২৩ জুন, ২০২৫·8 মিনিট
Snowflake-এর স্টোরেজ/কম্পিউট বিভাজন: পারফরম্যান্স এবং ইকোসিস্টেম
জানুন Snowflake কীভাবে স্টোরেজ ও কম্পিউট আলাদা করার ধারণাকে জনপ্রিয় করে, কীভাবে তা স্কেলিং ও খরচের ট্রেড‑অফ বদলায়, এবং কেন ইকোসিস্টেম কাঁচা গতি জিততে পারে।
জানুন Snowflake কীভাবে স্টোরেজ ও কম্পিউট আলাদা করার ধারণাকে জনপ্রিয় করে, কীভাবে তা স্কেলিং ও খরচের ট্রেড‑অফ বদলায়, এবং কেন ইকোসিস্টেম কাঁচা গতি জিততে পারে।
Snowflake ক্লাউড ডেটা ওয়্যারহাউসিং-এ একটি সহজ কিন্তু ব্যাপক ধারণা জনপ্রিয় করেছে: ডেটা স্টোরেজ এবং কুয়েরি কম্পিউট আলাদা রাখুন। এই বিভাজন ডেটা টিমগুলোর দুইটি রপ্ত সমস্যাকে বদলে দেয়—কীভাবে ওয়্যারহাউস স্কেল করে এবং আপনি কীভাবে ও কখন এর জন্য অর্থ প্রদান করেন।
ওয়ারহাউসকে একটি স্থির “বক্স” হিসেবে না দেখে (যেখানে বেশি ব্যবহারকারী, বেশি ডেটা, বা জটিল কুয়েরিগুলি একাধিক রিসোর্সের জন্য লড়াই করে), Snowflake-এর মডেল ডেটা একবার স্টোর করে প্রয়োজন অনুযায়ী সঠিক পরিমাণ কম্পিউট চালু করতে দেয়। ফলাফল প্রায়ই দ্রুত উত্তর, পিক ব্যবহারকালে কম বটলনেক, এবং কী খরচ করছে তা (এবং কখন) স্পষ্টভাবে নিয়ন্ত্রণযোগ্য হওয়া।
এই পোস্টটি সাবলীল ভাষায় ব্যাখ্যা করে স্টোরেজ এবং কম্পিউট আলাদা করার আসল অর্থ কী—এবং এর ফলে কী পরিবর্তন আসে:
আমরা নির্দেশ করব কোথায় মডেলসব কাজের সব সমস্যা জাদুমন্তর করে দেয় না—কারণ কিছু খরচ ও পারফরম্যান্স সারপ্রাইজ ওয়ার্কলোড ডিজাইনের কারণে আসে, প্ল্যাটফর্মের কারণে নয়।
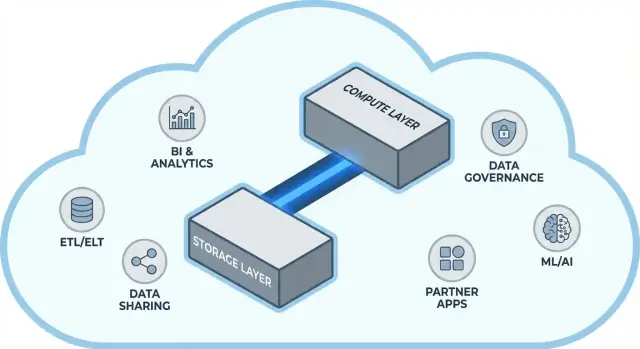
দ্রুত প্ল্যাটফর্ম পুরো গল্প নয়। অনেক টিমের জন্য টাইম-টু-ভ্যালু নির্ভর করে প্ল্যাটফর্মটিকে আপনি কি সহজে আপনার বিদ্যমান টুলগুলোর সঙ্গে কানেক্ট করতে পারেন—ETL/ELT পাইপলাইন, BI ড্যাশবোর্ড, ক্যাটালগ/গভর্ন্যান্স টুল, সিকিউরিটি কন্ট্রোল, এবং পার্টনার ডেটা সোর্স।
Snowflake-এর ইকোসিস্টেম (ডেটা শেয়ারিং প্যাটার্ন এবং মার্কেটপ্লেস-স্টাইল বিতরণসহ) ইমপ্লিমেন্টেশন টাইমলাইন ছোট করতে এবং কাস্টম ইঞ্জিনিয়ারিং কমাতে পারে। এই পোস্টটি দেখাবে বাস্তবে “ইকোসিস্টেম গভীরতা” কেমন লাগে এবং কীভাবে আপনার প্রতিষ্ঠানের জন্য তা মূল্যায়ন করবেন।
এই গাইডটি লেখা হয়েছে ডেটা লিডার, বিশ্লেষক, এবং নন-স্পেশালিস্ট ডিসিশন মেকারদের জন্য—যারা Snowflake আর্কিটেকচার, স্কেলিং, খরচ, এবং ইন্টিগ্রেশন পছন্দগুলোর ট্রেড-অফগুলি বুঝতে চান বিনা ভেন্ডর জার্গনে ঘেরা।
প্রচলিত ডেটা ওয়্যারহাউসগুলো একটি সরল অনুমান নিয়ে পঠন করা হত: আপনি একটি নির্দিষ্ট হার্ডওয়্যার কিনেন (বা ভাড়া দেন), তারপর সব কিছু একই বক্স বা ক্লাস্টারে চালান। যখন ওয়ার্কলোড পূর্বানুমানযোগ্য এবং বৃদ্ধি ধীরে ধীরে হত তখন তা কাজ করতো—কিন্তু ডেটা ভলিউম এবং ব্যবহারকারী সংখ্যা দ্রুত বাড়লে এটি কাঠামোগত সীমা তৈরি করে।
অন-প্রিম সিস্টেম (এবং প্রথম দফার ক্লাউড “লিফট-অ্যান্ড-শিফট”) সাধারণত এমন দেখায়:
ভেন্ডরগুলো “নোড” অফার করলেও মূল প্যাটার্ন একই রইল: স্কেলিং মানে সাধারণত বড় বা বেশি নোড যোগ করা এক ভাগ করা পরিবেশে।
এই ডিজাইন কয়েকটি সাধারণ মাথাব্যথা তৈরি করে:
এই ওয়্যারহাউসগুলো তাদের পরিবেশের সঙ্গে ঘনিষ্ঠভাবে জড়িত ছিল বলে, ইন্টিগ্রেশনগুলো প্রায়ই জৈবভাবে বেড়ে উঠত: কাস্টম ETL স্ক্রিপ্ট, হ্যান্ড-বিল্ট কানেক্টর, এবং এক-অফ পাইপলাইন। তারা কাজ করতো—যতক্ষণ না একটি স্কিমা বদলায়, একটি আপস্ট্রিম সিস্টেম সরায়, বা একটি নতুন টুল যোগ হয়। সব কিছুকে চালু রেখে রাখা ধীরে ধীরে রক্ষণাবেক্ষণের একটি অবিরাম কাজের মতো অনুভূত হত।
প্রচলিত ডেটা ওয়্যারহাউস প্রায়ই দুইটি ভিন্ন কাজ একে অপরের সঙ্গে বেঁধে রাখে: স্টোরেজ (আপনার ডেটা কোথায় থাকে) এবং কম্পিউট (CPU/মেমরি যা ডেটা পড়ে, জয়েন করে, অ্যাগ্রিগেট করে এবং লেখে)।
স্টোরেজ একটি দীর্ঘমেয়াদি প্যান্ট্রির মত: টেবিল, ফাইল, এবং মেটাডাটা নিরাপদে এবং সস্তায় রাখা হয়, স্থায়িত্ব ও সর্বদা উপলব্ধতার জন্য ডিজাইন করা।
কম্পিউট হল রান্নাঘরের কর্মী: এটি CPU এবং মেমরি সেট যা সত্যিই আপনার কুয়েরি “রান” করে—SQL চালায়, সাজায়, স্ক্যান করে, ফলাফল গঠন করে, এবং একসাথে বহু ব্যবহারকারীকে হ্যান্ডেল করে।
Snowflake এই দুইটিকে আলাদা করে যাতে প্রতিটিকে পরিবর্তন করা যায় অন্যটিকে বাধ্য করে না।
বাস্তবে, এটি দৈনন্দিন অপারেশন বদলে দেয়: ডেটা বাড়ার কারণে কম্পিউটকে ওভারবাই করতে হয় না, এবং আপনি ওয়ার্কলোডগুলো আলাদা করতে পারেন (উদাহরণ: বিশ্লেষক বনাম ETL) যাতে তারা একে অপরকে ধীর না করে।
এই বিভাজন শক্তিশালী, কিন্তু জাদু নয়।
মানটি হলো নিয়ন্ত্রণ: স্টোরেজ ও কম্পিউট আলাদা করে তাদের নিজ নিজ শর্তে পরিশোধ করা এবং প্রতিটিকে আপনার টিমের চাহিদার সঙ্গে মিলানো।
Snowflake সর্বোত্তমভাবে তিনটি লেয়ার হিসেবে বোঝা যায় যেগুলো একসঙ্গে কাজ করে, কিন্তু স্বাধীনভাবে স্কেল করতে পারে।
আপনার টেবিলগুলি শেষ পর্যন্ত ক্লাউড প্রোভাইডারের অবজেক্ট স্টোরেজে ডেটা ফাইল হিসেবে থাকে (S3, Azure Blob, অথবা GCS)। Snowflake ফাইল ফরম্যাট, কমপ্রেশন এবং অর্গানাইজেশন ম্যানেজ করে। আপনি ডিস্ক “অ্যাটাচ” করেন না বা স্টোরেজ ভলিউম সাইজ করেন না—স্টোরেজ ডেটা বাড়ার সাথে বাড়ে।
কম্পিউট প্যাকেজ করা হয় ভার্চুয়াল ওয়ারহাউস হিসেবে: স্বাধীন CPU/মেমরি ক্লাস্টার যা কুয়েরি কার্যকর করে। একই ডেটার উপর একাধিক ওয়ারহাউস একই সময়ে রান করতে পারে। এটি পুরনো সিস্টেমগুলোর মূল পার্থক্য যেখানে ভারী ওয়ার্কলোডগুলো একই রিসোর্স পুলের জন্য লড়াই করত।
একটি আলাদা সার্ভিস লেয়ার সিস্টেমের “ব্রেইন” হ্যান্ডেল করে: অথেনটিকেশন, কুয়েরি পার্সিং ও অপ্টিমাইজেশন, ট্রানজেকশন/মেটাডাটা ম্যানেজমেন্ট, এবং সমন্বয়। এই লেয়ার সিদ্ধান্ত নেয় যে কিভাবে একটি কুয়েরি দক্ষভাবে চালাতে হবে তার আগে কম্পিউট ডেটার কাছে যায়।
আপনি SQL সাবমিট করলে, Snowflake-এর সার্ভিস লেয়ার এটি পার্স করে, একটি এক্সিকিউশন প্ল্যান বানায়, তারপর সেই প্ল্যান একটি নির্বাচিত ভার্চুয়াল ওয়ারহাউস-এ পাঠায়। ওয়ারহাউসটি কেবল প্রয়োজনীয় ডেটা ফাইলগুলো অবজেক্ট স্টোরেজ থেকে পড়ে (ক্যাশিং সুবিধা থাকলে তা কাজে লাগে), প্রক্রিয়াকরণ করে, এবং ফলাফল ফেরত দেয়—বেস ডেটাকে স্থায়ীভাবে ওয়ারহাউসে সরিয়ে না নিয়ে।
যদি অনেকেই একসঙ্গে কুয়েরি চালায়, আপনি বা:
এটিই Snowflake-এর পারফরম্যান্স এবং “নয়জি মিগ্রেন” নিয়ন্ত্রণের আর্কিটেকচারাল ভিত্তি।
Snowflake-এর বড় ব্যবহারিক বদল হল আপনি কম্পিউটকে আলাদাভাবে স্কেল করতে পারেন ডেটা থেকে। “ওয়ারহাউস বড় হচ্ছে” বলার বদলে, আপনি প্রতিটি ওয়ার্কলোডের জন্য রিসোর্স আপ বা ডাউন করতে পারেন—বিনা টেবিল কপি, ডিস্ক রি-পার্টিশন, বা ডাউনটাইমের।
Snowflake-এ একটি ভার্চুয়াল ওয়ারহাউস হলো কুয়েরি চালানোর কম্পিউট ইঞ্জিন। আপনি সেকেন্ডের মধ্যে এটি রিসাইজ করতে পারেন (উদাহরণ: Small থেকে Large), এবং ডেটা একই জায়গায় থাকে। মানে পারফরম্যান্স টিউনিং প্রায়ই একটি সহজ প্রশ্নে নেমে আসে: “এই ওয়ার্কলোড কি এখন বেশি শক্তি প্রয়োজন?”
এটি অস্থায়ী বুর্সও সম্ভব করে: মাসশেষ ক্লোজের জন্য বাড়ান, স্পাইক পেরোলেই নামিয়ে আনুন।
প্রচলিত সিস্টেমগুলো প্রায়ই বিভিন্ন টিমকে একই কম্পিউট শেয়ার করতে বাধ্য করে, ফলে ব্যস্ত সময়গুলোতে কিউ লাইন তৈরি হয়।
Snowflake আপনাকে বিভিন্ন টিম বা ওয়ার্কলোড-এর জন্য অলাদা ওয়ারহাউস দিতে দেয়—যেমন একটি বিশ্লেষকদের জন্য, একটি ড্যাশবোর্ডের জন্য, এবং একটি ETL-এর জন্য। যেহেতু এরা একই আন্ডারলাইন ডেটা পড়ে, আপনি "তোমার ড্যাশবোর্ড আমার রিপোর্ট ধীর করে দিলো" সমস্যা কমান এবং পারফরম্যান্সকে আরও পূর্বানুমেয় বানান।
ইলাস্টিক কম্পিউট স্বয়ংক্রিয় সাফল্য নয়। সাধারণ সমস্যা:
মোট পরিবর্তন: স্কেলিং ও সমান্তরালতা ইনফ্রাস্ট্রাকচার প্রকল্প থেকে দৈনন্দিন অপারেটিং সিদ্ধান্তে পরিণত হয়।
Snowflake-এর "pay for what you use" মূলত দুইটি মিটারের সমান্তরাল চালক:
এই বিভাজনেই সাশ্রয় ঘটার জায়গা ছাড়া: আপনি অনেক ডেটা তুলনামূলকভাবে সস্তায় রাখতে পারেন এবং কেবল যখন প্রয়োজন তখনই কম্পিউট চালু রাখেন।
অধিকাংশ "অপ্রত্যাশিত" ব্যয় কম্পিউট আচরণ থেকে আসে, কাঁচা স্টোরেজ থেকে নয়। সাধারণ চালকগুলোর মধ্যে:
স্টোরেজ এবং কম্পিউট আলাদা থাকলে কুয়েরি স্বয়ংক্রিয়ভাবে দক্ষ হয় না—খারাপ SQL এখনও দ্রুত ক্রেডিট পোড়াতে পারে।
আপনাকে ফাইন্যান্স বিভাগ লাগবে না—কিছু গার্ডরেইলই যথেষ্ট:
ভালো ভাবে ব্যবহৃত হলে, মডেলটি শৃঙ্খলাকে পুরস্কৃত করে: স্বল্পকালীন, সঠিক-সাইজের কম্পিউট জোড়া ধারাবাহিক স্টোরেজ বৃদ্ধির সঙ্গে।
Snowflake শেয়ারিংকে প্ল্যাটফর্মে ডিজাইন করা একটা অংশ হিসেবে দেখে—এক্সপোর্ট, ফাইল ড্রপ, এবং এক-অফ ETL কাজের পরে লাগানো কিছু নয়।
এক্সট্র্যাক্ট পাঠানোর বদলে, Snowflake অন্য অ্যাকাউন্টকে একটি নিরাপদ “শেয়ার”-এর মাধ্যমে একই আন্ডারলাইন ডেটা কুয়েরি করতে দেয়। অনেক ক্ষেত্রে, ডেটা দ্বিতীয় ওয়ারহাউসে কপি করতে বা ডাউনলোডের জন্য অবজেক্ট স্টোরেজে পুশ করতে হয় না। কনসিউমার শেয়ার করা ডাটাবেজ/টেবিলকে স্থানীয় মতো দেখবে, অথচ প্রোভাইডার কন্ট্রোল রাখতে পারবে কোনটি এক্সপোজ হচ্ছে।
এই “ডিকপ্লড” পদ্ধতি ডেটা স্প্রল কমায়, অ্যাক্সেস দ্রুত করে, এবং আপনার তৈরি করা/রক্ষণাবেক্ষণ করা পাইপলাইনগুলোর সংখ্যা কমায়।
পার্টনার ও কাস্টমার শেয়ারিং: একজন ভেন্ডর কারিগরি সেট কিউরেটেড ডেটাসেট গ্রাহকদের প্রকাশ করতে পারে (যেমন ব্যবহার বিশ্লেষণ বা রেফারেন্স ডেটা) স্পষ্ট সীমানা সহ—শুধুমাত্র অনুমোদিত স্কিমা, টেবিল, বা ভিউ।
ইন্টার্নাল ডোমেইন শেয়ারিং: সেন্ট্রাল টিমগুলি সার্টিফায়েড ডেটাসেটগুলো প্রোডাক্ট, ফাইন্যান্স, অপারেশনসকে এক্সপোজ করতে পারে যাতে প্রত্যেকে তাদের নিজস্ব কুয়েরিটি চালাতে পারে, সবকিছু কপি না করেই। এটি "এক সেট নম্বর" সংস্কৃতি সমর্থন করে।
গভর্নড সহযোগিতা: সম্মিলিত প্রজেক্টগুলো (যেমন একটি এজেন্সি, সাপ্লায়ার, বা সাবসিডিয়ারি) শেয়ার করা ডেটা থেকে কাজ করতে পারে এবং সংবেদনশীল কলাম মাস্ক করা ও অ্যাক্সেস লগ করা যায়।
শেয়ারিং "সেট এবং ভুলে যান" নয়। আপনাকে এখনও:
দ্রুত ওয়্যারহাউস মূল্যবান, কিন্তু কেবল স্পিডই প্রজেক্ট সময়সীমা নির্ধারণ করে না। প্রকৃত পার্থক্য ঘটে যখন প্ল্যাটফর্মটিতে প্রস্তুত সংযোগ, টুলস, এবং নলেজ থাকে—যা কাস্টম কাজ কমায়।
বাস্তবে, একটি ইকোসিস্টেম অন্তর্ভুক্ত করে:
বেঞ্চমার্ক একটি সীমিত অংশের পারফরম্যান্স পরিমাপ করে। বাস্তব প্রকল্পের বেশিরভাগ সময় যায়:
আপনার প্ল্যাটফর্ম যদি এই ধাপগুলোর জন্য পরিপক্ক ইন্টিগ্রেশন দেয়, আপনি গ্লু কোড তৈরি ও রক্ষণাবেক্ষণ এড়াতে পারবেন। সাধারণত এটাই ইমপ্লিমেন্টেশন টাইমলাইন ছোট করে, নির্ভরযোগ্যতা বাড়ায়, এবং টিম/ভেন্ডর বদলালে বিস্তর পুনর্লিখন কমায়।
ইকোসিস্টেম মূল্যায়ন করলে খেয়াল রাখুন:
পারফরম্যান্স আপনাকে সক্ষমতা দেয়; ইকোসিস্টেম প্রায়ই নির্ধারণ করে আপনি কত দ্রুত সেই সক্ষমতাকে বাণিজ্যিক ফলাফলতে রূপান্তর করতে পারবেন।
Snowflake দ্রুত কুয়েরি চালাতে পারে, কিন্তু মূল্য তখনই বাস্তবে আসে যখন ডেটা নির্ভরযোগ্যভাবে আপনার স্ট্যাকে যায়: সোর্স থেকে Snowflake-এ, এবং পুনরায় টুলগুলিতে যার মাধ্যমে লোকেরা প্রতিদিন ব্যবহার করে। “লাস্ট মাইল” সাধারণত নির্ধারণ করে প্ল্যাটফর্মটা সহজ লাগে নাকি সবসময় ভঙ্গুর।
বেশিরভাগ টিম মিশ্রণ প্রয়োজন পড়ে:
সব "Snowflake-কম্প্যাটিবল" টুল একইভাবে আচরণ করে না। মূল্যায়নের সময় প্র্যাকটিক্যাল বিবরণে মনোযোগ দিন:
ইন্টিগ্রেশনগুলোকে ডে-2 প্রস্তুতিও দরকার: মনিটরিং ও অ্যালার্টিং, লিনিয়েজ/ক্যাটালগ হুক, এবং ইনসিডেন্ট রেসপন্স ওয়ার্কফ্লো (টিকেটিং, অন-কল, রানবুক)। শক্তিশালী ইকোসিস্টেম মানে কেবল বেশি লোগো নয়—এটি রাত দুইটায় পাইপলাইন ফেল হওয়ার সময় কম সারপ্রাইজ।
টিমগুলো বাড়ার সঙ্গে সঙ্গে অ্যানালিটিক্সের সবচেয়ে কঠিন অংশ প্রায়ই স্পিড নয়—এটি নিশ্চিত করা যে সঠিক মানুষ সঠিক ডেটা কাছে পাচ্ছে, সঠিক উদ্দেশ্যে, এবং নিয়ন্ত্রণ কাজ করছে এই প্রমাণ সহ। Snowflake-এর গভর্ন্যান্স ফিচারগুলো এই বাস্তবতার জন্য ডিজাইন করা: বহু ব্যবহারকারী, বহু ডেটা প্রোডাক্ট, এবং ঘন ঘন শেয়ারিং।
স্পষ্ট রোল এবং লিস্ট-অফ-প্রিভিলেজ মাইন্ডসেট দিয়ে শুরু করুন। ব্যক্তিদের সরাসরি অ্যাক্সেস দেয়ার বদলে ANALYST_FINANCE বা ETL_MARKETING মতো রোল সংজ্ঞায়িত করুন, তারপর সেগুলিকে নির্দিষ্ট ডাটাবেস, স্কিমা, টেবিল, এবং প্রয়োজনে ভিউ-তে অনুমতি দিন।
সংবেদনশীল ফিল্ডের জন্য (PII, আর্থিক আইডেন্টিফায়ার), masking policies ব্যবহার করুন যাতে লোকেরা ডেটাসেট কুয়েরি করতে পারে কিন্তু কাঁচা ভ্যালু না দেখতে পায় যদি তাদের রোল অনুমতি না দেয়। এটিকে অডিটিং-এর সঙ্গে জোড়া দিন: কে কখন কী কুয়েরি করেছে তা ট্র্যাক করুন, যাতে সিকিউরিটি ও কমপ্লায়েন্স টিম কাগজপত্র ছাড়াই প্রশ্নের উত্তর দিতে পারে।
ভালো গভর্ন্যান্স শেয়ারিংকে নিরাপদ ও স্কেলেবল করে তোলে। যখন আপনার শেয়ারিং মডেল রোল, নীতি, এবং অডিট করা অ্যাক্সেসের উপর নির্মিত, তখন আপনি আত্মবিশ্বাসের সঙ্গে সেলফ-সার্ভ সক্ষম করতে পারেন (বেশি ব্যবহারকারী ডেটা এক্সপ্লোর করবে) বিনা দুর্ঘটনাজনিত এক্সপোজার।
এটি কমপ্লায়েন্স প্রচেষ্টার ঘর্ষণও কমায়: নীতিগুলো রিপিটেবল কন্ট্রোল হয়ে যায়, এক-অফ এক্সেপশন নয়। যখন ডেটাসেটগুলো প্রকল্প, ডিপার্টমেন্ট, বা বাইরের পার্টনারদের মধ্যে পুনরায় ব্যবহৃত হয়, তখন এটা গুরুত্বপূর্ণ।
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X)। সঙ্গতি রিভিউ গতি বাড়ায় ও ভুল কমায়।স্কেলে বিশ্বাস মানে একটি “পারফেক্ট” কন্ট্রোল নয়, বরং ছোট, নির্ভরযোগ্য অভ্যাসগুলোর সিস্টেম যা অ্যাক্সেসকে ইচ্ছাকৃত এবং বর্ণনাযোগ্য রাখে।
Snowflake সাধারণত তখন উজ্জ্বল হয় যখন বহু মানুষ এবং টুল একই ডেটা বিভিন্ন কারণে কুয়েরি করে। কম্পিউট যদি স্বাধীন "ওয়ারহাউস"-এ প্যাকেজ করা থাকে, আপনি প্রতিটি ওয়ার্কলোডকে একটি আকার ও সময়সূচি দিতে পারেন যা মানানসই।
Analytics & dashboards: BI টুলগুলোকে নিযুক্ত একটি ডেডিকেটেড ওয়ারহাউসে দিন যেটি স্থির, পূর্বানুমেয় কুয়েরি ভলিউমের জন্য সাইজ করা। এতে ড্যাশবোর্ড রিফ্রেশগুলো অ্যাড হক এক্সপ্লোরেশনের দ্বারা ধীর হবে না।
Ad hoc analysis: বিশ্লেষককে আলাদা, প্রায়শই ছোট ওয়ারহাউস দিন (auto-suspend চালু)। দ্রুত ইটারেশন পাওয়া যায়, কিন্তু অব্যবহৃত সময়ের জন্য অর্থ কম লাগে।
Data science & experimentation: ভারী স্ক্যান ও মাঝে মাঝে বিস্ফোরণকারী চাহিদার জন্য সাইজ করা একটি ওয়ারহাউস ব্যবহার করুন। পরীক্ষা স্পাইক করলে অস্থায়ীভাবে আপস্কেল করুন যাতে BI ইউজাররা প্রভাবিত না হন।
Data apps & embedded analytics: অ্যাপ ট্রাফিককে একটি প্রোডাকশন-সদৃশ সার্ভিস হিসেবে বিবেচনা করুন—আলাদা ওয়ারহাউস, রক্ষণশীল টাইমআউট, এবং রিসোর্স মনিটর যাতে আচমকা খরচ না আসে।
যদি আপনি হালকা ওজনের অভ্যন্তরীণ ডেটা অ্যাপ তৈরি করেন (উদাহরণ: একটি অপস পোর্টাল যা Snowflake কুয়েরি করে KPI দেখায়), একটি দ্রুত পথ হলো React + API স্ক্যাফোল্ড জেনারেট করে স্টেকহোল্ডারদের সাথে ইটারেট করা। Koder.ai মত প্ল্যাটফর্ম (চ্যাট থেকে ওয়েব/সার্ভার/মোবাইল অ্যাপ বানায় এমন ভিব-কোডিং টুল) টিমগুলোকে এই Snowflake-ব্যাকড অ্যাপগুলো দ্রুত প্রোটোটাইপ করতে সাহায্য করতে পারে এবং যখন আপনি অপারেশনালাইজ করতে প্রস্তুত তখন সোর্স কোড এক্সপোর্ট করতে দেয়।
একটি সরল নিয়ম: দর্শক ও উদ্দেশ্য অনুযায়ী ওয়ারহাউস আলাদা করুন (BI, ELT, ad hoc, ML, অ্যাপ)। সেটি ভাল কুয়েরি অভ্যাস-এর সঙ্গে জোড়া—বৃহৎ SELECT * এড়ান, আগে ফিল্টার করুন, ও অদক্ষ জয়েনের নজর রাখুন। মডেলিংয়ের ক্ষেত্রে, মানুষের কিভাবে কুয়েরি করে তা অনুসারে গঠন বাড়ান (সাধারণত একটি পরিষ্কার সেমান্টিক লেয়ার বা ভাল সংজ্ঞায়িত marts), ফিজিক্যাল লেআউট অতিমাত্রায় অপ্টিমাইজ করার বদলে।
Snowflake সবকিছুর বিকল্প নয়। উচ্চ-থ্রুপুট, কম-লেটেন্সি ট্রানজেকশনাল ওয়ার্কলোড (সাধারণ OLTP) জন্য বিশেষায়িত ডেটাবেস সাধারণত ভাল। Snowflake-কে অ্যানালিটিক্স, রিপোর্টিং, শেয়ারিং, এবং ডাউনস্ট্রীম ডেটা প্রোডাক্টের জন্য ব্যবহার করা হয়। হাইব্রিড সেটআপ সাধারণ এবং প্রায়ই সবচেয়ে ব্যবহারিক।
Snowflake মাইগ্রেশন সাধারণত “লিফট অ্যান্ড শিফট” নয়। স্টোরেজ/কম্পিউট বিভাজন কিভাবে আপনি সাইজ, টিউন, এবং ওয়ার্কলোডের জন্য অর্থ প্রদান করবেন তা বদলে দেয়—তাই আগে পরিকল্পনা করলে পরে সারপ্রাইজ কম হয়।
ইনভেন্টরিতে দিয়ে শুরু করুন: কোন সোর্সগুলো ওয়্যারহাউসকে ফিড করে, কোন পাইপলাইনগুলি তা ট্রান্সফর্ম করে, কোন ড্যাশবোর্ডগুলো এতে নির্ভরশীল, এবং প্রতিটি অংশের মালিক কে। তারপর ব্যবসায়িক প্রভাব ও জটিলতা অনুযায়ী অগ্রাধিকার দিন (উদাহরণ: গুরুত্বপূর্ণ ফাইন্যান্স রিপোর্টিং আগে, পরীক্ষামূলক ছকবক্স পরে)।
পরবর্তী ধাপে SQL ও ETL লজিক কনভার্ট করুন। বেশিরভাগ স্ট্যান্ডার্ড SQL ট্রান্সফার হয়, কিন্তু কিছু ডিটেইল—ফাংশন, তারিখ হ্যান্ডলিং, প্রক্রিয়াগত কোড, এবং টেম্প-টেবিল প্যাটার্ন—প্রায়ই রিরাইট করা লাগে। তাড়াতাড়ি ফলাফল ভ্যালিডেট করুন: প্যারালাল আউটপুট চালান, রো কাউন্ট ও অ্যাগ্রিগেট তুলনা করুন, এবং এজ কেসগুলো নিশ্চিত করুন (NULL, টাইমজোন, ডেডুপ লজিক)। শেষমেশ কাটওভার পরিকল্পনা করুন: ফ্রিজ উইন্ডো, রোলব্যাক পথ, এবং প্রতিটি dataset ও রিপোর্টের জন্য স্পষ্ট "ডান হওয়ার সংজ্ঞা"।
হাইডেন ডিপেন্ডেন্সি সবচেয়ে সাধারণ: একটি স্প্রেডশিট এক্সট্র্যাক্ট, হার্ড-কোডেড কানেকশন স্ট্রিং, এমন একটি ডাউনস্ট্রীম জব যা কেউ মনে রাখে না। পারফরম্যান্স সারপ্রাইজ তখন আসে যখন পুরনো টিউনিং অনুমান প্রযোজ্য না (উদাহরণ: অতিরিক্ত ছোট ওয়ারহাউস ব্যবহার, বা বহু ছোট কুয়েরি চালিয়ে সমান্তরালতা বিবেচনা না করা)। খরচ স্পাইক সাধারণত আসে ওয়ারহাউস ছেড়ে রাখলে, অনিয়ন্ত্রিত রিট্রাই, বা ডুপ্লিকেট DEV/TEST ওয়ার্কলোডে। পারমিশন গ্যাপ দেখা দেয় যখন coarse রোল থেকে বেশি সূক্ষ্ম গভর্ন্যান্সে মাইগ্রেট করা হয়—টেস্টে "least privilege" ইউজার রান অন্তর্ভুক্ত করা উচিত।
একটি মালিকানা মডেল সেট করুন (কে ডেটা, পাইপলাইন, এবং খরচের মালিক), বিশ্লেষক ও ইঞ্জিনিয়ারদের জন্য রোল-বেসড প্রশিক্ষণ দিন, এবং কাটওভারের পর প্রথম কয়েক সপ্তাহের জন্য সাপোর্ট প্ল্যান সংজ্ঞায়িত করুন (অন-কল রোটেশন, ইনসিডেন্ট রানবুক, এবং সমস্যার রিপোর্ট করার একটি স্থান)।
আধুনিক ডেটা প্ল্যাটফর্ম বেছে নেওয়া কেবল শীর্ষ বেঞ্চমার্ক স্পিড নয়। এটি প্ল্যাটফর্ম আপনার প্রকৃত ওয়ার্কলোড, আপনার দলের কাজের ধরন, এবং আপনি যে টুলগুলো নির্ভর করেন সেগুলোর সঙ্গে কতটা খাপ খায় তা নিয়ে।
এই প্রশ্নগুলো আপনার শর্টলিস্ট ও ভেন্ডর আলাপ চালাতে গাইড করবে:
2–3 প্রতিনিধিত্বমূলক dataset বেছে নিন (একটি বড় fact, একটি অগোছালো semi-structured, এবং একটি ব্যবসায়-সমালোচনামূলক ডোমেইন)।
তারপর বাস্তব ইউজার কুয়েরি চালান: সকাল পিকে ড্যাশবোর্ড, বিশ্লেষক এক্সপ্লোরেশন, নির্ধারিত লোড, এবং কিছু ওয়ার্সট-কেস জয়েন। ট্র্যাক করুন: কুয়েরি সময়, সমান্তরাল আচরণ, ইনজেস্ট টাইম, অপারেশনাল শ্রম, এবং ওয়ার্কলোড প্রতি খরচ।
আপনি যদি মূল্যায়নে “কত দ্রুত আমরা কিছু মানুষ ব্যবহার করতে দেব” দেখতে চান, পাইলটে একটি ছোট ডেলিভারেবল যোগ করুন—যেমন একটি অভ্যন্তরীণ মেট্রিক্স অ্যাপ বা একটি গভর্নড ডেটা-রিকোয়েস্ট ওয়ার্কফ্লো যা Snowflake কুয়েরি করে। সেই পাতলা লেয়ার বিল্ড করলে ইন্টিগ্রেশন ও সিকিউরিটি বাস্তবতাগুলো বেঞ্চমার্কের তুলনায় দ্রুত প্রকাশ পায়, এবং Koder.ai মতো টুলস প্রোটোটাইপ-টু-প্রোডাকশনের কাজকে দ্রুত করে।
খরচ অনুমান ও অপশন তুলনা করতে /pricing দিয়ে শুরু করুন।
মাইগ্রেশন ও গভর্ন্যান্স নির্দেশিকার জন্য /blog ব্রাউজ করুন।
Snowflake আপনার ডেটা ক্লাউড অবজেক্ট স্টোরেজে রাখে এবং আলাদা কম্পিউট ক্লাস্টার—যা ভার্চুয়াল ওয়ারহাউস নামে পরিচিত—উপরে কুয়েরি চালায়। যেহেতু স্টোরেজ এবং কম্পিউট আলাদা, তাই আপনি কম্পিউটকে আলাদাভাবে বাড়ানো/কমানো (বা নতুন ওয়ারহাউস যোগ করা) করতে পারেন, আর এতে মৌলিক ডেটা সরাতে বা প্রতিলিপি তৈরি করতে হয় না।
এটি রিসোর্স প্রতিযোগিতা কমায়। আপনি বিভিন্ন ওয়ার্কলোড আলাদা ভার্চুয়াল ওয়ারহাউস-এ রেখে ওয়ার্কলোড আইসোলেট করতে পারেন (উদাহরণ: BI বনাম ETL), অথবা সিপাইক স্পাইক হয়ে গেলে মাল্টি-ক্লাস্টার ওয়ারহাউস ব্যবহার করে অতিরিক্ত কম্পিউট যোগ করতে পারেন। এতে ঐতিহ্যবাহী MPP সেটআপে যে “একই ক্লাস্টার শেয়ার করা” কিউয়িং সমস্যা দেখা দেয় তা কমে যায়।
আটোম্যাটিকভাবে নয়। ইলাস্টিক কম্পিউট আপনাকে নিয়ন্ত্রণ দেয়, কিন্তু আপনারাও গার্ডরেইল সেট করতে হবে:
খারাপ SQL, বারবার ড্যাশবোর্ড রিফ্রেশ, বা সবসময় অন থাকা ওয়ারহাউস এখনও উচ্চ কম্পিউট খরচ করে দিতে পারে।
বিলিং সাধারণত দুইটি মূল উপাদানে বিভক্ত:
এতে দেখা যায় কোনটি বর্তমানে খরচ তৈরি করছে (কম্পিউট) এবং কোনটি ধীরে ধীরে বাড়ছে (স্টোরেজ)।
অধিকাংশ ব্যয় “ডেটা সাইজ”-এর চেয়ে অপারেশনাল আচরণ থেকে আসে। সাধারণ কারণগুলির মধ্যে রয়েছে:
কয়েকটি বাস্তবকর্মী নিয়ন্ত্রণ (auto-suspend, monitors, শিডিউলিং) সাধারণত বড় সাশ্রয় দেয়।
এটি হল যখন একটি সাসপেন্ড করা ওয়ারহাউস আবার চালু হয়ে কাজ শুরু করে—প্রথম কুয়েরিতে কিছু বিলম্ব দেখা যায়। অনিয়মিত ওয়ার্কলোডের ক্ষেত্রে auto-suspend দামে সাশ্রয় এনে দেয়, কিন্তু প্রথম কুয়েরিতে ছোট সময়গত লেটেন্সি যোগ করতে পারে। ইউজার-ফেসিং ড্যাশবোর্ডের জন্য, ঘন ঘন suspend/resume চক্রের বদলে স্থিরভাবে চালিত একটি নির্দিষ্ট সাইজের ওয়ারহাউস বিবেচনা করুন।
ভার্চুয়াল ওয়ারহাউস হলো SQL কার্যকর করার জন্য স্বাধীন কম্পিউট ক্লাস্টার। দলগুলো সাধারণত ওয়ারহাউসকে শ্রোতা ও উদ্দেশ্য অনুযায়ী ম্যাপ করে:
এতে পারফর্ম্যান্স আলাদা থাকে এবং খরচের দায় স্পষ্ট হয়।
সাধারণত হ্যাঁ। Snowflake শেয়ারিং-এর মাধ্যমে কোনো অ্যাকাউন্টকে আপনি যে টেবিল/ভিউ এক্সপোজ করেন তা কুয়েরি করার অনুমতি দিতে পারেন, যার জন্য ফাইল এক্সপোর্ট বা অতিরিক্ত পাইপলাইন দরকার হয় না। তবে শেয়ারিং ব্যবহারের সময় শক্তিশালী গভর্ন্যান্স থাকা জরুরি—স্পষ্ট মালিকানা, অ্যাক্সেস রিভিউ, এবং সংবেদনশীল ফিল্ডের জন্য নীতিমালা যাতে শেয়ারিং নিয়ন্ত্রিত ও অডিটেবল থাকে।
কারণ প্রকল্প ডেলিভারি সাধারণত ইন্টিগ্রেশন ও অপারেশনাল কাজের ওপর নির্ভর করে, কেবল র ফাস্ট কুয়েরি-স্পিডেই নয়। একটি শক্তিশালী ইকোসিস্টেম কাস্টম ইঞ্জিনিয়ারিং কমিয়ে দেয়:
এগুলো বাস্তবে ইমপ্লিমেন্টেশনের সময়সীমা ছোট করে এবং ডে-2 বজায় রাখার ভার কমায়।
ছোট, বাস্তবসম্মত পাইলট (প্রায় 2–4 সপ্তাহ) ব্যবহার করুন:
খরচ অনুমান করতে /pricing দেখুন, এবং মাইগ্রেশন/গভর্ন্যান্স নির্দেশনার জন্য /blog ব্রাউজ করুন।