভাবে ভাগ করা হয়। ক্লায়েন্ট ইউজার অভিজ্ঞতার ওপর ফোকাস করে (ব্যবহারকারী কী দেখে ও কী করে), আর সার্ভার ডেটা, নিয়ম, ও পারসিস্টেন্স নিয়ে কাজ করে (কী সত্য এবং কী অনুমোদিত)। এই বিভাজন থাকলে প্রতিটি দিকই পুনর্লিখন ছাড়াই পরিবর্তন করা যায়।
ক্লায়েন্টে কি থাকে vs সার্ভারে কি থাকে?
দৈনন্দিন ভাষায়, ক্লায়েন্ট হচ্ছে “প্রেজেন্টেশন লেয়ার”: স্ক্রিন, নেভিগেশন, দ্রুত ফিডব্যাকের জন্য ফর্ম ভ্যালিডেশন, এবং অপটিমিস্টিক UI আচরণ (যেমন নতুন কমেন্ট অবিলম্বে দেখানো)। সার্ভার হচ্ছে “ট্রুথের উত্স”: অথেন্টিকেশন, অথরাইজেশন, ব্যবসায়িক নিয়ম, ডাটা স্টোরেজ, অডিটিং, এবং যেকোনো কিছু যা ডিভাইস জুড়ে কনসিস্টেন্ট থাকতে হবে।
প্র্যাগম্যাটিক রুল: যদি কোনো সিদ্ধান্ত সিকিউরিটি, অর্থ, পারমিশন, বা শেয়ারড কনসিস্টেন্সি প্রভাবিত করে, তা সার্ভারে থাকা উচিৎ। যদি কেবল অভিজ্ঞতার কিভাবে অনুভব হয় সেটা প্রভাবিত করে (লেআউট, লোকাল ইনপুট হিন্ট, লোডিং স্টেট), তা ক্লায়েন্টে থাকা ভালো।
কেন এটি আধুনিক অ্যাপ প্যাটার্নে ফিট করে
এই বাধ্যতাটি সরাসরি সাধারণ সেটআপের সঙ্গে মিলে যায়:
- SPA + API: ওয়েব অ্যাপ (React/Vue ইত্যাদি) UI-এ দ্রুত ইটারেট করে, যখন API রিসোর্স সার্ভ করে।
- মোবাইল অ্যাপস: iOS ও Android ক্লায়েন্ট একই সার্ভার নিয়ম ও এন্ডপয়েন্ট শেয়ার করতে পারে।
- থার্ড-পার্টি ইন্টিগ্রেশন: পার্টনাররা আপনার UI ছাড়াই একই সার্ভার ক্ষমতা ব্যবহার করতে পারে।
ক্লায়েন্ট–সার্ভার বিভাজনই “একটি ব্যাকএন্ড, অনেক ফ্রন্টএন্ড” বাস্তবসম্মত করে।
সাধারণ জাল: UI স্টেট সার্ভার সেশনে লিক করা
একটা সাধারণ ভুল হলো UI ওয়ার্কফ্লো স্টেট সার্ভারে সংরক্ষণ করা (উদাহরণ: “চেকআউট-এ ব্যবহারকারী কোন ধাপে আছে”)—এতে ব্যাকএন্ড একটি নির্দিষ্ট স্ক্রিন ফ্লো-এ কাপলড হয়ে পড়ে এবং স্কেলিং কঠিন হয়।
প্রেফার করুন যে প্রয়োজনীয় কনটেক্সট প্রতিটি অনুরোধের সঙ্গে পাঠান বা সঞ্চিত রিসোর্স থেকে উদ্ভূত করুন, যাতে সার্ভার রিসোর্স ও নিয়মে ফোকাস করে—কোনো নির্দিষ্ট UI কীভাবে চলছে সেটা মনে না করে।
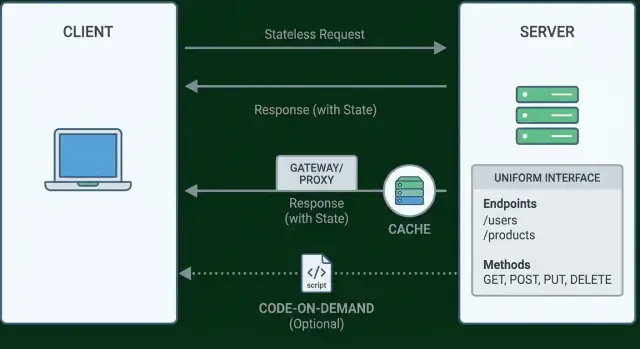
বাধ্যতা ২: স্টেটলেস ইন্টারঅ্যাকশন
স্টেটলেসনেস অর্থ সার্ভারকে ক্লায়েন্ট সম্পর্কে অনুরোধগুলোর মধ্যে কিছু মনে রাখার প্রয়োজন নেই। প্রতিটি অনুরোধে প্রয়োজনীয় সব তথ্য থাকে যাতে তা বুঝে সঠিকভাবে প্রতিক্রিয়া জানানো যায়—কে কল করেছে, তারা কী চায়, এবং প্রসেসিংয়ের জন্য কোনো প্রাসঙ্গিক কনটেক্সট।
কেন এটা গুরুত্বপূর্ণ
যখন অনুরোধগুলো স্বাধীন, তখন লোড-ব্যালান্সারের পেছনে আপনি সার্ভার যোগ বা বিয়োগ করতে পারেন কোন চিন্তা ছাড়াই যে “কোন সার্ভার আমার সেশন জানে।” এটা স্কেলিং ও রেজিলিয়েন্স বাড়ায়: যে কোনো ইনস্ট্যান্স যেকোনো অনুরোধ হ্যান্ডেল করতে পারে।
এটি অপারেশনও সহজ করে: ডিবাগ সহজ হয় কারণ পূর্ণ প্রসঙ্গ অনুরোধে (এবং লগে) দৃশ্যমান থাকে, সার্ভার-সাইড সেশন মেমরিতে লুকানো নয়।
বাস্তবে যে ট্রেড-অফগুলো অনুভব করবেন
স্টেটলেস API সাধারণত প্রতি কলেই কিছু বেশি ডাটা পাঠায়। সার্ভার-সাইড সেশন নির্ভর করার বদলে, ক্লায়েন্ট প্রতিবার প্রমাণীকরণ ও কনটেক্সট অন্তর্ভুক্ত করে।
আপনাকে স্পষ্টভাবে “স্টেটফুল” ইউজার ফ্লো (পেজিনেশন বা বহু-ধাপ চেকআউট) নিয়ে কাজ করতে হবে। REST এটা নিষিদ্ধ করে না—এটি শুধু স্টেট ক্লায়েন্টে বা সার্ভার-সাইড রিসোর্সে সনাক্তযোগ্য রাখতে বলে।
ব্যবহারিক প্যাটার্ন (এবং তারা কী সমাধান করে)
- Auth tokens (উদাহরণ: Bearer JWT): প্রতিটি অনুরোধে
Authorization: Bearer … হেডার যাতে যেকোনো সার্ভার সেটিকে অথেন্টিকেট করতে পারে।
- Idempotency keys: “পেমেন্ট তৈরি”র মতো অপারেশনের জন্য ক্লায়েন্ট
Idempotency-Key পাঠায় যাতে রিট্রাইতে দ্বৈত কাজ না হয়।
- Correlation IDs:
X-Correlation-Id মতো হেডার এক ব্যবহারকারীর কর্মকে সার্ভিস ও লগ জুড়ে ট্রেস করতে দেয়।
পেজিনেশনের জন্য “সার্ভার পেজ ৩ মনে রাখে” এড়িয়ে চলুন। স্পষ্ট প্যারামিটার ব্যবহার করুন যেমন ?cursor=abc বা রেসপন্সে next লিঙ্ক দিন, যাতে নেভিগেশন স্টেট রেসপন্সে রাখা যায় সার্ভার মেমরিতে নয়।
বাধ্যতা ৩: ক্যাশেবল রেসপন্স
ক্যাশিং মানে পূর্বের রেসপন্সকে নিরাপদে পুনঃব্যবহার করা যাতে ক্লায়েন্ট (বা মধ্যস্থকারী) বারবার আপনার সার্ভারের কাছে না যায়। ভালভাবে করা হলে এটি ব্যবহারকারীর জন্য ল্যাটেন্সি কমায় এবং আপনার জন্য লোড কমায়—কিন্তু API-র অর্থ অপরিবর্তিত থাকতেই হবে।
বাস্তবে “ক্যাশেবল” মানে কী
একটি রেসপন্স তখন ক্যাশেবল যখন কোনো সময়ের জন্য অন্য অনুরোধ একই পে-লোড পাওয়া নিরাপদ। HTTP-এ আপনি ক্যাশিং হেডার দিয়ে এই উদ্দেশ্য জানান:
Cache-Control: প্রধান নিয়ন্ত্রক (কতক্ষণ রাখবে, শেয়ার করা যাবে কিনা ইত্যাদি)ETag ও Last-Modified: ভ্যালিডেটর যা ক্লায়েন্টকে “এটা বদলেছে?” জানতে দেয় এবং সস্তায় 304 Not Modified পেতে দেয়Expires: পুরনো পথ, তবুও দেখা যায়
এটা শুধু “ব্রাউজার ক্যাশ” নয়। প্রক্সি, CDN, API গেটওয়ে, এবং এমনকি মোবাইল অ্যাপগুলোও রেসপন্স পুনঃব্যবহার করতে পারে যখন নিয়মগুলো স্পষ্ট।
সাধারণভাবে কী ক্যাশ করা নিরাপদ (এবং কী নয়)
ভাল প্রার্থীরা:
- পাবলিক, সবার জন্য একই ডেটা (পণ্য ক্যাটালগ, ডকুমেন্টেশন)
- আলপকালীন বদল হওয়া রিড-ওয়ানলি রিসোর্স
- GET রেসপন্স যা কুকি বা অথোরাইজেশনের উপর নির্ভর করে না
সাধারণত খারাপ প্রার্থীরা:
- অ্যাকাউন্ট-সংযুক্ত ব্যক্তিগত ডেটা (প্রোফাইল, অর্ডার, মেসেজ)
- অথ-সংক্রান্ত রেসপন্স (টোকেন এক্সচেঞ্জ, সেশন স্টেট)
- এমন কিছু যা ব্যবহারকারীবিশেষে ভ্যারিয়েবল যদি আপনি স্পষ্টভাবে তা হ্যান্ডল না করেন (উদাহরণ:
private ক্যাশিং)
ব্যবহারিক ফলাফল আপনি লক্ষ্য করবেন
- দ্রুত পেজ ও স্মার্টার অ্যাপ (কম নেটওয়ার্ক অপেক্ষা)
- কম সার্ভার ও ডাটাবেস খরচ
- কম “রেট লিমিট” সমস্যা (ক্যাশ করা পড়ে রিড কমে যায়)
মূল ভাবনা: ক্যাশিং কোনো পরে-আহ্বান নয়। এটা একটি REST বাধ্যতা যা স্পষ্টভাবে ফ্রেশনেস ও ভ্যালিডেশন কমিউনিকেট করা API-কে পুরস্কৃত করে।
বাধ্যতা ৪: ইউনিফর্ম ইন্টারফেস (এর প্রকৃত মানে)
ইউনিফর্ম ইন্টারফেস প্রায়ই “GET দিয়ে পড়ুন এবং POST দিয়ে তৈরি করুন” হিসেবে ভুল বোঝা হয়। তা কিছুকালীন অংশ মাত্র। ফিল্ডিং-এর ধারণা বড়: API-গুলো এতটাই কনসিস্টেন্ট হওয়া উচিৎ যে ক্লায়েন্টদের প্রতিটি এন্ডপয়েন্টের জন্য আলাদা বিশেষ জ্ঞান দরকার না হয়।
ইউনিফর্ম ইন্টারফেসের চারটি অংশ
-
রিসোর্সের শনাক্তকরণ: আপনি বস্তু (রিসোর্স) কে স্থায়ী আইডেন্টিফায়ার (সাধারণত URL) দিয়ে নামান, ক্রিয়া নয়। উদাহরণ: /orders/123।
-
রেপ্রেজেন্টেশন দিয়ে ম্যানিপুলেশন: ক্লায়েন্ট একটি রিসোর্স পরিবর্তন করে রেপ্রেজেন্টেশন (JSON, HTML) পাঠিয়ে। সার্ভার রিসোর্স নিয়ন্ত্রণ করে; ক্লায়েন্ট শুধুই তার রেপ্রেজেন্টেশন আদান-প্রদান করে।
-
স্ব-বর্ণনামূলক মেসেজ: প্রতিটি রিকোয়েস্ট/রেসপন্স পর্যাপ্ত তথ্য বহন করা উচিৎ যাতে তা প্রসেস করা যায়—মেথড, স্ট্যাটাস কোড, হেডার, মিডিয়া টাইপ এবং পরিষ্কার বডি। যদি অর্থ বাই-অফ-ব্যান্ড ডকুমেন্টে লুকিয়ে থাকে, ক্লায়েন্ট কাপলড হয়ে যায়।
-
হাইপারমিডিয়া (HATEOAS): রেসপন্সে লিঙ্ক ও অনুমোদিত অ্যাকশন থাকা উচিৎ যাতে ক্লায়েন্ট ওয়ার্কফ্লো অনুসরণ করতে পারে বিনা-হার্ডকোড URL-এ।
কেন এটা কাপলিং কমায়
একটি কনসিস্টেন্ট ইন্টারফেস ক্লায়েন্টকে সার্ভারের অভ্যন্তরীণ বিশদ থেকে কম নির্ভরশীল করে। সময়ের সাথে, সেটি কম ব্রেকিং চেঞ্জ, কম স্পেশাল কেস, এবং কম রিফ্যাক্টরিং নির্দেশ করে।
প্রায়োগিক হিউরিস্টিকস
- স্ট্যাটাস কোড নিয়মিত ব্যবহার করুন: যেমন পড়ার জন্য
200, তৈরি-র জন্য 201 (সঙ্গে Location), ভ্যালিডেশন ইস্যুর জন্য 400, অথ-জনিত 401/403, না পাওয়া হলে 404।
- ত্রুটি ফরম্যাট স্ট্যান্ডার্ড করুন: উদাহরণ ক্ষেত্র:
code, message, details, requestId।
- মিডিয়া টাইপ ও হেডারগুলিকে অর্থপূর্ণ রাখুন (
Content-Type, ক্যাশিং হেডার) যাতে মেসেজ নিজেই ব্যাখ্যা করে।
ইউনিফর্ম ইন্টারফেস হল পূর্বানুমেয়তা ও বিবর্তনশীলতার বিষয়ে—কেবল “সঠিক ক্রিয়া” নয়।
স্ব-বর্ণনামূলক মেসেজ: বোঝার জন্য ডিজাইন
একটি “স্ব-বর্ণনামূলক” মেসেজ তা, যা রিসিভারকে বলে কিভাবে তা ব্যাখ্যা করতে—বাই-অফ-ব্যান্ড টুইক ছাড়াই। যদি একটি ক্লায়েন্ট (বা মধ্যস্থকারী) দেখতে না পারে রেসপন্সের মানে কী HTTP হেডার ও বডি দেখে, আপনি HTTP-এ একটি প্রাইভেট প্রোটোকল বানিয়ে ফেলেছেন।
পে-লোড বোঝাতে মিডিয়া টাইপ ব্যবহার করুন
সহজ জিতে নেওয়া হলো Content-Type স্পষ্টভাবে দেওয়া (আপনি কি পাঠাচ্ছেন) এবং প্রায়ই Accept (আপনি কী চান) ব্যবহার করা। একটি রেসপন্সে Content-Type: application/json থাকলে ক্লায়েন্টকে বেসিক পার্সিং নিয়ম বলে দেওয়া হয়, তবে আপনি ভেন্ডর বা প্রোফাইল ভিত্তিক মিডিয়া টাইপ দিয়ে আরও স্পষ্ট করতে পারেন যখন অর্থ গুরুত্বপূর্ণ।
পন্থাগুলো:
- জেনেরিক মিডিয়া টাইপ + স্থিতিশীল ফিল্ড:
application/json একটি ভাল মূলধারা।
- ভেন্ডর মিডিয়া টাইপ:
application/vnd.acme.invoice+json বিশেষ রেপ্রেজেন্টেশন বোঝাতে।
- প্রোফাইল:
application/json রেখে profile প্যারামিটার বা লিংক দিয়ে সেমান্টিক বিবরণ যুক্ত করা।
ভার্সনিং এবং সামঞ্জস্য (ক্লায়েন্ট ভেঙে না যাওয়ার জন্য)
ভার্সনিং উচিত বিদ্যমান ক্লায়েন্টকে রক্ষা করা। জনপ্রিয় অপশন:
- URL ভার্সনিং (
/v1/orders): স্পষ্ট কিন্তু প্রায়ই রেপ্রেজেন্টেশনগুলি কাটা-বাঁধা করার প্রবণতা বাড়ায়।
- হেডার বা মিডিয়া টাইপ ভার্সনিং (
Accept ব্যবহার করে): URL অখণ্ড রাখে এবং “এটার মানে কি” মেসেজের অংশ করে।
- অ্যাডিটিভ ইভোলিউশন: নতুন ফিল্ড যোগ করা এবং পুরোনোগুলো কাজ করে রাখাই উত্তম; ধাপে ধাপে ডিপ্রিকেট করা।
যাই করুন, ব্যাকওয়ার্ড কম্প্যাটিবিলিটি ডিফল্ট রাখার চেষ্টা করুন: ক্ষেত্রের নাম হঠাৎ বদলাবেন না, অদৃশ্যভাবে মান পালটাবেন না, এবং রিমুভালকে ব্রেকিং চেঞ্জ হিসেবে বিবেচনা করুন।
সঙ্গত ত্রুটি এবং স্পষ্ট নামকরণ
ক্লায়েন্ট দ্রুত শিখে যখন ত্রুটিগুলো সব জায়গায় একইরকম দেখায়। একটি ত্রুটি শেপ বেছে নিন (উদাহরণ: code, message, details, traceId) এবং সব এন্ডপয়েন্টে তা ব্যবহার করুন। স্পষ্ট, পূর্বানুমেয় ফিল্ড নাম ব্যবহার করুন (createdAt বনাম created_at) এবং একটি কনভেনশন মেনে চলুন।
ডকুমেন্টেশন সাহায্য করে—কিন্তু বার্তায় স্পষ্টতা থাকা বাধ্যতামূলক
ভালো ডকস অ্যাডপশন দ্রুত করে, কিন্তু ডকসই যদি একমাত্র জায়গা যেখানে মানে থাকে, তাহলে সমস্যা। যদি ক্লায়েন্টকে জানতে হয় status: 2 মানে “paid” না “pending”, তাহলে বার্তাটি স্ব-বর্ণনামূলক নয়। ভাল ডিজাইন করা হেডার, মিডিয়া টাইপ, এবং পাঠযোগ্য পে-লোড এই নির্ভরতা কমায় এবং সিস্টেমগুলোকে সহজে বিবর্তিত করে।
হাইপারমিডিয়া (HATEOAS): সবচেয়ে ত্যাগ করা REST ধারণা
হাইপারমিডিয়া (HATEOAS) মানে ক্লায়েন্টকে আগে থেকেই API-এর পরবর্তী URL গুলো জানার প্রয়োজন নেই। প্রতিটি রেসপন্স ডিসকভারেবল পরবর্তী ধাপ হিসেবে লিঙ্ক অন্তর্ভুক্ত করে: কোথায় যেতে হবে পরবর্তী, কোন অ্যাকশনগুলো সম্ভব, এবং কখনও কখনও কোন HTTP মেথড ব্যবহার করতে হবে।
এটি প্র্যাকটিক্যালি কেমন দেখায়
হার্ড-কোডিং /orders/{id}/cancel করার বদলে, ক্লায়েন্ট সার্ভার প্রদত্ত লিঙ্ক ফলো করে। সার্ভার বলতে চায়: “এই রিসোর্সের বর্তমান স্টেটে, এগুলোই বৈধ পদক্ষেপ।”
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
যদি পরে অর্ডার paid হয়ে যায়, সার্ভার cancel লিঙ্ক আর না রাখতেই পারে এবং refund যোগ করতে পারে—একটি ভালচর্চা ক্লায়েন্ট ভাঙ্গা ছাড়া।
হাইপারমিডিয়া সবচেয়ে কাজে লাগে কখন
ফ্লোগুলো বিবর্তিত হলে হাইপারমিডিয়া মহিমান্বিত হয়: অনবোর্ডিং ধাপ, চেকআউট, অনুমোদন, সাবস্ক্রিপশন—কোনো প্রসেস যেখানে “পরবর্তী কি করা যাবে” স্টেট, পারমিশন, বা ব্যবসায়িক নিয়ম অনুযায়ী বদলে যায়।
এটি হার্ড-কোডেড URL ও ভাঙনশীল ক্লায়েন্ট অনুমান কমায়। রুটগুলো পুনর্গঠন, নতুন অ্যাকশন পরিচয় করানো, বা পুরোনোগুলো ডিপ্রিকেট করার সময় লিংক রিলেশনগুলোর মান বজায় রেখে ক্লায়েন্টরা কার্যকর থাকে।
দলগুলো কেন এড়িয়ে যায় (এবং তারা কী হারায়)
দলগুলো প্রায়ই HATEOAS এড়িয়ে যায় কারণ এটি অতিরিক্ত কাজ মনে হয়: লিংক ফরম্যাট নির্ধারণ, রিলেশন নাম নিয়ে সিদ্ধান্ত, এবং ক্লায়েন্ট ডেভেলপারদের লিঙ্ক ফলো করাতে শেখানো।
তারা যা হারায় তা হল একটি প্রধান REST সুবিধা: শিথিল কাপলিং। হাইপারমিডিয়া ছাড়া অনেক API হয় “RPC over HTTP”—HTTP ব্যবহার করে, কিন্তু ক্লায়েন্টগুলো এখনও বাই-অফ-ব্যান্ড ডকস ও নির্দিষ্ট URL টেমপ্লেটে বেশি নির্ভরশীল।
বাধ্যতা ৫: স্তরভিত্তিক সিস্টেম
স্তরভিত্তিক সিস্টেম মানে ক্লায়েন্টকে জানা প্রয়োজন নেই (এবং প্রায়ই বোঝা যায় না) এটি আসল অরিজিন সার্ভারের সাথে কথা বলছে না কি মধ্যস্থকার—তারা গেটওয়ে, রিভার্স প্রক্সি, CDN, অথ সার্ভিস, WAF, সার্ভিস মেশ ইত্যাদি হতে পারে।
স্তর কেন উপকারী
স্তর পরিষ্কার সীমা তৈরি করে। সিকিউরিটি টিম টিএলএস, রেট লিমিট, অথেনটিকেশন, এবং রিকোয়েস্ট ভ্যালিডেশন এজে প্রয়োগ করতে পারে ব্যাকএন্ডকে না বদলে। অপারেশন্স টিম গেটওয়ের পেছনে হরাইজন্টালি স্কেল করতে পারে, CDN এ ক্যাশ যোগ করতে পারে, বা ইনসিডেন্টের সময় ট্র্যাফিক সরিয়ে দিতে পারে। ক্লায়েন্টের জন্য এটি সহজ করে: এক স্থায়ী API এন্ডপয়েন্ট, কনসিস্টেন্ট হেডার, এবং পূর্বানুমেয় এরর ফরম্যাট।
বাস্তবে যে ট্রেড-অফগুলো অনুভব করবেন
মধ্যস্থকারি অতিরিক্ত লেটেন্সি যোগ করতে পারে (অতিরিক্ত হপ, অতিরিক্ত হ্যান্ডশেক) এবং ডিবাগিং কঠিন করে তুলতে পারে: বাগটি গেটওয়ে রুলে থাকতে পারে, CDN ক্যাশে থাকতে পারে, অথবা অরিজিন কোডে। ক্যাশিং বিভ্রান্তিও হতে পারে যখন বিভিন্ন স্তর আলাদা ভাবে ক্যাশ করে বা গেটওয়ে হেডার রিরাইট করে যা ক্যাশ কীকে প্রভাবিত করে।
স্তরগুলোকে ক্ষতিকর হওয়া থেকে রক্ষা করার ব্যবহারিক টিপস
- ট্রেসিং আইডি এন্ড-টু-এন্ড ব্যবহার করুন: একটি রিকোয়েস্ট আইডি গ্রহণ করুন (বা জেনারেট করুন) এবং প্রতিটি হপে প্রোপেগেট করুন; এটাকে রেসপন্স ও লগে অন্তর্ভুক্ত করুন।
- এরর প্রচার স্পষ্ট করুন: স্ট্যান্ডার্ড ত্রুটি বডি ব্যবহার করুন এবং আপস্ট্রিম ফেলিওরগুলো স্পষ্টভাবে ম্যাপ করুন (সবকিছুকে জেনেরিক
500 করবেন না)।
- প্রতিটি হপে টাইমআউট সেট করুন: গেটওয়ে টাইমআউট, আপস্ট্রিম টাইমআউট, ও ক্লায়েন্ট টাইমআউট সঙ্গতিপূর্ণ রাখুন যাতে রহস্যময় ডিসকানেক্ট না হয়।
- ক্যাশিং আচরণ ডকুমেন্ট করুন: কোন রেসপন্স ক্যাশেবল এবং কোন হেডারগুলিকে মধ্যস্থকারিদের সংরক্ষণ করতে হবে তা স্পষ্ট রাখুন।
স্তরগুলো শক্তিশালী—তবে সিস্টেমটি অবজারভেবল ও পূর্বানুমেয় রাখা দরকার।
বাধ্যতা ৬ (ঐচ্ছিক): কোড-অন-ডিমান্ড
কোড-অন-ডিমান্ড হল ঐচ্ছিক REST বাধ্যতা: সার্ভার ক্লায়েন্টকে এক্সিকিউটেবল কোড পাঠাতে পারে যা ক্লায়েন্ট সাইডে চলে।
ওয়েবের পরিচিত উদাহরণ: JavaScript
যদি আপনি কখনও এমন পেজ লোড করে থাকেন যা পরে ইন্টারঅ্যাকটিভ হয়ে ওঠে—ফর্ম ভ্যালিডেশন, চার্ট রেন্ডারিং, টেবিল ফিল্টার করা—তবে আপনি কোড-অন-ডিমান্ড ব্যবহার করেছেন। সার্ভার HTML ও ডেটার সাথে JavaScript পাঠায় যা ব্রাউজারে রান করে আচরণ যোগ করে।
এই কারণে ওয়েব দ্রুত বিবর্তিত হতে পারে: ব্রাউজার একটি সাধারণ ক্লায়েন্ট হিসেবে থেকে যাচ্ছে, সাইটগুলো নতুন কার্যকারিতা সরবরাহ করে ব্যবহারকারীকে নতুন অ্যাপ ইনস্টল না করেই।
কেন এটি ঐচ্ছিক এবং অনেক API এ এড়ানো হয়
অন্যান্য সব বাধ্যতা থাকলেই REST কাজ করে; কোড-অন-ডিমান্ড ছাড়া অনেক প্রোডাকশন API সম্পূর্ণভাবে কাজ করে কারণ বাকি বাধ্যতাগুলোই স্কেলিং, সরলতা, ও ইন্টারঅপারিবিলিটি দেয়।
বহু আধুনিক Web API ইচ্ছাকৃতভাবে এক্সিকিউটেবল কোড পাঠাতে এড়ায় কারণ:
- নিরাপত্তা: এক্সিকিউটেবল কোড আক্রমণের পৃষ্ঠফল বাড়ায়
- কনটেন্ট পলিসি: ব্রাউজার CSP ইত্যাদি সীমাবদ্ধতা আরোপ করে
- অডিটিং ও কমপ্লায়েন্স: কী কোড কখন ক্লায়েন্টে রান করেছে তা প্রমাণ করা কঠিন
কোড-অন-ডিমান্ড কোথায় উপযোগী হতে পারে
যখন আপনি ক্লায়েন্ট পরিবেশ নিয়ন্ত্রণ করেন এবং দ্রুত UI আচরণ রোলআউট করতে চান, বা পাতলা ক্লায়েন্টকে সার্ভার থেকে প্লাগইন/রুল ডাউনলোড করাতে চান—তখন এটি মানে রাখতে পারে। কিন্তু এটিকে অতিরিক্ত টুল হিসেবে দেখা ভালো, ভিত্তি হিসেবে নয়।
মুল কথা: REST কোড-অন-ডিমান্ড ছাড়াই পুরোপুরি মেনে চলা যায়—এবং অনেক প্রোডাকশন API তাই করে, কারণ এটি অপশনাল এক্সটেনশিবিলিটি।
আজকের দিনে REST প্রয়োগ করা: ব্যবহারিক পছন্দ ও সাধারণ ভুল
অধিকাংশ দল REST নিখ হাতে প্রত্যাখ্যান করে না—তারা “REST-ish” স্টাইল গ্রহণ করে जो HTTP কে ট্রান্সপোর্ট হিসেবে রেখে কিছু মূল বাধ্যতা বাদ দেয়। এটা ঠিক আছে যদি তা সচেতন ট্রেড-অফ হয়, না হলে পরে এটি ভাঙনশীল ক্লায়েন্ট ও ব্যয়বহুল রিভাইট আকারে ফিরে আসে।
সাধারণ REST-ish শর্টকাট (এবং কেন ঘটে)
পুনরাবৃত্তি করা প্যাটার্নগুলো:
- RPC এন্ডপয়েন্ট:
/doThing, /runReport, /users/activate—নামকরণ সহজ, সংযুক্ত করা সহজ।
- ভর্ব-ভারি URL:
/createOrder, /updateProfile, /deleteItem—HTTP মেথড দ্বিতীয় স্তরে চলে যায়।
- গোপন সেশন: “স্টেটলেস” বলে দাবি করে কিন্তু স্টিকি সেশন বা সার্ভার মেমরি ব্যবহার করা।
এসব পছন্দ প্রথম দিকে দ্রুত উত্পাদনশীল মনে হয় কারণ তারা অভ্যন্তরীণ ফাংশন নাম ও ব্যবসায়িক অপারেশনের মতোই মানায়।
পরে আপনি কী ফলাফল দেখবেন
- ভাঙনশীল ক্লায়েন্ট: ক্লায়েন্টরা নির্দিষ্ট এন্ডপয়েন্ট আকার ও অ্যাড-হক আচরণের ওপর নির্ভর করলে ছোট সার্ভার রিফ্যাক্টরিংও ব্রেকিং চেঞ্জ হয়ে দাঁড়ায়।
- কঠিন ভার্সনিং: URL-এ অ্যাকশন কোড করলে আপনি আচরণ ভের্শনিং-এ পড়ে যান, রেপ্রেজেন্টেশন বিকাশের উপর না।
- ক্যাশ মিস (এবং বেশি ল্যাটেন্সি): সবকিছু POST করা বা ক্যাশ হেডার উপেক্ষা করলে মধ্যস্থকারিরা সাহায্য করতে পারে না।
- স্কেলিং সমস্যা: গোপন সার্ভার-সাইড সেশন হরাইজন্টাল স্কেলিং জটিল করে এবং ব্যর্থতা পুনরুদ্ধার কঠিন করে।
একটি বাস্তববাদী মিল-চেকলিস্ট
এটি একটি “আমরা কতটা REST-আছি” রিভিউ হিসেবে ব্যবহার করুন:
- রিসোর্স নাম দিন, অ্যাকশন নয়:
/orders/{id}-কে বেছে নিন /createOrder-এর বদলে।
- HTTP মেথড সচেতনভাবে ব্যবহার করুন: GET পড়ার জন্য, POST তৈরির জন্য, PUT/PATCH আপডেটের জন্য, DELETE সরানোর জন্য।
- অনুরোধগুলোকে স্বাধীন রাখুন: “ক্লায়েন্ট কোন ধাপে আছে” বুঝতে সার্ভার মেমরি নির্ভর করবেন না।
- যেখানে নিরাপদ ক্যাশিং ব্যবহার করুন: GET রেসপন্সে
Cache-Control, ETag, ও Vary নির্দিষ্ট করুন।
- ত্রুটি ও মিডিয়া টাইপ মানক করুন: কনসিস্টেন্ট স্ট্যাটাস কোড ও রেসপন্স শেইপ বানান
যখন আপনি বাস্তবে নির্মাণ করছেন তখন এটি কোথায় প্রকাশ পায়
REST বাধ্যতাগুলো শুধুই তত্ত্ব নয়—এগুলি শিপিং করার সময়ই অনুভূত হয়। যখন আপনি দ্রুত API জেনারেট করছেন (উদাহরণ: React ফ্রন্টএন্ড স্ক্যাফোল্ড করে Go + PostgreSQL ব্যাকএন্ড), সবচেয়ে সহজ ভুল হলো “যা দ্রুত কাজ করে” দিয়ে ইন্টারফেস নির্ধারণ করা।
যদি আপনি Koder.ai-এর মতো কোনো ভিব-কোডিং প্ল্যাটফর্ম ব্যবহার করে চ্যাট থেকে ওয়েব অ্যাপ বানান, তাহলে এই REST বাধ্যতাগুলো কথ্য আলোচনায় আগে আনা ভালো—প্রথমে রিসোর্সের নামকরণ করা, স্টেটলেস থাকা, কনসিস্টেন্ট ত্রুটি শেপ নির্ধারণ করা, এবং কোথায় ক্যাশিং নিরাপদ তা ঠিক করা। এইভাবে দ্রুত ইটারেশন করলেও API-গুলো ক্লায়েন্টদের জন্য পূর্বানুমেয় ও সহজে বিবর্তনশীল থাকবে। (এবং কারণ Koder.ai সোর্স কোড এক্সপোর্ট সমর্থন করে, আপনি API কন্ট্র্যাক্ট ও ইমপ্লিমেন্টেশন ধাপে ধাপে পরিমার্জন করতে পারবেন।)
API ও ওয়েব অ্যাপ টিমদের জন্য ফলাফল
প্রথমে আপনার মূল রিসোর্সগুলো নির্ধারণ করুন, তারপর বাধ্যতাগুলো সচেতনভাবে বেছে নিন: যদি আপনি ক্যাশিং বা হাইপারমিডিয়া বাদ দিচ্ছেন, কেন ছেড়ে দিলেন এবং তার বিকল্প কী তা ডকুমেন্ট করুন। লক্ষ্য পরিশুদ্ধতা নয়—সুযুক্ততা: স্থায়ী রিসোর্স আইডি, পূর্বানুমেয় সেমান্টিকস, এবং প্রকাশ্য ট্রেড-অফ যাতে আপনার সিস্টেম বিবর্তনশীল থাকলেও ক্লায়েন্ট স্থিতিশীল থাকে।