১৮ মে, ২০২৫·8 মিনিট
স্কিমা ডিজাইন প্রথম: প্রাথমিক কোয়েরি টিউনিংয়ের চেয়ে দ্রুত অ্যাপস
শুরুতেই পারফরম্যান্স লাভ সাধারণত ভাল স্কিমা ডিজাইন থেকে আসে: সঠিক টেবিল, কী এবং কনস্ট্রেইন্ট পরবর্তীতে ধীর কোয়েরি ও ব্যয়বহুল রিরাইট প্রতিরোধ করে।
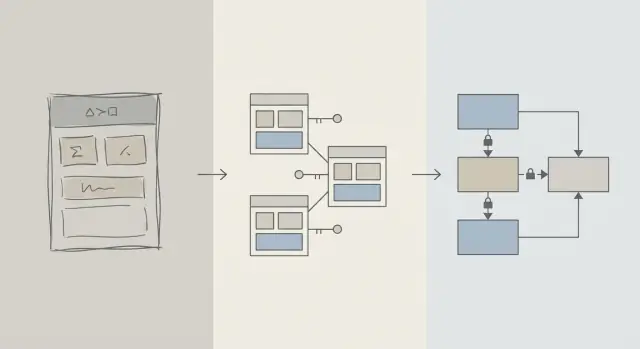
স্কিমা বনাম কোয়েরি অপটিমাইজেশন: আমরা কী বুঝি
যখন কোনো অ্যাপ ধীর লাগে, প্রথম প্রতিক্রিয়া প্রায়ই “SQL ঠিক করি” হয়। এই ইচ্ছাটা যৌক্তিক: একটা পৃথক কোয়েরি দেখা যায়, পরিমাপযোগ্য এবং সহজে দোষারোপ করা যায়। আপনি EXPLAIN চালাতে পারেন, একটি ইন্ডেক্স যোগ করতে পারেন, JOIN সামঞ্জস্য করতে পারেন, এবং কখনও কখনও তাত্ক্ষণিক উন্নতি দেখতে পাবেন।
কিন্তু প্রোডাক্টের জীবনের প্রথমে, গতি সমস্যা নির্দিষ্ট কোয়েরি লেখার থেকে নয় বরং ডেটার আকার-আকৃতির কারণেও হতে পারে। যদি স্কিমা আপনাকে ডাটাবেসের বিরুদ্ধে লড়তে বাধ্য করে, তাহলে কোয়েরি টিউনিং একটি হুইক-এ-মোল খেলার মতো চক্রে পরিণত হয়।
স্কিমা ডিজাইন (সরল বাংলা)
স্কিমা ডিজাইন হল আপনি কীভাবে ডেটা সাজাবেন: টেবিল, কলাম, সম্পর্ক এবং নিয়ম। এর মধ্যে রয়েছে নির্ধারণ—কোন “বস্তুকে” আলাদা টেবিল দেওয়া হবে (ব্যবহারকারী, অর্ডার, ইভেন্ট), টেবিলগুলো কীভাবে সম্পর্কিত থাকবে (one-to-many, many-to-many), কী ইউনিক বা আবশ্যক হবে (কনস্ট্রেইন্ট), এবং কীভাবে স্টেট বা ইতিহাস তুলে ধরা হবে (টাইমস্ট্যাম্প, স্ট্যাটাস ফিল্ড, অডিট রেকর্ড)।
ভাল স্কিমা ডিজাইন করলে যে প্রশ্নগুলো স্বাভাবিকভাবে জিজ্ঞাসা করা হয়, সেগুলোই দ্রুতও হয়।
কোয়েরি অপটিমাইজেশন (সরল বাংলা)
কোয়েরি অপটিমাইজেশন হল ডেটা আহরণের বা আপডেটের উপায় উন্নত করা: কোয়েরি পুনর্লিখন, ইন্ডেক্স যোগ করা, অপ্রয়োজনীয় কাজ কমানো, এবং এমন প্যাটার্ন এড়ানো যা বড় স্ক্যান ট্রিগার করে।
উভয়ই জরুরি—কিন্তু সময়ক্রম বেশি জরুরি
এই আর্টিকেলটি “স্কিমা ভাল, কোয়েরি খারাপ” বলতে চায় না। এটি ক্রমানুক্রমের বিষয়: ডাটাবেস স্কিমার মূল বিষয়গুলো প্রথমে ঠিক করুন, তারপর সেই কোয়েরিগুলো টিউন করুন যেগুলো প্রকৃতপক্ষে প্রয়োজন।
আপনি শেখাবেন কেন স্কিমা সিদ্ধান্তগুলো প্রথমদিকে পারফরম্যান্সকে অত্যধিক প্রভাবিত করে, কখন স্কিমাই প্রকৃত বটলনেক তা চিনবেন, এবং কিভাবে অ্যাপ বাড়ার সাথে সেটি নিরাপদভাবে বিবর্তিত করবেন। এটি প্রোডাক্ট টিম, ফাউন্ডার এবং বাস্তববিশ্বের অ্যাপ বানানো ডেভেলপারদের জন্য লেখা—ডাটাবেস বিশেষজ্ঞদের জন্য নয়।
কেন স্কিমা ডিজাইন প্রাথমিকভাবে পারফরম্যান্স চালায়
শুরুতে পারফরম্যান্স সাধারণত কল্পনাপ্রসূত SQL-এর সম্পর্কে নয়—এটি ডাটাবেসকে কত ডেটা স্পর্শ করতে হচ্ছে তার ব্যাপার।
কাঠামো নির্ধারণ করে কতটা স্ক্যান হবে
একটি কোয়েরি কেবল সেই পরিমাণে সিলেক্টিভ হতে পারে যতটা ডেটা মডেল অনুমতি দেয়। যদি আপনি “status”, “type”, বা “owner” মতো অ্যাট্রিবিউটগুলো অসংগঠিত ক্ষেত্রে রাখেন (বা অসামঞ্জস্য টেবিলগুলোর মধ্যে ছড়িয়ে রাখেন), ডাটাবেস প্রায়ই মিল খুঁজতে অনেক বেশি রো স্ক্যান করতে বাধ্য হয়।
ভালো স্কিমা স্বাভাবিকভাবে সার্চ স্পেস সংকীর্ণ করে: স্পষ্ট কলাম, সামঞ্জস্যপূর্ণ ডেটা টাইপ, এবং সুশৃঙ্খল টেবিলের মানে কোয়েরিগুলো আগেভাগে ফিল্টার করে কম পৃষ্ঠা পড়ে।
অনুপস্থিত কিs ব্যয়বহুল কাজ তৈরি করে
যখন প্রাইমারী কি এবং ফরেন কি অনুপস্থিত (অথবা জোরদার না করা), সম্পর্কগুলো অনুমানীয় হয়ে ওঠে। সেটা কাজকে কোয়েরি স্তরে ঠেলে দেয়:
- Join বড় হয়ে যায় কারণ নির্ভরযোগ্য, ইনডেক্সড জয়েন পথ নেই।
- ফিল্টারগুলো আরও জটিল হয় কারণ আপনি ডুপ্লিকেট, NULL, এবং “প্রায় মিল” মানগুলোর জন্য ক্ষতিপূরণ দিচ্ছেন।
কনস্ট্রেইন্ট না থাকলে খারাপ ডেটা জমে যায়—তাই রো বাড়ার সাথে কোয়েরিগুলো ক্রমশ ধীর হয়ে যায়।
ইন্ডেক্স স্কিমার অনুসরণ করে (সবকিছু মেরামত করতে পারে না)
ইন্ডেক্স তখনই সবচেয়ে কার্যকর যখন তারা এমন প্রবেশপথগুলোর সাথে মিলবে যেগুলো পূর্বানুমানযোগ্য: ফরেন কি দিয়ে জয়েন করা, ভাল সংজ্ঞায়িত কলাম দিয়ে ফিল্টার করা, সাধারণ ফিল্ড দিয়ে সোর্ট করা। যদি স্কিমা গুরুত্বপূর্ণ অ্যাট্রিবিউট ভুল টেবিলে রাখে, একটি কলামে মান মিক্স করে, বা টেক্সট পার্সিংয়ের ওপর নির্ভর করে, ইন্ডেক্স আপনাকে বাঁচাতে পারবেন না—আপনি তবুও অতিরিক্ত স্ক্যান ও রূপান্তর করতে হবে।
ডিফল্ট হিসাবে দ্রুত
পরিস্কার সম্পর্ক, স্থিতিশীল শনাক্তকারী, এবং যুক্তিসঙ্গত টেবিল সীমানার সঙ্গে অনেক সাধারণ কোয়েরি “ডিফল্টভাবে দ্রুত” হয় কারণ তারা কম ডেটা স্পর্শ করে এবং সরল, ইনডেক্স-ফ্রেন্ডলি শর্ত ব্যবহার করে। তখন কোয়েরি টিউনিং একটি শেষ স্তরের কাজ হয়ে যায়—নিয়মিত আগুন নেভানোর কাজ নয়।
প্রারম্ভিক-স্টেজ বাস্তবতা: পরিবর্তনই স্থায়ী
শুরুতে প্রোডাক্টগুলোর “স্থিতিশীল রিকোয়ারমেন্ট” থাকে না—এর বদলে থাকে পরীক্ষা-নিরীক্ষা। ফিচার শিপ হয়, আবার লেখা হয়, বা হারিয়ে যায়। ছোট একটি টিম সীমিত সময়ে রোডম্যাপ, সাপোর্ট, ও অবকাঠামো সামলায় এবং পুরনো সিদ্ধান্তগুলো পুনর্বিবেচনার সময় কম থাকে।
সবচেয়ে বেশি কী পরিবর্তন হয়
অধিকাংশ ক্ষেত্রে SQL টেক্সট প্রথমে বদলে যায় না। ডেটার অর্থই বদলে যায়: নতুন স্টেট, নতুন সম্পর্ক, নতুন “ওহ, আমাদের এটা ট্র্যাক করতে হবে…” ফিল্ড, এবং এমন ওয়ার্কফ্লো যা লঞ্চের সময় কল্পনাও করা হয়নি। সেই পরিবর্তন স্বাভাবিক—এবং ঠিক এই কারণেই প্রথম পর্যায়ে স্কিমা সিদ্ধান্তগুলো এত গুরুত্বপূর্ণ।
পরে স্কিমা ঠিক করা কেন কোয়েরি ঠিক করা থেকে কঠিন
একটি কোয়েরি পুনঃলিখন সাধারণত উল্টানো যোগ্য এবং লোকাল: আপনি একটি উন্নতি শিপ করতে পারেন, পরিমাপ করতে পারেন, এবং প্রয়োজন হলে রোল ব্যাক করতে পারেন।
স্কিমা রিরাইট ভিন্ন। একবার আপনি বাস্তব কাস্টমার ডেটা জমা করে ফেললে, প্রত্যেক গঠনগত পরিবর্তন একটি প্রকল্পে পরিণত হয়:
- মাইগ্রেশন যা টেবিল লক করে বা পিক সময়ে লেখাকে ধীর করে
- ব্যাকফিলস নতুন কলাম পূরণ করতে বা ডেরাইভড ডেটা পুনর্নিমাণ করতে
- ডুয়াল-রাইট বা শ্যাডো টেবিল অ্যাপ চলমান রাখার জন্য ট্রান্সিশনের সময়
- ডাউনটাইম ঝুঁকি যদি পরিবর্তন অনলাইনভাবে করা না যায়
ভাল টুলিং থাকা সত্ত্বেও, স্কিমা পরিবর্তন সমন্বয়ের খরচ বাড়ায়: অ্যাপ কোড আপডেট, ডেপ্লয়মেন্ট সিকোয়েন্সিং, এবং ডেটা ভ্যালিডেশন।
প্রারম্ভিক সিদ্ধান্ত কিভাবে গুনিত হয়
যখন ডাটাবেস ছোট থাকে, একটি ক্লামি স্কিমা “বুঝতে ভালো” দেখাতে পারে। কিন্তু রো লক্ষ থেকে মিলিয়নে বাড়লে একই ডিজাইন বড় স্ক্যান, ভারী ইন্ডেক্স, এবং বেশি ব্যয়বহুল জয়েন তৈরি করে—তারপর প্রতিটি নতুন ফিচার সেই ভিত্তির উপর নির্মিত হয়।
তাই প্রারম্ভিক-স্টেজ লক্ষ্য পারফেকশন নয়। লক্ষ্য হল এমন একটি স্কিমা বেছে নেওয়া যা পরিবর্তন গ্রহণ করতে পারে এমনকি যখন প্রোডাক্ট কিছু নতুন শিখে—প্রতিবার ঝুঁকিপূর্ণ মাইগ্রেশন ছাড়াই।
ধীর কোয়েরি প্রতিরোধে ডিজাইনের মৌলিক বিষয়াবলি
প্রাথমিক অবস্থায় বেশিরভাগ “ধীর কোয়েরি” সমস্যা SQL কায়দা নয়—তারা ডেটা মডেল ambiguity থেকে আসে। যদি স্কিমা স্পষ্ট না করে একটি রেকর্ড কী প্রতিনিধিত্ব করে, বা রেকর্ডগুলো কীভাবে সম্পর্কিত, প্রতিটি কোয়েরি লেখার, চালানোর এবং রক্ষণাবেক্ষণের জন্য ব্যয়বহুল হয়ে ওঠে।
কয়েকটি মূল ইন্টিটি নিয়ে শুরু করুন
শুরুতেই আপনার প্রডাক্ট যে কয়েকটি জিনিস ছাড়া কাজ করতে পারবে না সেগুলো নাম দিন: ব্যবহারকারী, অ্যাকাউন্ট, অর্ডার, সাবস্ক্রিপশন, ইভেন্ট, ইনভয়েস—যা সত্যিই কেন্দ্রীয়। তারপর সম্পর্কগুলো স্পষ্টভাবে নির্ধারণ করুন: one-to-many, many-to-many (সাধারণত একটি join টেবিল দিয়ে), এবং মালিকানা (কে কী “ধারণ” করে)।
একটি ব্যবহারিক চেক: প্রতিটি টেবিলের জন্য আপনি বাক্যটি সম্পূর্ণ করতে পারা উচিত “এই টেবিলের একটি রো প্রতিনিধিত্ব করে ___।” যদি পারেন না, টেবিলটি সম্ভবত ধারণা মিশ্রিত করছে, যা পরে জটিল ফিল্টার এবং জয়েন বাধ্য করবে।
নামকরণ এবং মালিকানা বিরক্তিকরভাবে ধারাবাহিক রাখুন
কনসিস্টেন্সি আকস্মিক জয়েন এবং বিভ্রান্তিকর API আচরণ প্রতিরোধ করে। কনভেনশন নির্বাচন করুন (snake_case বনাম camelCase, *_id, created_at/updated_at) এবং সেগুলোর প্রতি অনসলিষ্ট থাকুন।
আরও বলা উচিত—একটি ফিল্ড কার: উদাহরণস্বরূপ, “billing_address” কি একটি অর্ডারের (তার সময়ের স্ন্যাপশট) নাকি একটি ব্যবহারকারীর (বর্তমান ডিফল্ট)? উভয়ই বৈধ হতে পারে—কিন্তু যদি স্পষ্ট উদ্দেশ্য ছাড়া মিশ্রিত করা হয়, তাহলে সত্য বের করতে ধীর, ত্রুটিপূর্ণ কোয়েরি তৈরি হবে।
বাস্তবতার সাথে মিলিয়ে টাইপ নির্বাচন করুন
রানটাইম কনভার্শন এড়াতে টাইপ ব্যবহার করুন:
- আপনার বোঝাপড়া অনুযায়ী টাইমজোন-সহ টাইমস্ট্যাম্প ব্যবহার করুন।
- মানের জন্য decimal ব্যবহার করুন (float নয়)।
- পরিচিত ক্যাটেগরির জন্য enum/রেফারেন্স টেবিল ব্যবহার করুন।
টাইপ ভুল হলে, ডাটাবেস কার্যকরভাবে তুলনা করতে পারে না, ইন্ডেক্স কম কার্যকর হয়, এবং কোয়েরিগুলো প্রায়ই কাস্টিং করতে হয়।
পরিকল্পনা ছাড়া ফ্যাক্ট ডুপ্লিকেট করবেন না
একই ফ্যাক্ট যদি একাধিক স্থানে সংরক্ষিত হয় (উদাহরণ: order_total এবং sum(line_items)), এটা ড্রিফট সৃষ্টি করে। যদি আপনি ডেরাইভড ভ্যালু ক্যাশ করেন, সেটি ডকুমেন্ট করুন, সোর্স অফ ট্রুথ নির্ধারণ করুন, এবং আপডেট সাবলীলভাবে নিশ্চিত করুন (প্রায়শই অ্যাপ্লিকেশন লজিক সহ কনস্ট্রেইন্ট)।
কিs এবং কনস্ট্রেইন্ট: ডাটা ইন্টিগ্রিটি থেকেই গতি শুরু
দ্রুত ডাটাবেস সাধারণত একটি পূর্বানুমিত ডাটাবেস। কি ও কনস্ট্রেইন্ট আপনার ডেটাকে পূর্বানুমিত করে কারণ তারা “অসম্ভব” অবস্থা—মিসিং সম্পর্ক, ডুপ্লিকেট পরিচয়, বা এমন মান যা অ্যাপ বোঝে না—রোধ করে। সেই পরিষ্কারতা সরাসরি পারফরম্যান্সে প্রভাব ফেলে কারণ কুয়েরি প্ল্যানার ভাল অনুমান করতে পারে।
প্রাইমারী কি: প্রতিটি টেবিলে স্থায়ী শনাক্তকারী থাকা দরকার
প্রতিটি টেবিলের একটি প্রাইমারী কি (PK) থাকা উচিত: একটি কলাম (বা ছোট সেট) যা ইউনিকভাবে একটি রো চিহ্নিত করে এবং কখনও পরিবর্তন হয় না। এটা শুধু ডাটাবেস তত্ত্ব নয়—এটি টেবলগুলো দক্ষভাবে জয়েন করতে, নিরাপদভাবে ক্যাশ করতে, এবং রেকর্ড রেফারেন্স করতে দেয়।
একটি স্থায়ী PK অনুপস্থিত হলে, অ্যাপগুলো ইমেইল, নাম, টাইমস্ট্যাম্প বা কয়েক কলামের বান্ডলে রো চিহ্নিত করা শুরু করে—যার ফলে প্রশস্ত ইন্ডেক্স, ধীর জয়েন, এবং সেই মানগুলো পরিবর্তিত হলে এজ-কেস তৈরি হয়।
ফরেন কি: অপ্টিমাইজারকে সাহায্য করে এমন ইন্টেগ্রিটি
ফরেন কি (FK) সম্পর্কগুলো নিশ্চিত করে: উদাহরণস্বরূপ orders.user_id অবশ্যই users.id-কে পয়েন্ট করবে। FK ছাড়া, অবৈধ রেফারেন্স বেড়ে যায় (ডিলিটেড ইউজারের অর্ডার, অনুপস্থিত পোস্টের জন্য মন্তব্য), এবং প্রতিটি কোয়েরি প্রতিরক্ষামূলকভাবে ফিল্টার, left-join, এবং NULL হ্যান্ডল করতে বাধ্য হয়।
FK থাকলে, কুয়েরি প্ল্যানার প্রায়ই জয়েনগুলো আরও আত্মবিশ্বাসীভাবে অপ্টিমাইজ করতে পারে কারণ সম্পর্ক স্পষ্ট ও গ্যারান্টিযুক্ত। আপনি অরফান রো জমা হবার সম্ভাবনাও কমাবেন যা সময়ের সাথে টেবিল ও ইন্ডেক্স বড় করে।
পরিষ্কার, দ্রুত ডেটার জন্য কনস্ট্রেইন্টগুলো গার্ডরেইল
কনস্ট্রেইন্টগুলো নীতিবিরোধ নয়—এগুলো গার্ডরেইল:
- UNIQUE ডুপ্লিকেট প্রতিরোধ করে যা অ্যাপকে অতিরিক্ত লুকআপ ও ক্লিনআপ করতে বাধ্য করে। উদাহরণ: canonical
users.email। - NOT NULL তিন-অবস্থার যুক্তি এবং অপ্রত্যাশিত NULL-হ্যান্ডলিং শাখা এড়ায়।
- CHECK মানগুলো নির্দিষ্ট সেটে রাখে (উদাহরণ:
status IN ('pending','paid','canceled'))।
পরিষ্কার ডেটা মানে সরল কোয়েরি, কম ব্যাকআপ কন্ডিশন, এবং কম “যদি না” ধাঁচের জয়েন।
ধীরতার দিকে ধাবিত কিছু সাধারণ অ্যান্টি-প্যাটার্ন
- ফরেন কি নেই: পরবর্তীতে অরফান ক্লিনআপ জব এবং জটিল কোয়েরি লজিক খরচ হবে।
- ডুপ্লিকেট "email" ফিল্ড (যেমন
users.emailএবংcustomers.email): পরিচয় দ্বন্দ্ব এবং ডুপ্লিকেট ইন্ডেক্স তৈরি করে। - ফ্রি-ফর্ম স্ট্যাটাস স্ট্রিং: যেমন "Cancelled" বনাম "canceled" টাইপ টাইপো গোপন সেগমেন্ট তৈরি করে যা ফিল্টার এবং রিপোর্ট ভেঙে দেয়।
যদি আপনি প্রাথমিকভাবে গতি চান, খারাপ ডেটা সংরক্ষণ করা কঠিন করে দিন। ডাটাবেস আপনাকে সরল প্ল্যান, ছোট ইন্ডেক্স, এবং কম পারফরম্যান্স অচমকে পুরস্কৃত করবে।
নরমালাইজেশন বনাম ডেনরমালাইজেশন: ব্যবহারিক ভারসাম্য
শিপ করার আগে মাইগ্রেশন পরিকল্পনা করুন
প্রোডাকশন ডেটা বদলানোর আগে মাইগ্রেশন ধাপ নকশা করতে প্ল্যানিং মোড ব্যবহার করুন।
নরমালাইজেশন একটি সহজ ধারণা: প্রতিটি “ফ্যাক্ট” এক জায়গায় রাখুন যাতে ডেটাবেস জায়গায় জায়গায় কপি না হয়। একই মান যদি একাধিক টেবিলে বা কলামে কপি করা হয়, আপডেট ঝুঁকিপূর্ণ হয়ে ওঠে—এক কপি পরিবর্তিত হলে অন্যটি না হলে কনফ্লিক্ট দেখাবে।
নরমালাইজেশন (ডিফল্ট): এক ফ্যাক্ট, এক বাড়ি
বাস্তবে, নরমালাইজেশন মানে এন্টিটি আলাদা করা যাতে আপডেট স্পষ্ট ও পূর্বানুমিত হয়। উদাহরণ: একটি পণ্যের নাম ও দাম products টেবিলে থাকা উচিত, প্রতিটি অর্ডারের রোতে বারবার রাখার বদলে। ক্যাটেগরি নাম categories-এ থাকা উচিত এবং ID দিয়ে রেফার করা উচিত।
এটি কমায়:
- ডুপ্লিকেট ডেটা (কম স্টোরেজ, কম অসামঞ্জস্য)
- আপডেট ভুল (একবার পরিবর্তন করলে সব জায়গায় প্রতিফলিত হবে)
- বিভ্রান্তকর “কোনটি সঠিক?” বাগ
অতিরিক্ত নরমালাইজেশন ক্ষতি করে কখন
নরমালাইজেশন অতিরিক্ত হলে সমস্যাও হয়—যখন আপনি ডেটা অনেক ছোট টেবিলে ভাগ করেন এবং দৈনন্দিন পৃষ্ঠাগুলোর জন্য বারবার জয়েন দরকার পড়ে। ডাটাবেস সঠিক ফলাফল দিতে পারতে পারে, কিন্তু সাধারণ রিড ধীর ও জটিল হয়ে ওঠে কারণ প্রতিটি রিকোয়েস্ট বহুজায়গায় জয়েন করে।
একটি সাধারণ প্রাথমিক-স্টেজ লক্ষণ: একটি “সহজ” পেজ (যেমন অর্ডার ইতিহাস তালিকা) দেখানোর জন্য 6–10 টেবিল জয়েন করতে হয় এবং পারফরম্যান্স ট্রাফিক ও ক্যাশ উষ্ণতার উপর নির্ভর করে ভিন্নভাবে যায়।
ব্যবহারিক পদ্ধতি: কোর ফ্যাক্ট নরমালাইজ করুন, হট রিডগুলোর জন্য ডেনরমালাইজ করুন
একটি যুক্তিসঙ্গত ভারসাম্য হল:
- কোর ফ্যাক্ট এবং মালিকানা নরমালাইজ করুন (সোর্স অফ ট্রুথ)। প্রোডাক্ট অ্যাট্রিবিউট
products-এ রাখুন, ক্যাটেগরি নামcategories-এ রাখুন, এবং ফরেন কি দিয়ে সম্পর্ক বজায় রাখুন। - সর্বাধিক ব্যবহৃত রিডগুলোর জন্য সাবধানে ডেনরমালাইজ করুন—কিন্তু শুধু তখনই যখন আপনি সুবিধা ও কীভাবে সঠিক থাকবে এটি ব্যাখ্যা করতে পারেন।
ডেনরমালাইজেশন মানে একটি ঘনিষ্ঠ অংশের ডেটা ইচ্ছাকৃতভাবে ডুপ্লিকেট করা যাতে ঘনবহুল কোয়েরি সহজ হয় (কম জয়েন, দ্রুত লিস্ট)। গুরুত্বপূর্ণ শব্দ হল সাবধানে: প্রতিটি ডুপ্লিকেট ফিল্ড আপডেট রাখার পরিকল্পনা চাই।
উদাহরণ: প্রোডাক্টস, ক্যাটেগরিস, ও অর্ডার আইটেমস
একটি নরমালাইজড সেটআপ হতে পারে:
products(id, name, price, category_id)categories(id, name)orders(id, customer_id, created_at)order_items(id, order_id, product_id, quantity, unit_price_at_purchase)
মনযোগী জিনিস: order_items-এ unit_price_at_purchase রাখা (এক ধরণের ডেনরমালাইজেশন) কারণ আপনাকে ঐতিহাসিক সঠিকতা দরকার, এমনকি প্রোডাক্টের দাম পরবর্তীতে বদলে গেলেও। ওই কপি ইচ্ছাকৃত এবং স্থিতিশীল।
আপনার সবচেয়ে সাধারণ স্ক্রিন যদি “আইটেম সারসংক্ষেপসহ অর্ডার” হয়, আপনি order_items-এ product_name ডেনরমালাইজ করতে পারেন যাতে প্রতিটি তালিকার জন্য products-এ জয়েন করতে না হয়—কিন্তু কেবল যদি আপনি সিঙ্ক রাখার জন্য প্রস্তুত থাকেন (অথবা গ্রহণ করেন যে এটি ক্রয়কালীন স্ন্যাপশট)।
ইন্ডেক্স কৌশল স্কিমার অনুসরণ করে, উল্টো নয়
ইন্ডেক্সকে প্রায়ই জাদুকরী “স্পিড বাটন” হিসেবে দেখা হয়, কিন্তু তারা কেবল সেই সময় ভাল কাজ করে যখন টেবিল স্ট্রাকচার অর্থবহ। যদি আপনি এখনও কলামগুলো নাম পরিবর্তন করছেন, টেবিল ভাগ বা সম্পর্ক বদলাচ্ছেন, তাহলে আপনার ইন্ডেক্স সেটও চক্রচূর্ণ হবে। ইন্ডেক্সগুলো তখনই সর্বোত্তম কাজ করে যখন কলামগুলো (এবং অ্যাপ কিভাবে ফিল্টার/সোর্ট করে) পর্যাপ্ত স্থিতিশীল যেন আপনি প্রতি সপ্তাহে পুনর্নির্মাণ না করছেন।
আপনার অ্যাপ যে প্রশ্ন বেশি জিজ্ঞাসা করে তা দিয়ে শুরু করুন
আপনাকে নিখুঁত ভবিষ্যদ্বাণী করতে হবে না, কিন্তু আপনাকে সারাংশে গুরুত্বপূর্ণ কয়েকটি কোয়েরি জানতে হবে:
- “ইমেইল দিয়ে ব্যবহারকারী খুঁজুন।”
- “এক গ্রাহকের সাম্প্রতিক অর্ডার দেখান।”
- “ইনভয়েসগুলো স্ট্যাটাস অনুযায়ী, সর্বশেষে প্রথম তালিকা করুন।”
এই বিবৃতিগুলো সরাসরি বলে দেয় কোন কলামগুলো ইন্ডেক্স পাবে। যদি আপনি এগুলো মুখে বলতে না পারেন, সাধারণত এটা স্কিমা স্পষ্টতার সমস্যা—ইন্ডেক্সিংয়ের নয়।
কম্পোজিট ইন্ডেক্স সহজ ভাষায়
কম্পোজিট ইন্ডেক্স একাধিক কলাম কভার করে। কলামের ক্রম গুরুত্বপূর্ণ কারণ ডাটাবেস বামে-বাম দিয়ে ইনডেক্সকে কার্যকরভাবে ব্যবহার করতে পারে।
উদাহরণস্বরূপ, যদি আপনি প্রায়ই customer_id দিয়ে ফিল্টার করেন এবং তারপর created_at দিয়ে সোর্ট করেন, (customer_id, created_at) ইন্ডেক্স বেশ উপকারী। বিপরীত (created_at, customer_id) একই কোয়েরির ক্ষেত্রে সমানভাবে সাহায্য নাও করতে পারে।
সবকিছুকে ইনডেক্স করবেন না
প্রতি অতিরিক্ত ইন্ডেক্সের একটি খরচ আছে:
- ধীর লেখাঃ ইনসার্ট/আপডেট সব ইন্ডেক্স আপডেট করতে হবে।
- অতিরিক্ত স্টোরেজঃ ইন্ডেক্স ডাটাবেস সাইজের বড় অংশ হতে পারে।
- জটিলতা বাড়ে: অতিরিক্ত ইন্ডেক্স ম্যানেজমেন্ট ও টিউনিংকে কঠিন করে তোলে।
একটি পরিষ্কার, ধারাবাহিক স্কিমা “সঠিক” ইন্ডেক্সগুলোকে একটি ছোট সেটে সীমাবদ্ধ করে যেগুলো বাস্তব অ্যাক্সেস প্যাটার্নের সাথে মেলে—বিনা স্থায়ী লেখার ও স্টোরেজ ট্যাক্সের।
লিখন পারফরম্যান্স: অগোচর্য খরচ একটি অসংগঠিত স্কিমা তৈরি করে
আপনার সোর্স কোড যেকোনো সময় এক্সপোর্ট করুন
স্কিমা ও ফিচার পরিবর্তন হলে সোর্স কোড এক্সপোর্ট করে নিয়ন্ত্রণ রাখুন।
ধীর অ্যাপ সবসময় রিডের কারণে ধীর নয়। অনেক প্রাথমিক পারফরম্যান্স সমস্যা ইনসার্ট ও আপডেটের সময় দেখা যায়—ইউজার সাইনআপ, চেকআউট ফ্লো, ব্যাকগ্রাউন্ড জব—কারণ একটি জটিল স্কিমা প্রতিটি লেখার উপর অতিরিক্ত কাজ করে।
কেন লেখাগুলি ব্যয়বহুল হয়
কয়েকটি স্কিমা পছন্দ গোপনে প্রতিটি পরিবর্তনের খরচ গুণিত করে:
- ওয়াইড রো: একটি টেবিলে ডজন বা শত কলাম ঠুকে দিলে সাধারণত বড় রো, বেশি I/O, এবং বেশি ক্যাশ চ্যার্ন হয়—যদিও অধিকাংশ কলাম রোজ দেখা না-ও যায়।
- অতিরিক্ত ইন্ডেক্স: ইন্ডেক্স রিড দ্রুত করে, কিন্তু প্রতিটি ইনসার্ট/আপডেট প্রতিটি ইন্ডেক্সও আপডেট করে।
- ট্রিগার ও ক্যাসকেড: ট্রিগার একটি সরল
INSERTএর পিছনে অতিরিক্ত কাজ লুকিয়ে রাখতে পারে। ক্যাসকেডিং ফরেন কি সঠিক ও উপযোগী হতে পারে, কিন্তু তা লেখার সময় অতিরিক্ত কাজ যোগ করে যা সম্পর্কিত ডেটার সাথে বৃদ্ধি পায়।
রিড-হেভি বনাম রাইট-হেভি: কষ্ট জানা করে বেছে নিন
আপনার ওয়ার্কলোড যদি রিড-হেভি (ফিড, সার্চ পেজ), আপনি বেশি ইন্ডেক্সিং ও মাঝে মাঝে নির্বাচিত ডেনরমালাইজেশন নিতে পারবেন। যদি এটি রাইট-হেভি (ইভেন্ট ইনজেশন, টেলিমেট্রি, উচ্চ ভলিউম অর্ডার), তাহলে এমন একটি স্কিমাকে অগ্রাধিকার দিন যা লেখাকে সরল ও পূর্বানুমিত রাখে, তারপর যেখানে দরকার রিড অপ্টিমাইজেশন যোগ করুন।
প্রাথমিক-স্টেজে সাধারণ প্যাটার্ন যা লেখাকে ক্ষতিগ্রস্ত করে
- অডিট লগ: কমপ্লায়েন্সের জন্য ভালো, কিন্তু প্রতিটি আপডেটে বড় স্ন্যাপশট লগ করা থেকে বিরত থাকুন।
- ইভেন্ট টেবিল: অ্যাপেন্ড-ওনলি টেবিল ভালভাবে স্কেল করে, কিন্তু যদি আপনি হুবহু পে-লোড রিপিট রাখেন তবে বোম্বুষ্ট হবে।
- সফট ডিলেট: সুবিধাজনক, কিন্তু ইন্ডেক্স সাইজ বাড়ায় এবং আপডেট/কোয়েরি ধীর করতে পারে যদি পরিকল্পনা না করা হয়।
ইতিহাস সংরক্ষণ করে লেখাকে সরল রাখুন
একটি ব্যবহারিক পদ্ধতি:
- “কারেন্ট স্টেট” এক টেবিলে রাখুন, আর ইতিহাস আলাদা একটি অ্যাপেন্ড-ওনলি টেবিলে রাখুন।
- ইতিহাস রো সংকীর্ণ রাখুন (খুবই দরকারি মাত্র: কে/কখন/কি পরিবর্তিত হয়েছে)।
- বাস্তব অ্যাক্সেস প্যাটার্ন অনুসারে ইতিহাসে ইন্ডেক্স যোগ করুন (সাধারণত
entity_id,created_at)। - শুরুতে অডিটিংয়ের জন্য ট্রিগার না ব্যবহার করুন; পরিবর্তে স্পষ্ট অ্যাপ্লিকেশন লেখন ব্যবহার করুন যাতে খরচ দৃশ্যমান ও টেস্টযোগ্য হয়।
পরিষ্কার রাইট পাথ আপনাকে মাথাপিছু স্পেস দেয়—এবং পরে কোয়েরি অপ্টিমাইজেশন অনেক সহজ করে।
ORM এবং API কিভাবে স্কিমা সিদ্ধান্তকে বাড়ায়
ORM অ্যাপ তথ্যভাণ্ডবকে সহজ মনে করায়: আপনি মডেল ডিফাইন করেন, মেথড কল করেন, এবং ডেটা আসে। কস্ট হচ্ছে ORM অনেক সময় ব্যয়বহুল SQL লুকিয়ে রাখতে পারে যতক্ষণ না সেটি আঘাত করে।
ORM: সুবিধা যা ধীর প্যাটার্ন লুকাতে পারে
দুই সাধারণ ফাঁদ:
- অকার্যকর জয়েন: একটি মসৃণ
.include()বা নেস্টেড সিরিয়ালাইজার বড় জয়েন, ডুপ্লিকেট রো, বা বড় সোর্টে রূপান্তরিত করতে পারে—বিশেষত যদি সম্পর্ক পরিষ্কারভাবে সংজ্ঞায়িত না থাকে। - N+1 কোয়েরি: আপনি 50 রেকর্ড নিয়ে আসেন, তারপর ORM নীরবে সম্পর্কিত ডেটা লোড করতে 50 আরও কোয়েরি চালায়। ডেভেলপমেন্টে প্রায়ই কাজ করে এবং বাস্তব ট্রাফিকে ভেঙে পড়ে।
ভালভাবে ডিজাইন করা স্কিমা এই প্যাটার্নগুলো উদ্ভব হওয়ার সম্ভাবনা কমায় এবং সেগুলো দেখা গেলে সনাক্ত করা সহজ করে।
স্পষ্ট সম্পর্ক ORM ব্যবহারের নিরাপত্তা বাড়ায়
যখন টেবিলগুলিতে স্পষ্ট ফরেন কি, ইউনিক কনস্ট্রেইন্ট, এবং নট-নাল নিয়ম থাকে, ORM নিরাপদ কোয়েরি জেনারেট করতে পারে এবং আপনার কোড নির্ভর করতে পারে ধারাবাহিক অনুমানের উপর।
উদাহরণ: orders.user_id অবশ্যই থাকবে (FK এনফোর্স) এবং users.email ইউনিক হওয়া নিশ্চিত করলে অনেক ধরণের এজ-কেস অ্যাপে না এসে কোয়েরি স্তরে সমাধান হয়।
API স্কিমা সিদ্ধান্তকে প্রোডাক্ট আচরণে রূপ দেয়
আপনার API ডিজাইন স্কিমার নিচে পড়ে:
- স্থিতিশীল ID (এবং ধারাবাহিক কী টাইপ) URL, ক্যাশিং, এবং ক্লায়েন্ট-সাইড স্টেট সহজ করে।
- পেজিনেশন সবচেয়ে ভাল কাজ করে যখন আপনি একটি ইনডেক্সড, মনোটোনিক কলাম দিয়ে অর্ডার করতে পারেন (সাধারণত
created_at+id)। - ফিল্টারিং তখনই পূর্বানুমিত হয় যখন কলামগুলো বাস্তব অ্যাট্রিবিউট প্রতিনিধিত্ব করে (ওভারলোডেড স্ট্রিং বা JSON ব্লব নয়) এবং কনস্ট্রেইন্ট মানগুলো পরিষ্কার রাখে।
এটিকে একটি ওয়ার্কফ্লো বানান, উদ্ধার অভিযান নয়
স্কিমা সিদ্ধান্তগুলোকে প্রথম-শ্রেণীর ইঞ্জিনিয়ারিং হিসেবে ট্রিট করুন:
- প্রতিটি পরিবর্তনের জন্য মাইগ্রেশন ব্যবহার করুন, কোডের মতো রিভিউ করুন (/blog/migrations).
- নতুন এন্ডপয়েন্টের জন্য হালকা “স্কিমা রিভিউ” যোগ করুন: কোন টেবিল, কোন কী, কোন কনস্ট্রেইন্ট, কী কোয়েরি আকার হবে।
- স্টেজিং-এ ORM কোয়েরিগুলো লগ করুন এবং N+1 প্যাটার্নগুলো প্রোডাকশনে যাওয়ার আগে ফ্ল্যাগ করুন (/blog/orm-performance-checks).
যদি আপনি দ্রুত বিল্ড করছেন একটি চ্যাট-চালিত ডেভেলপমেন্ট ওয়ার্কফ্লো দিয়ে (উদাহরণ হিসেবে React অ্যাপ এবং Go/PostgreSQL ব্যাকএন্ড জেনারেট করা Koder.ai), তখন “স্কিমা রিভিউ” কথোপকথনের অংশ বানানো সাহায্য করে। আপনি দ্রুত ইটারেট করতে পারবেন, কিন্তু কনস্ট্রেইন্ট, কী, এবং মাইগ্রেশন পরিকল্পনা deliberate হওয়া উচিত—বিশেষত ট্রাফিক আসার আগে।
প্রাথমিক সতর্কবার্তা যে স্কিমা বটলনেক হচ্ছে
কিছু পারফরম্যান্স সমস্যা “খারাপ SQL” নয় বরং ডাটাবেস আপনার ডেটার আকারের বিরুদ্ধে লড়ছে। যদি আপনি অনেক এন্ডপয়েন্ট ও রিপোর্টে একই ধরণের সমস্যা দেখেন, সাধারণত এটা স্কিমা সংকেত, কোয়েরি-টিউনিংয়ের সুযোগ নয়।
নজর রাখার সাধারণ উপসর্গ
ধীর ফিল্টার একটি ক্লাসিক ইঙ্গিত। যদি “কাস্টমার অনুযায়ী অর্ডার খুঁজুন” বা “তৈরি তারিখ অনুযায়ী ফিল্টার” মত সরল শর্তগুলো ধারাবাহিকভাবে ধীর হয়, সমস্যা হতে পারে মিসিং সম্পর্ক, টাইপ মিসম্যাচ, বা এমন কলাম যেগুলো কার্যকরভাবে ইনডেক্স করা যায় না।
আরেকটা লাল পতাকা হল জয়েন সংখ্যা বিস্ফোরণ: একটি কোয়েরি যা 2–3 টেবিল জয়েন করা উচিত ছিল, সেটি 6–10 টেবিল জয়েন করে কারণ ওভার-নরমালাইজড লুকআপ, পলিমরফিক প্যাটার্ন, বা "সবকিছু এক টেবিলে" ডিজাইনের কারণে।
তারপর কলামে অসামঞ্জস্যপূর্ণ মান—বিশেষত স্ট্যাটাস ফিল্ড—যেমন “active”, “ACTIVE”, “enabled”, “on” দেখা গেলে সাবধান। অসামঞ্জস্য নিরাপদ কোয়েরি চালাতে বাধ্য করে (LOWER(), COALESCE(), OR-চেইন) যা যতই টিউন করা হোক ধীরই থাকবে।
স্কিমা চেকলিস্ট (দ্রুত যাচাই করার জন্য)
- ফরেন কি (জয়েন কলামে) অনুপস্থিত ইন্ডেক্স (টেবিল বড় হলে জয়েন ফুল স্ক্যান হবে)।
- ভুল ডেটা টাইপ (IDs স্ট্রিং, তারিখ টেক্সট হিসাবে, অর্থ float হিসেবে)।
- EAV টেবিল (Entity–Attribute–Value) কোর ডেটার জন্য ব্যবহৃত: শুরুতে নমনীয়, কিন্তু ফিল্টার/সোর্ট অনেক জয়েন ও হার্ড-টু-ইন্ডেক্স প্রেডিকেটে পরিণত করে।
সরল, টুল-নিরপেক্ষ ডায়াগনোস্টিক
শুরুতে বাস্তবতা চেক করুন: প্রতিটি টেবিলের রো কাউন্ট, ও কী কলামগুলোর কার্ডিনালিটি (কতটি ভিন্ন মান)। যদি একটি “status” কলামে 4 প্রত্যাশিত মান থাকা উচিত আর আপনি 40 দেখতে পান, স্কিমা ইতিমধ্যে জটিলতা ফাঁস করছে।
তারপর আপনার ধীর এন্ডপয়েন্টগুলির কোয়েরি প্ল্যান দেখুন। যদি আপনি বারবার join কলামে সিকোয়েনশিয়াল স্ক্যান বা বড় ইন্টারমিডিয়েট রেজাল্টস দেখেন, স্কিমা ও ইন্ডেক্সিং হচ্ছে মূল কারণ।
অবশেষে, স্লো কোয়েরি লগ সক্রিয় করে পর্যালোচনা করুন। যখন অনেক ভিন্ন কোয়েরি একইভাবে ধীর (একই টেবিল, একই প্রেডিকেট), সাধারণত এটি একটি গঠনগত সমস্যা যা মডেল স্তরে ঠিক করা উচিত।
বাড়তে গিয়ে স্কিমা নিরাপদভাবে বিবর্তিত করা
হোস্টিংসহ ডেপ্লয় করুন
প্রথমে ইনফ্রাস্ট্রাকচার সেটআপ না করে আপনার অ্যাপ ডেপ্লয় ও হোস্ট করুন।
প্রাথমিক স্কিমা সিদ্ধান্তগুলো সাধারণত প্রথম ব্যবহারকারীর সাথে টিকে থাকে না। লক্ষ্য হল “দূরদর্শী” না হয়ে—বরং পরিবর্তন করা যাতে প্রোডাকশনে ভাঙা, ডেটা হারানো, বা দল এক সপ্তাহ পিছু হটতে না হয়।
হালকা, পুনরাবৃত্ত পরিবর্তন প্রক্রিয়া
একটি ব্যবহারিক ওয়ার্কফ্লো যা এক ব্যক্তি অ্যাপ থেকে বড় টিম পর্যন্ত স্কেল করে:
- মডেল: নতুন আকার লিখে রাখুন (টেবিল/কলাম, সম্পর্ক, এবং কী হবে সোর্স অফ ট্রুথ)। উদাহরণ রেকর্ড ও এজ-কেস অন্তর্ভুক্ত করুন।
- মাইগ্রেট: নতুন স্ট্রাকচার ব্যাকওয়ার্ড-কম্প্যাটিবলভাবে যোগ করুন (নতুন কলাম/টেবিল প্রথমে; সরানো বা রিনেম তাত্ক্ষণিকভাবে এড়িয়ে চলুন)।
- ব্যাকফিল: ব্যাচে বিদ্যমান ডেটা থেকে নতুন ফিল্ডpopulate করুন। প্রগতি ট্র্যাক করুন যাতে পুনরায় শুরু করা যায়।
- ভ্যালিডেট: ডেটা পরিষ্কার হওয়ার পরে কনস্ট্রেইন্ট যোগ করুন (উদাহরণ: NOT NULL, ফরেন কি)। পুরনো বনাম নতুন আউটপুট তুলনা করে চেক চালান।
ফিচার ফ্ল্যাগ ও ডুয়াল-রাইট (সংযতভাবে ব্যবহার করুন)
অধিকাংশ স্কিমা পরিবর্তনে জটিল রিলোয়াল প্যাটার্ন দরকার নেই। “এক্সপ্যান্ড-এন্ড-কনট্র্যাক্ট” নীতি অনুসরণ করুন: কোড লিখে এমন রাখুন যে এটি পুরানো ও নতুন উভয়ের পড়তে পারে, তারপর একবার আত্মবিশ্বাস হলে রাইট পরিবর্তন করুন।
ফিচার ফ্ল্যাগ বা ডুয়াল-রাইট শুধু তখনই ব্যবহার করুন যখন ধীরে ধীরে কাটওভার প্রয়োজন (উচ্চ ট্রাফিক, দীর্ঘ ব্যাকফিল, বা একাধিক সার্ভিস)। ডুয়াল-রাইট করলে ড্রিফট ডিটেকশনের মনিটরিং যোগ করুন এবং দ্বন্দ্বে কোন পাশ জিতবে তা নির্ধারণ করুন।
রোলব্যাক ও মাইগ্রেশন টেস্টিং বাস্তবতাকে প্রতিফলিত করা উচিত
নিরাপদ রোলব্যাক শুরু হয় রিভার্সিবল মাইগ্রেশনের সঙ্গে। “আনডু” পথ অনুশীলন করুন: একটি নতুন কলাম ড্রপ করা সহজ; ওভাররাইট করা ডেটা পুনরুদ্ধার করা কঠিন।
প্রোডাকশন-মত ডেটা ভলিউমে মাইগ্রেশন টেস্ট করুন। ল্যাপটপে 2 সেকেন্ডের মাইগ্রেশন প্রোডাকশনে মিনিট লক করতে পারে। প্রোডাকশন-সদৃশ রো কাউন্ট ও ইন্ডেক্স নিয়ে রUNTIME পরিমাপ করুন।
এখানেই প্ল্যাটফর্ম টুলিং ঝুঁকি কমাতে পারে: নির্ভরযোগ্য ডেপ্লয়মেন্ট, স্নাপশট/রোলব্যাক, এবং কোড এক্সপোর্ট করার সক্ষমতা থাকলে স্কিমা ও অ্যাপ লজিকে একসঙ্গে ইটারেট করা নিরাপদ হয়। যদি আপনি Koder.ai ব্যবহার করেন, মাইগ্রেশন পরিচয়ে সাবধানতার প্রয়োজন হলে স্ন্যাপশট ও প্ল্যানিং মোড ব্যবহার করুন।
পরের ব্যক্তির জন্য সিদ্ধান্ত নথিভুক্ত করুন (আপনিও ভবিষ্যত ব্যক্তি)
একটি সংক্ষিপ্ত স্কিমা লগ রাখুন: কী বদলেছে, কেন বদল হয়েছে, এবং কোন ট্রেড-অফ গৃহীত হয়েছে। /docs বা আপনার রিপো README থেকে লিংক করুন। নোট যোগ করুন যেমন “এই কলাম ইচ্ছাকৃতভাবে ডেনরমালাইজ করা” বা “ফরেন কি ব্যাকফিলের পরে 2025-01-10-এ যোগ করা হয়েছে” যাতে ভবিষ্যৎ পরিবর্তনকারীরা পুরনো ত্রুটি পুনরাবৃত্তি না করে।
কখন কোয়েরি অপটিমাইজ করবেন (এবং যুক্তিসম্মত অর্ডার অব অপারেশন্স)
কোয়েরি অপটিমাইজেশন জরুরি—কিন্তু এটা সবচেয়ে লাভজনক যখন আপনার স্কিমা আপনাকে লড়াই করছিল না। যদি টেবিলগুলিতে স্পষ্ট কী না থাকে, সম্পর্ক inconsistent হয়, বা “এক ঘটনা প্রতি জিনিস” ভঙ্গ করা হয়, আপনি পরের সপ্তাহে পুনরায় লিখে ফেলবেন এমন কোয়েরি টিউন করতে ঘন্টা ব্যয় করতে পারেন।
ব্যবহারিক অগ্রাধিকার ক্রম
-
প্রথমে স্কিমা ব্লকার ঠিক করুন। এমন কিছু শুরু করুন যা সঠিকভাবে কোয়েরি করা কঠিন করে তোলে: অনুপস্থিত প্রাইমারী কী, inconsistent ফরেন কী, বহুমুখী অর্থ যুক্ত কলাম, সোর্স অব ট্রুথের ডুপ্লিকেশন, বা বাস্তবতার সঙ্গে না মিলানো টাইপ (উদাহরণ: তারিখ স্ট্রিং হিসেবে)।
-
অ্যাক্সেস প্যাটার্ন স্থিতিশীল করুন। একবার ডেটা মডেল এমনভাবে প্রতিফলিত করে যেভাবে অ্যাপ আচরণ করে (এবং পরবর্তী কয়েকটি স্প্রিন্টের জন্য সম্ভাব্য আচরণ), কোয়েরি টিউনিং টেকসই হবে।
-
শীর্ষ কোয়েরিগুলো অপ্টিমাইজ করুন—সব কোয়েরি নয়। লগ/APM ব্যবহার করে ধীর ও সবচেয়ে ঘন কোয়েরিগুলো চিহ্নিত করুন। প্রতি দিন 10,000 বার হিট হওয়া একটি এন্ডপয়েন্ট সাধারণত বিরল অ্যাডমিন রিপোর্টকে পেছনে ফেলে।
প্রারম্ভিক কোয়েরি টিউনিংয়ের 80/20
প্রাথমিক জয় অধিকাংশই একটি ছোট সেটের পরিবর্তন থেকে আসে:
- আপনার সবচেয়ে সাধারণ ফিল্টার ও জয়েনের জন্য সঠিক ইন্ডেক্স যোগ করুন (এবং নিশ্চিত করুন এটি ব্যবহার হচ্ছে)।
- কম কলাম ফেরত দিন (বিশেষত ওয়াইড টেবিলে
SELECT *এড়ান)। - অপ্রয়োজনীয় জয়েন এড়ান—কখনও কখনও জয়েন কেবল থাকে কারণ স্কিমা আপনাকে “ভিত্তি” আবিষ্কার করতে বাধ্য করে।
প্রত্যাশা সেট করুন: এটি চলমান কাজ, কিন্তু ভিত্তি প্রথম আসে
পারফরম্যান্স কাজ শেষ হয় না, কিন্তু লক্ষ্য এটি পূর্বানুমিত করা। পরিষ্কার স্কিমা থাকলে প্রতিটি নতুন ফিচার বাড়তি লোড যোগ করে; একটি মিশ্র স্কিমা থাকলে প্রতিটি ফিচার যৌগিক জটিলতা যোগ করে।
এই সপ্তাহের চেকলিস্ট
- শীর্ষ 5টি ধীরতর এবং 5টি সবচেয়ে ঘন কোয়েরির তালিকা করুন।
- প্রতিটির জন্য নিশ্চিত করুন: প্রাইমারি কি আছে, জয়েনগুলো key-to-key, এবং টাইপগুলো সঠিক।
- একটি ইন্ডেক্স যোগ করুন যা ডোমিন্যান্ট ফিল্টার/অর্ডার মেলে।
- একটি হট পাথে
SELECT *প্রতিস্থাপন করুন। - পুনঃপরিমাপ করুন এবং পরের স্প্রিন্টের জন্য একটি সহজ “পূর্ব/পশ্চাৎ” নোট রাখুন।